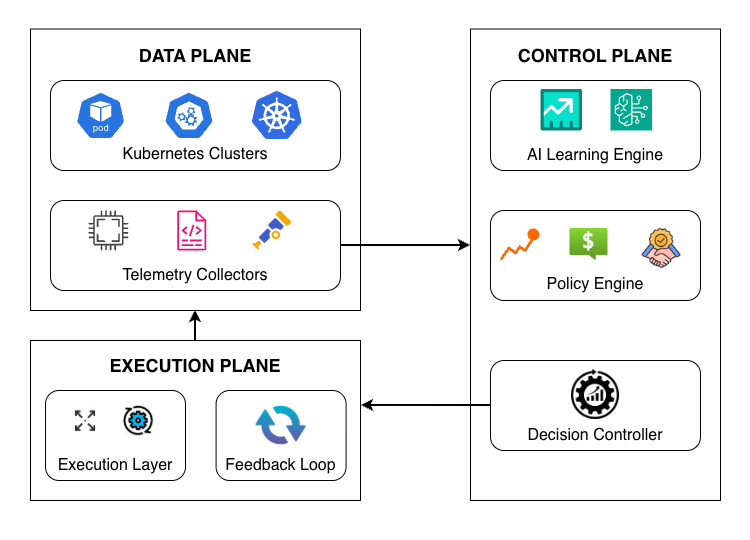
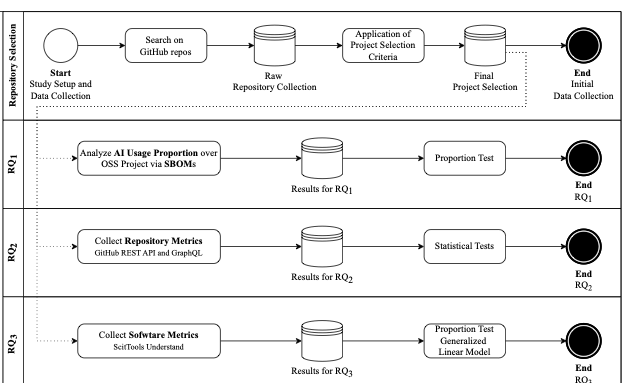
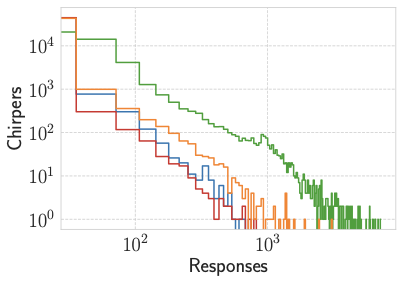
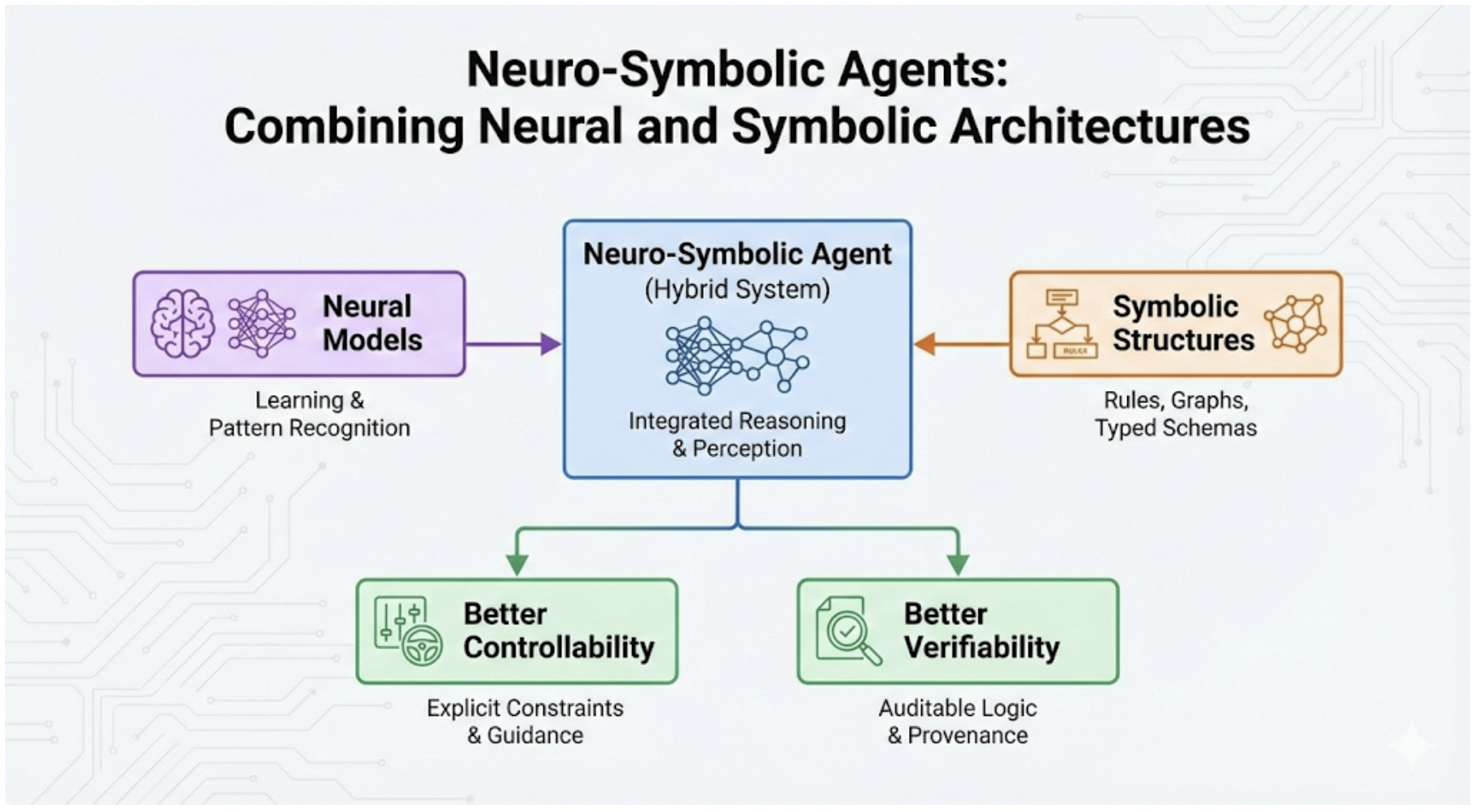
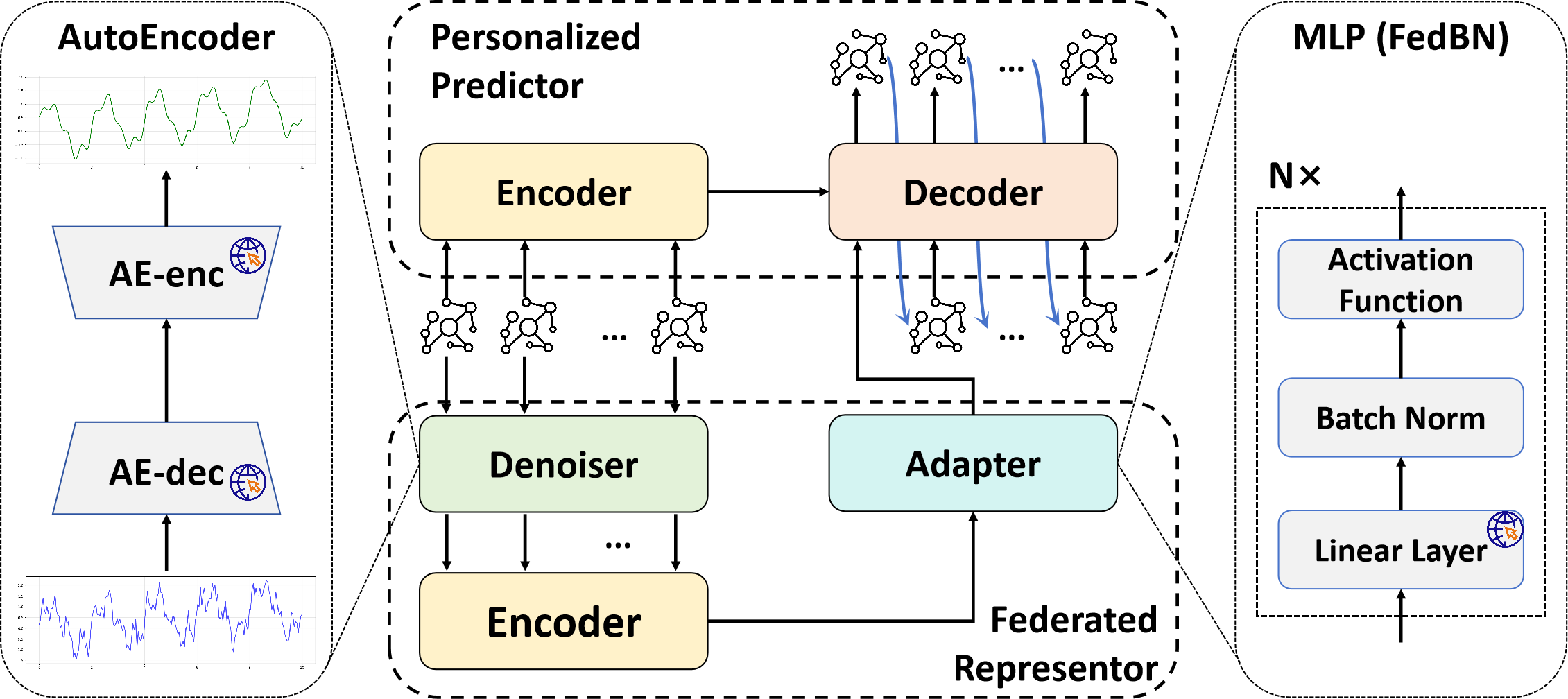
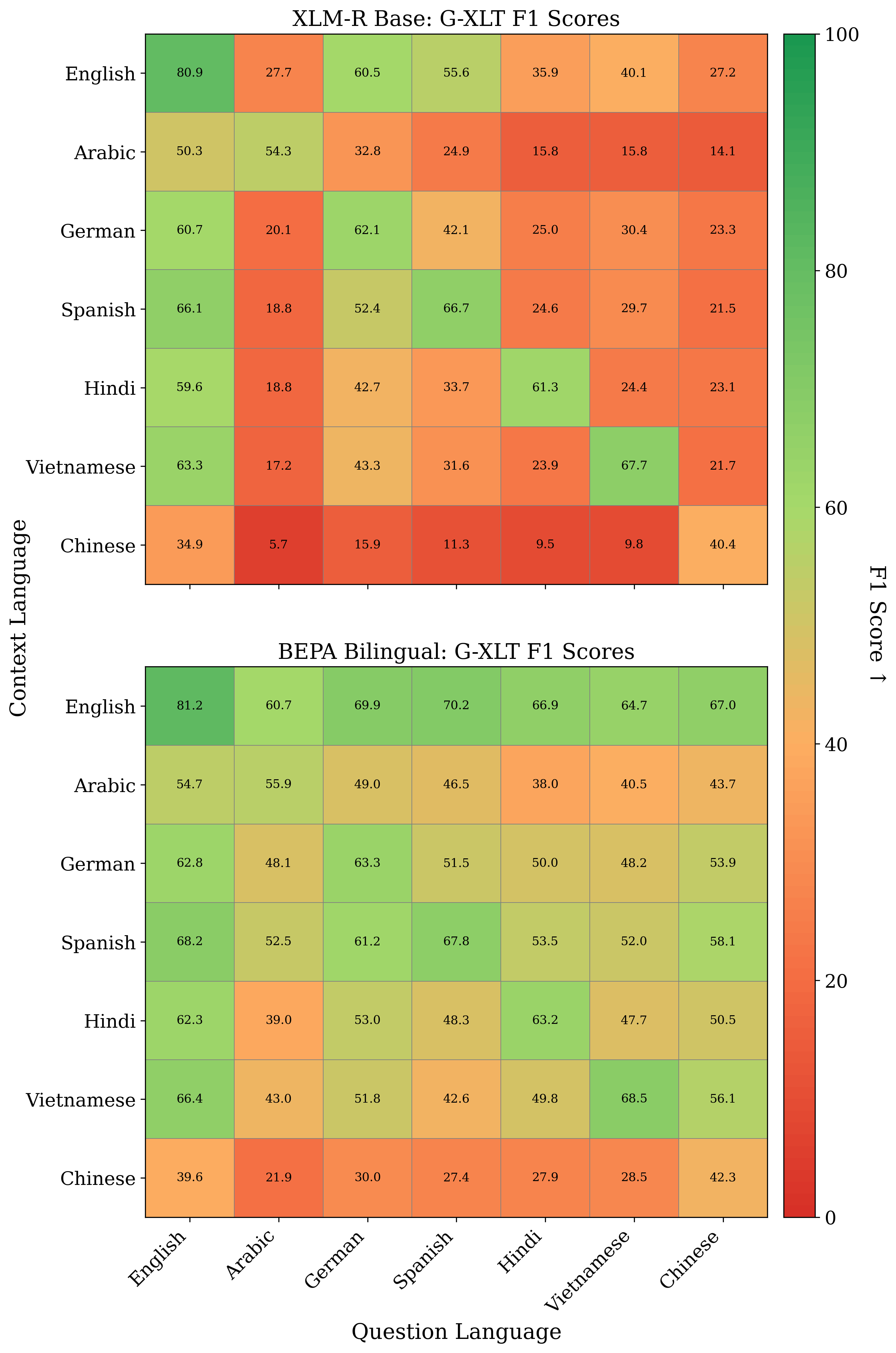
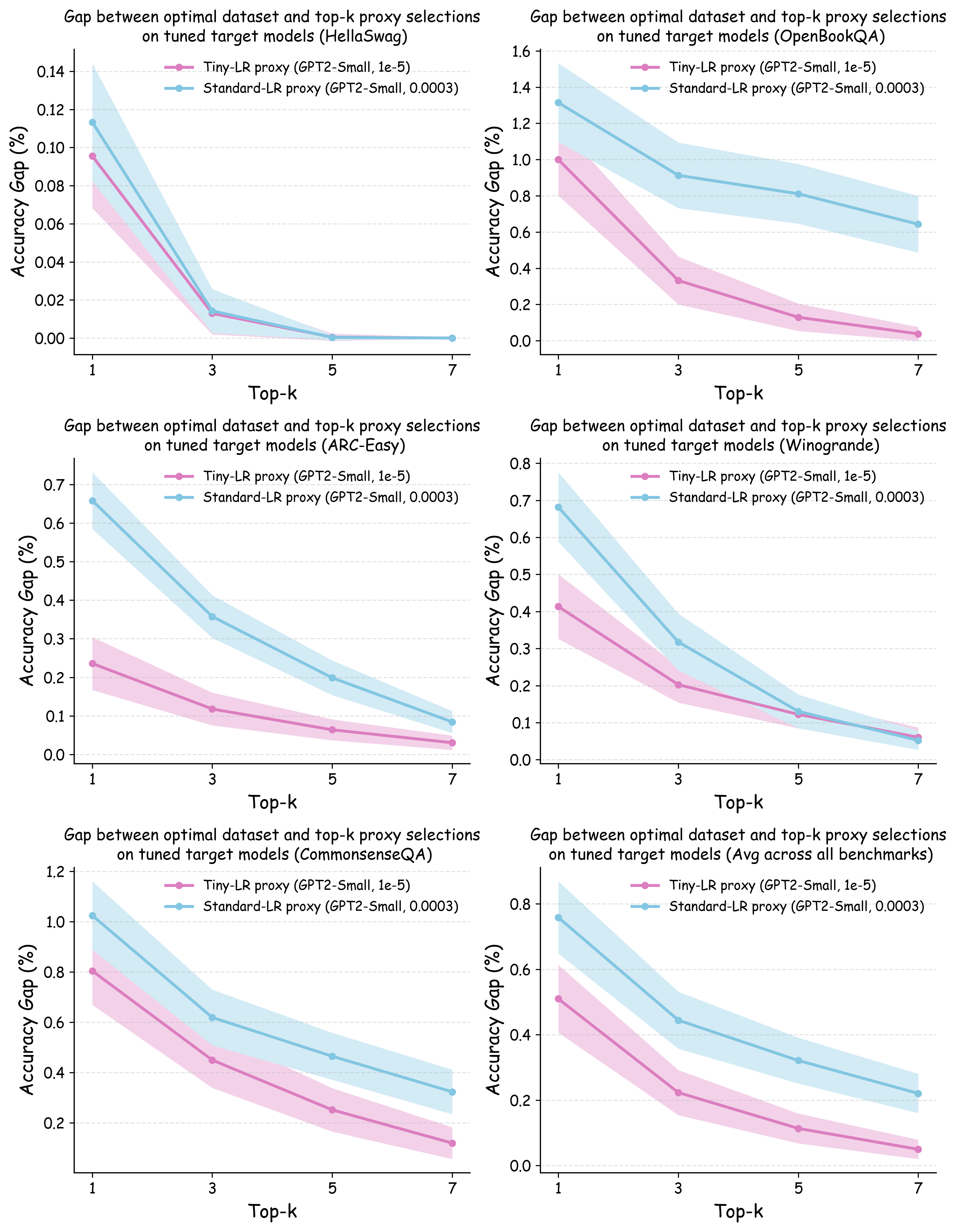
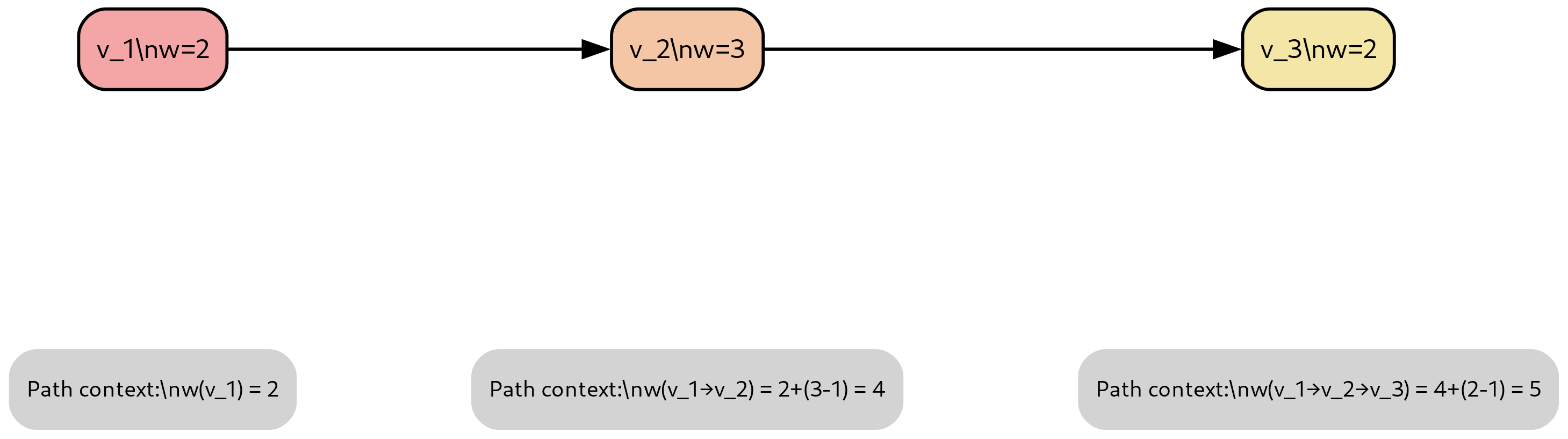
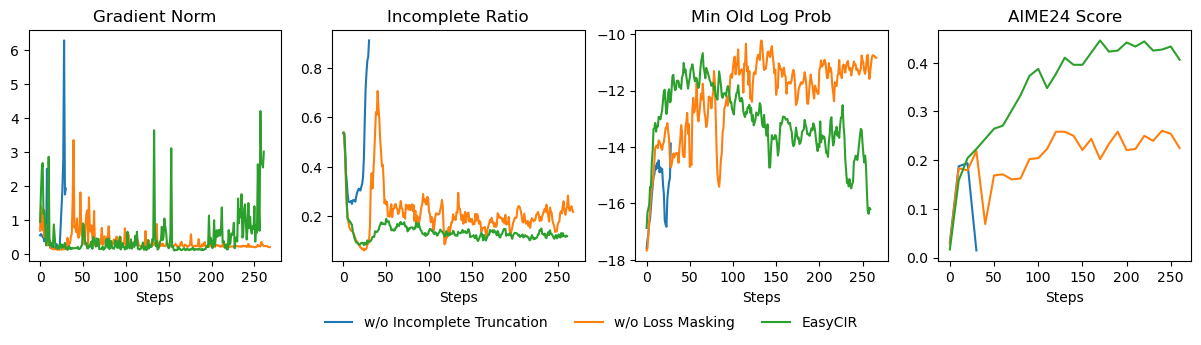
