Cadence 기반 추천 시스템 구현 및 파라미터 최적화 연구
📝 원문 정보
- Title: Cadence 기반 추천 시스템 구현 및 파라미터 최적화 연구
- ArXiv ID: 2512.17733
- 발행일:
- 저자: Unknown
📝 초록 (Abstract)
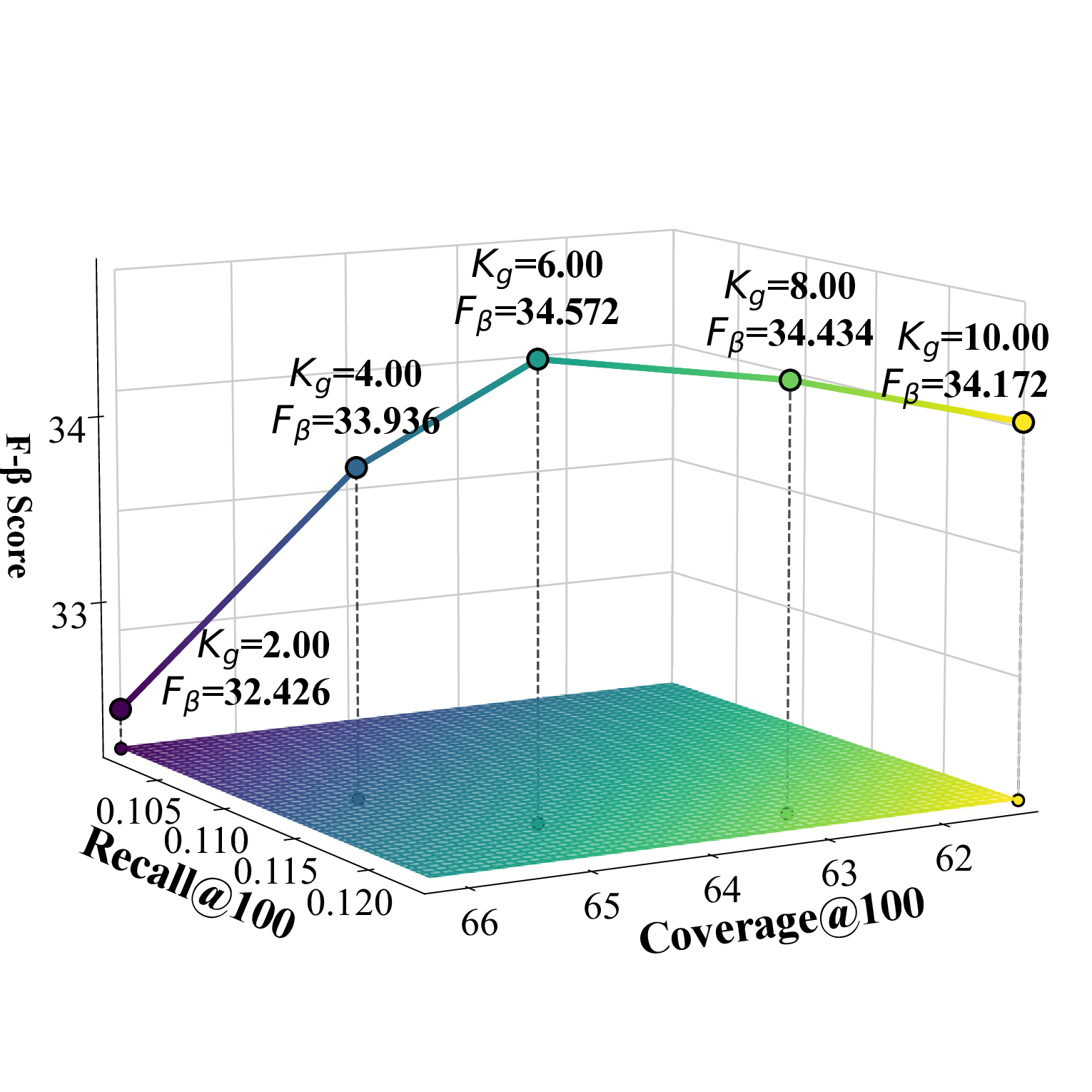
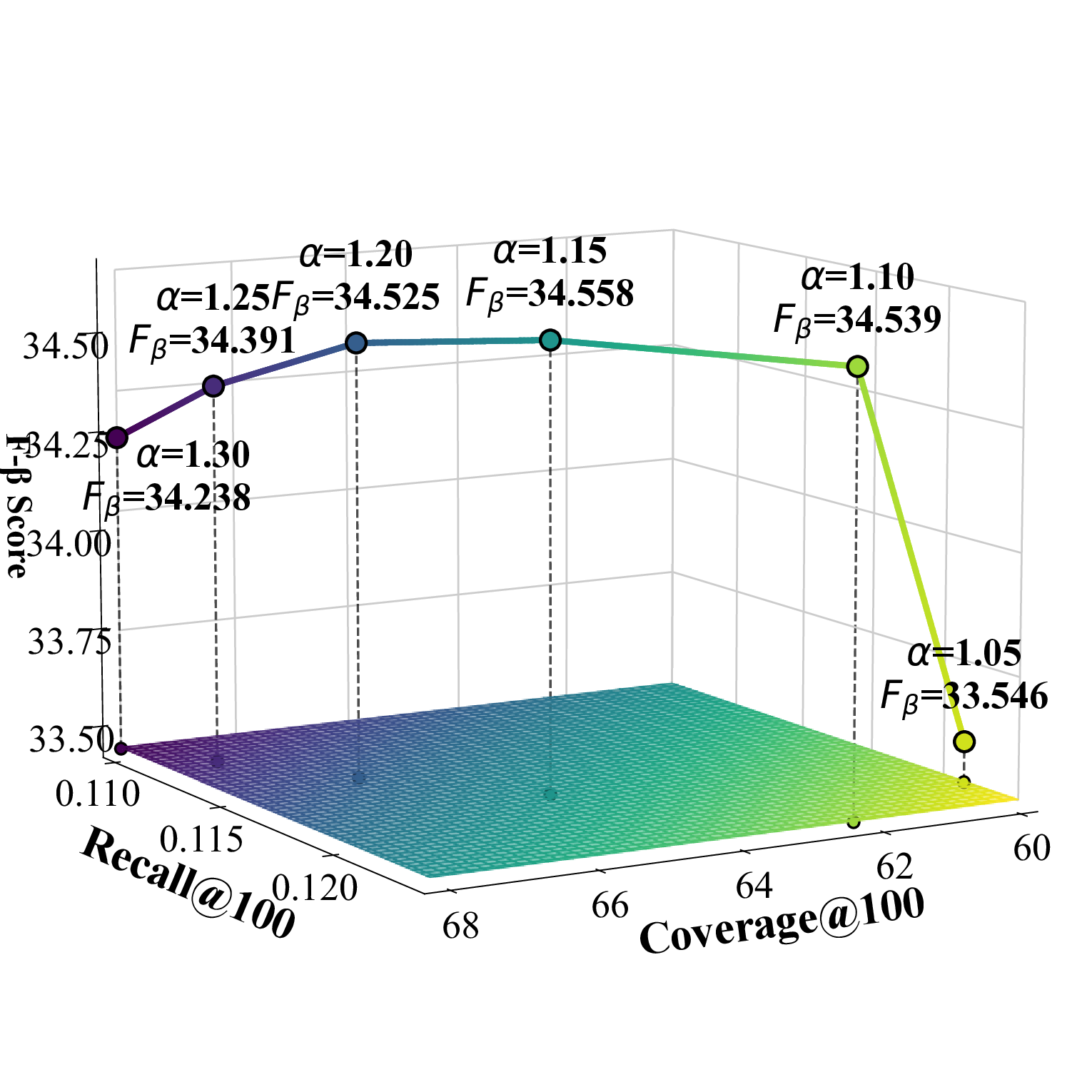
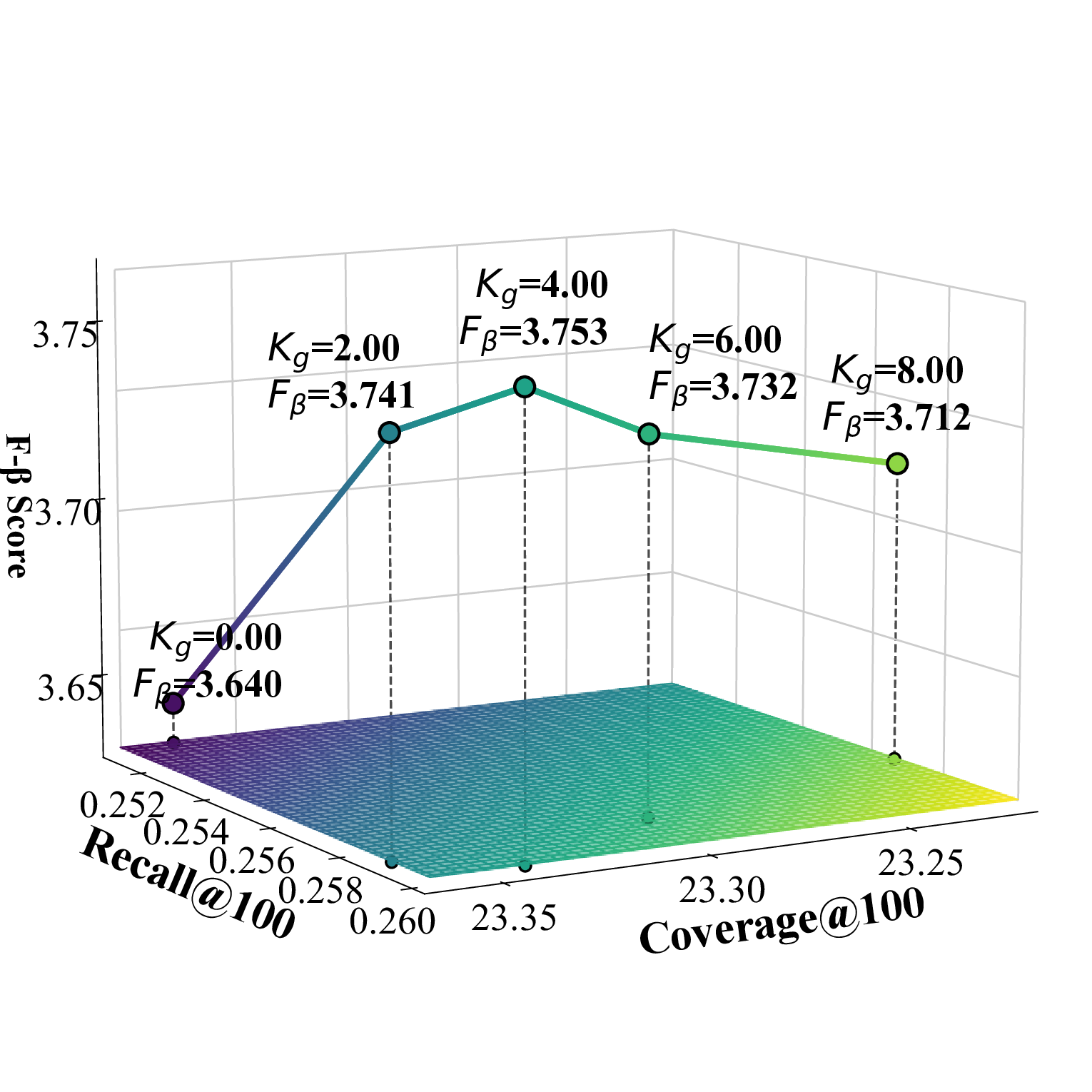
우리는 Cadence를 PyTorch 기반으로 구현하고 Adam 옵티마이저를 사용해 학습하였다. 