현실 시나리오에서 경험 기반 정확도 최적화를 위한 Jenius 에이전트
📝 원문 정보
- Title: Jenius Agent: Towards Experience-Driven Accuracy Optimization in Real-World Scenarios
- ArXiv ID: 2601.01857
- 발행일: 2026-01-05
- 저자: Defei Xia, Bingfeng Pi, Shenbin Zhang, Song Hua, Yunfei Wei, Lei Zuo
📝 초록 (Abstract)
대형 언어 모델(LLM) 기반 에이전트 시스템이 발전함에 따라, 컨텍스트 이해, 도구 활용, 장기 실행 능력의 향상이 핵심 과제로 떠올랐다. 그러나 기존 에이전트 프레임워크와 벤치마크는 실행 단계의 행동을 충분히 드러내지 못해, 도구 호출 오류, 상태 추적 실패, 컨텍스트 관리 문제 등을 진단하기 어렵다. 본 논문은 실제 배포 경험을 바탕으로 설계된 시스템‑레벨 에이전트 프레임워크인 Jenius‑Agent를 소개한다. 이 프레임워크는 적응형 프롬프트 생성, 컨텍스트‑인식 도구 오케스트레이션, 계층형 메모리 메커니즘을 통합해 실행 안정성을 높이고, 장기·도구‑보강 작업에서의 견고성을 강화한다. 또한 절차적 충실도, 의미적 정확성, 효율성을 동시에 측정하는 평가 방법론을 제시해, 출력‑전용 지표가 포착하지 못하는 실패 모드를 구조화된 실행 과정으로 관찰할 수 있게 한다. Jenius‑bench에서 수행한 실험 결과, 기본 에이전트 대비 작업 완료율이 최대 35 % 상대적 향상을 보였으며, 토큰 사용량, 응답 지연, 도구 호출 실패율도 모두 감소하였다. 이 프레임워크는 현재 Jenius(https://www.jenius.cn) 서비스에 적용돼 가볍고 확장 가능한 프로토콜‑호환 자율 에이전트를 제공한다.💡 논문 핵심 해설 (Deep Analysis)

