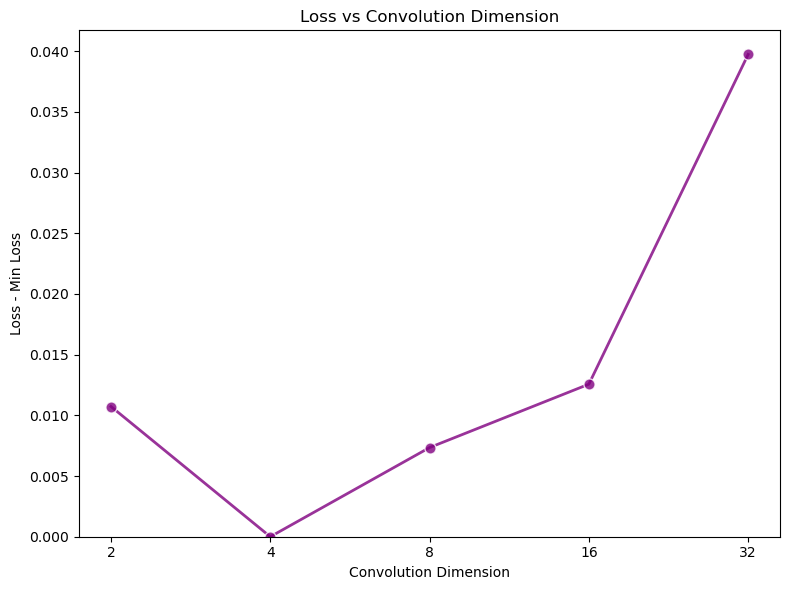
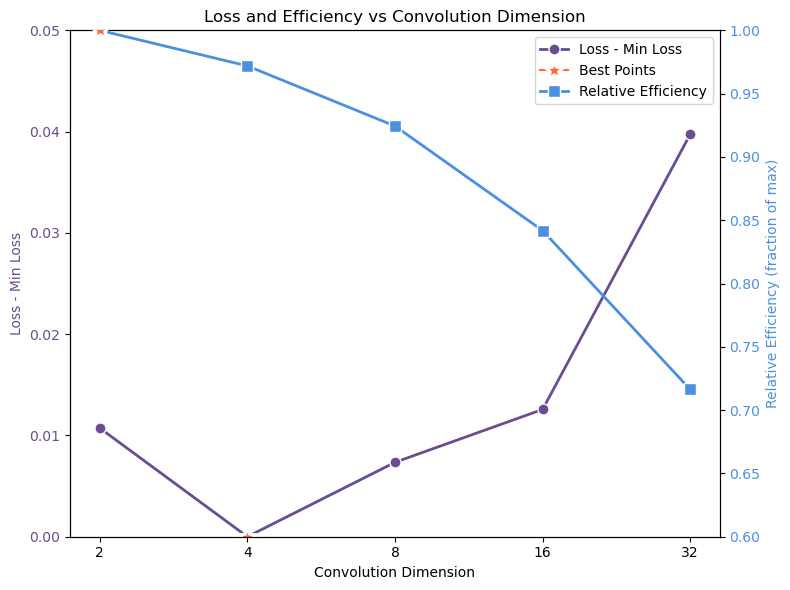