학습률은 0.001로 설정하고 배치 크기는 2048, 임베딩 차원은 32로 고정하였다. UACR 기반 아이템‑아이템 집계 레이어에서는 L II = 2로 설정했으며, LightGCN의 전파 레이어 수는 L = 3으로 두었다. CSCE 모듈의 2단계 후보 선택에서는 전역 선택 수 K_g를 Beauty 데이터셋에서는 4, TaoBao에서는 12, Toy에서는 6으로 지정하고, 카테고리별 선택 수 K_c는 세 데이터셋 모두 1로 설정하였다. 스케일링 팩터 α는 Beauty와 Toy에서 1.15, TaoBao에서 1.05로 설정하였다. 우리는 부정 샘플링을 포함한 Bayesian Personalized Ranking(BPR) 손실을 사용해 모델을 학습한다. BPR 손실은 D_S(학습 삼중항 집합), σ(시그모이드 함수), r_{u,i}, r_{u,j}(양성·음성 아이템에 대한 예측 점수), λ(정규화 계수), θ(모델 파라미터)를 이용해 정의된다.💡 논문 핵심 해설 (Deep Analysis)
UACR‑구동 아이템‑아이템 집계 레이어의 깊이 L II = 2는 과도한 레이어 깊이로 인한 과적합 위험을 최소화하면서, 아이템 간 상호작용을 충분히 포착하도록 설계되었다. LightGCN의 전파 레이어 수 L = 3은 그래프 구조 내에서 이웃 정보를 3단계까지 전파함으로써, 사용자와 아이템 사이의 복합적인 관계를 효과적으로 학습한다.
