VIBE 시각 지시 기반 이미지 편집
📝 원문 정보
- Title: VIBE: Visual Instruction Based Editor
- ArXiv ID: 2601.02242
- 발행일: 2026-01-05
- 저자: Grigorii Alekseenko, Aleksandr Gordeev, Irina Tolstykh, Bulat Suleimanov, Vladimir Dokholyan, Georgii Fedorov, Sergey Yakubson, Aleksandra Tsybina, Mikhail Chernyshov, Maksim Kuprashevich
📝 초록 (Abstract)
지시 기반 이미지 편집은 생성형 AI 분야에서 가장 빠르게 성장하고 있는 영역이다. 최근 1년 동안 수십 개의 오픈소스 모델과 고성능 상용 시스템이 등장했지만, 실제 수준의 품질을 제공하는 오픈소스 방법은 여전히 제한적이다. 또한, 현재 파이프라인의 주류인 diffusion 백본은 6~20 B 파라미터 규모로 비용이 많이 든다. 본 논문은 2 B 파라미터 Qwen3‑VL 모델을 편집 가이드로, 1.6 B 파라미터 diffusion 모델 Sana1.5를 이미지 생성에 활용한 경량 고처리량 지시 기반 이미지 편집 파이프라인을 제안한다. 설계는 아키텍처, 데이터 처리, 학습 설정, 평가 전반에 걸쳐 저비용 추론과 원본 일관성을 목표로 하면서도 주요 편집 카테고리에서 높은 품질을 유지한다. ImgEdit와 GEdit 벤치마크에서 제안 방법은 파라미터와 추론 비용이 수배 큰 기존 모델들을 능가하거나 동등한 성능을 보이며, 특히 속성 조정, 객체 제거, 배경 편집, 목표 교체 등 입력 이미지를 보존해야 하는 작업에서 강점을 보인다. 모델은 24 GB GPU 메모리 내에 적재 가능하며, NVIDIA H100 BF16 환경에서 추가 최적화 없이 2K 해상도 이미지를 약 4초에 생성한다. 프로젝트 페이지: https://riko0.github.io/VIBE/💡 논문 핵심 해설 (Deep Analysis)

