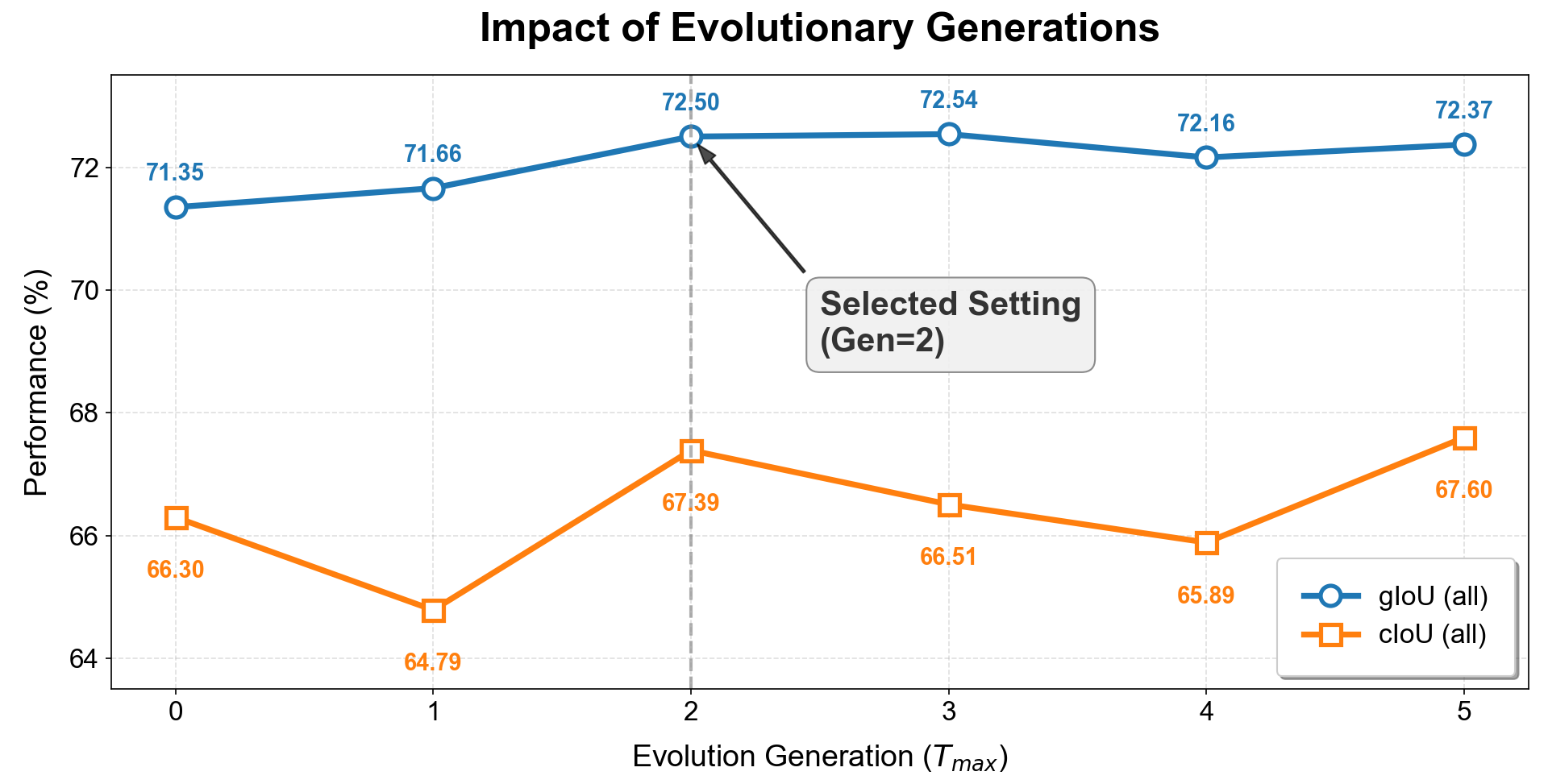
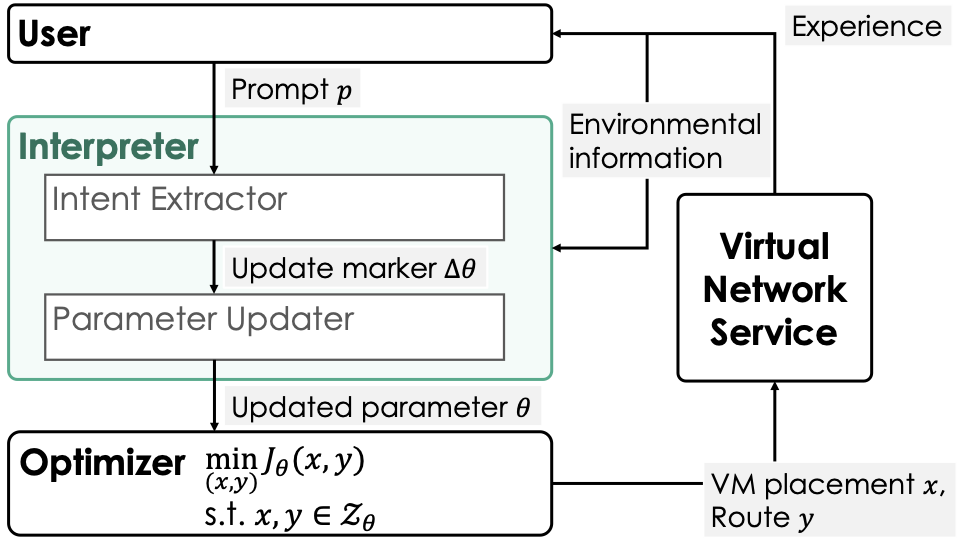
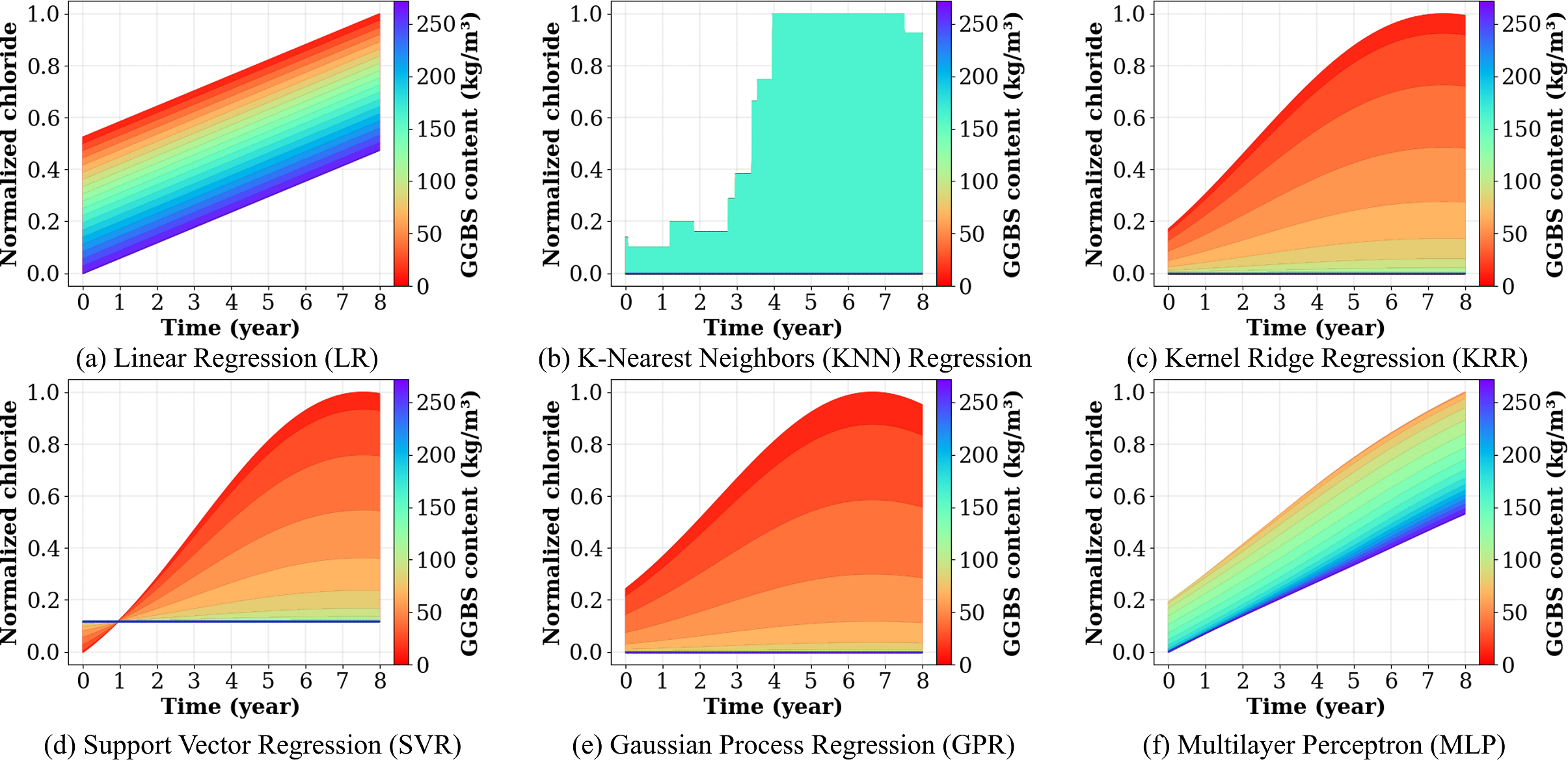
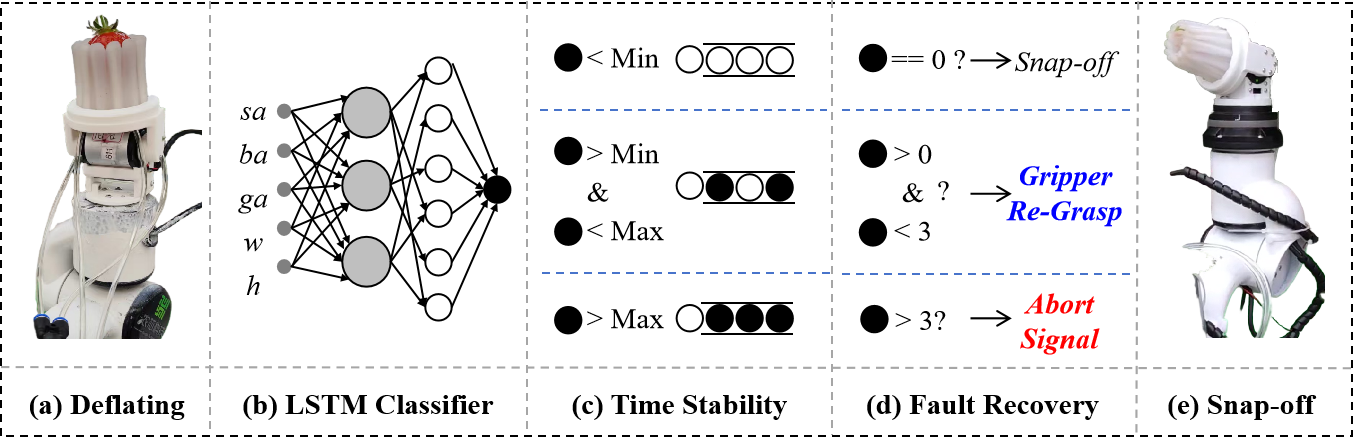
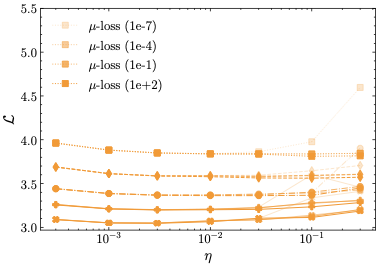
