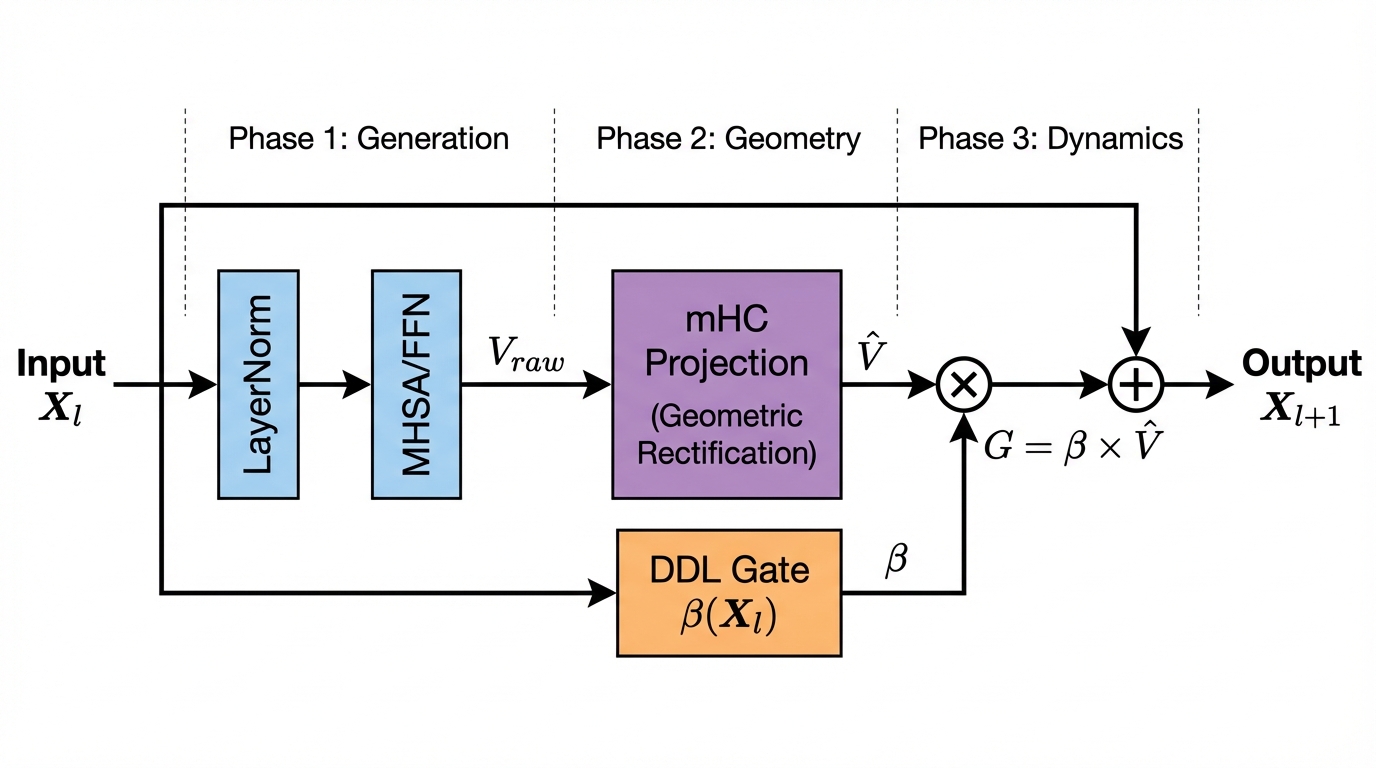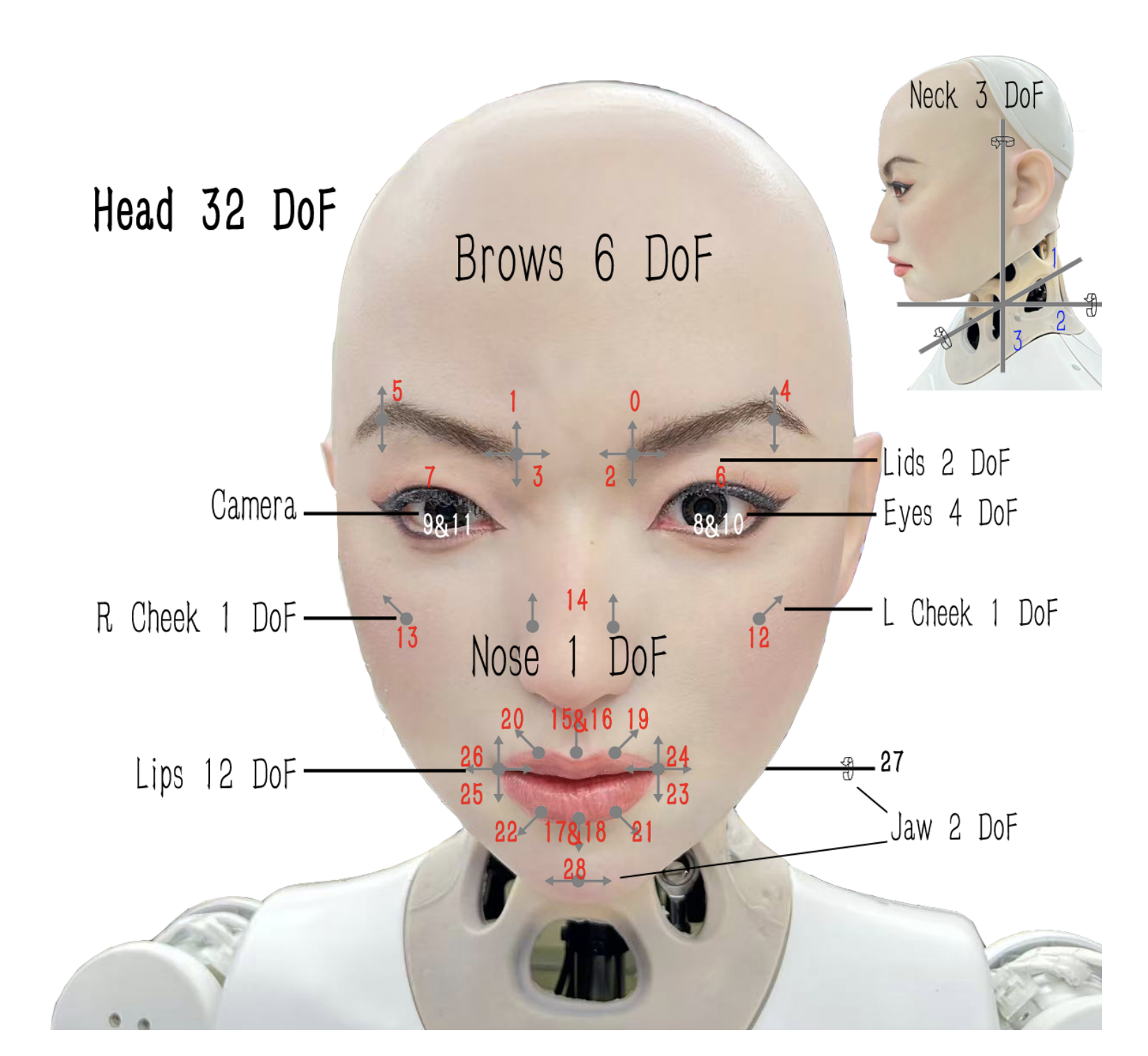