Title: DatBench: Discriminative, Faithful, and Efficient VLM Evaluations
ArXiv ID: 2601.02316
발행일: 2026-01-05
저자: DatologyAI, :, Siddharth Joshi, Haoli Yin, Rishabh Adiga, Ricardo Monti, Aldo Carranza, Alex Fang, Alvin Deng, Amro Abbas, Brett Larsen, Cody Blakeney, Darren Teh, David Schwab, Fan Pan, Haakon Mongstad, Jack Urbanek, Jason Lee, Jason Telanoff, Josh Wills, Kaleigh Mentzer, Luke Merrick, Parth Doshi, Paul Burstein, Pratyush Maini, Scott Loftin, Spandan Das, Tony Jiang, Vineeth Dorna, Zhengping Wang, Bogdan Gaza, Ari Morcos, Matthew Leavitt
📝 초록 (Abstract)
본 논문은 비전‑언어 모델(VLM)의 평가가 갖추어야 할 세 가지 핵심 기준을 제시한다. 첫째, 평가가 해당 모달리티와 실제 응용에 충실해야 한다(신뢰성). 둘째, 모델 간 성능 차이를 명확히 구분할 수 있어야 한다(차별성). 셋째, 평가에 드는 계산 비용이 효율적이어야 한다(효율성). 이러한 관점에서 기존 벤치마크의 주요 결함을 지적한다. 다중 선택 형식은 추측을 장려하고 실제 사용 사례를 반영하지 못하며, 모델이 향상될수록 조기에 포화된다. 이미지 없이도 답할 수 있는 ‘블라인드 해결 가능’ 질문이 전체 평가의 70%까지 차지하고, 라벨 오류나 모호한 샘플이 데이터셋의 42%까지를 오염시킨다. 또한 최첨단 모델을 평가하는 데 소요되는 연산량이 개발 비용의 약 20%를 차지할 정도로 비효율적이다. 저자들은 기존 벤치마크를 변환·필터링하여 신뢰성과 차별성을 높이고 계산량을 줄이는 방법을 제안한다. 예를 들어, 다중 선택 문제를 생성형 과제로 전환하면 성능 격차가 최대 35%까지 드러난다. 블라인드 해결 가능 샘플과 라벨 오류를 제거하면 평가의 차별력이 강화되고 동시에 연산 비용이 크게 감소한다. 최종적으로 33개의 데이터셋과 9가지 VLM 능력을 포괄하는 정제된 평가 모음인 DATBENCH‑FULL과, 원본 대비 평균 13배(최대 50배) 빠른 속도를 유지하면서 차별력을 거의 동일하게 보존하는 서브셋 DATBENCH을 공개한다. 이 연구는 VLM이 지속적으로 확장됨에 따라 평가 방법을 보다 엄격하고 지속 가능하게 만들기 위한 로드맵을 제공한다.
💡 논문 핵심 해설 (Deep Analysis)
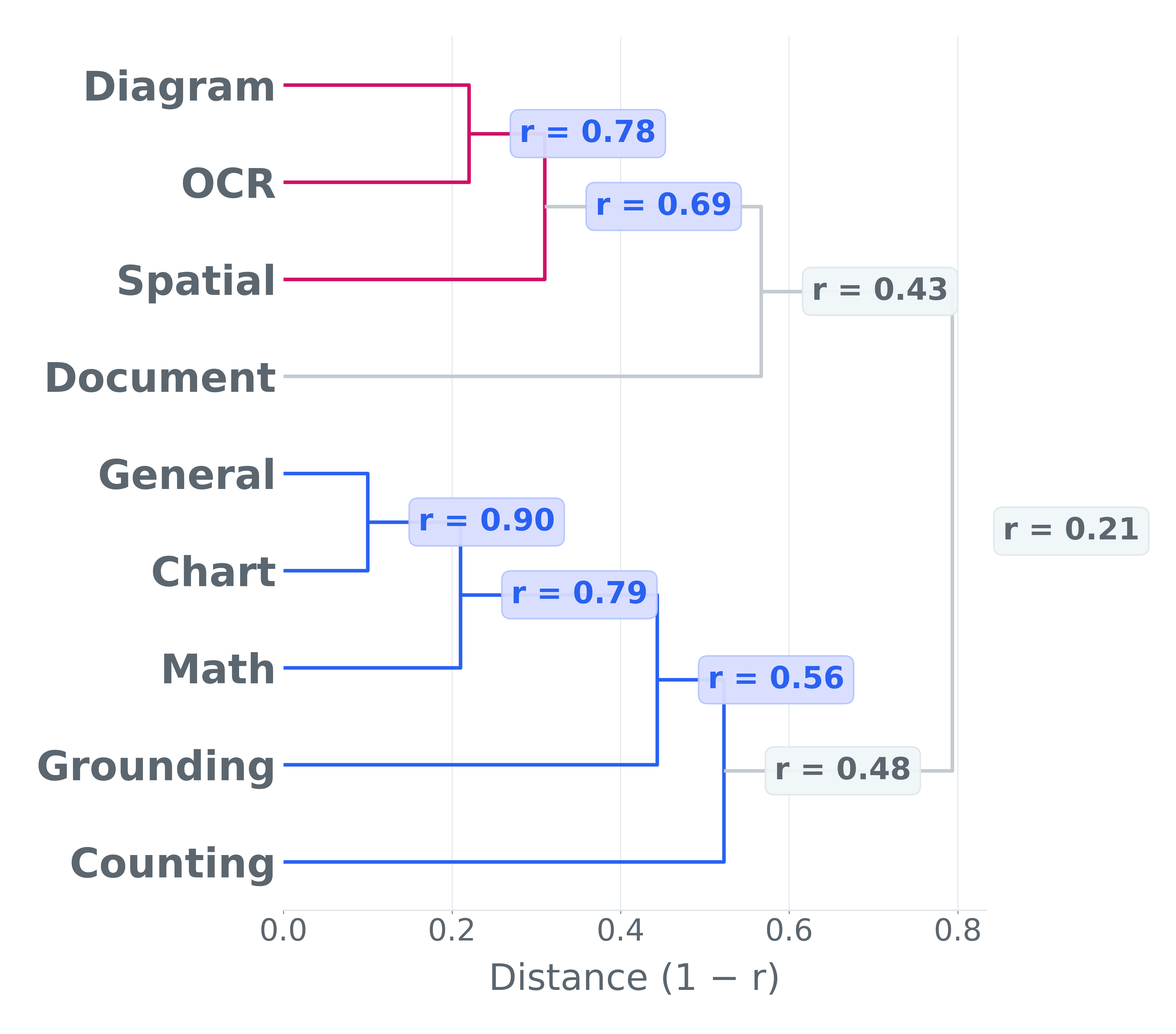
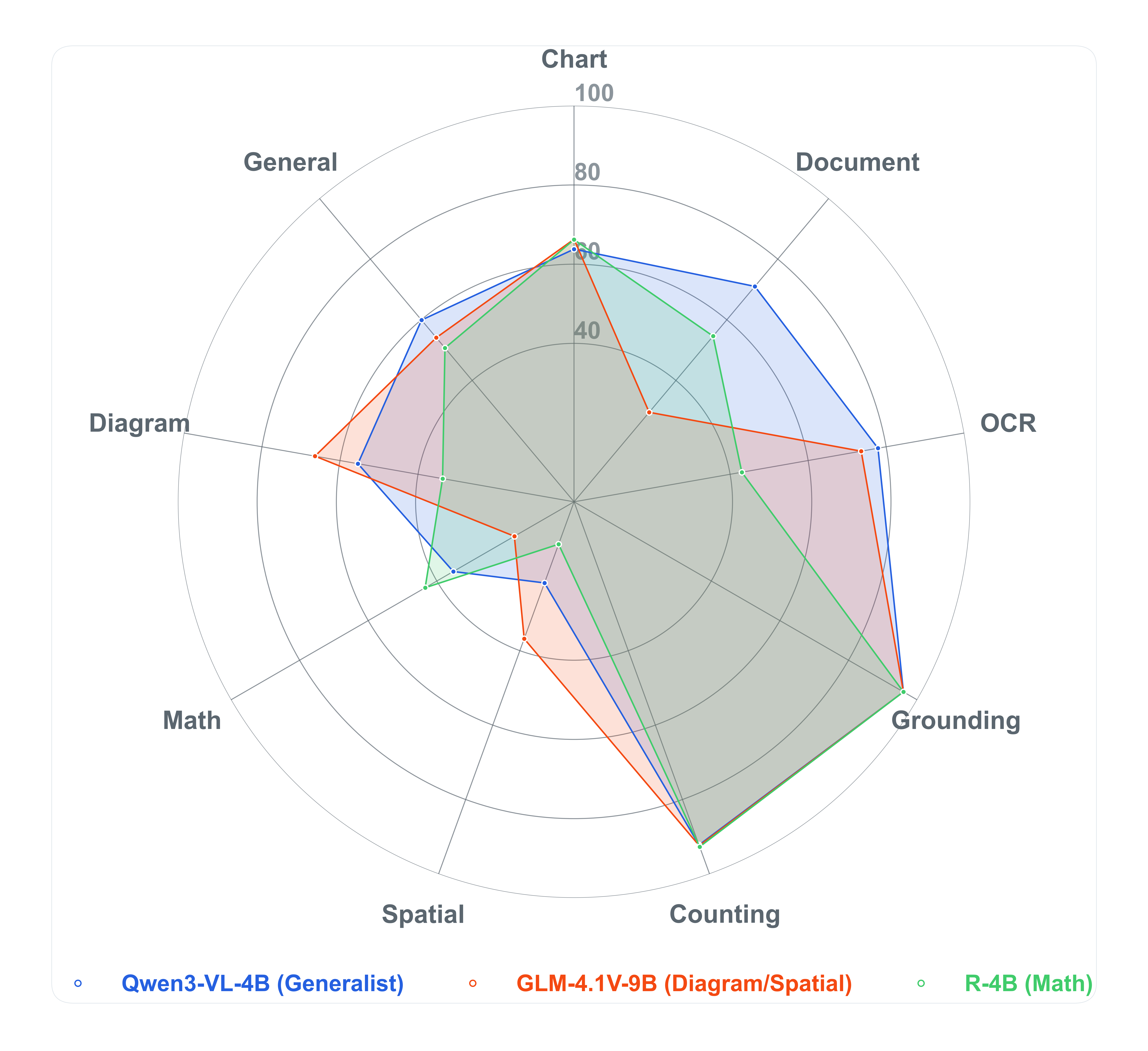
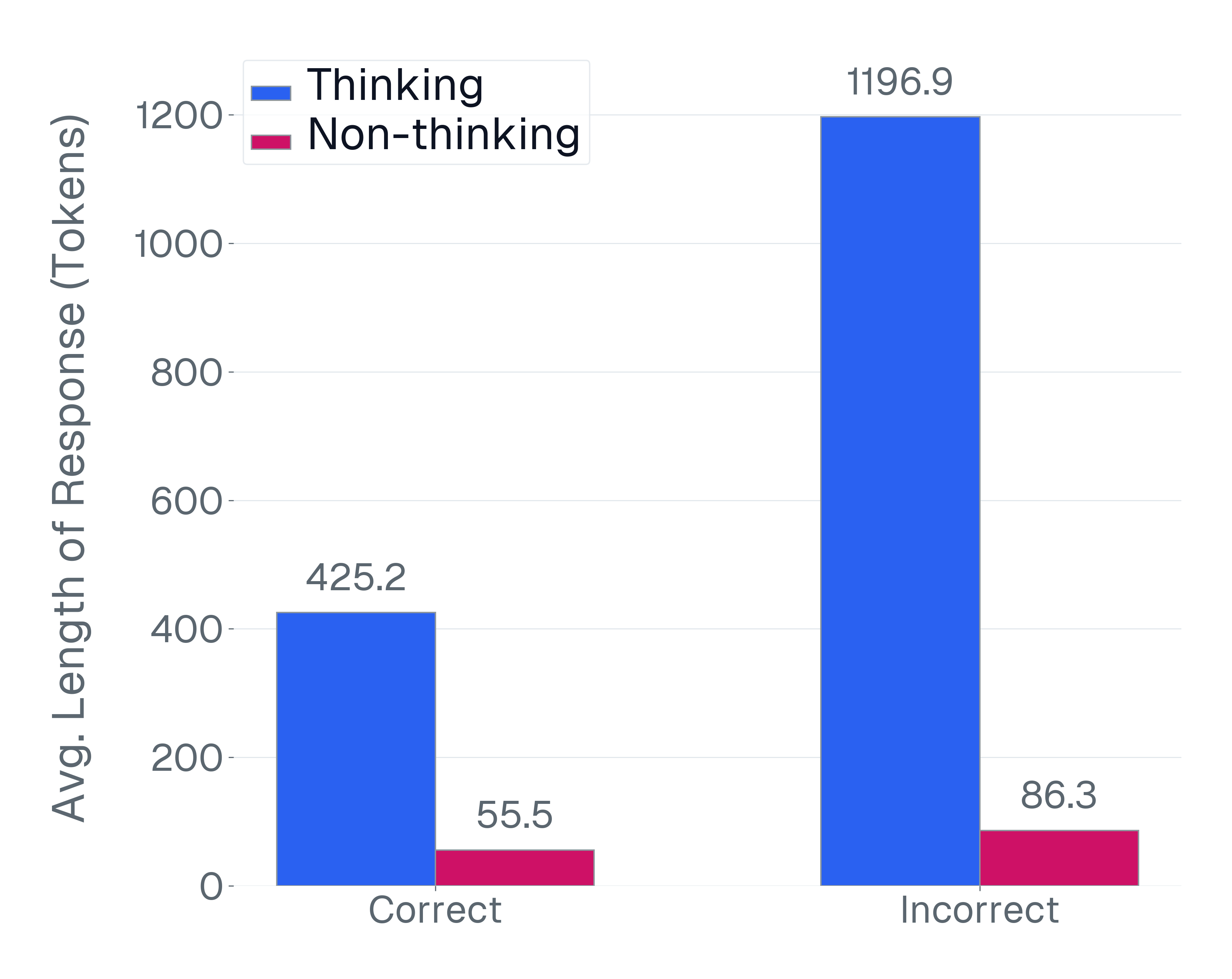
Vision‑Language Model(VLM)은 이미지와 텍스트를 동시에 이해하고 생성하는 복합 인공지능으로, 최근 몇 년간 GPT‑4V, Gemini‑Pro 등 급격히 성능이 향상되고 있다. 그러나 이러한 모델을 실제 서비스에 적용하기 위해서는 “얼마나 잘 작동하는가”를 객관적으로 측정할 수 있는 평가 체계가 필수적이다. 논문은 평가 체계가 가져야 할 세 가지 ‘desiderata’를 명확히 정의한다. 첫 번째 ‘faithfulness(신뢰성)’는 평가가 모델이 실제로 수행해야 할 작업과 일치해야 함을 의미한다. 예를 들어, 이미지 캡션 생성 모델을 텍스트‑전용 퀴즈에 시험한다면 모델이 이미지 정보를 활용하지 못하므로 평가가 왜곡된다. 두 번째 ‘discriminability(차별성)’는 서로 다른 수준의 모델을 구분할 수 있는 민감도를 말한다. 현재 널리 쓰이는 다중 선택(MCQ) 형식은 정답 후보가 제한돼 있어 모델이 추측만으로도 높은 점수를 받을 수 있다. 모델 성능이 향상될수록 정답률이 급격히 포화돼 미세한 차이를 포착하지 못한다는 점이 큰 문제다. 세 번째 ‘efficiency(효율성)’는 평가에 소요되는 연산량과 비용을 의미한다. 최신 VLM은 수십억 파라미터를 갖고 있어 한 번의 추론에 수 초에서 수 분이 걸리며, 대규모 벤치마크를 여러 번 실행하면 전체 연구 개발 비용의 상당 부분을 차지한다.
