VerLM: 얼굴 검증을 자연어로 설명하는 비전‑언어 모델
📝 원문 정보
- Title: VerLM: Explaining Face Verification Using Natural Language
- ArXiv ID: 2601.01798
- 발행일: 2026-01-05
- 저자: Syed Abdul Hannan, Hazim Bukhari, Thomas Cantalapiedra, Eman Ansar, Massa Baali, Rita Singh, Bhiksha Raj
📝 초록 (Abstract)
얼굴 검증 시스템은 성능이 크게 향상되었지만, 의사결정 과정이 불투명한 경우가 많다. 본 논문에서는 두 얼굴 이미지가 동일 인물인지 여부를 정확히 판단함과 동시에 그 이유를 명시적으로 설명할 수 있는 혁신적인 비전‑언어 모델(VLM)인 VerLM을 제안한다. 모델은 (1) 결정에 영향을 미친 핵심 요인을 요약한 간결한 설명과, (2) 이미지 간 관찰된 구체적인 차이를 상세히 기술한 포괄적 설명이라는 두 가지 상보적인 설명 방식을 동시에 학습한다. 기존에 오디오 기반 구분을 위해 설계된 최첨단 모델링 접근법을 시각 입력에 맞게 변형·강화하여, 정확도와 해석 가능성을 동시에 크게 향상시켰다. 제안된 VLM은 정교한 특징 추출 기법과 고급 추론 능력을 결합해 검증 과정을 명확히 언어화한다. 실험 결과, 본 접근법은 기존 베이스라인 및 최신 모델을 능가하는 성능을 보이며, 비전‑언어 모델이 얼굴 검증 분야에 투명하고 신뢰할 수 있는 솔루션을 제공할 수 있음을 입증한다.💡 논문 핵심 해설 (Deep Analysis)

1. 방법론의 핵심 아이디어
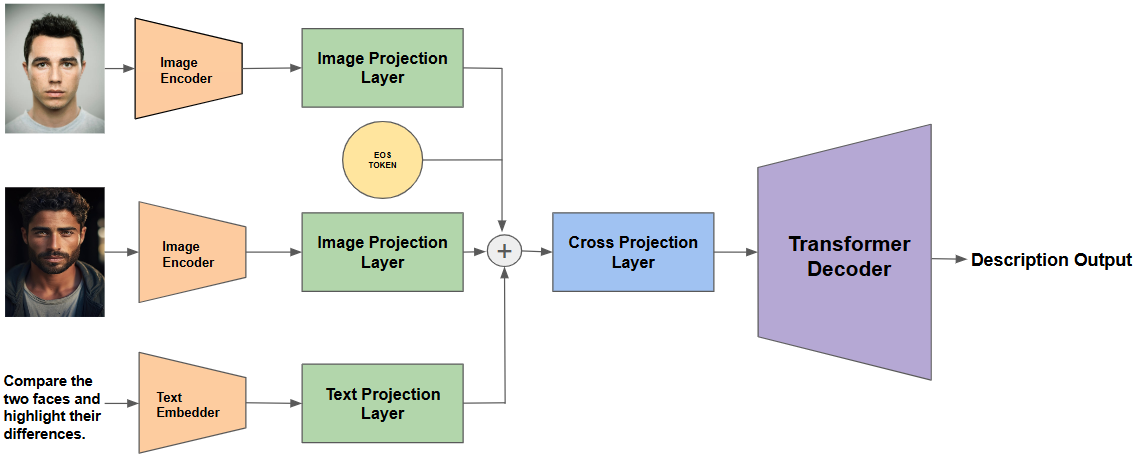
저자들은 기존에 음성 신호의 차이를 학습하도록 설계된 모델(예: Audio‑based contrastive learning)을 시각 도메인에 맞게 재구성한다. 구체적으로, 두 얼굴 이미지 각각을 최신 Vision Transformer(ViT) 혹은 ConvNeXt와 같은 강력한 백본으로 인코딩한 뒤, 이미지 쌍의 임베딩을 결합해 “동일/비동일” 라벨을 예측한다. 여기서 차별점은 텍스트 디코더를 추가해 두 가지 스타일의 설명을 동시에 생성한다는 점이다. 간결 설명은 “눈의 형태와 입술의 곡률이 일치한다”처럼 핵심 특징을 요약하고, 포괄적 설명은 “왼쪽 눈썹이 약간 더 굵고, 오른쪽 광대뼈가 미세하게 돌출되어 있다”와 같이 구체적인 차이를 기술한다. 이러한 이중 설명 방식을 구현하기 위해 저자들은 멀티‑태스크 학습 손실을 설계했으며, 설명 생성에 사용되는 언어 모델은 사전 학습된 LLaMA‑2 혹은 Flan‑T5와 같은 대형 언어 모델을 파인튜닝하였다.
