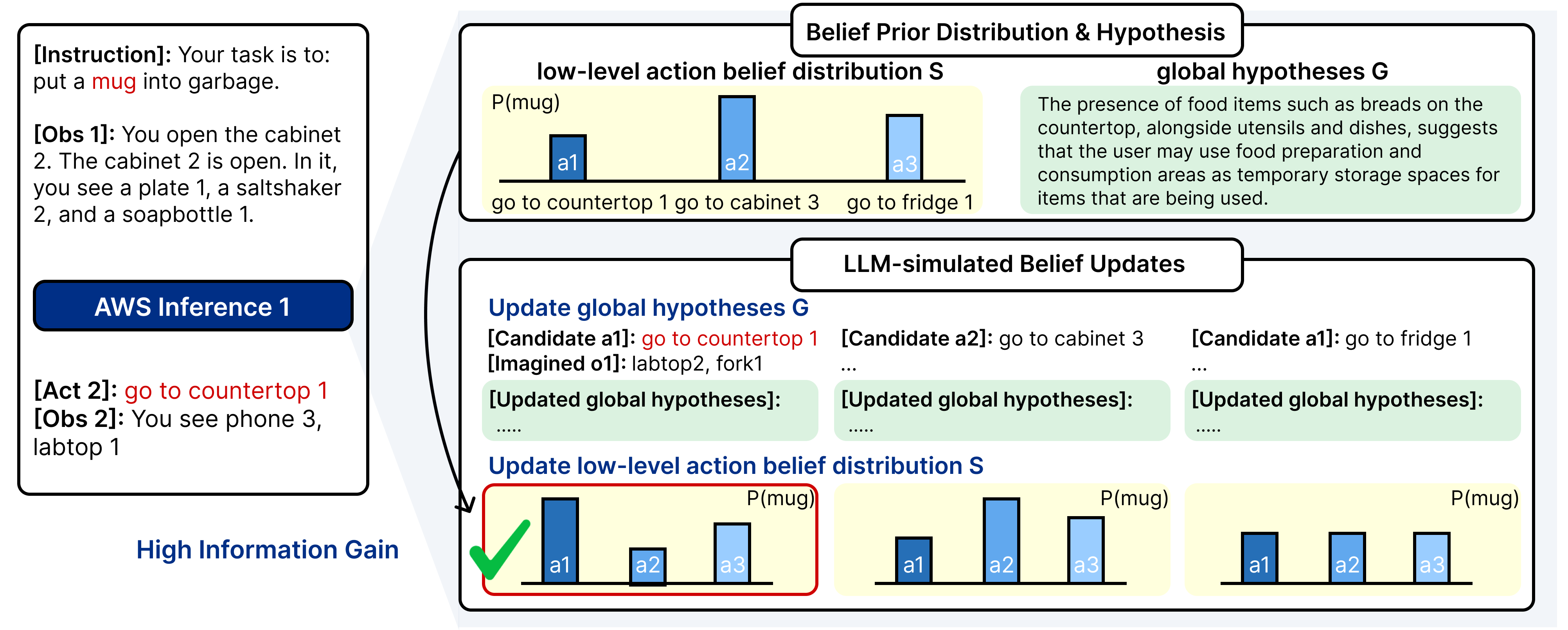
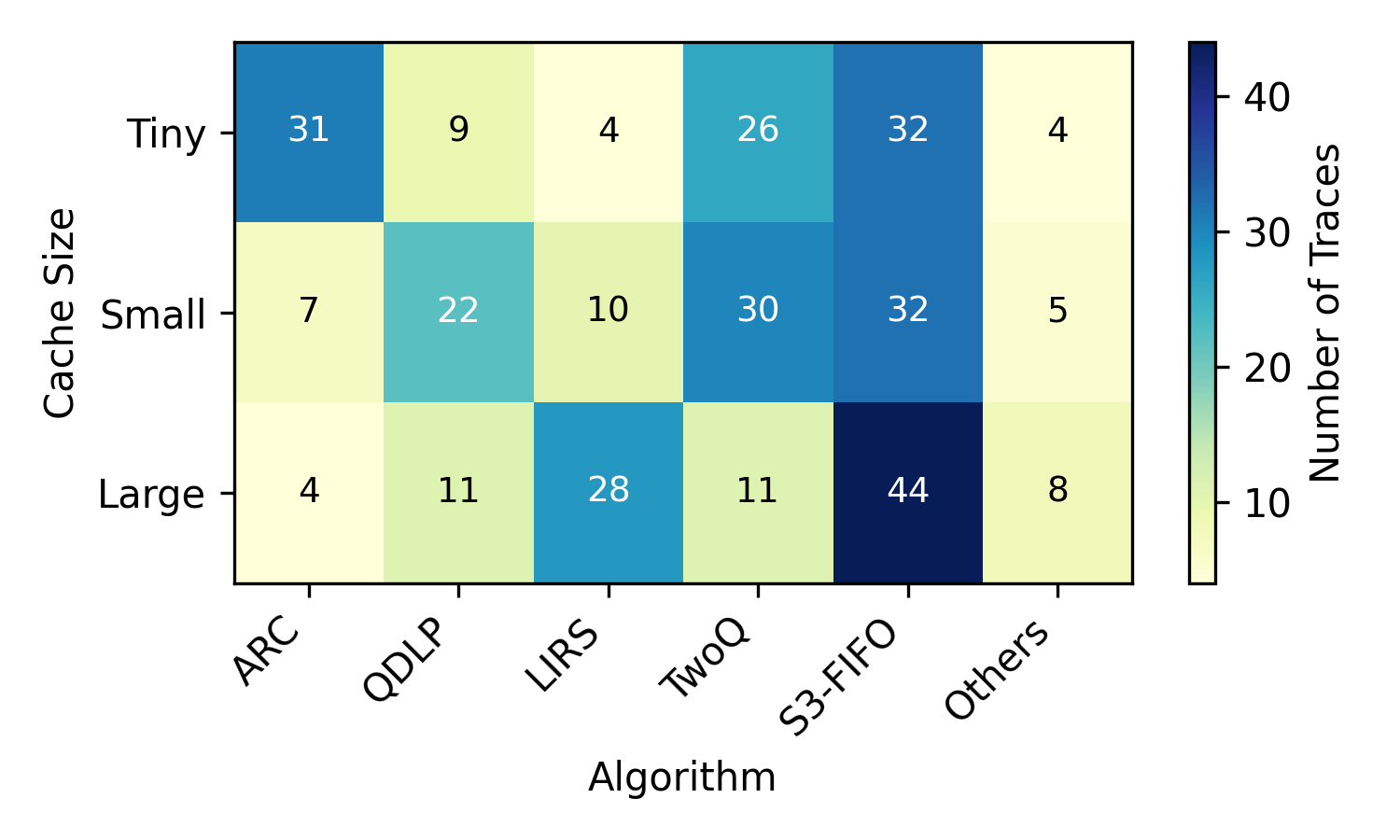
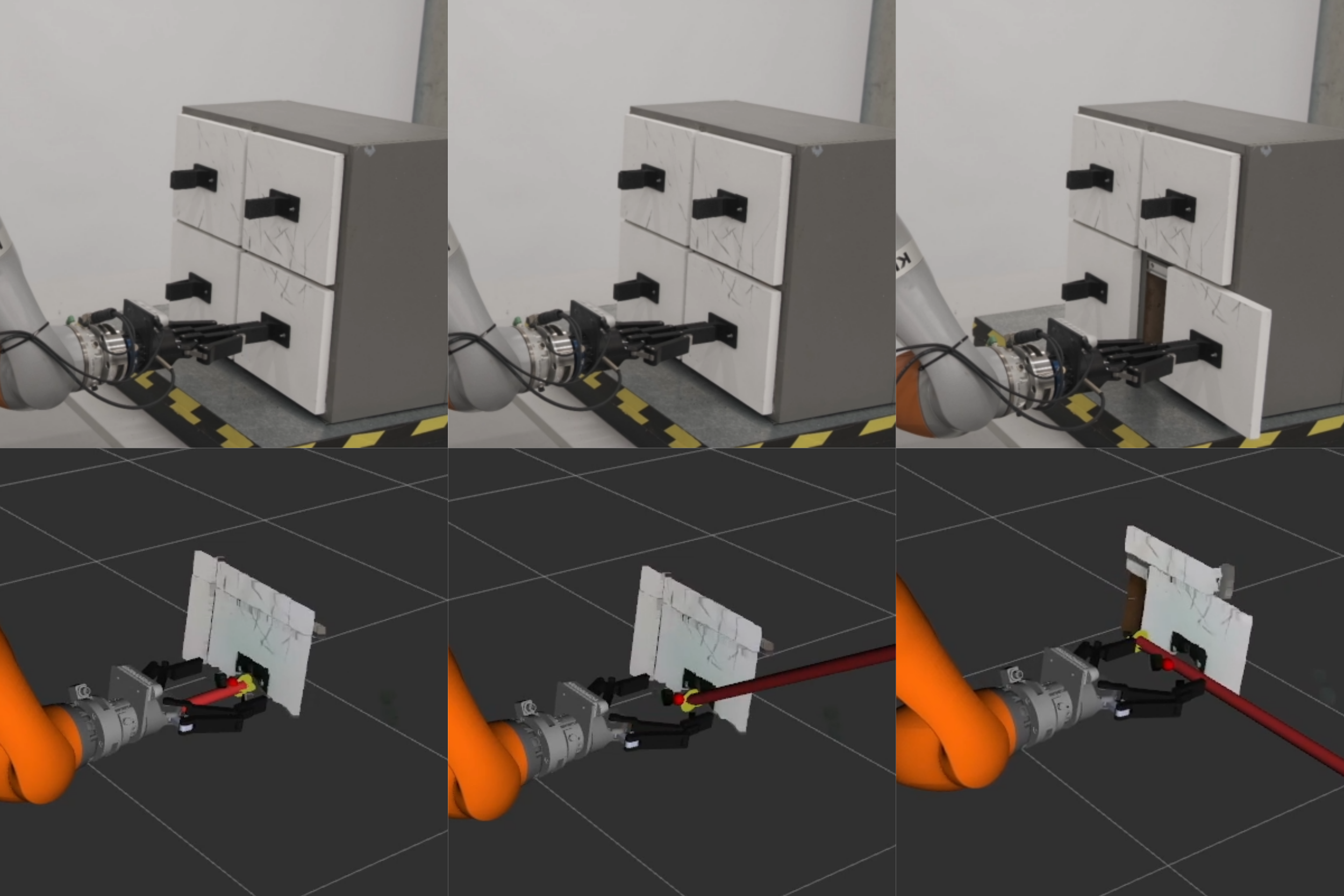
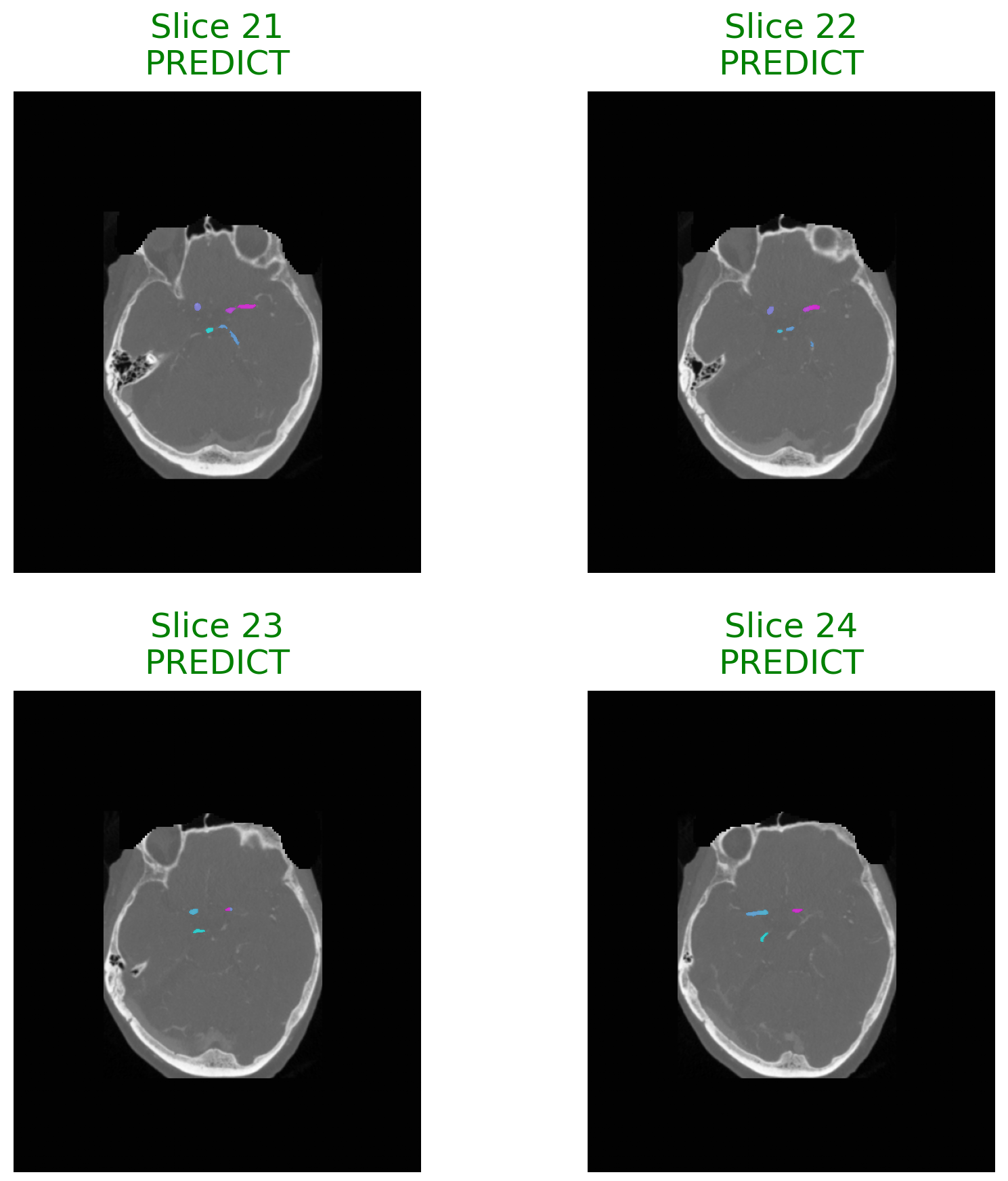
