베이지안 관점에서 재조명한 k‑최근접 이웃 분류법
본 논문은 전통적인 k‑최근접 이웃(k‑NN) 알고리즘을 확률적 모델로 정형화하고, 베이지안 추론을 적용한다. 기존 Holmes‑Adams 모델의 비정합성을 보완하고, 정규화 상수의 추정 문제를 완전 샘플링과 Gibbs 샘플링으로 해결한다. 실험을 통해 의사가능도(pseudo‑likelihood) 접근법의 한계를 확인한다.
저자: Lionel Cucala¹, Jean‑Michel Marin¹³, Christian P. Robert²³
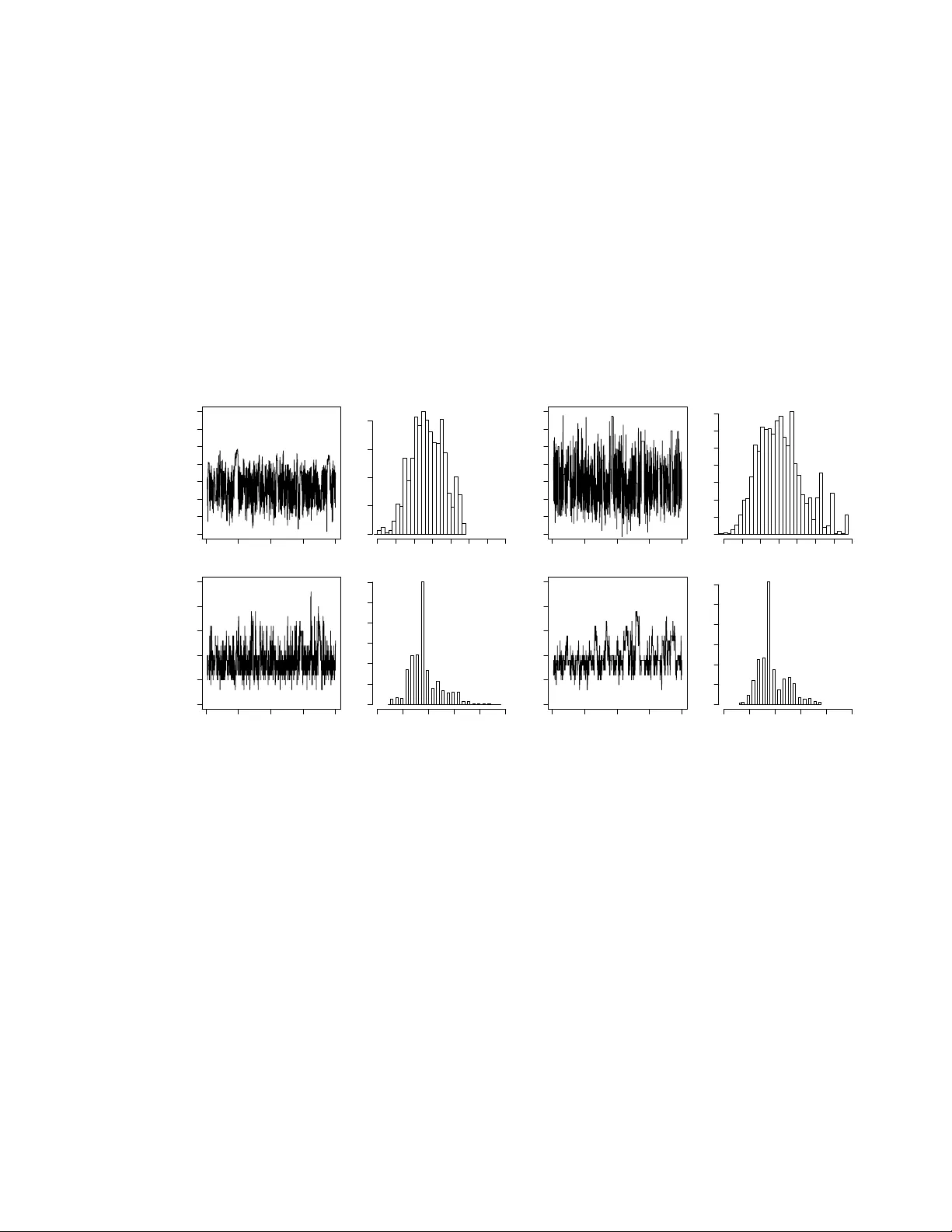
논문은 먼저 k‑NN이 머신러닝과 통계학에서 널리 쓰이지만, 분류 오류에 대한 확률적 해석이 결여된 점을 지적한다. 기존 연구인 Holmes‑Adams(2002,2003)는 k‑NN을 베이지안 프레임으로 확장하려 했으나, 조건부 확률이 서로 호환되지 않아 일관된 결합분포를 정의하지 못한다는 근본적인 결함이 있다. 이를 보완하기 위해 저자들은 라벨 y_i와 공변량 x_i 사이의 관계를 마코프 랜덤 필드(MRF) 형태로 모델링하고, 이웃 관계를 δ 함수로 표현한 Boltzmann 분포를 도입한다. 여기서 β는 이웃의 영향력을 조절하는 스케일 파라미터이며, k는 정규화 상수의 분모에 들어가 차원을 무관하게 만든다. 그러나 k‑최근접 이웃이 비대칭적이기 때문에 (1)식의 조건부 분포를 만족하는 전역 결합분포가 존재하지 않는다. Holmes‑Adams가 제안한 (2)식도 정규화 상수가 누락된 비정규화된 형태이며, 실제로 n=2인 간단한 사례에서도 정상화 상수가 1이 아님을 보여준다.
