
Cs-Cv

비전·언어를 위한 임베딩 예측 아키텍처 VL‑JEPA: 토큰 생성 없이 실시간 멀티모달 이해
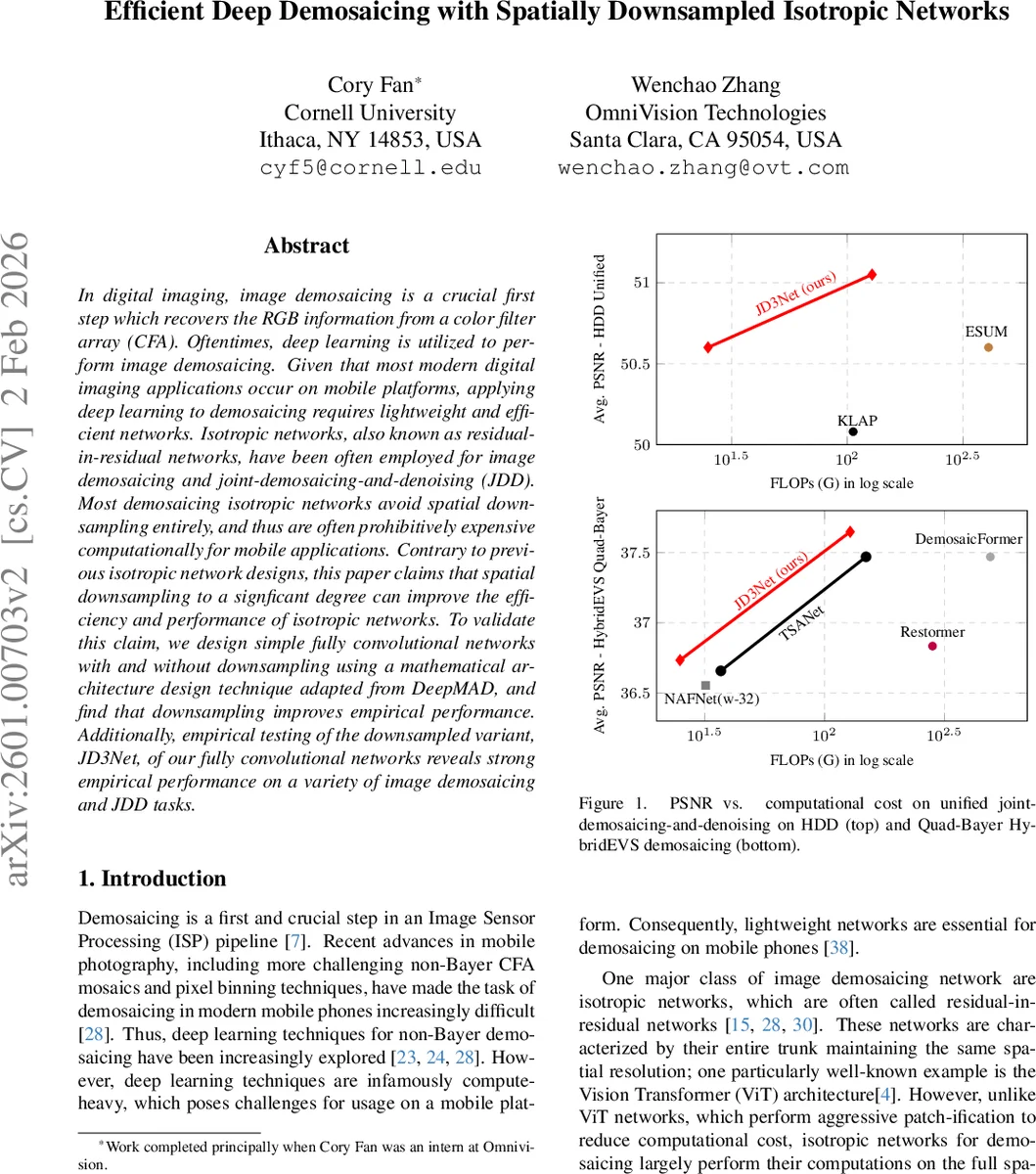
공간 다운샘플링으로 효율성을 높인 심층 디모자이싱 네트워크