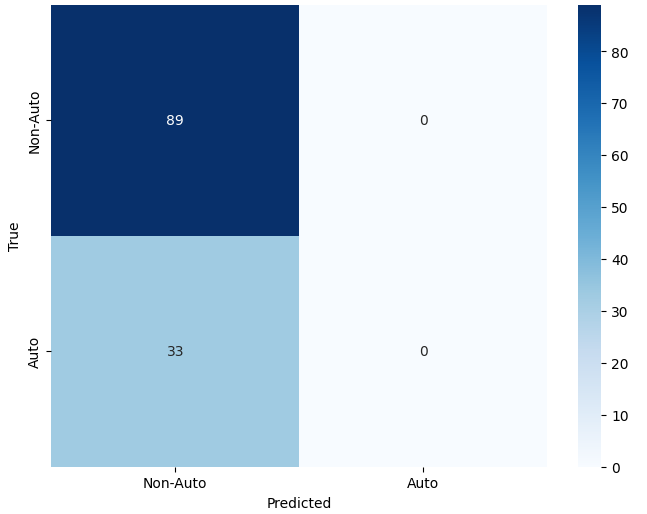
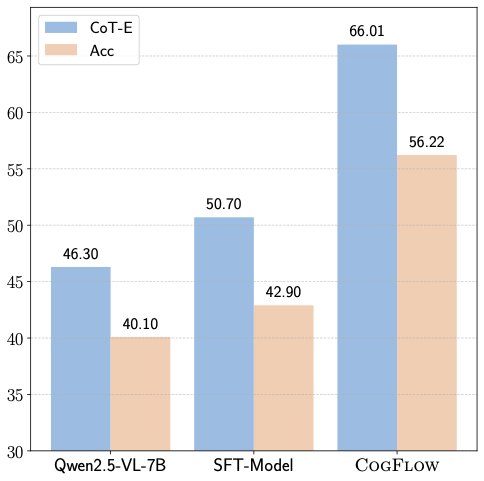
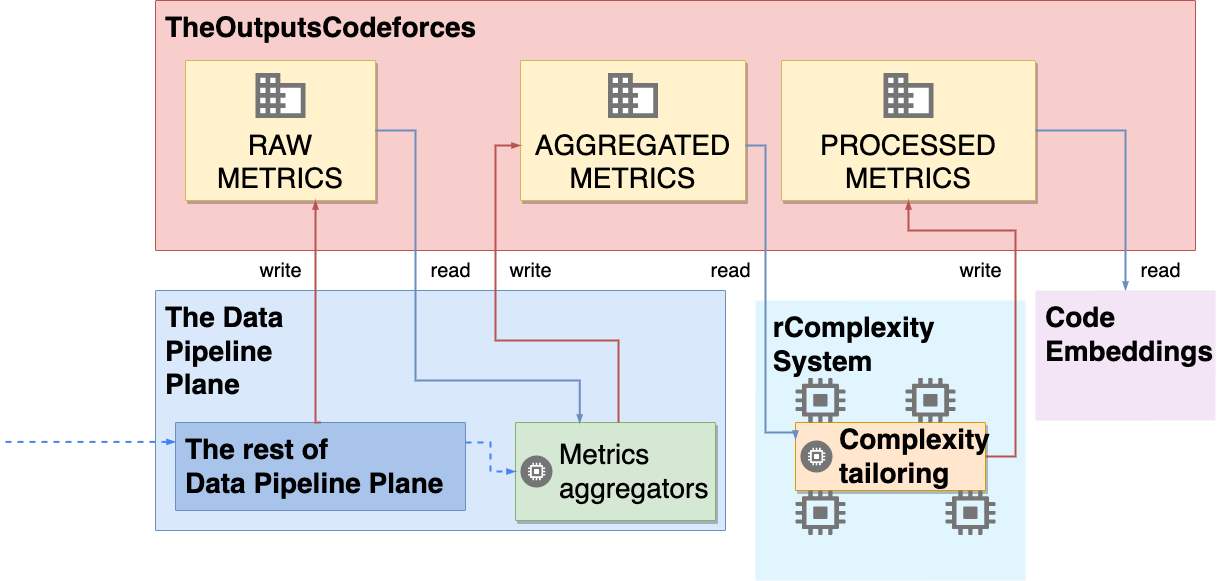
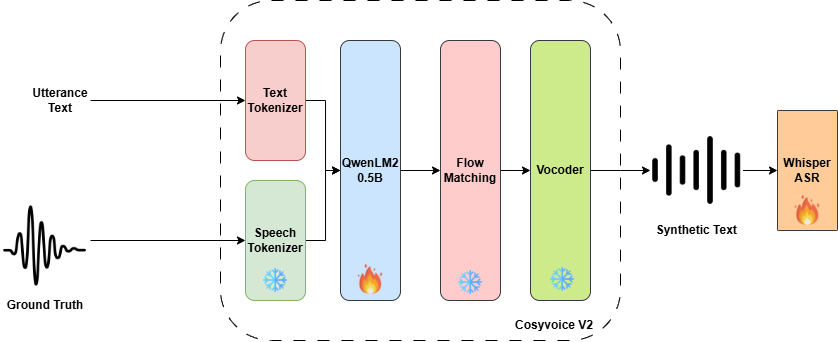
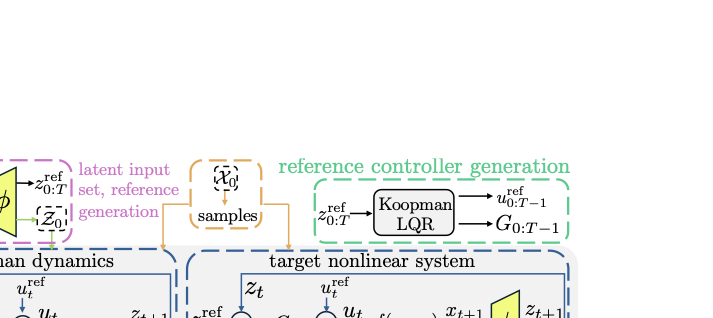
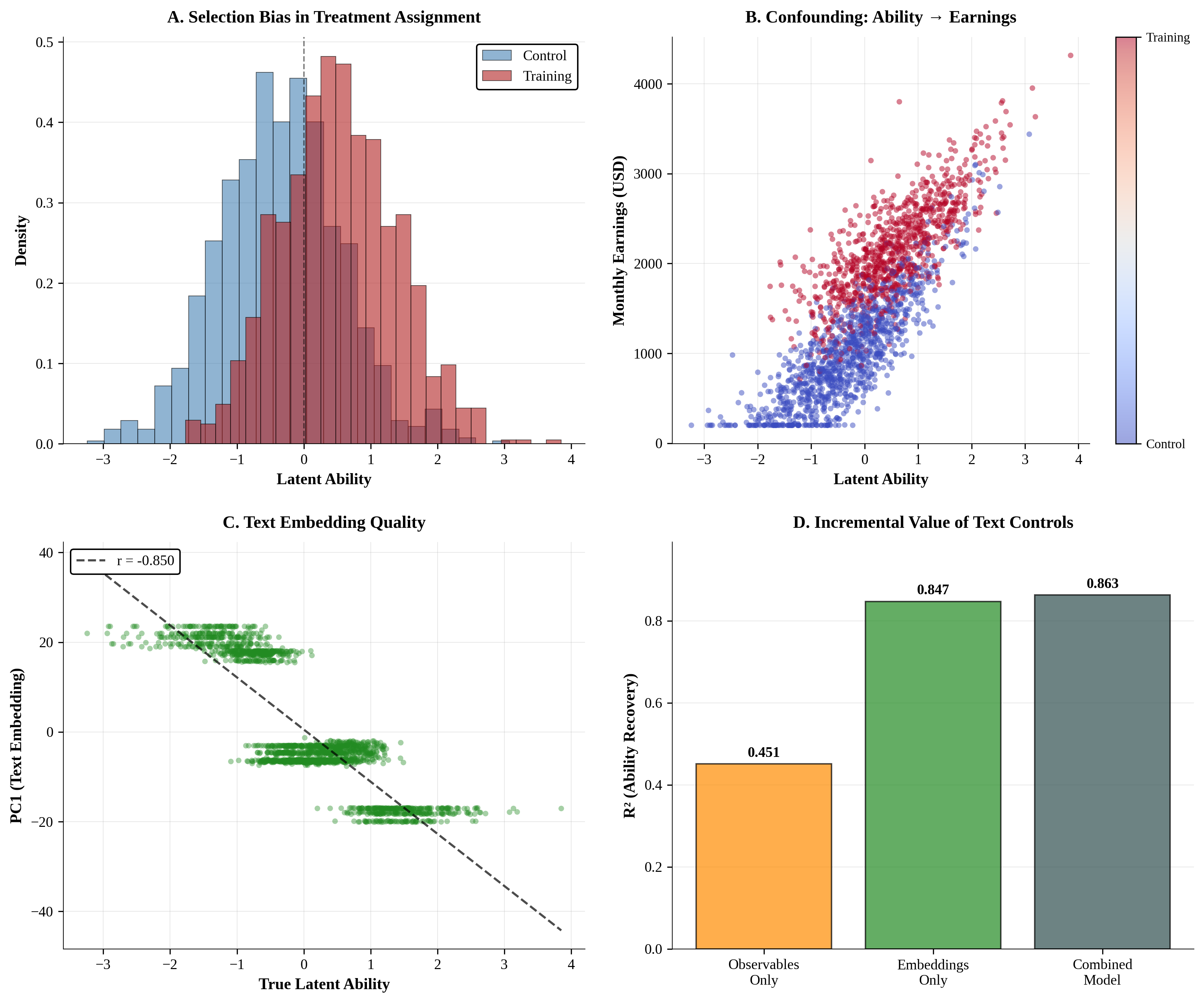
