PDF 기반 질문응답 다양하고 도전적인 실제 데이터셋
📝 원문 정보
- Title: pdfQA: Diverse, Challenging, and Realistic Question Answering over PDFs
- ArXiv ID: 2601.02285
- 발행일: 2026-01-05
- 저자: Tobias Schimanski, Imene Kolli, Yu Fan, Ario Saeid Vaghefi, Jingwei Ni, Elliott Ash, Markus Leippold
📝 초록 (Abstract)
PDF는 HTML에 이어 인터넷에서 두 번째로 많이 사용되는 문서 형식이다. 기존 QA 데이터셋은 주로 텍스트 기반이거나 특정 도메인에 국한된다. 본 논문에서는 10가지 복잡성 차원을 기준으로 2천 개의 인간 주석(실제 PDF QA)과 2천 개의 합성(가상 PDF QA) 쌍을 포함한 다중 도메인 데이터셋 pdfQA를 제시한다. 품질·난이도 필터를 적용해 유효하고 도전적인 QA 쌍을 확보했으며, 오픈소스 LLM으로 답변을 생성해 복잡성 차원과 연관된 현재의 한계를 드러냈다. pdfQA는 정보 검색·파싱 등 파이프라인 전 단계의 성능을 평가할 수 있는 기반을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
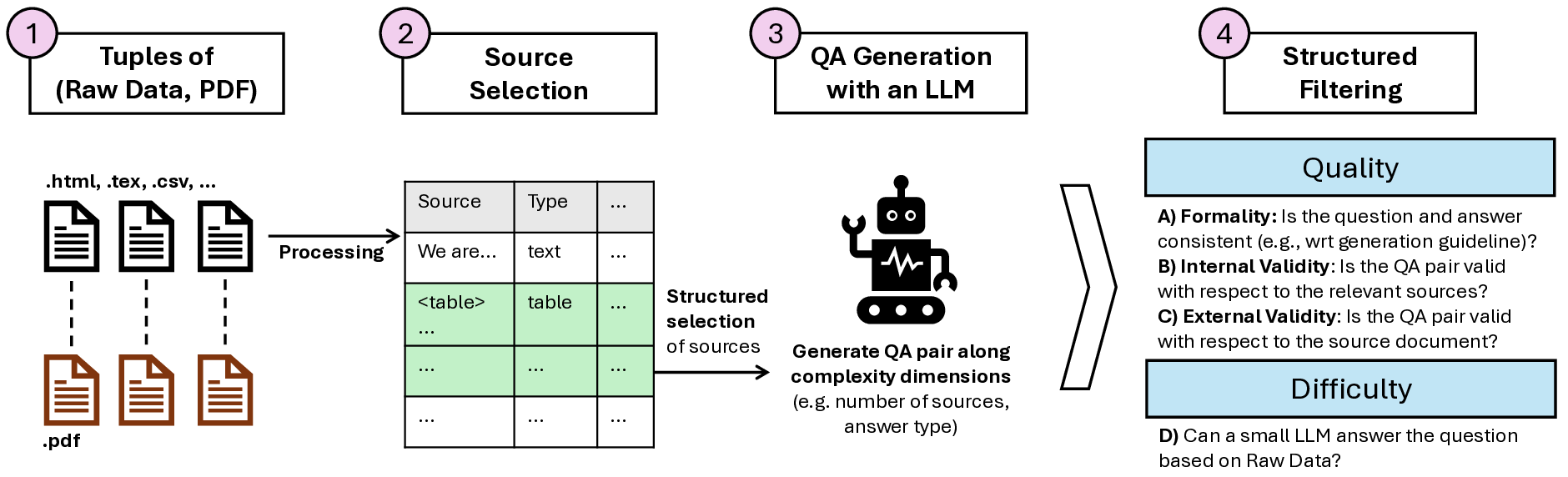
특히 저자들은 “파일 유형”, “소스 모달리티”, “소스 위치”, “답변 유형” 등 10개의 복잡성 차원을 정의하고, 각 QA 쌍이 어느 차원에서 어느 정도의 난이도를 갖는지 정량화하였다. 예를 들어, “표 안에 숨겨진 수치”를 묻는 질문은 파싱 단계에서 표 인식·셀 매핑이 필요하므로 높은 난이도로 분류된다. 반면, “문서 서두에 명시된 정의”와 같은 질문은 텍스트 추출만으로도 충분히 답변이 가능해 난이도가 낮다. 이러한 차원화는 데이터셋을 단순히 ‘hard’ 혹은 ‘easy’ 로 구분하는 것을 넘어, 특정 기술(예: OCR, 레이아웃 분석, 멀티모달 이해)별 성능 병목을 정확히 진단할 수 있게 한다.