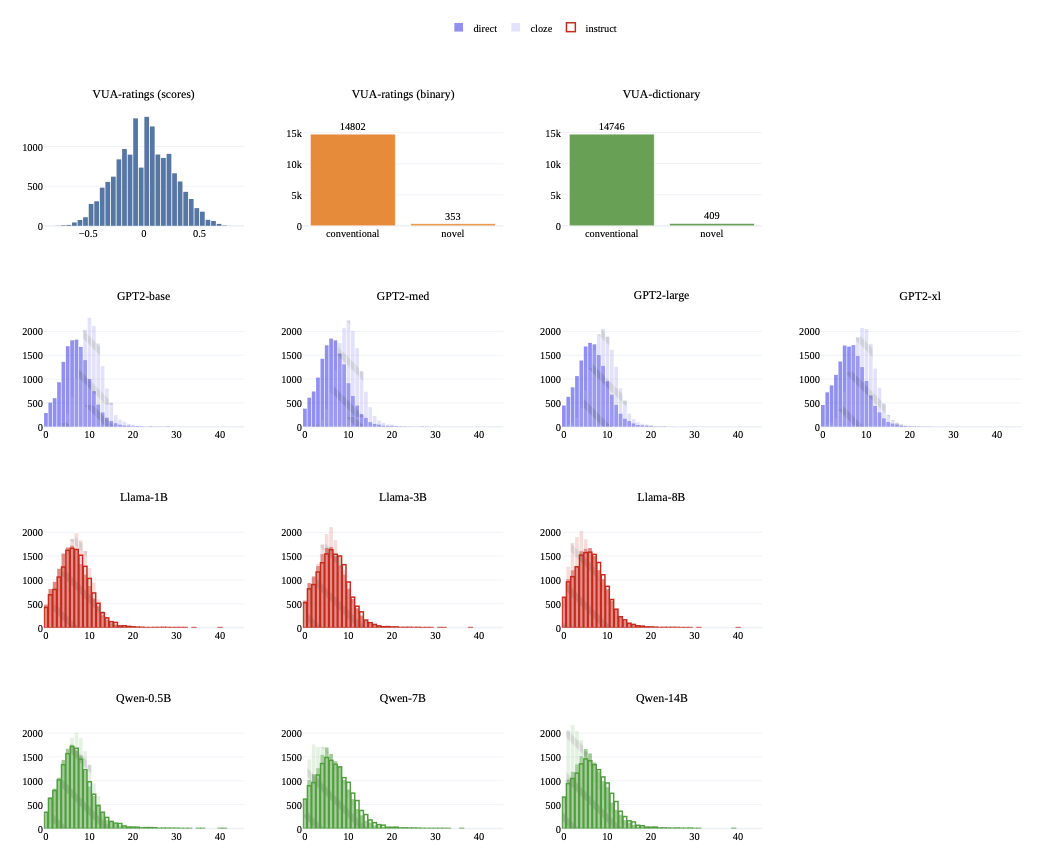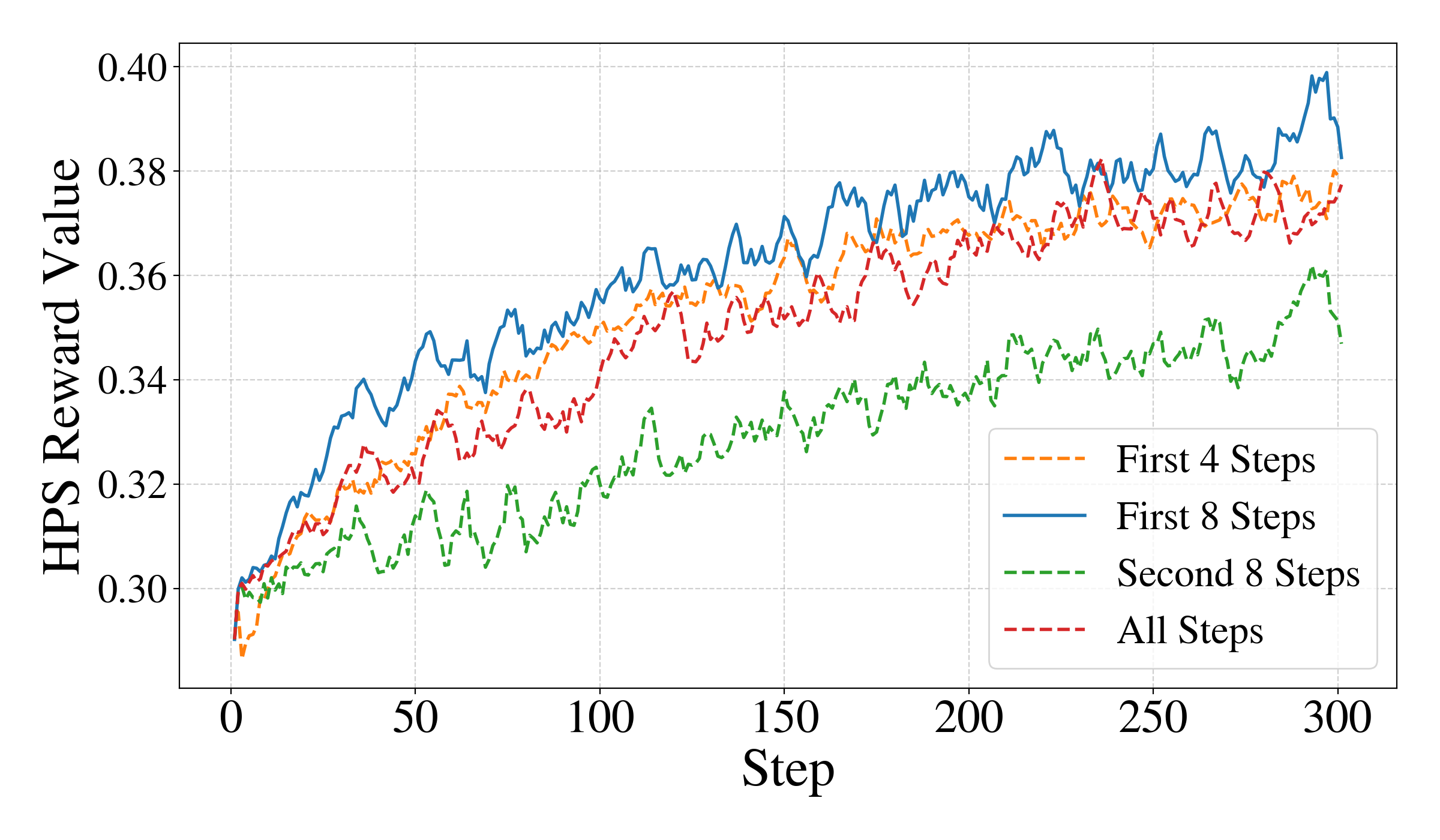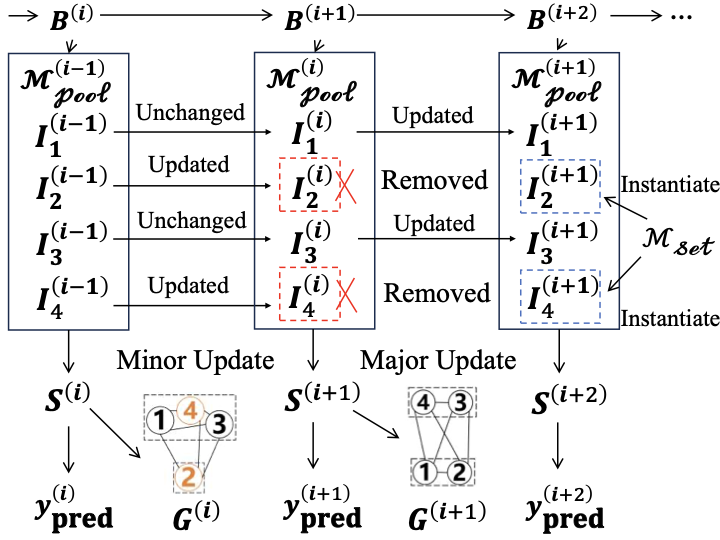