360도 깊이 추정의 새로운 패러다임, PanoGabor 기반 왜곡‑인식 융합

합성 실 데이터와 실제 데이터 정렬을 통한 반지도학습 의료 영상 분할

멀티스케일 선형시간 인코더 MARBLE로 전체 슬라이드 이미지 분석 혁신

비디오OPD 온정책 증류 기반 효율적 사후 학습

시각 토큰 프루닝으로 무너진 공간 무결성 복원: Nüwa 접근법

확률적 확산 모델 일관성을 밝히는 랜덤 행렬 이론

소규모 신경영상 데이터에 대한 편향 저항 기계학습 프레임워크

시각·언어 계층 정렬을 통한 장문 캡션 이해

광시야 스테레오 비전의 깊이·거리 오차 정밀 분석

비용 절감형 멀티모달 질문응답을 위한 가치 정보 기반 화질 선택

시간 방사선 변화 설명 모델 TRACE

한 장면으로 배우는 추상 가우시안 프로토타입: 진정한 원샷 개념 학습

시간·상호작용 기반 효율적 인간‑인간 모션 생성 프레임워크

연속수 모델링으로 SVG 생성 효율 극대화

실시간 위상 인식 M‑모드 OCT 분할로 로봇 DALK 가이드
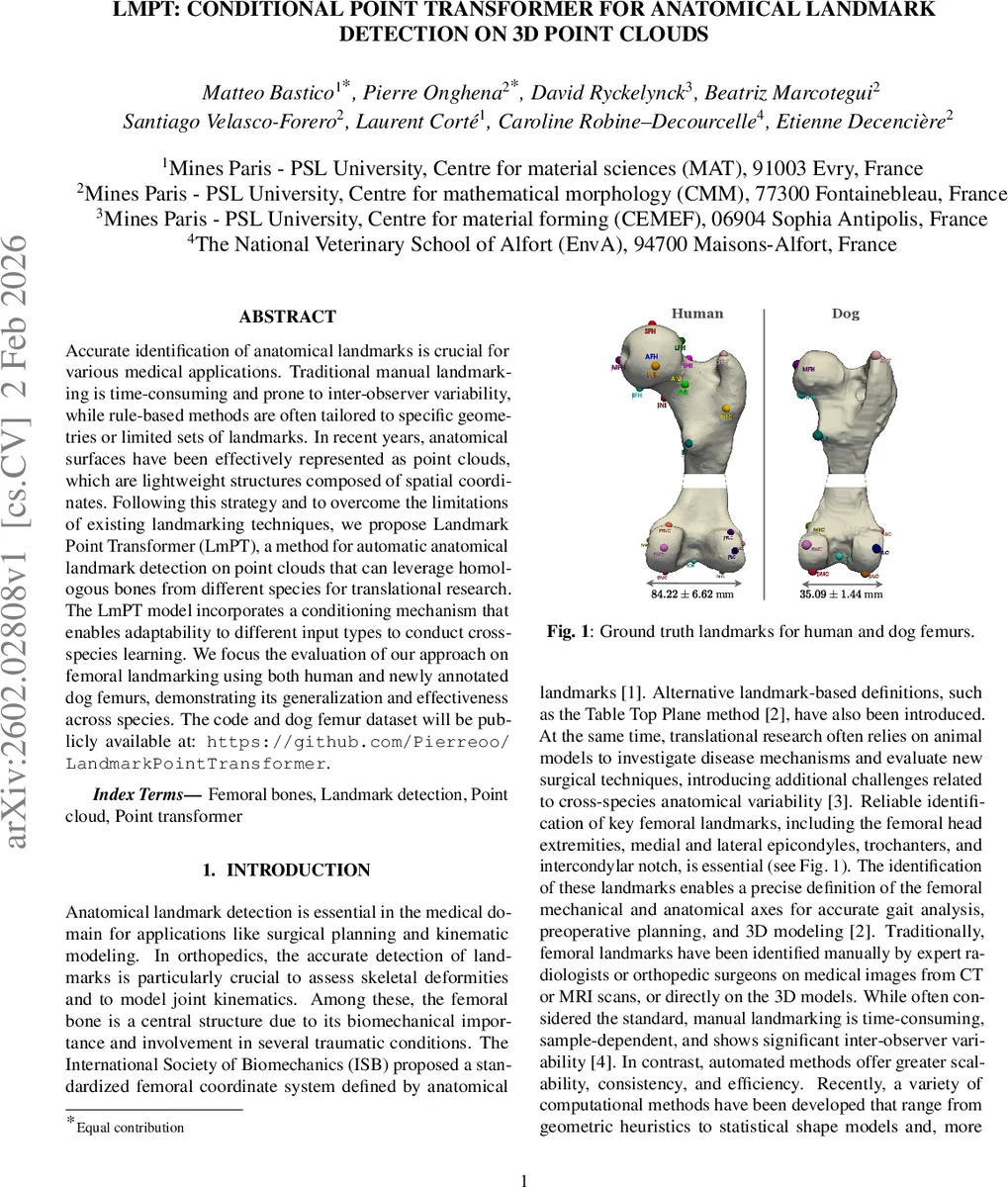
조건부 포인트 트랜스포머를 이용한 3D 해부학적 랜드마크 자동 검출