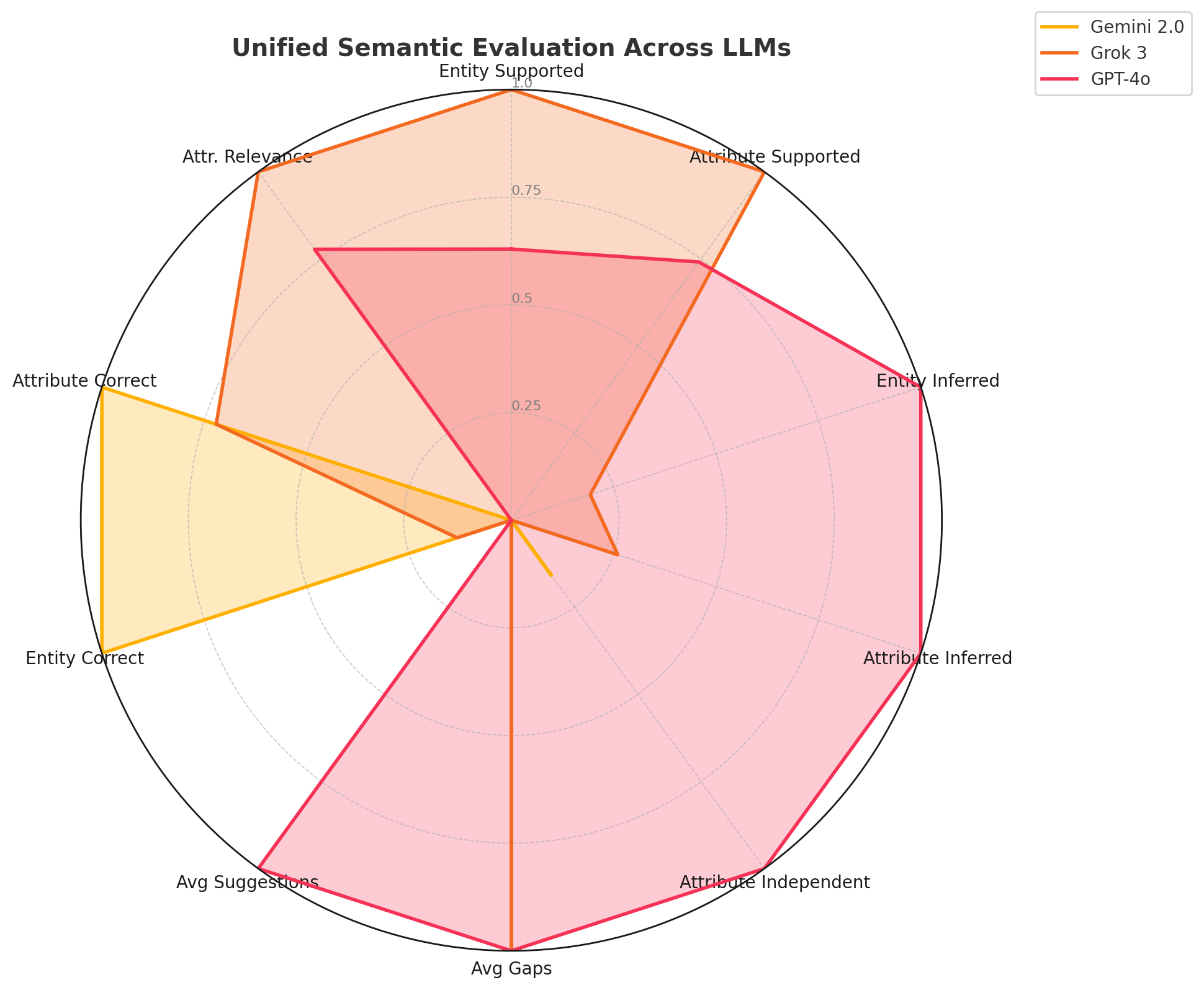
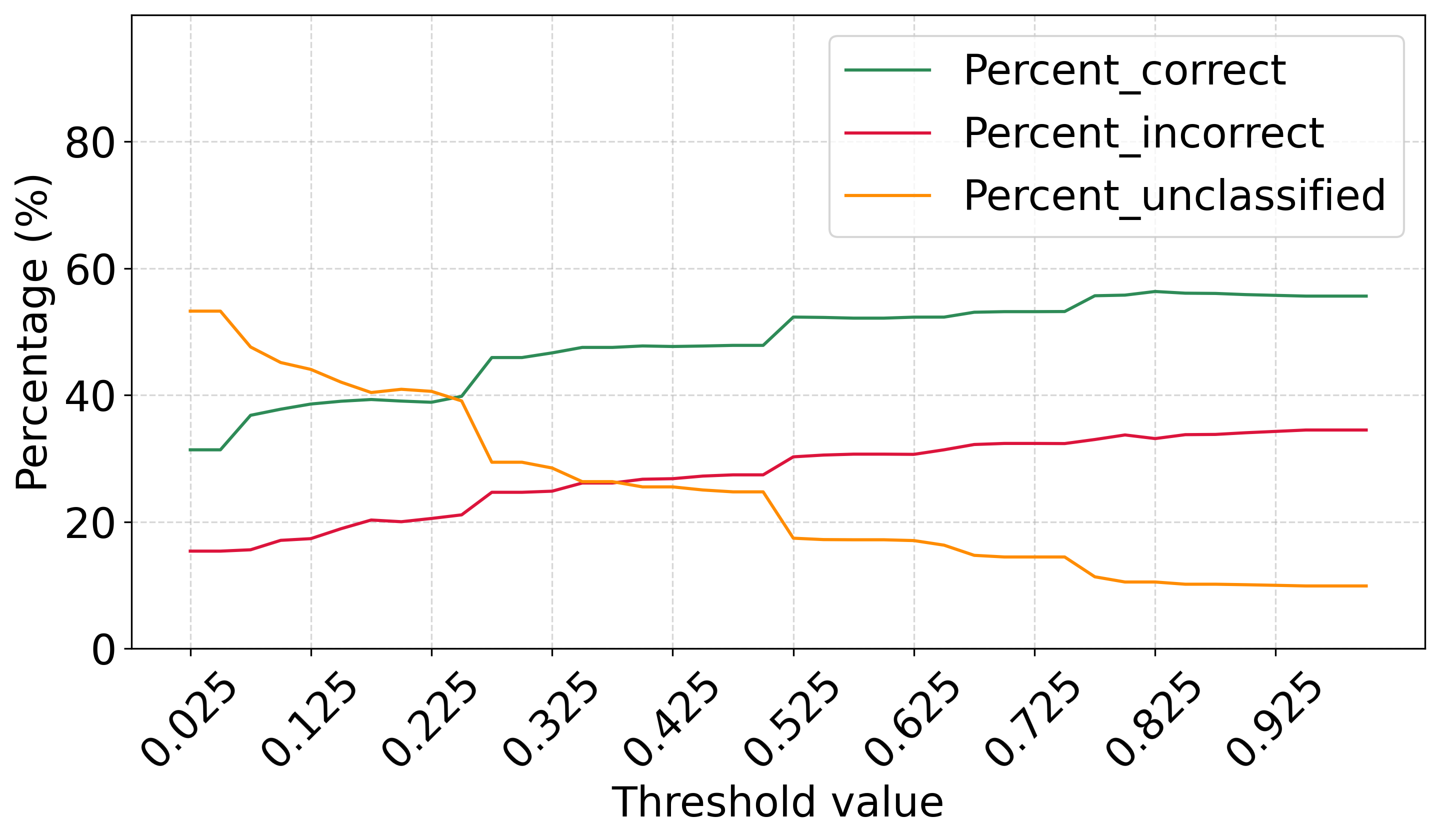
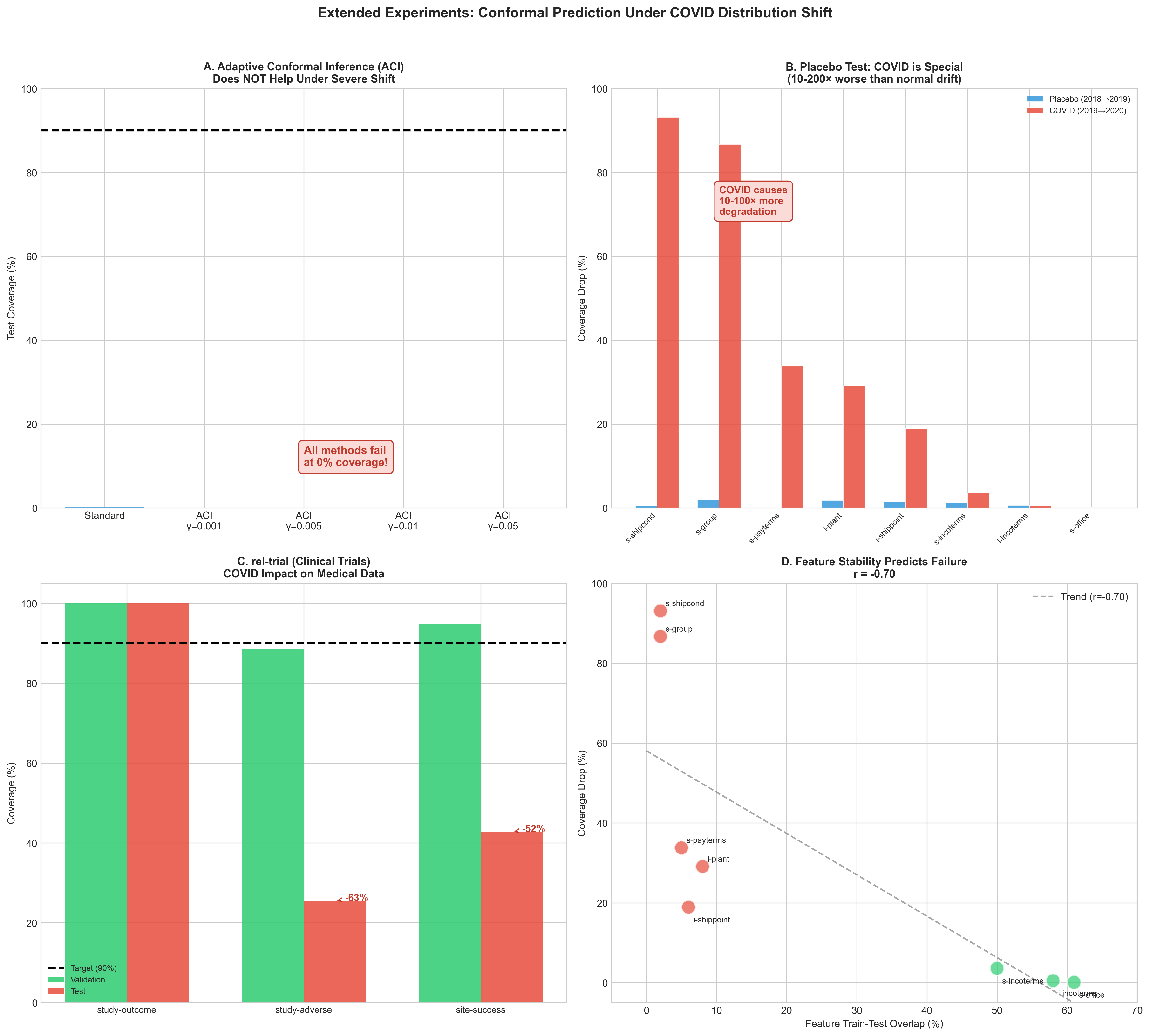
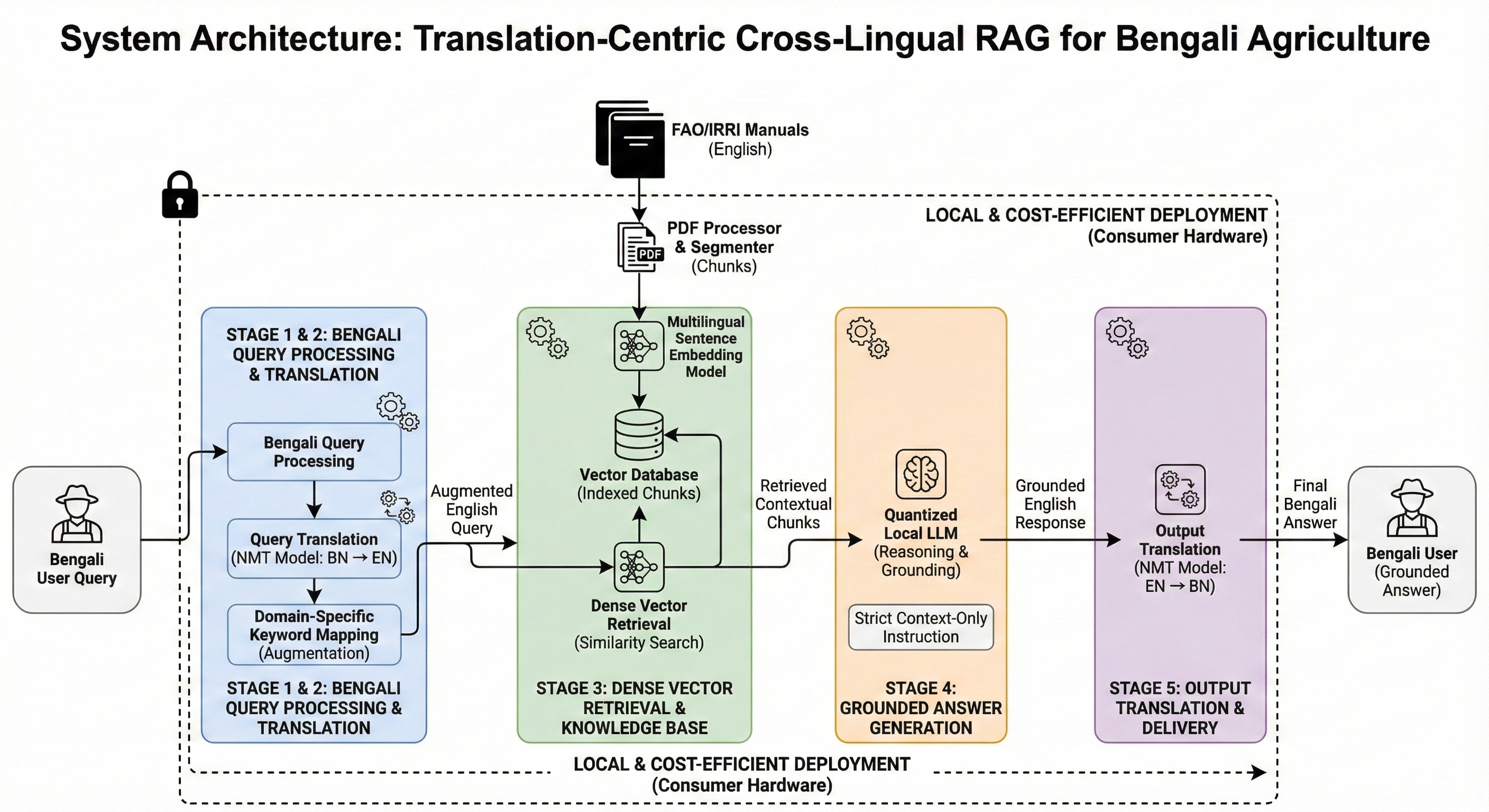
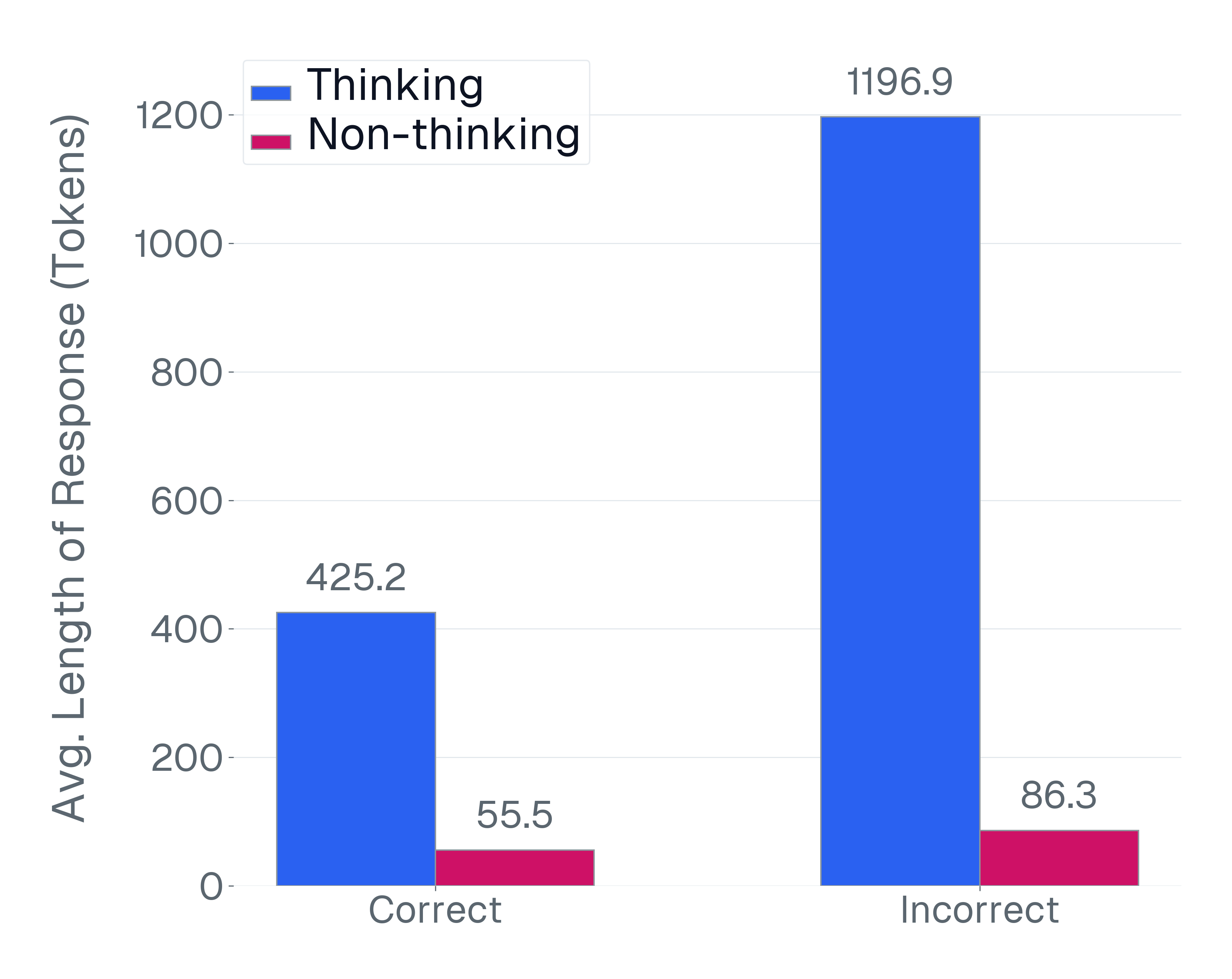
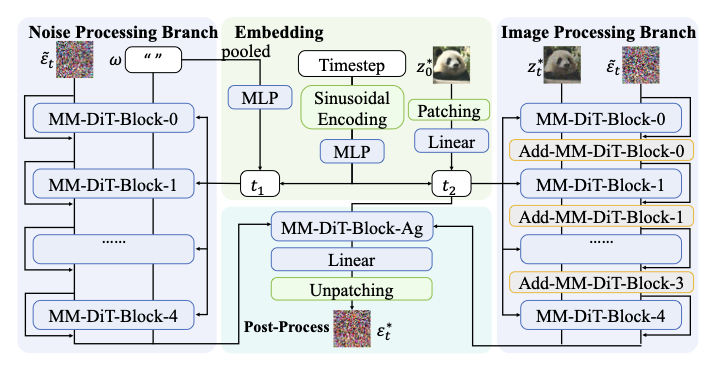
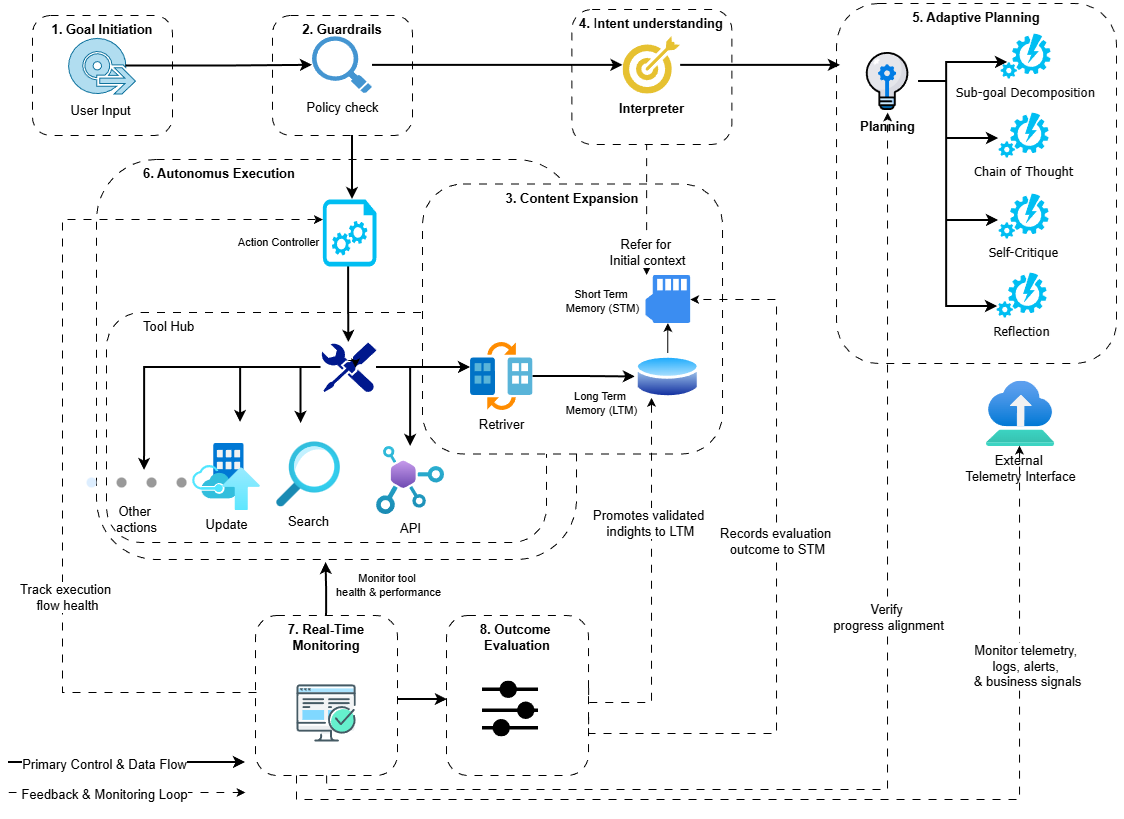
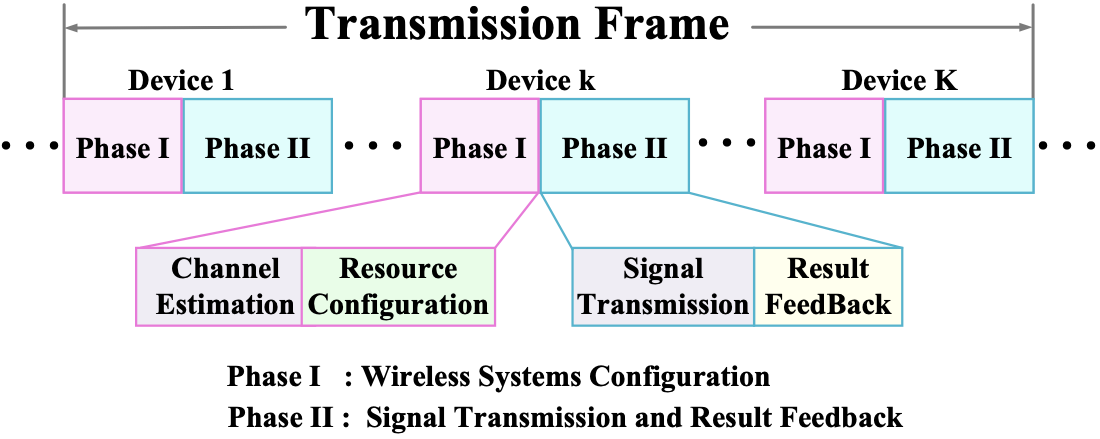