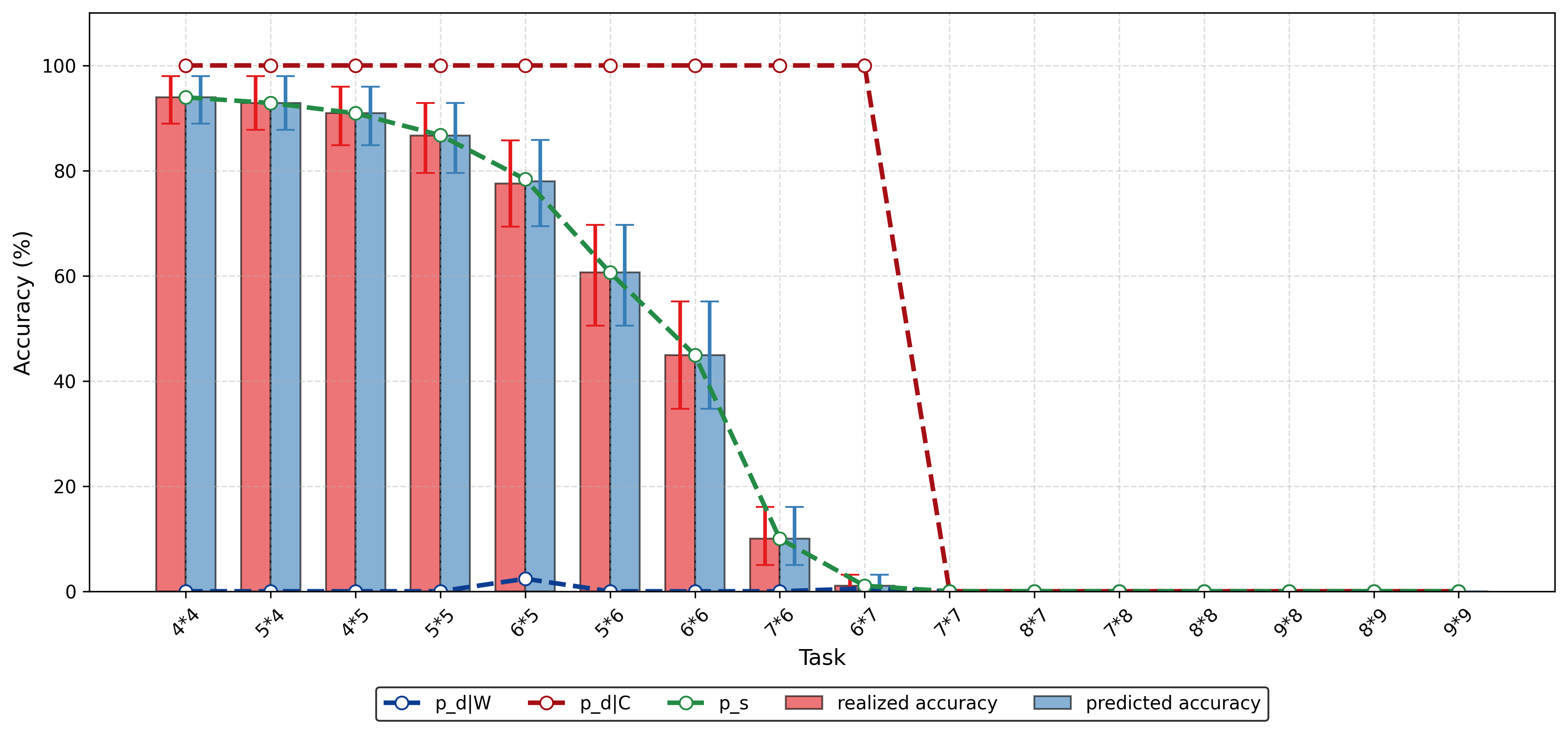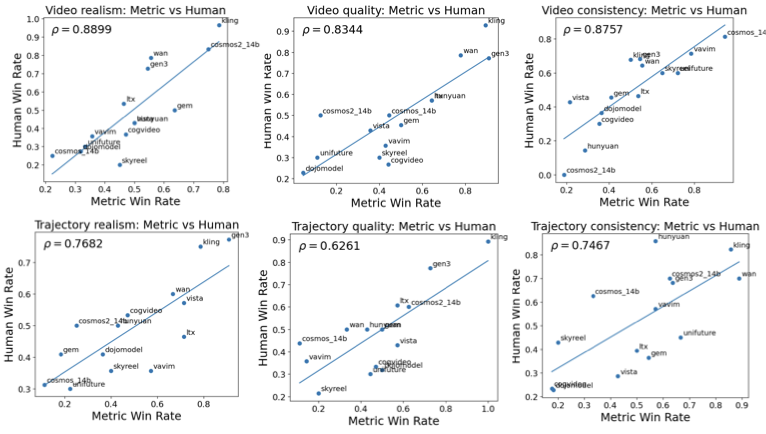