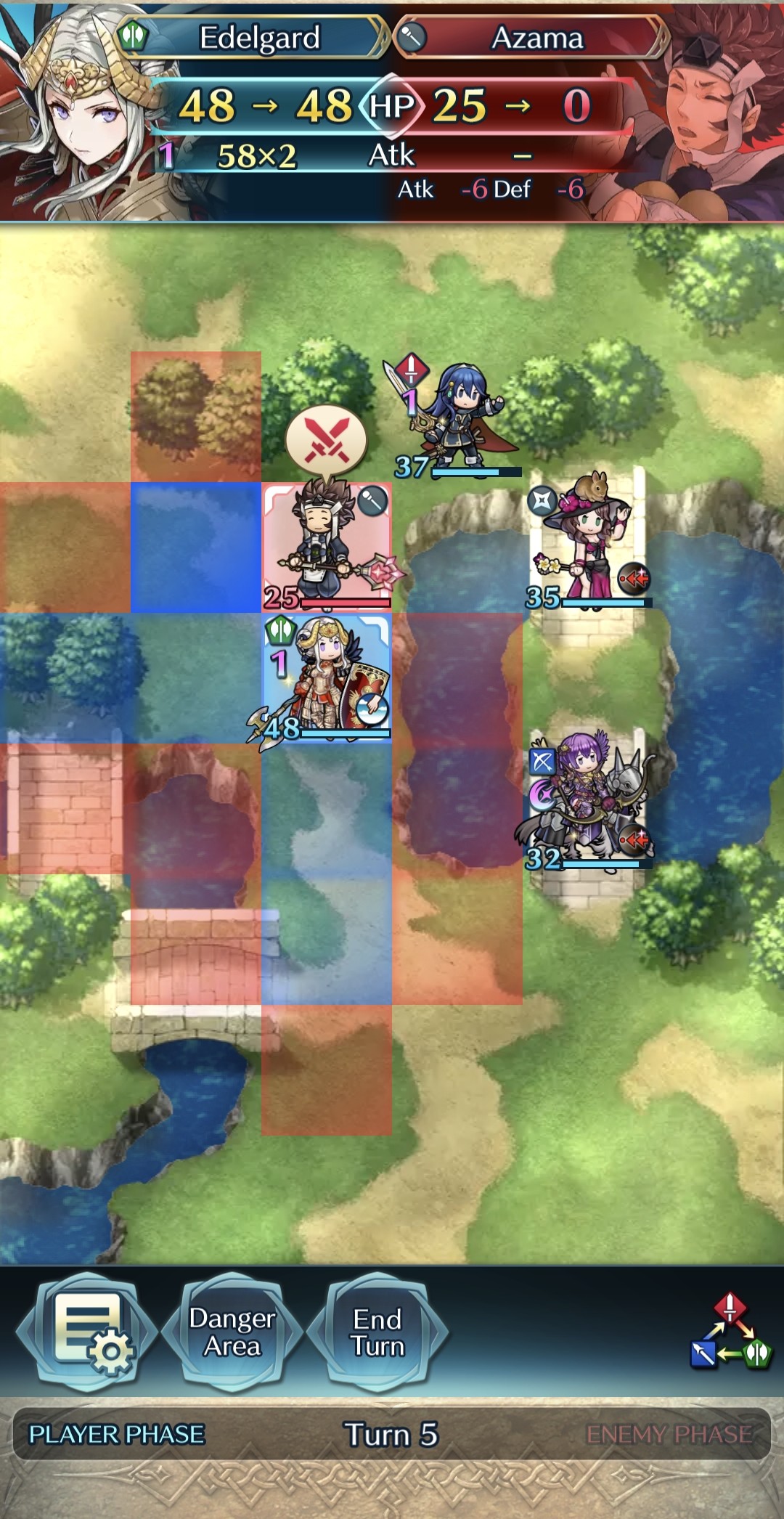
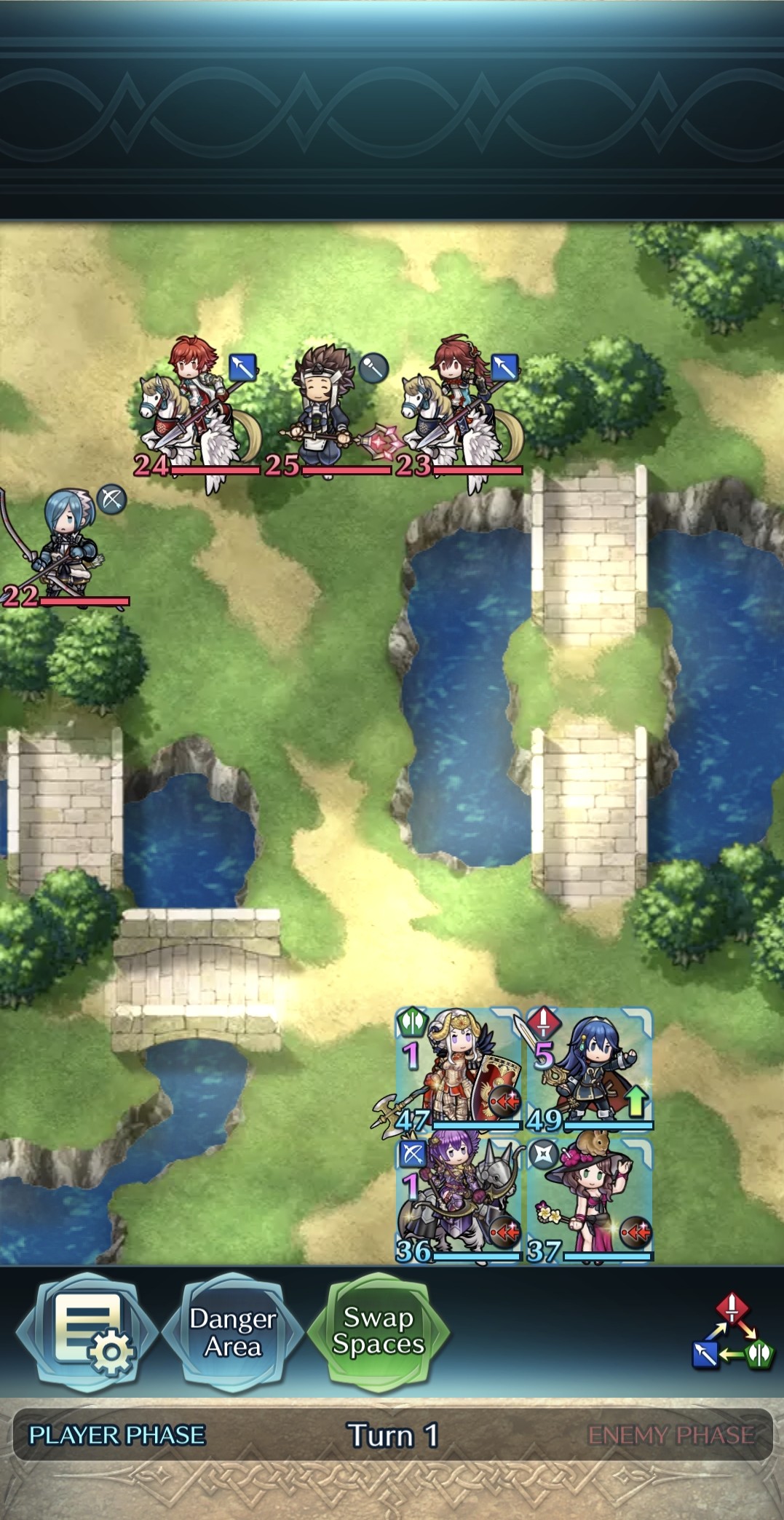
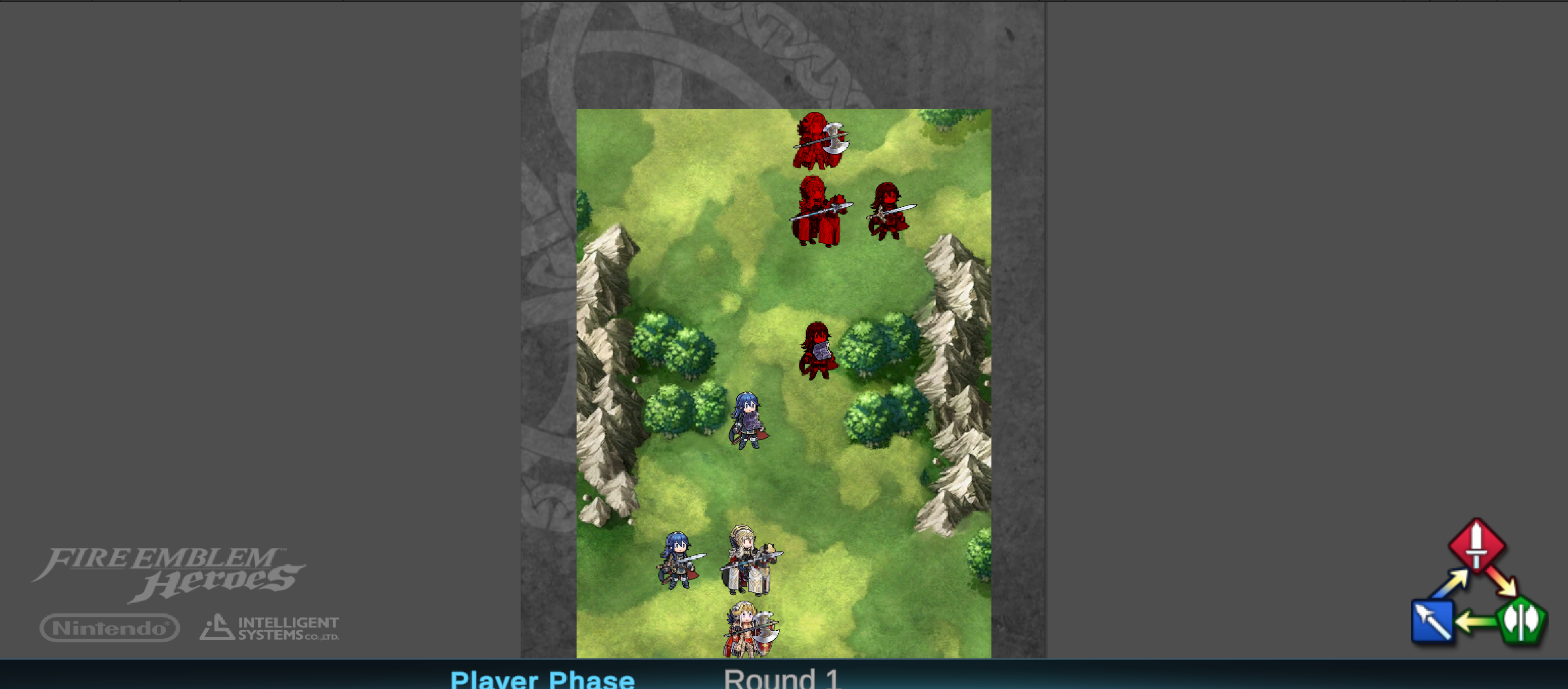
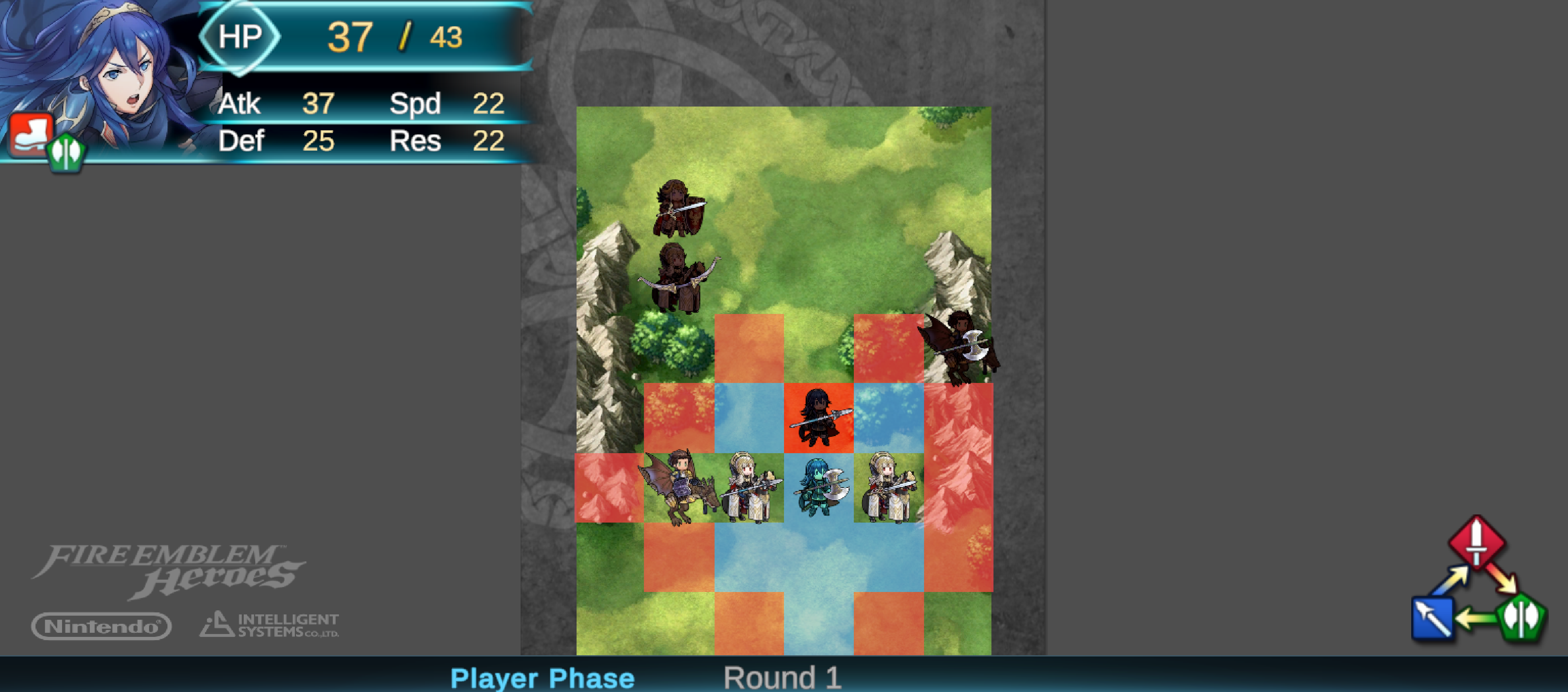
턴제 게임에서 적의 행동은 놀라움과 예측 불가능성을 가져야 한다. 본 연구는 플레이어가 스스로의 전략을 반복해서 사용하지 못하도록 유도하기 위해, 적 AI가 플레이어의 개인 전략을 그대로 모방하는 ‘거울 모드’를 제안한다. Nintendo의 전략 게임 Fire Emblem Heroes를 단순화하여 Unity로 구현한 실험 환경에는 표준 모드와 거울 모드가 포함된다. 