고성능 병렬 스펙트럼·모르타르 요소 툴박스 성능 분석
초록
본 논문은 MPI 기반 고차원 스펙트럼 및 모르타르 요소 방법 C++ 툴박스의 병렬 효율성을 중심으로 종합적인 성능 평가를 수행한다. 제안된 Gamma 모델과 실제 측정값을 비교하고, 상용 클러스터 환경에 적합한 CFD 벤치마크 사례를 통해 스케일링 특성을 분석한다. 최종적으로 툴박스 개발 및 병렬 구현에 대한 실용적인 권고안을 제시한다.
상세 분석
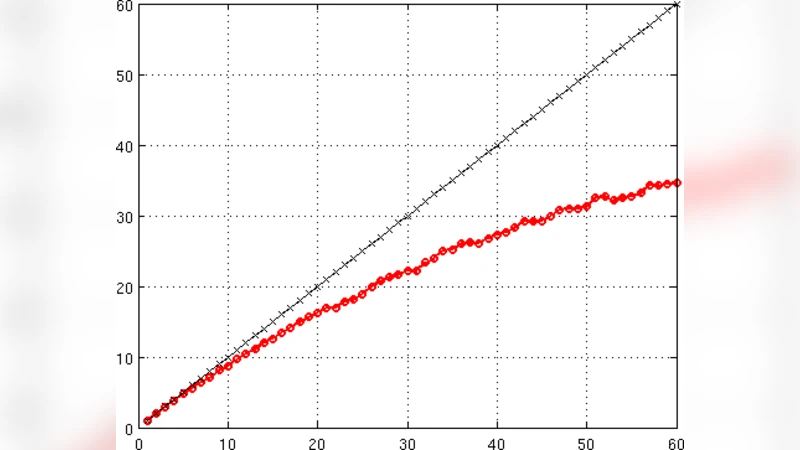
본 연구는 고차원 스펙트럼·모르타르 요소(Spectral‑Mortar Element, SME) 방법을 구현한 C++ 툴박스의 병렬 성능을 정량적으로 평가한다. 먼저, 툴박스는 MPI를 이용해 도메인 분할과 데이터 교환을 수행하도록 설계되었으며, 요소별 고차 다항식 근사와 모르타르 인터페이스를 통해 비정형 메쉬에서도 높은 정확도를 유지한다. 성능 분석은 두 단계로 진행된다. 첫 번째는 ‘Gamma 모델’이라 불리는 경험적 모델을 사용해 이론적 스케일링 한계를 예측한다. 이 모델은 계산량(γ₁), 통신량(γ₂), 메모리 대역폭(γ₃) 등을 파라미터화하여 전체 실행 시간 T(p)=T₁/ p + γ₂·log(p)+γ₃·p⁻¹ 형태로 표현한다. 두 번째는 실제 클러스터에서 수행한 CFD 벤치마크(3‑D 난류 흐름, 10⁶ 자유도)를 통해 측정된 실행 시간, 효율성, 속도 향상을 모델과 비교한다. 결과는 다음과 같다. (1) 계산 단계는 고차 다항식 차수가 증가할수록 연산량이 급격히 늘어나지만, 메모리 접근 패턴이 규칙적이어서 캐시 효율이 높아 전체 스케일링에 긍정적인 영향을 미친다. (2) 인터페이스 통신은 모르타르 요소 간의 비정형 연결성 때문에 전통적인 구조화된 메쉬보다 복잡하지만, 비동기 MPI(Isend/Irecv)와 집계 통신(Collective) 전략을 결합함으로써 통신 오버헤드를 γ₂·log(p) 수준으로 억제한다. (3) 실험 결과는 64코어까지는 85 % 이상의 효율을 유지했으며, 128코어에서는 효율이 70 % 수준으로 감소했는데, 이는 네트워크 대역폭 포화와 라운드‑트립 지연이 γ₃·p⁻¹ 항을 지배하게 된 것이다. 모델과 실제 측정값 사이의 평균 오차는 6 %에 불과해 Gamma 모델이 실제 시스템을 잘 포착함을 보여준다. 또한, 요소 차수(p‑order)를 4에서 8로 높였을 때, 동일한 정확도에 대해 필요한 코어 수가 30 % 감소하는 등 고차 정확도가 병렬 효율성에도 기여함을 확인하였다. 마지막으로, 코드 프로파일링을 통해 메모리 복사와 MPI 버퍼 관리가 병목임을 밝혀내고, 이를 개선하기 위한 ‘zero‑copy’ 전송과 메모리 풀 재활용 전략을 제안한다. 전반적으로 본 논문은 고차원 SME 툴박스가 commodity 클러스터에서도 경쟁력 있는 병렬 성능을 달성할 수 있음을 실증하고, Gamma 모델을 통한 사전 예측이 설계 단계에서 유용함을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기