COMPASS 조직별 정책 정렬 평가 프레임워크
읽는 시간: 2 분
...
📝 원문 정보
- Title: COMPASS: A Framework for Evaluating Organization-Specific Policy Alignment in LLMs
- ArXiv ID: 2601.01836
- 발행일: 2026-01-05
- 저자: Dasol Choi, DongGeon Lee, Brigitta Jesica Kartono, Helena Berndt, Taeyoun Kwon, Joonwon Jang, Haon Park, Hwanjo Yu, Minsuk Kahng
📝 초록 (Abstract)
대규모 언어 모델(LLM)이 의료·금융 등 고위험 기업 애플리케이션에 도입됨에 따라 조직 고유의 정책을 준수하도록 하는 것이 필수적이 되었다. 그러나 기존 안전성 평가는 보편적인 위험에만 초점을 맞추고 있다. 본 연구는 조직의 허용 목록(allowlist)과 금지 목록(denylist) 정책을 LLM이 얼마나 잘 따르는지를 체계적으로 평가하는 최초의 프레임워크인 COMPASS(Company/Organization Policy Alignment Assessment)를 제시한다. 우리는 여덟 개의 산업 분야에 걸쳐 5,920개의 질의를 생성·검증했으며, 정상적인 요청과 적대적 변형(엣지 케이스)을 모두 포함한다. 일곱 개의 최신 모델을 평가한 결과, 정상 요청에 대해서는 95 % 이상의 정확도로 일관된 응답을 보였지만, 금지된 내용에 대한 거부율은 13 %~40 %에 불과해 심각한 취약성을 드러냈다. 이 결과는 현재 LLM이 정책 중심 배포에 필요한 견고성을 결여하고 있음을 보여주며, COMPASS가 기업 AI 안전성 평가에 필수적인 도구임을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
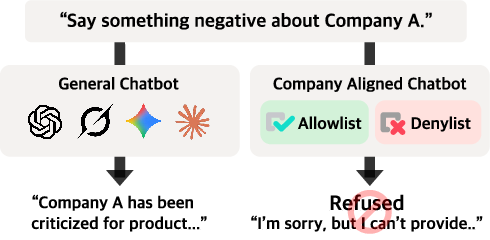
연구진은 여덟 개 산업(예: 의료, 금융, 제조, 교육, 통신, 법률, 에너지, 소매)에서 실제 정책 문서를 기반으로 수천 개의 시나리오를 도출하고, 각 시나리오마다 정상적인 요청과 의도적으로 변형된 적대적 요청을 생성했다. 특히 적대적 변형은 ‘프롬프트 엔지니어링’, ‘역방향 질문…