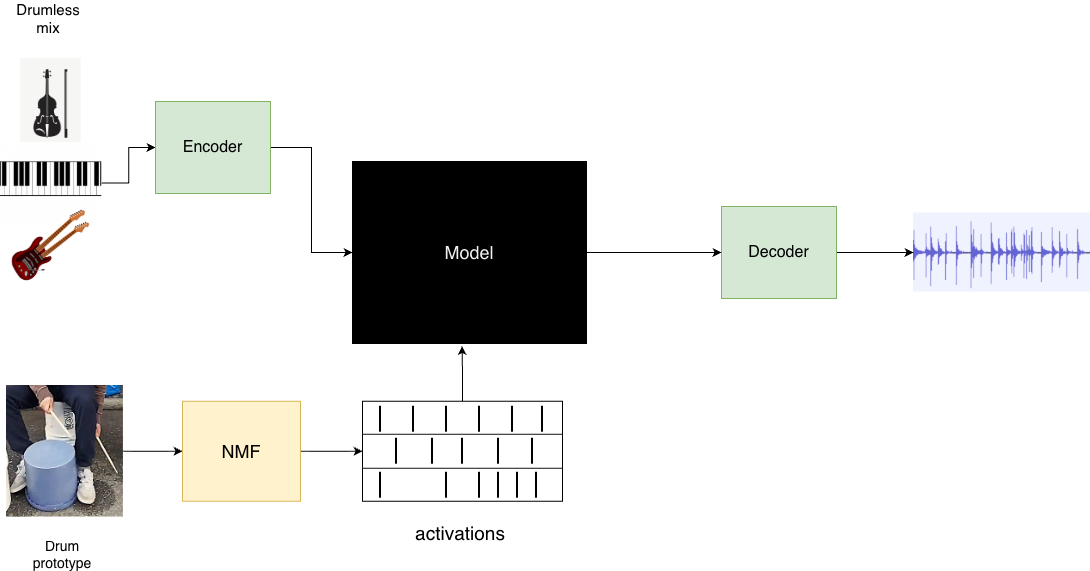
기계를 위한 코드, 인간만을 위한 것이 아니라 코드 헬스 메트릭으로 AI 친화성을 측정하기
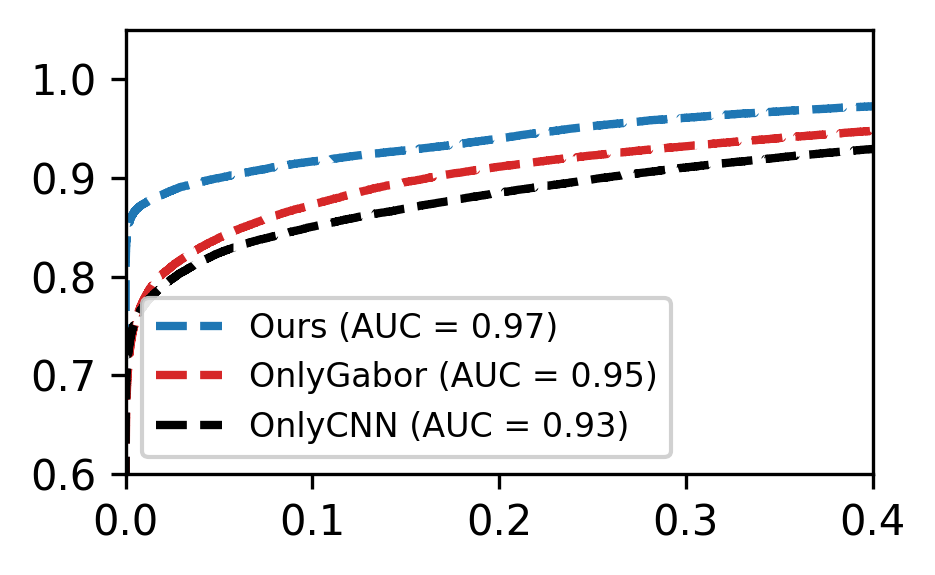
