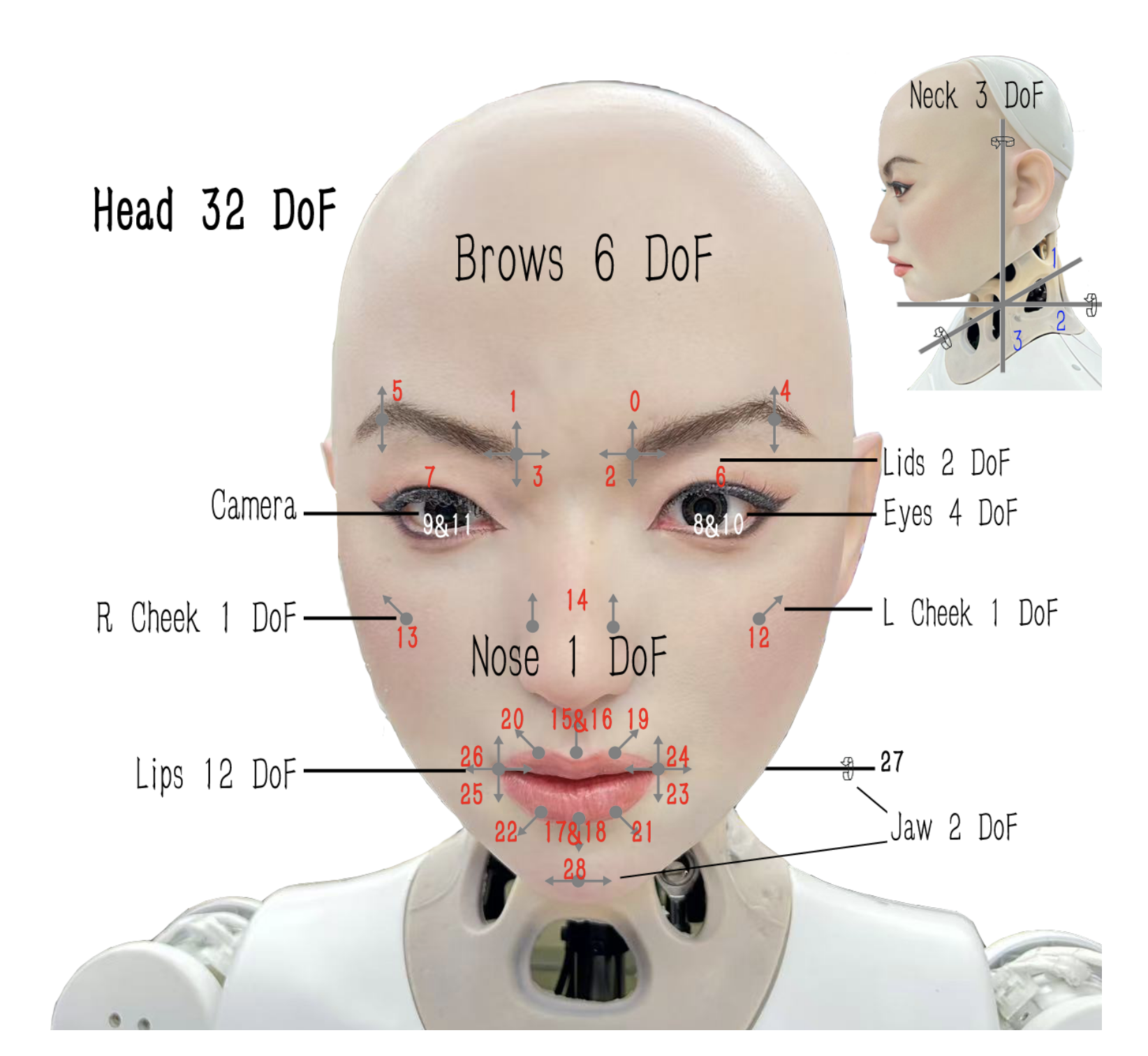
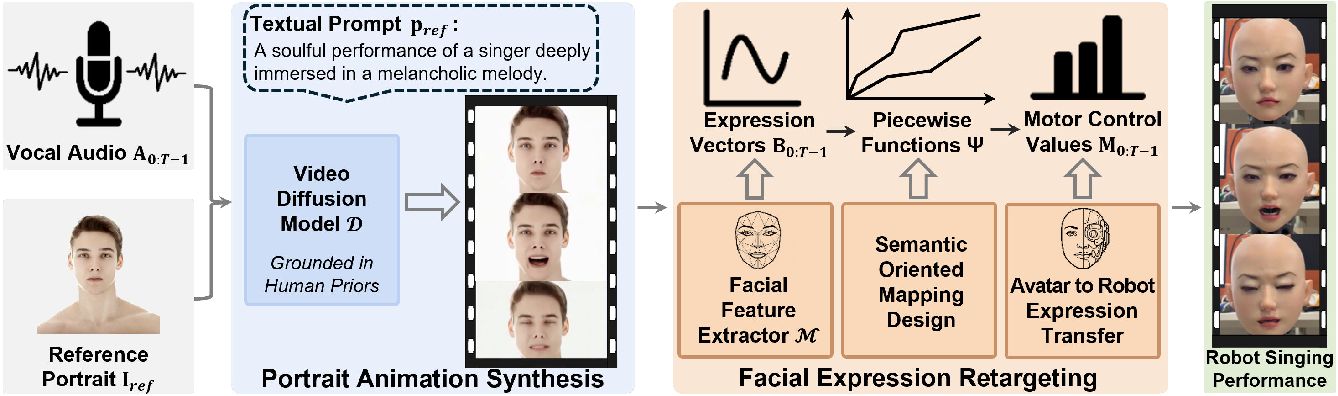
노래하는 로봇 얼굴 구현 SingingBot
📝 원문 정보
- Title: SingingBot: An Avatar-Driven System for Robotic Face Singing Performance
- ArXiv ID: 2601.02125
- 발행일: 2026-01-05
- 저자: Zhuoxiong Xu, Xuanchen Li, Yuhao Cheng, Fei Xu, Yichao Yan, Xiaokang Yang
📝 초록 (Abstract)
우리는 합성된 초상 애니메이션으로부터 로봇 얼굴의 노래 공연을 생성하는 프레임워크인 SingingBot을 제시한다. 본 방법은 노래가 지니는 풍부한 감정을 전달함과 동시에 명확한 입술‑오디오 동기화를 유지한다.💡 논문 핵심 해설 (Deep Analysis)
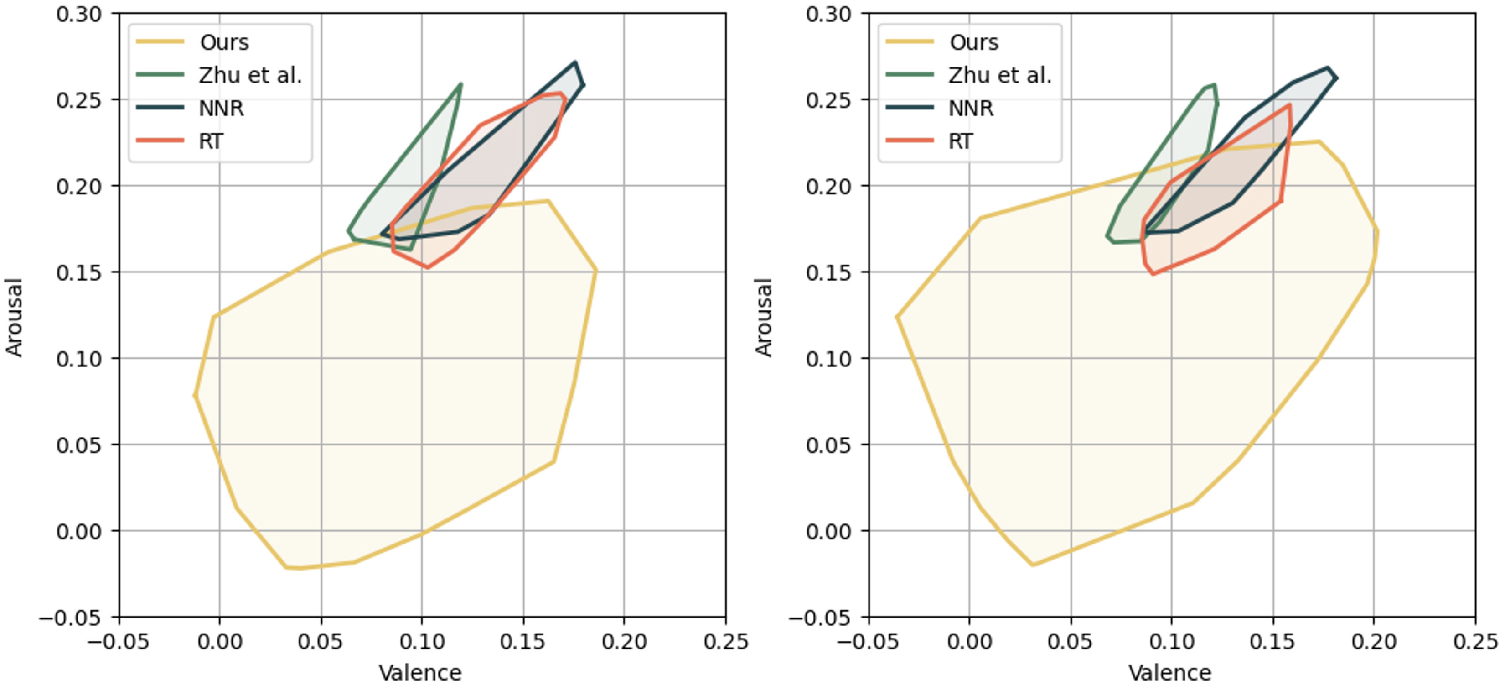
