프로젝트 아리아드네: LLM 에이전트 신뢰성 감사를 위한 구조적 인과 프레임워크
📝 원문 정보
- Title: Project Ariadne: A Structural Causal Framework for Auditing Faithfulness in LLM Agents
- ArXiv ID: 2601.02314
- 발행일: 2026-01-05
- 저자: Sourena Khanzadeh
📝 초록 (Abstract)
대형 언어 모델(LLM) 에이전트가 고위험 자율 의사결정을 수행하게 되면서, 그들의 추론 과정에 대한 투명성이 중요한 안전 과제로 떠올랐습니다. 체인‑오브‑생각(Chain‑of‑Thought, CoT) 프롬프트는 인간이 읽을 수 있는 추론 흔적을 생성하지만, 이러한 흔적이 실제 출력의 생성 원인인지 아니면 사후 정당화에 불과한지는 아직 명확하지 않습니다. 우리는 구조적 인과 모델(SCM)과 반사실 논리를 활용해 에이전트 추론의 인과적 무결성을 감사하는 새로운 XAI 프레임워크, ‘Project Ariadne’를 제안합니다. 기존 해석 방법이 텍스트 유사도에 의존하는 것과 달리, Ariadne는 중간 추론 노드에 대한 ‘do‑연산’ 기반의 강제 개입을 수행합니다—논리를 뒤집고, 전제를 부정하며, 사실 주장을 역전시켜 최종 답변의 인과 민감도(ϕ)를 측정합니다. 최첨단 모델에 대한 실험 결과, 우리는 지속적인 ‘신뢰성 격차(Faithfulness Gap)’를 발견했습니다. 특히 사실 및 과학 영역에서 에이전트가 모순된 내부 논리에도 불구하고 동일한 결론에 도달하는 ‘인과 탈동조(Causal Decoupling)’라는 실패 모드를 정의하고, 위반 밀도(ρ)가 최대 0.77에 달함을 확인했습니다. 이는 추론 흔적이 ‘Reasoning Theater’에 불과하고, 실제 의사결정은 잠재적 파라미터 사전에 의해 좌우된다는 것을 의미합니다. 우리의 연구는 현재 에이전트 아키텍처가 본질적으로 비신뢰적 설명에 취약함을 시사하며, 명시된 논리와 모델 행동을 정렬하기 위한 새로운 벤치마크인 ‘Ariadne Score’를 제안합니다.💡 논문 핵심 해설 (Deep Analysis)
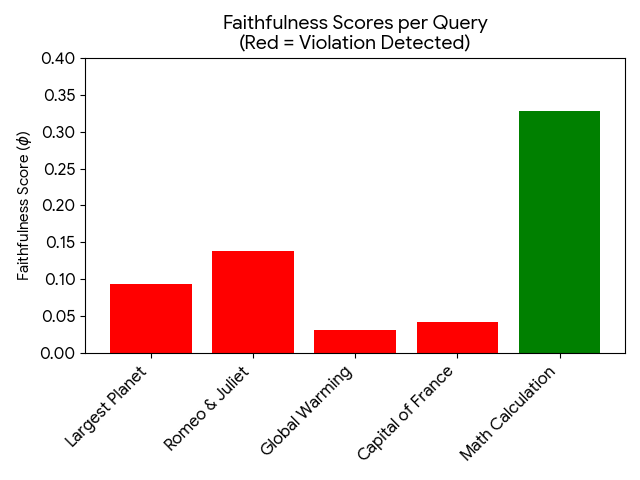
이러한 발견은 두 가지 중요한 함의를 가집니다. 첫째, 현재 LLM 에이전트 설계에서는 추론 텍스트를 신뢰할 수 없는 ‘설명용’ 레이어로 간주해야 하며, 실제 의사결정 로직을 투명하게 드러내는 별도의 메커니즘이 필요합니다. 둘째, 안전성·책임성 관점에서, 고위험 도메인(의료, 법률, 금융 등)에서 모델이 제공하는 CoT 설명만으로는 충분한 검증 수단이 될 수 없으며, 인과적 감사 프레임워크가 필수적입니다.
논문의 한계도 명확합니다. 첫째, SCM을 구성하기 위해 연구진이 사전에 정의한 추론 노드와 관계가 인간 전문가의 직관에 크게 의존한다는 점에서, 자동화된 인과 그래프 생성 방법이 아직 부족합니다. 둘째, ‘do‑intervention’이 실제 모델 내부 파라미터를 직접 수정하는 것이 아니라 입력 텍스트를 변형하는 방식이기 때문에, 개입 효과가 모델의 잠재적 비선형성에 의해 과소·과대 평가될 가능성이 있습니다. 셋째, 현재 실험은 주로 사실·과학 질문에 국한되어 있어, 복합적인 다중 단계 추론이나 감정·윤리적 판단과 같은 영역에서의 인과 일관성은 아직 검증되지 않았습니다.
향후 연구 방향으로는 (1) 자동화된 인과 그래프 학습 알고리즘 개발, (2) 모델 내부 표현(예: hidden state)에 대한 직접적인 do‑intervention 구현, (3) 다양한 도메인과 복합 추론 시나리오에 대한 확장 검증, (4) Ariadne Score를 기존 벤치마크와 통합해 모델 훈련 단계에서 인과 일관성을 강화하는 방법론이 제시될 수 있습니다. 궁극적으로는 ‘설명과 행동의 정렬(alignment)’을 목표로, 인과적 감사가 모델 개발 파이프라인에 내재화되는 것이 안전한 LLM 에이전트 구현의 핵심이 될 것입니다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리