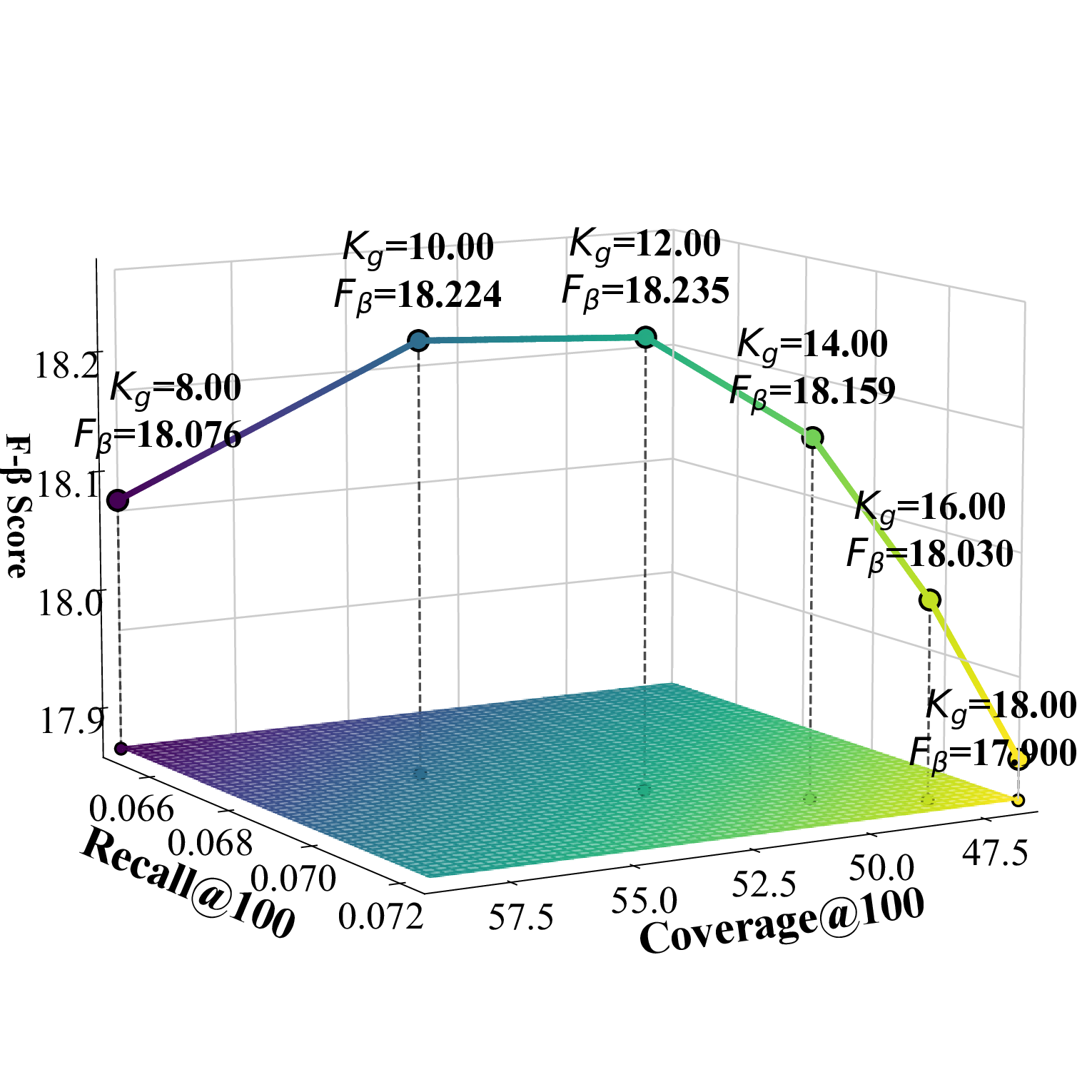
CSCE 모듈의 두 단계 후보 선택은 특히 도메인별 특성을 반영한다. 전역 선택 수 K_g를 데이터셋마다 다르게 설정한 것은 각 도메인의 아이템 다양성과 사용자 행동 패턴 차이를 고려한 것이다. 예를 들어, TaoBao는 제품군이 방대하므로 K_g = 12로 확대했으며, Beauty와 Toy는 상대적으로 제한된 카테고리 특성을 반영해 K_g = 4·6으로 설정하였다. 카테고리‑특정 선택 수 K_c를 1로 고정함으로써, 각 카테고리에서 가장 유망한 후보 하나만을 추출해 후속 단계의 연산 부하를 크게 감소시켰다.