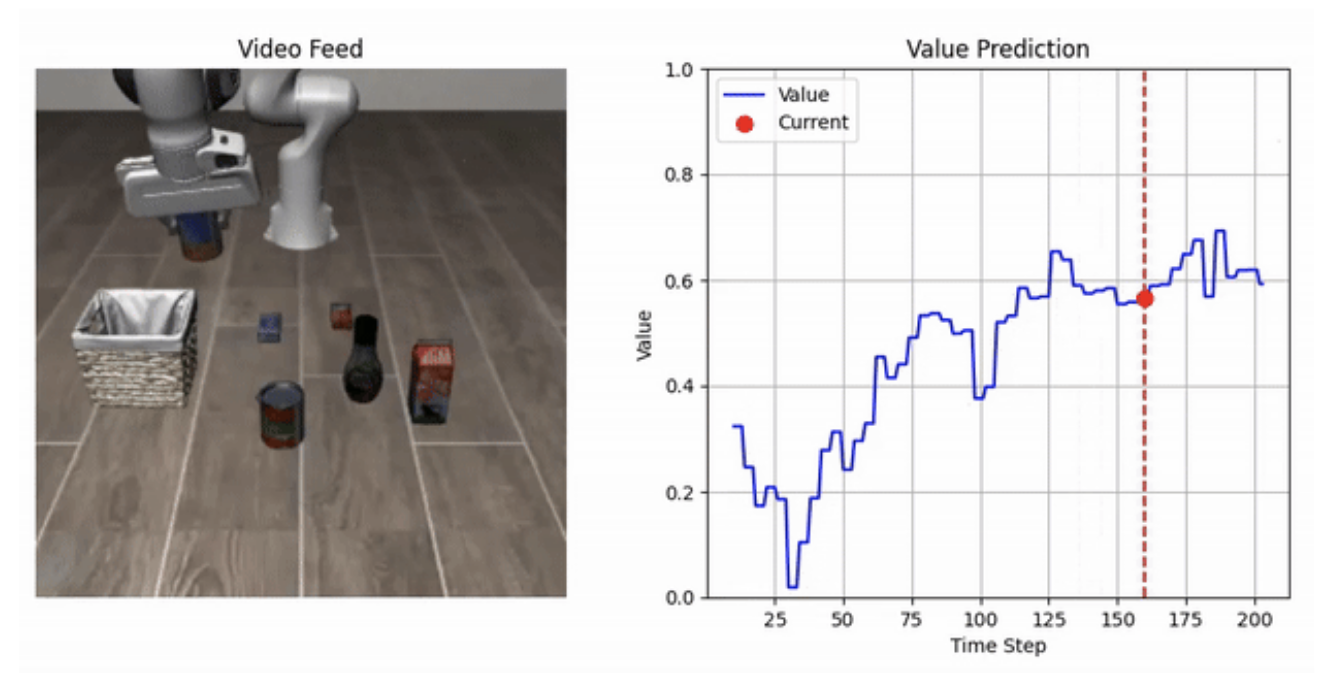
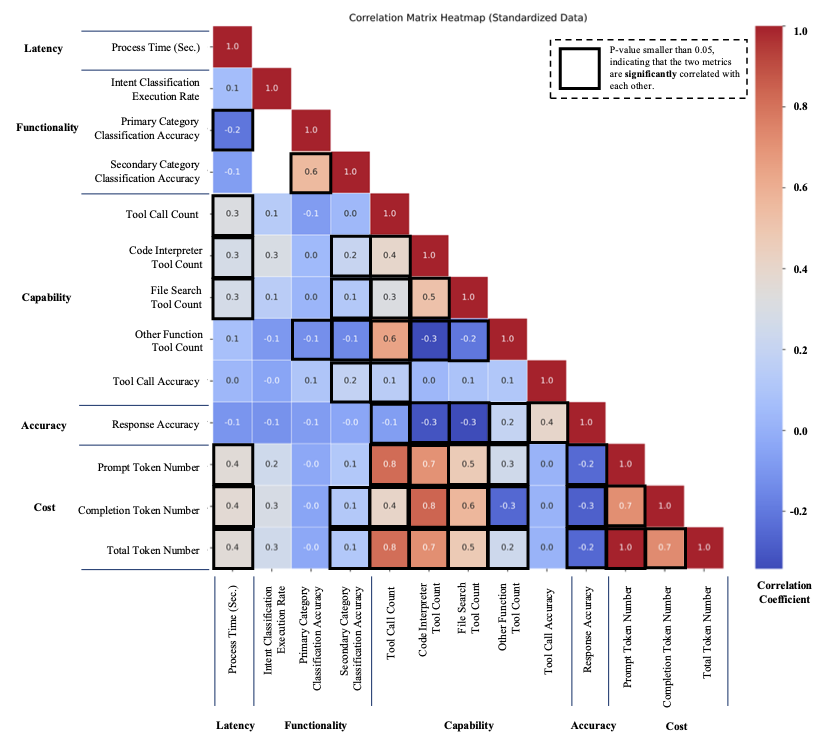
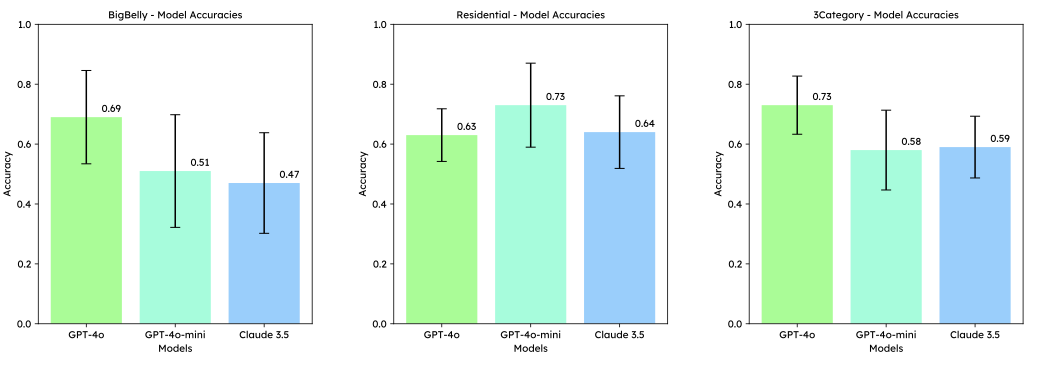
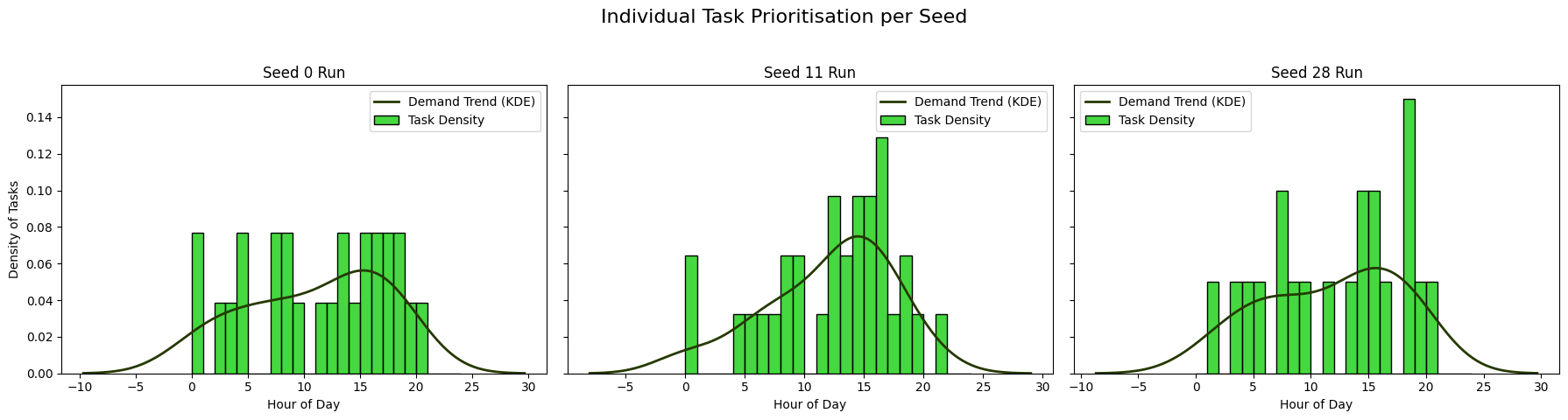
