: 본 논문에서는 음악 미학 평가를 위한 새로운 접근 방식인 HEAR(Hierarchical Evaluation of Aesthetic Ratings) 프레임워크를 소개합니다. 음악적 인식의 다차원적 특성과 레이블이 지정된 데이터 부족이라는 도전 과제를 해결하기 위해, 연구자들은 Songformer와 MuQ와 같은 기존 모델을 활용하여 보완적인 지역 및 전역 수준의 음악 표현을 추출하는 방법을 제안했습니다. 또한, 계층적 증강 전략과 하이브리드 훈련 목표를 도입하여 과적합을 완화하고 정확한 평가를 수행합니다.
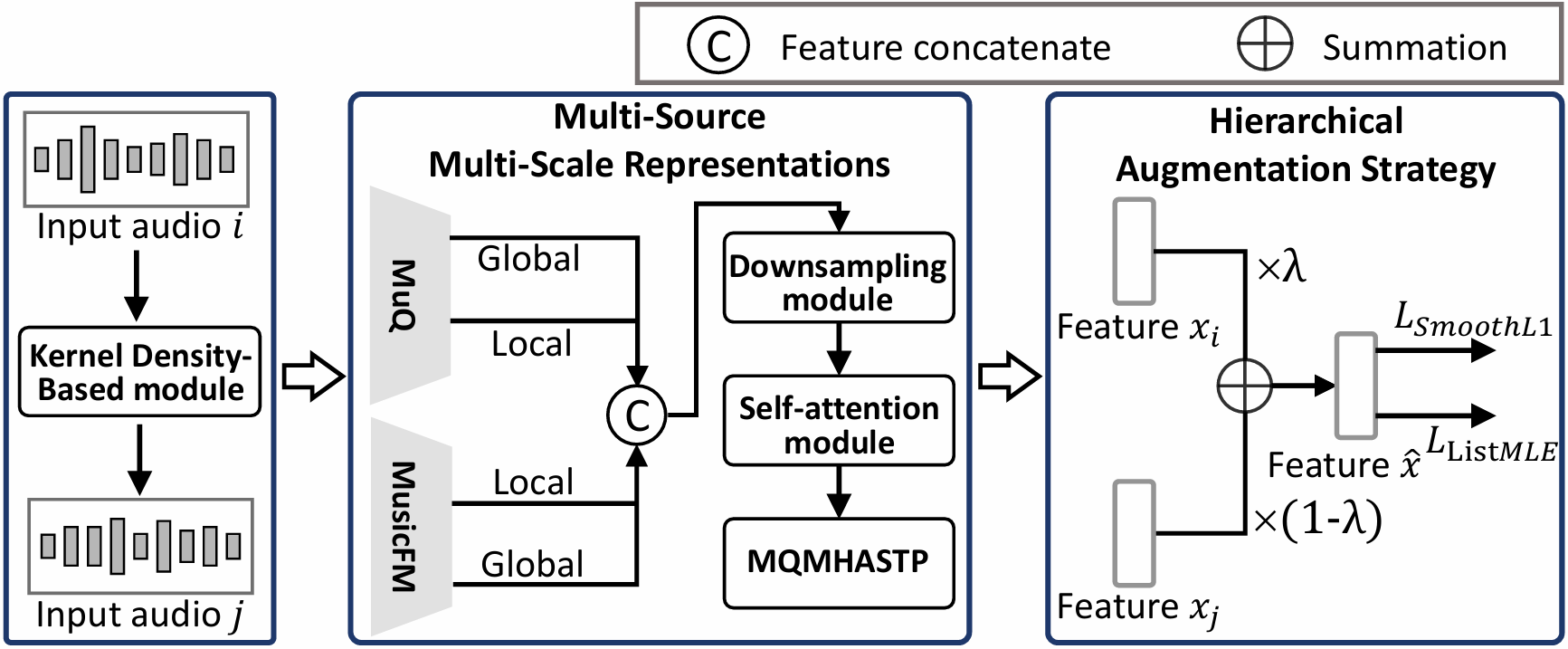
HEAR 프레임워크는 다음과 같은 세 가지 주요 요소를 통합합니다: (1) 다중 소스 및 다중 스케일 표현 모듈을 통해 다양한 음악적 특성을 포착, (2) 보수적인 오디오 증강 파이프라인과 조건부 혼합 기법을 활용한 계층적 증강 전략으로 데이터를 강화, (3) 회귀와 순위 손실을 결합한 하이브리드 훈련 목표를 통해 정확한 점수 매김과 상위 티어 노래 식별을 수행.