첫 번째 실험에서는 플레이어 시연을 모방하기 위한 최적 모델을 탐색했으며, 강화학습과 모방학습을 결합한 접근법—Generative Adversarial Imitation Learning, Behavioral Cloning, Proximal Policy Optimization—을 사용하였다. 두 번째 실험에서는 참가자들이 제공한 시연 데이터를 기반으로 학습된 모델을 실제 플레이에 적용하였다. 결과는 방어 행동에서는 높은 모방 정확도를 보였으나, 공격 전략에서는 한계가 있음을 보여준다. 설문 조사에서 참가자들은 자신의 후퇴 전술이 재현된 것을 인식했으며, 거울 모드에 대한 전반적인 만족도가 더 높게 나타났다. 모델을 추가로 정교화하면 모방 품질이 향상되고, 플레이어가 자신의 전략과 마주했을 때 만족도가 더욱 증대될 것으로 기대한다. 전체 코드와 설문 결과는 https://github.com/YannaSmid/MirrorMode 에서 확인할 수 있다.
💡 논문 핵심 해설 (Deep Analysis)
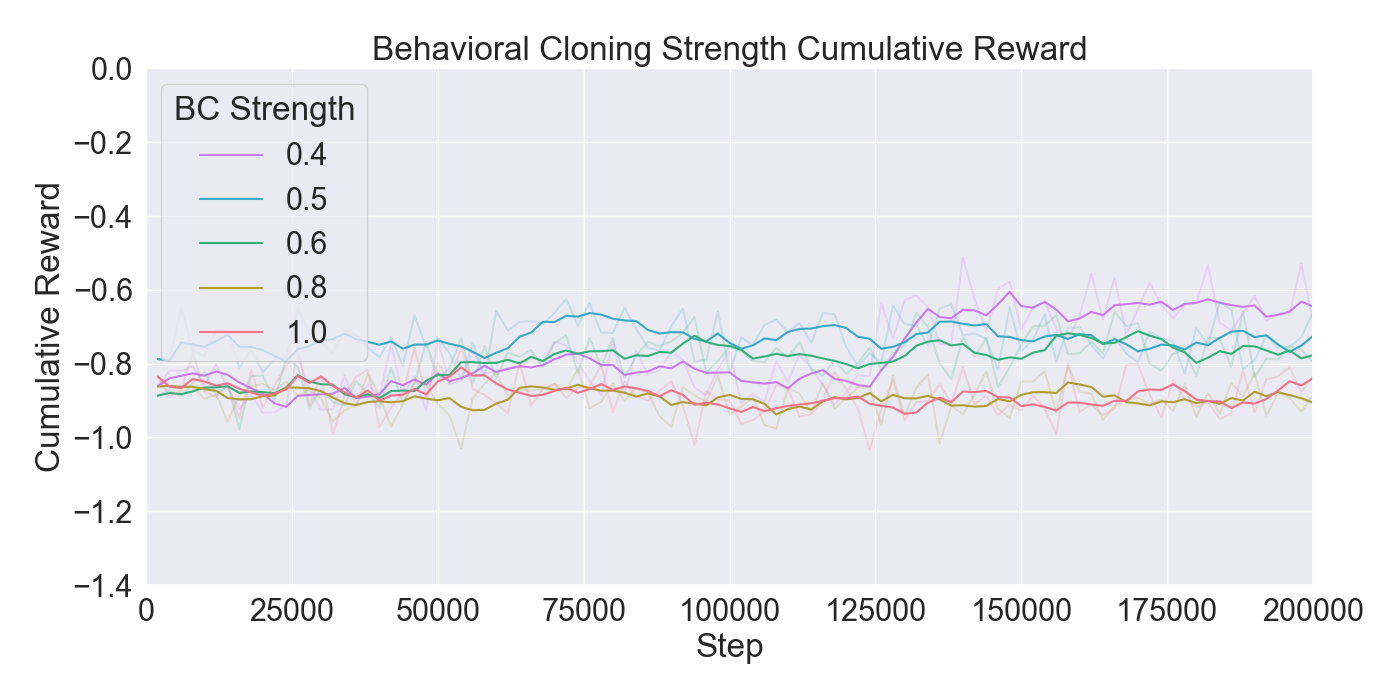
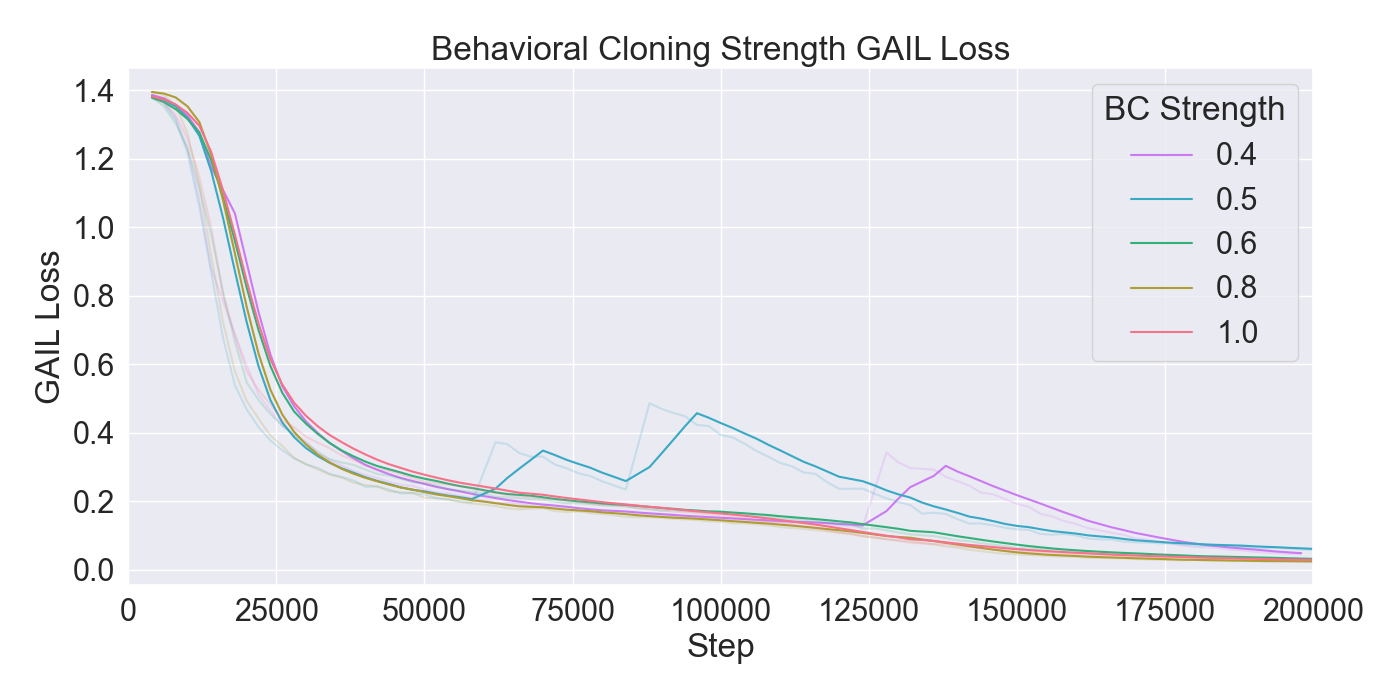
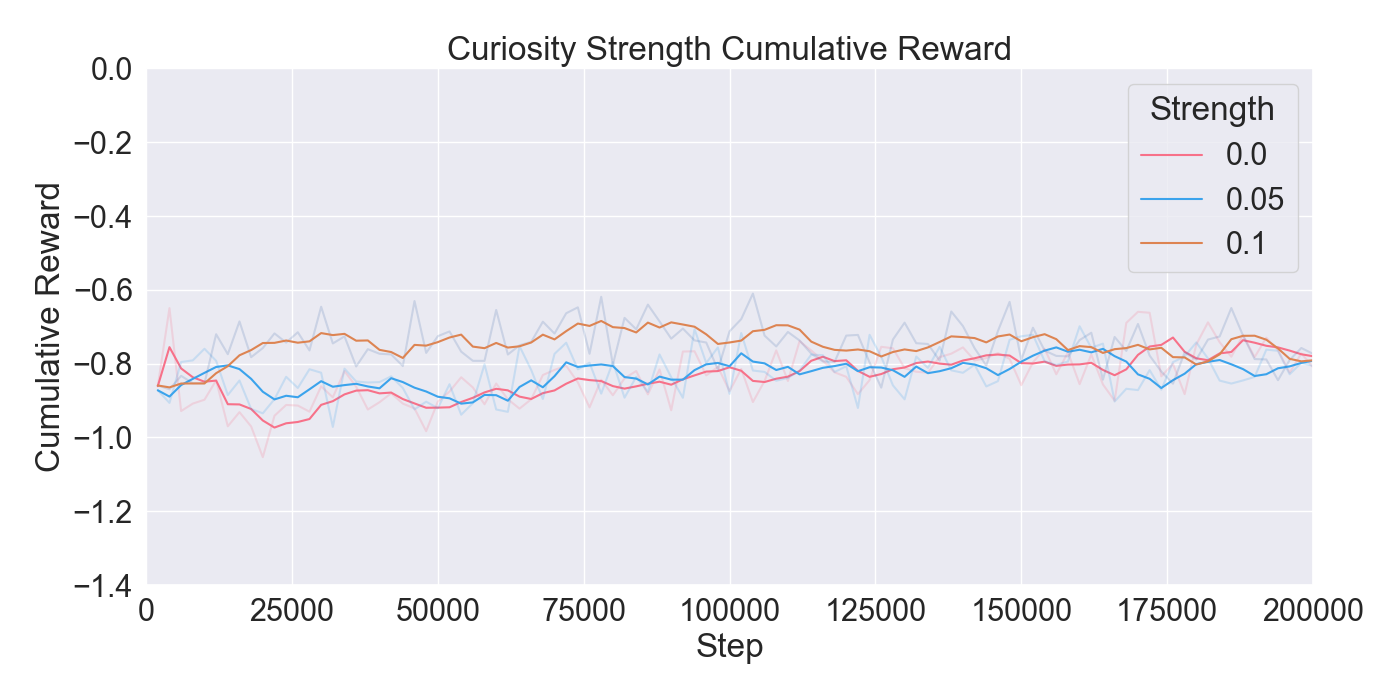
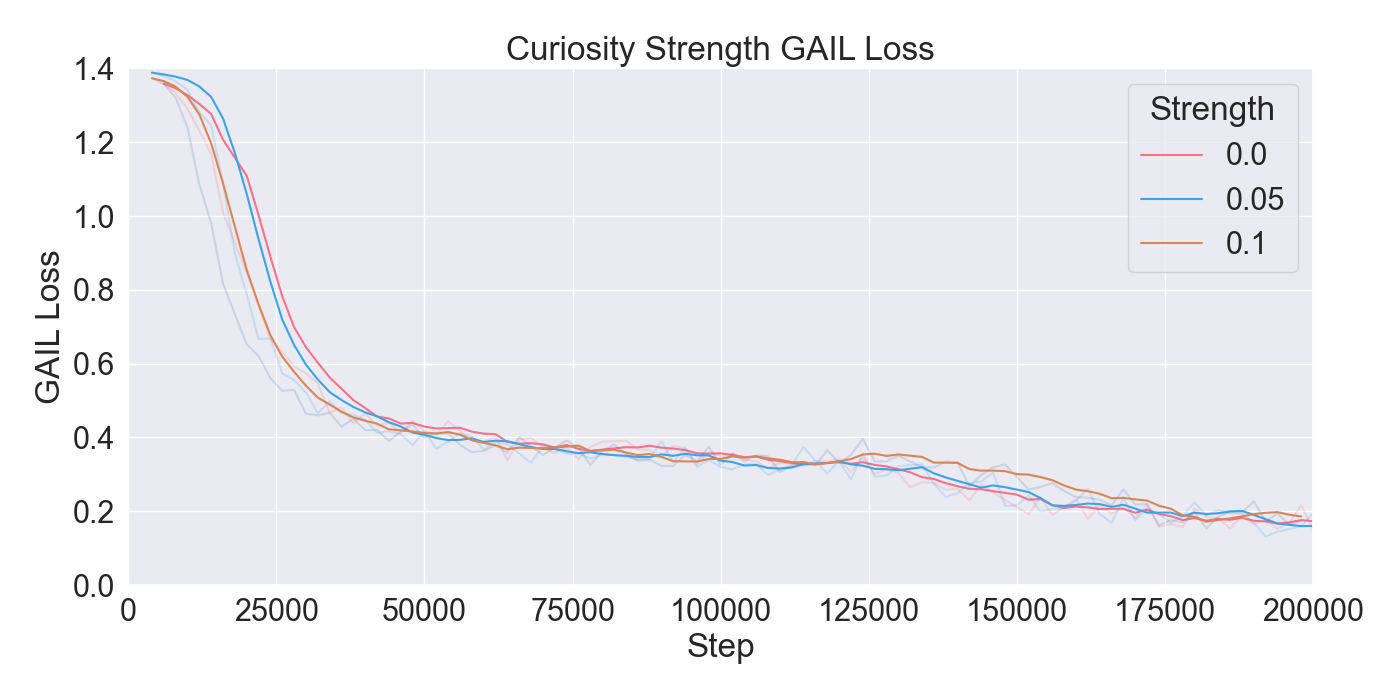
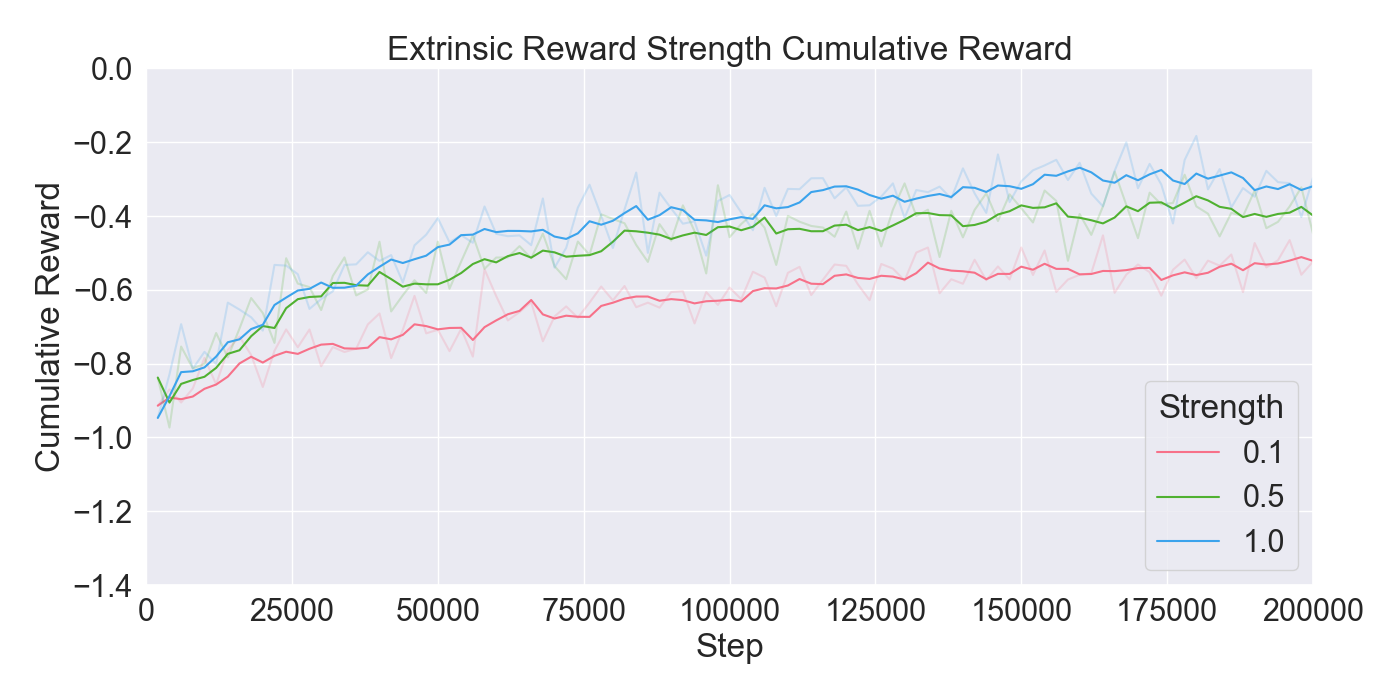
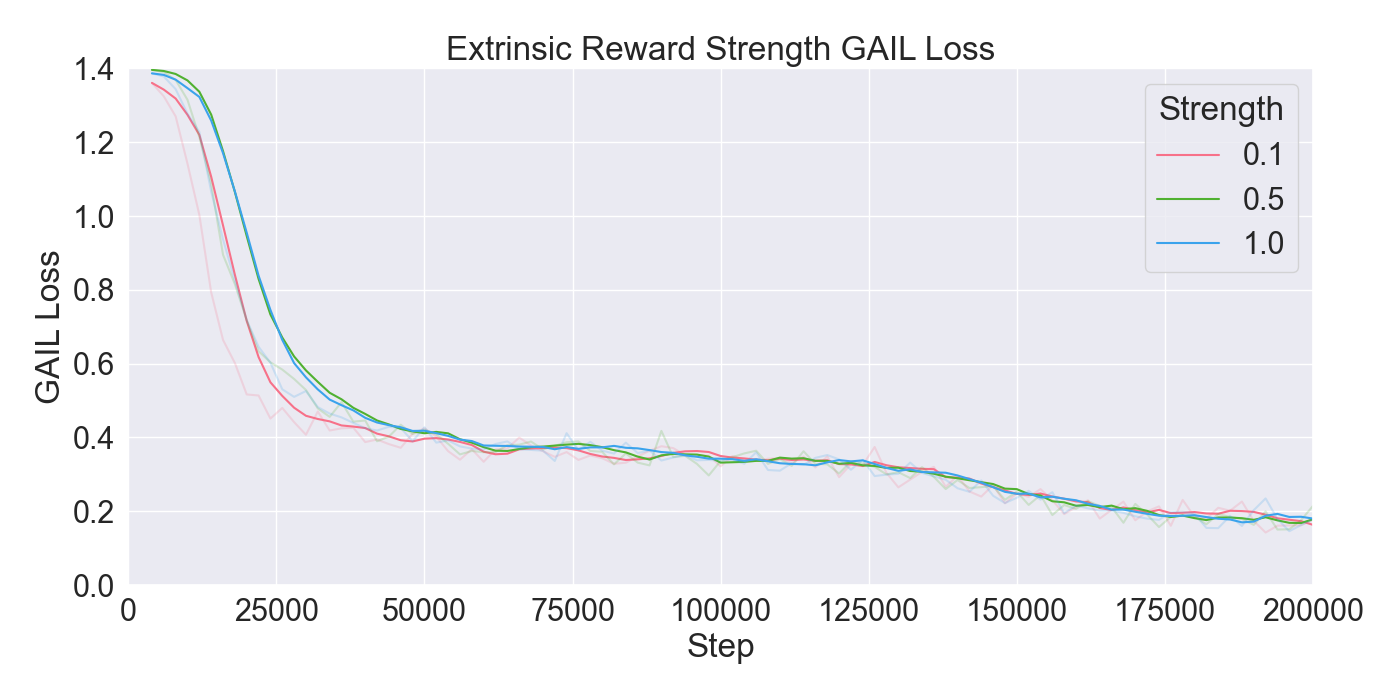
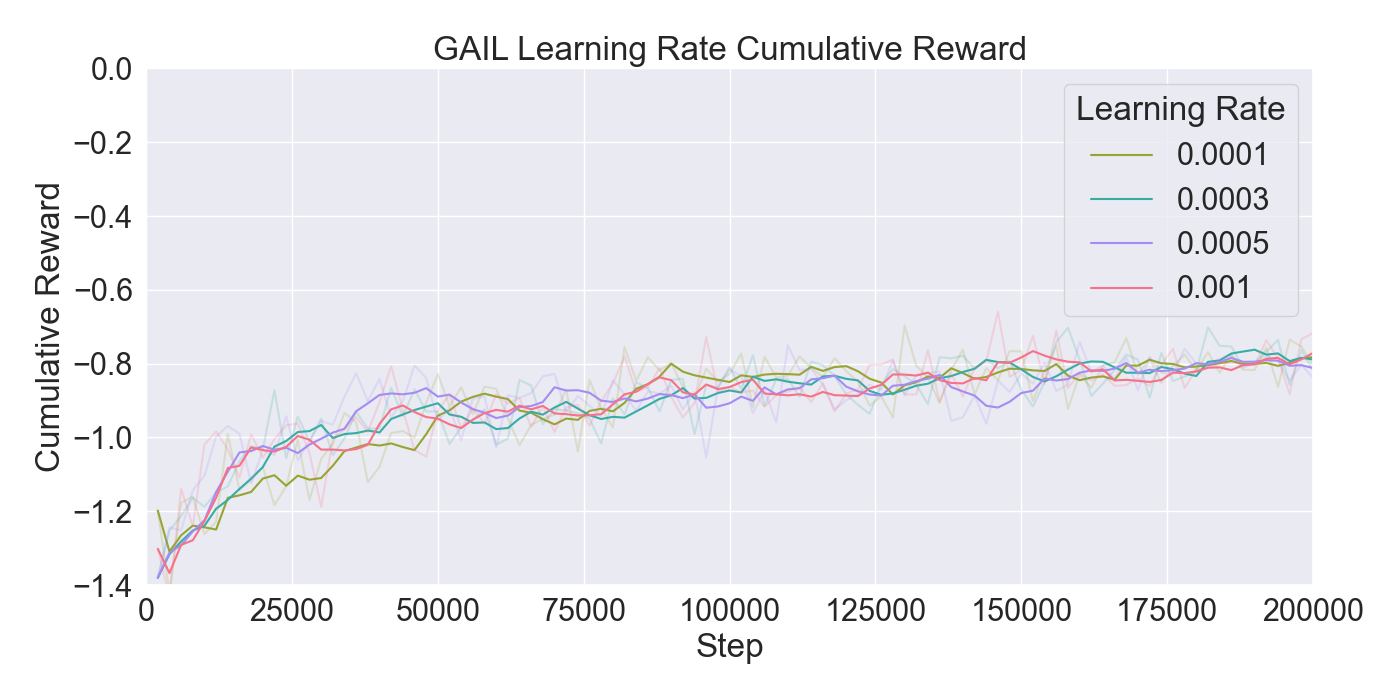
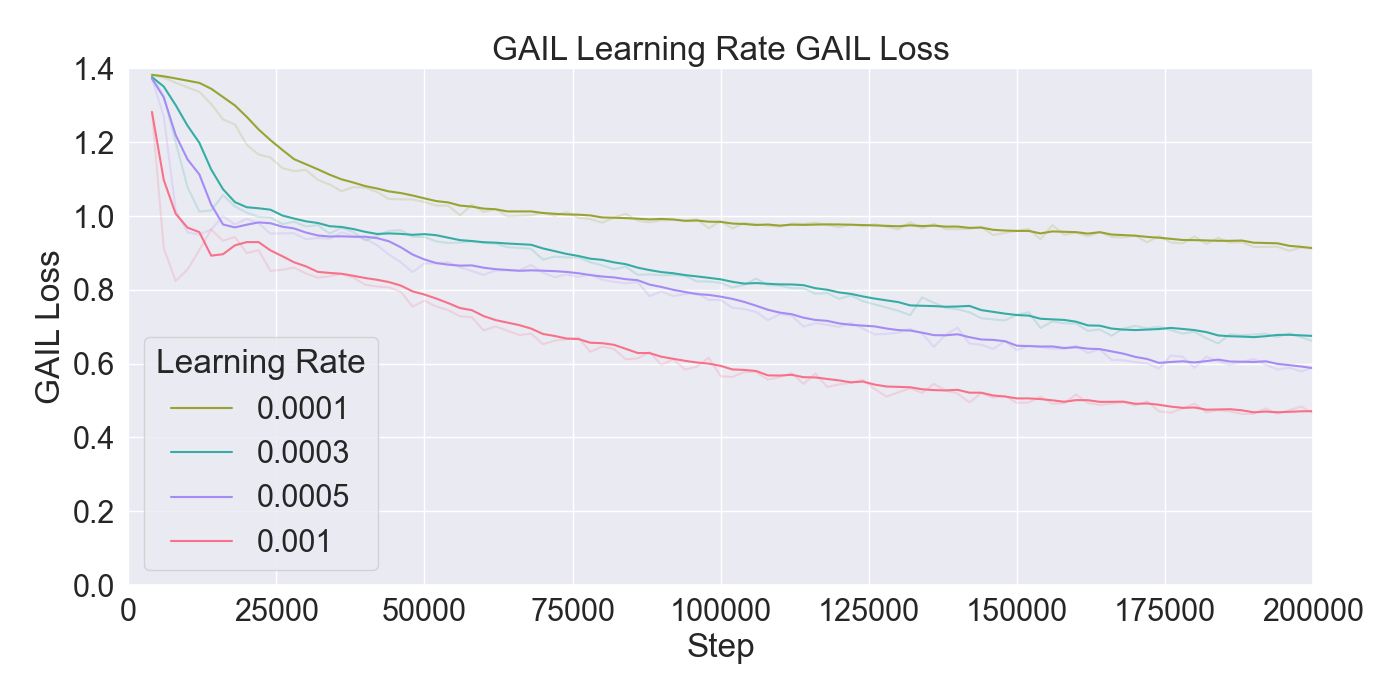