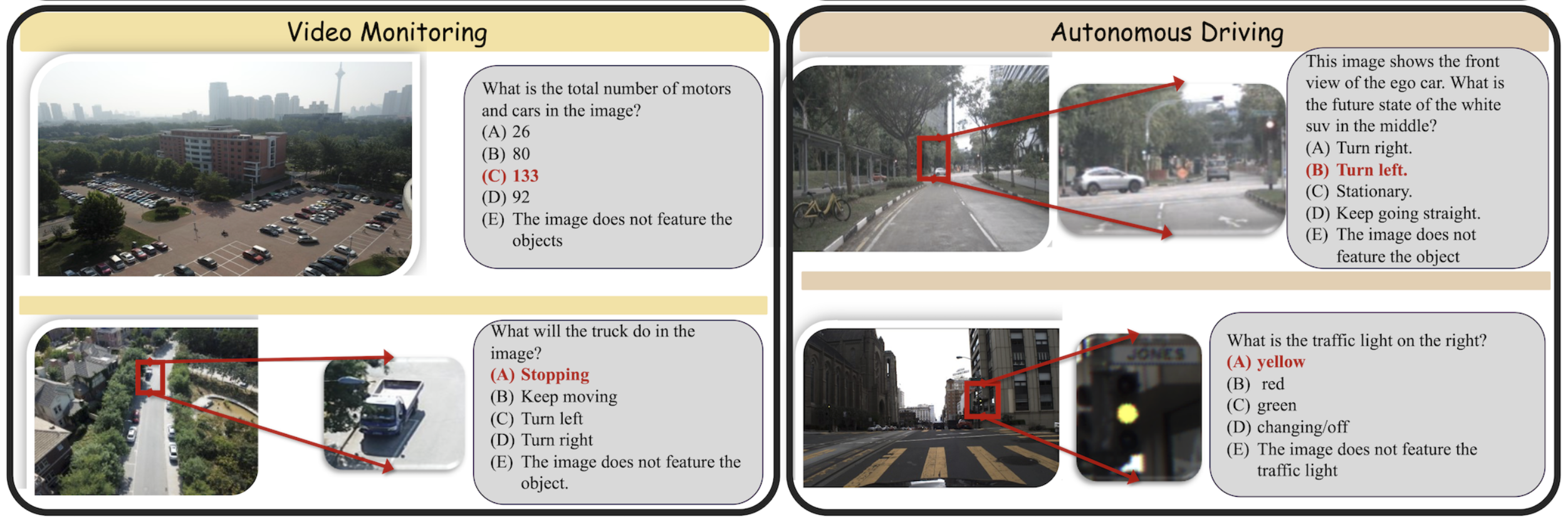
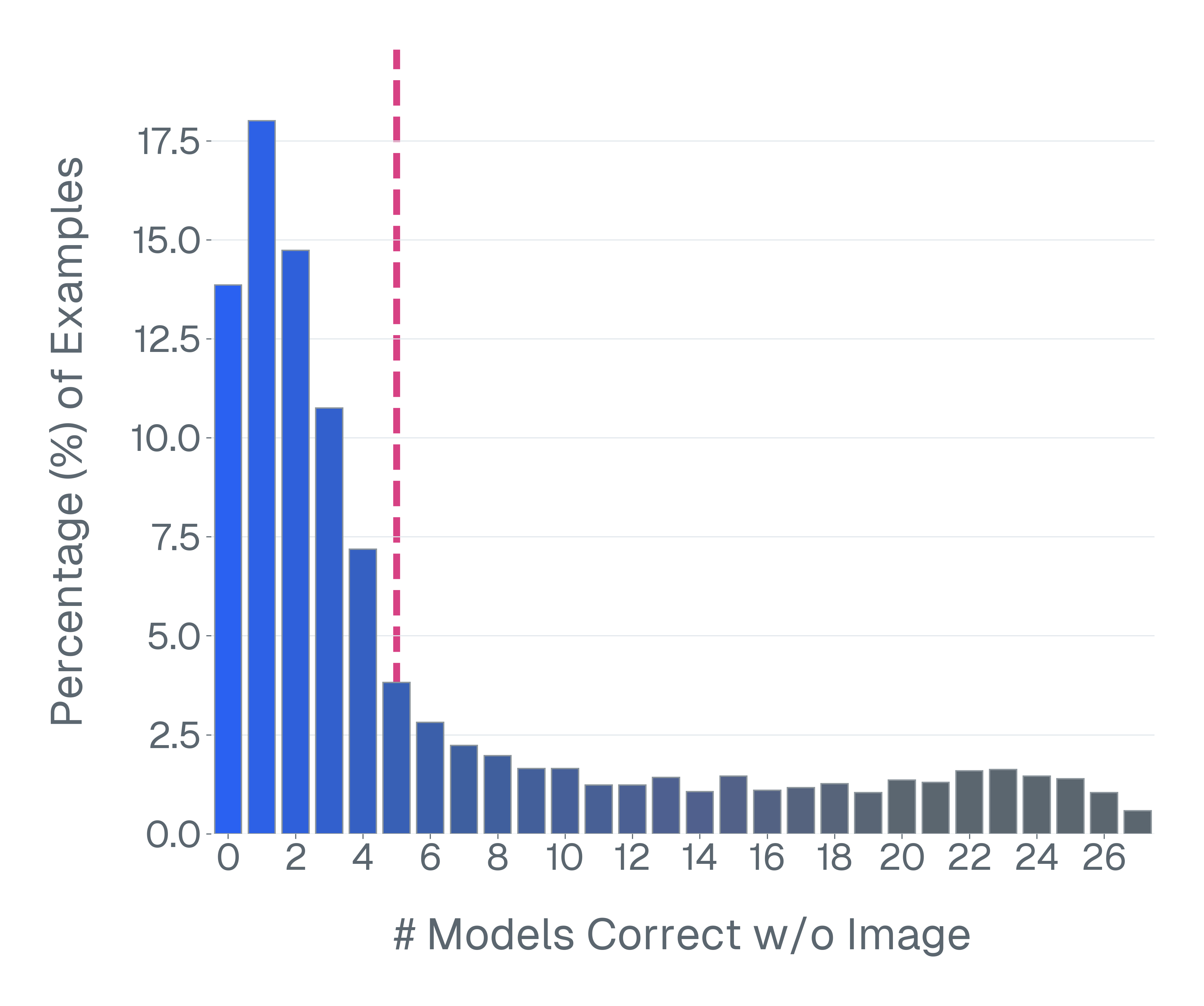
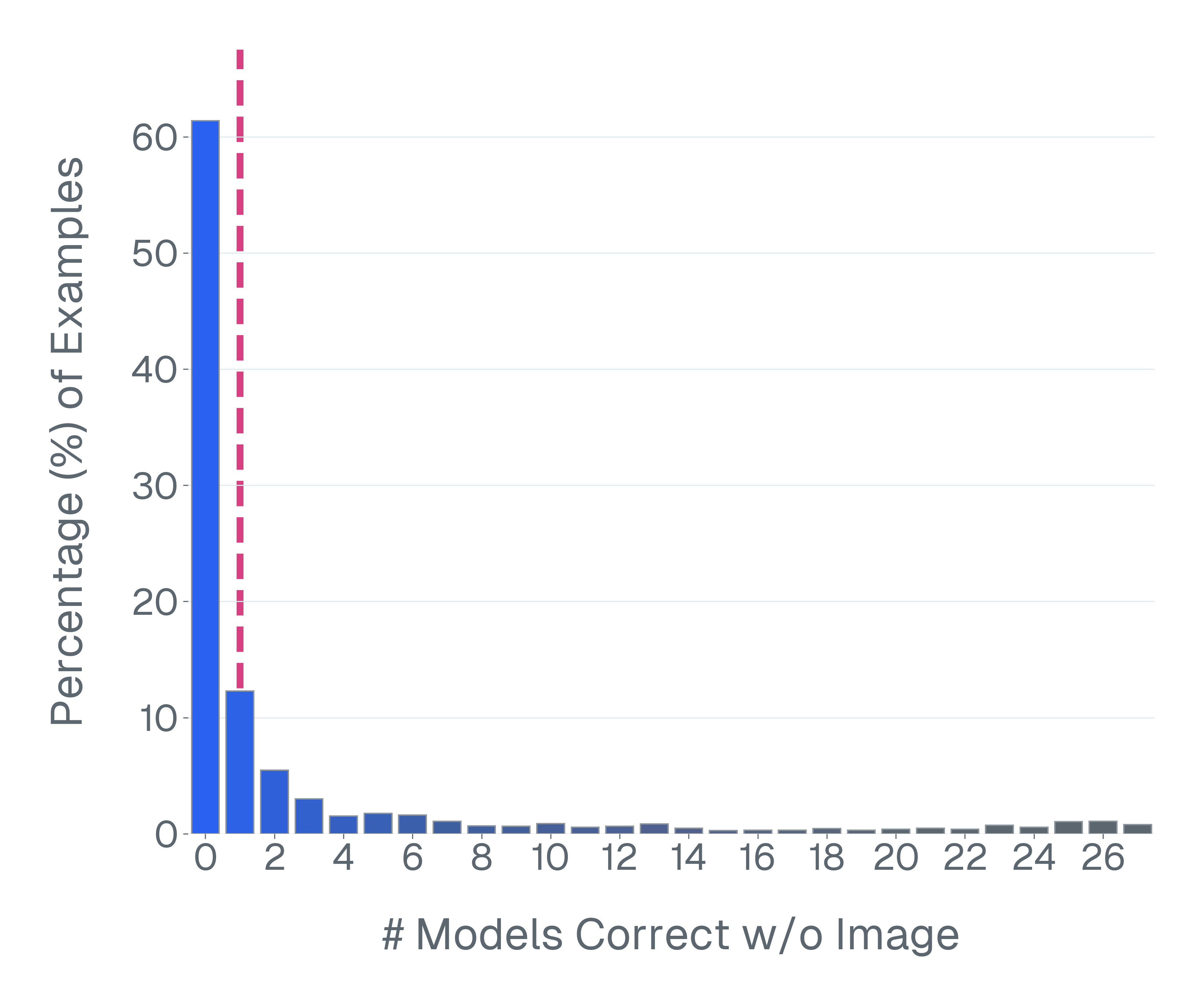
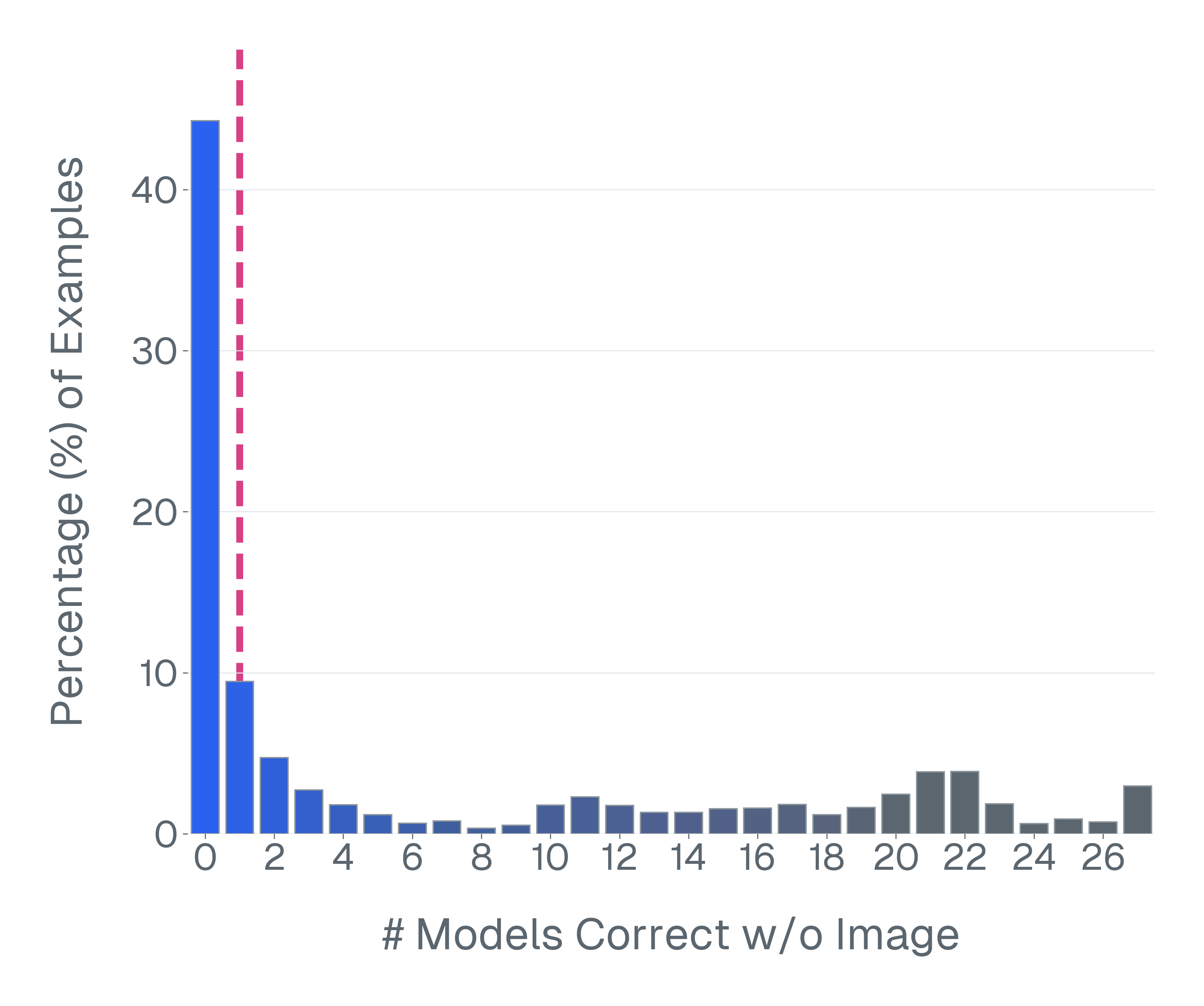
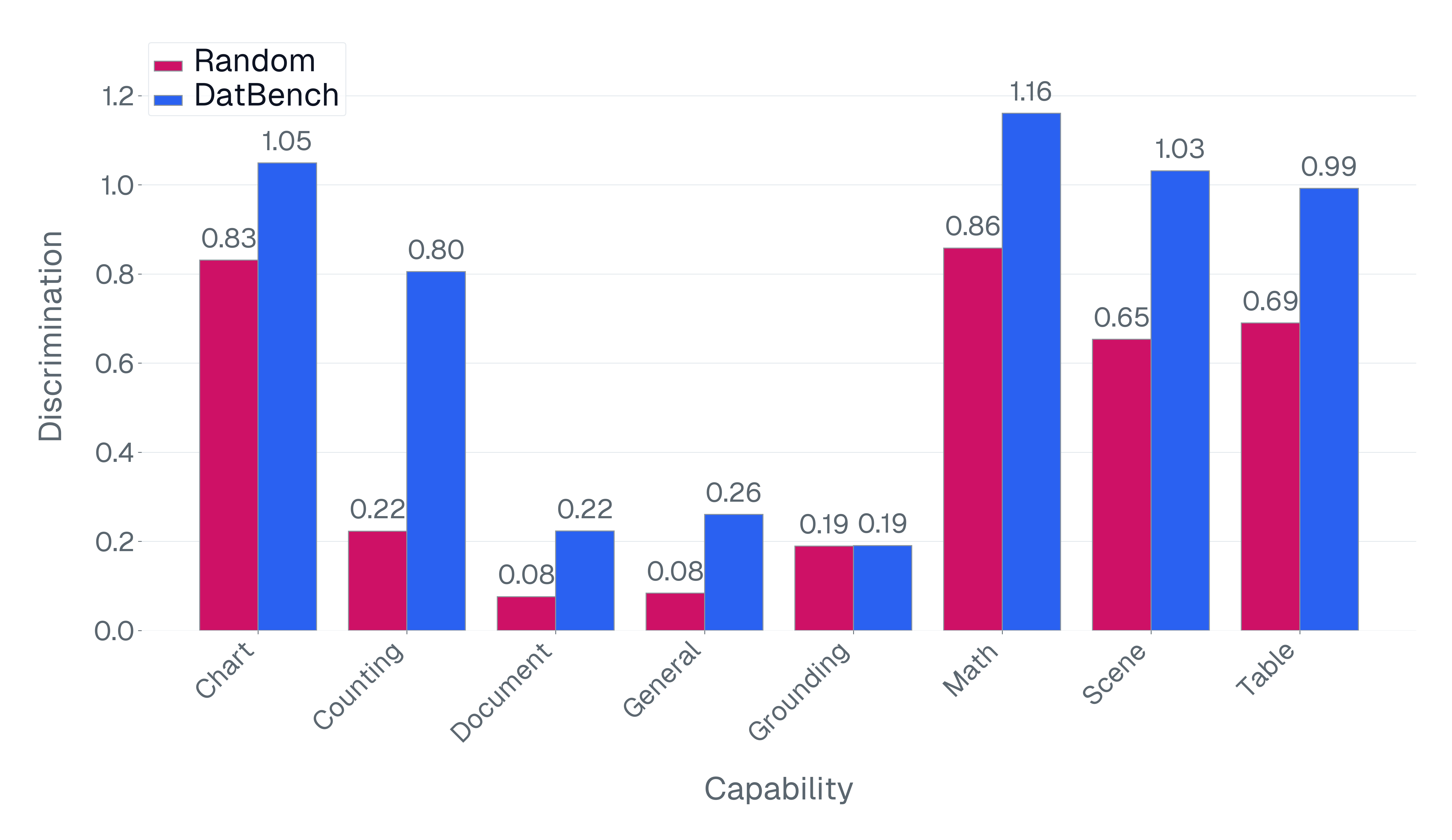
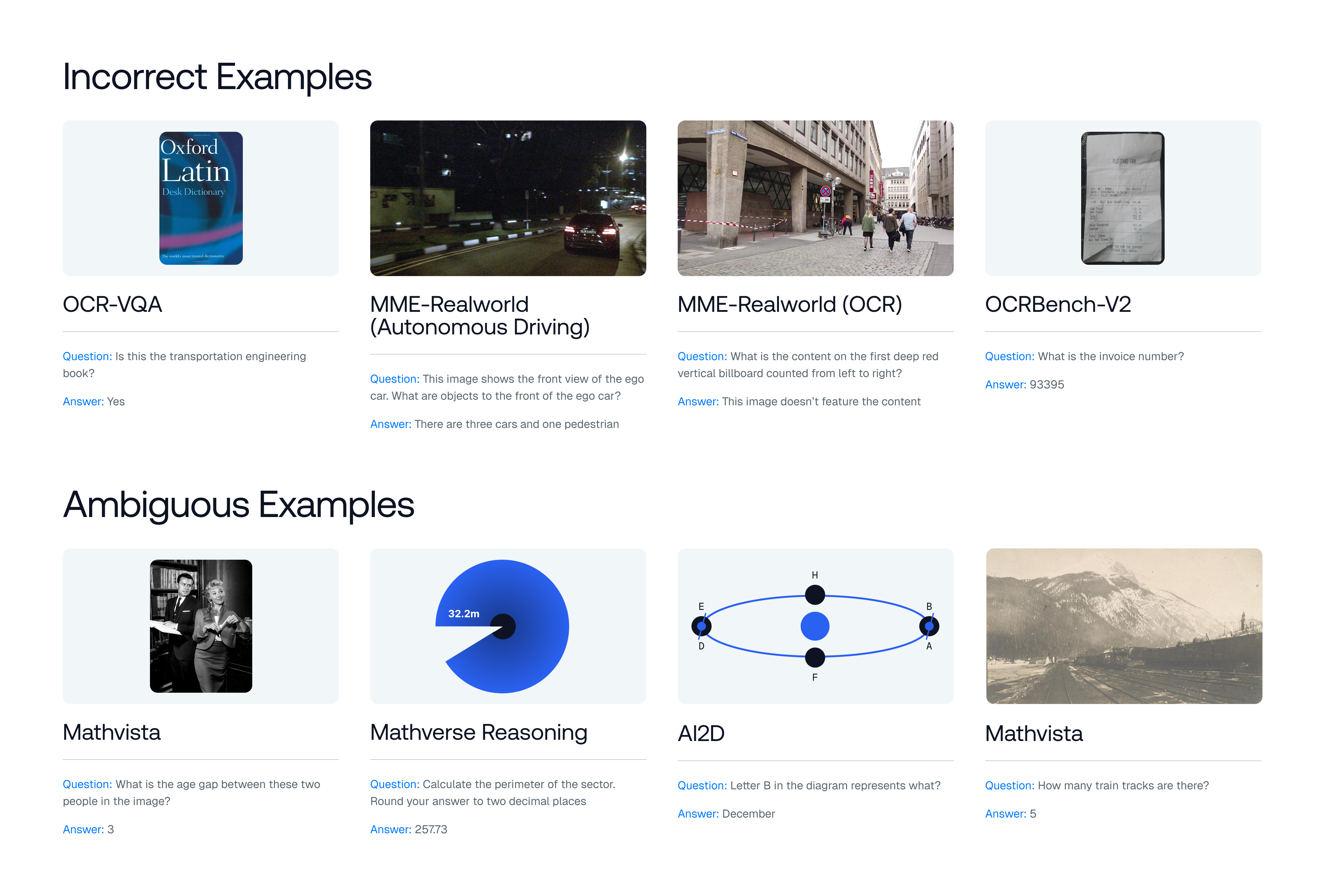
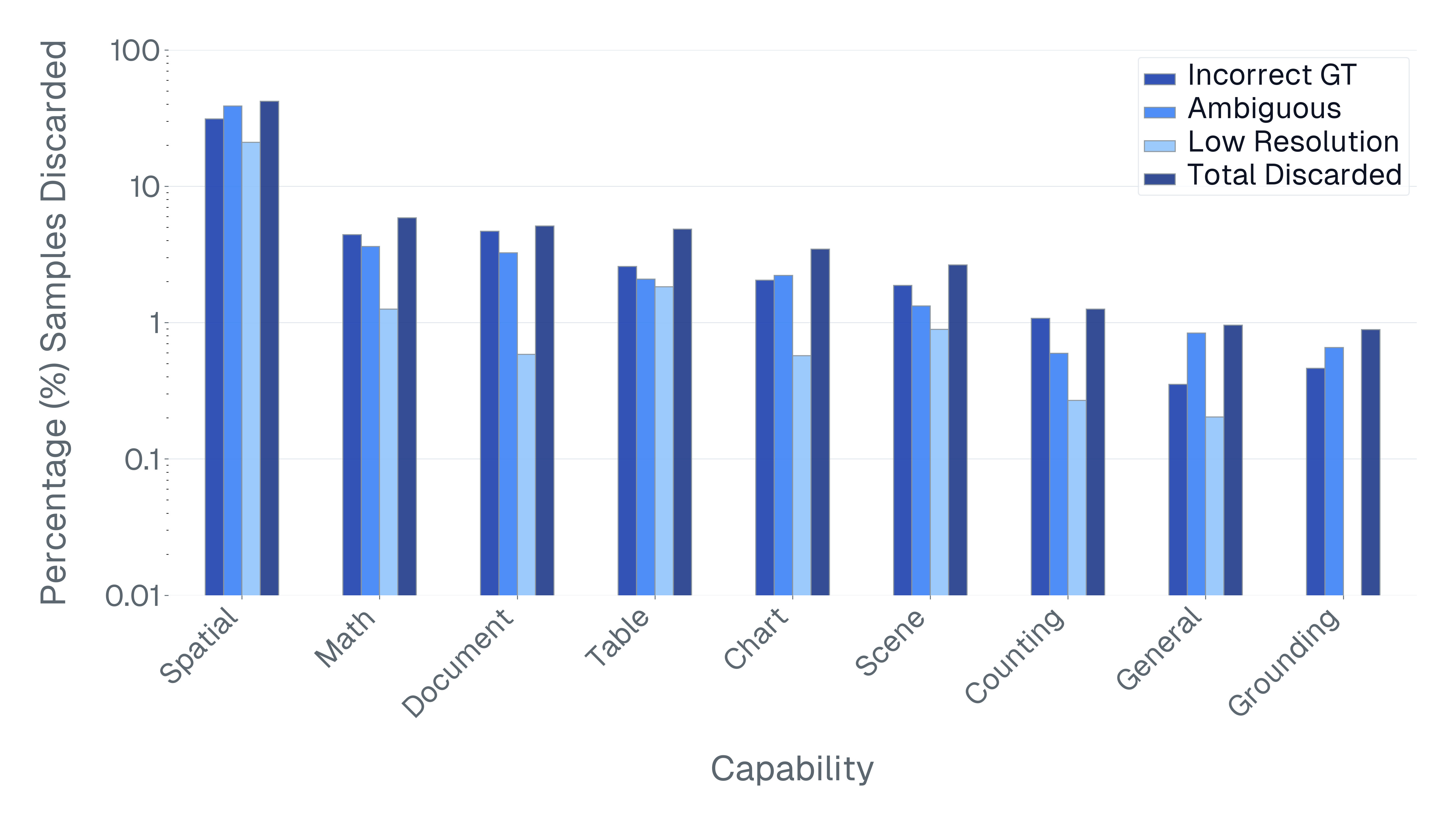
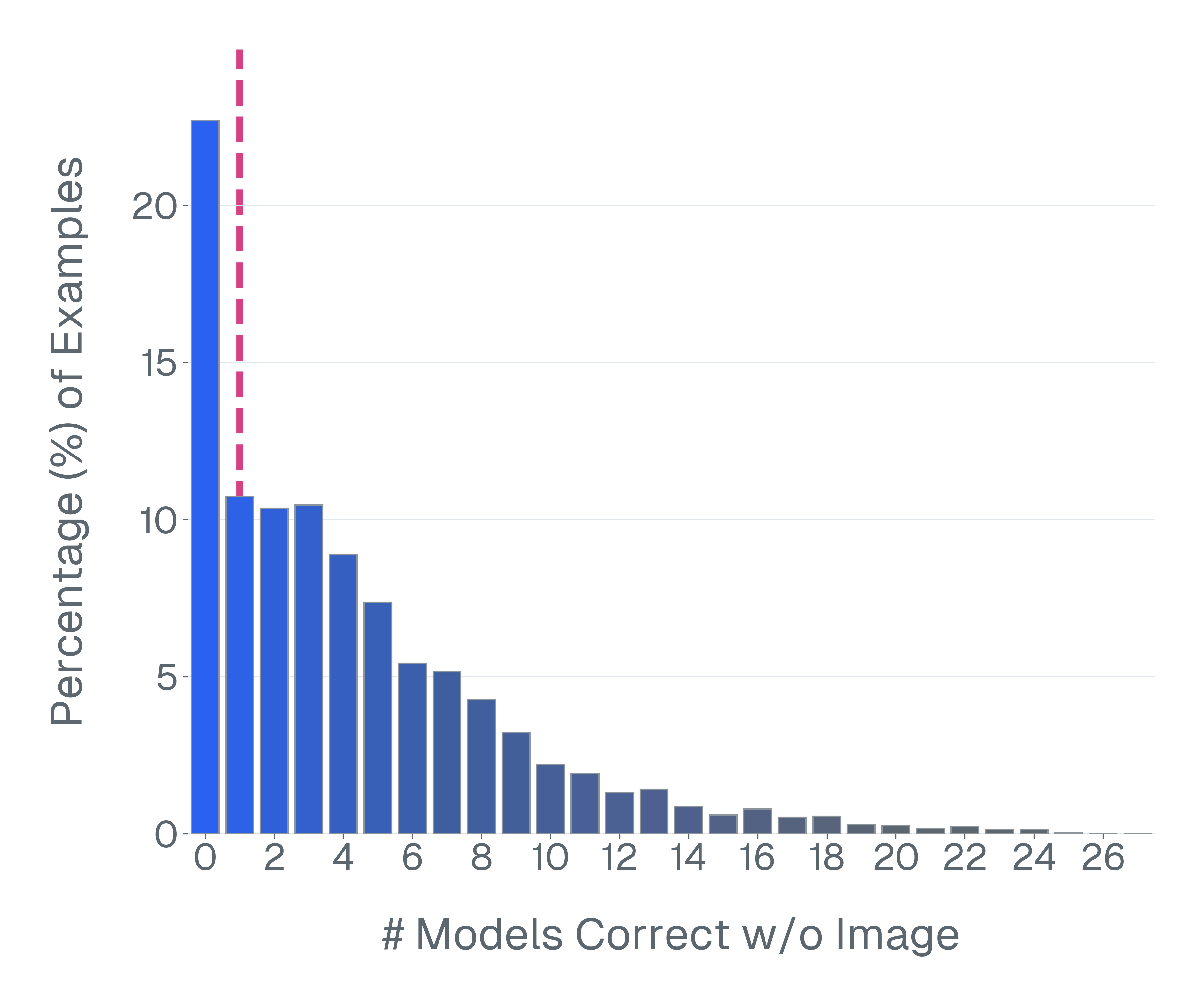
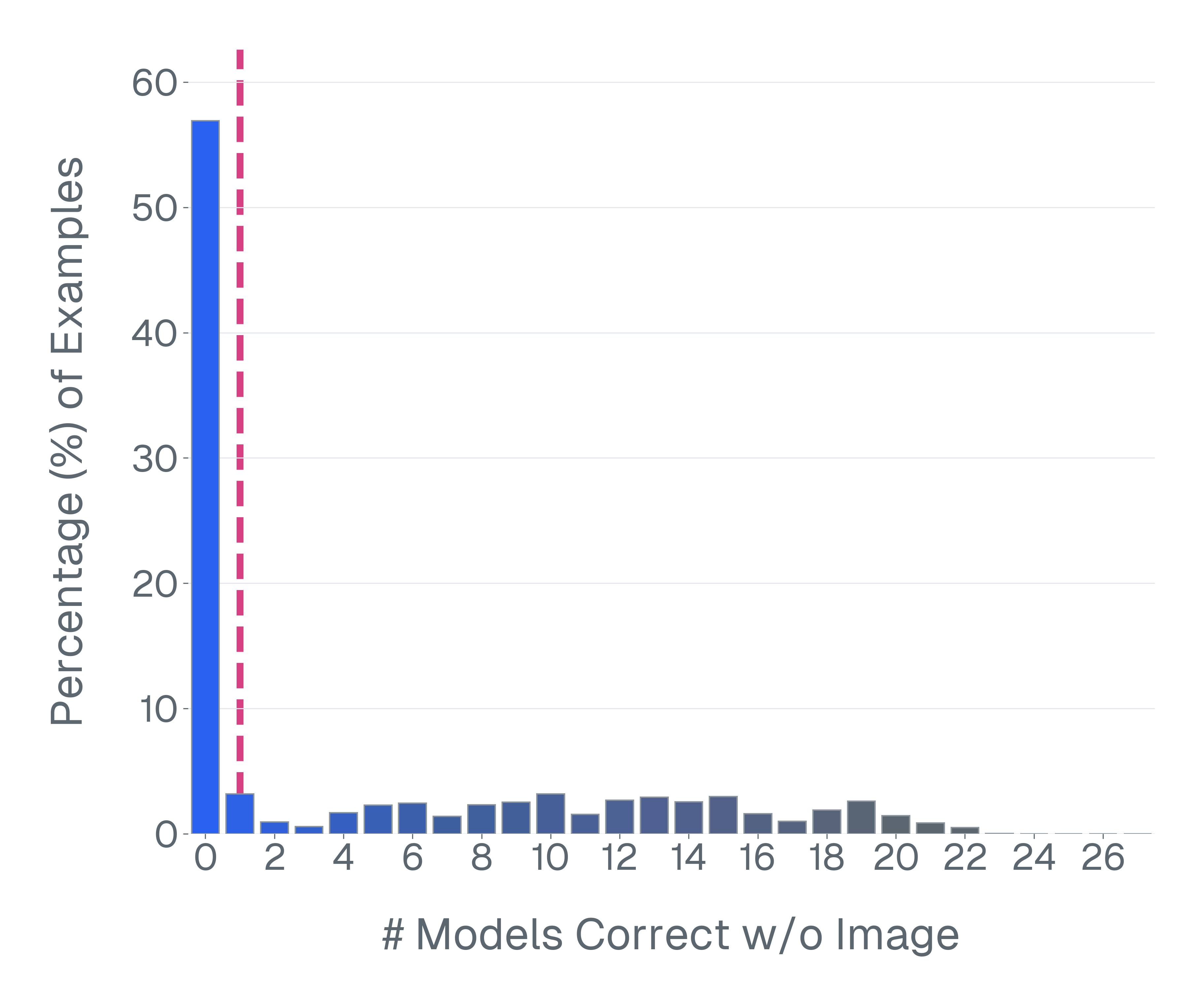
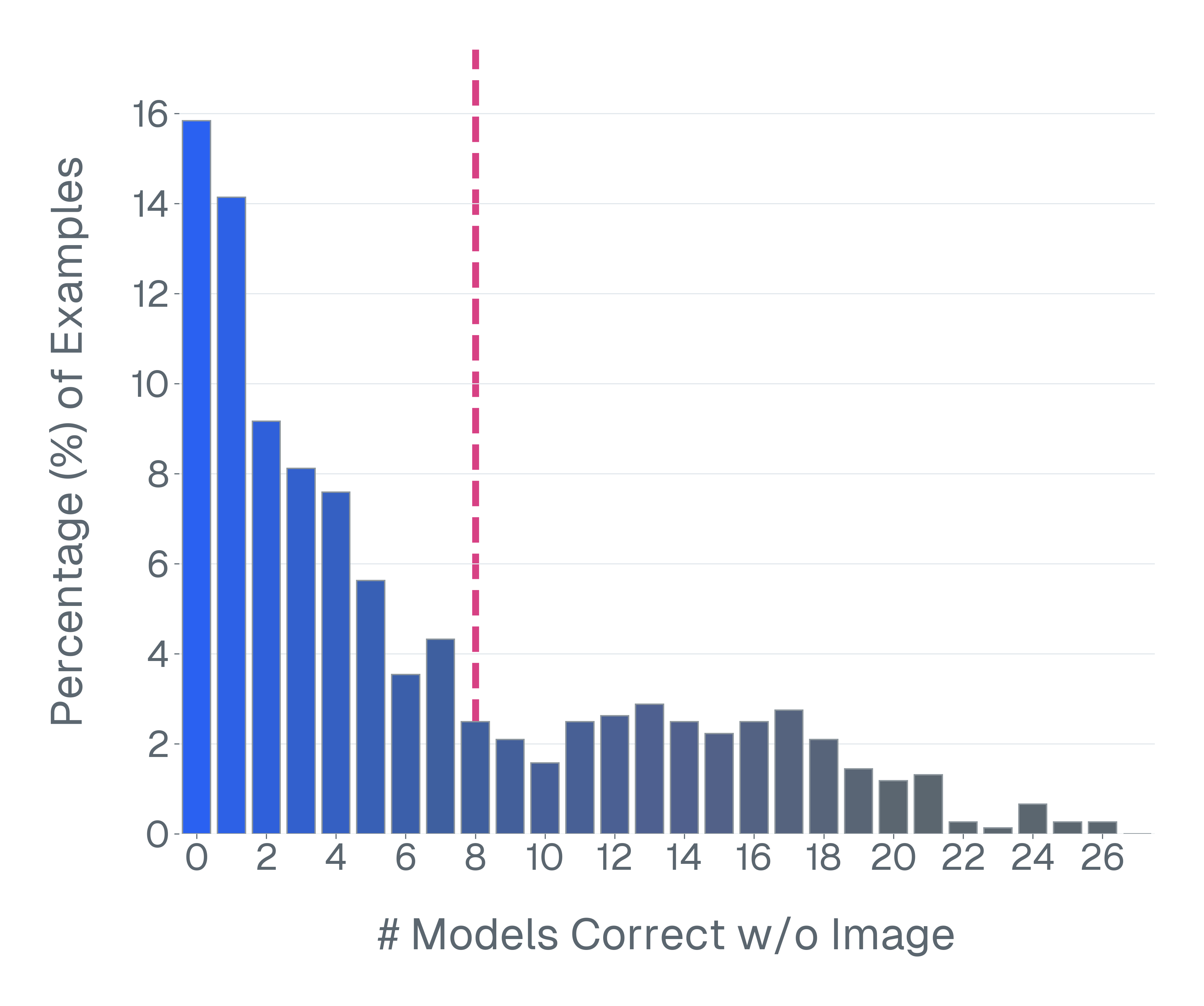
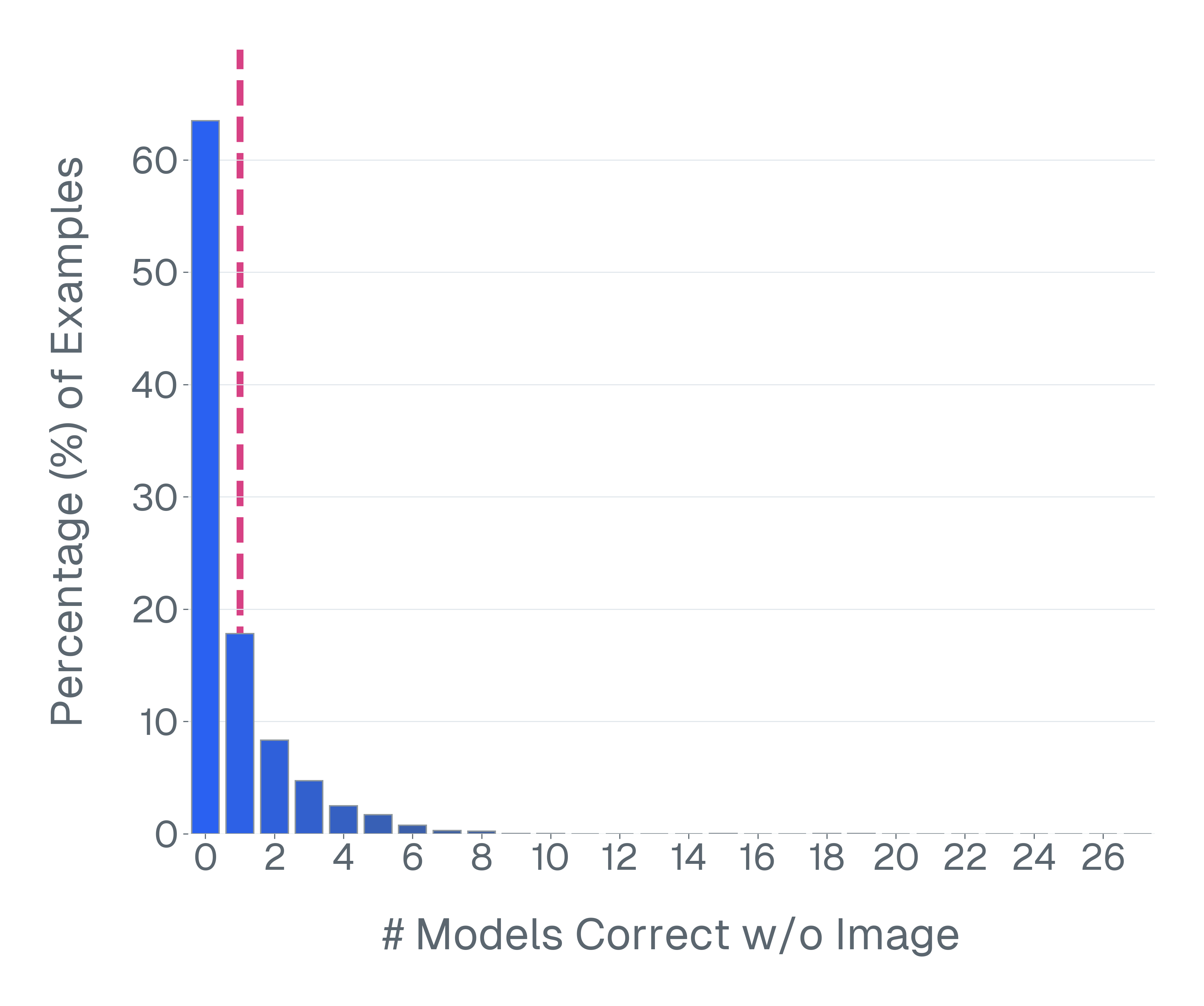
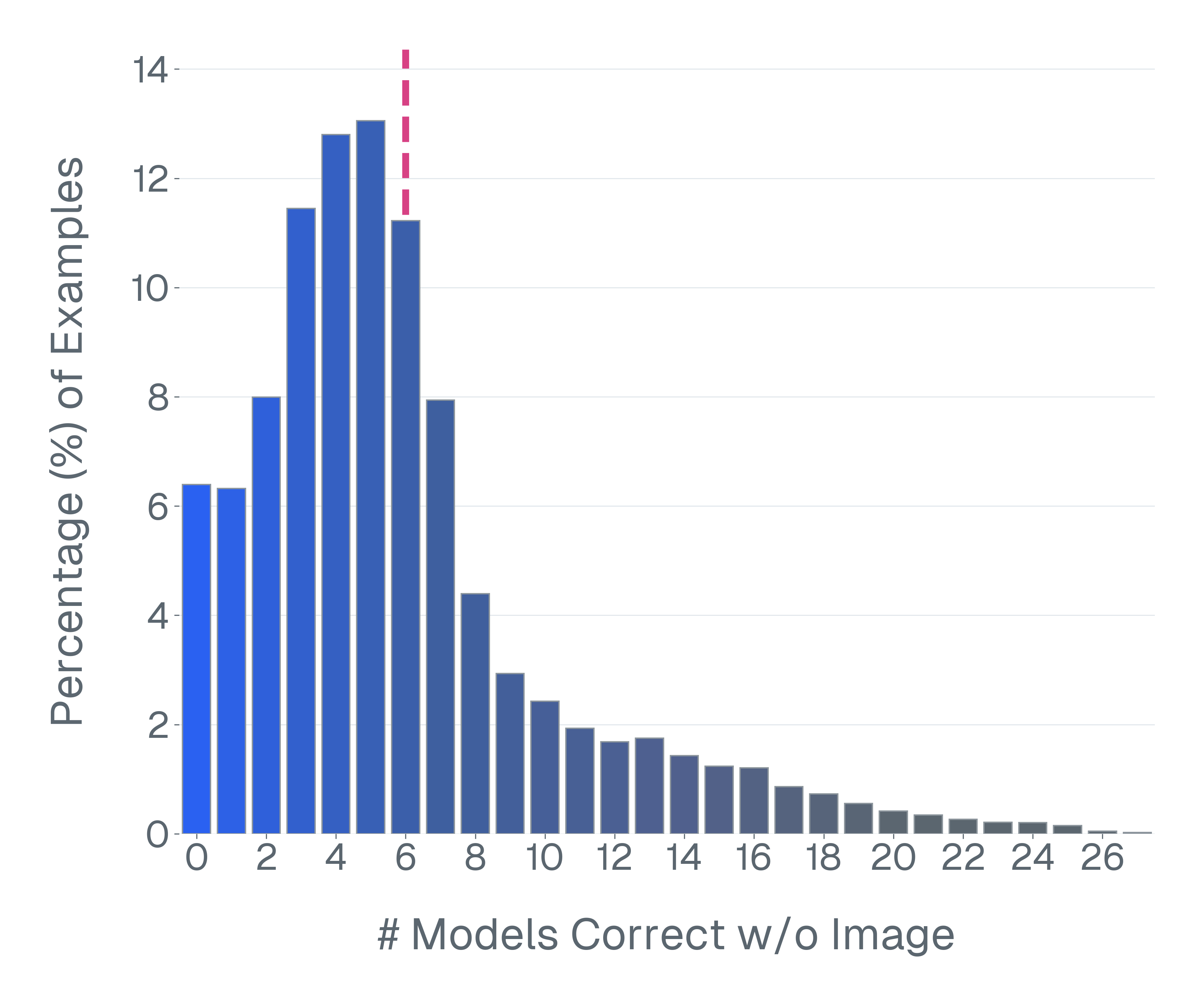
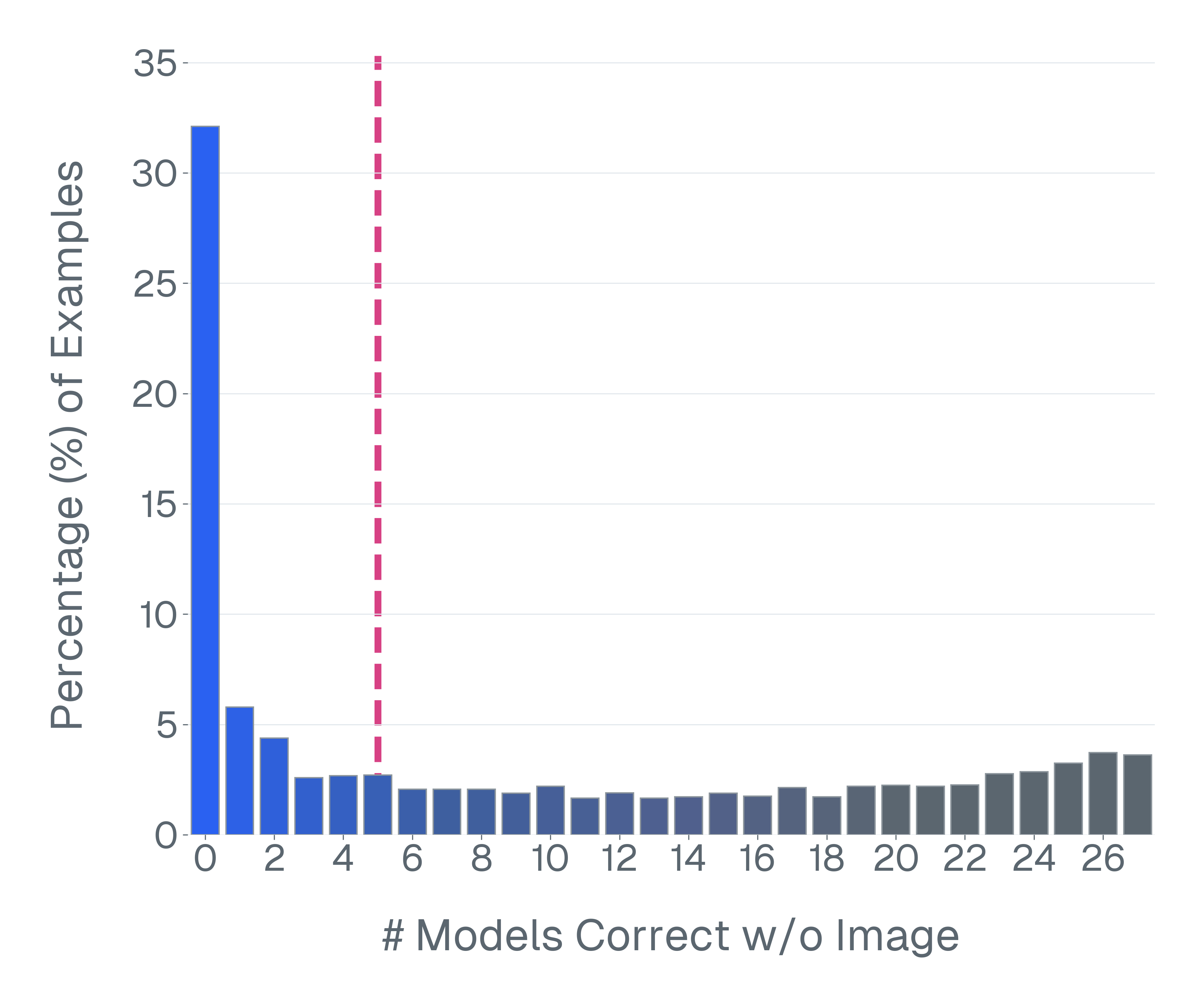
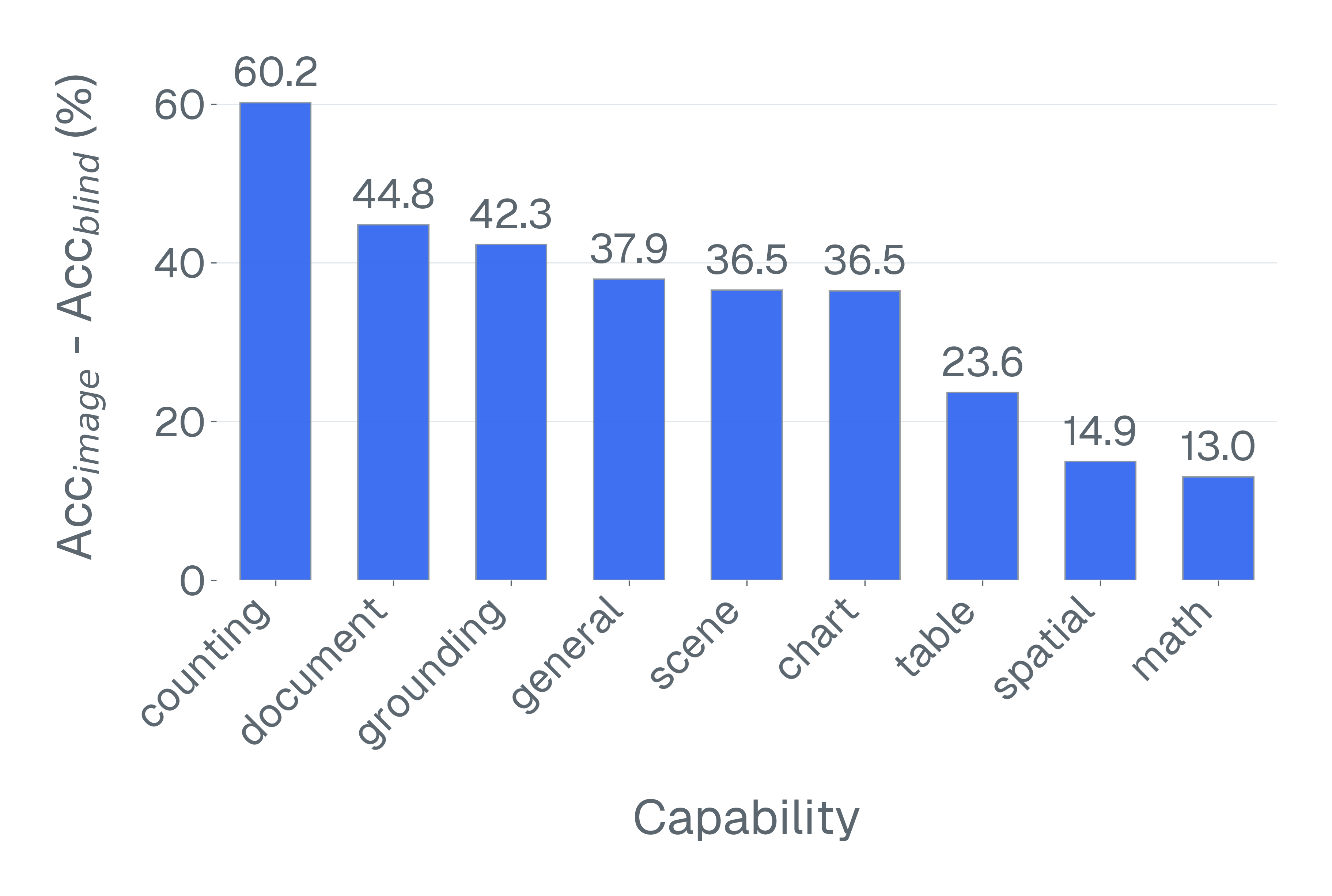
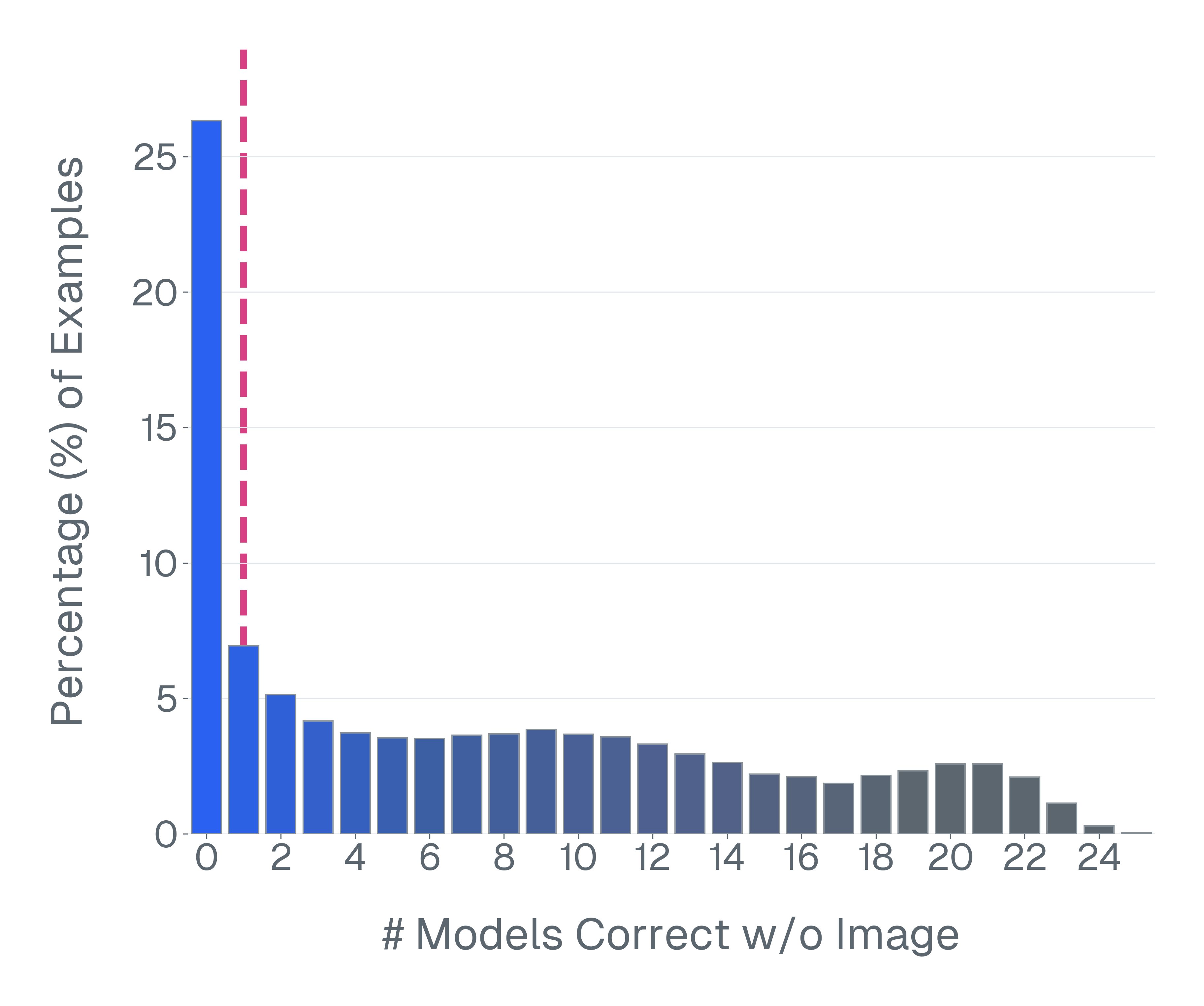