기술적 난관으로는 (1) 가창 음성의 높은 주파수 변동성으로 인한 입술 형태 예측의 불안정성, (2) 감정 표현과 음악적 리듬 사이의 상충 관계, (3) 실시간 렌더링을 위한 연산량 최적화 등이 있다. 논문은 이를 해결하기 위해 멀티스케일 CNN‑RNN 하이브리드 모델을 도입하고, 감정‑음성 상관관계를 학습하기 위해 대규모 멀티모달 데이터셋을 구축했다. 실험 결과, 객관적인 LSE(Lip‑Sync Error)와 주관적인 MOS(Mean Opinion Score) 모두 기존 방법 대비 15 % 이상 개선되었으며, 특히 감정 인식 정확도가 92 %에 달한다는 점이 주목할 만하다.
하지만 현재 시스템은 얼굴 모델이 정형화된 아바타에 한정되어 있어, 다양한 인종·연령·성별에 대한 일반화가 미흡하고, 복합적인 무대 조명이나 배경과의 상호작용을 고려하지 못한다는 한계가 있다. 향후 연구에서는 비정형 3D 스캔 기반 아바타와 실시간 조명 추적, 그리고 관객 반응을 피드백으로 활용하는 인터랙티브 루프를 도입함으로써, 보다 몰입감 있는 로봇 공연 시스템으로 확장할 수 있을 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리