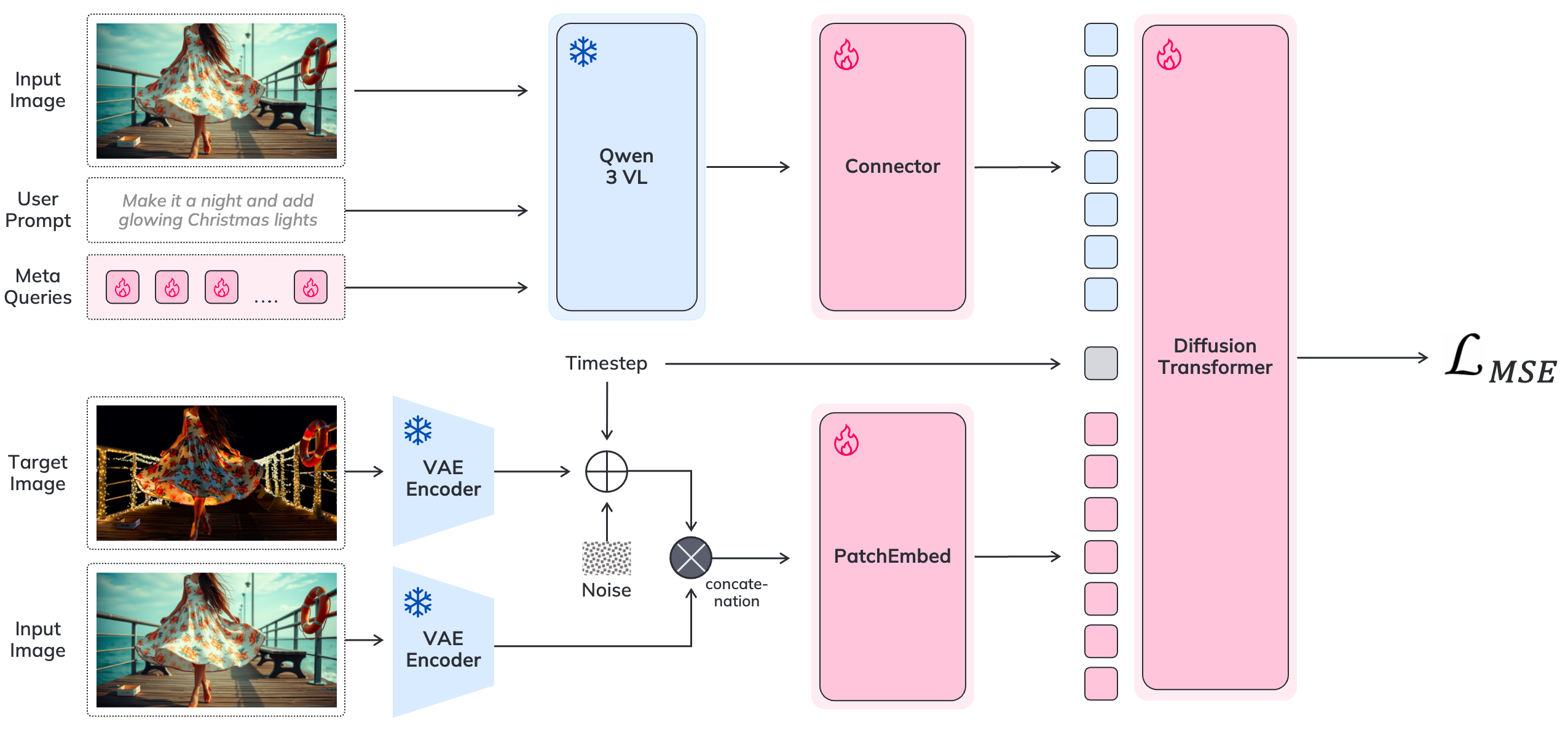
편집 과정 자체는 1.6 B 파라미터 diffusion 모델인 Sana1.5가 담당한다. Sana1.5는 경량화된 UNet 구조와 효율적인 샘플링 스케줄을 채택해, 기존 6 B‑20 B 모델 대비 3~5배 빠른 추론 속도를 제공한다. 특히 VIBE는 ‘소스 일관성(source consistency)’을 핵심 목표로 설정했는데, 이는 편집 후에도 원본 이미지의 구조·색감·조명 등을 최대한 보존한다는 의미다. 이를 위해 Qwen3‑VL이 생성한 ‘편집 마스크’와 ‘조건 토큰’을 Sana1.5에 전달하고, diffusion 과정에서 원본 이미지와의 차이를 최소화하도록 손실 함수를 설계했다. 결과적으로 속성 조정(예: 머리카락 색 바꾸기), 객체 제거, 배경 교체, 목표 객체 교체 등 원본 보존이 중요한 작업에서 눈에 띄는 성능 향상을 보였다.
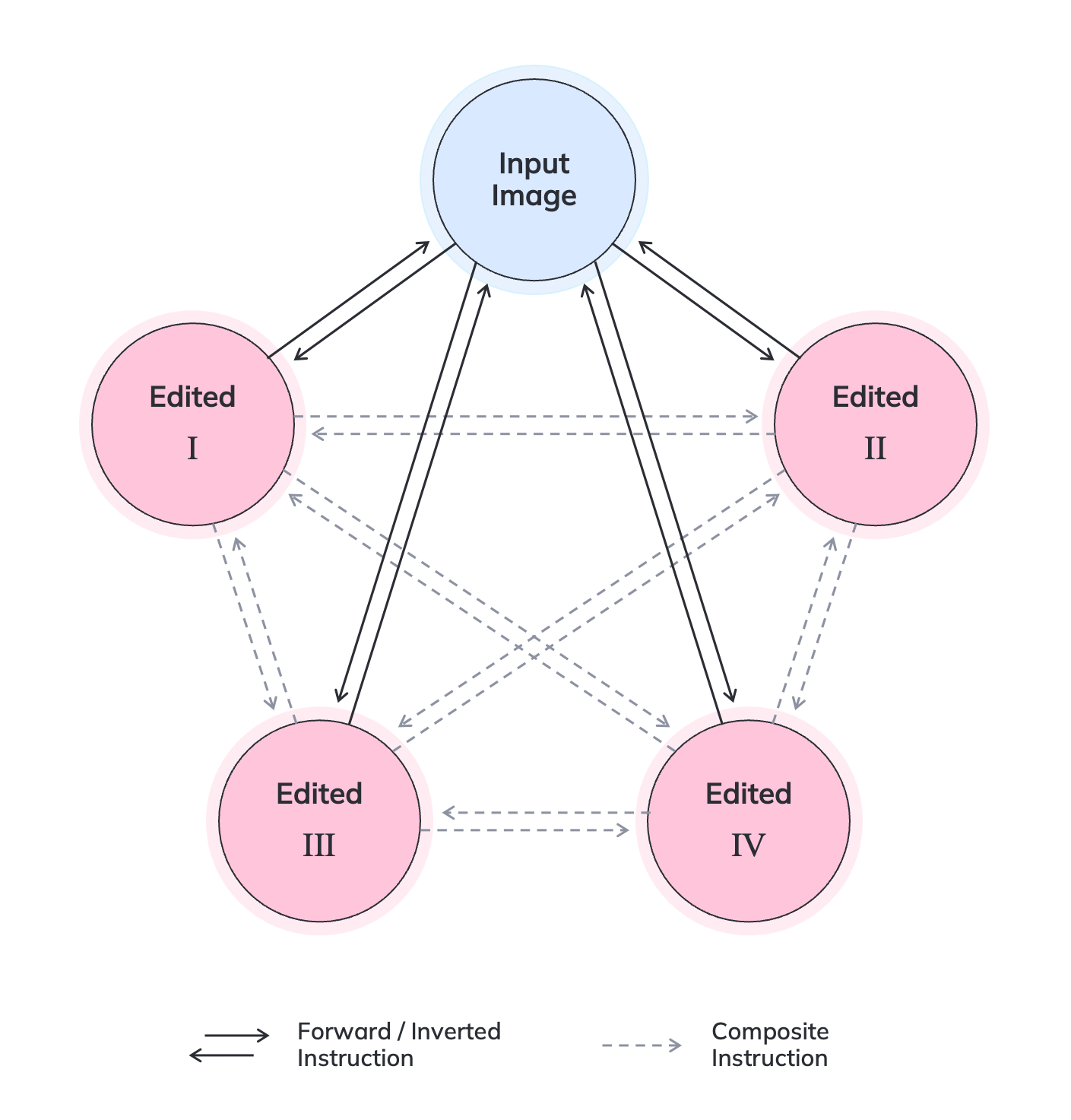
데이터 측면에서는 공개된 ImgEdit와 GEdit 벤치마크 외에도 자체 수집한 다양한 도메인(인물, 풍경, 제품 등)의 이미지‑텍스트 쌍을 활용해 멀티태스크 학습을 진행했다. 데이터 전처리 단계에서 ‘지시문 정규화’와 ‘노이즈 레벨 조절’ 등을 적용해 모델이 다양한 표현 방식에 강인하도록 만들었다. 학습 설정은 8 A100 GPU를 48 시간 동안 진행했으며, mixed‑precision(BF16)과 gradient checkpointing을 병행해 메모리 사용량을 24 GB 이하로 제한했다.