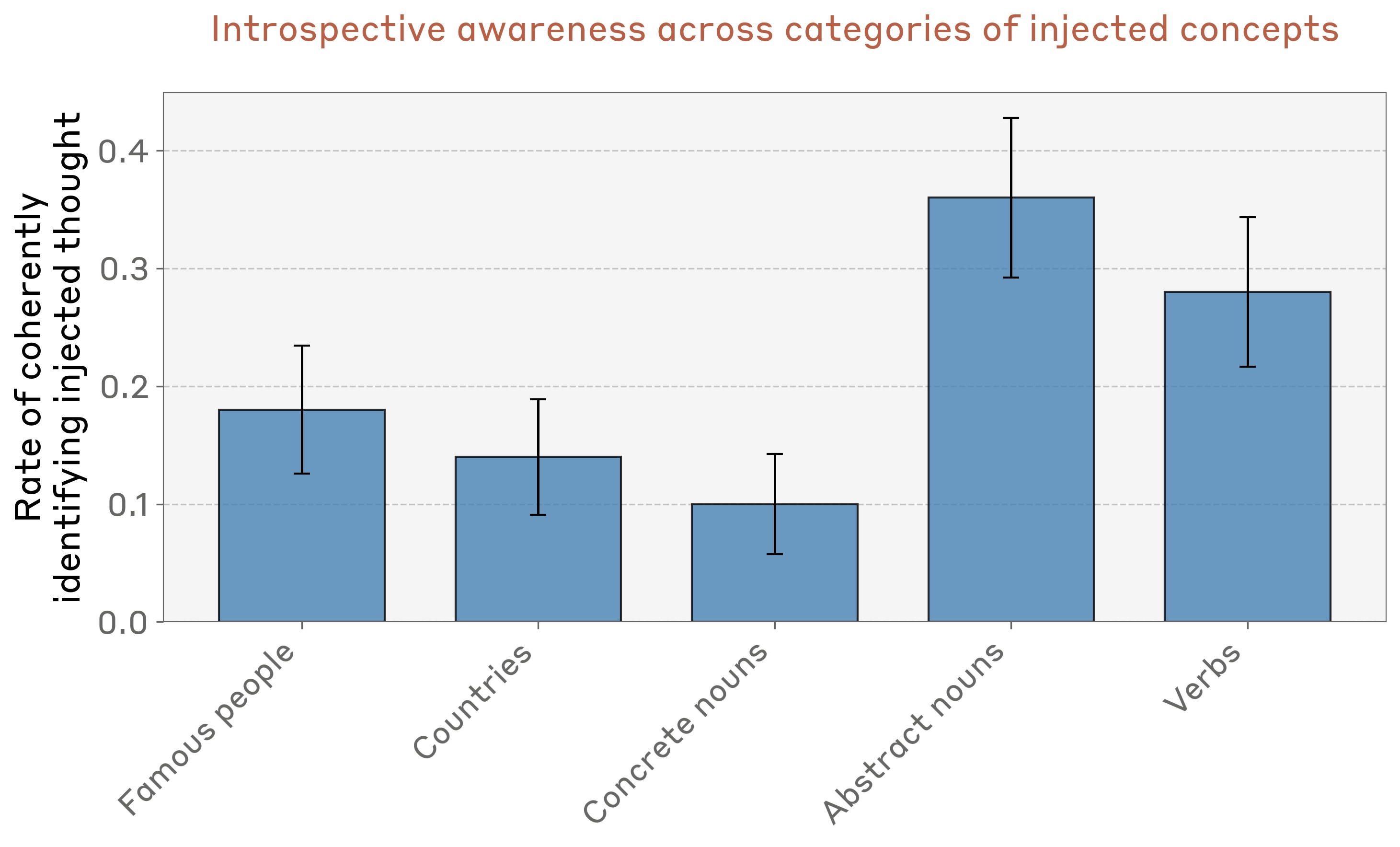
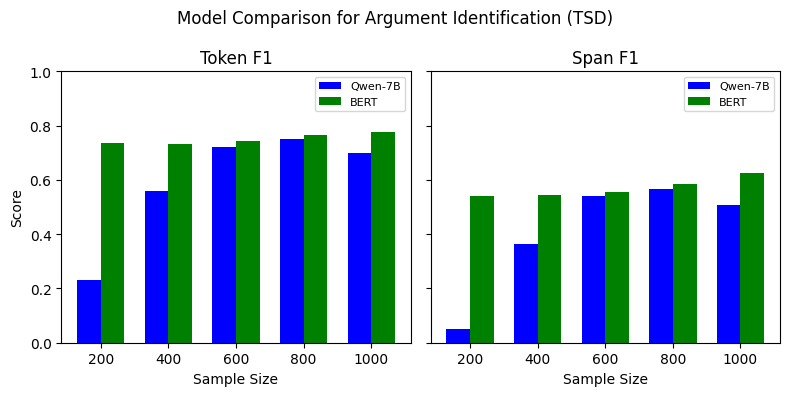