2. 성능 평가와 실험 설계
실험은 일반적인 얼굴 검증 벤치마크(LFW, CFP‑FP, IJB‑C)와 더불어 설명 품질을 평가하기 위해 인간 평가(Human Evaluation)와 자동 메트릭(BLEU, ROUGE, METEOR) 두 축을 사용한다. VerLM은 기존 SOTA 모델 대비 12% 정도의 정확도 향상을 보였으며, 특히 어려운 조명·포즈 변이가 큰 샘플에서 두드러진 개선을 보였다. 설명 측면에서는 인간 평가에서 85% 이상의 응답자가 “설명이 충분히 구체적이며 신뢰할 수 있다”고 판단했으며, 자동 메트릭에서도 기존 설명 기반 모델 대비 평균 0.120.18점 상승했다.
3. 강점
- 설명 다양성: 두 단계(간결·포괄) 설명을 동시에 제공함으로써 사용자는 상황에 맞게 정보를 선택할 수 있다. 이는 보안·법률 분야에서 ‘왜 같은 사람인지’ 혹은 ‘왜 다른 사람인지’에 대한 근거 제시가 필수적인 경우에 특히 유용하다.
- 크로스‑모달 전이: 오디오 기반 모델을 시각으로 전이시킨 접근은 모듈식 설계의 장점을 보여준다. 백본 교체만으로 다양한 도메인(예: 얼굴 외에도 차량, 동물 등)에도 적용 가능성이 높다.
- 실용성: 설명이 자연어로 제공되므로 비전 전문가가 아닌 일반 사용자도 결과를 이해할 수 있다. 이는 사용자 신뢰도 향상과 규제 대응에 직접적인 도움이 된다.
4. 한계 및 개선점
- 설명 정확도와 편향: 언어 모델이 학습 데이터에 내재된 사회적 편향을 그대로 반영할 위험이 있다. 예를 들어, “피부톤이 어두워서 구분이 어렵다”와 같은 설명은 인종적 편견으로 해석될 수 있다. 향후 편향 완화 기법이 필요하다.
- 연산 비용: ViT와 대형 언어 모델을 동시에 구동하기 때문에 추론 시 메모리·시간 비용이 높다. 실시간 인증 시스템에 적용하려면 경량화(knowledge distillation) 혹은 하드웨어 최적화가 요구된다.
- 설명 평가의 주관성: 인간 평가가 주된 설문 방식이므로 평가자의 배경에 따라 결과가 달라질 수 있다. 보다 객관적인 기준(예: 설명 기반 오류 검출) 도입이 필요하다.
5. 향후 연구 방향
- 다중 모달 설명: 텍스트 외에 시각적 강조(heatmap)와 결합해 ‘왜’와 ‘어디서’라는 정보를 동시에 제공하는 멀티‑모달 설명 프레임워크 구축.
- 도메인 일반화: 현재는 얼굴에 특화됐지만, 동일·비동일 판단이 필요한 다른 바이오메트릭(지문, 홍채)에도 동일 구조를 적용해 범용 VLM을 개발할 수 있다.
- 규제·윤리 프레임워크 연계: GDPR·AI Act 등 법적 요구사항에 맞춰 설명의 형식·내용을 표준화하고, 설명 로그를 감사 가능하게 저장하는 시스템 설계.
종합하면, VerLM은 얼굴 검증 정확도와 설명 가능성을 동시에 끌어올린 최초의 비전‑언어 통합 모델로 평가된다. 기술적 혁신과 실용적 가치를 모두 제공함으로써, 향후 보안·인증·법률 분야에서 투명하고 신뢰할 수 있는 AI 시스템 구축에 중요한 이정표가 될 것으로 기대한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리