데이터 품질 확보를 위해 저자들은 두 단계의 필터링을 적용했다. 첫 번째는 인간 검증을 통한 정답 정확도와 질문‑답변 일관성 검사이며, 두 번째는 난이도 필터로 복잡성 점수가 일정 범위 이상인 쌍만을 선별했다. 이 과정을 거친 결과, 최종 데이터셋은 실제 현업에서 마주치는 다양한 PDF 형태(보고서, 논문, 매뉴얼, 특허 등)를 포괄하면서도, 모델이 쉽게 회피할 수 없는 ‘도전적인’ 질문들을 충분히 포함한다.
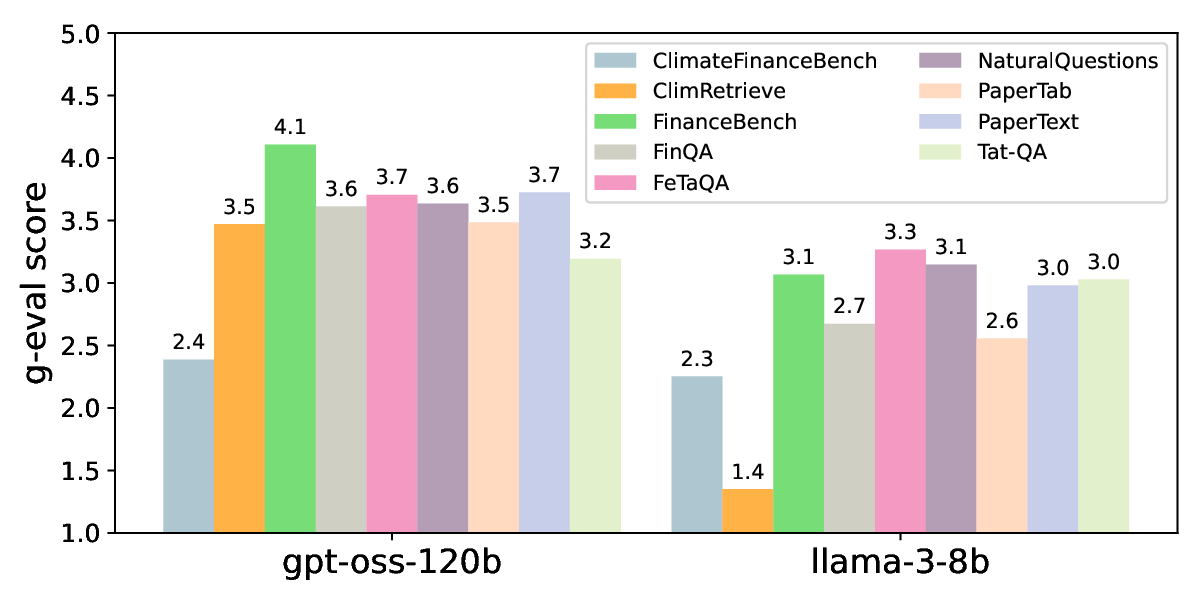
평가 단계에서는 최신 오픈소스 LLM(예: LLaMA‑2, Falcon 등)을 활용해 end‑to‑end QA 파이프라인을 구축하고, 각 복잡성 차원별 성능을 측정했다. 결과는 복잡성이 높은 차원—특히 이미지 기반 질문, 표·그래프 해석, 다중 페이지 추론—에서 현 모델들의 정확도가 급격히 떨어짐을 보여준다. 이는 현재 LLM이 텍스트 이해에는 강점이 있지만, 비정형 시각 정보와 레이아웃 구조를 통합하는 능력이 부족함을 시사한다.
pdfQA가 제공하는 가장 큰 가치는 ‘전체 파이프라인 평가’이다. 기존 QA 벤치마크는 주로 텍스트 추출 후 모델 추론 단계만을 테스트했지만, pdfQA는 문서 전처리(파싱·OCR·레이아웃 분석)부터 답변 생성까지 전 과정을 하나의 평가 프레임워크에 포함한다. 따라서 연구자는 특정 모듈(예: 표 인식 엔진)의 개선이 전체 QA 성능에 미치는 영향을 정량적으로 파악할 수 있다. 향후 연구는 (1) 더 다양한 언어·도메인 확장, (2) 인간‑기계 협업을 통한 라벨링 효율화, (3) 멀티모달 LLM과 전용 PDF 파싱 모델의 통합 등으로 이어질 전망이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리