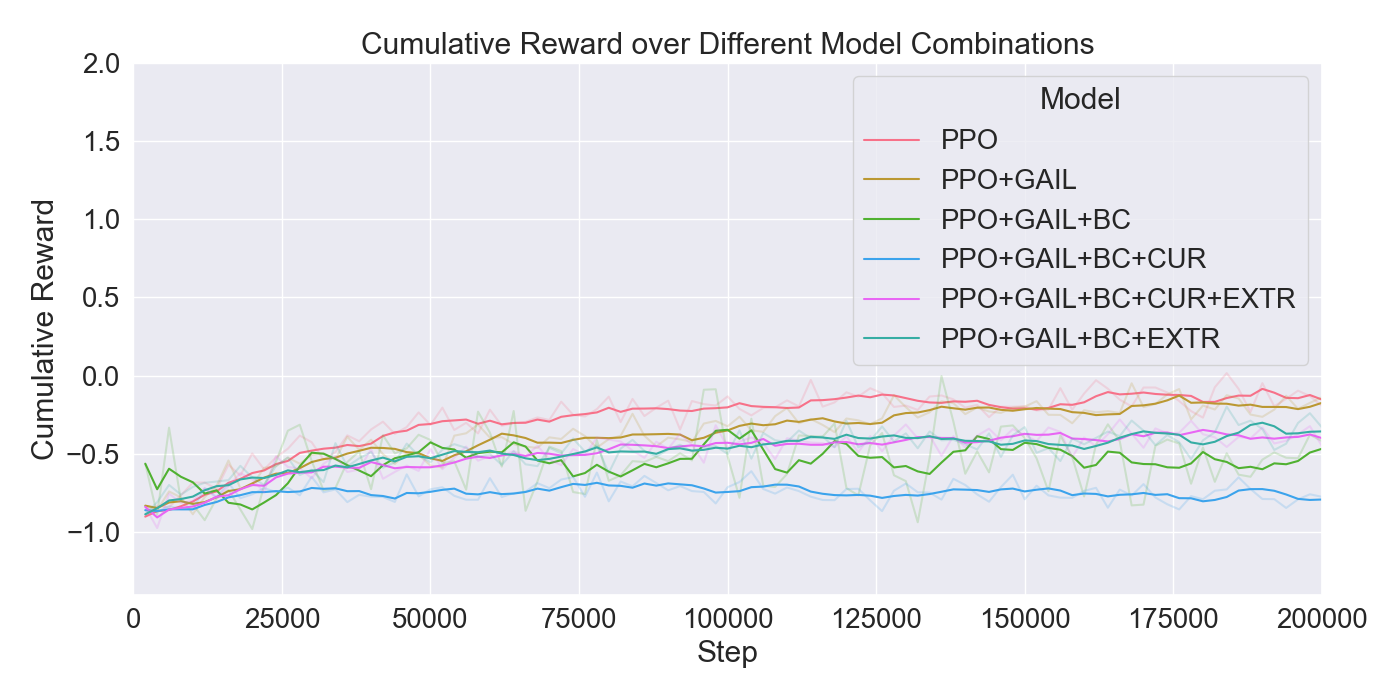
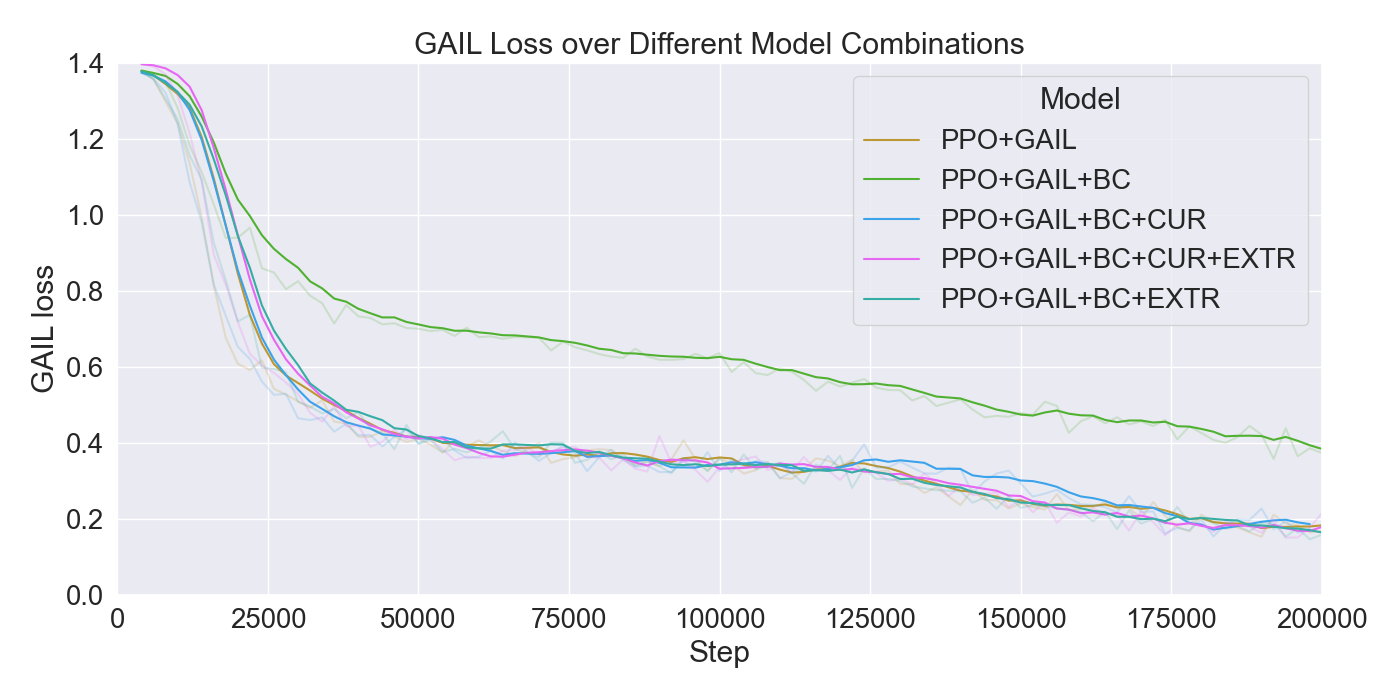
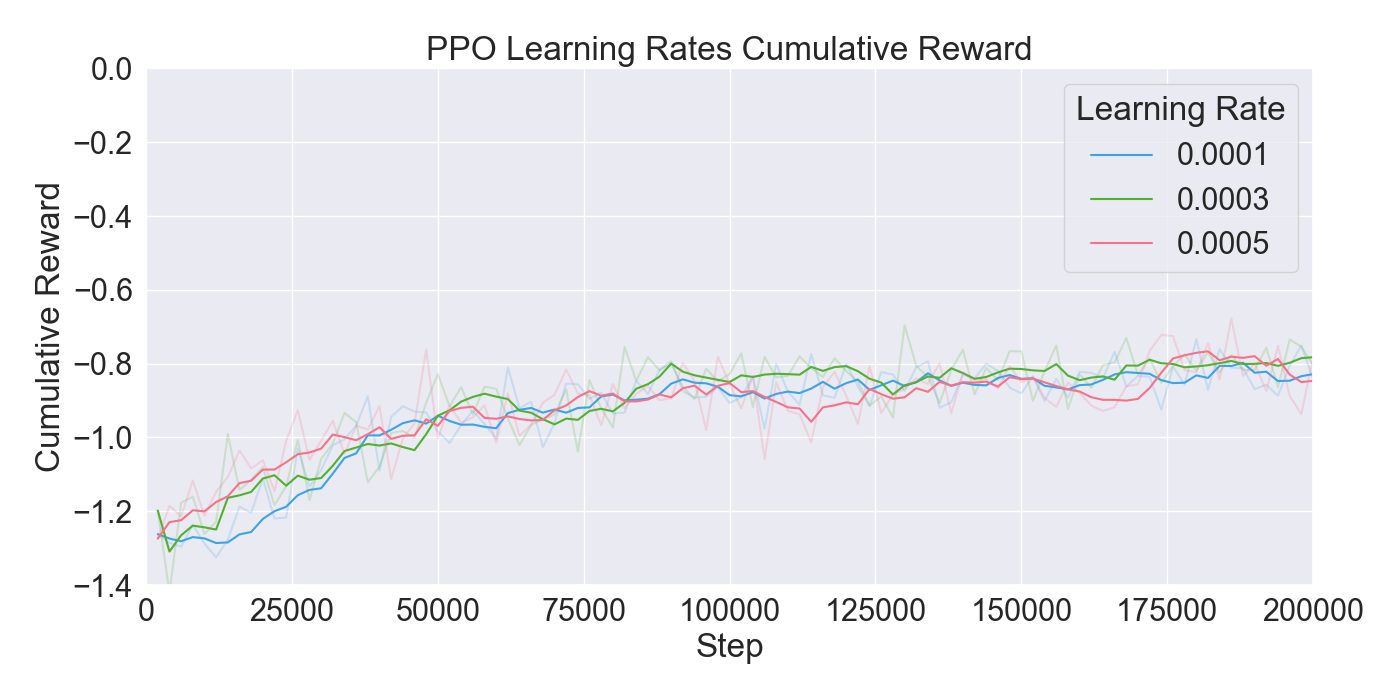
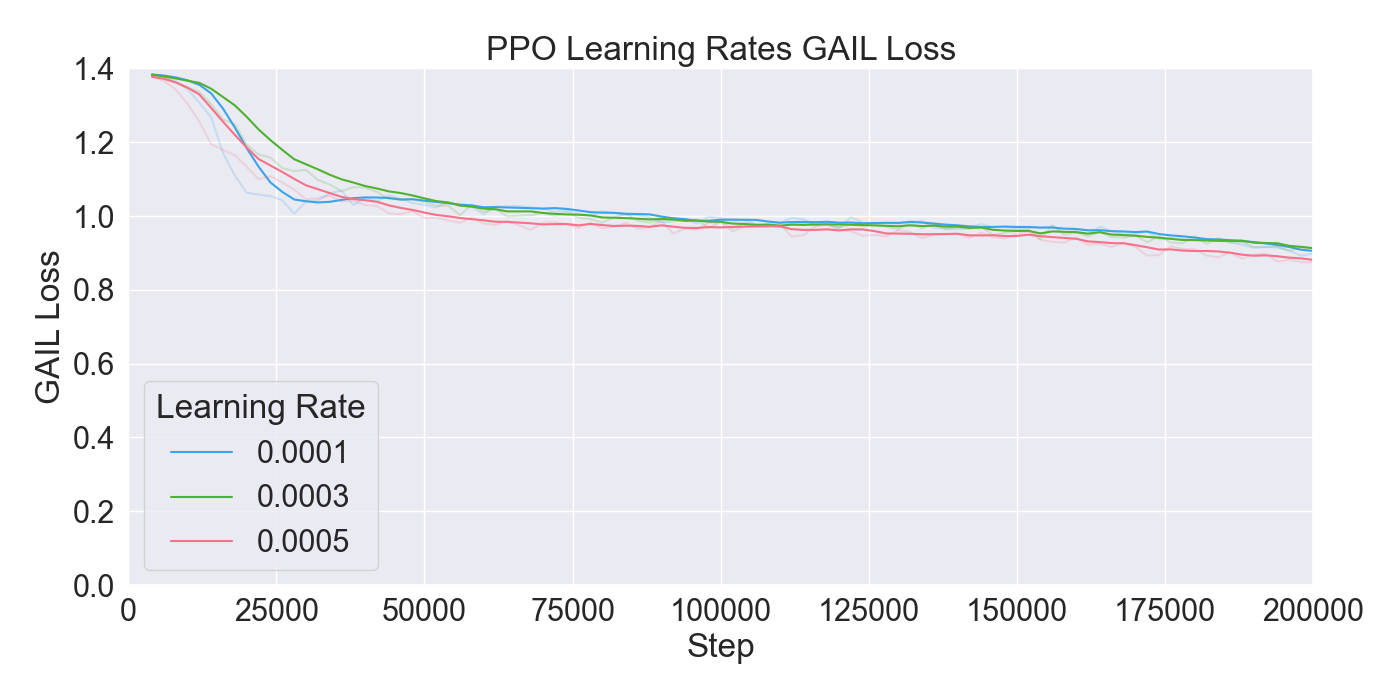
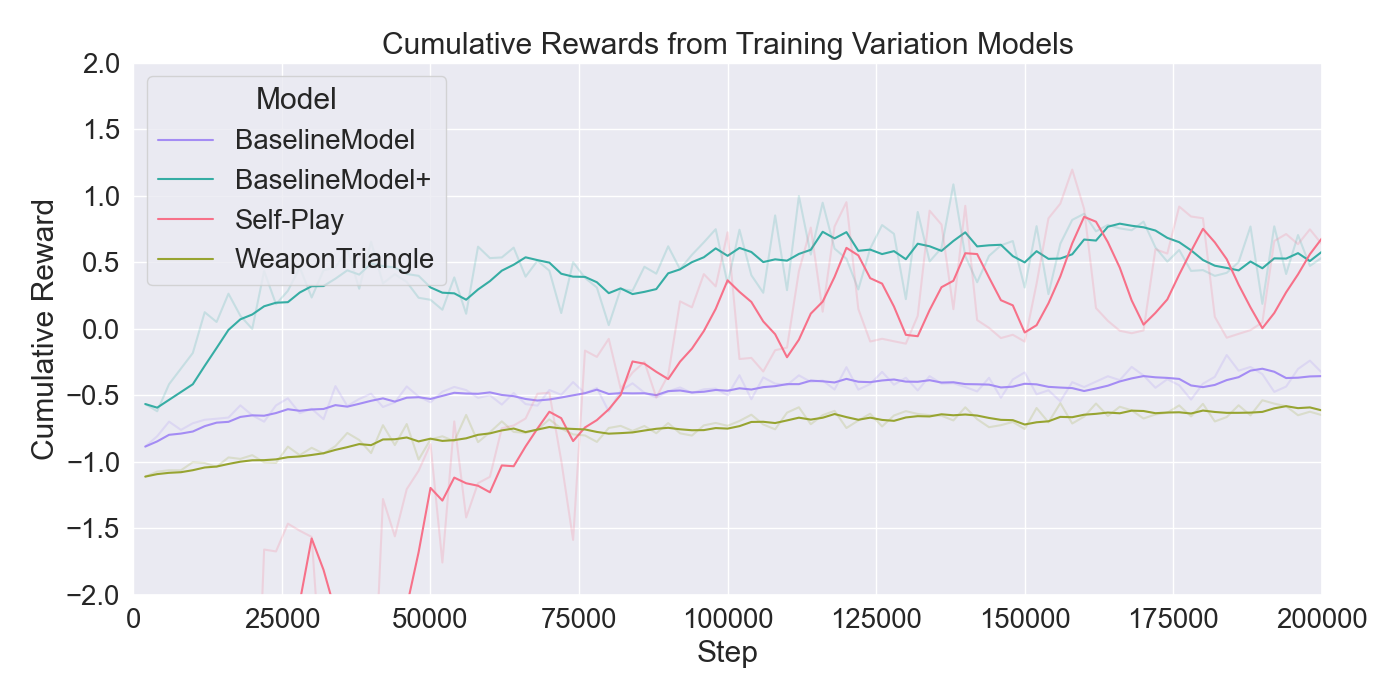
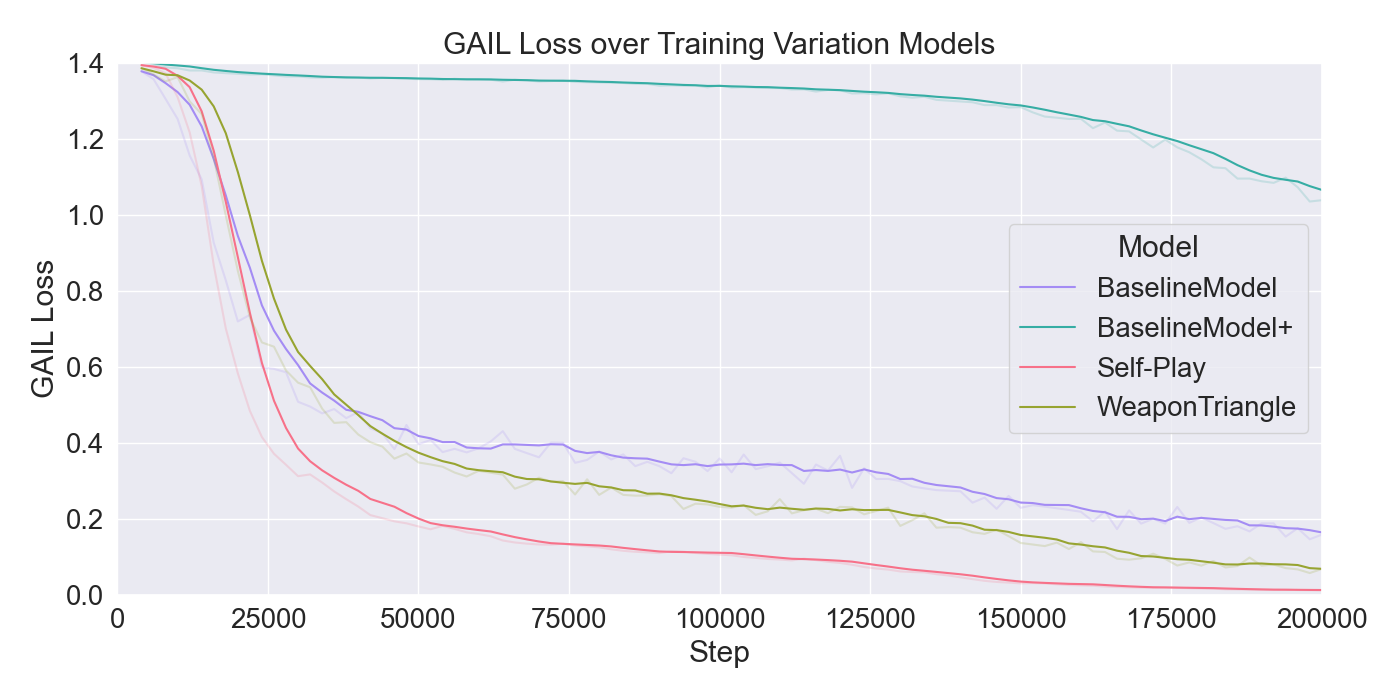
본 논문은 기존 턴제 전략 게임에서 적 AI가 단순히 사전 정의된 규칙이나 난이도에 따라 행동하는 방식을 탈피하여, 플레이어 개별의 전술 패턴을 실시간으로 학습·재현함으로써 게임의 예측 불가능성을 높이고자 한다. 이를 위해 연구팀은 두 단계의 실험 설계를 채택하였다. 첫 번째 단계에서는 ‘어떤 모델이 플레이어 시연을 가장 효과적으로 모방할 수 있는가’라는 질문에 답하기 위해, 최신 모방학습 기법들을 조합하였다. 구체적으로, Generative Adversarial Imitation Learning(GAIL)은 전문가 시연과 에이전트 행동 사이의 분포 차이를 최소화하는 적대적 프레임워크를 제공하고, Behavioral Cloning(BC)은 시연 데이터를 직접 지도학습으로 활용해 초기 정책을 빠르게 형성한다. 여기에 Proximal Policy Optimization(PPO)을 결합함으로써, 정책 업데이트 시 급격한 변화를 억제하고 안정적인 학습을 보장한다. 이러한 하이브리드 접근법은 각각의 기법이 가진 장점을 보완하며, 특히 시연 데이터가 제한적인 상황에서도 견고한 성능을 발휘한다는 점에서 의미가 크다.
