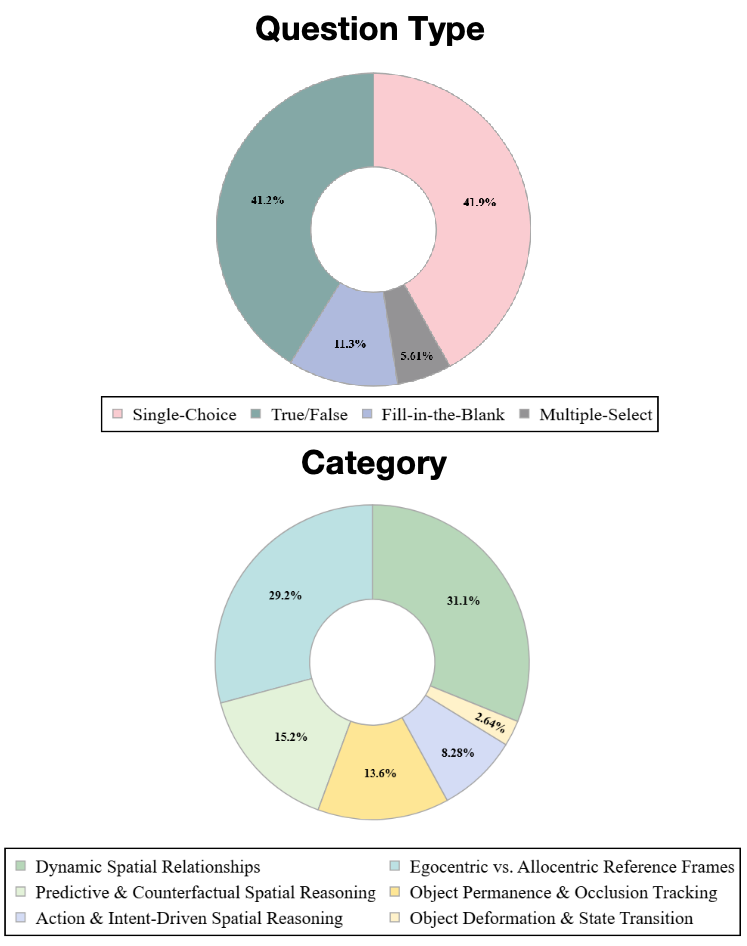
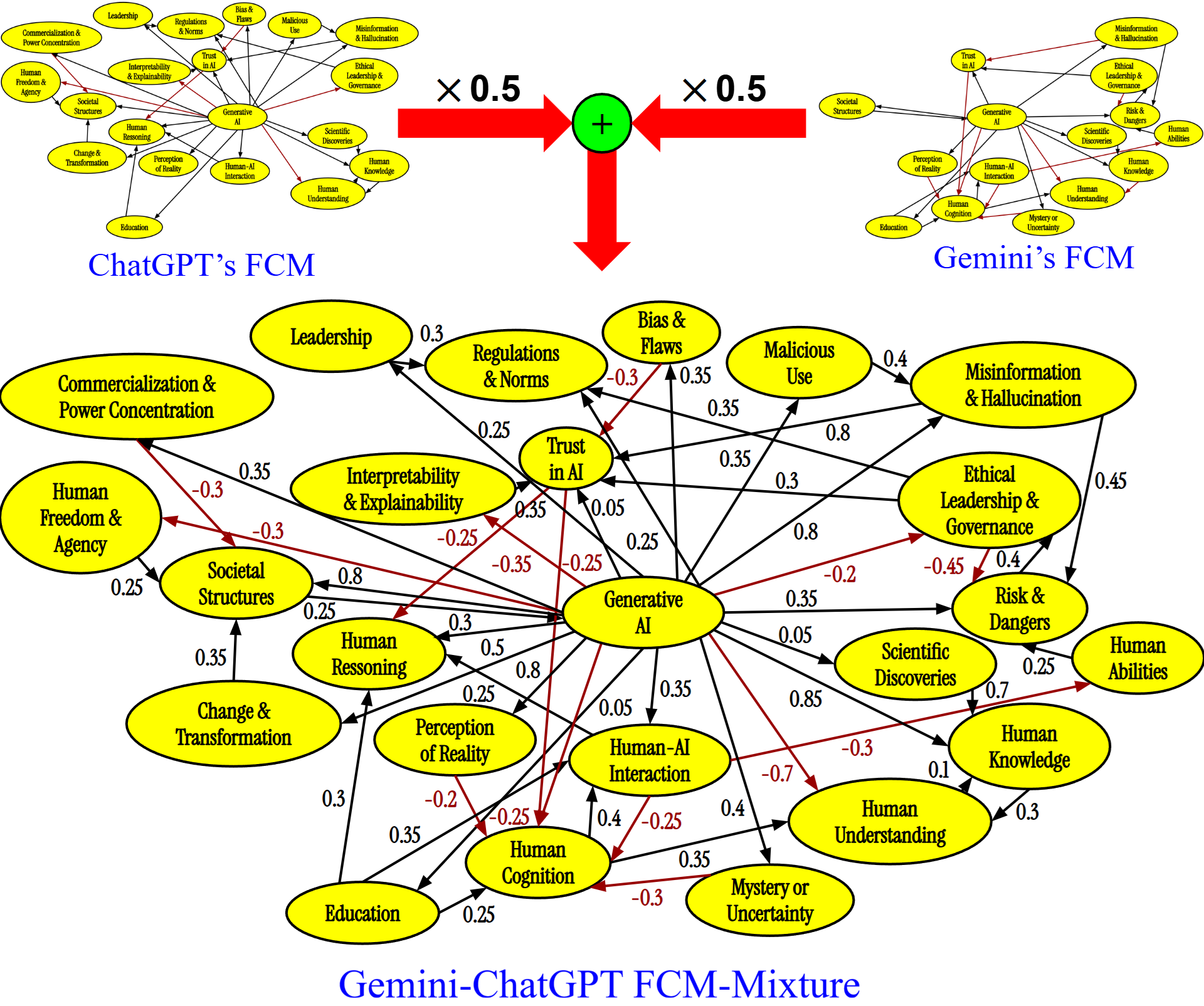
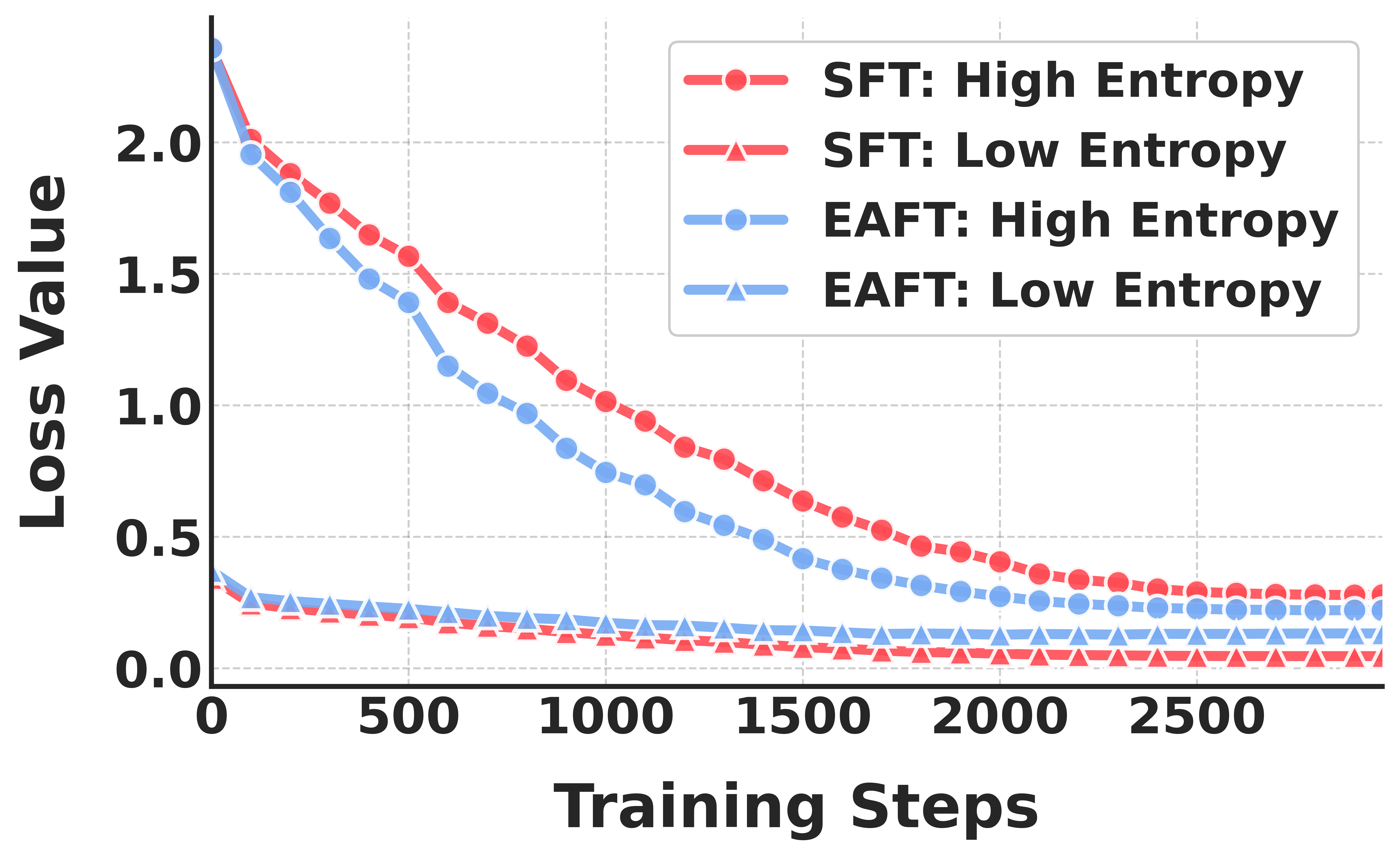
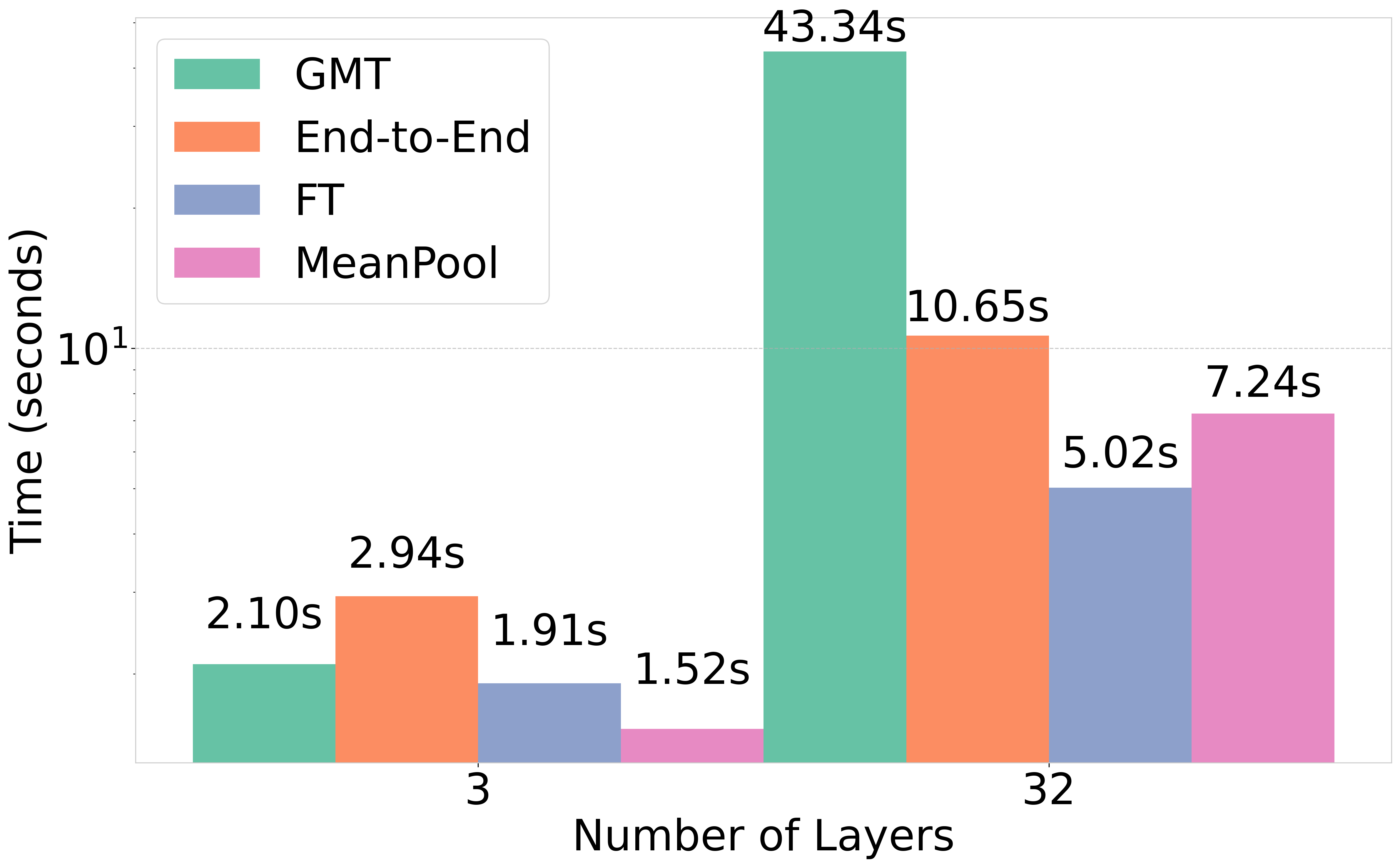
유니크롭 확장 가능한 작물 수확량 예측을 위한 다소스 데이터 공학 파이프라인
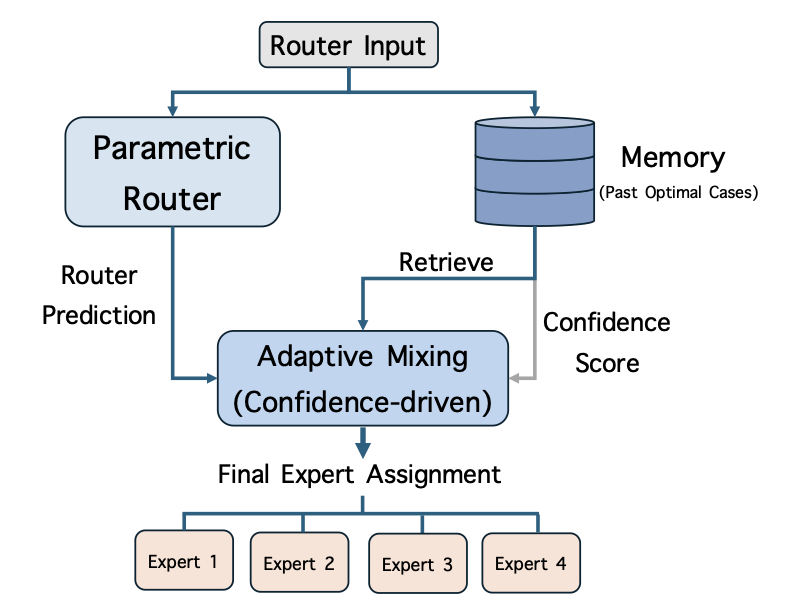
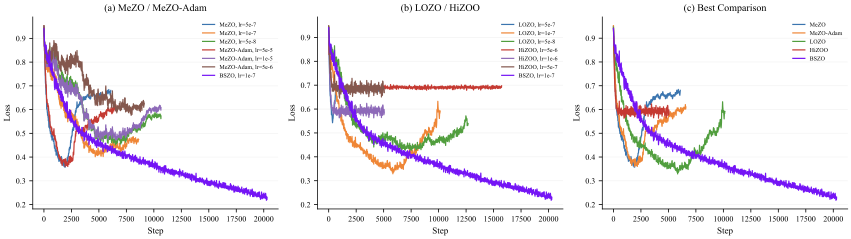