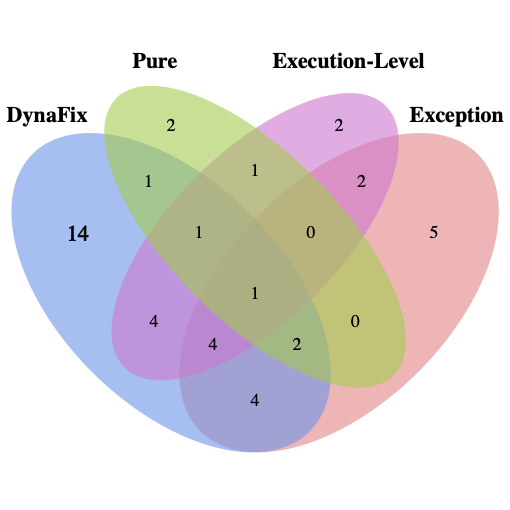
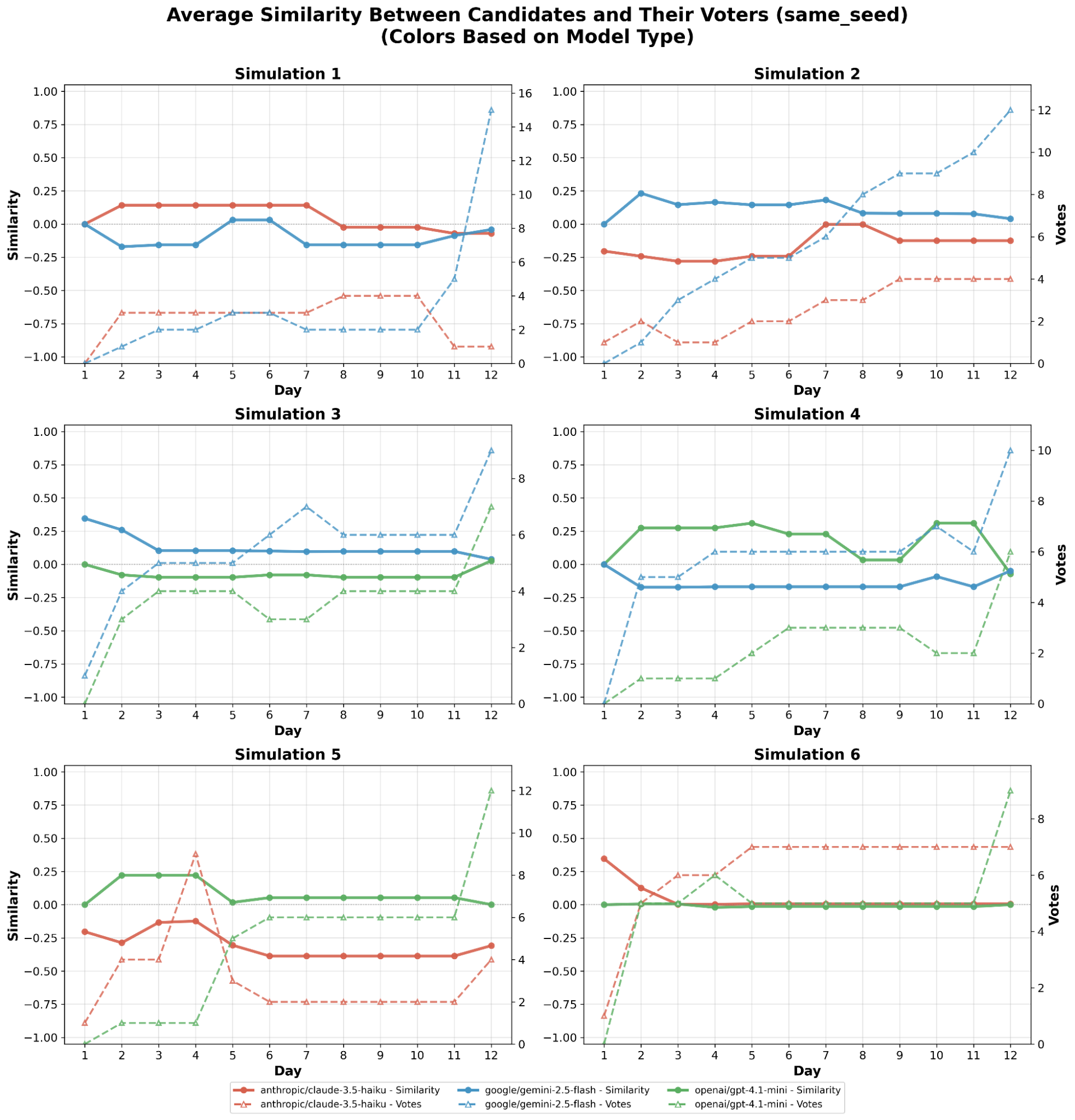
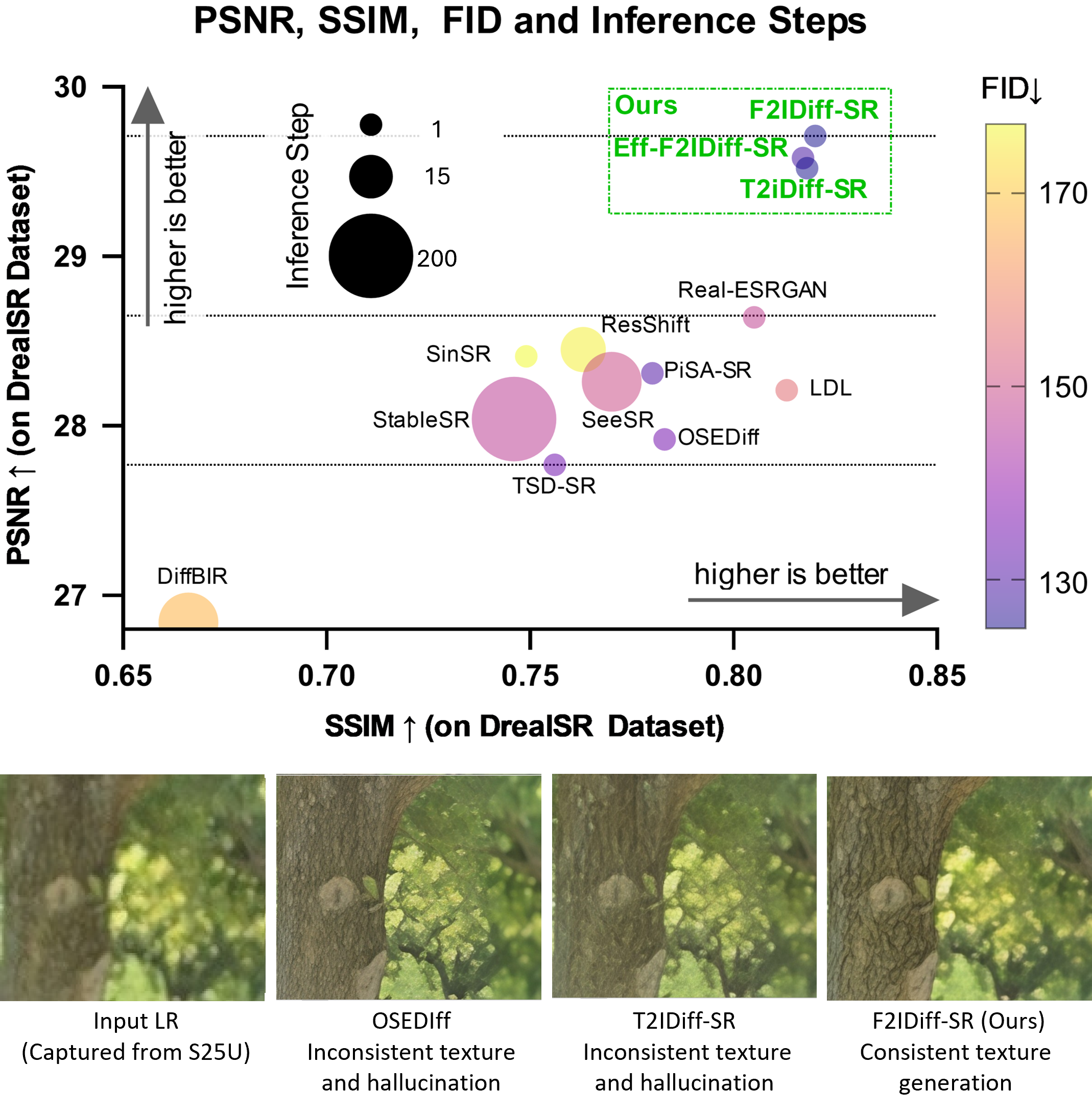
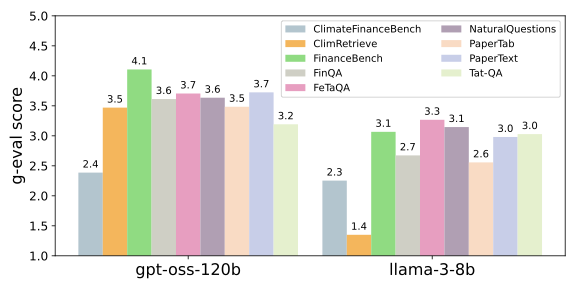
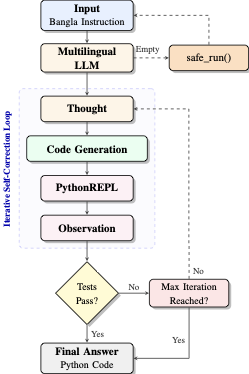
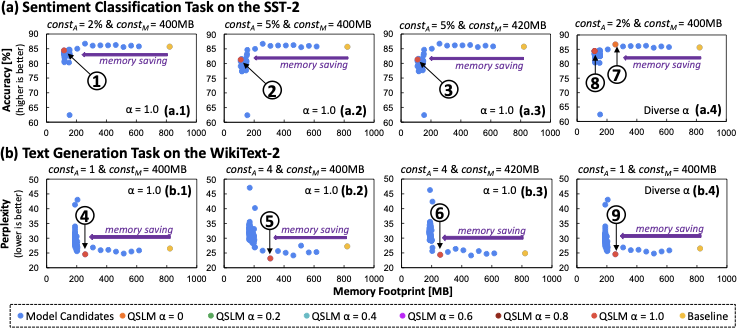
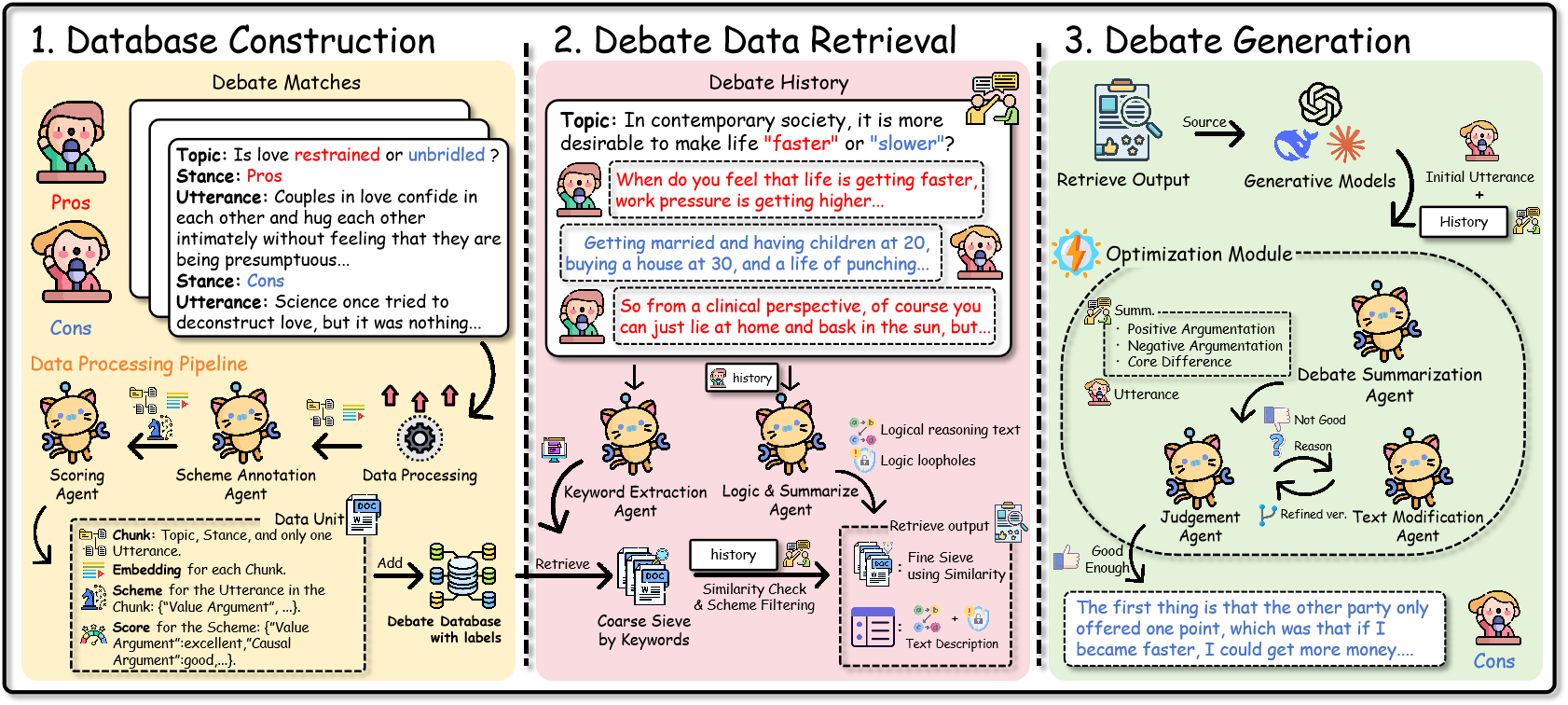
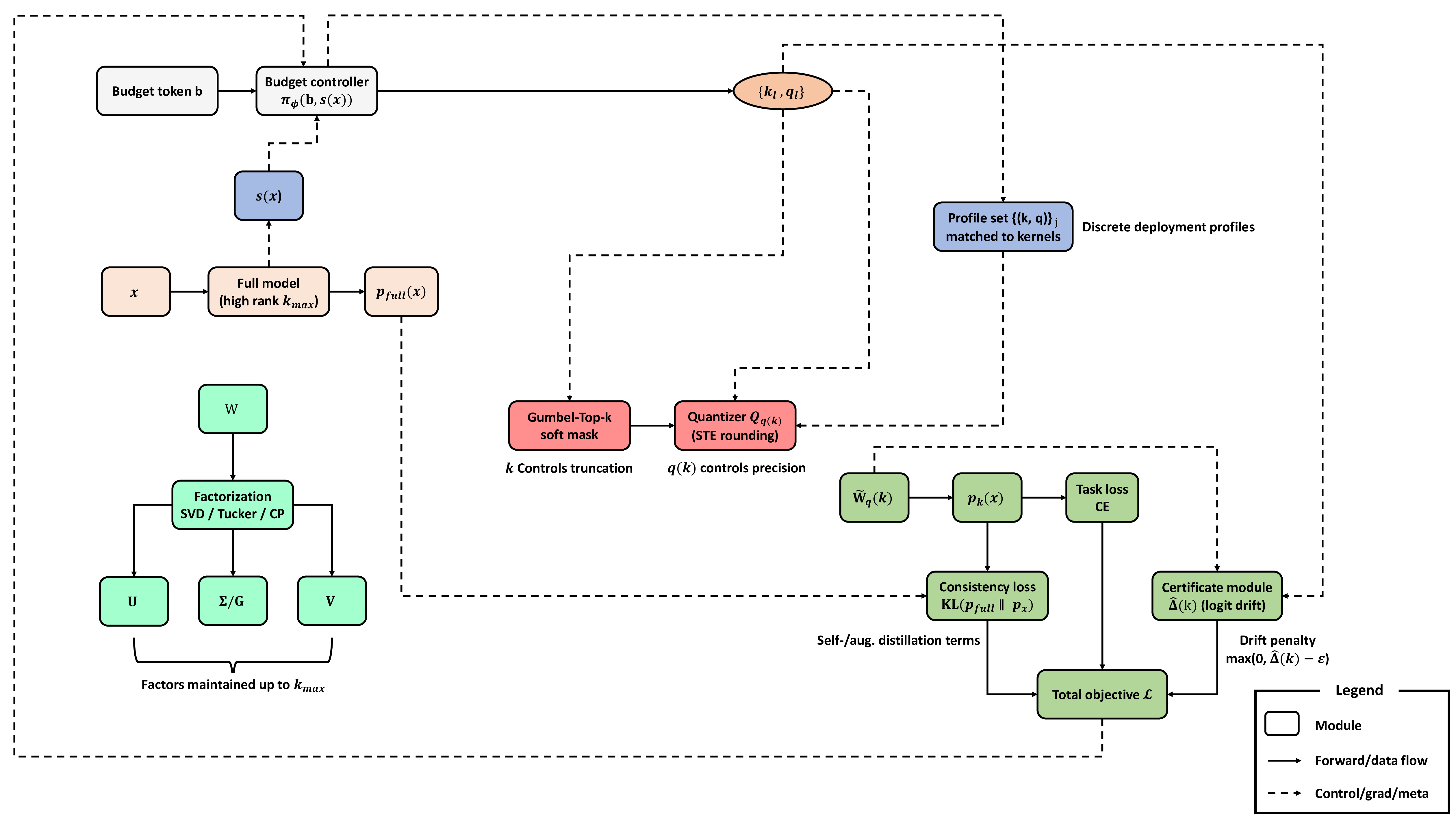
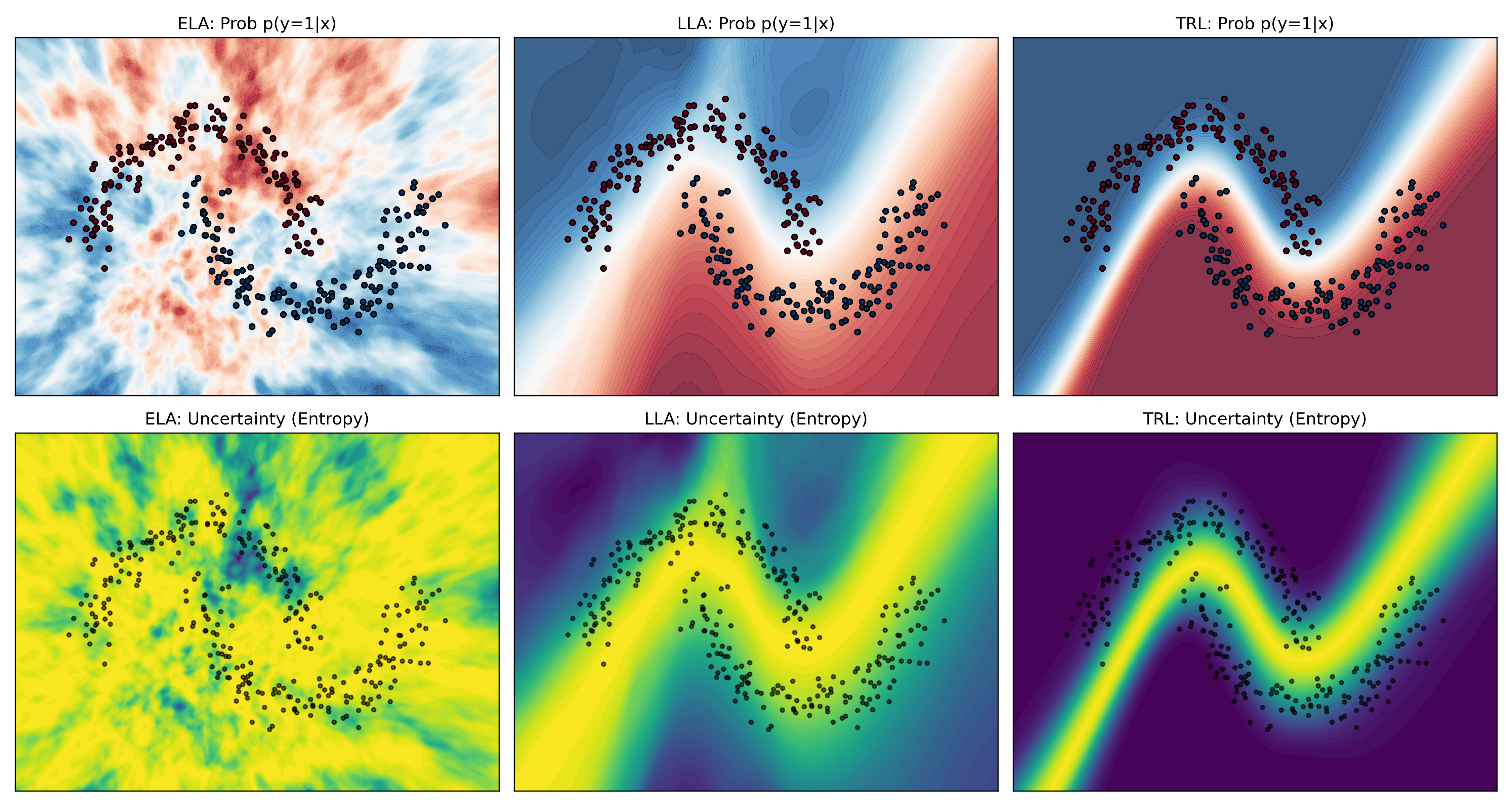
