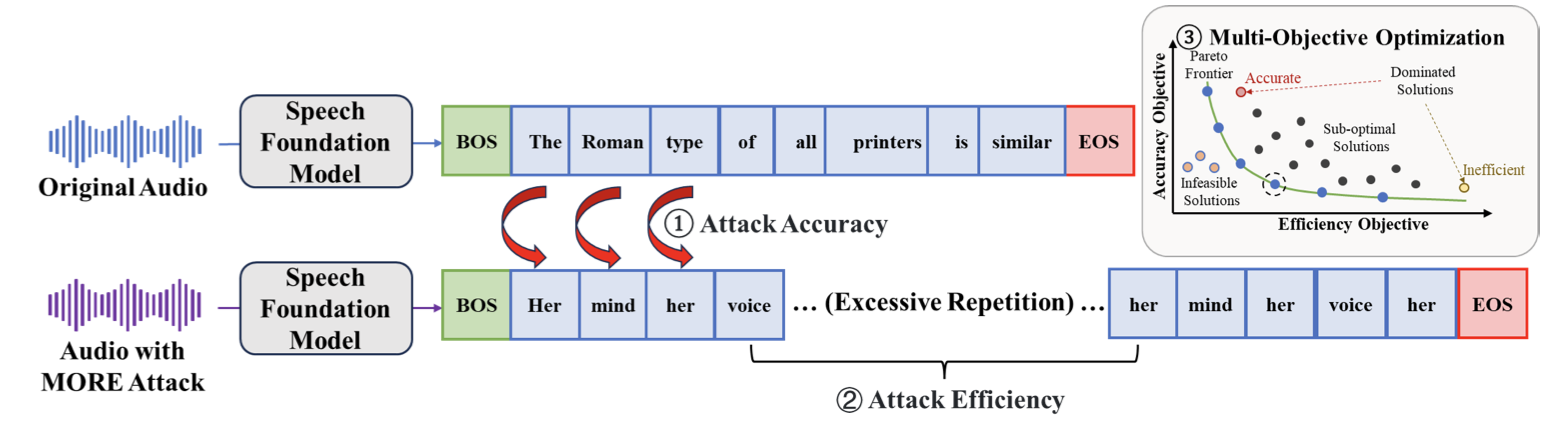
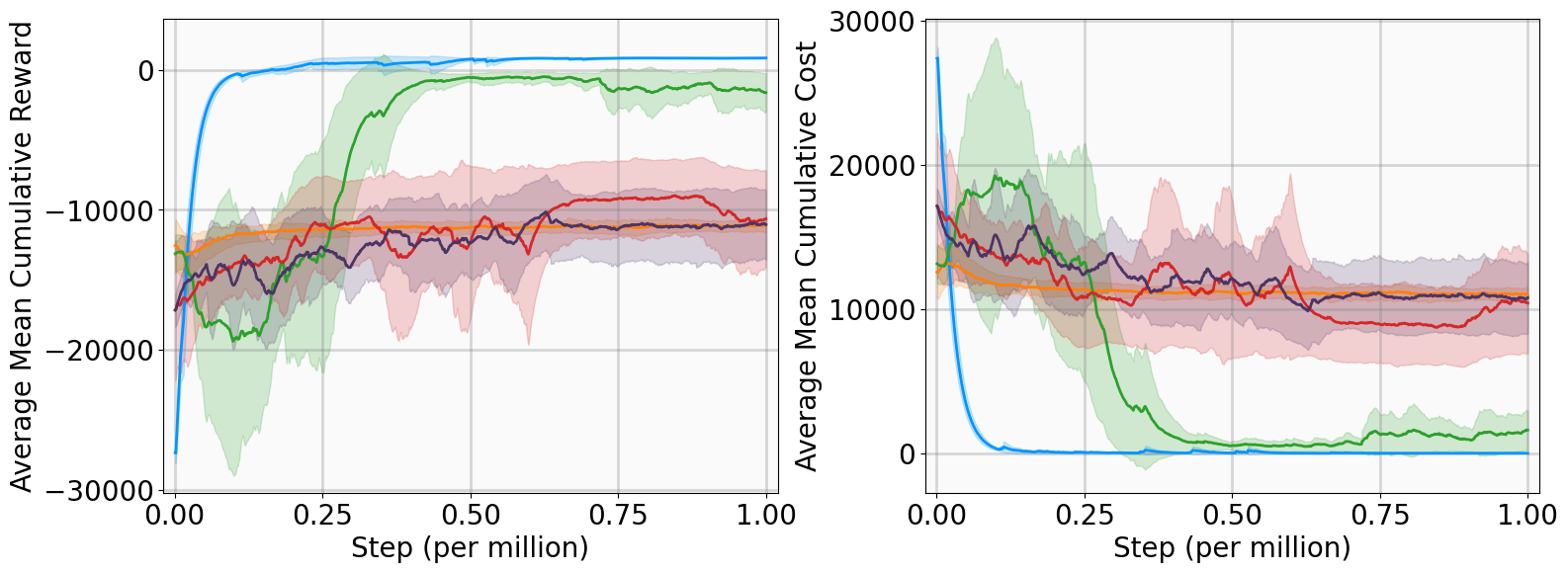
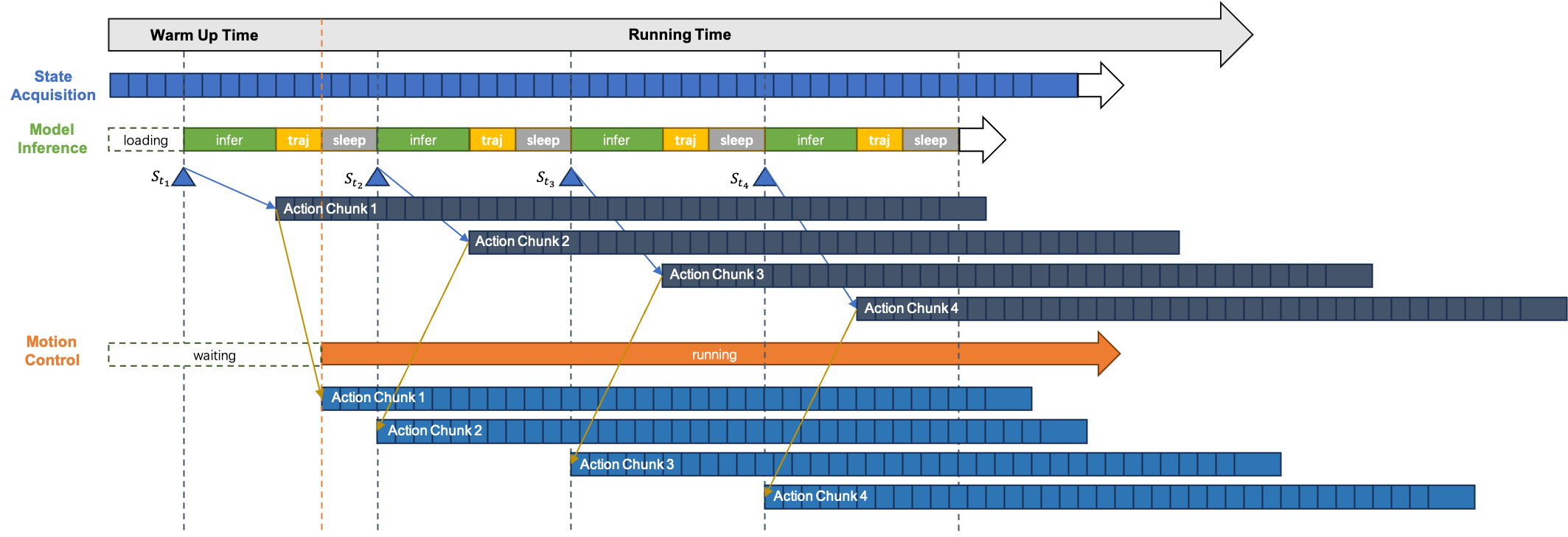
MergeRec Model Merging for Data-Isolated Cross-Domain Sequential Recommendation
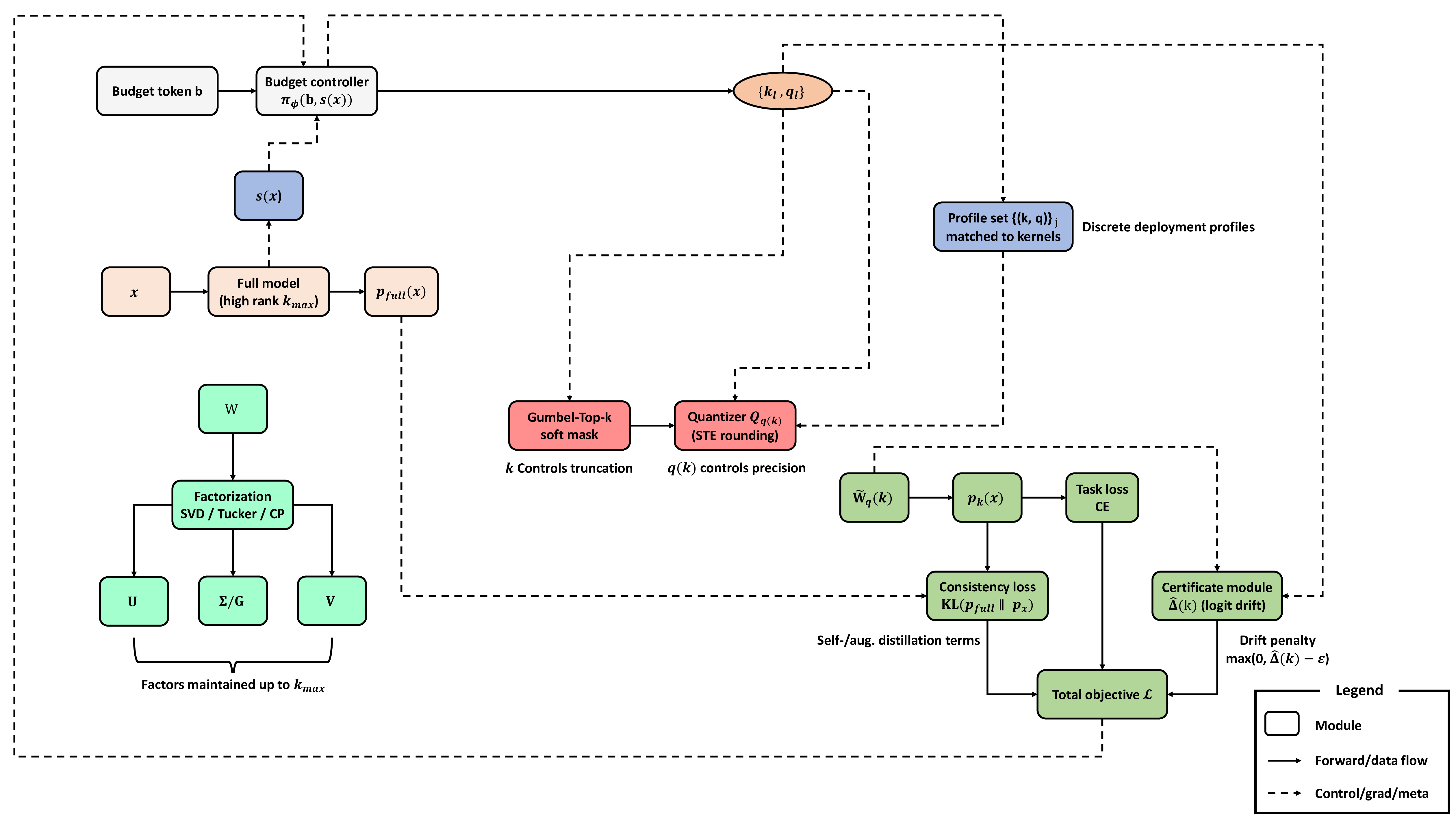
현대의 추천 시스템은 도메인별 데이터를 기반으로 학습되지만, 여러 도메인 간에 일반화하는 데 어려움을 겪는다. 도메인 간 순차적 추천은 이러한 문제점을 해결하기 위한 유망한 연구 방향으로 부상했지만, 기존 접근법들은 도메인 간 중복 사용자나 항목의존성 또는 프라이버시 제약을 무시하는 비현실적인 가정과 같은 근본적인 한계를 가지고 있다. 