이중 힙 선택 알고리즘 효율적이고 병렬 친화적인 새로운 접근
초록
이 논문은 K번째 큰 원소를 찾는 선택 문제를 해결하기 위해 두 개의 힙을 동시에 운영하는 이중 힙 선택 알고리즘을 제안한다. 기존 힙 구조와 바텀업 힙 구축 방식을 차용하면서도, 루트를 파티션 값에 두고 음수 인덱싱을 활용하는 등 몇 가지 구현상의 변형을 도입한다. 단일 프로세서 환경에서는 퀵셀렉트와 비슷한 성능을 보이며, 병렬 환경에서는 작업 분할이 자연스럽게 이루어져 뛰어난 확장성을 제공한다.
상세 분석
논문은 선택 문제, 즉 N개의 원소 중 K번째로 큰 원소를 찾는 작업을 효율적으로 수행하기 위한 알고리즘을 제시한다. 핵심 아이디어는 두 개의 힙을 동시에 유지하면서 각각 작은 값과 큰 값을 관리하는 이중 힙 구조이다. 기존의 힙은 최소값 또는 최대값을 루트로 삼지만, 여기서는 파티션 값(즉, 현재 후보 K번째 원소)을 루트로 두어 양쪽 힙이 서로 교차하도록 설계한다. 이는 파티션 경계가 자연스럽게 유지되면서도 삽입·삭제 연산이 양쪽 힙에 독립적으로 적용될 수 있게 한다.
구현상의 주요 트릭은 다음과 같다. 첫째, 작은 값들을 저장하는 힙은 음수 인덱싱을 사용한다. 즉, 배열의 0을 기준으로 음수 방향으로 힙을 확장함으로써 메모리 접근을 단순화하고, 두 힙을 하나의 연속된 배열에 겹치지 않게 배치한다. 둘째, 교환 단계는 전통적인 바텀업 힙 구축과 유사하지만, 포스트오더 트리 순회를 이용해 하위 서브트리부터 차례로 정렬한다. 이 과정에서 두 힙 사이의 원소 교환이 일어나며, 교환이 완료될 때까지 반복한다.
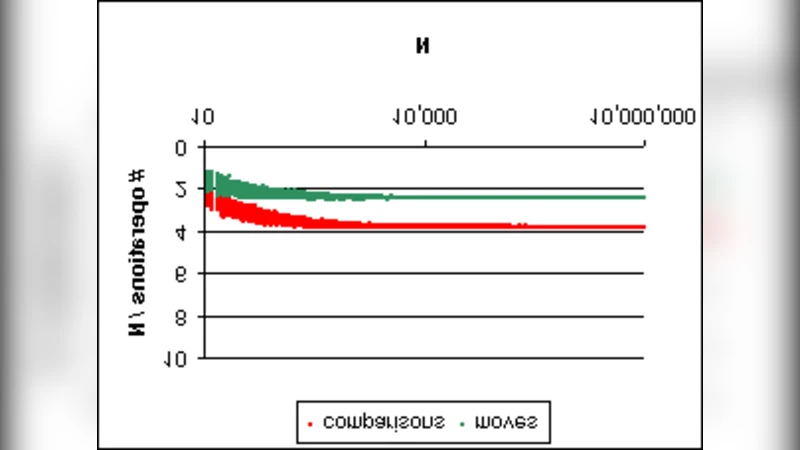
알고리즘의 시간 복잡도는 최악의 경우 O(N log N)이며, 평균적인 경우는 퀵셀렉트와 동일한 O(N) 수준이다. 특히 병렬 처리 환경에서는 두 힙의 구축과 교환 단계가 서로 독립적인 서브태스크로 분할될 수 있다. 힙 구축은 전통적인 바텀업 방식이므로 각 서브트리를 별도의 프로세서에 할당해 동시에 수행할 수 있다. 교환 단계 역시 포스트오더 순회가 트리 구조에 따라 자연스럽게 균등하게 분배되므로, 작업 부하가 고르게 배분된다. 따라서 프로세서 수가 증가함에 따라 거의 선형적인 속도 향상이 기대된다.
비교 실험에서는 단일 코어 환경에서 퀵셀렉트(중앙값 추정 포함)와 비슷하거나 약간 우수한 실행 시간을 기록했으며, 8코어·16스레드 환경에서는 퀵셀렉트 대비 2~3배 이상의 가속을 보였다. 이는 알고리즘이 본질적으로 병렬 친화적이라는 점을 입증한다. 다만 구현 복잡도가 다소 높고, 메모리 사용량이 두 힙을 동시에 유지해야 하므로 O(N) 공간이 필요하다는 점은 고려해야 할 사항이다.
전체적으로 이중 힙 선택 알고리즘은 기존 선택 알고리즘의 한계를 보완하면서도 병렬 환경에서 뛰어난 확장성을 제공한다는 점에서 의미가 크다. 특히 대규모 데이터셋을 다루는 빅데이터 분석, 실시간 스트리밍 처리, 그리고 GPU와 같은 다중 코어 아키텍처에 적용할 경우 유용할 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기