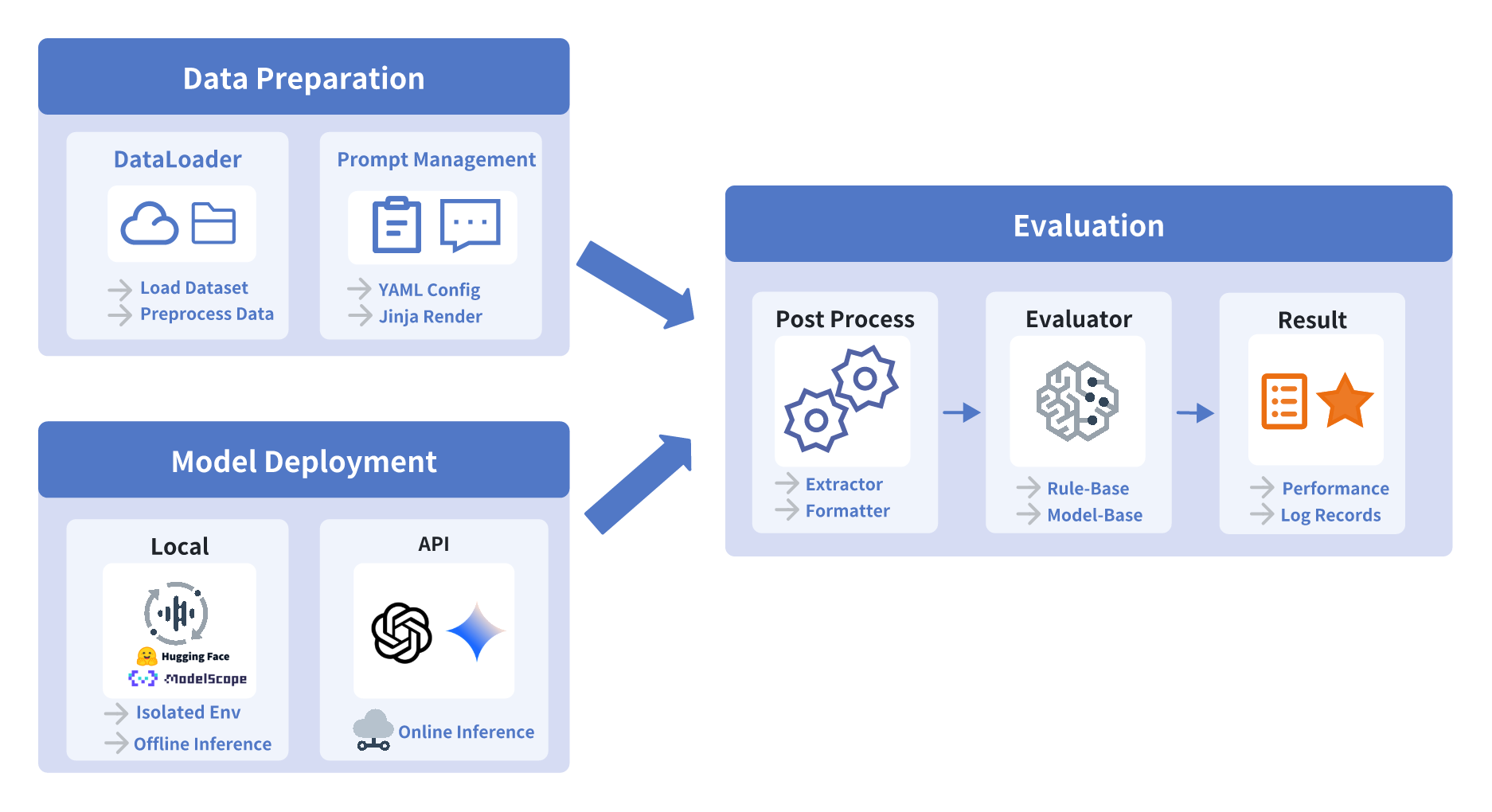
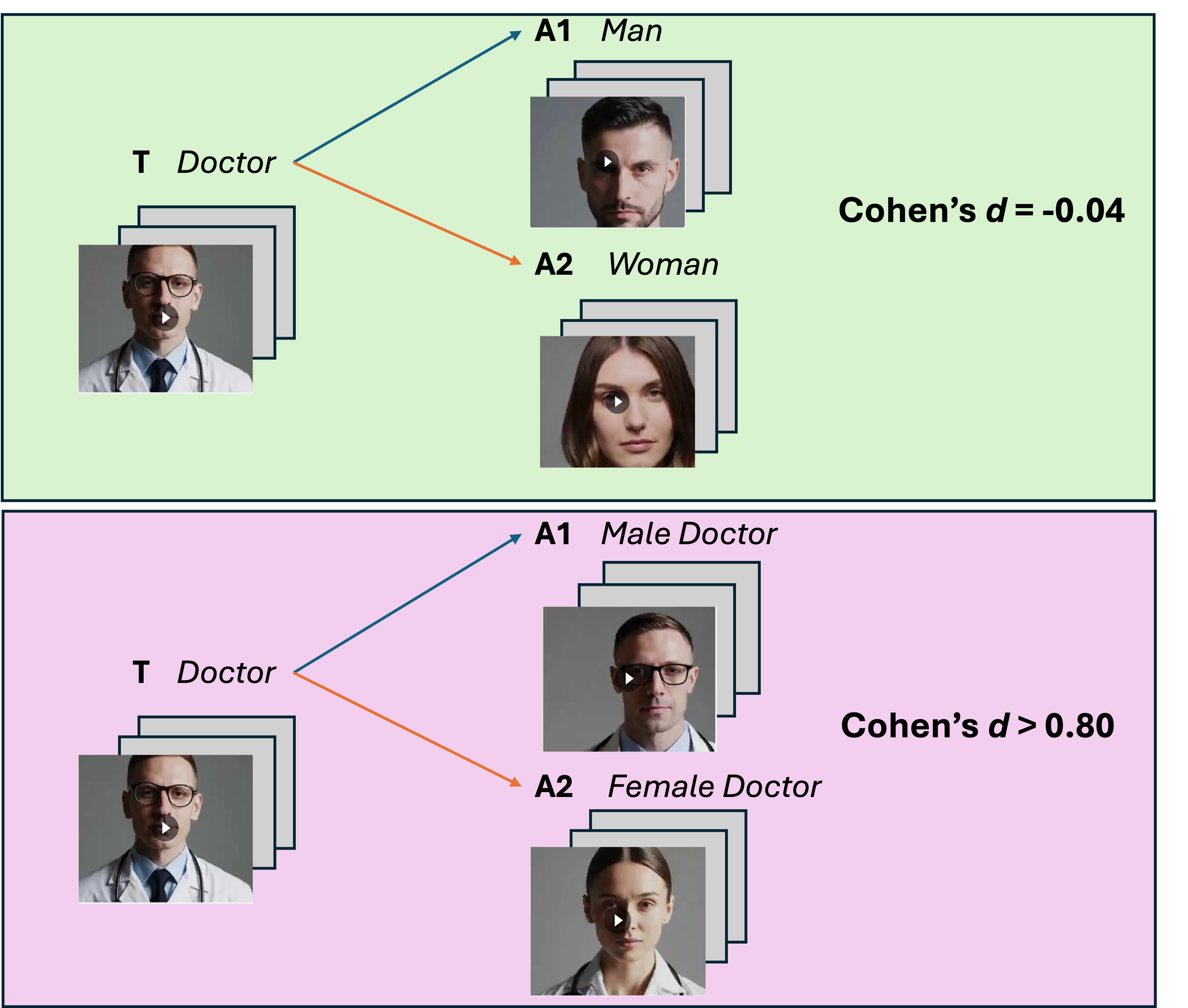
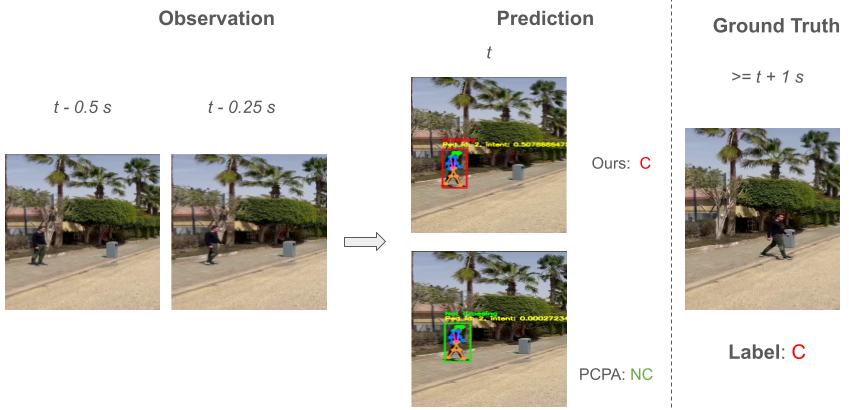
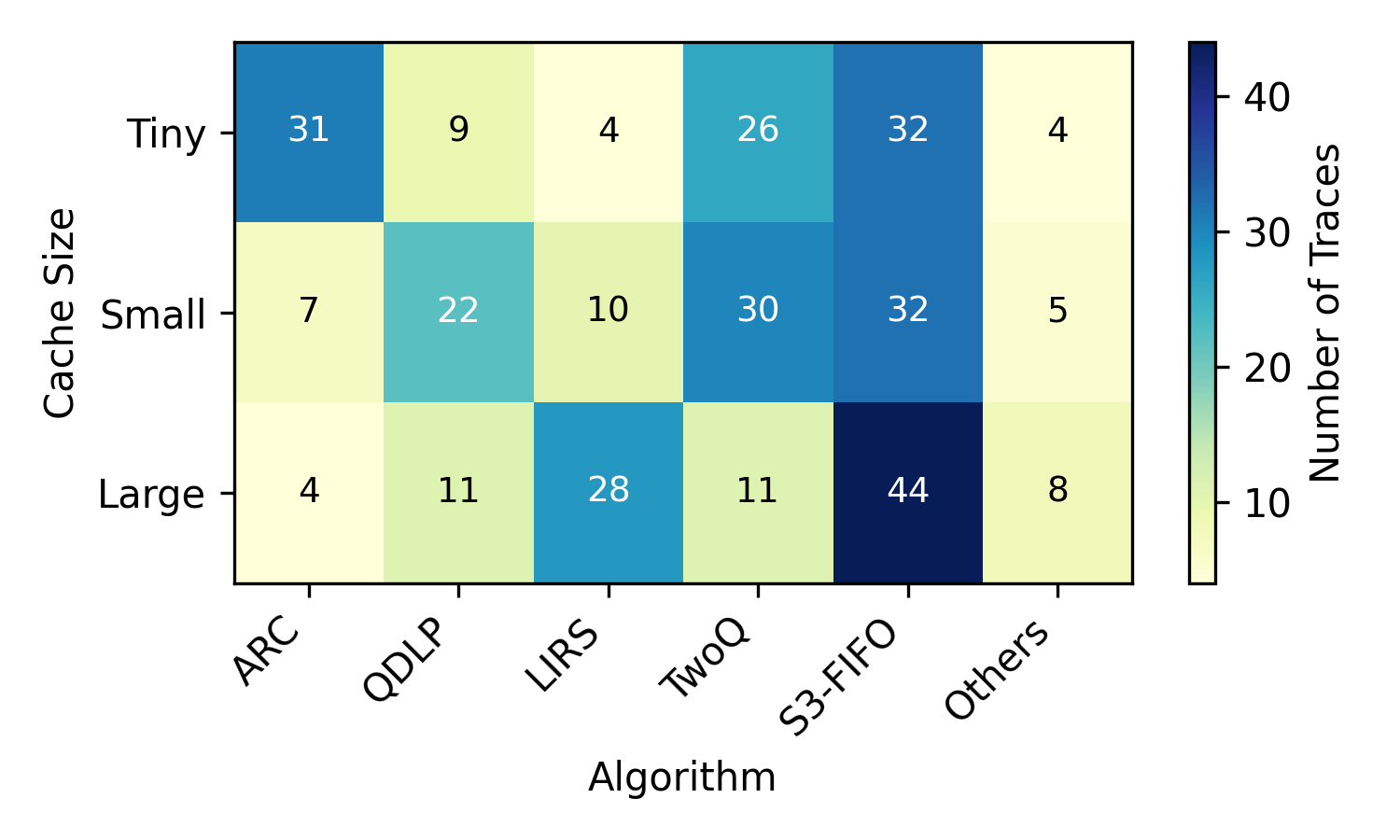
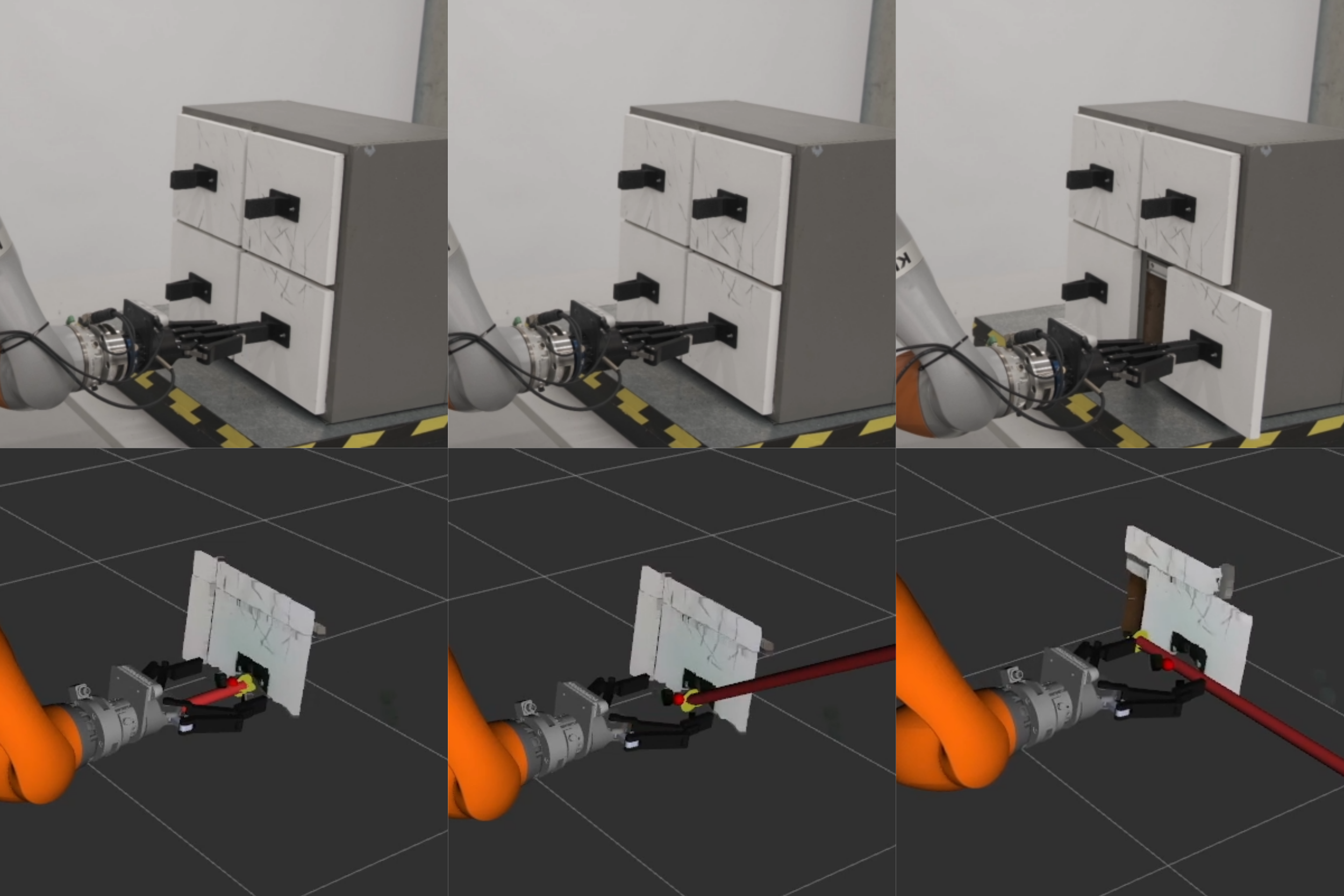
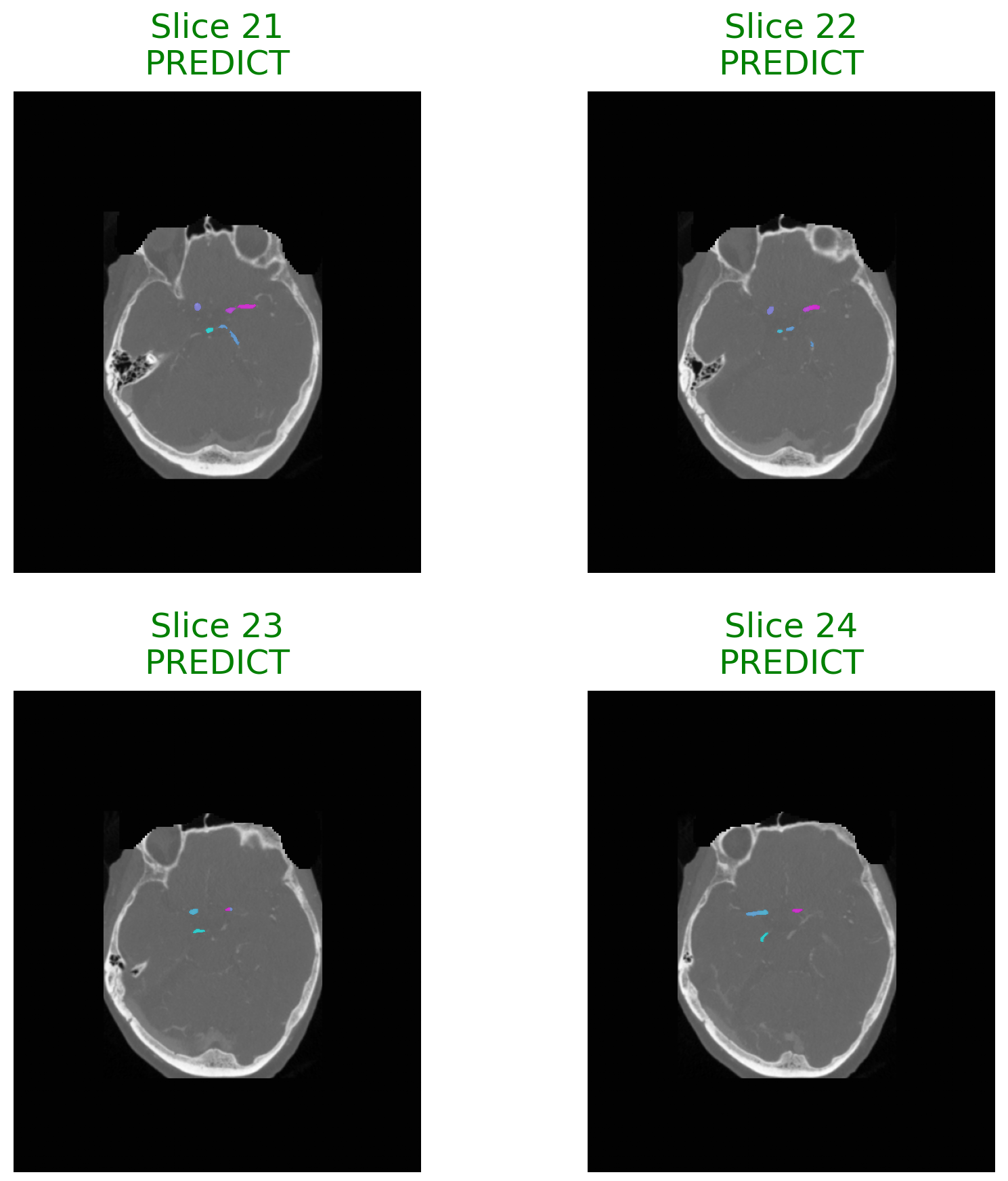
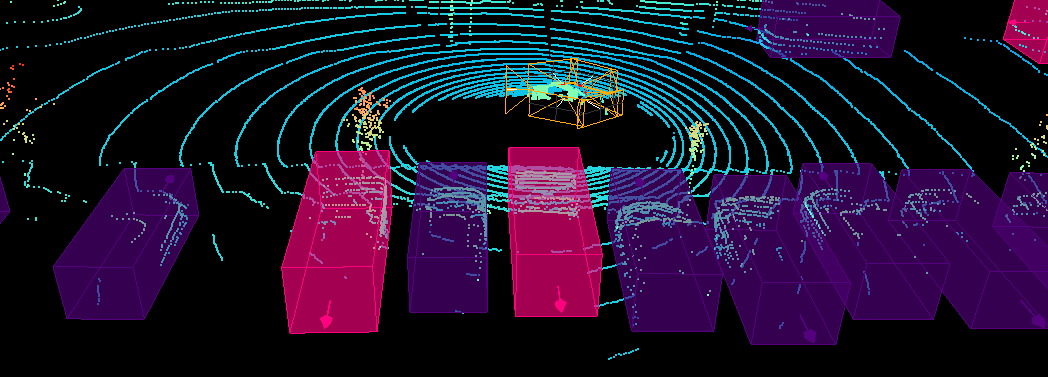
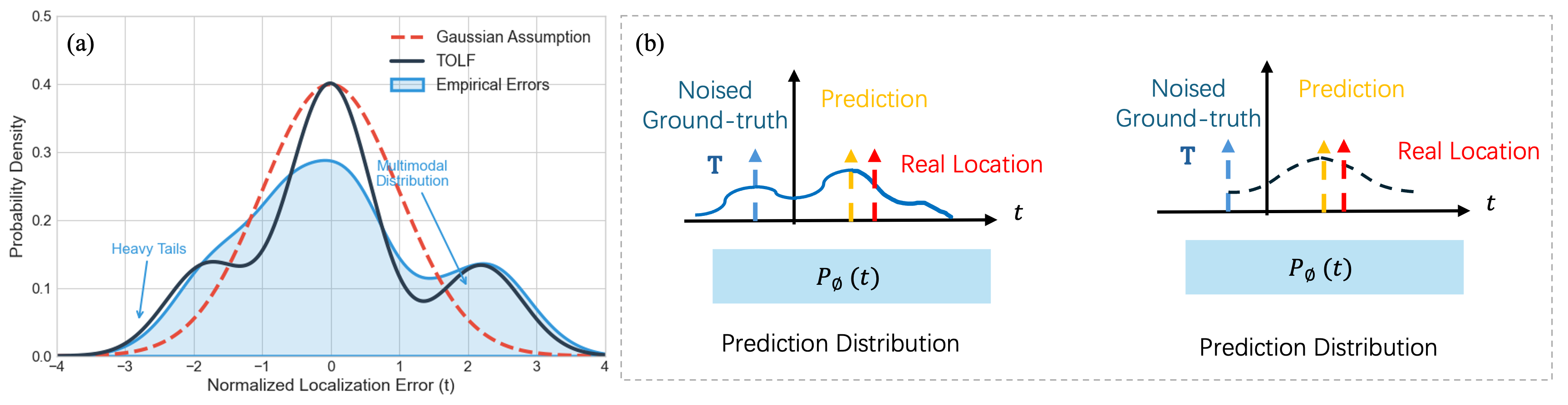
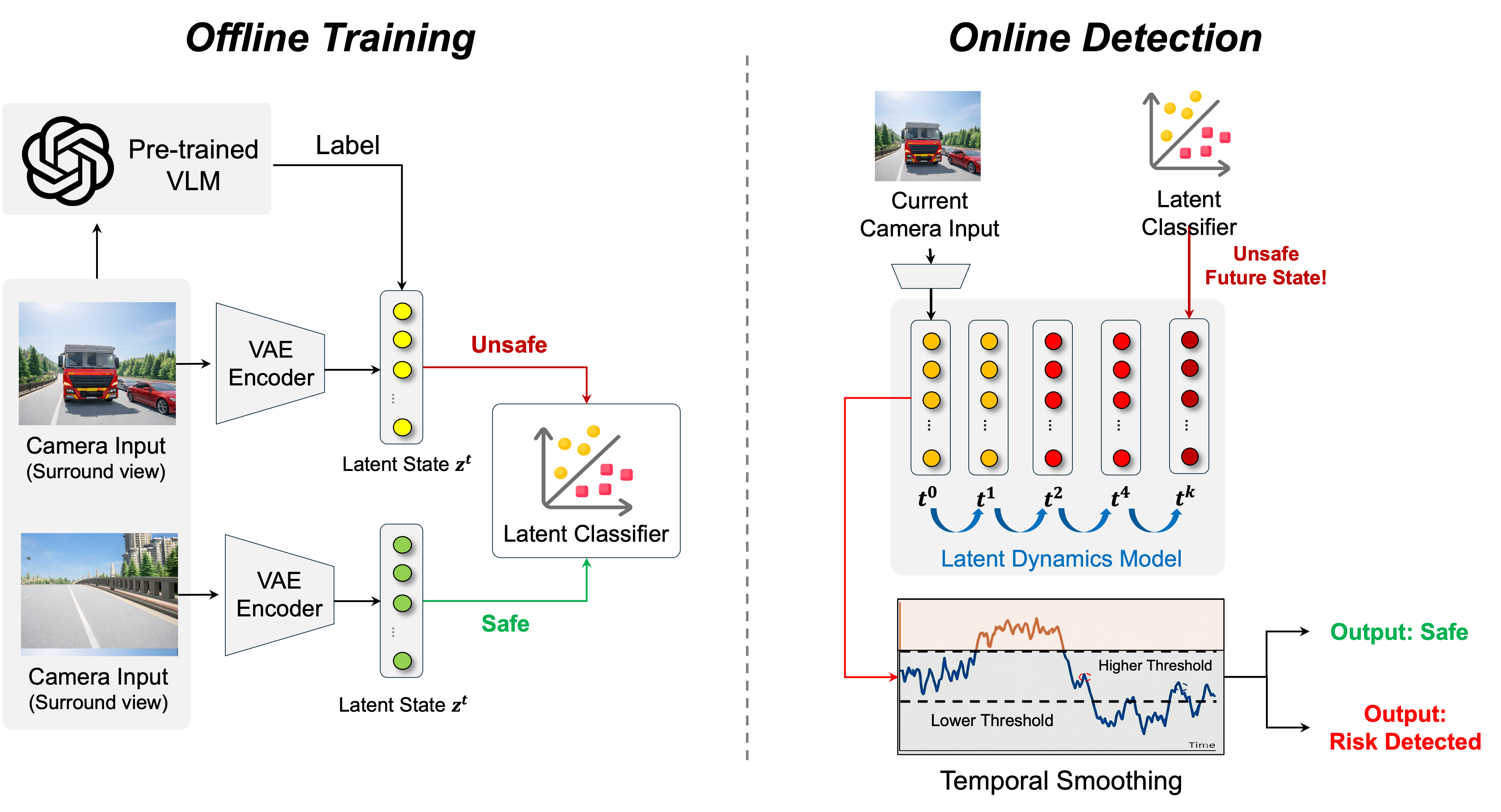
