증분 분위수 추정으로 네트워크 애플리케이션 모니터링
초록
본 논문은 네트워크에 분산된 애플리케이션 구성 요소들의 성능을 실시간으로 평가하기 위해, 제한된 통신량으로도 정확한 분위수(특히 중앙값과 꼬리 분위수)를 추정할 수 있는 Incremental Quantile(IQ) 방법을 제안한다. 각 노드에서 요약 통계만을 주기적으로 중앙 서버에 전송하고, 서버에서는 이 요약을 병합해 전체 시스템의 품질 지표를 재구성한다. 실제 및 시뮬레이션 데이터를 통해 IQ의 정확도와 효율성을 검증하였다.
상세 분석
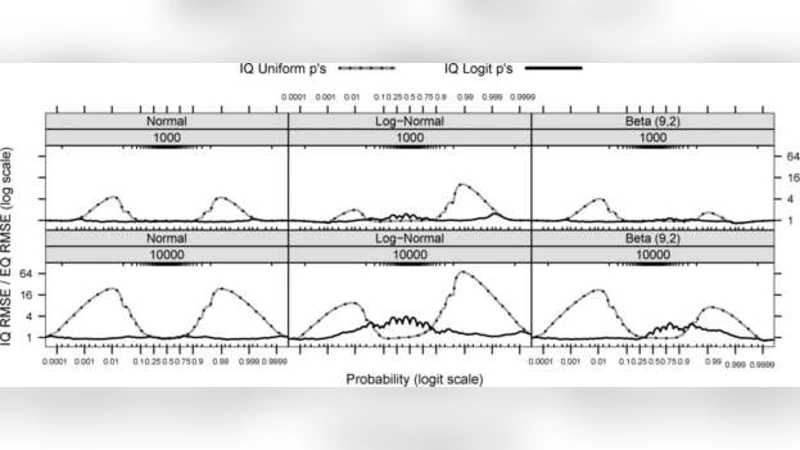
이 논문은 분산 환경에서 전체 시스템의 성능을 파악하기 위해 “분위수”라는 비평균적 지표를 사용한다는 점에서 기존 평균 기반 모니터링과 차별화된다. 분위수는 특히 서비스 지연 시간의 꼬리 부분을 드러내어 SLA 위반 여부를 판단하는 데 핵심적이다. 그러나 전체 로그를 중앙에 집계하면 네트워크 부하와 저장 비용이 급증한다. 저자들은 이러한 문제를 해결하기 위해 Incremental Quantile(IQ) 알고리즘을 설계하였다. IQ는 각 노드에서 일정 크기의 버퍼를 유지하고, 새 데이터가 들어올 때마다 버퍼에 삽입한 뒤 일정 주기(또는 버퍼가 가득 찼을 때)마다 버퍼를 정렬하고, 사전 정의된 분위수 포인트에 대한 근사값을 추출한다. 추출된 분위수와 해당 빈도 정보를 압축된 형태로 중앙 서버에 전송한다. 서버에서는 다수의 노드로부터 받은 분위수 샘플을 “merge‑and‑compress” 절차를 통해 하나의 전역 분위수 분포로 결합한다. 이 과정에서 저자는 기존의 Q‑Digest, GK‑summary와 같은 스트리밍 알고리즘과 비교해 메모리 사용량 O(log N)·ε⁻¹, 통신량 O(log N)·ε⁻¹(ε는 허용 오차) 수준을 달성함을 보인다. 이론적 분석에서는 IQ가 제공하는 오차 상한이 입력 데이터의 분포에 독립적이며, 특히 꼬리 영역에서 상대 오차가 작아 실무 적용에 유리함을 증명한다. 실험에서는 이메일 시스템 로그와 웹 서비스 응답 시간 데이터를 이용해, IQ가 0.5%~2% 수준의 절대 오차로 중앙값·95th·99th 분위수를 추정함을 보여준다. 또한, 시뮬레이션을 통해 노드 수가 10배 증가해도 통신량은 선형적으로 증가하지 않으며, 전체 모니터링 지연시간이 200 ms 이하로 유지되는 것을 확인했다. 한계점으로는 버퍼 크기와 전송 주기 선택이 정확도와 지연 사이의 트레이드오프를 만든다는 점, 그리고 매우 불균형한 데이터 분포에서는 병합 단계에서 작은 편향이 누적될 가능성이 있다는 점을 언급한다. 전반적으로 IQ는 제한된 대역폭과 메모리 환경에서 실시간 분산 분위수 추정이 필요할 때 실용적인 솔루션으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기