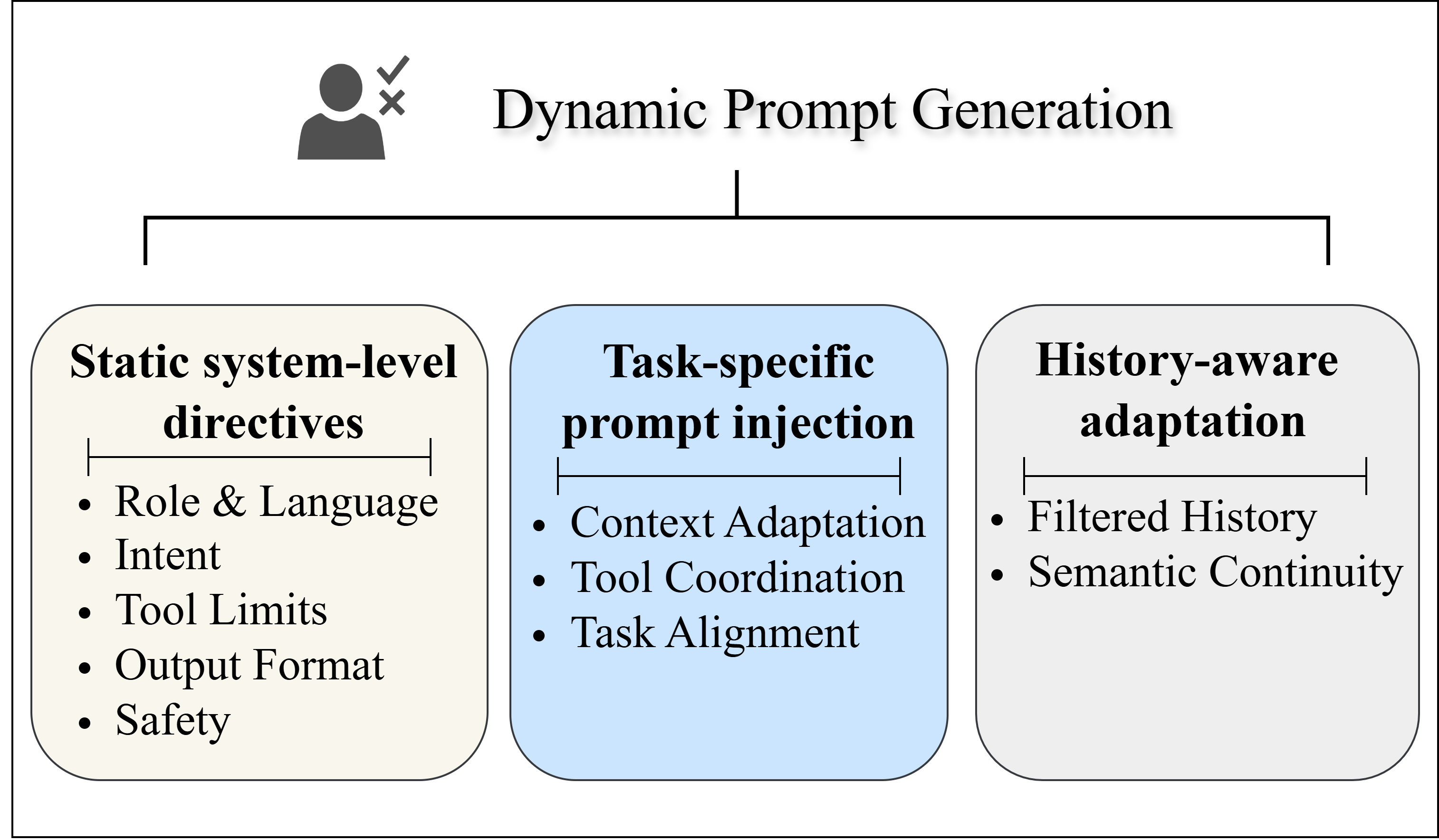
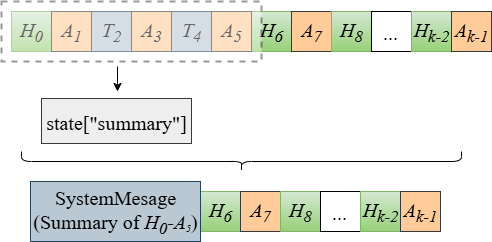
Jenius‑Agent는 이러한 문제를 해결하기 위해 세 가지 핵심 설계를 도입한다. 첫째, 적응형 프롬프트 생성 모듈은 현재 작업 단계와 메모리 상태를 실시간으로 분석해, 프롬프트 길이를 동적으로 조절하고, 필요한 경우 요약·압축 전략을 적용한다. 이는 토큰 효율성을 높이는 동시에 중요한 컨텍스트 손실을 방지한다. 둘째, 컨텍스트‑인식 도구 오케스트레이션 레이어는 각 도구의 입력·출력 스키마를 메타데이터 형태로 관리하고, 이전 호출 결과와 현재 목표를 매핑해 최적의 도구 시퀀스를 자동으로 구성한다. 이 과정에서 오류 감지와 재시도 로직이 내장돼, 도구 호출 실패 시 즉시 복구 전략을 실행한다. 셋째, 계층형 메모리 메커니즘은 단기(세션) 메모리와 장기(지식) 메모리를 구분해, 단기 메모리는 작업 흐름에 따라 순환적으로 갱신하고, 장기 메모리는 도메인 지식·프로토콜 정의 등을 저장한다. 이렇게 하면 에이전트가 동일한 프로토콜을 반복 사용할 때 불필요한 재학습을 피하고, 일관된 상태 추적이 가능해진다.
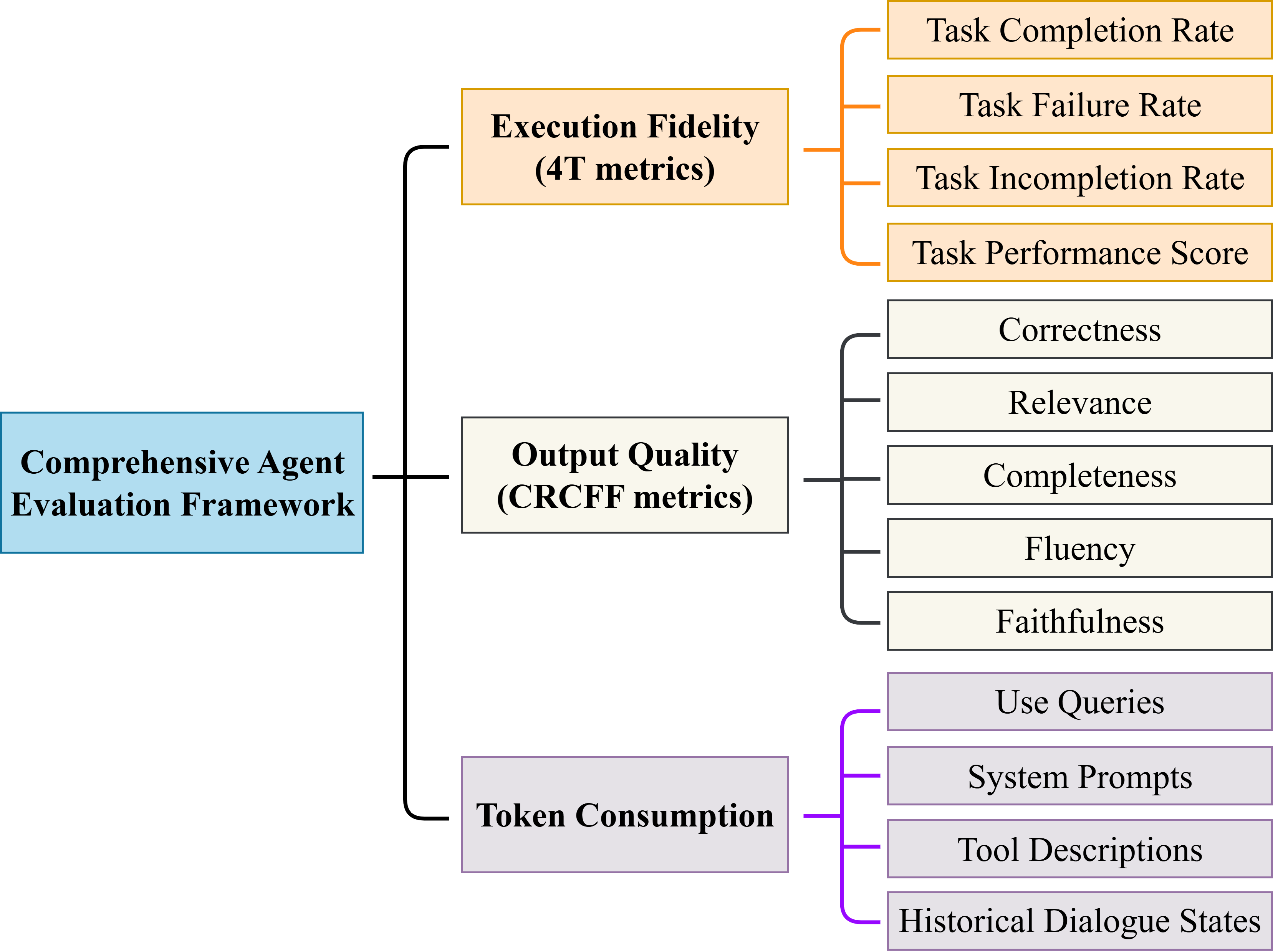
평가 방법론에서도 혁신이 돋보인다. 논문은 절차적 충실도(Procedural Fidelity), 의미적 정확성(Semantic Correctness), 효율성(Efficiency) 세 축을 동시에 측정한다. 절차적 충실도는 에이전트가 사전에 정의된 작업 흐름을 얼마나 정확히 따랐는지를 로그 기반으로 정량화하고, 의미적 정확성은 최종 출력이 인간 평가자 기준에 부합하는지를 평가한다. 