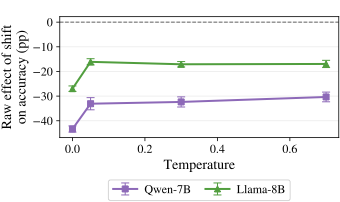
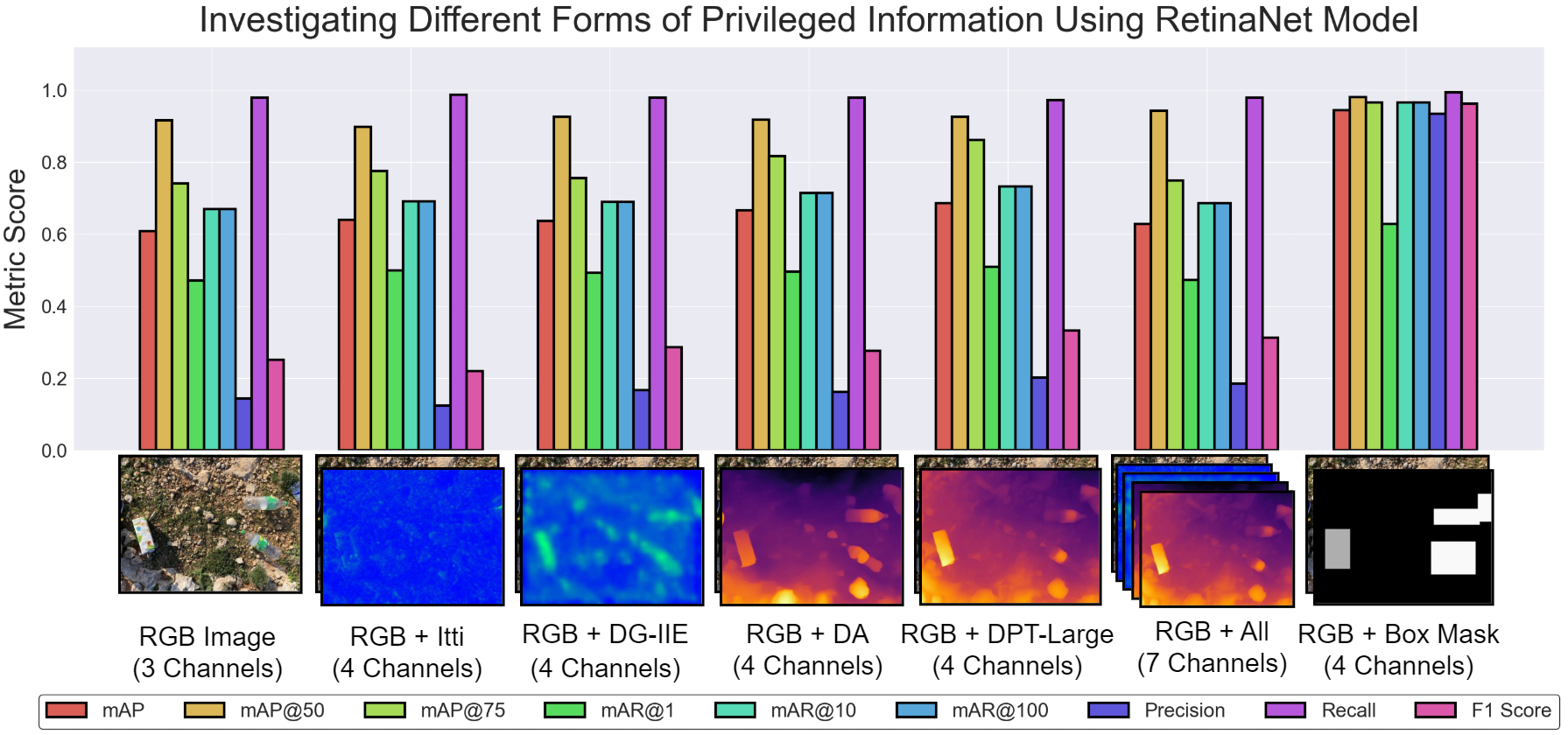
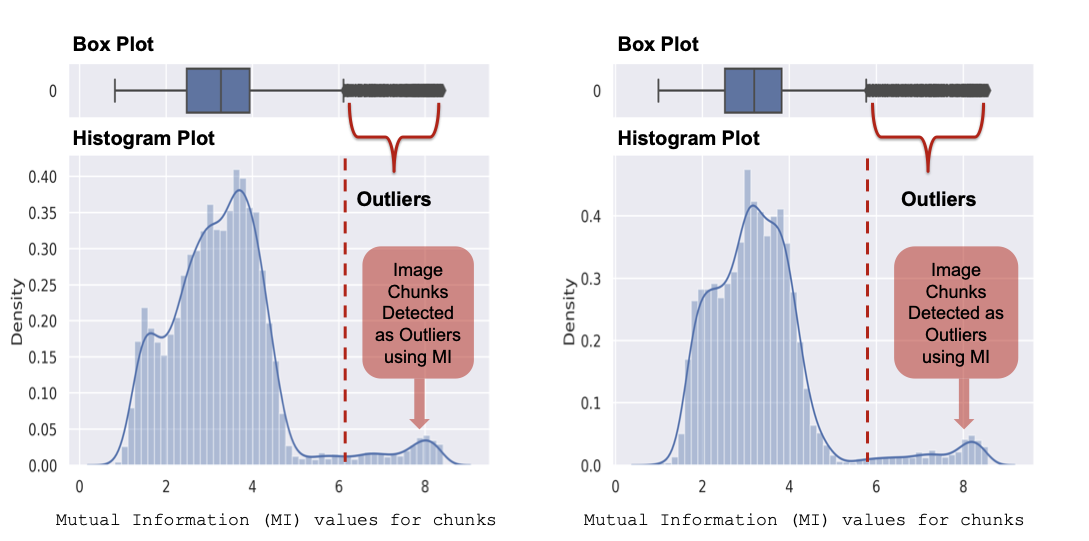
제너레이티브 AI의 패러독스 진실의쇠퇴와 정보검증의 부식
생성 인공지능(GenAI)은 이제 텍스트, 이미지, 오디오, 비디오를 대규모로 그리고 거의 무시할 수 