정규화 상수 문제를 해결하기 위해 두 가지 MCMC 접근법을 제시한다. 첫 번째는 ‘완전 샘플링(perfect sampling)’을 이용해 정확한 정상화 상수를 추정하고, 이를 기반으로 Metropolis‑Hastings 알고리즘을 설계한다. 완전 샘플링은 Coupling From The Past(CFTP) 기법을 활용해 목표 분포에서 직접 샘플을 얻으며, 이때 β와 k에 대한 사후분포를 정확히 탐색한다. 두 번째는 완전 샘플링이 실용적으로 어려운 경우를 대비해 Gibbs 샘플링을 제안한다. Gibbs 샘플링은 각 라벨을 현재 이웃 라벨을 조건으로 업데이트하는 방식으로, 정상화 상수 없이도 근사 사후분포를 얻을 수 있다.
또한, 의사가능도(pseudo‑likelihood) 방법을 사용하면 계산이 간단하지만, 비대칭성으로 인해 β와 k에 대한 편향이 심하고, 실제 데이터에 적용했을 때 예측 정확도가 크게 떨어진다. 이를 실험적으로 확인하기 위해 Ripley의 2차원 데이터와 여러 공개 벤치마크(예: Iris, Wine 등)를 사용했다. 실험 결과, 베이지안 k‑NN은 전통적 k‑NN보다 불확실성 영역을 명시적으로 표시하고, k에 대한 사전·사후 불확실성을 반영함으로써 보다 신뢰할 수 있는 분류 결과를 제공한다. 특히, 95% 신뢰구간을 이용해 ‘불확실한’ 영역을 시각화한 Figure 3은 베이지안 접근법의 실용적 가치를 강조한다.
결론적으로, 이 논문은 k‑NN을 확률적 모델로 정립하고, 정상화 상수 문제를 정확히 다루는 완전 샘플링 및 Gibbs 샘플링 기반 MCMC 방법을 제시함으로써 기존 베이지안 k‑NN 연구의 한계를 극복한다. 또한, 의사가능도 접근법의 한계를 실험적으로 입증하고, 베이지안 프레임에서 k와 β를 동시에 추정하는 방법론을 제공한다. 이는 k‑NN을 단순한 결정론적 도구에서 불확실성을 정량화할 수 있는 통계적 모델로 전환시키는 중요한 진전이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기