베이지안 멜딩을 활용한 HIV 유병률 확률적 예측
초록
본 연구는 UNAIDS의 Estimation and Projection Package(EPP)를 기반으로, 베이지안 멜딩 기법을 적용해 HIV 유병률 추정치와 향후 추이의 불확실성을 정량화한다. 안테날 클리닉 데이터와 인구 수준 유병률을 연결하는 랜덤 효과 모델을 도입하고, 우간다 사례를 통해 2010년 예상 유병률 2%~7%의 95% 예측 구간을 제시한다.
상세 분석
이 논문은 HIV 유병률 추정에 널리 사용되는 UNAIDS의 EPP 모델에 대한 불확실성 평가 방법으로 베이지안 멜딩(Bayesian melding)을 제안한다. 전통적인 EPP는 관측된 안테날 클리닉(ANC) 데이터에 기반해 파라미터를 최적화하고, 단일 최적값을 이용해 미래 유병률을 예측한다. 그러나 파라미터 공간이 고차원이고, 입력 파라미터에 대한 사전 지식이 제한적이며, 관측 데이터 자체에도 측정오차와 클리닉 간 변동이 존재한다는 점에서 단일값 예측은 정책 입안에 충분한 정보를 제공하지 못한다.
베이지안 멜딩은 “입력 파라미터에 대한 사전 분포”와 “모델이 생성하는 출력(예: 연도별 유병률)과 관측 데이터 간의 가능도”를 동시에 고려해, 입력‑출력 전반에 걸친 사후 확률분포를 추정한다. 구체적으로 저자는 다음과 같은 절차를 수행한다.
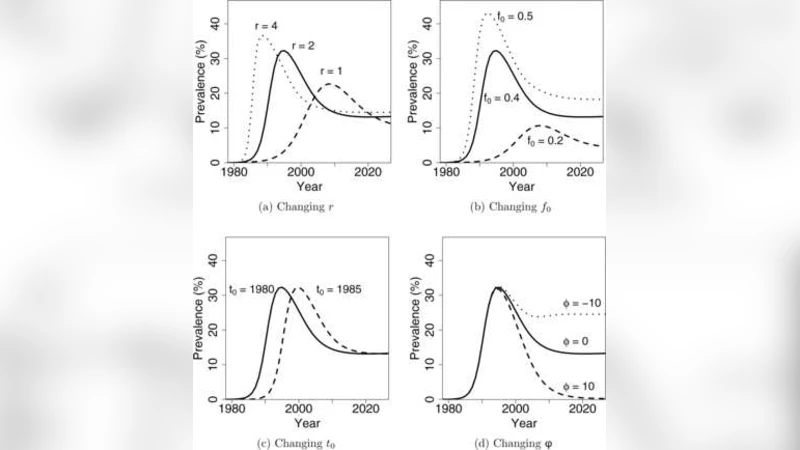
- 입력 파라미터 사전: EPP 모델에 필요한 5~6개의 핵심 파라미터(예: 전염률, 감염 지속 기간, 초기 감염자 비율 등)에 대해 전문가 의견과 문헌값을 바탕으로 베타·정규·균등 등 적절한 사전분포를 설정한다.
- 모델 실행: 사전에서 샘플링된 파라미터 집합을 EPP에 투입해 시뮬레이션을 수행하고, 연도별 인구 전체 유병률 궤적을 생성한다.
- 관측 모델링: ANC 데이터는 실제 인구 유병률과 비례하지만, 클리닉마다 검체 수, 검사 정확도, 지역 특성 등에 따라 차이가 있다. 이를 반영하기 위해 논문은 로그-오즈 변환 후 클리닉 간 랜덤 효과를 포함한 계층적 베이지안 모델을 구축한다. 즉, 각 클리닉의 관측값은 전체 평균 유병률에 클리닉 고유 편차와 측정오차를 더한 형태로 모델링한다.
- 가능도 계산: 위 계층 모델을 통해 시뮬레이션된 유병률 궤적이 실제 ANC 데이터와 얼마나 일치하는지를 확률적으로 평가한다.
- 베이지안 멜딩 사후: 입력 파라미터 사전과 관측 가능도를 결합해, 입력‑출력 전반에 대한 사후 분포를 샘플링한다. 여기서 핵심은 “멜딩” 단계에서 입력 사전과 출력 가능도 사이의 불일치를 최소화하기 위해 가중 평균(또는 최적화된 혼합) 방법을 적용한다.
이 절차를 우간다 사례에 적용한 결과, 1990년경 유병률이 28%에 달했으며, 2010년 예상 유병률은 2%~7% 사이의 95% 예측 구간을 보였다. 이는 기존 EPP가 제공하는 단일값(예: 4.5%)에 비해 불확실성을 명확히 제시함으로써 정책 입안자가 보수적·낙관적 시나리오를 동시에 고려할 수 있게 한다.
또한, 논문은 모델 검증을 위해 “예측 구간”을 ANC 데이터에 직접 적용해, 관측값이 구간 내에 포함되는 비율을 확인한다. 대부분의 클리닉이 구간에 포함되었으며, 이는 제안된 베이지안 멜딩 프레임워크가 실제 데이터와 일관된 예측을 제공함을 시사한다.
핵심 기여는 다음과 같다.
- 불확실성 정량화: 파라미터와 관측 오차를 동시에 고려해 전체 예측의 확률분포를 제공한다.
- 계층적 관측 모델: ANC 데이터의 클리닉 간 이질성을 랜덤 효과로 포착함으로써 보다 현실적인 가능도를 만든다.
- 정책 활용성: 예측 구간을 통해 최악·최선 시나리오를 명시하고, 자원 배분·예방 전략 수립에 직접 활용 가능하게 한다.
한계점으로는 사전 분포 설정이 전문가 의견에 크게 의존한다는 점, 그리고 Monte Carlo 샘플링 비용이 높아 실시간 정책 시뮬레이션에 제약이 있을 수 있다는 점을 들 수 있다. 향후 연구에서는 사전 정보를 데이터‑드리븐 방식으로 업데이트하거나, 변분 베이지안 방법을 도입해 계산 효율성을 높이는 방안을 모색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기