생명체의 자가회복, 분산계산에 새 바람
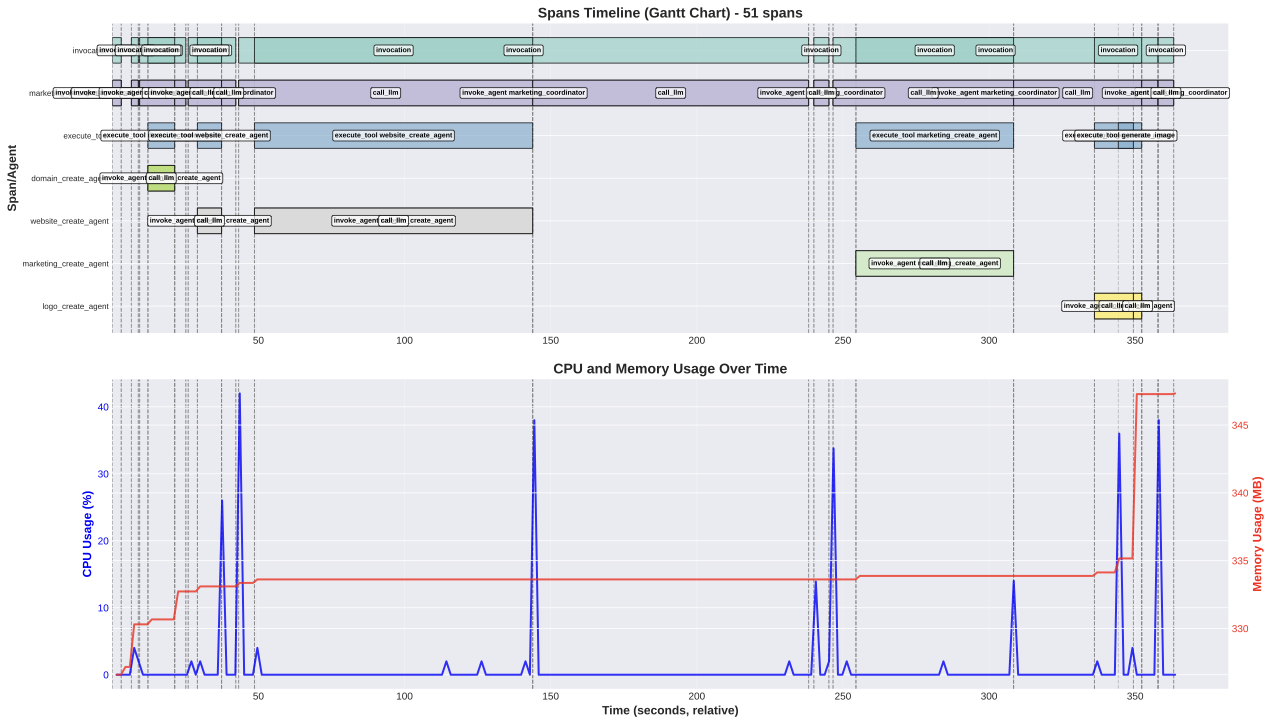
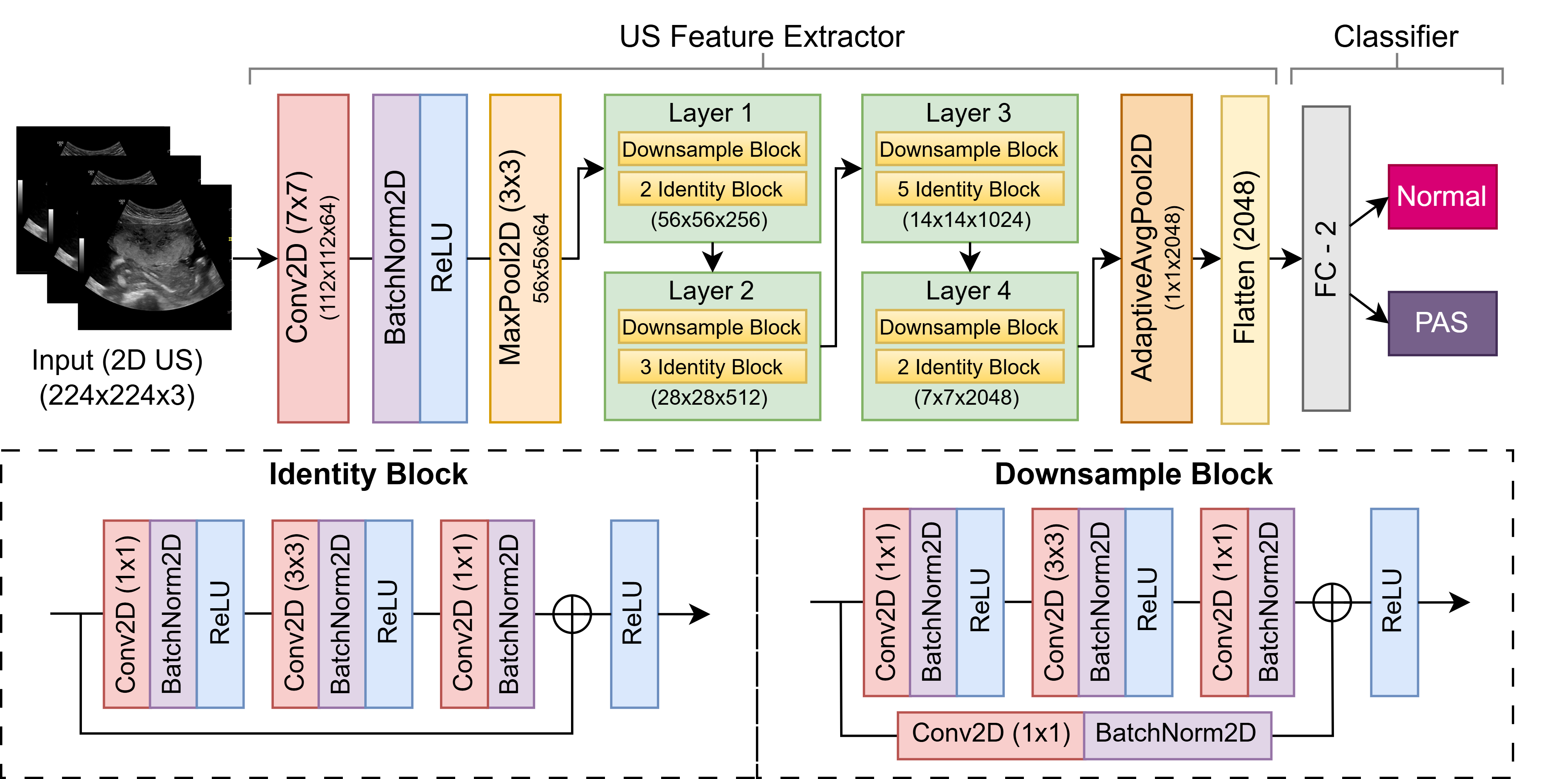
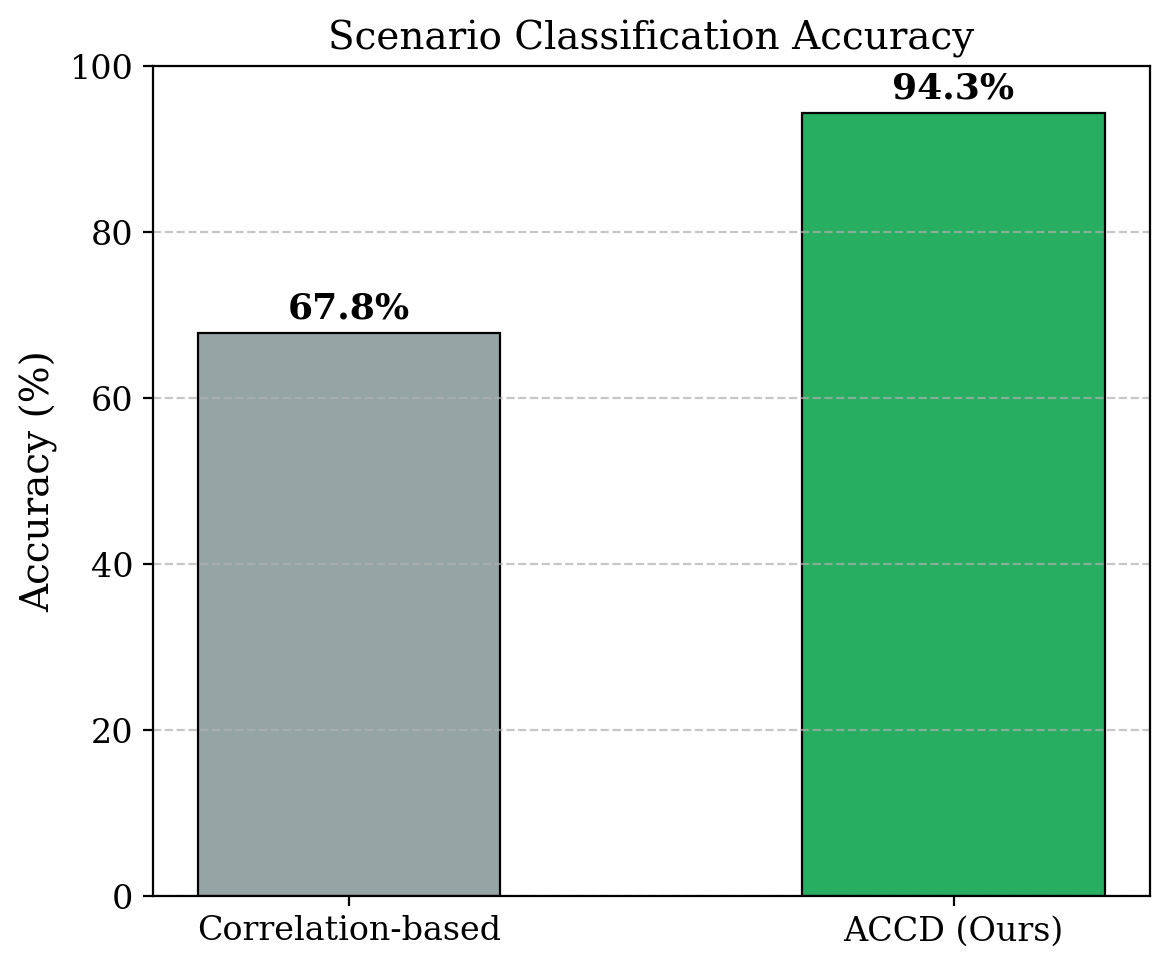
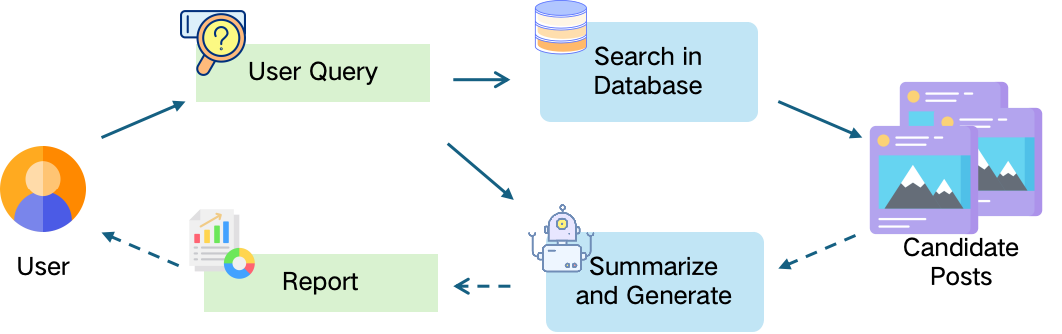