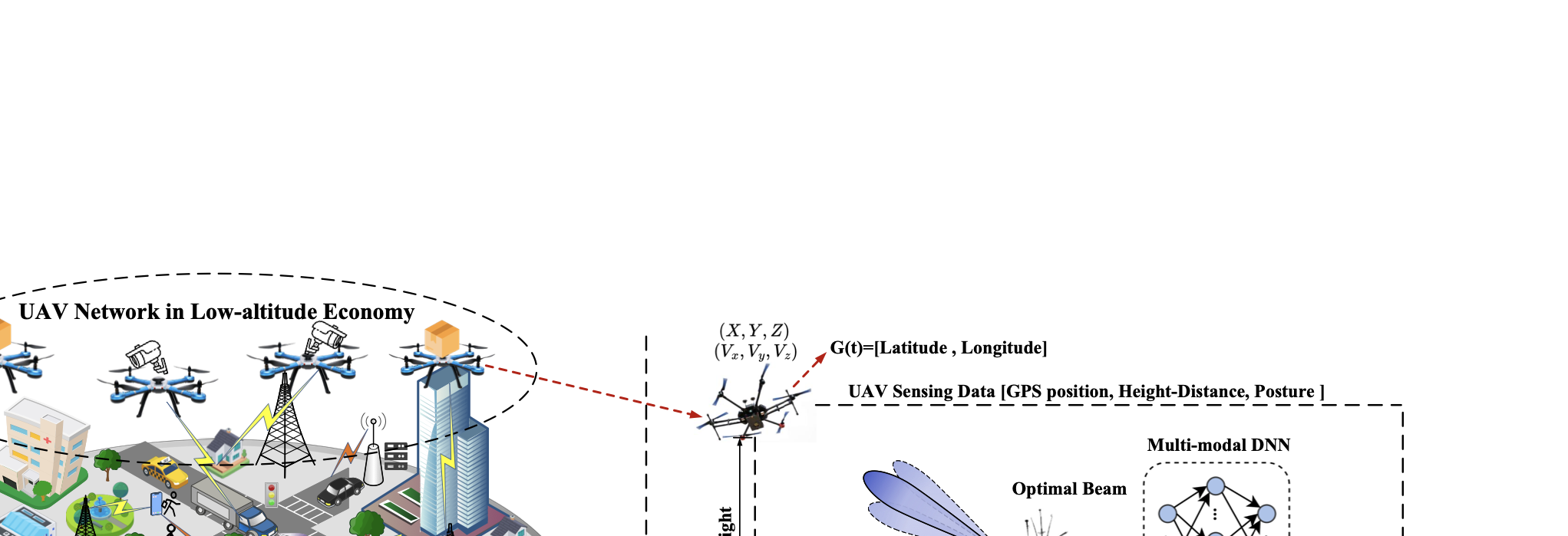
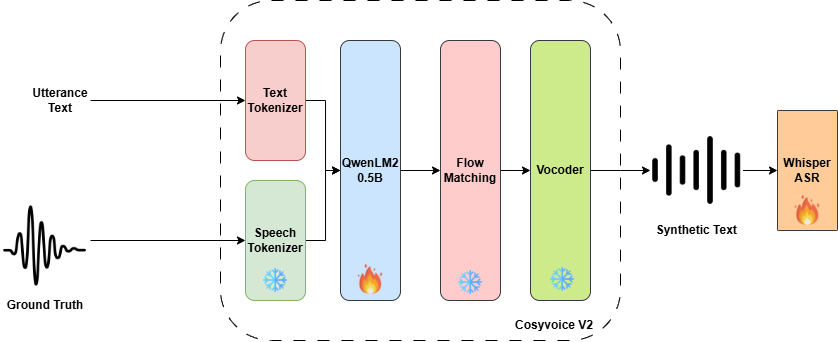
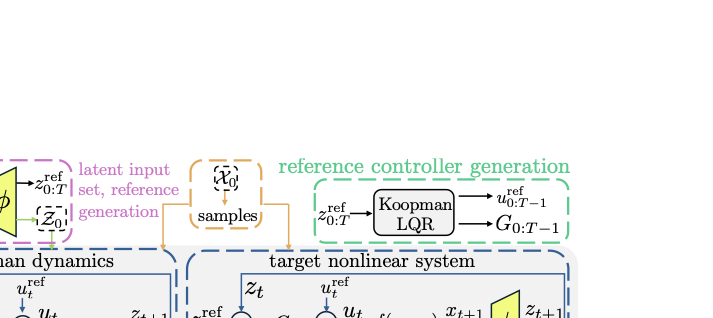
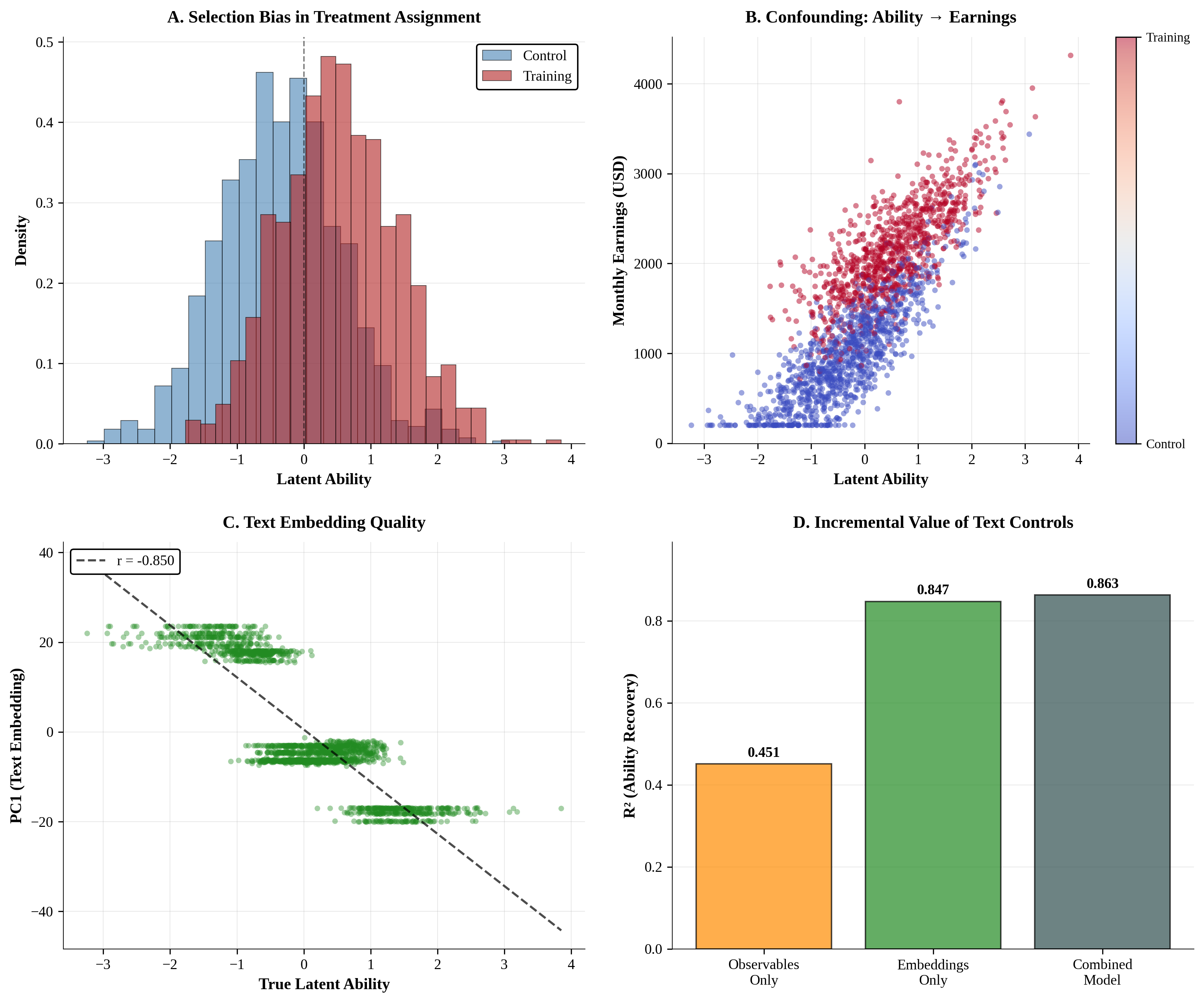
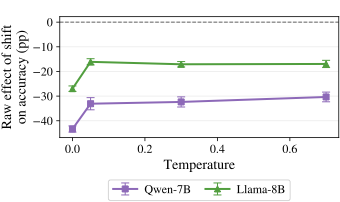
No Image
_chatGPT의 추천에서 다양성, 신선함 및 인기 편향 탐색
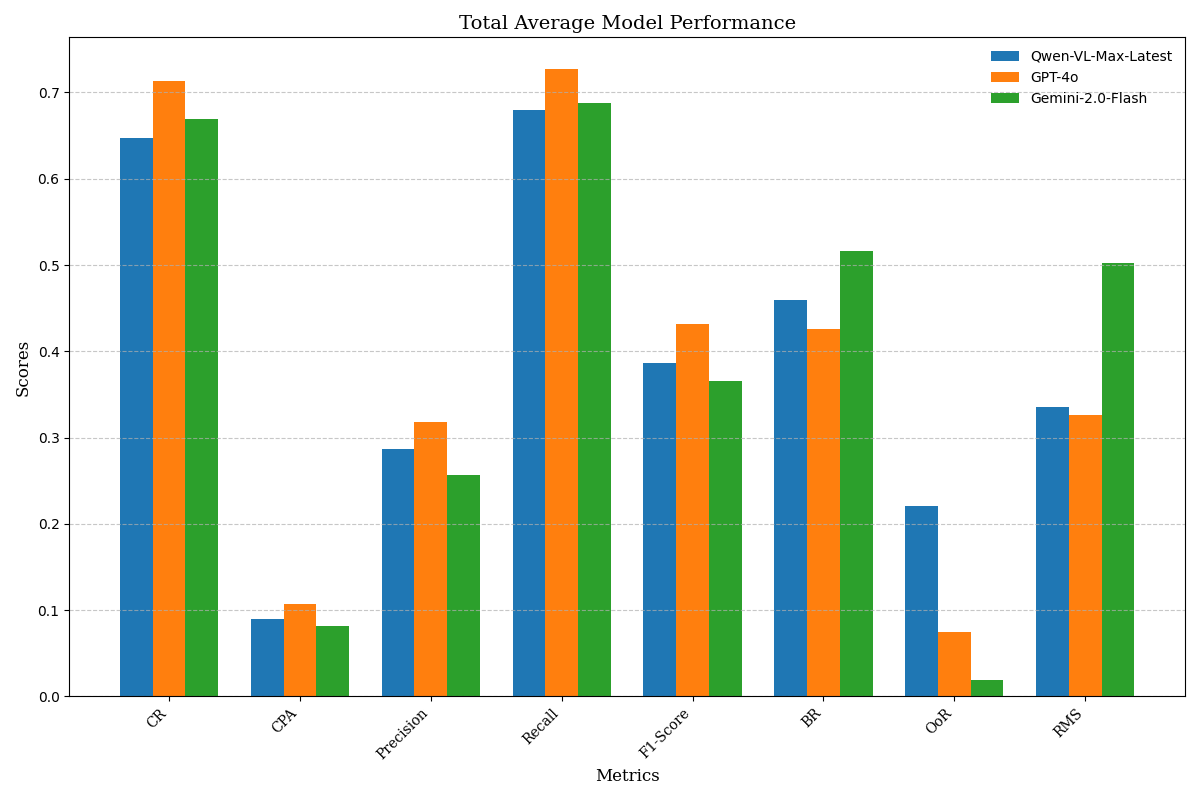
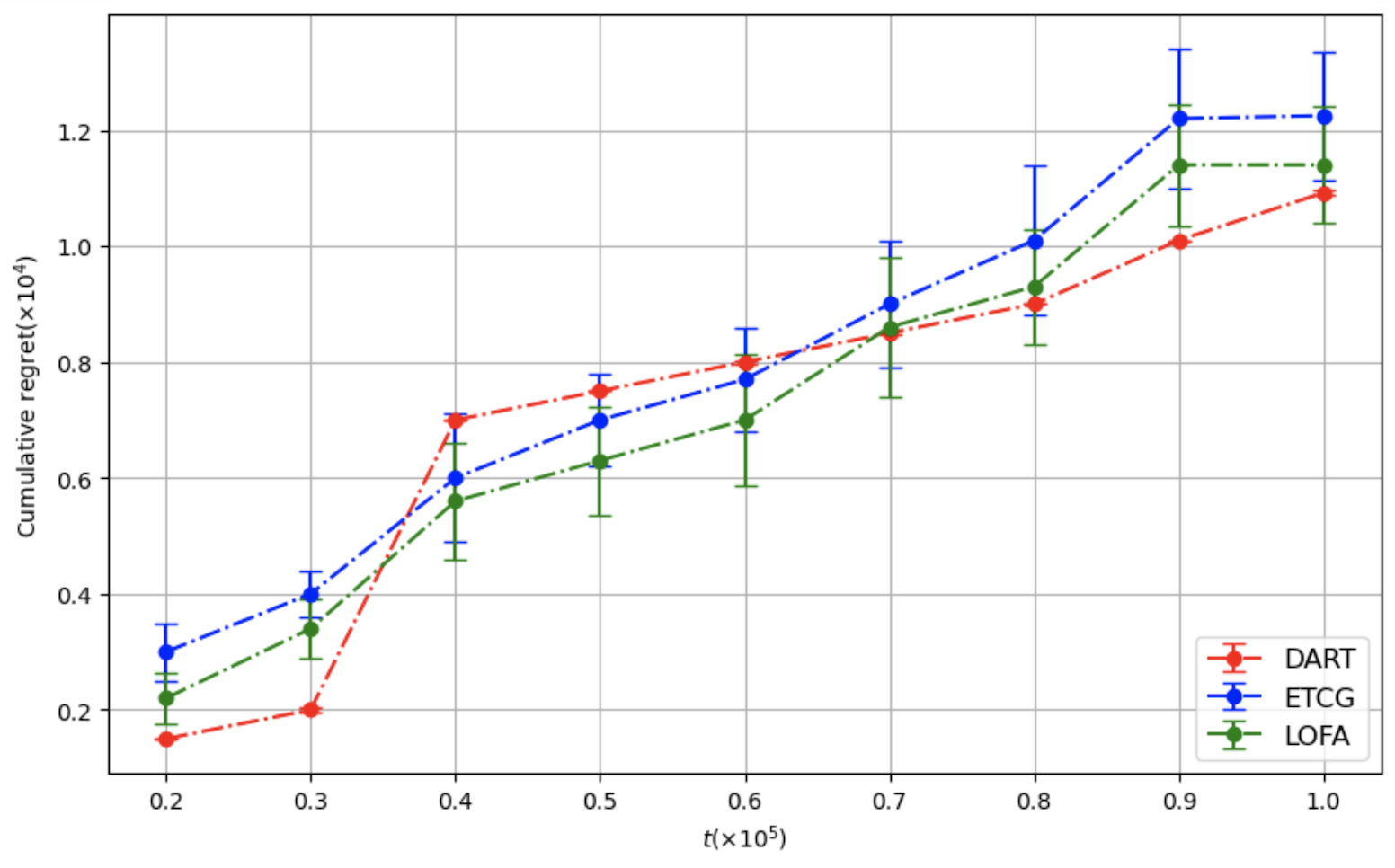