본 논문에서는 새로운 문제 설정인 데이터 고립된 도메인 간 순차적 추천 하에서 모델 합병에 기반한 새 프레임워크, MergeRec을 제안한다. 이 설정에서는 원시 사용자 상호작용 데이터가 도메인 간 공유되지 않는다. MergeRec은 세 가지 주요 구성 요소로 이루어져 있다 (1) 합병 초기화, (2) 가상 사용자 데이터 생성, (3) 공동 합병 최적화. 먼저, 우리는 트레이닝 없는 합병 기법을 통해 합병 모델을 초기화한다. 그다음으로 각 도메인에서 항목별로 가상 시퀀스를 만들어 실제 사용자 상호작용에 의존하지 않고 의미 있는 훈련 샘플을 생성한다. 마지막으로, 우리는 추천 손실과 디스티ல레이션 손실을 결합한 공동 목표를 통해 도메인별 합병 가중치를 최적화한다. 이 두 가지 손실은 각각 합병 모델이 관련 항목을 식별하도록 유도하고, 조정된 소스 모델에서 협업 필터링 신호를 전달한다. 광범위한 실험 결과 MergeRec은 원래 모델들의 강점을 유지하면서 새로운 도메인에 대한 일반화 능력을 크게 향상시킨다. 기존의 모델 합병 방법들과 비교했을 때, MergeRec은 평균적으로 Recall@10에서 최대 17.21%까지 개선되는 우수한 성능을 일관되게 보여주어, 모델 합병이 대규모 추천 시스템 구축에 효과적인 접근법임을 입증한다. 소스 코드는 https //github.com/DIALLab-SKKU/MergeRec에서 이용 가능하다.