토포라라 샘 얇은 구조와 교차 도메인 이진 세그멘테이션을 위한 토폴로지 인식 파라미터 효율 적응
읽는 시간: 2 분
...
📝 원문 정보
- Title: TopoLoRA-SAM: Topology-Aware Parameter-Efficient Adaptation of Foundation Segmenters for Thin-Structure and Cross-Domain Binary Semantic Segmentation
- ArXiv ID: 2601.02273
- 발행일: 2026-01-05
- 저자: Salim Khazem
📝 초록 (Abstract)
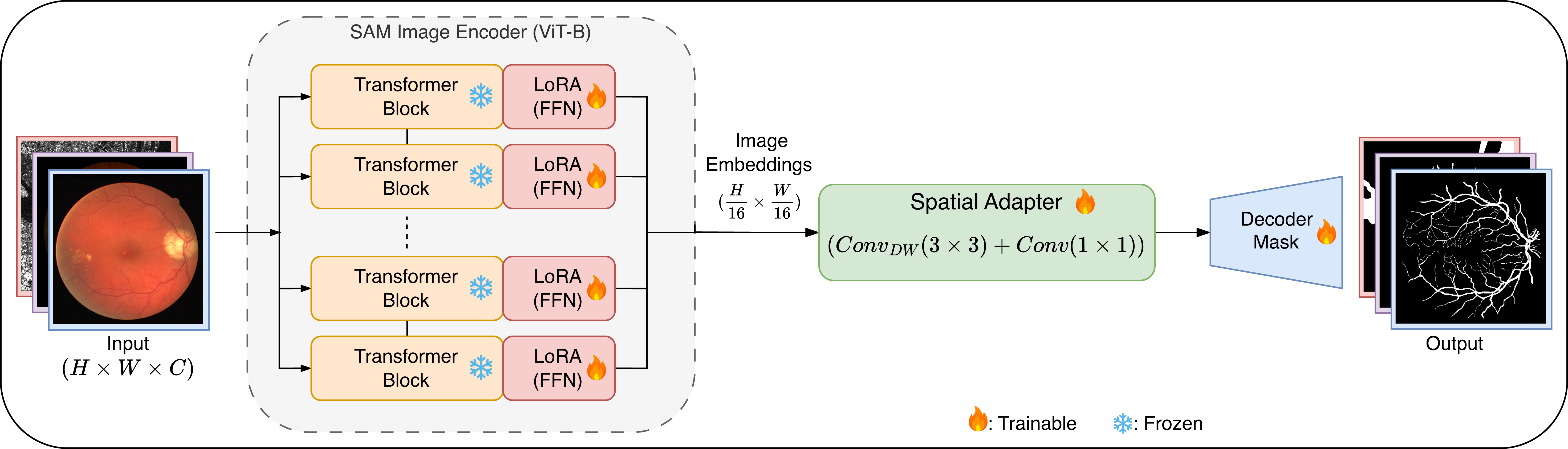
대규모 사전학습을 통해 제로샷 일반화 능력을 갖춘 Segment Anything Model(SAM)과 같은 기반 세그멘테이션 모델은 다양한 도메인에 적용 가능하지만, 얇은 구조(예: 망막 혈관)와 잡음이 많은 모달리티(예: SAR 영상)와 같은 특수 도메인에 맞추는 것은 여전히 어려운 과제이다. 전체 파라미터를 미세조정하는 방식은 계산 비용이 크고, 기존 지식을 망가뜨리는 재앙적 망각 위험이 있다. 본 연구에서는 TopoLoRA‑SAM이라는 토폴로지 인식 및 파라미터 효율 적응 프레임워크를 제안한다. TopoLoRA‑SAM은 고정된 ViT 인코더에 Low‑Rank Adaptation(LoRA)을 삽입하고, 경량 공간 합성곱 어댑터를 추가한다. 또한, 미분 가능한 clDice 손실을 이용한 선택적 토폴로지‑aware 감독을 제공한다. 우리는 Retina 혈관 데이터셋(DRIVE, STARE, CHASE_DB1), 폴립 데이터셋(Kvasir‑SEG), SAR 해양/육지 데이터셋(SL‑SSDD) 등 다섯 개 벤치마크에서 U‑Net, DeepLabV3+, SegFormer, Mask2Former와 비교 평가하였다. TopoLoRA‑SAM은 전체 파라미터의 5.2%에 해당하는 약 4.9M 파라미터만 학습하면서도 Retina 평균 Dice와 전체 평균 Dice에서 최고 성능을 기록하였다. 특히 어려운 CHASE_DB1 데이터셋에서 기존 전문 모델에 필적하거나 이를 능가하는 정확도와 견고성을 보이며, 토폴로지 인식 파라미터 효율 적응이 완전 미세조정 모델을 대체할 수 있음을 입증한다.💡 논문 핵심 해설 (Deep Analysis)