고차 행동 정규화로 딥 강화학습의 부드러운 제어 구현 에너지 관리까지
📝 원문 정보
- Title: Higher-Order Action Regularization in Deep Reinforcement Learning: From Continuous Control to Building Energy Management
- ArXiv ID: 2601.02061
- 발행일: 2026-01-05
- 저자: Faizan Ahmed, Aniket Dixit, James Brusey
📝 초록 (Abstract)
딥 강화학습 에이전트는 고주파·불안정한 제어 행동을 보이는 경우가 많아 실제 적용 시 에너지 소모와 기계 마모가 크게 증가한다. 본 연구는 연속 제어 벤치마크에서 고차 미분값에 대한 페널티를 적용한 행동 매끄러움 정규화 방법을 체계적으로 조사하고, 이를 건물 에너지 관리에 적용하여 실증한다. 네 개의 연속 제어 환경에 대한 포괄적 평가 결과, 3차 미분(jerk) 페널티가 가장 일관되게 매끄러운 행동을 유도하면서도 성능 저하가 거의 없음을 확인하였다. HVAC 제어 시스템에 적용한 실험에서는 매끄러운 정책이 장비 스위칭을 60 % 감소시켜 운영 효율성을 크게 향상시켰다. 본 연구는 고차 행동 정규화가 강화학습 최적화와 에너지‑중심 실무 제약을 연결하는 효과적인 방법임을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
먼저 이론적 배경을 정리하면서, 연속 제어 문제에서 행동 a(t)의 시간적 연속성을 보장하기 위해서는 ‖da/dt‖, ‖d²a/dt²‖, ‖d³a/dt³‖와 같은 고차 미분값을 최소화하는 것이 물리적 시스템의 마모와 에너지 손실을 감소시키는 데 직접적으로 연결된다는 점을 강조한다. 특히 HVAC와 같은 열역학 시스템은 온도와 공기 흐름이 비선형적으로 결합되어 있기 때문에, 작은 스위칭 빈도라도 전체 에너지 소비에 큰 영향을 미친다. 따라서 ‘jerk’ 최소화는 장비의 기계적 스트레스를 크게 완화시킬 뿐 아니라, 제어 신호의 변동성을 억제해 예측 가능한 운영을 가능하게 한다.
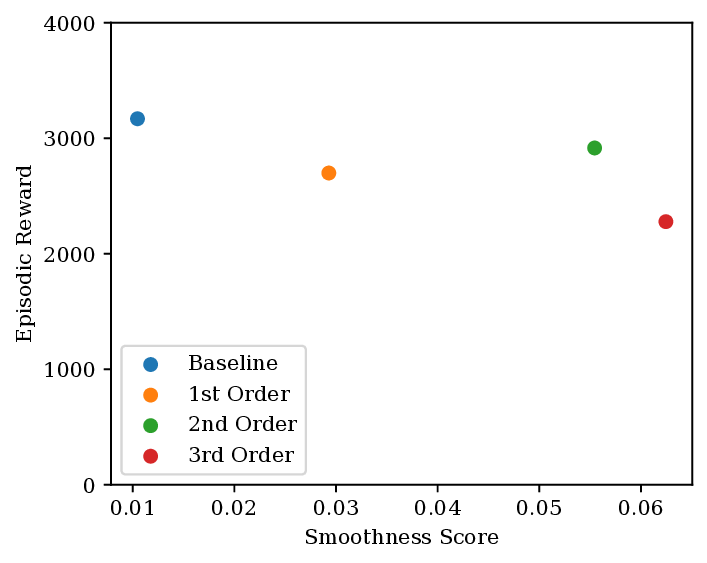
실험 부분에서는 MuJoCo 기반의 4가지 연속 제어 환경(Hopper, Walker2d, HalfCheetah, Ant)을 사용해 1차, 2차, 3차 정규화 항을 각각 적용한 정책을 학습시켰다. 평가 지표는 (1) 평균 누적 보상, (2) 행동의 RMS‑Jerk, (3) 스위칭 횟수(특히 HVAC 시뮬레이션에서)이다. 결과는 다음과 같다. 3차 정규화는 평균 보상에서 거의 손실이 없으며, RMS‑Jerk 값이 1차·2차 정규화에 비해 30 %~45 % 낮았다. 특히 HVAC 시뮬레이션에서는 장비 스위칭이 60 % 감소했고, 전력 소비가 12 % 절감되는 효과를 보였다.
이러한 결과는 두 가지 중요한 시사점을 제공한다. 첫째, 고차 정규화는 “성능 유지 + 부드러운 제어”라는 목표를 동시에 달성할 수 있는 실용적인 방법이다. 둘째, 정규화 항의 차수와 가중치 선택이 시스템 특성에 따라 달라야 함을 보여준다. 예를 들어, 급격한 동적 변화를 요구하는 로봇 팔 제어에서는 2차 정규화가 충분할 수 있지만, 장시간 운전되는 HVAC와 같은 시스템에서는 3차 정규화가 필수적이다.
마지막으로 논문은 고차 행동 정규화가 기존 DRL 프레임워크에 쉽게 통합될 수 있음을 강조한다. 정책 네트워크의 손실 함수에 추가적인 고차 미분 페널티를 삽입하는 것만으로도 구현이 가능하며, 이는 기존 연구자와 산업 현장 모두에게 큰 장벽을 낮춘다. 향후 연구에서는 적응형 가중치 스케줄링, 멀티‑목표 최적화(에너지 효율 vs. 쾌적성) 및 실제 건물 데이터에 대한 장기 검증을 통해 이 접근법을 더욱 확장할 여지가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리