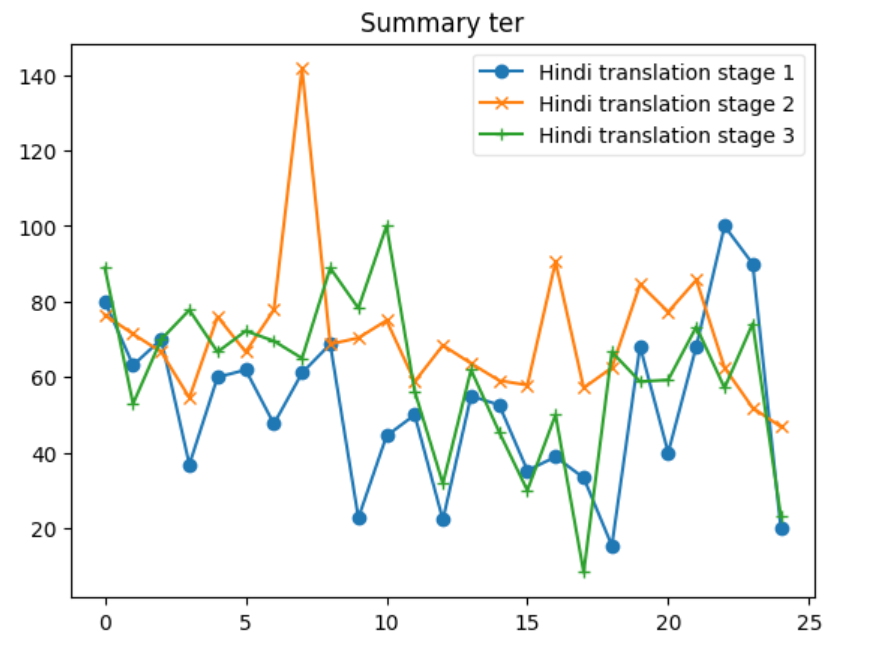
힌디어 요약 데이터셋을 자동으로
자연어 처리(NLP)와 기계 학습(ML) 기술의 발전은 주로 자원이 풍부한 언어, 특히 영어에 집중되어왔다. 이는 힌디어 같은 저자원 언어에서 데이터셋의 부족과 질적 불균형을 초래했다. 특히 텍스트 요약이라는 전문 작업에서는 이러한 간극이 더욱 두드러진다. 텍스트 요약은 긴 문서를 짧고 정보적인 요약으로 압축하는 중요한 NLP 응용 분야이다. 텍스트 요약 모델의 개발은 광범위하고 다양한 데이터셋에 크게 의존하지만, 저자원 언어에서는 이러한 데이터셋이 부족하여 다양한 언어 환경에서의 발전을 방해한다. 본 연구는 힌디어를 위한 포괄적인 텍스트 요약 데이터셋 개발뿐만 아니라 저자원 언어용 자동화된 데이터셋 생성 방법론을 제안한다. 이 방법은 고급 번역 및 언어적 적응 기법과 Crosslingual Optimized Metric for Evaluation of Translation (COMET)를 활용하여 번역의 정확성과 문맥적 관련성을 보장하는 것을 특징으로 한다. 제안된 힌디어 데이터셋은 XSUM의 강력한 번역 버전으로, 다양한 주제와 쓰기 스타일을 반영하고 있다. 이를 통해 힌디어 텍스트 요약 연구를 진흥시키고, 언어 간 NLP 도전 과제에 대한 보다 광범위한 이해를 제공한다. 이 데이터셋은 원본 XSUM과 같은 다양성을 유지하면서 다양한 텍스트 복잡성 및 주제를 반영하고 있다. 결론적으로, 영어 XSUM을 기반으로 한 힌디어 텍스트 요약 데이터셋의 생성은 NLP 연구와 응용 분야에서 비용을 절감함으로써 민주화에 중요한 단계를 이룬다. 이로 인해 저자원 언어에 대한 더 세밀하고 문화적으로 관련성이 높은 NLP 모델이 개발되며, 특히 기존에 계산 언어학에서 소홀히 대했던 언어들에 대한 텍스트 요약 연구가 활성화된다. ###