있는 추가비용으로 인식상 납득 가능한 결과물을 생산하고 있습니다. 공론장에서는 이러한 관련 피해를 주로 딥페이크 나 증언 및 사기의 점진적 확장을 통한 것으로 다루는 경우가 많으나, 이 관점은 더 넓은 사회기술 변화를 놓치고 있습니다 GenAI는 합성 현실을 가능하게 합니다; 내용, 정체성, 그리고 사회 상호작용이 공동으로 제조되고 상호 보완적인 일관되고 상호 작용 가능한 정보 환경입니다. 본 논문은 단지 고립된 합성 제품의 생산에 그치는 것이 아니라, 합성 콘텐츠, 합성 정체성, 그리고 합성 상호작용이 생성하기 쉬우며 심사가 어려워짐으로써 공유 지식 기반과 제도적 검증 실천이 점진적으로 훼손되는 것이 가장 중대한 위험이라는 입장을 주장합니다. 이 논문은 (i) 합성 현실을 층叠的堆栈(内容、身份、互动、机构),(ii) 扩展涵盖个人、经济、信息和社技风险的GenAI危害分类,(iii) 阐述由GenAI引入的定性转变(成本崩溃、吞吐量、定制化、微细分、出处缺口和信任侵蚀),以及(iv) 将近期风险实现(2023-2025年)综合成一个紧凑案例库,说明这些机制如何在欺诈、选举、骚扰、文件编制和供应链妥协中表现。然后我们提出了一种缓解堆栈,将来源基础设施、平台治理、机构工作流程重新设计以及公共复原力视为互补而非替代的,并概述了一个专注于衡量知识安全的研究议程。我们以生成式人工智能悖论结束:随着合成媒体变得无处不在,社会可能合理地完全忽视数字证据。 请允许我纠正并完成韩语翻译: (ii) 개인, 경제, 정보, 사회기술적 위험을 포괄하는 GenAI 해악 분류를 확장하고, (iii) 제네레이티브 AI가 도입한 정성적인 변화(비용 붕괴, 처리량, 맞춤화, 미세 세분화, 출처 격차, 신뢰 침식)를 설명하며, (iv) 사기, 선거, 괴롭힘, 문서 작성, 공급망 해킹에서 이러한 메커니즘이 어떻게 나타나는지 보여주는 2023-2025년의 최근 위험 실현을 간결한 사례 은행으로 종합합니다. 그런 다음 우리 주장은 입증 인프라, 플랫폼 통치력, 기관 워크플로 리디자인, 공공 복원력을 대체가 아닌 보완적인 것으로 취급하는 완화 스택을 제안하고, 지식 안전성 측정에 초점을 맞춘 연구 계획을 개략합니다. 우리는 생성 AI 패러독스를 결론으로 내립니다 합성 미디어가 보편화됨에 따라 사회는 합리적으로 디지털 증거를 완전히 할인할 수 있습니다.