논문은 기존 벤치마크가 위 세 기준을 어떻게 위반하고 있는지 구체적인 사례를 들어 설명한다. ‘Blindly‑solvable’ 질문은 이미지 없이도 정답을 유추할 수 있는 텍스트‑전용 문제로, 일부 데이터셋에서는 전체 질문의 70%까지 차지한다. 이는 모델이 실제 시각 정보를 활용하는지를 평가하지 못한다는 근본적인 결함이다. 또한 라벨 오류와 모호한 질문이 데이터셋의 42%에 달한다는 조사 결과는, 평가 결과가 데이터 품질에 크게 좌우된다는 점을 강조한다.
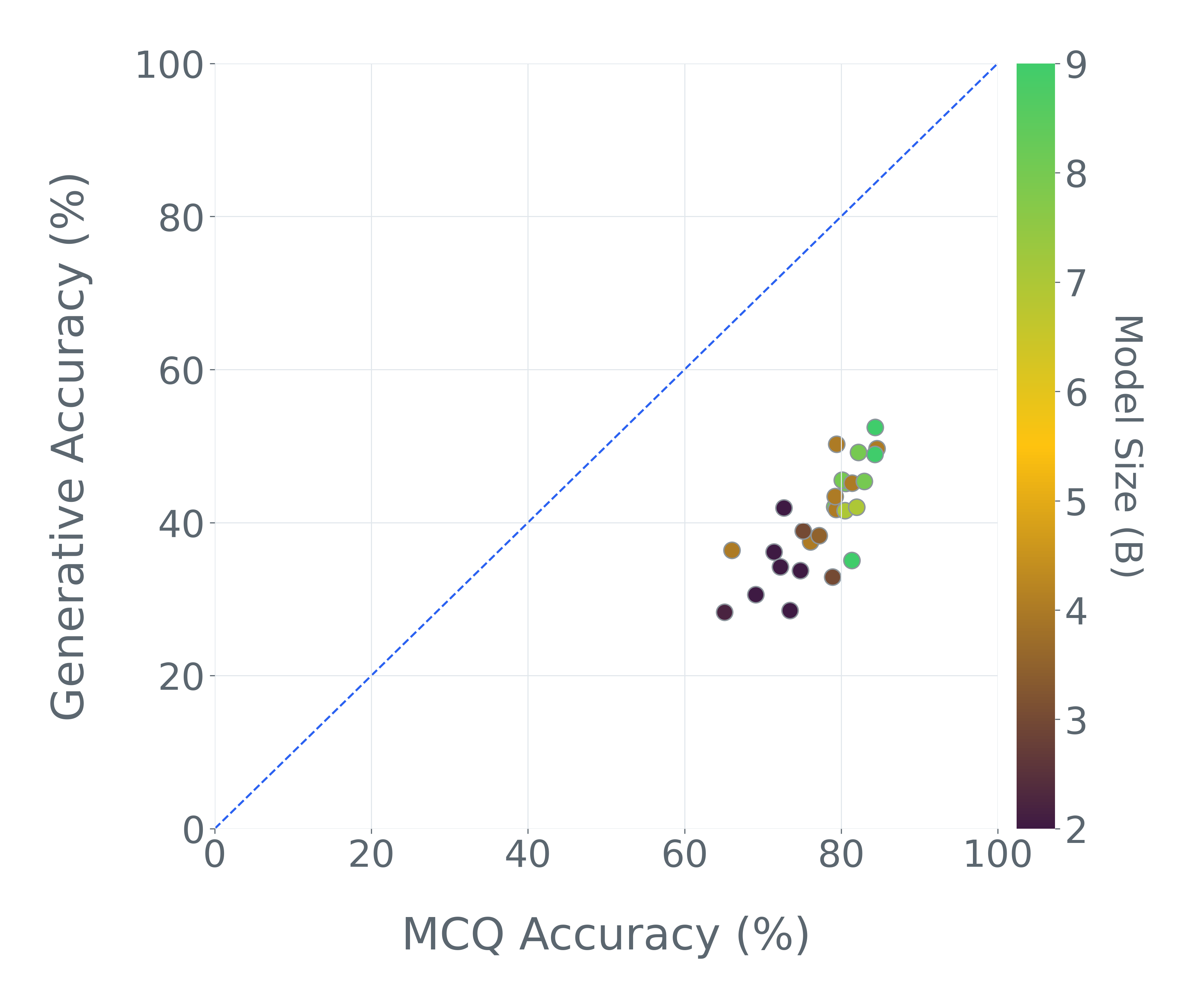
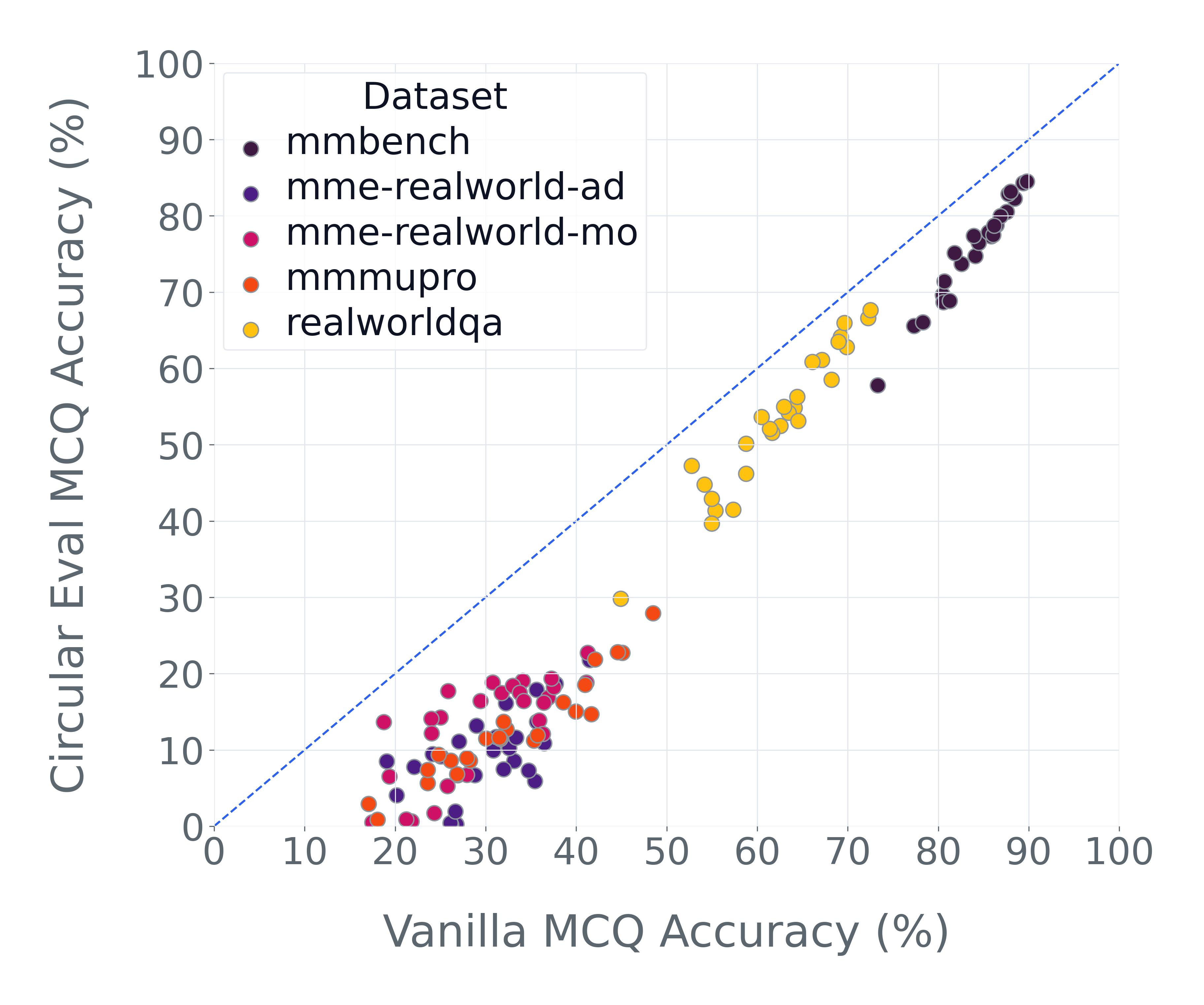
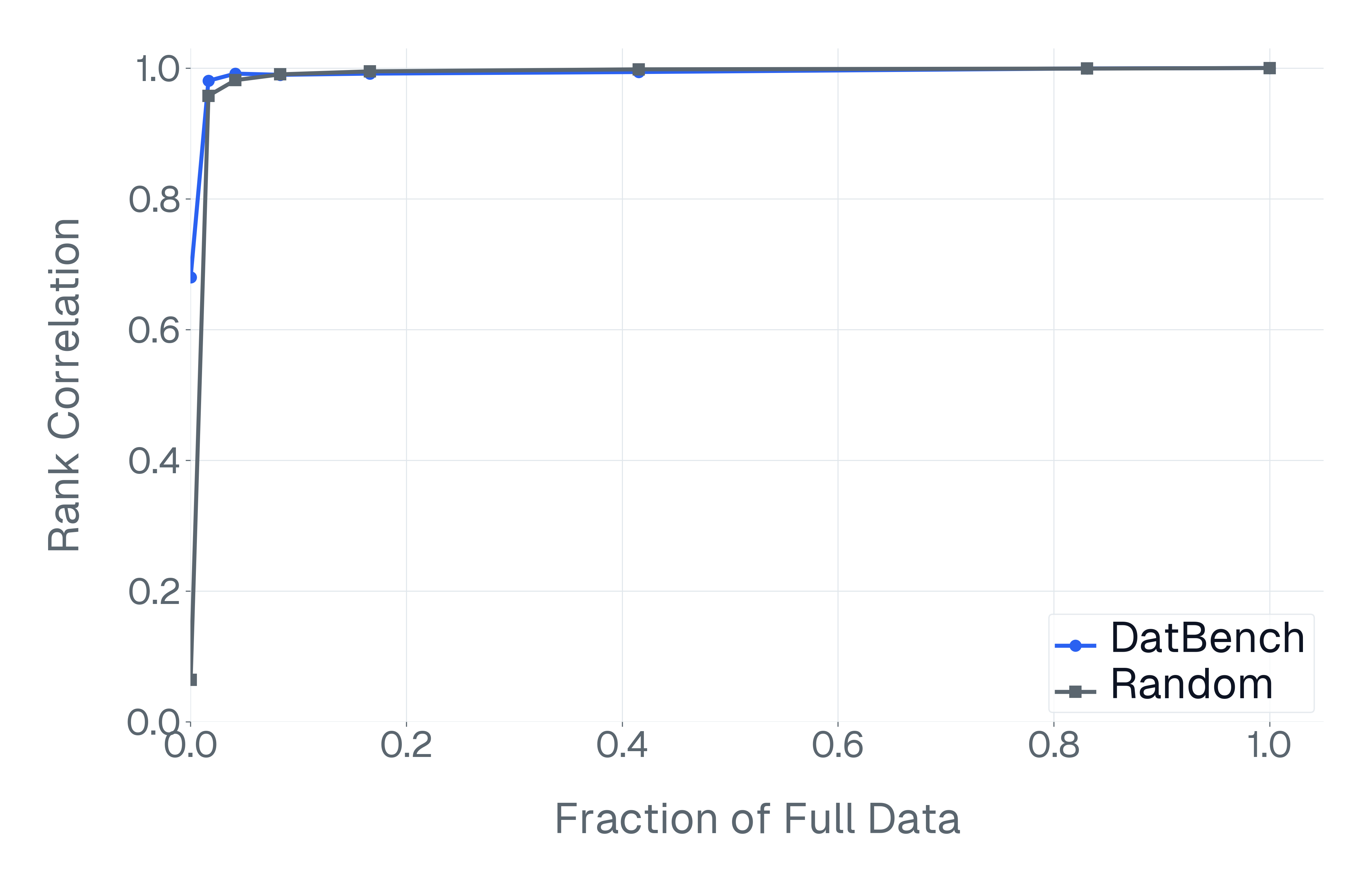
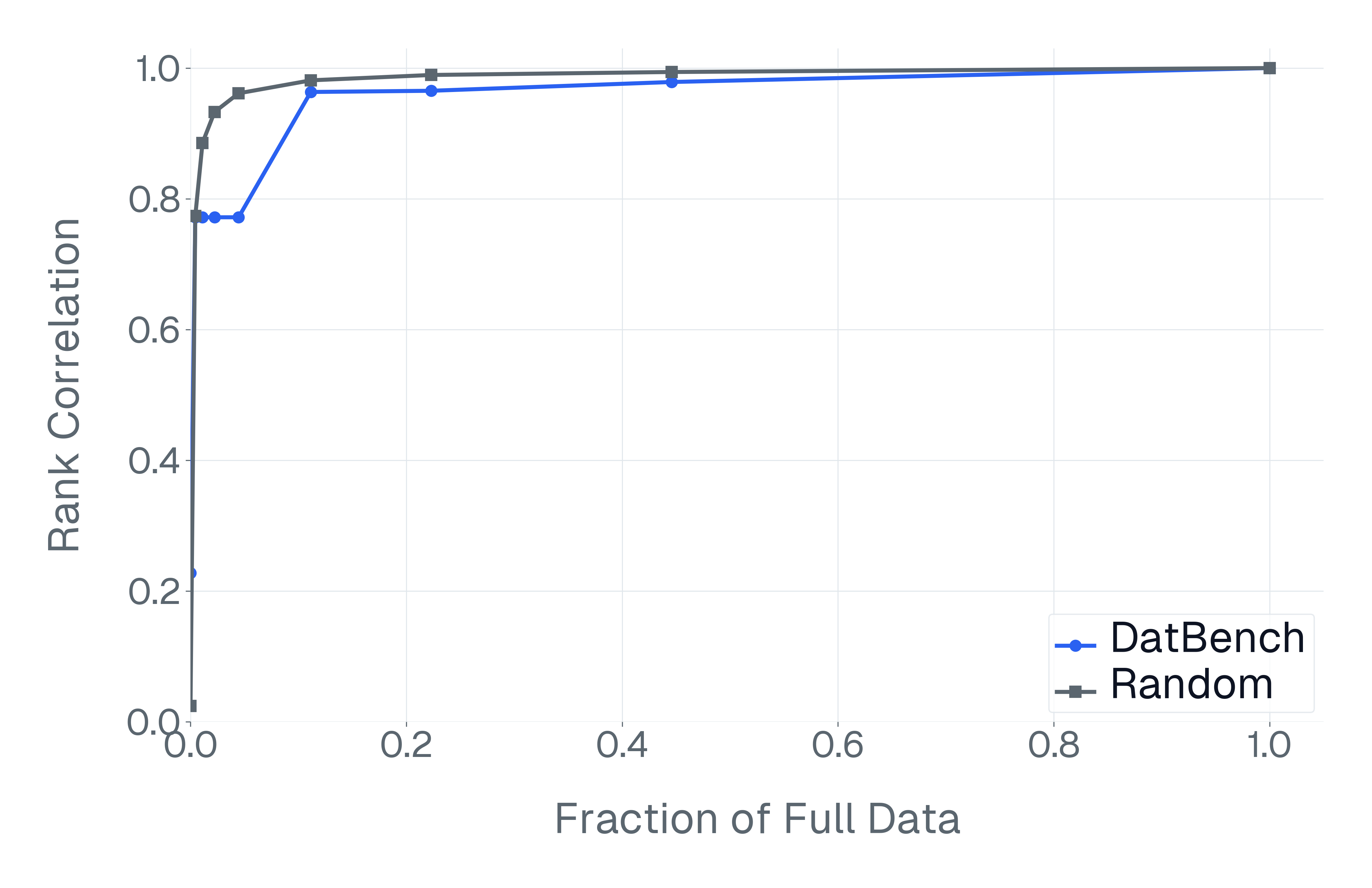
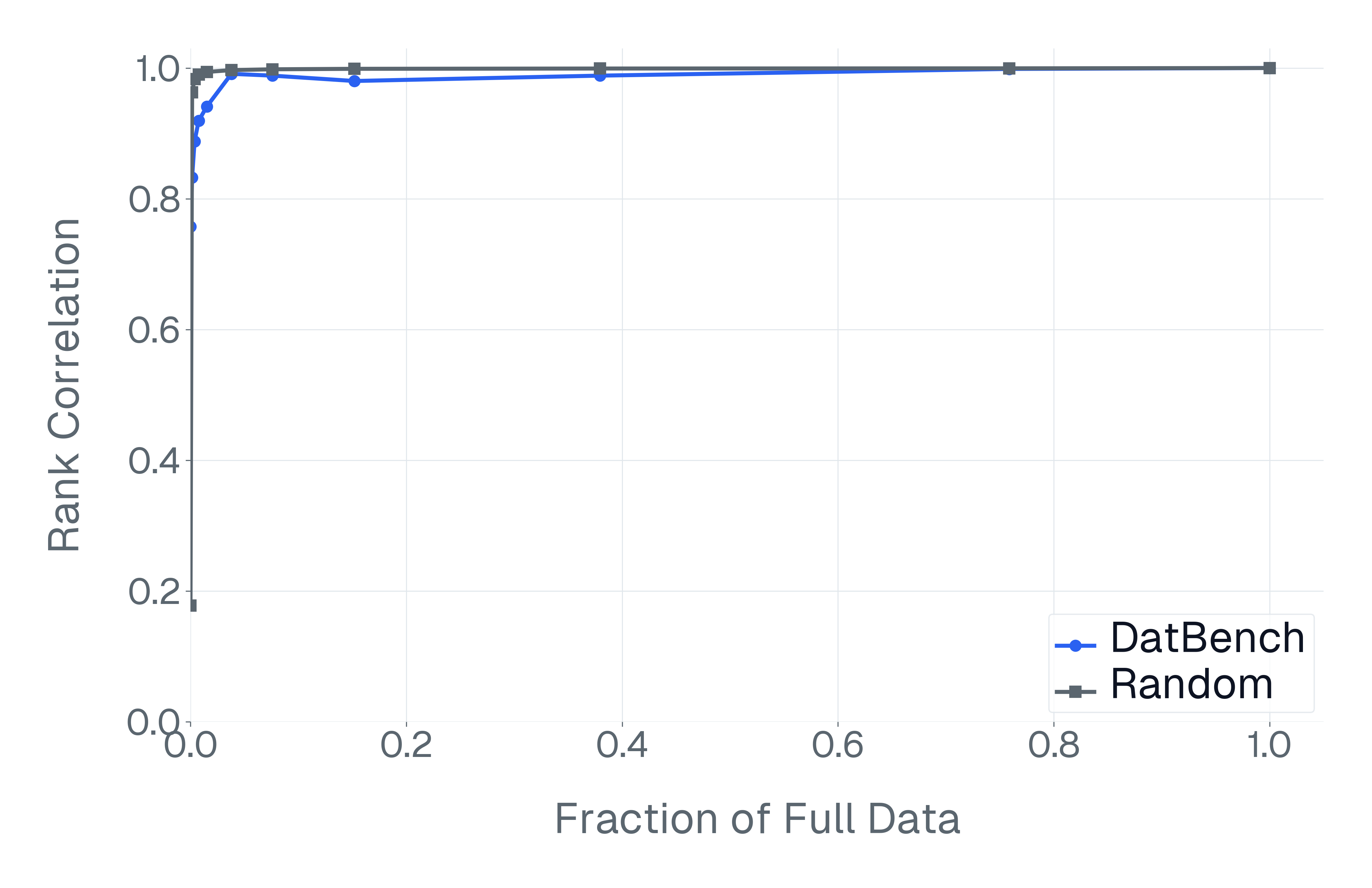
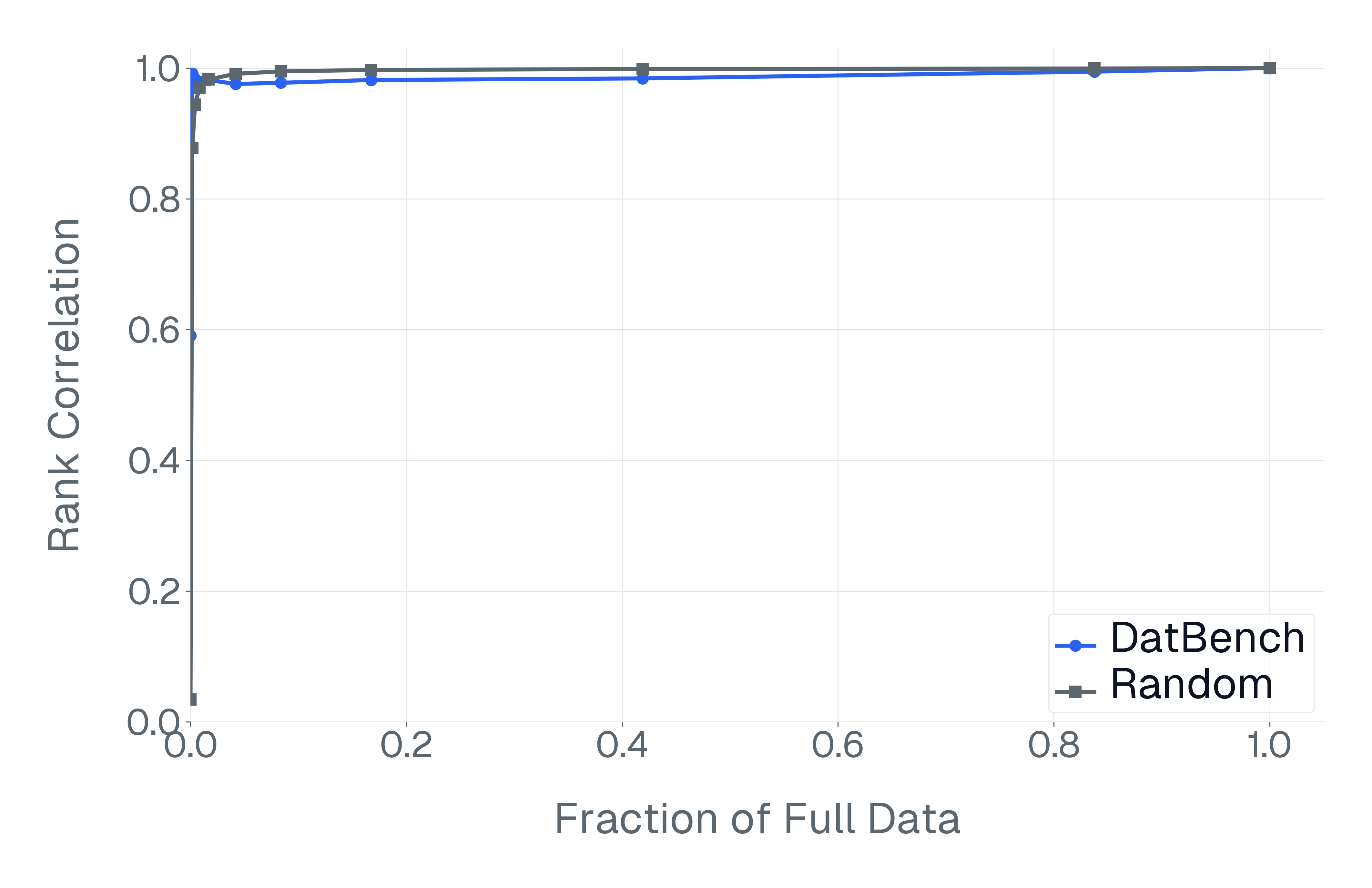
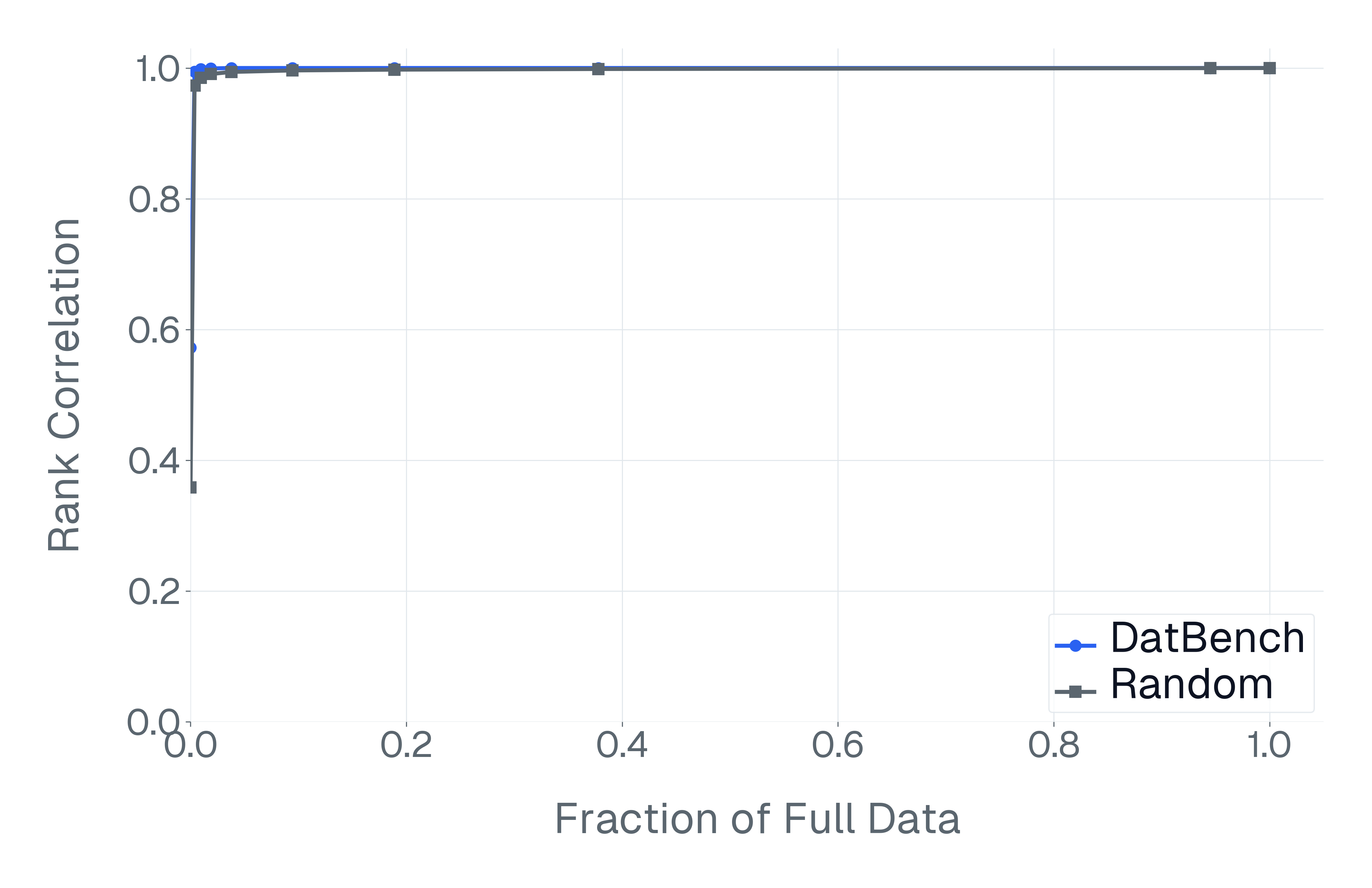
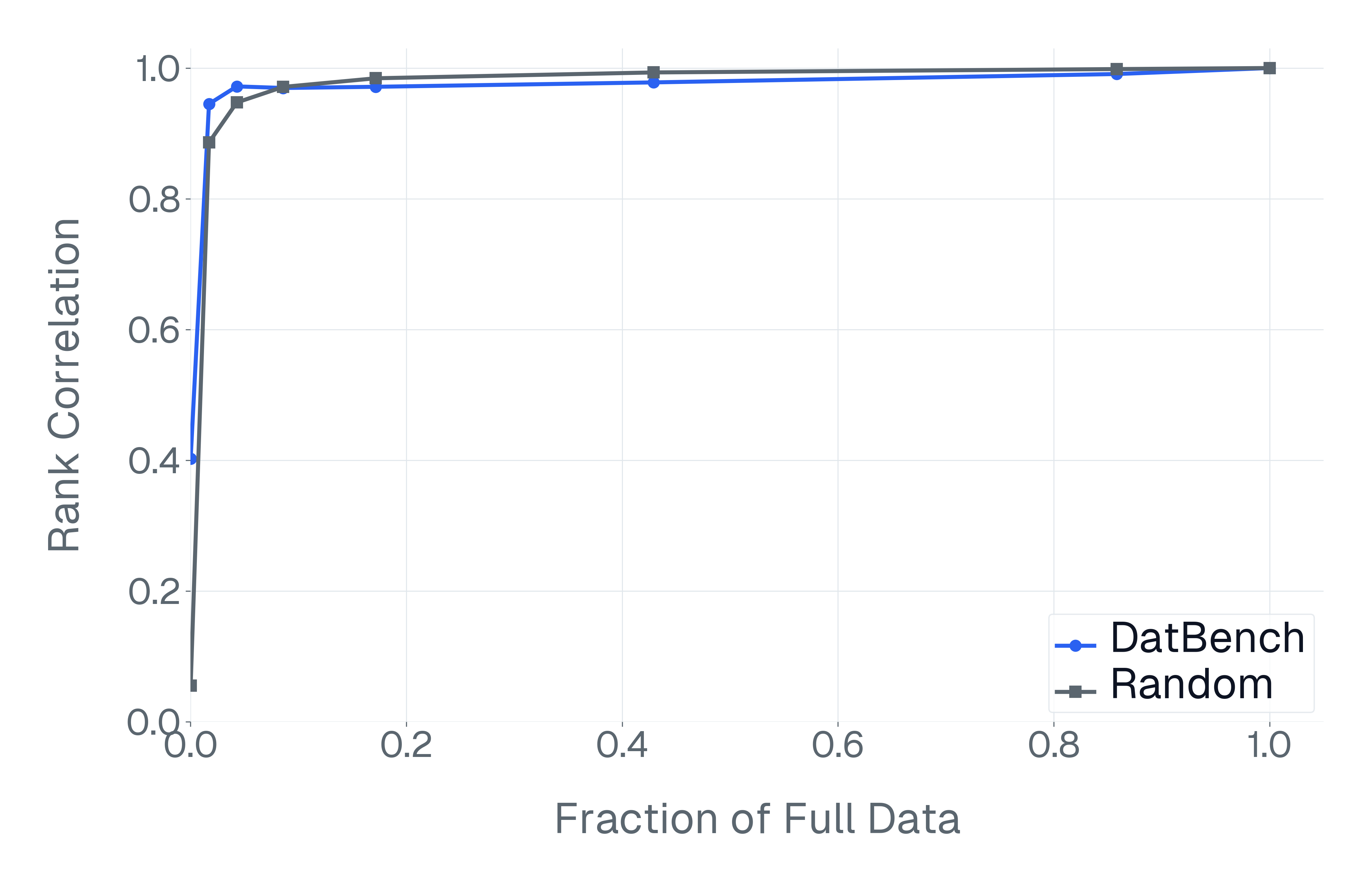
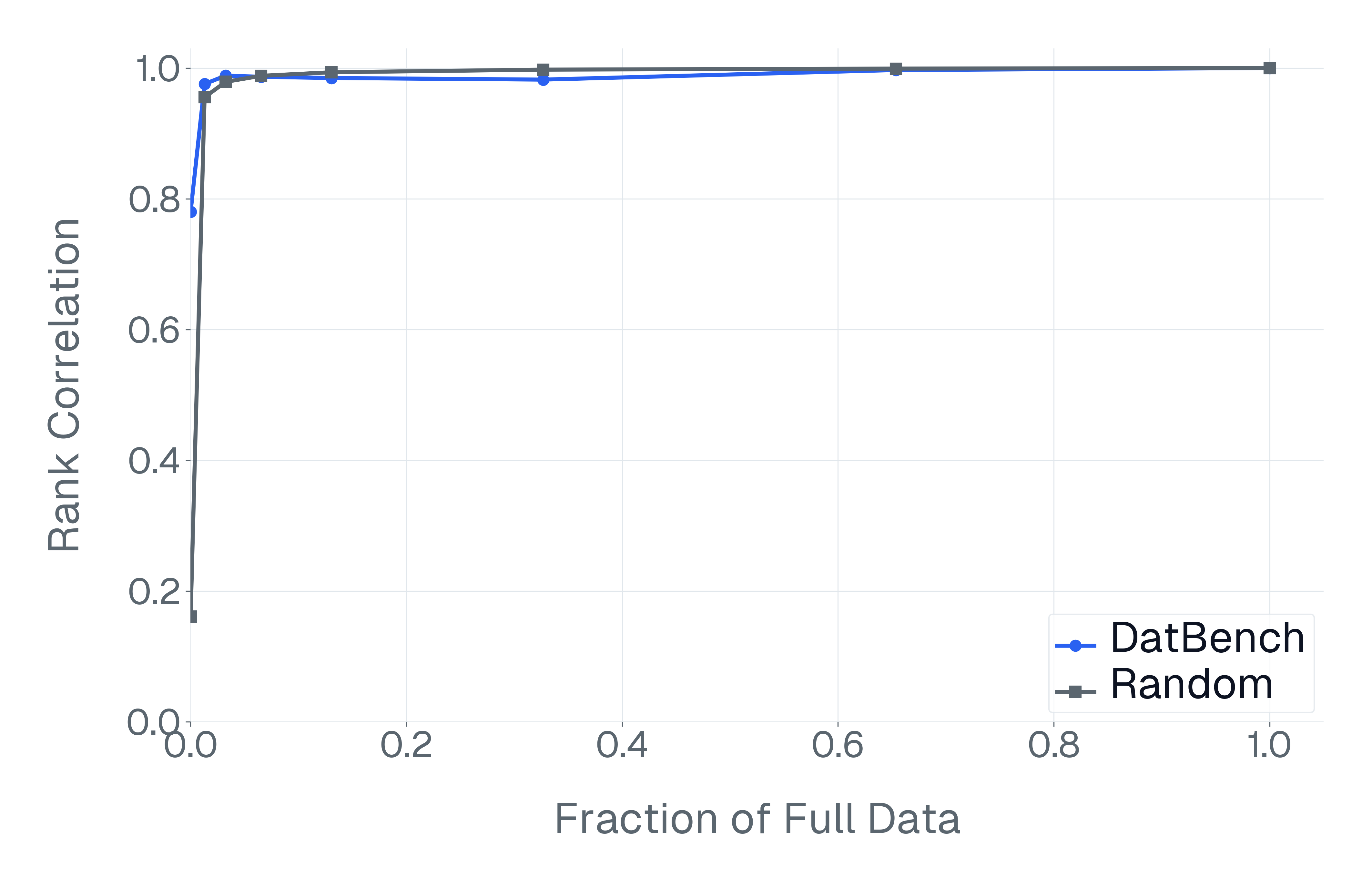
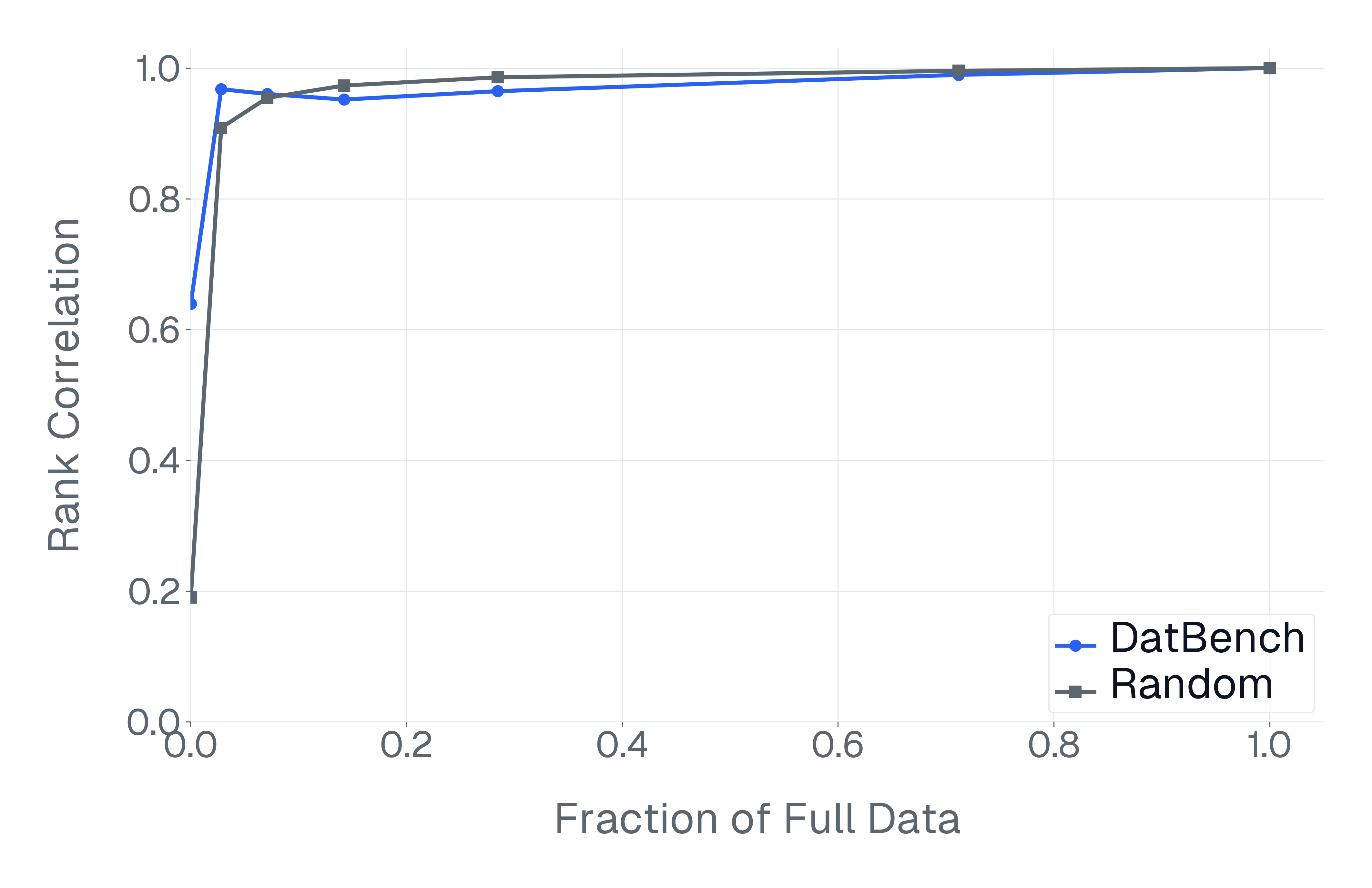