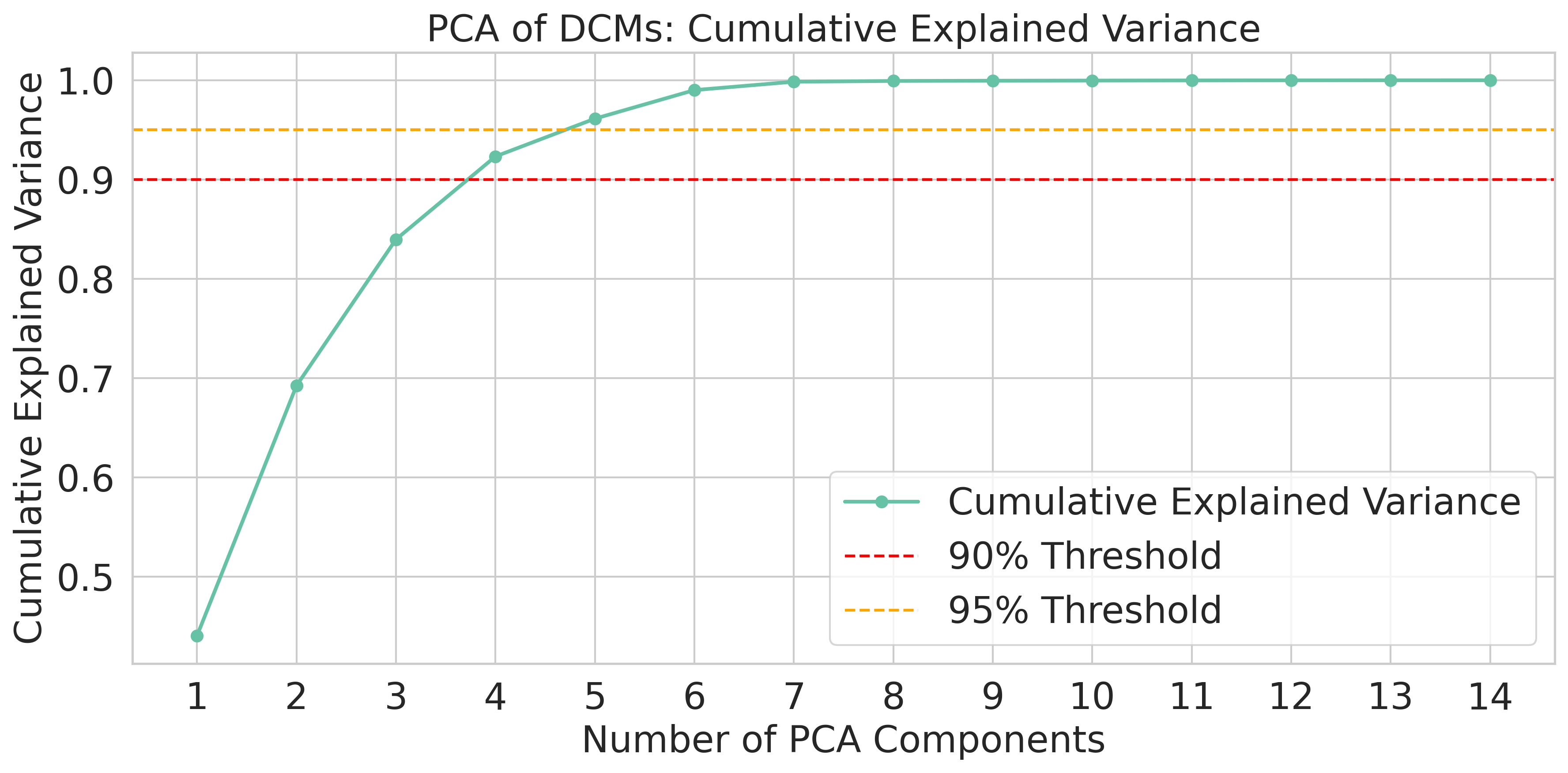
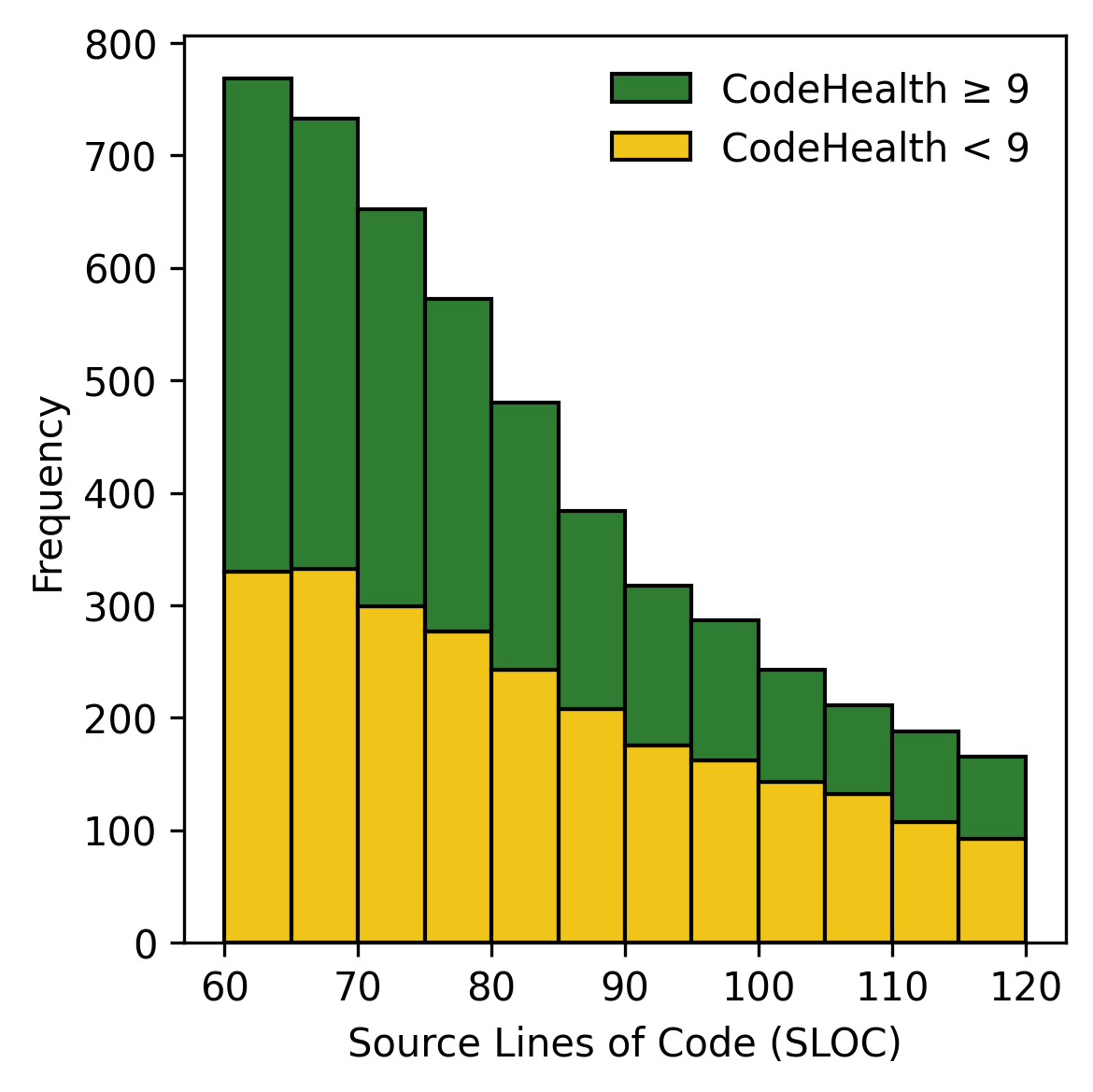
AI가 코드를 이해하고 개선하는 데 있어, 인간이 읽기 쉬운 코드는 어떻게 도움을 줄 수 있을까? 본 논문은 CodeHealth 지표를 사용하여 AI 친화적인 코드 디자인이 더 나은 결과를 내는지 분석한다. 또한, Perplexity와 Source Lines of Code(SLOC)와 비교해보며, 인간이 이해하기 쉬운 코드가 실제로 AI에게도 더 친근한지 확인한다.
paper
AI 요약