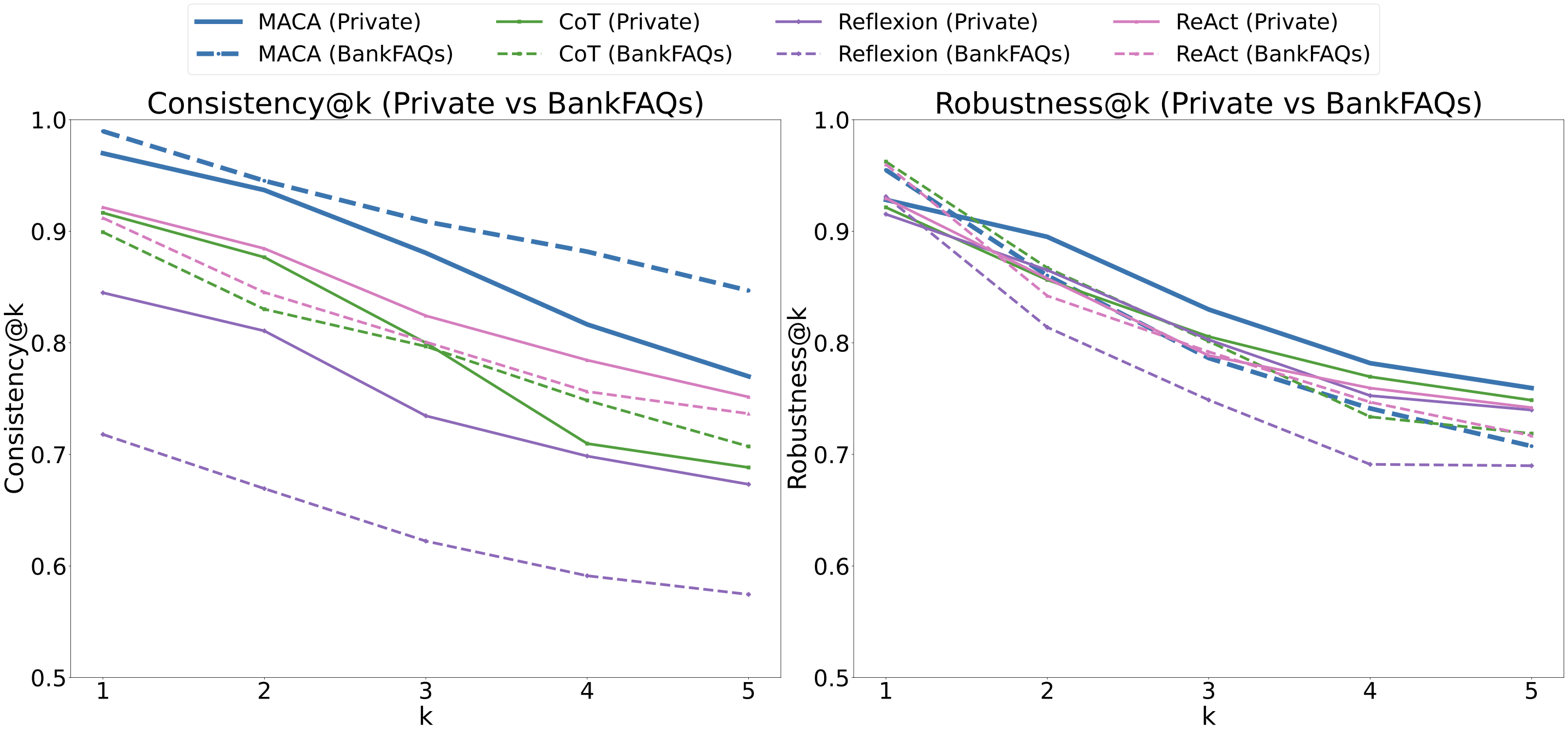
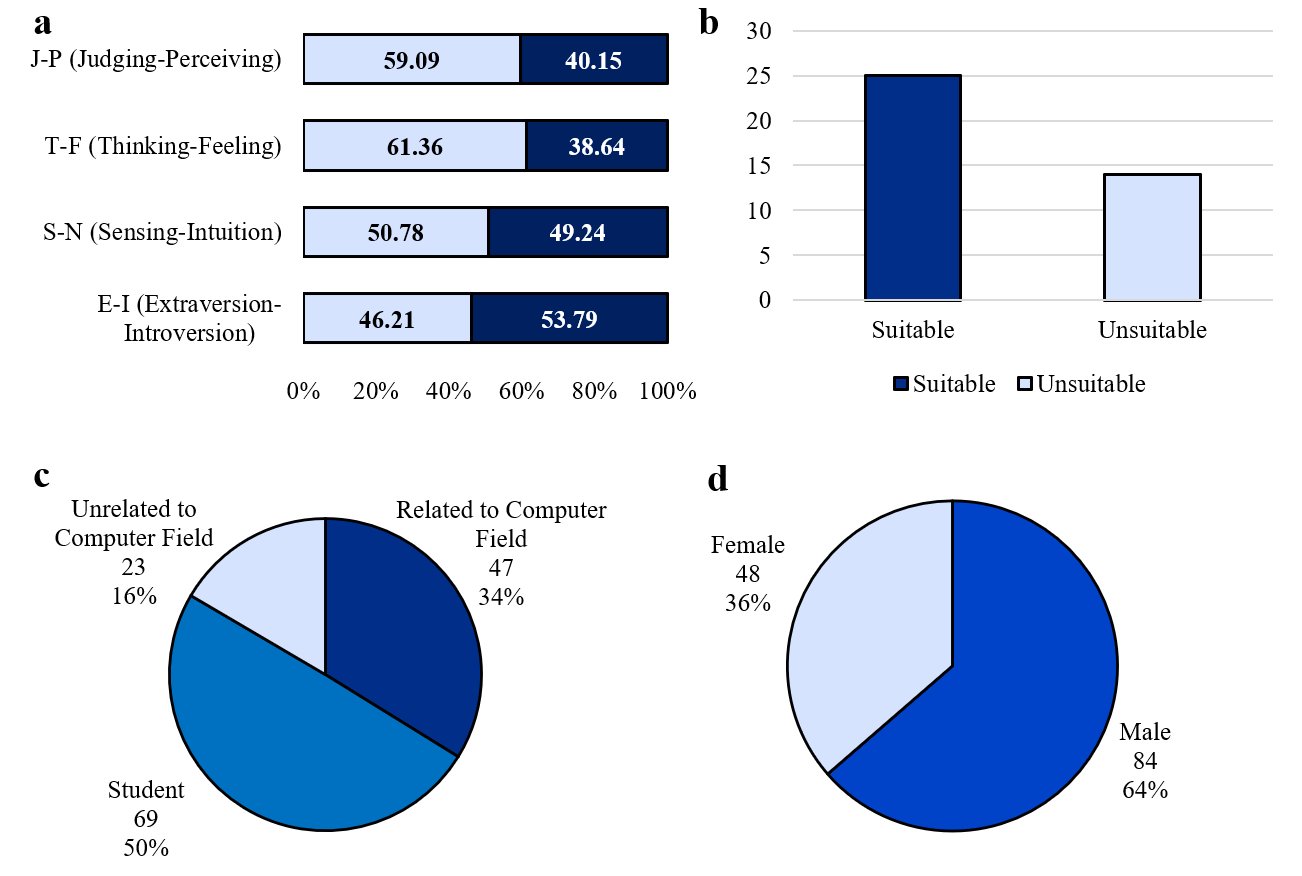
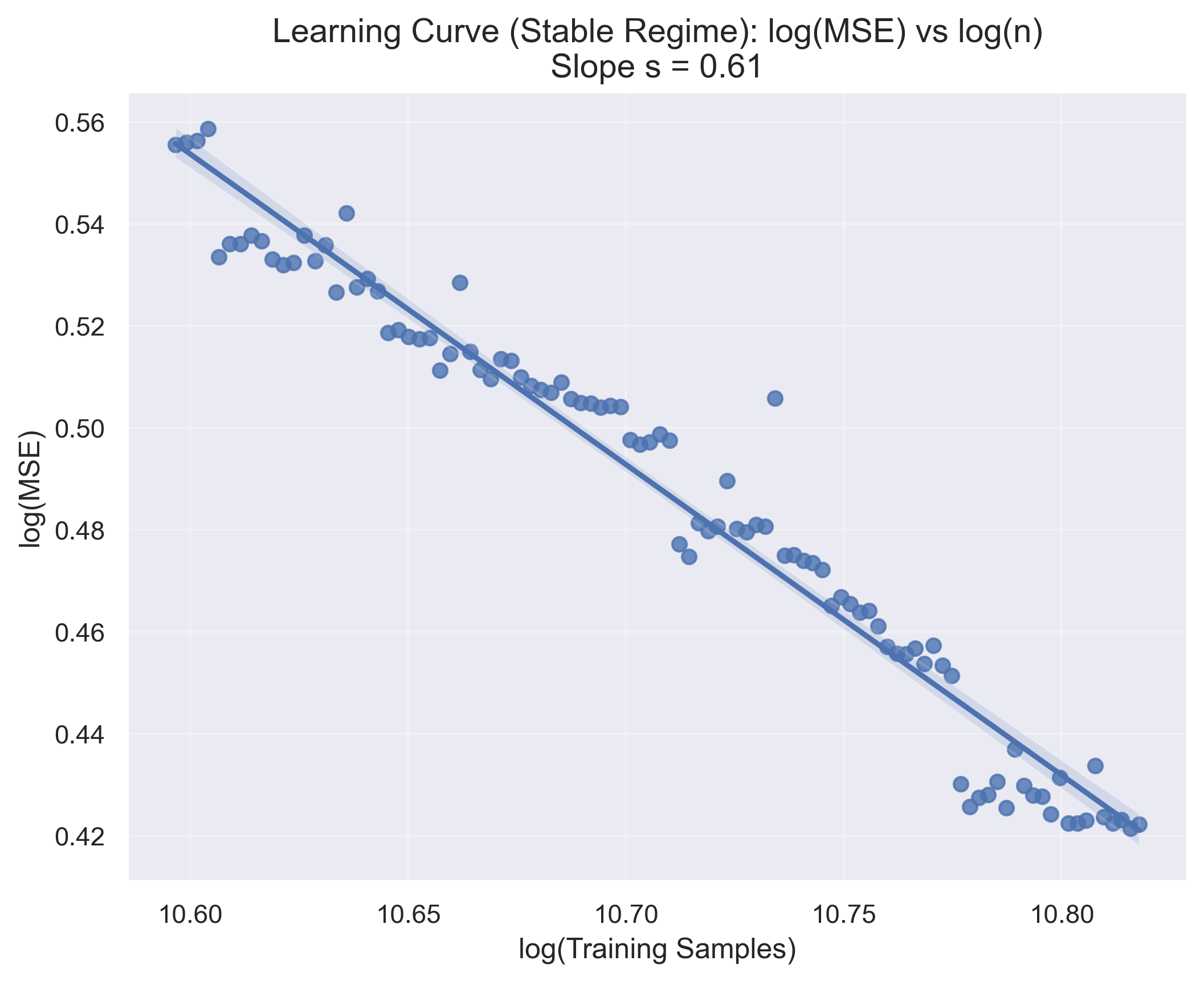
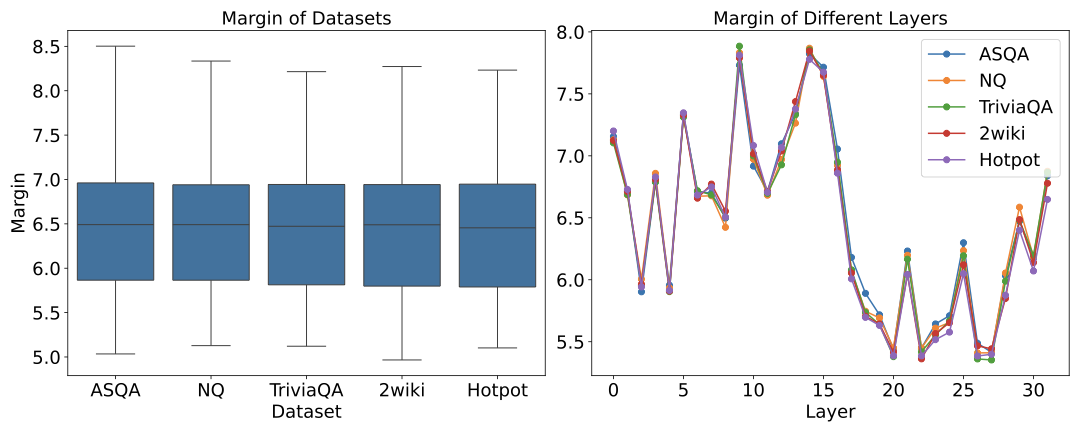
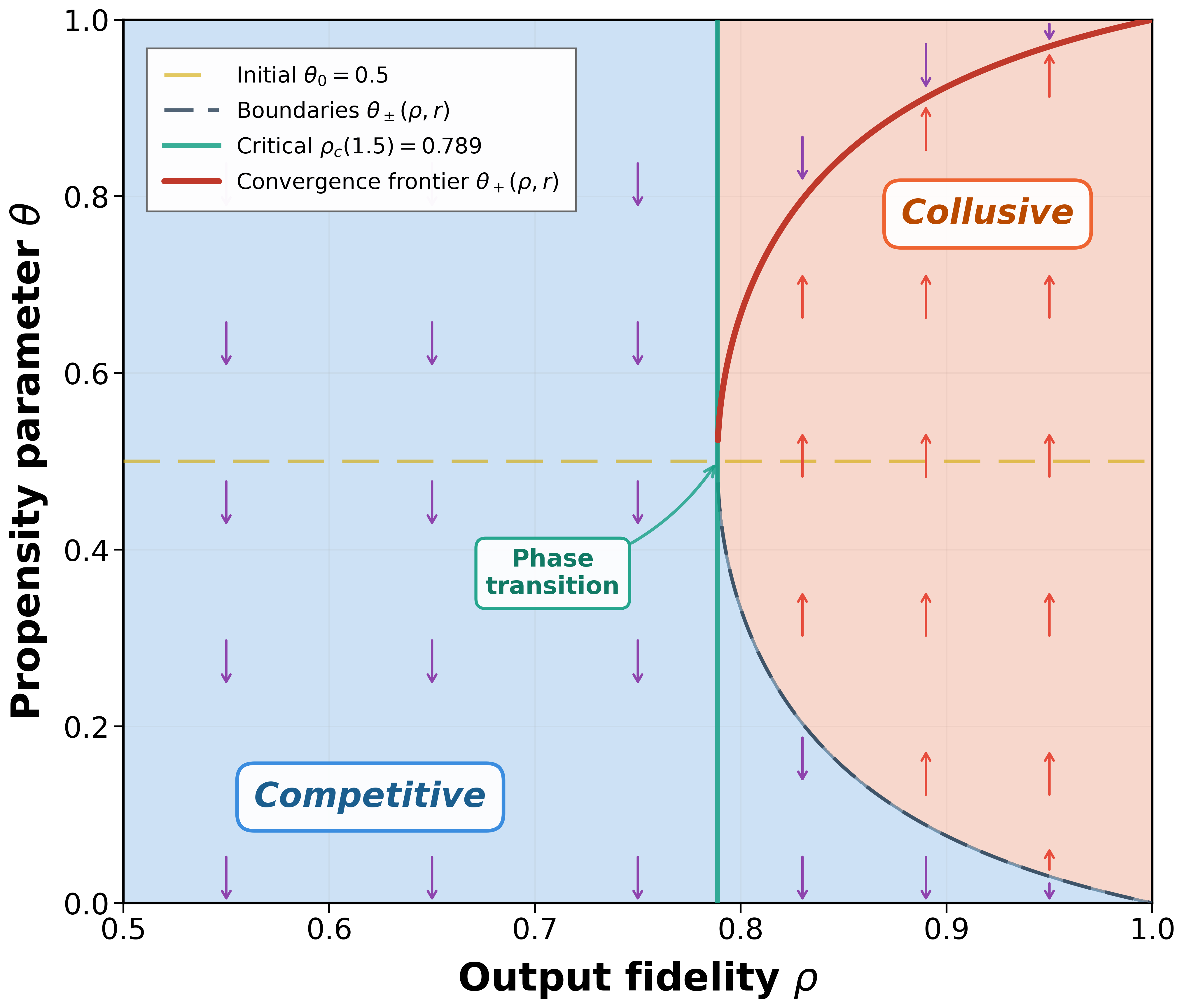
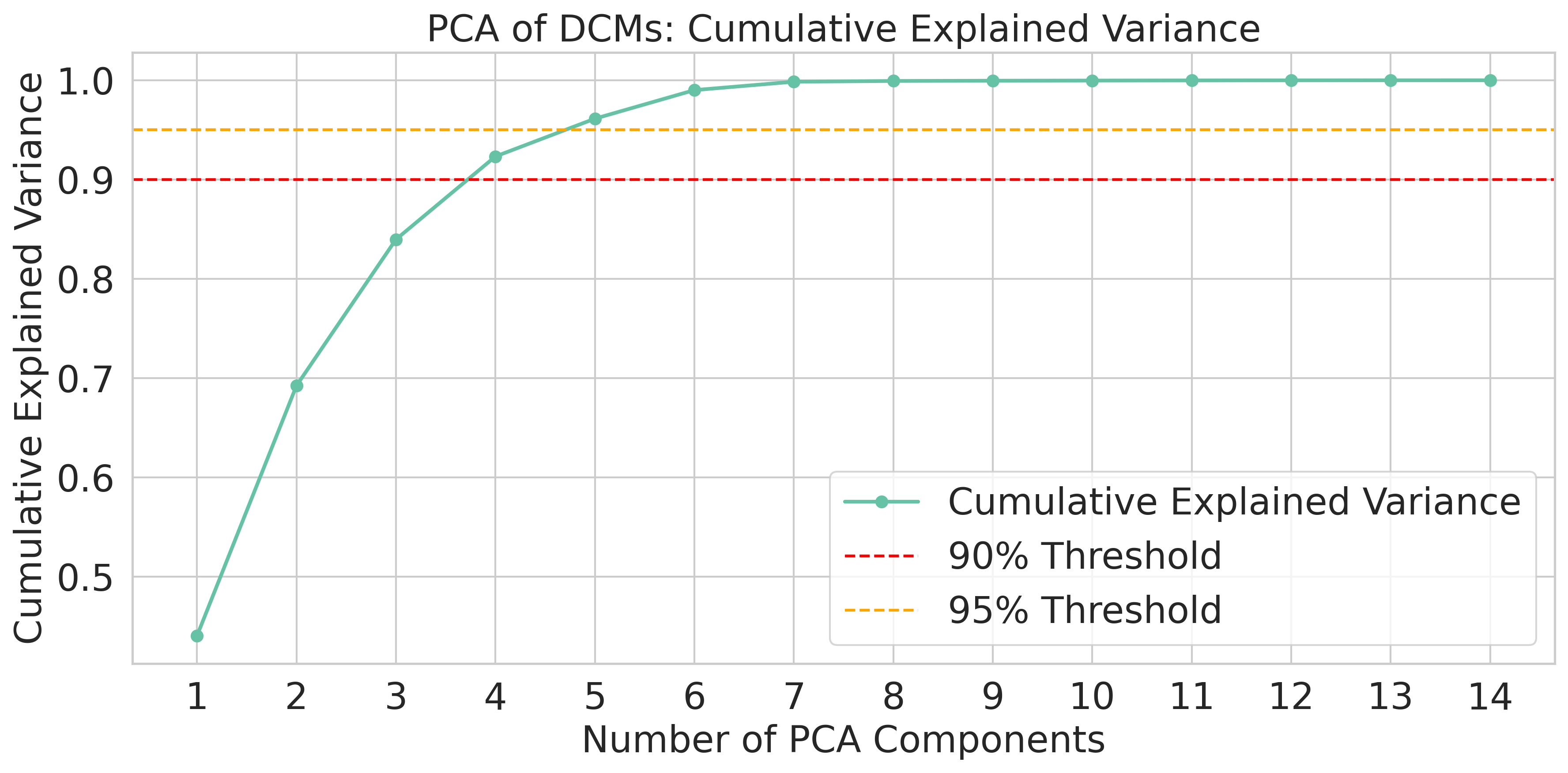
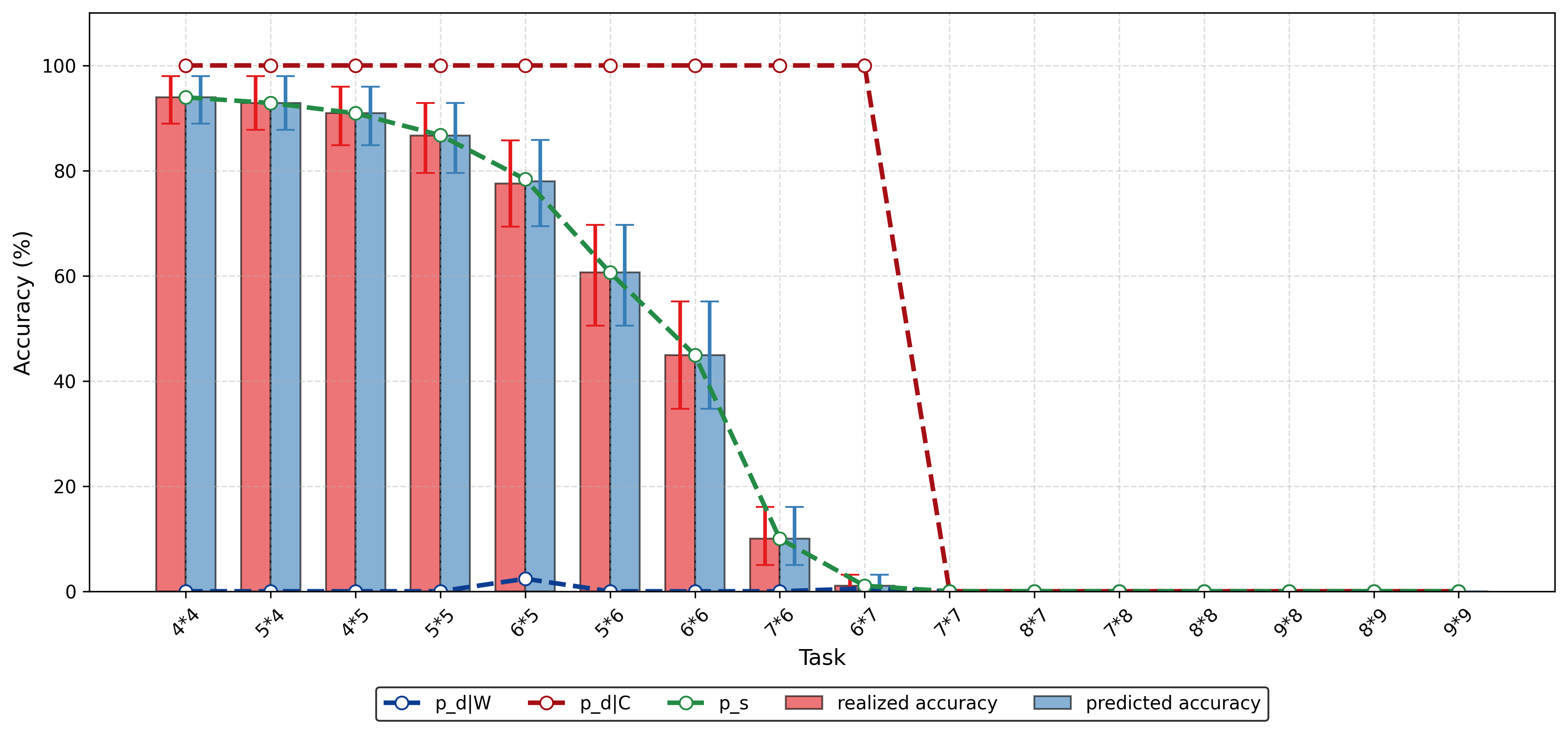
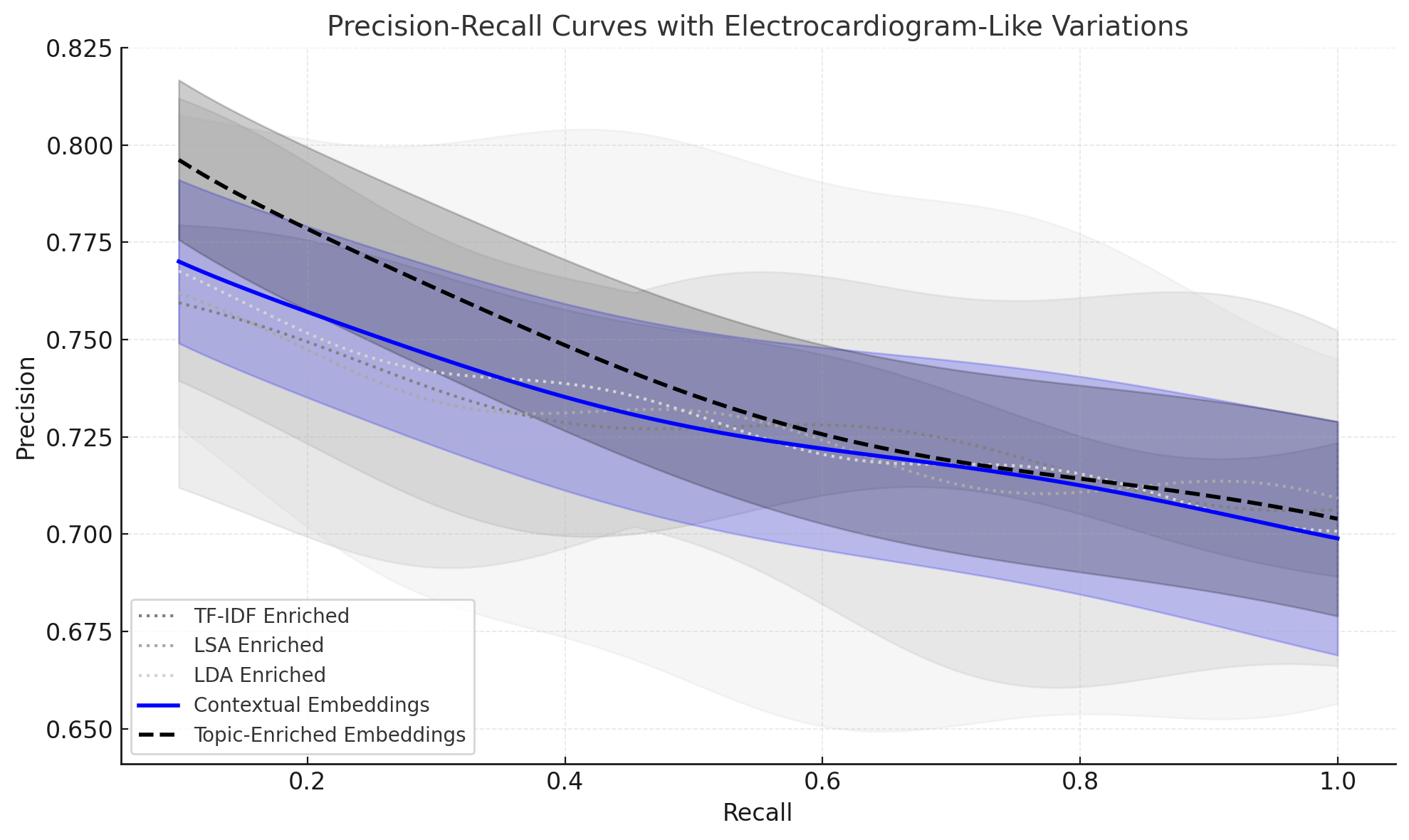