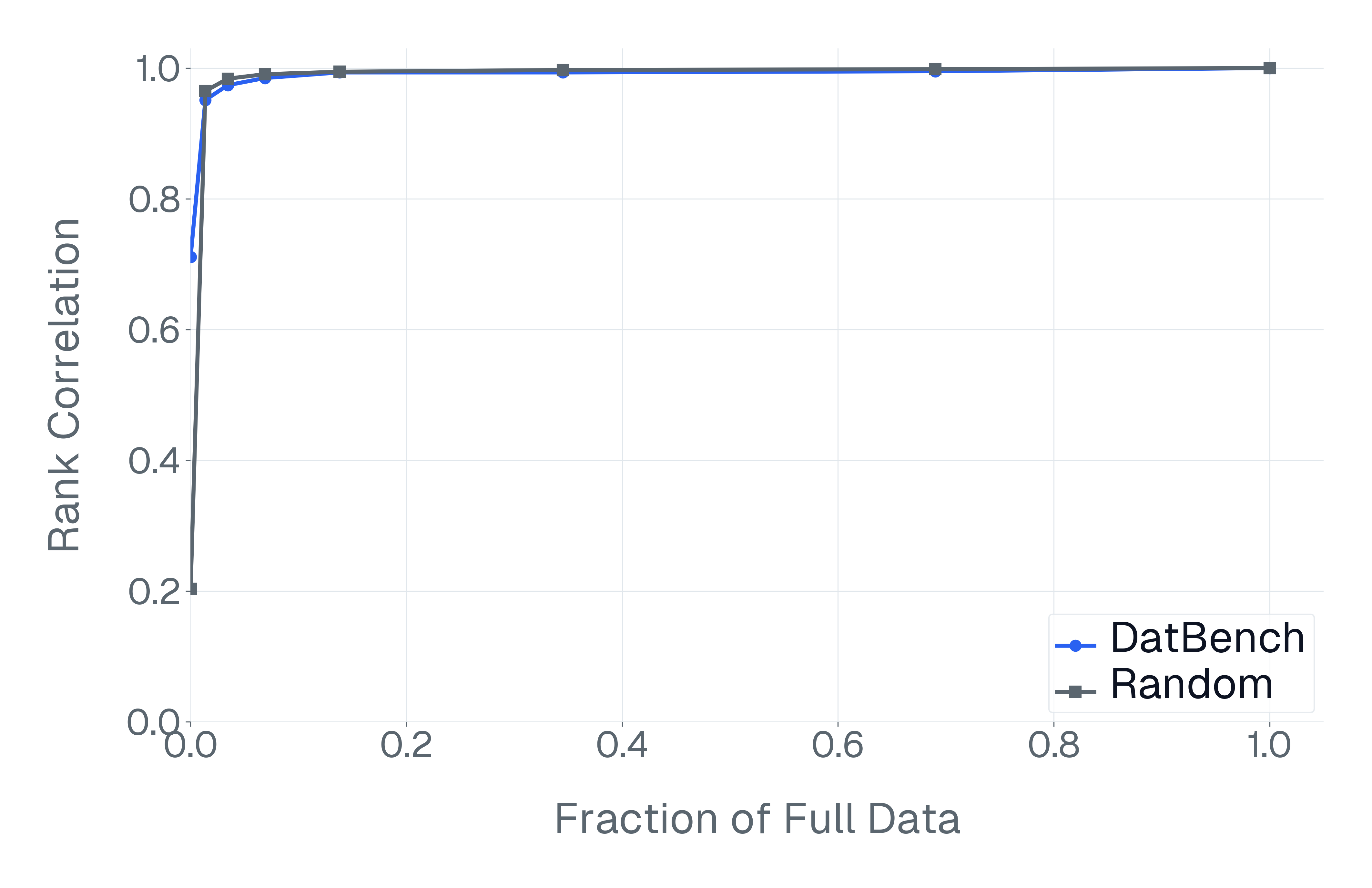
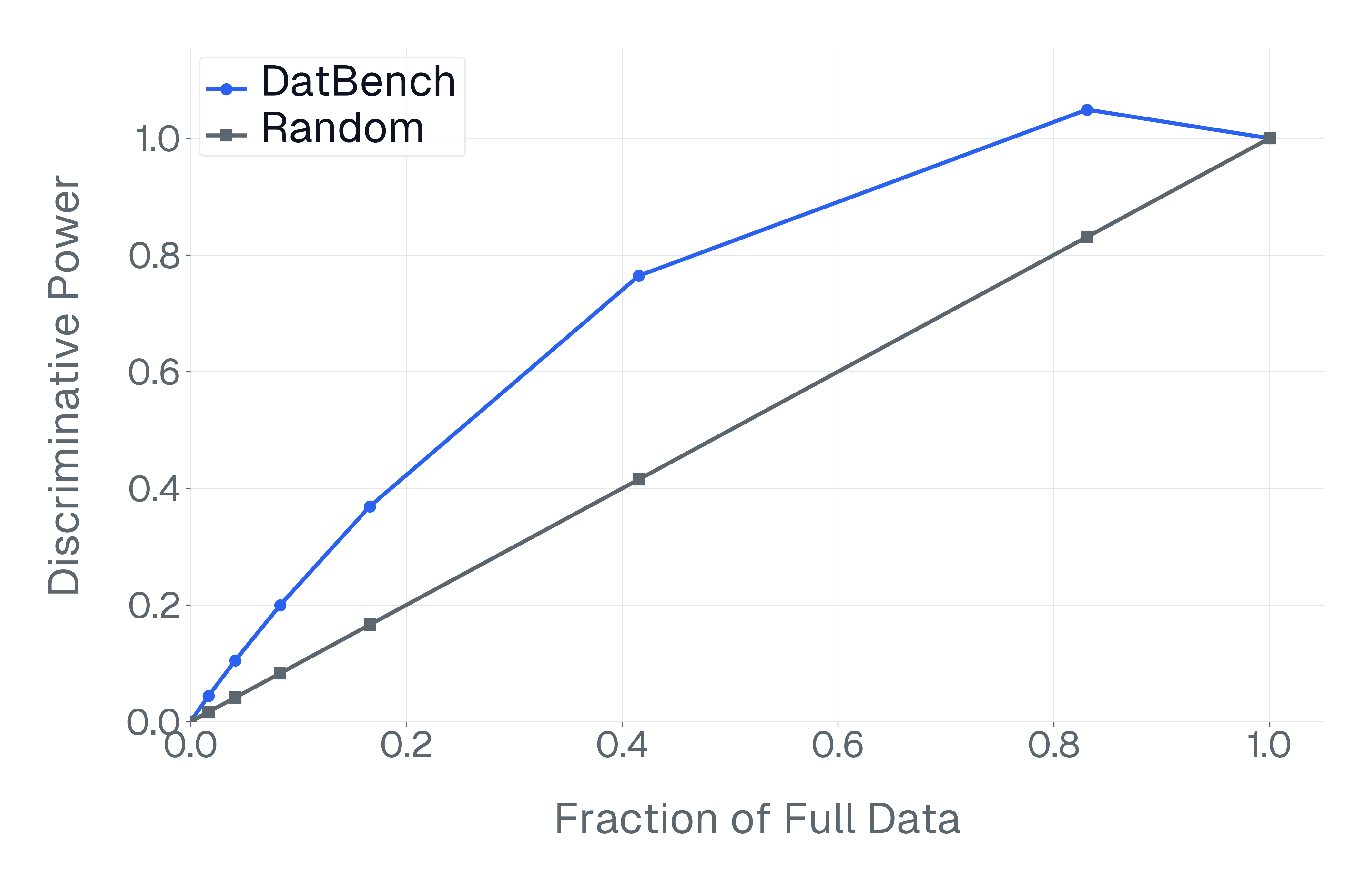
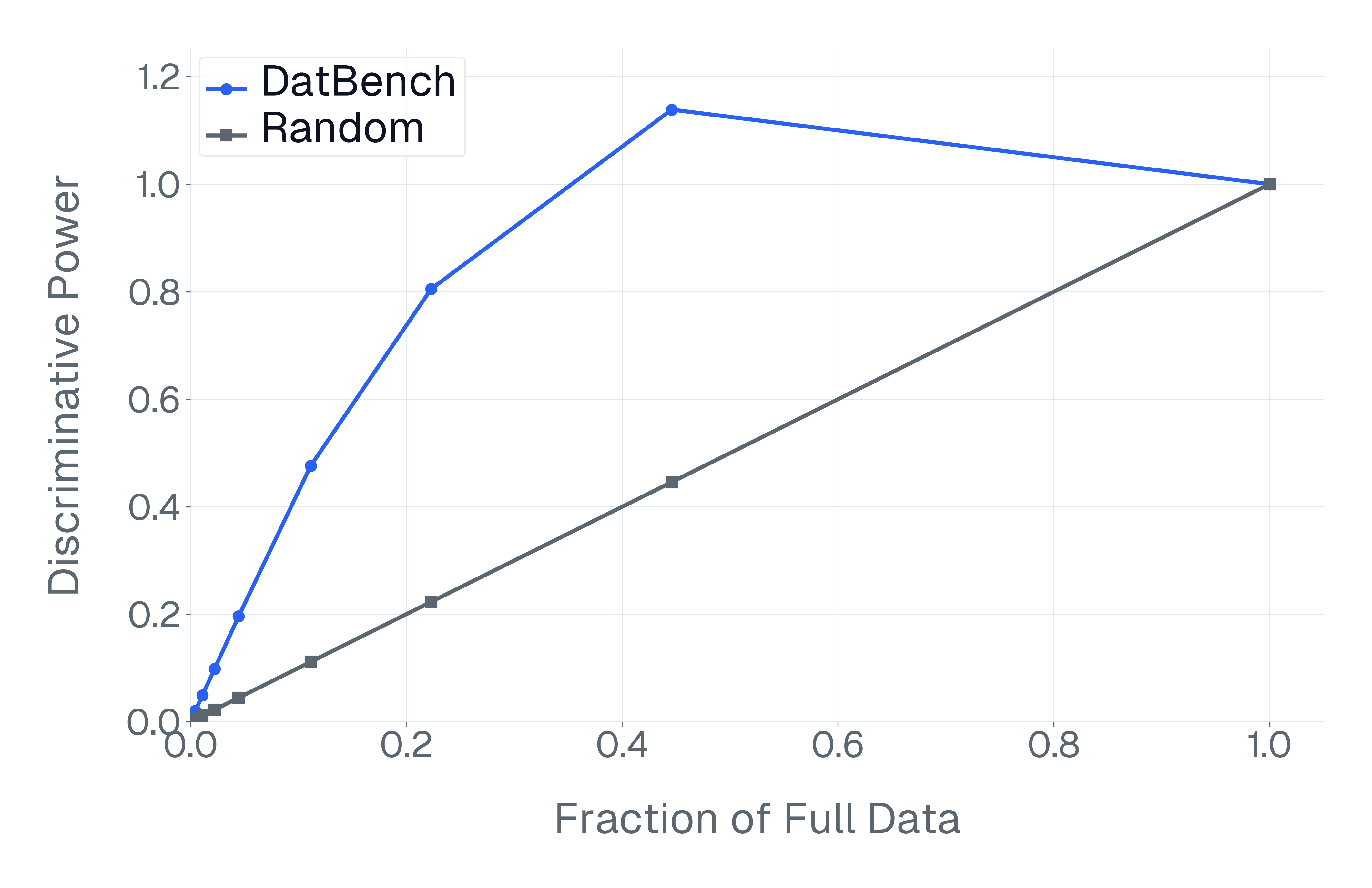
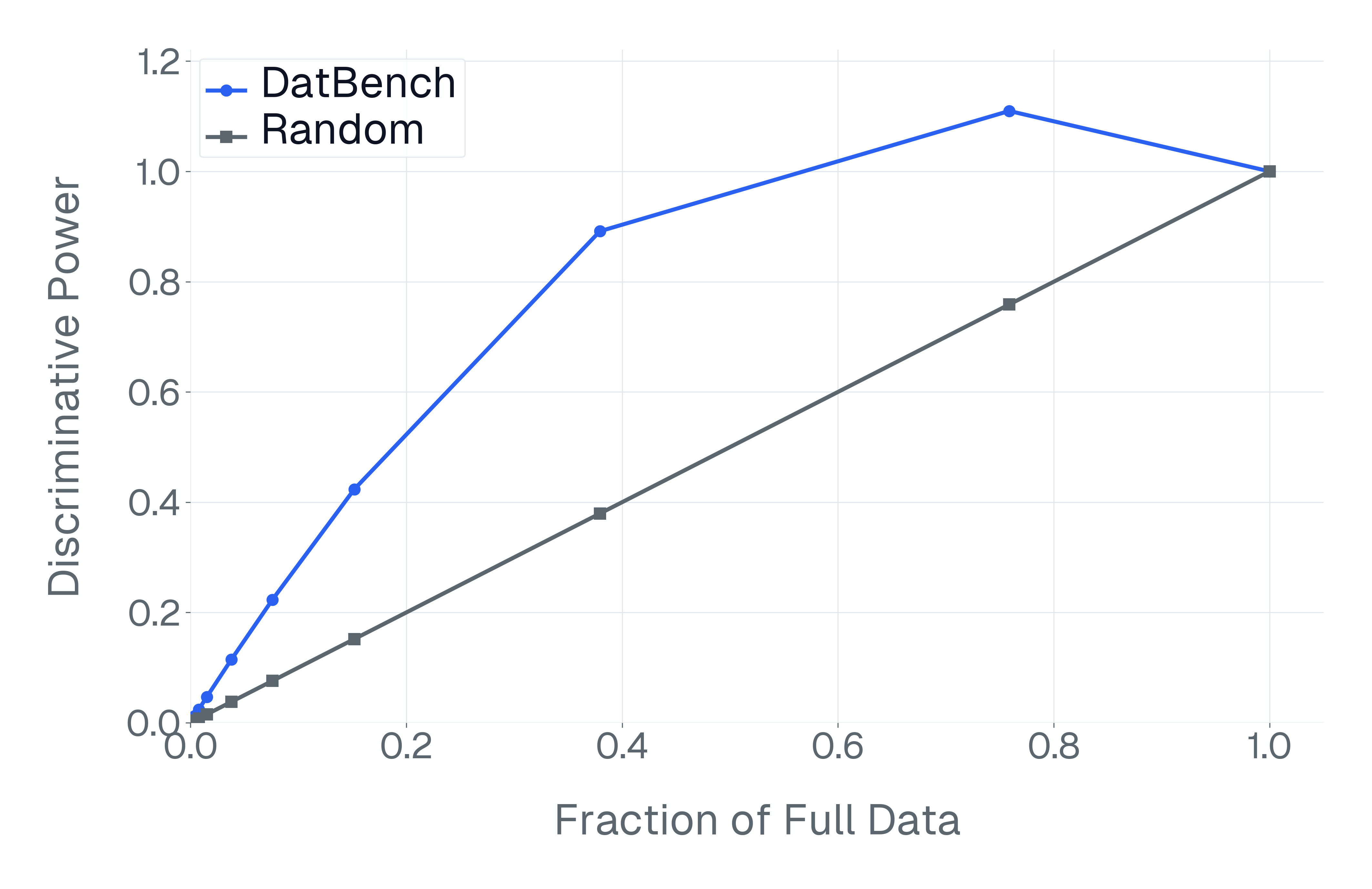
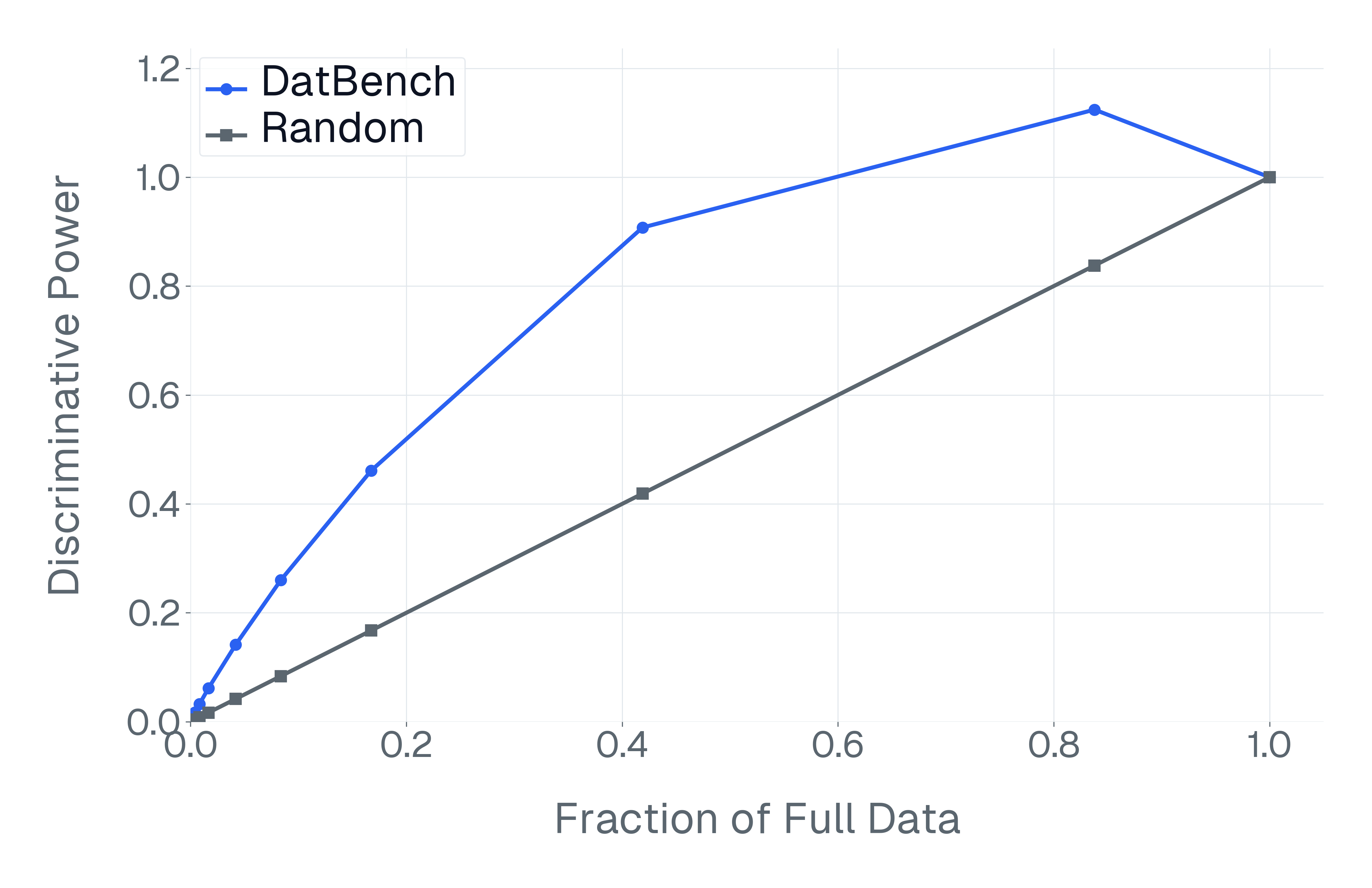
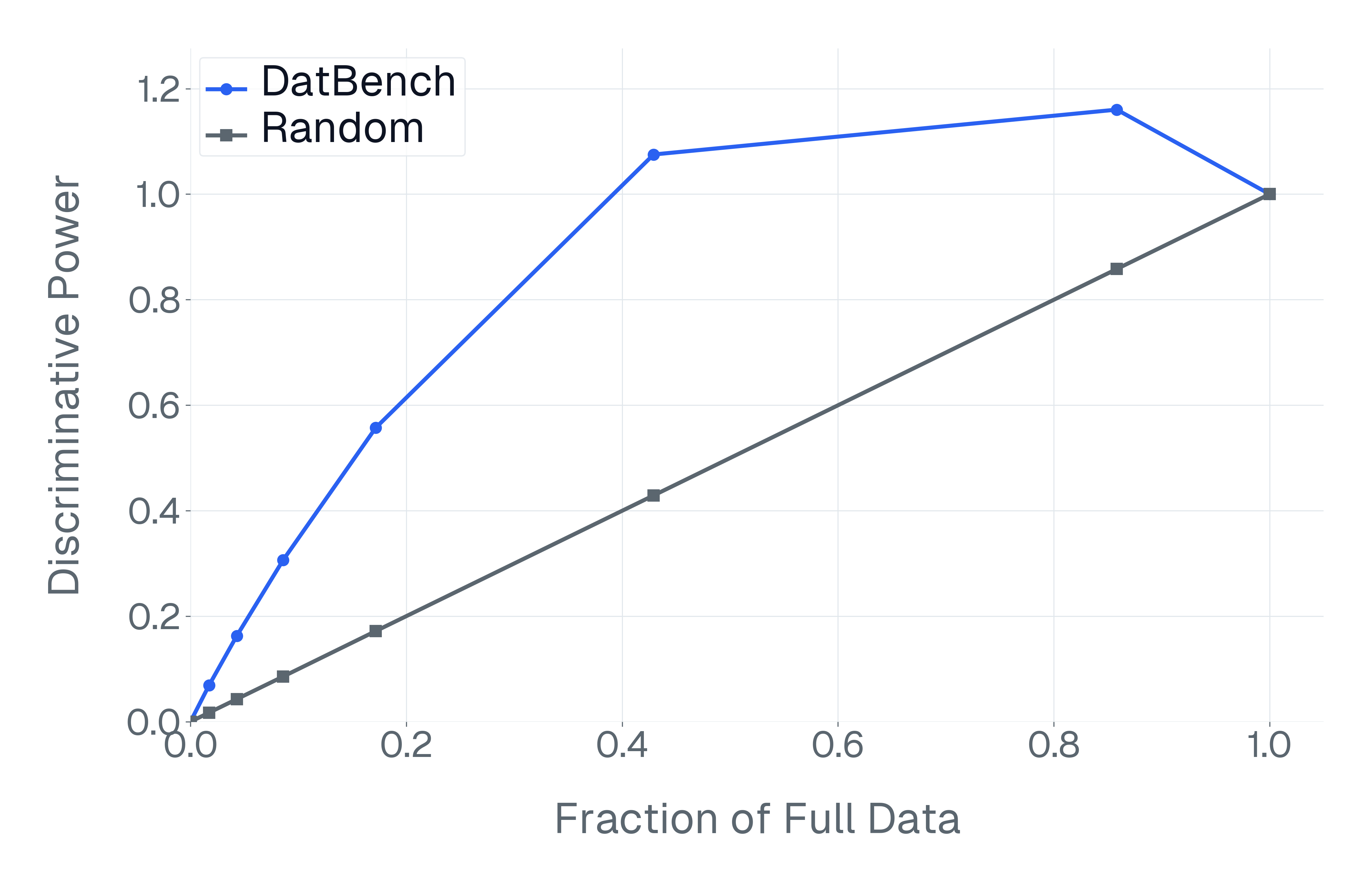
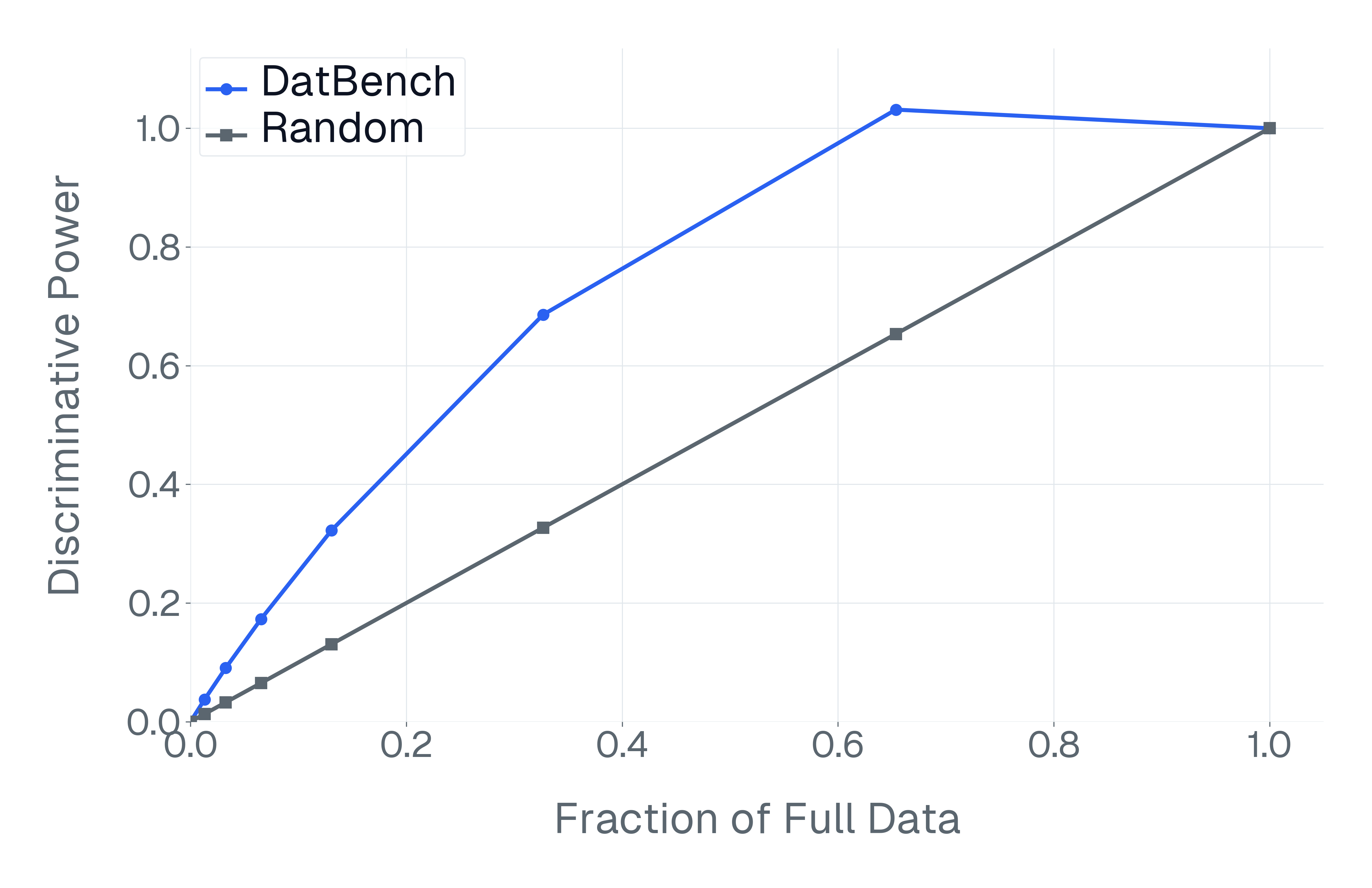
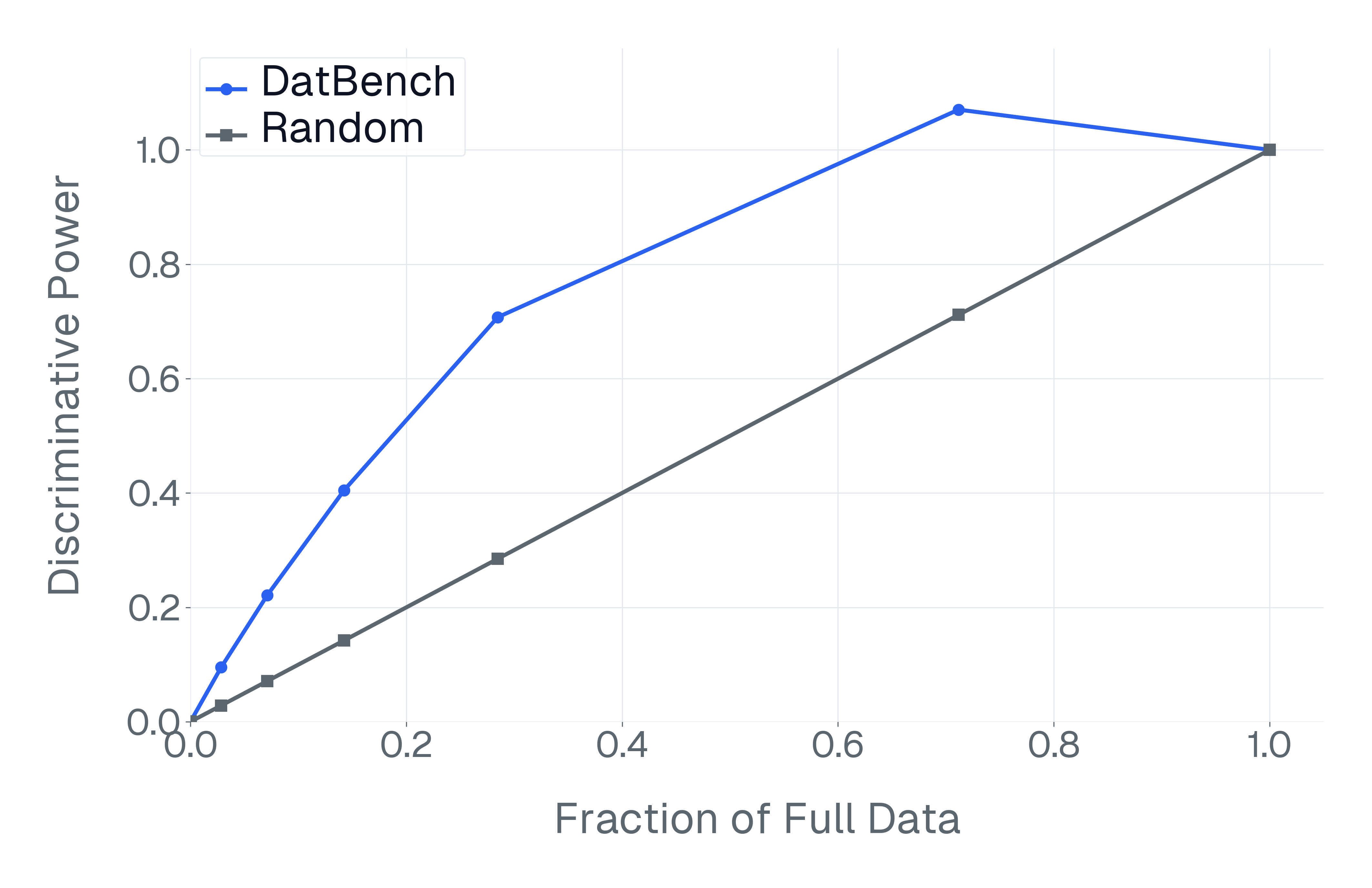
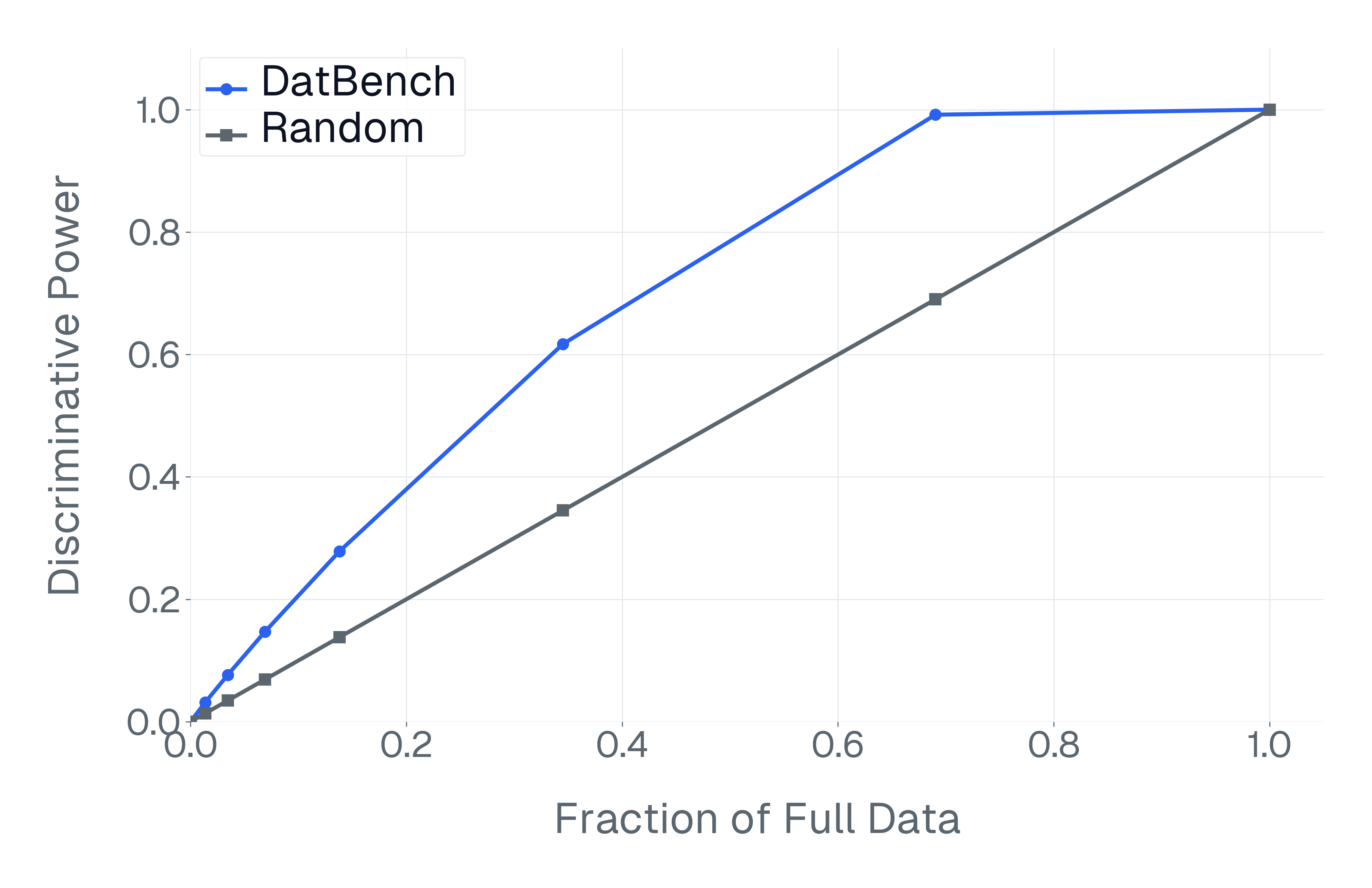
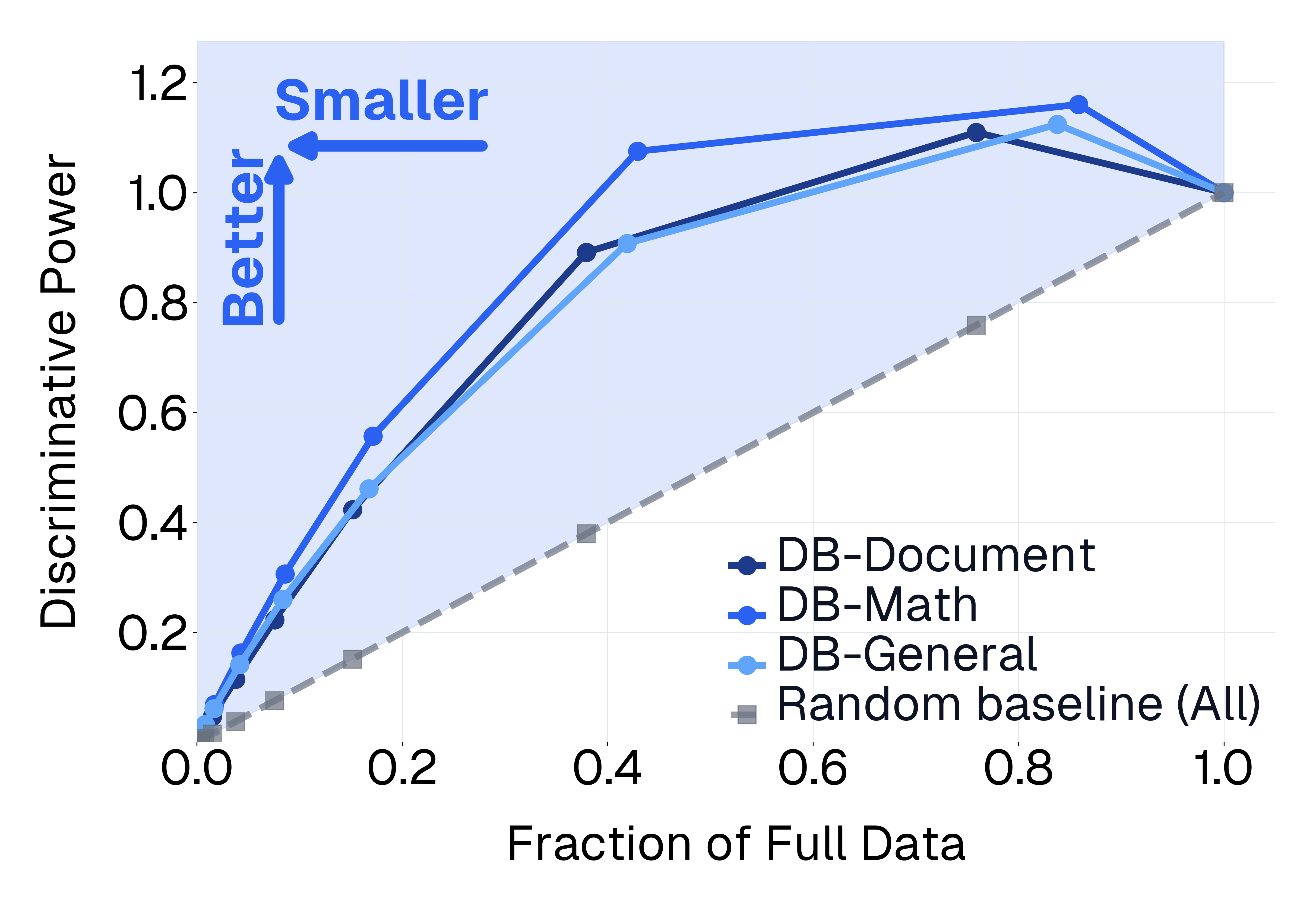
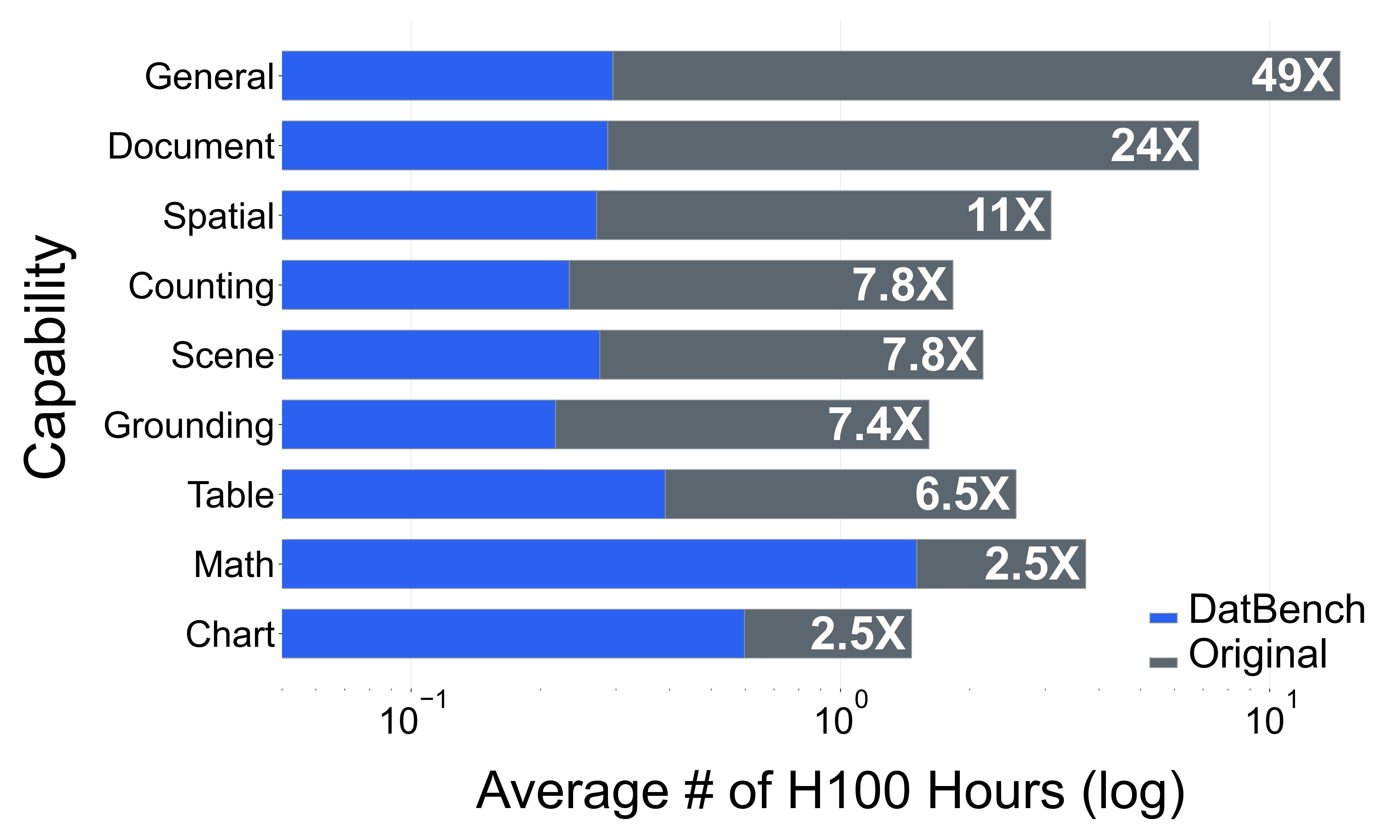
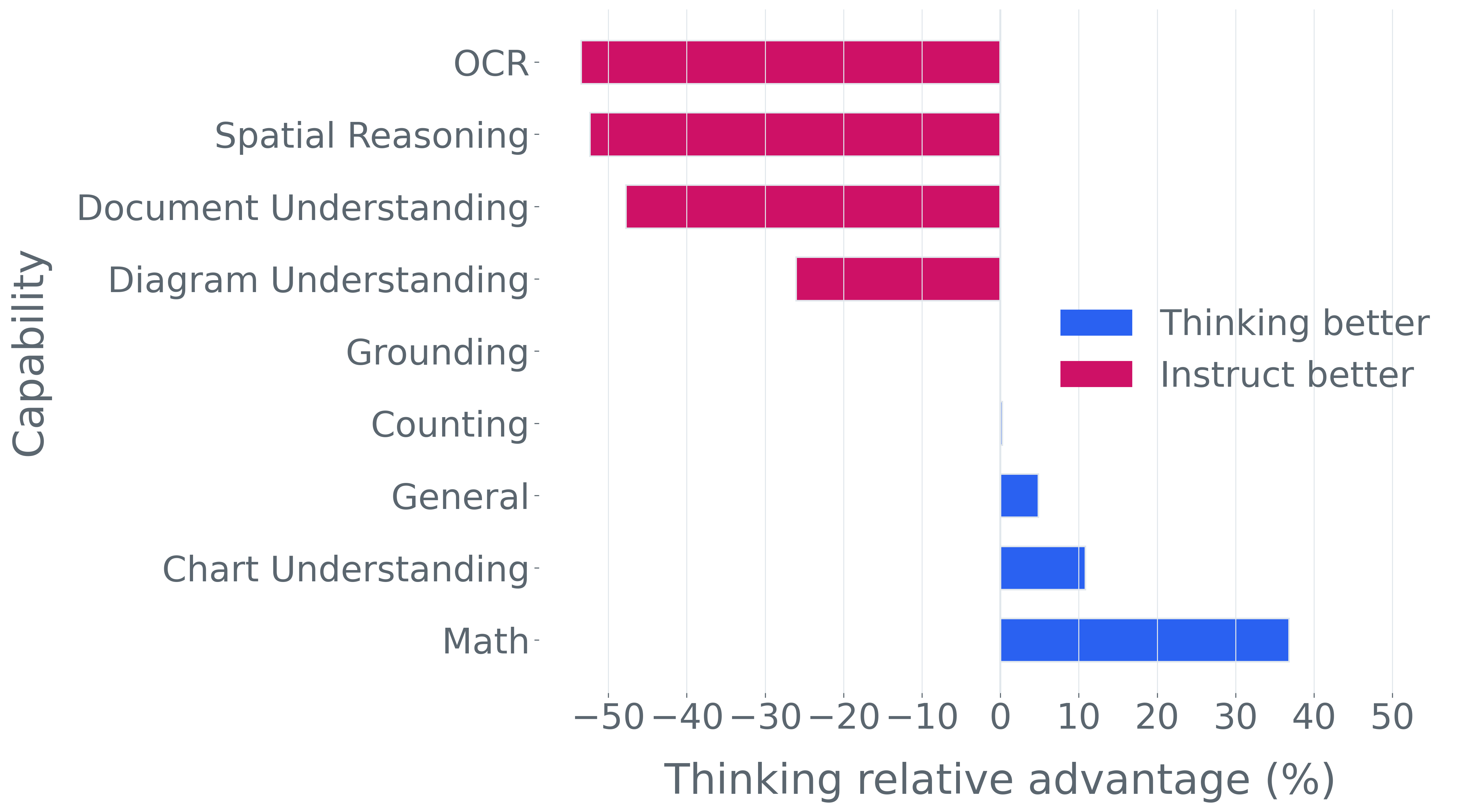
이러한 문제를 해결하기 위해 저자들은 두 가지 핵심 전략을 제시한다. 첫 번째는 형식 변환이다. MCQ를 자유형 생성(generative) 과제로 바꾸면 모델은 정답을 직접 생성해야 하므로 추측이 불가능해지고, 성능 격차가 최대 35%까지 확대된다. 두 번째는 샘플 필터링이다. 