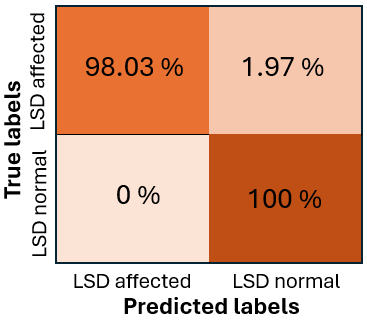
농작물 수확량 예측은 전 세계 식량 안보와 경제적 안정에 중추적인 역할을 하지만, 기후 변화, 인구 증가 및 불규칙한 날씨 패턴으로 인해 점점 더 큰 압력을 받고 있습니다. 정확한 농작물 수확량 예측은 정부 정책, 공급망 안정화, 농업 기업 물류 그리고 농민들의 관수, 비료 사용 및 수확 일정에 대한 결정을 위한 정보를 제공하는데 필수적입니다. 이러한 필요성은 한 지역의 생산 충격이 국제 시장 전체로 급속히 확산되는 경향으로 인해 더욱 절실해졌습니다. 지구관측(EO), 농기상학 및 기계 학습(ML) 분야에서 이루어진 주요 진전은 데이터 주도의 농업 예측 가능성을 크게 확장시켰습니다. 개방형 EO 프로그램인 코페르니쿠스 센티넬 임무는 높은 공간적 및 시간적 해상도로 광학, 레이더 및 대기 측정을 제공하며 작물 상태를 상세하게 모니터링할 수 있도록 합니다. MODIS의 장기간 식생 지수는 큰 지역에서 식물학적 분석을 가능하게 하며, ERA5-Land와 NASA POWER 등 기후 데이터셋은 온도, 강수량, 복사량, 습도 및 바람과 같은 농업 생산성의 주요 촉진 요인에 대한 전 세계적으로 일관된 정보를 제공합니다. 