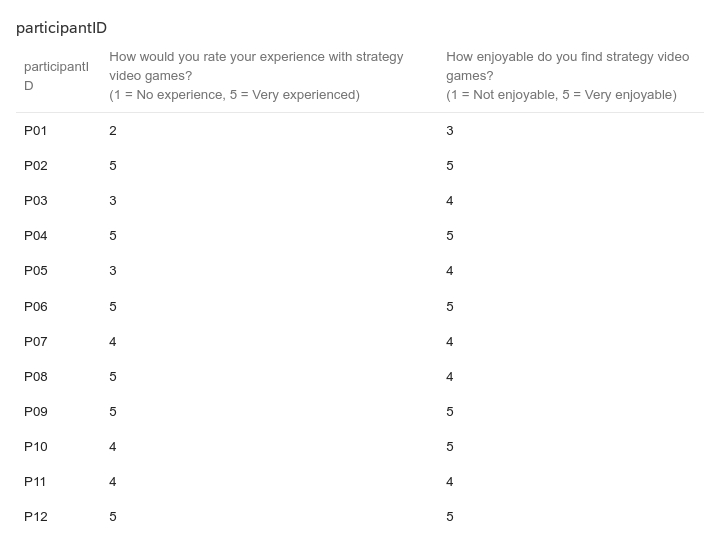
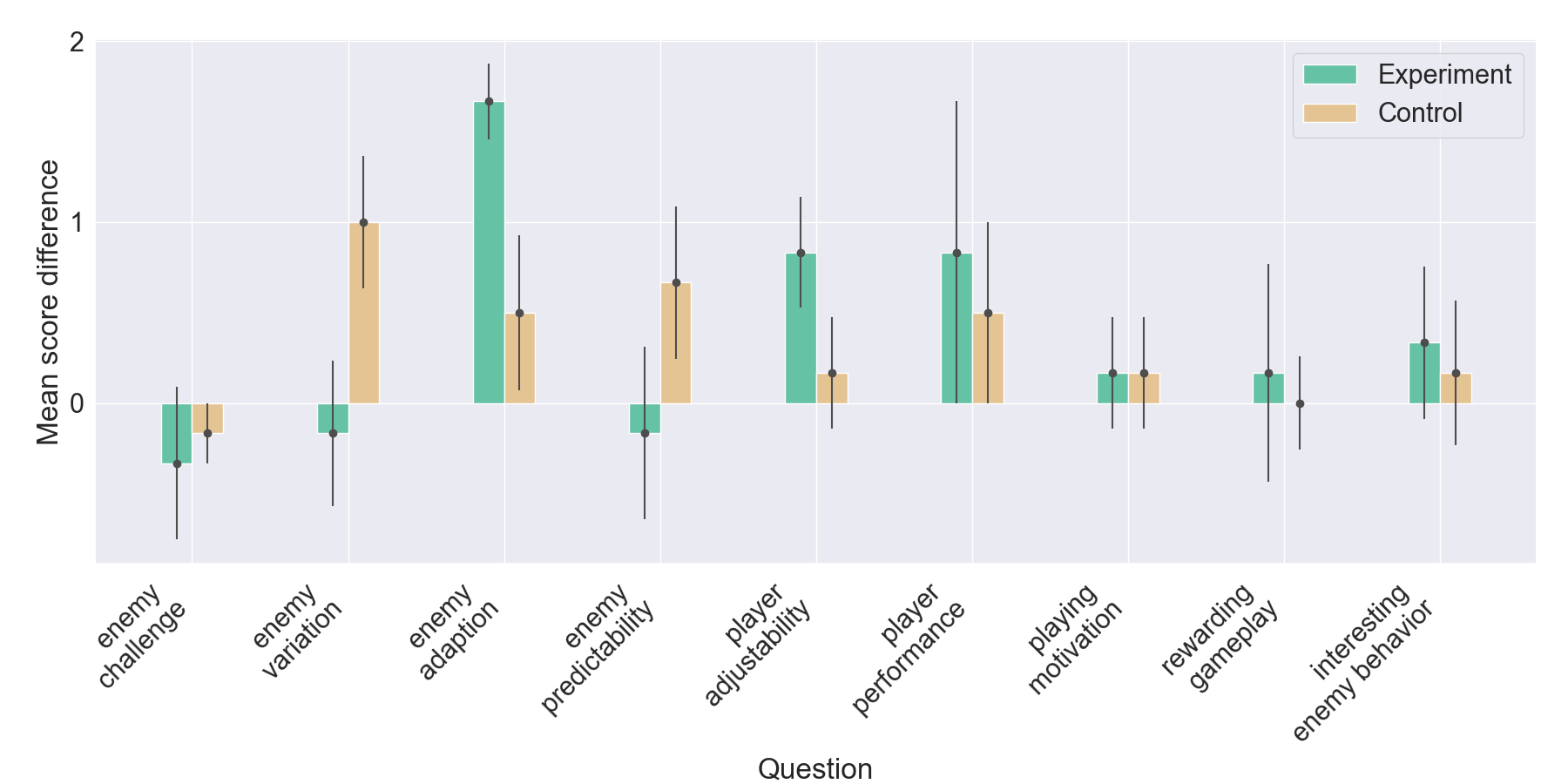
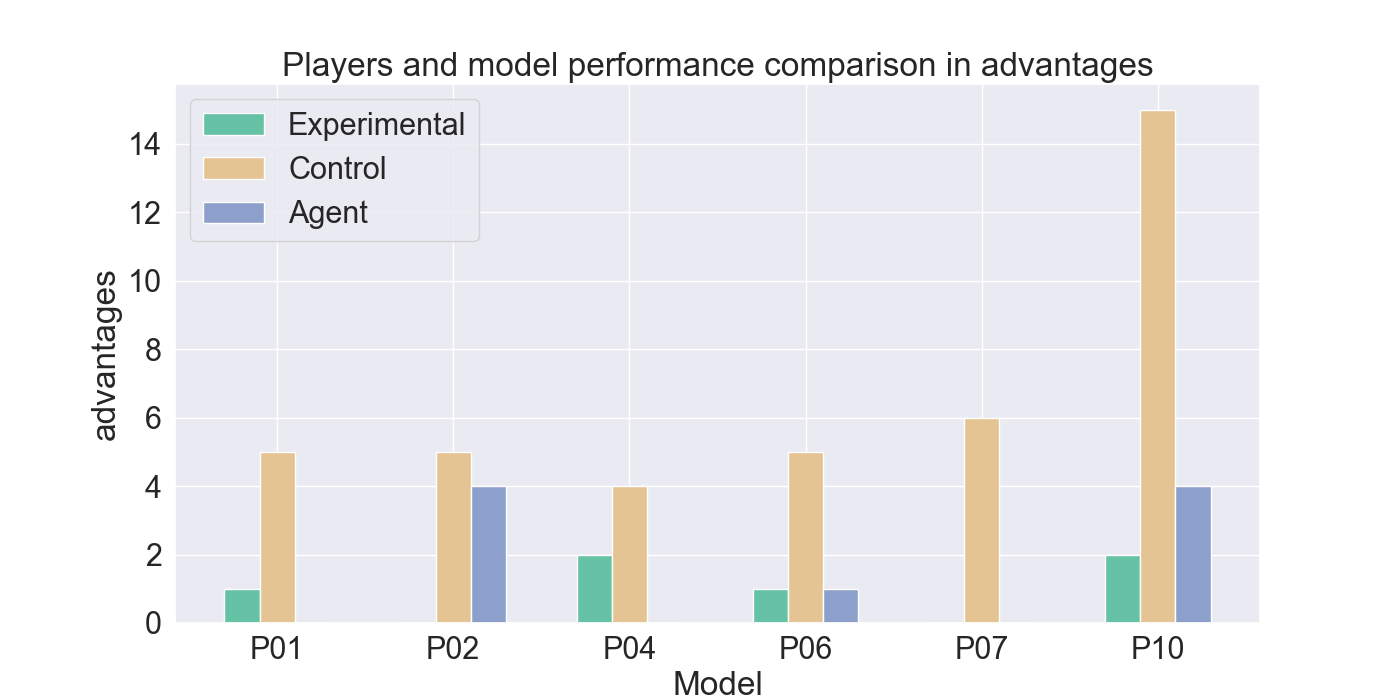
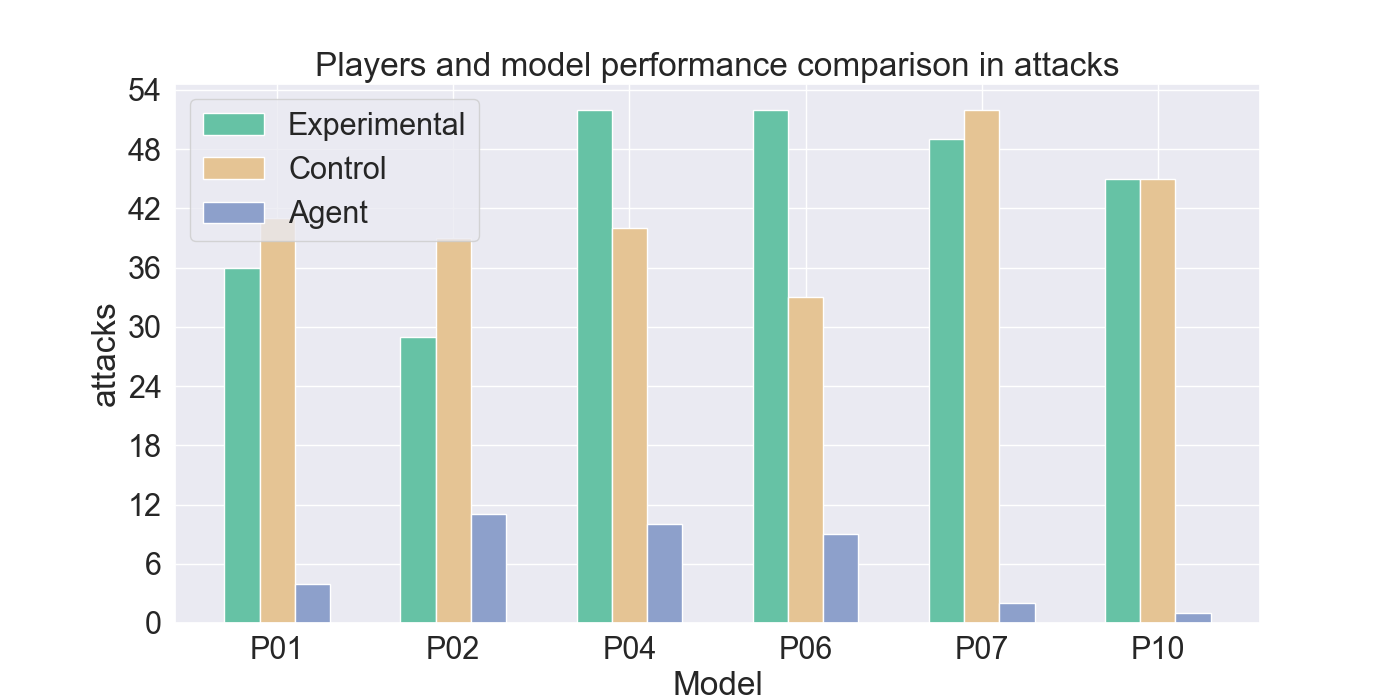
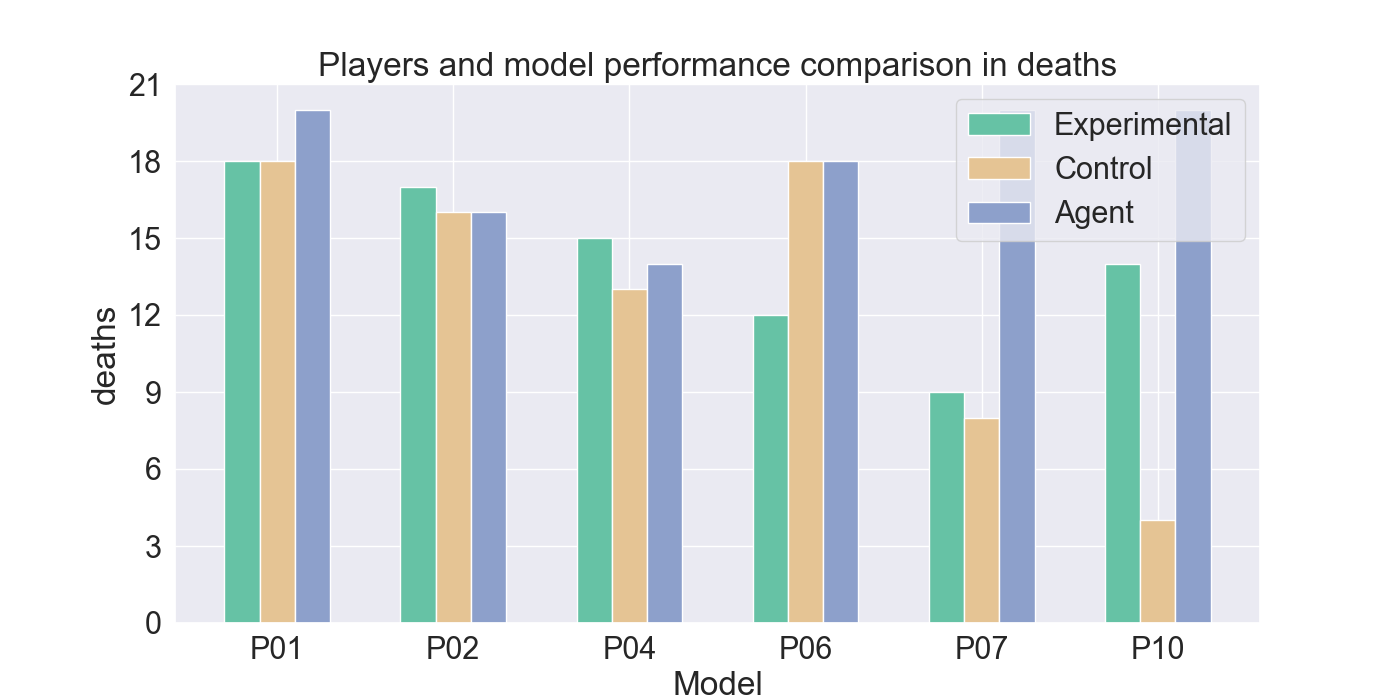
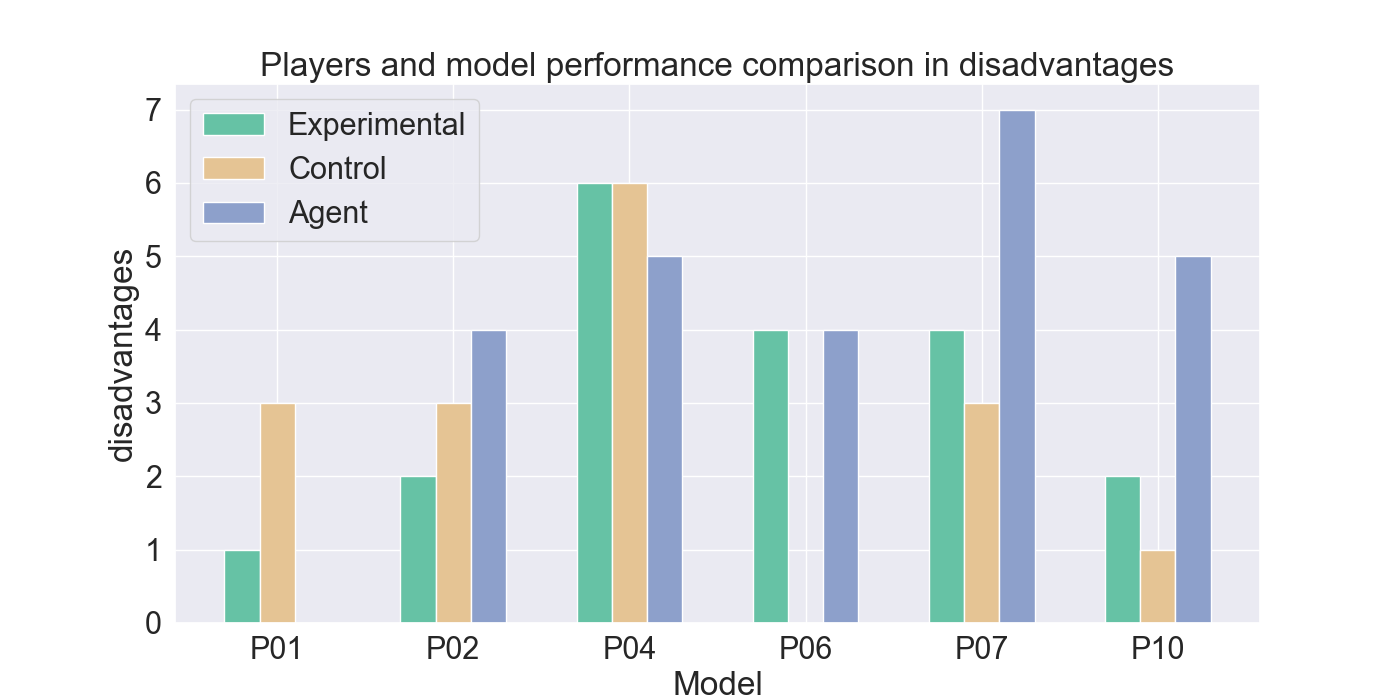
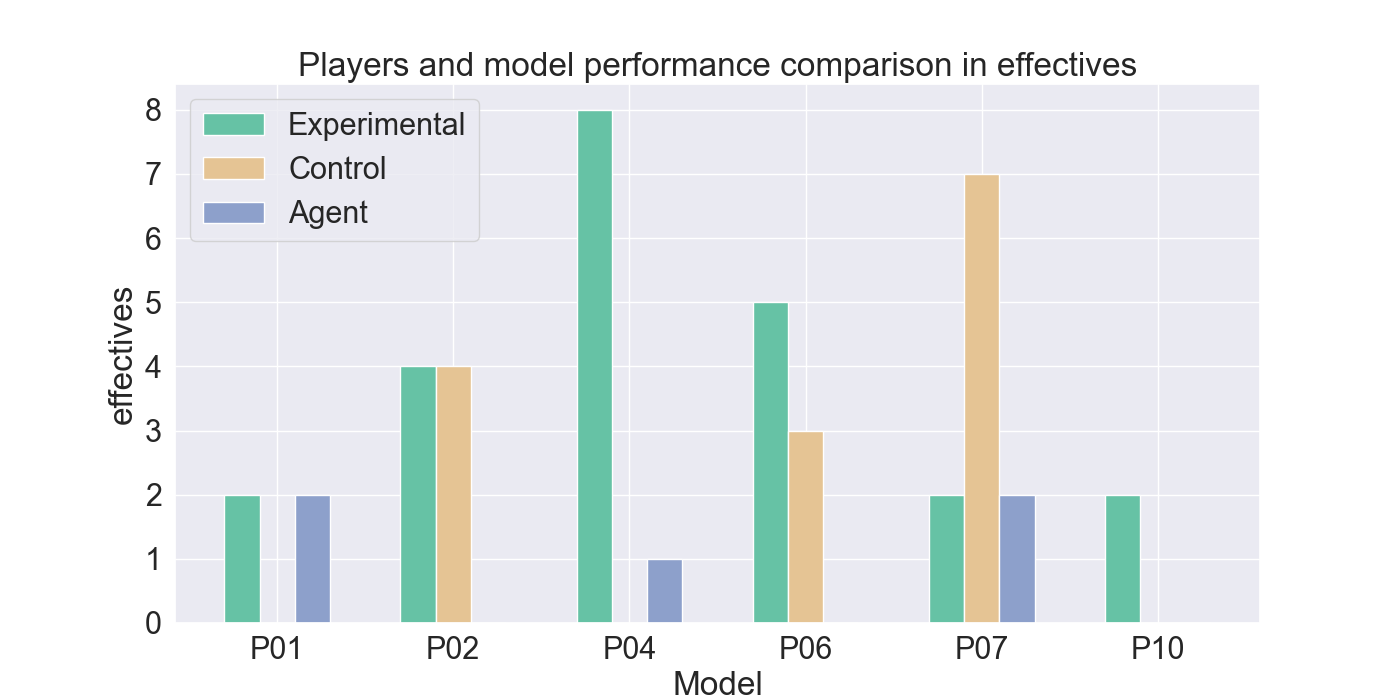
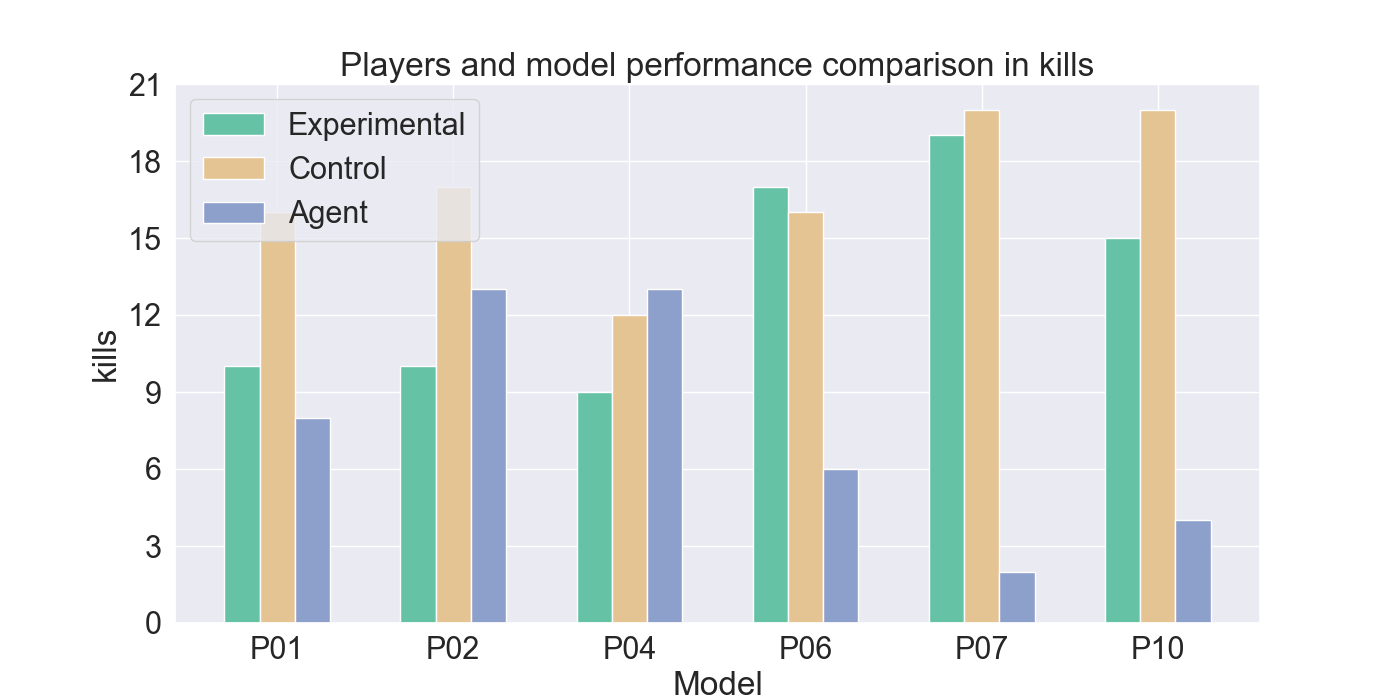
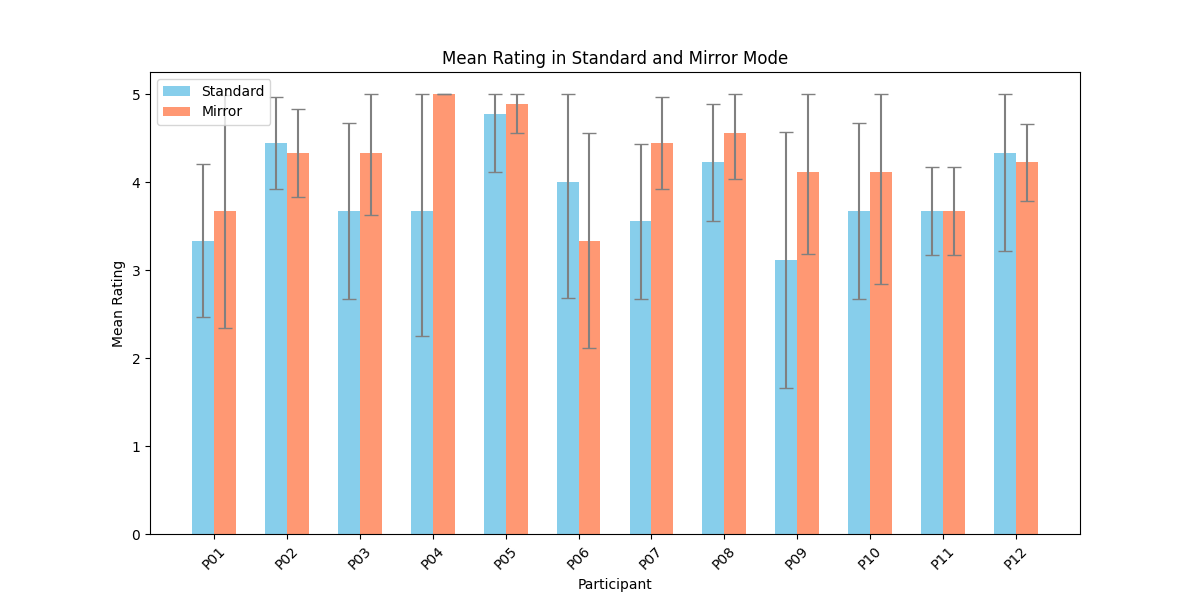
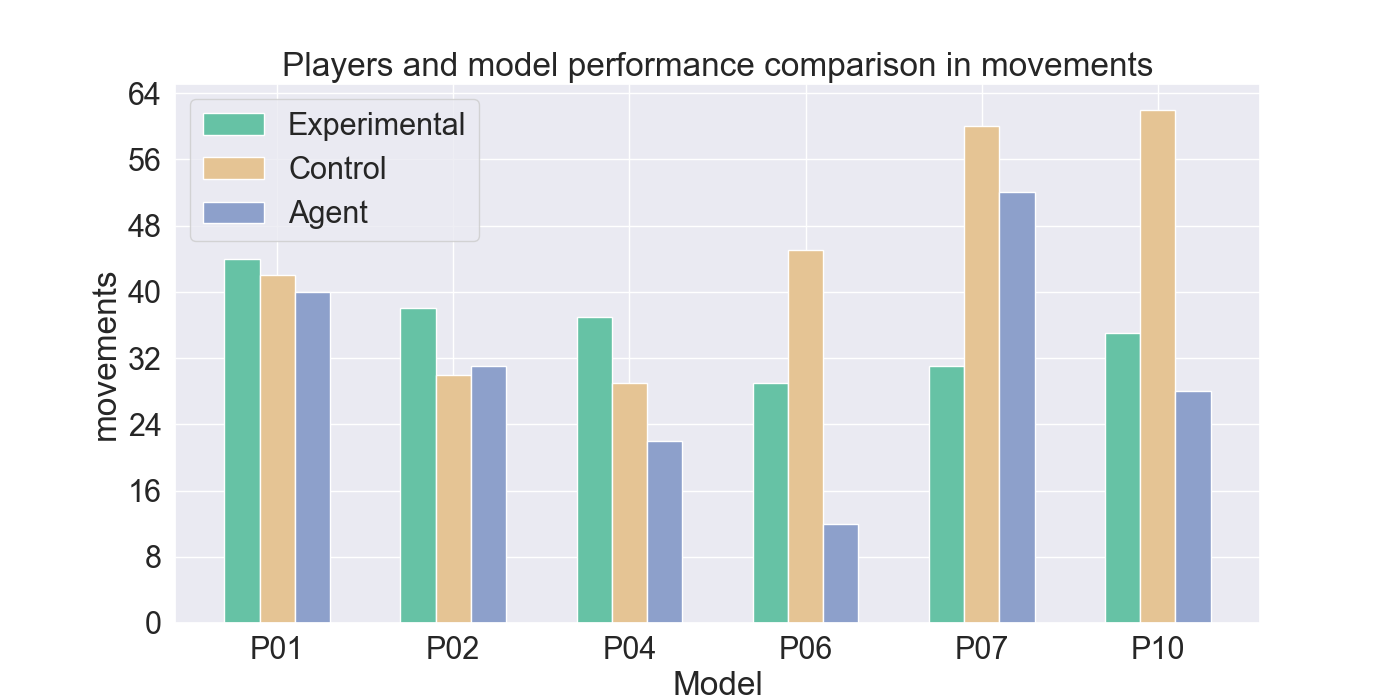
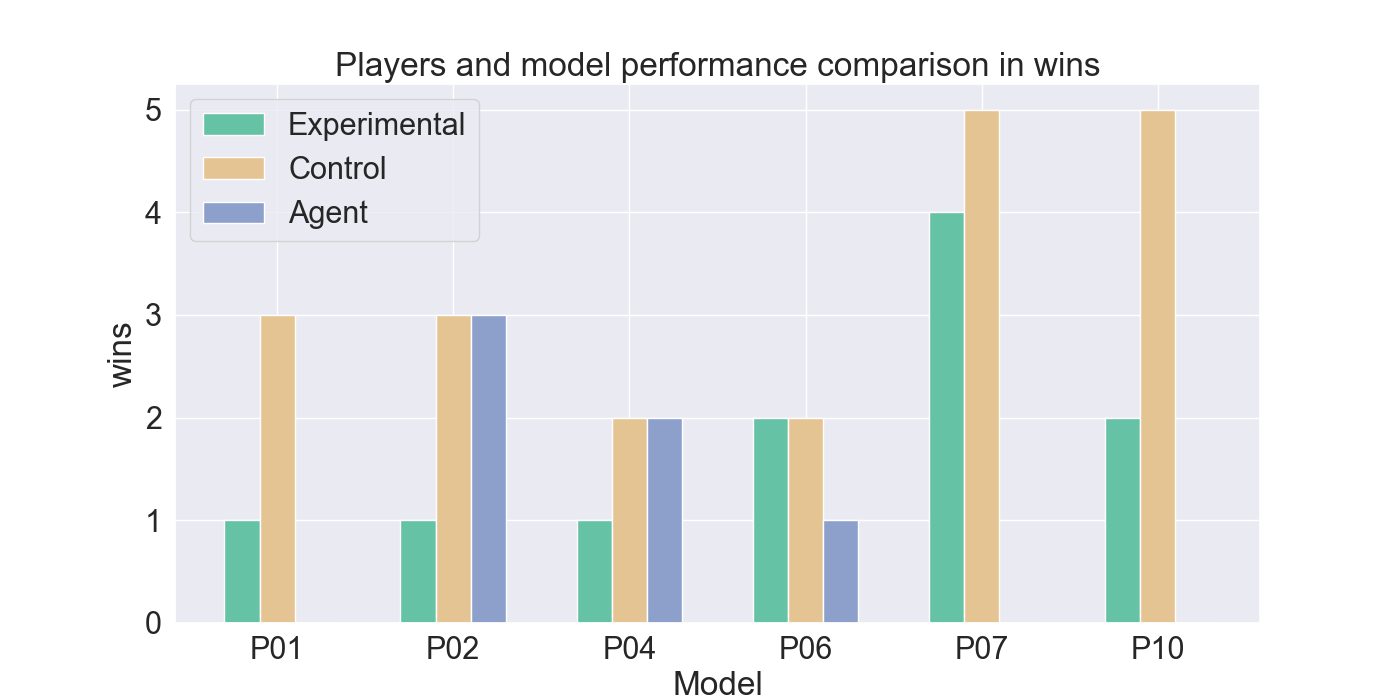
두 번째 단계에서는 실제 플레이어를 대상으로 모델을 평가하였다. 참가자들은 자신의 플레이를 녹화해 시연 데이터로 제공하고, 이후 동일한 시나리오에서 표준 모드와 거울 모드 양쪽을 체험하였다. 결과 분석에 따르면, 모델은 방어적인 움직임—예를 들어 유닛을 후퇴시키거나 방어적인 포지션을 유지하는 행동—을 높은 정확도로 재현하였다. 이는 방어 행동이 비교적 규칙적이고 반복적인 패턴을 보이는 반면, 공격 행동은 상황에 따라 다양한 선택지를 포함하고 있어 학습 난이도가 높아졌기 때문으로 해석된다. 설문 응답에서도 참가자들은 “내가 자주 쓰던 후퇴 전술이 그대로 재현돼서 신선했다”는 긍정적인 피드백을 남겼으며, 거울 모드에 대한 전반적인 만족도가 표준 모드보다 유의미하게 높았다.
이러한 결과는 두 가지 중요한 시사점을 제공한다. 첫째, 적 AI가 플레이어의 방어 전략을 정확히 모방함으로써, 플레이어는 자신의 전술을 지속적으로 재평가하고 변형할 압박을 받는다. 이는 게임 디자인 차원에서 ‘플레이어의 습관에 안주하지 않게 하는 메커니즘’으로 활용될 수 있다. 둘째, 공격 전략 모방의 한계는 현재 모델이 복합적인 의사결정 과정을 충분히 포착하지 못한다는 점을 보여준다. 향후 연구에서는 멀티-에이전트 협업 학습, 장기 보상 설계, 혹은 트랜스포머 기반 시퀀스 모델을 도입해 복잡한 공격 전술을 더 정교하게 학습시키는 방안을 모색할 필요가 있다.