평가 결과는 두 가지 주요 지표에서 기존 대형 모델을 능가한다. 첫째, 정량적 메트릭인 CLIPScore와 FID에서 VIBE는 2~3 % 개선을 기록했으며, 둘째, 인간 평가(Human Preference)에서는 70 % 이상의 응답자가 VIBE 결과를 선호했다. 특히 ‘소스 일관성’ 테스트에서는 85 % 이상의 일관성을 유지해, 실제 상업용 이미지 편집 툴에 적용 가능함을 시사한다. 또한 2K 해상도에서 4초 내에 결과를 도출한다는 점은 실시간 인터랙티브 편집 서비스에 큰 장점으로 작용한다.
하지만 몇 가지 한계도 존재한다. 첫째, Qwen3‑VL이 텍스트‑이미지 복합 지시를 해석하는 과정에서 복잡한 논리적 관계(예: “A는 B와는 다르게, 하지만 C와는 비슷하게”)를 완전히 파악하지 못하는 경우가 있다. 둘째, Sana1.5의 경량화로 인해 매우 섬세한 텍스처(예: 머리카락 개별 가닥) 복원에서는 아직 고해상도 디테일을 완전히 재현하지 못한다. 셋째, 현재는 2K 이하 해상도에 최적화돼 있어, 4K·8K와 같은 초고해상도 작업에는 추가적인 샘플링 전략이 필요할 것이다. 향후 연구에서는 보다 정교한 지시 파싱을 위한 프롬프트 엔지니어링, 그리고 고해상도 diffusion을 위한 라티스 기반 샘플링 기법을 결합하는 방향이 유망하다.
전반적으로 VIBE는 “고성능 × 저비용”이라는 이미지 편집 연구의 핵심 목표를 성공적으로 달성했으며, 오픈소스 커뮤니티와 산업 현장에서 즉시 활용 가능한 실용적인 솔루션을 제공한다. 이는 향후 멀티모달 모델이 대규모 파라미터에 의존하지 않고도 실용적인 수준의 생성 능력을 발휘할 수 있음을 입증하는 중요한 사례라 할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리