인간 생물학적 시스템은 뛰어난 유연성을 통해 생명을 유지하며, 손상 감지와 표적화된 반응 조정, 그리고 자체 치유를 통한 기능 복원을 계속하고 있습니다. 이러한 능력에 영감 받아 이 논문에서는 분산 컴퓨팅 연속 체계(DCCS)에서 탄력성을 달성하기 위해 생물학적으로 모티브화된 자가치유 프레임워크인 ReCiSt를 소개합니다. 현대의 DCCS는 리소스 제약이 있는 IoT 장비부터 고성능 클라우드 인프라에 이르기까지 다양한 컴퓨팅 자원을 통합하며, 내재한 복잡성, 모빌리티 및 동적인 운영 조건은 서비스 연속성을 방해하는 빈번한 결함에 노출됩니다. 이러한 과제들은 확장 가능하고 적응적이며 자기조절 탄력성을 달성하기 위한 전략의 필요성을 강조합니다. ReCiSt는 DCCS를 위해 생물학적 단계인 혈전, 염증, 증식, 재모델링을 각각 통제, 진단, 메타-인지, 지식 계층으로 재구성합니다. 이 네 개의 계층은 언어 모델(LM) 기반 에이전트를 통해 자동화된 결함 격리, 원인 진단, 적응적 복구 및 장기적인 지식 통합을 수행합니다. 이러한 에이전트는 다양한 로그를 해석하고 근본 원인을 추론하며 합리적 경로를 정교하게 만들고 최소한의 인간 개입으로 리소스를 재구성합니다. 제안된 ReCiSt 프레임워크는 여러 LM을 사용하여 공개 결함 데이터셋에서 평가되었으며 유사한 접근법이 드물기 때문에 기준 비교는 포함되지 않았습니다. 그럼에도 불구하고 다양한 LM 하에서 수행된 우리의 결과는 ReCiSt의 자가치유 능력이 최소 10%의 에이전트 CPU 사용률로 수십 초 내에 이루어진다는 것을 확인합니다. 또한 우리의 결과는 불확실성을 극복하기 위한 분석 깊이와 탄력성达成的微量代理数量进行了演示。