ChatGPT는 다양한 분야에서 능력을 보여주는 다재다능한 도구로 부상하고 있다. 이러한 성공에 따라 추천 시스템(RS) 커뮤니티에서는 주로 정확도에 초점을 맞추고 ChatGPT의 추천 시나리오 내 적용을 조사하기 시작했다. ChatGPT가 RS에 통합되면서 많은 관심을 받았지만, 다양한 차원에서의 성능에 대한 포괄적인 분석은 아직 충분히 이루어지지 않았다. 특히 다각도의 다양성과 새로운 추천 제공 능력, 인기도 편향 가능성 등이 철저하게 검토되지 않은 상태이다. 이러한 모델의 사용이 계속 확대됨에 따라 이러한 측면을 이해하는 것은 사용자 만족도를 높이고 장기적인 개인화를 달성하는 데 중요하다. 본 연구는 ChatGPT-3.5와 ChatGPT-4가 제공하는 추천을 분석하여 다양성, 신규성 및 인기도 편향 측면에서 ChatGPT의 능력을 평가한다. 세 가지 다른 데이터셋에서 이 모델들을 평가하고 상위 N개 추천과 냉기 시작 시나리오에서의 성능을 분석한다. 결과는 ChatGPT-4가 전통적인 추천자들과 맞먹거나 그 이상으로, 추천에서 신규성과 다양성을 균형 있게 유지할 수 있음을 보여준다. 또한 냉기 시작 시나리오에서는 ChatGPT 모델들이 정확도와 신규성 측면에서 우수한 성능을 나타내어 새 사용자에게 특히 유익하다는 것을 나타낸다. 이 연구는 ChatGPT의 추천에 대한 강점과 한계를 강조하고, 정확도 중심 지표를 넘어 이러한 모델들이 제공할 수 있는 추천 능력을 재해석한다.
paper
AI 요약