실험 결과는 HEAR 프레임워크가 ICASSP 2026 SongEval 벤치마크에서 우수한 성능을 보임을 보여주었습니다. 모든 지표에 걸쳐 기준선을 능가하며, 특히 미학 점수 예측과 상위 티어 노래 식별에서 뛰어난 정확도를 달성했습니다.
💡 논문 핵심 해설 (Deep Analysis)
음악의 미학적 평가를 자동화하는 것은 음악 생성 모델의 발전과 함께 중요한 과제로 떠오르고 있습니다. 기존 접근 방식은 풍부한 음악적 특성을 포착하는 데 한계가 있었습니다. HEAR 프레임워크는 이러한 문제를 해결하기 위해 다차원적인 음악 미학 평가를 위한 견고한 솔루션을 제공합니다.
HEAR의 핵심은 보완적인 지역 및 전역 수준의 음악 표현을 추출하는 것입니다. Songformer와 MuQ 모델을 활용하여 다양한 스케일의 음악적 단서를 포착하고, 이를 통해 시간적, 스펙트럼, 조화, 콘텐츠 측면에서 미학 평가를 수행할 수 있습니다. 이러한 다중 소스 표현은 음악의 복잡한 특성을 효과적으로 캡처합니다.
또한, HEAR는 계층적 증강 전략을 도입하여 데이터를 강화하고 과적합을 방지합니다. 보수적인 오디오 증강 파이프라인을 통해 훈련 세트를 확장하고, 조건부 혼합 기법인 C-Mixup을 사용하여 레이블 공간에서 인접한 예제를 샘플링함으로써 모델의 일반화 능력을 향상시킵니다. 이는 음악 미학 평가에 있어 중요한 기여를 합니다.
하이브리드 훈련 목표는 HEAR 프레임워크의 또 다른 강점입니다. 회귀와 순위 손실을 결합하여 정확한 점수 매김과 상위 티어 노래 식별을 동시에 수행합니다. 특히, SmoothL1 손실과 ListMLE 순위 손실을 사용하여 모델이 미학 점수를 예측하고 순위를 매기는 능력을 향상시킵니다. 이는 음악의 아름다움을 평가하는 데 있어 더욱 정교한 접근 방식입니다.
실험 결과는 HEAR 프레임워크가 SongEval 데이터 세트에서 우수한 성능을 보임을 보여줍니다. 선형 상관 계수, Spearman 순위 상관 계수, Kendall’s Tau Rank Correlation과 같은 다양한 지표를 통해 HEAR의 정확성과 일관성이 입증되었습니다. 특히, 상위 티어 노래 식별에 있어 뛰어난 정확도를 달성했습니다.
HEAR 프레임워크는 음악 미학 평가를 위한 혁신적인 접근 방식으로, 다차원적 특성을 고려하고 데이터 증강 전략을 활용하여 음악의 아름다움을 평가합니다. 이를 통해 음악 산업과 연구 분야에서 음악의 미학적 가치를 더욱 깊이 이해하고 분석할 수 있는 기반을 제공합니다.
📄 논문 본문 발췌 (Excerpt)
# 추상:
음악적 인식의 다차원적인 본질과 레이블이 지정된 데이터의 부족으로 인해 노래 미학의 평가를 수행하는 것은 어렵습니다. 우리는 HEAR라고 불리는 견고한 음악 미학 평가 프레임워크를 제안합니다. 이는 다음과 같은 세 가지 요소를 결합합니다: (1) 보완적인 세그먼트 및 트랙 수준 기능을 얻기 위한 다중 소스 다중 스케일 표현 모듈, (2) 과적합을 완화하기 위한 계층적 증강 전략, 그리고 (3) 정확한 점수 매김과 신뢰할 수 있는 상위 티어 노래 식별을 위한 회귀 및 순위 손실을 통합하는 하이브리드 훈련 목표. 실험 결과는 HEAR가 ICASSP 2026 SongEval 벤치마크의 트랙에서 모든 지표에 걸쳐 기준선을 지속적으로 능가함을 보여줍니다. 코드와 훈련된 모델 가중치는 https://github.com/Eps-Acoustic-Revolution-Lab/EAR_HEAR에서 사용할 수 있습니다.