마지막으로, 코드와 설문 데이터를 공개함으로써 재현 가능성을 확보하고, 학계·산업계가 동일한 프레임워크를 기반으로 다양한 게임 장르에 적용해 볼 수 있는 기반을 제공한다는 점도 주목할 만하다.
📄 논문 본문 발췌 (Translation)
Enemy strategies in turn-based games should be surprising and unpredictable. This study introduces Mirror Mode, a new game mode where the enemy AI mimics the personal strategy of a player to challenge them to keep changing their gameplay. A simplified version of the Nintendo strategy video game Fire Emblem Heroes has been built in Unity, with a Standard Mode and a Mirror Mode. Our first set of experiments find a suitable model for the task to imitate player demonstrations, using Reinforcement Learning and Imitation Learning: combining Generative Adversarial Imitation Learning, Behavioral Cloning, and Proximal Policy Optimization. The second set of experiments evaluates the constructed model with player tests, where models are trained on demonstrations provided by participants. The gameplay of the participants indicates good imitation in defensive behavior, but not in offensive strategies. Participant's surveys indicated that they recognized their own retreating tactics, and resulted in an overall higher player-satisfaction for Mirror Mode. Refining the model further may improve imitation quality and increase player's satisfaction, especially when players face their own strategies. The full code and survey results are stored at: https://github.com/YannaSmid/MirrorMode.
턴제 게임에서 적의 전략은 놀라움과 예측 불가능성을 가져야 한다. 본 연구는 적 AI가 플레이어의 개인 전략을 모방하여 플레이어가 지속적으로 게임플레이를 변화시키도록 도전하는 새로운 게임 모드인 ‘거울 모드’를 제안한다. Nintendo의 전략 비디오 게임 Fire Emblem Heroes를 단순화하여 Unity로 구현했으며, 표준 모드와 거울 모드 두 가지를 제공한다. 첫 번째 실험에서는 플레이어 시연을 모방하기 위한 적절한 모델을 찾기 위해 강화 학습과 모방 학습을 활용했으며, Generative Adversarial Imitation Learning, Behavioral Cloning, Proximal Policy Optimization을 결합하였다. 두 번째 실험에서는 참가자들이 제공한 시연 데이터를 기반으로 학습된 모델을 이용해 플레이어 테스트를 수행하였다. 참가자들의 게임플레이 결과는 방어 행동에서는 높은 모방 정확도를 보였으나, 공격 전략에서는 한계가 있음을 나타냈다. 설문 조사에서는 참가자들이 자신의 후퇴 전술이 재현된 것을 인식했으며, 거울 모드에 대한 전반적인 만족도가 더 높게 나타났다. 모델을 추가로 정교화하면 모방 품질이 향상되고, 특히 플레이어가 자신의 전략과 마주할 때 만족도가 더욱 증가할 것으로 기대된다. 전체 코드와 설문 결과는 https://github.com/YannaSmid/MirrorMode
에서 확인할 수 있다.