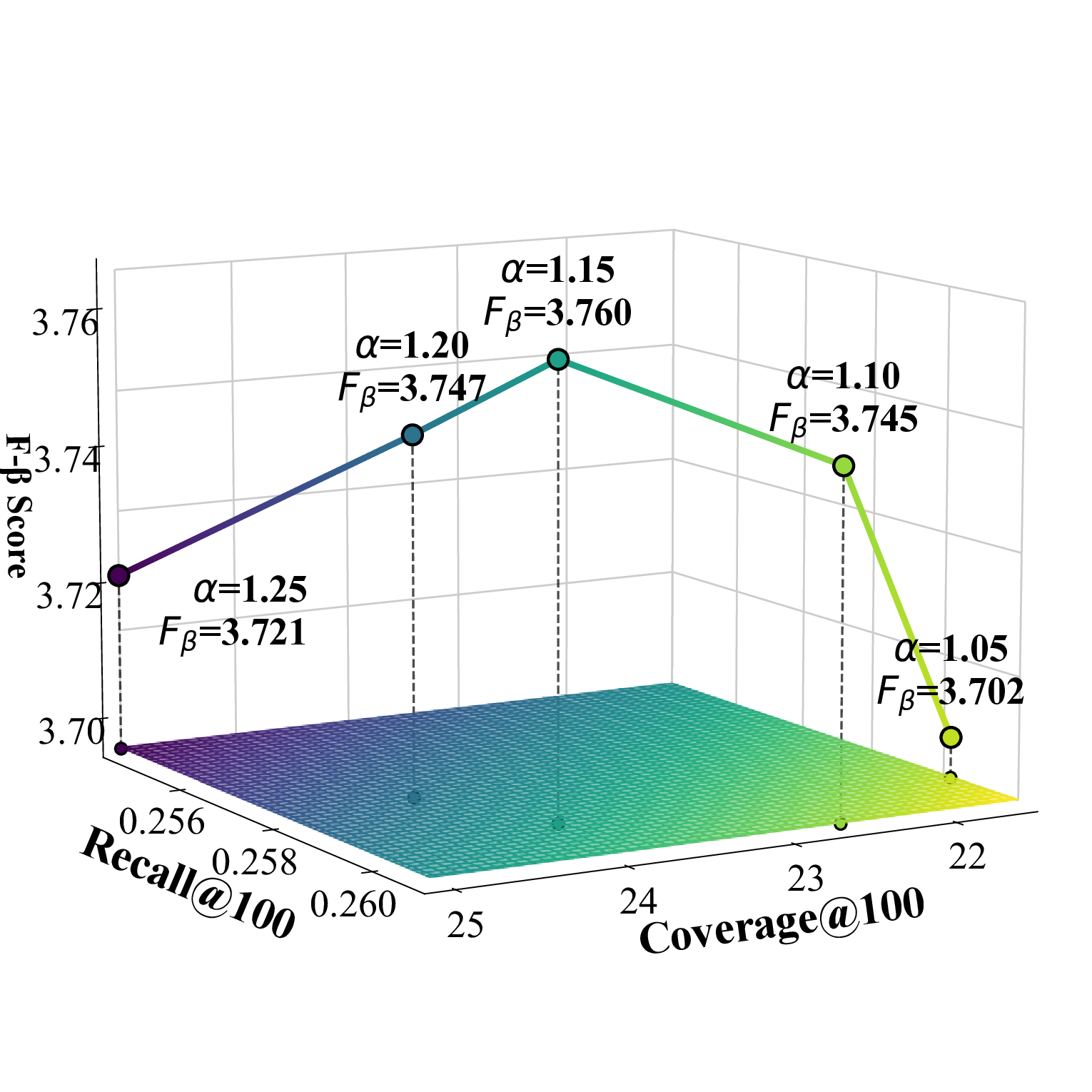
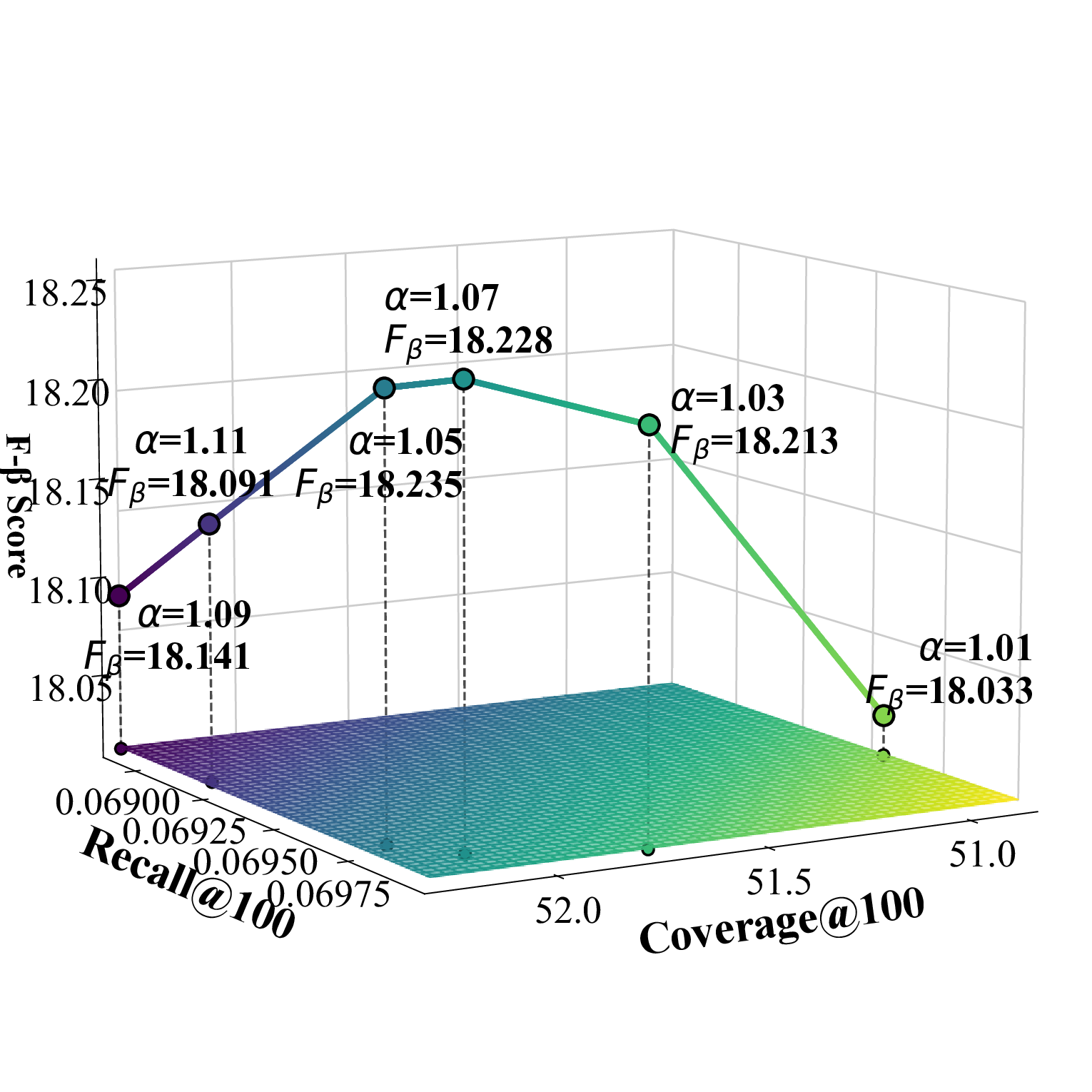
스케일링 팩터 α는 후보 집합의 크기를 조절하는 핵심 파라미터로, α > 1은 후보를 확대해 탐색 범위를 넓히고, α < 1은 후보를 축소해 정밀도를 높인다. 본 논문에서는 Beauty와 Toy에서 α = 1.15, TaoBao에서 α = 1.05를 사용해 각 도메인의 특성에 맞는 탐색‑정밀도 균형을 맞추었다.
학습 손실로 선택된 BPR 손실은 순위 기반 추천에 널리 쓰이며, 부정 샘플링과 결합해 효율적인 파라미터 업데이트를 가능하게 한다. 손실 정의에 포함된 정규화 항 λ은 과적합을 방지하고 모델 일반화를 촉진한다.
마지막으로 실험 인프라로 NVIDIA A100 80GB GPU와 최신 PyTorch 2.4를 활용한 점은 대규모 그래프 연산과 고차원 임베딩 학습을 원활히 수행할 수 있음을 보여준다. 전체 설정은 연구 재현성을 높이고, 향후 다양한 도메인에 Cadence를 적용할 때 기준점으로 활용될 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리