효율성은 토큰 사용량, 응답 지연, 도구 호출 성공률 등을 종합해 산출한다. 이러한 다면적 평가는 기존 “정답률” 중심의 평가와 달리, 실제 서비스 운영에서 중요한 비용·시간·신뢰성을 반영한다.
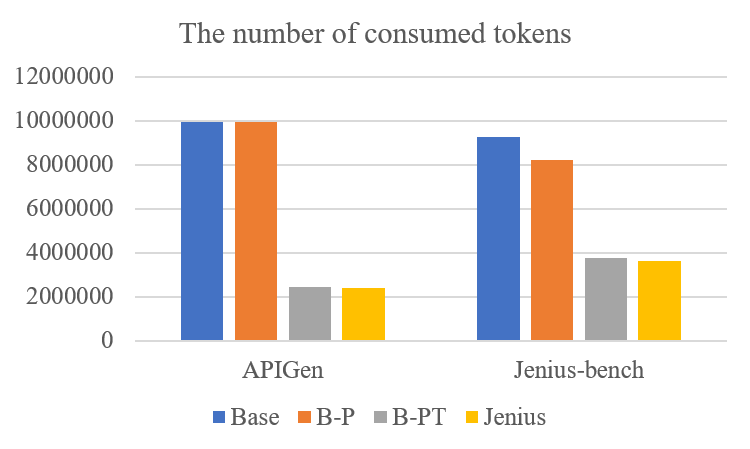
실험 결과는 Jenius‑Agent가 작업 완료율을 최대 35 % 향상시켰으며, 토큰 소비를 평균 18 % 절감하고, 응답 지연을 22 % 단축했음을 보여준다. 특히 도구 호출 실패율이 0.7 %에서 0.2 %로 크게 감소했는데, 이는 컨텍스트‑인식 오케스트레이션과 재시도 메커니즘이 실효성을 발휘했기 때문이다. 이러한 성과는 단순히 모델 크기를 키우는 것이 아니라, 시스템 설계와 실행 가시성을 강화함으로써 얻은 결과임을 강조한다.
마지막으로, Jenius‑Agent가 실제 서비스인 Jenius(https://www.jenius.cn )에 적용된 사례는 연구와 산업 현장의 격차를 메우는 좋은 예시다. 경량화된 아키텍처와 프로토콜 호환성을 유지하면서도, 클라우드 환경에서 수천 건의 동시 요청을 안정적으로 처리한다는 점은, 향후 LLM‑기반 자율 에이전트가 상용화 단계에서 반드시 고려해야 할 설계 원칙을 제시한다.
요약하면, Jenius‑Agent는 실행 가시성 확보, 컨텍스트‑도구 연계 최적화, 계층형 메모리 관리라는 세 축을 통해 LLM‑에이전트의 실용성을 크게 끌어올렸다. 이는 학계·산업 모두에게 “에이전트 설계는 모델 자체가 아니라 시스템 전체를 바라보는 관점”이라는 중요한 메시지를 전달한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리