또한, SoilGrids와 SRTM의 보조 환경 데이터셋은 토양 구조, 탄소 함량, pH, 고도, 경사 및 미기후적 영향을 설명합니다. 그러나 이러한 진전에도 불구하고 농작물 수확량 예측 모델의 실용적인 개발은 지속적으로 데이터 공학적 병목 현상에 제한받고 있습니다. 대부분의 연구는 특정 작물, 지역 또는 시간대를 대상으로 맞춤형 파이프라인을 구축하는데, 이 과정에서 다양한 데이터셋을 통합하고 공간 및 시간 해상도를 조화시키기 위한 수작업이 많이 필요합니다. 심지어 최신 다중 모드의 심층 학습 접근 방식조차 복잡한, 수작업이 필요한 전처리 워크플로우에 의존하고 있습니다. 이러한 문제를 해결하기 위해 **UniCrop**을 소개합니다. UniCrop는 농작물 수확량 예측을 위한 다중 출처 환경 데이터의 획득, 조화 및 변환을 자동화하는 보편적이고 구성 설정에 따른 데이터 파이프라인입니다. UniCrop은 필요한 변수 지정과 구현을 분리하여 사용자가 단순한 구성 파일을 수정함으로써 새로운 작물이나 지역에 파이프라인을 적응시킬 수 있도록 합니다.