내용 발췌:
생성 음악 모델의 급속한 발전과 함께 자동화된 음악 미학 평가가 점점 더 중요해지고 있지만 여전히 도전 과제로 남아 있습니다. 기존 접근 방식인 Audiobox-Aesthetics [1]는 다차원 미학 점수를 예측하기 위해 간단한 Transformer 기반 아키텍처를 사용하지만 풍부한 음악적 특성을 포착하는 데 어려움을 겪습니다. SongEval [2]은 고품질 벤치마크를 수립했지만 제한된 데이터 규모로 인해 견고한 미학 평가자의 훈련이 어렵습니다. 이를 위해 우리는 다음과 같은 주요 기여가 있는 견고한 프레임워크를 제안합니다:
Songformer [3]에서 영감을 받아 MuQ [4]와 MusicFM [5] 모두를 사용하여 보완적인 지역 세그먼트 수준 및 전역 트랙 수준 다중 스케일 음악 표현을 추출합니다. 이어서 다운샘플링, 자기 주의력, 그리고 Multi-Query Multi-Head Attention Statistical Pooling (MQMHASTP) 모듈 [6]이 있습니다. 이는 모델이 시간적, 스펙트럼, 조화 및 콘텐츠 단서가 다양한 미학 차원에 어떻게 기여하는지 포착하면서 가변 길이 기능을 고정 길이 표현으로 변환합니다.
우리는 데이터 수준과 기능 수준에서 모두 작동하는 계층적 증강 전략을 도입했습니다. 데이터 수준에서는 보수적인 오디오 증강 파이프라인을 적용하여 훈련 세트를 확장합니다. 자세한 내용은 3.1.1절에 요약되어 있습니다. 기능 수준에서는 C-Mixup [7]을 사용하여 조건부 혼합을 수행합니다. 이는 레이블 공간에서 더 높은 확률로 인접한 예제를 샘플링함으로써 커널 밀도 추정(KDE)을 통해 수행됩니다:
여기서 d(i, j)는 두 예제의 레이블 간의 유클리드 거리입니다. 그 후 볼록 조합으로 혼합 기능-레이블 쌍이 얻어진다:
λ는 베타 분포에서 샘플링되며, 즉 λ ∼ Beta(α, α)입니다.
미학 점수 예측과 상위 티어 노래 식별을 모두 지원하기 위해 우리는 회귀를 위한 SmoothL1 손실 [8]과 샘플 간의 상대적 순서를 모델링하는 listwise 순위 손실 ListMLE [9]를 결합한 하이브리드 목표 L 총을 채택합니다:
여기서 β는 주어진 순위가 특히 유사한 샘플 사이에서 신뢰할 수 없을 때 순위 항에 가중치를 주어 민감도를 완화합니다.
모든 실험은 SongEval 데이터 세트 [2]에서 수행됩니다. 이 데이터 세트는 5가지 미학 차원에 걸쳐 2,399개의 노래로 주석이 달려 있습니다. 공식 프로토콜을 따라 200개의 샘플이 검증에 사용되며 나머지 데이터는 표 1에 요약된 8가지 데이터 수준 전략으로 증강됩니다. 모델은 학습률 1×10 -5, 가중치 감쇠 1×10 -3 및 배치 크기 8을 가진 Adam 최적기를 사용하여 훈련됩니다. 순위 목표를 가중하는 하이퍼파라미터 β는 트랙 1에 대해 0.15로, 트랙 2에 대해 0.05로 설정됩니다.
C-Mixup의 경우, 가우시안 커널의 대역폭 매개변수 σ는 1로 설정되며 베타 분포에서 α는 2로 설정됩니다.
표 1. 훈련에 사용된 데이터 수준 증강 설정입니다.
모델은 네 가지 공식 지표를 사용하여 평가됩니다: 선형 상관 계수(LCC) [10]는 예측된 점수와 실제 점수 사이의 선형 정렬을 측정하며, Spearman의 순위 상관 계수(SRCC) [11]와 Kendall’s Tau Rank Correlation (KTAU) [12]은 순위의 일관성을 평가합니다. 상위 티어 정확도(TTA)는 공식 임계값을 사용하여 F1 점수로 상위 티어 노래를 식별하는 것을 측정합니다.
우리는 제한된 레이블 데이터와 복잡한 음악적 인식의 문제를 효과적으로 해결하는 다차원 음악 미학 평가를 위한 견고한 프레임워크인 HEAR를 제시했습니다. 우리의 방법은 다중 소스 다중 스케일 표현, 계층적 증강 전략 및 하이브리드 훈련 목표를 시너지 효과로 결합합니다. ICASSP 2026 SongEval 벤치마크에 대한 실험 결과는 우리 접근 방식이 기준선을 지속적으로 능가하며 미학 점수 매김과 상위 티어 노래 식별 모두에서 뛰어난 성능을 달성함을 보여줍니다.