블라인드 해결 가능 샘플과 라벨 오류를 사전에 제거하면 평가의 차별력이 크게 상승하고, 동시에 불필요한 연산을 줄일 수 있다. 실제 실험에서는 전체 데이터셋을 13배(최대 50배) 빠르게 평가하면서도 원본과 거의 동일한 모델 순위와 차별성을 유지하는 ‘DATBENCH’ 서브셋을 구축했다.
이 연구가 가지는 의미는 단순히 새로운 벤치마크를 제시하는 데 그치지 않는다. 평가 자체가 연구 비용의 20%를 차지한다는 사실은, 평가 효율성을 개선하는 것이 모델 개발 속도를 가속화하고, 자원 낭비를 방지하는 핵심 과제임을 시사한다. 또한, 평가 데이터의 품질 관리가 모델 신뢰성을 확보하는 데 필수적이라는 점을 재확인한다. 앞으로 VLM이 멀티모달 로봇, 의료 영상 해석, 증강 현실 등 다양한 실세계 응용으로 확장될수록, ‘faithful, discriminative, efficient’한 평가 프레임워크가 학계와 산업계 모두에게 표준이 될 필요가 있다.
📄 논문 본문 발췌 (Translation)
Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, do not represent downstream use-cases, and saturate early as models improve; (ii) 