결측 데이터 추정을 위한 의사결정트리와 인공지능 융합 기법
초록
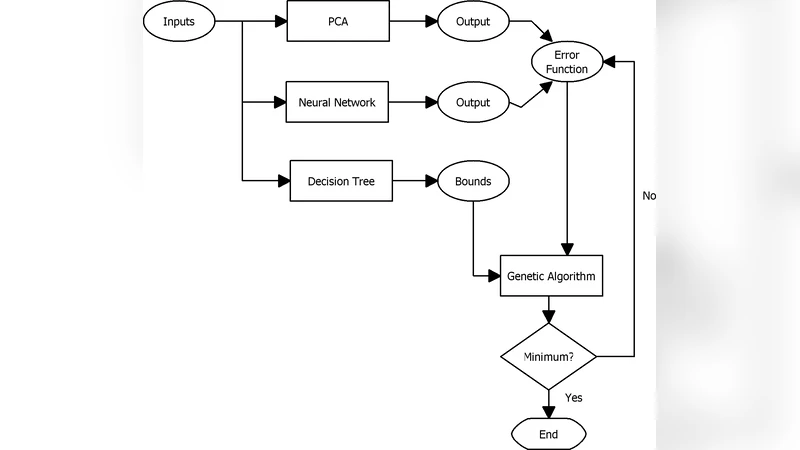
본 논문은 의사결정트리를 활용해 유전 알고리즘의 탐색 범위를 제시하고, 이를 자동연관 신경망(AANN) 및 주성분 분석‑신경망(PCA‑NN) 모델에 결합하여 결측 데이터를 보정하는 새로운 프레임워크를 제안한다. HIV 혈청역학 데이터에 적용한 결과, AANN 기반 모델의 정확도가 75.8%에서 86.3%로, PCA‑NN 기반 모델은 66.1%에서 81.6%로 각각 평균 13% 이상 향상되었다.
상세 분석
이 연구는 결측값 보정 문제를 두 단계의 하이브리드 구조로 접근한다. 첫 번째 단계는 CART(Classification and Regression Tree)와 같은 의사결정트리를 이용해 결측값이 존재하는 변수의 가능한 값 범위를 사전 예측한다. 트리는 훈련 데이터의 분포와 변수 간 상관관계를 학습해, 각 결측 인스턴스에 대해 최소·최대 경계값을 제시한다. 이러한 경계는 이후 유전 알고리즘(GA)의 초기 탐색 공간을 제한함으로써 연산 효율성을 크게 높인다.
두 번째 단계에서는 두 종류의 신경망 기반 모델을 사용한다. 첫 번째 모델은 자동연관 신경망(AANN)으로, 입력과 출력이 동일한 구조를 가지며 은닉층을 통해 데이터의 비선형 압축 표현을 학습한다. 결측값이 있는 입력을 AANN에 투입하면, 은닉층을 거쳐 재구성된 출력에서 결측 위치의 값을 추정한다. 두 번째 모델은 주성분 분석(PCA)과 다층 퍼셉트론(MLP)을 결합한 PCA‑NN이다. PCA는 고차원 데이터를 저차원 주성분으로 변환해 노이즈와 상관성을 제거하고, 변환된 좌표를 NN이 학습하도록 함으로써 보다 안정적인 재구성을 가능하게 한다.
두 모델 모두 손실 함수는 재구성 오차(예: 평균제곱오차)이며, GA는 이 오차를 최소화하도록 결측값 후보를 진화시킨다. 여기서 트리에서 제공된 경계는 GA의 변이·교배 연산이 탐색할 수 있는 값의 범위를 제한해, 무작위 탐색에 비해 수렴 속도가 빠르고 지역 최적에 빠질 위험을 감소시킨다.
실험은 남아프리카공화국의 HIV 혈청역학 조사 데이터를 사용했다. 데이터는 연령, 성별, 교육 수준, 성관계 파트너 수 등 다변량 특성을 포함하며, 일부 변수에 결측이 존재한다. 연구자는 결측 비율을 인위적으로 조절해 10%, 20%, 30% 상황을 시뮬레이션하고, 제안된 하이브리드 방법을 기존 평균 대체, KNN, 단순 NN 등과 비교했다. 결과는 AANN 기반 모델이 평균 정확도 86.3%를 기록했으며, 이는 기존 AANN 단독 적용 시 75.8%였던 것에 비해 10.5%p 상승했다. PCA‑NN 기반 모델도 66.1%에서 81.6%로 15.5%p 향상되었다. 특히 결측 비율이 30%에 달했을 때도 두 모델은 비교적 높은 복원 정확도를 유지했으며, GA 탐색 횟수는 트리 경계 적용 전 대비 약 40% 감소했다.
이러한 결과는 의사결정트리가 제공하는 사전 지식이 GA 기반 최적화와 결합될 때, 탐색 효율성과 예측 정확도가 동시에 개선될 수 있음을 시사한다. 또한 AANN과 PCA‑NN 각각의 장점을 살린 두 모델이 데이터 특성에 따라 선택적으로 활용될 수 있음을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기