'blindly‑solvable' questions which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize their fidelity and discriminability. We find that transformations such as converting MCQs to generative tasks reveal sharp capability drops of up to 35%. In addition, filtering blindly‑solvable and mislabeled samples enhances the discriminative power of these evaluations, while simultaneously reducing their computational cost. We release DATBENCH‑FULL, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DATBENCH, a discriminative subset that achieves 13× average speedup (up to 50×) while closely matching the discriminative power of the original datasets. Our work provides a path towards evaluation practices that are both rigorous and sustainable as VLMs continue to scale. (Korean academic translation)
본 연구는 기초 모델 연구의 진행 방향을 제시하는 핵심 도구인 실증적 평가가 현재 비전‑언어 모델(VLM) 분야에서 충분히 체계화되지 않았음을 지적한다. 최첨단 VLM의 학습에 관한 연구는 활발히 진행되고 있으나, 이들 모델을 객관적으로 측정하는 평가 방법론은 아직 초기 단계에 머물러 있다. 따라서 우리는 평가가 충족해야 할 세 가지 필수 요건을 제안한다. 첫째, 평가가 해당 모달리티와 실제 적용 상황에 충실해야 함(‘faithfulness’). 둘째, 서로 다른 품질의 모델을 명확히 구분할 수 있어야 함(‘discriminability’). 셋째, 평가 과정이 계산 비용 측면에서 효율적이어야 함(‘efficiency’).
이러한 기준을 적용해 기존 벤치마크의 주요 결함을 분석하였다. 다중 선택(MCQ) 형식은 정답을 추측하도록 유도하고, 실제 downstream 작업을 반영하지 못하며, 모델 성능이 향상될수록 조기에 포화되는 경향이 있다. 또한 이미지 없이도 정답을 도출할 수 있는 ‘blindly‑solvable’ 질문이 전체 평가의 최대 70%를 차지하고, 라벨이 잘못되었거나 모호한 샘플이 특정 데이터셋의 42%까지 존재한다는 사실을 발견하였다. 계산 효율성 측면에서는 최첨단 모델을 평가하는 데 소요되는 연산량이 개발 전체 비용의 약 20%에 달할 정도로 비경제적이다.
우리는 기존 벤치마크를 완전히 폐기하기보다는 변환 및 필터링을 통해 신뢰성과 차별성을 극대화하고 계산 비용을 최소화하는 방안을 제시한다. 구체적으로 MCQ를 생성형(generative) 과제로 전환하면 모델 성능이 급격히 감소하는 현상이 최대 35%까지 관찰된다. 또한 ‘blindly‑solvable’ 샘플과 라벨 오류가 포함된 데이터를 사전에 제거하면 평가의 차별력이 향상될 뿐 아니라 연산 부담도 크게 감소한다.
이러한 과정을 거쳐 9가지 VLM 능력을 포괄하는 33개의 데이터셋으로 구성된 정제된 평가 스위트인 DATBENCH‑FULL을 공개한다. 더불어 원본 데이터셋과 거의 동일한 차별력을 유지하면서 평균 13배(최대 50배) 빠른 평가 속도를 제공하는 서브셋 DATBENCH도 제공한다. 본 연구는 VLM이 지속적으로 규모를 확대함에 따라 평가 관행이 보다 엄격하고 지속 가능하도록 하는 로드맵을 제시한다.