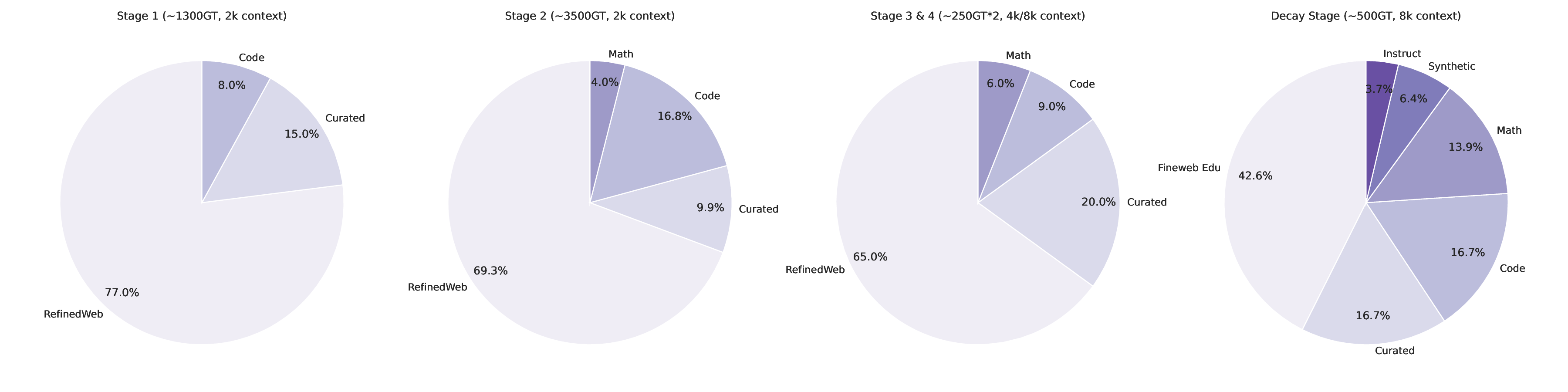
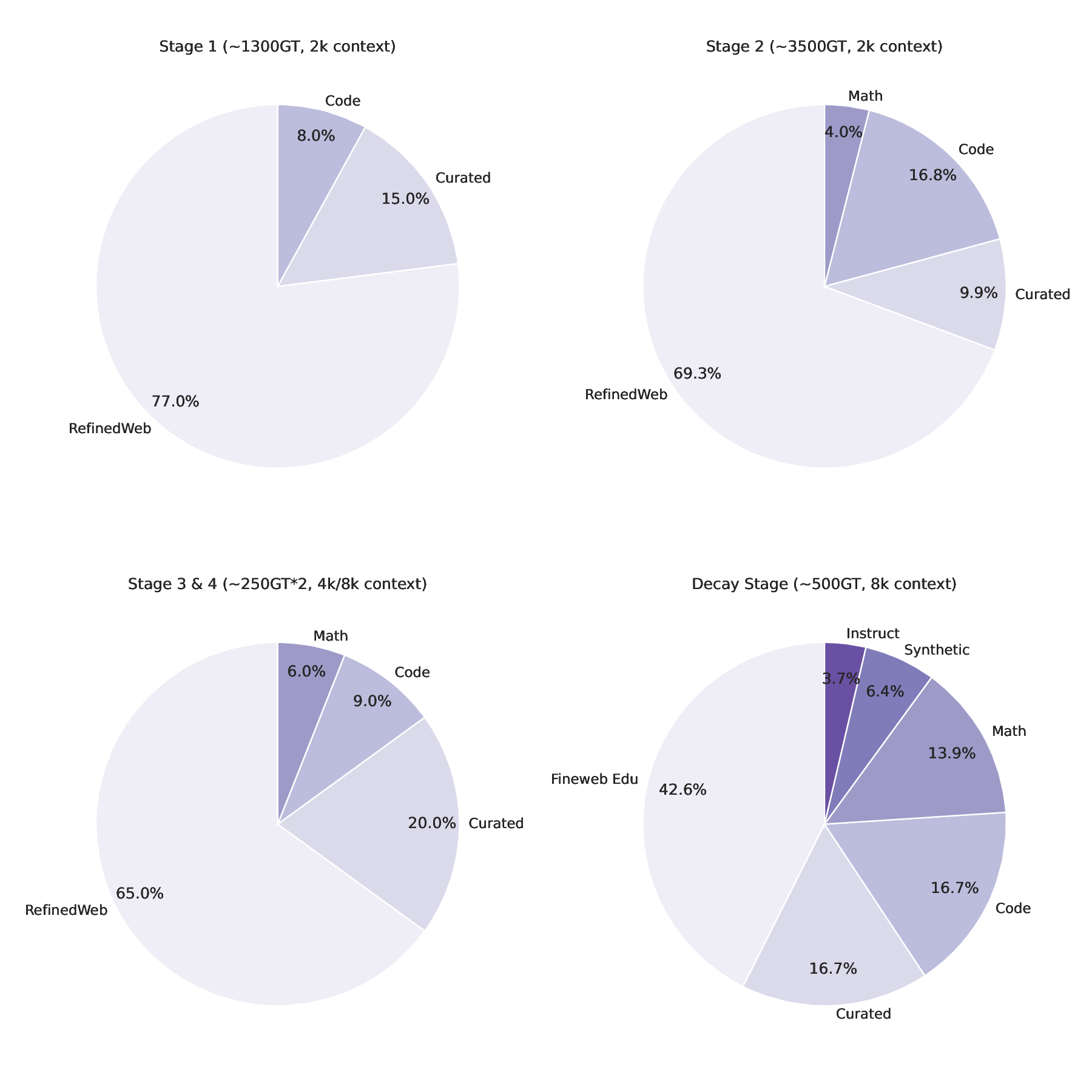
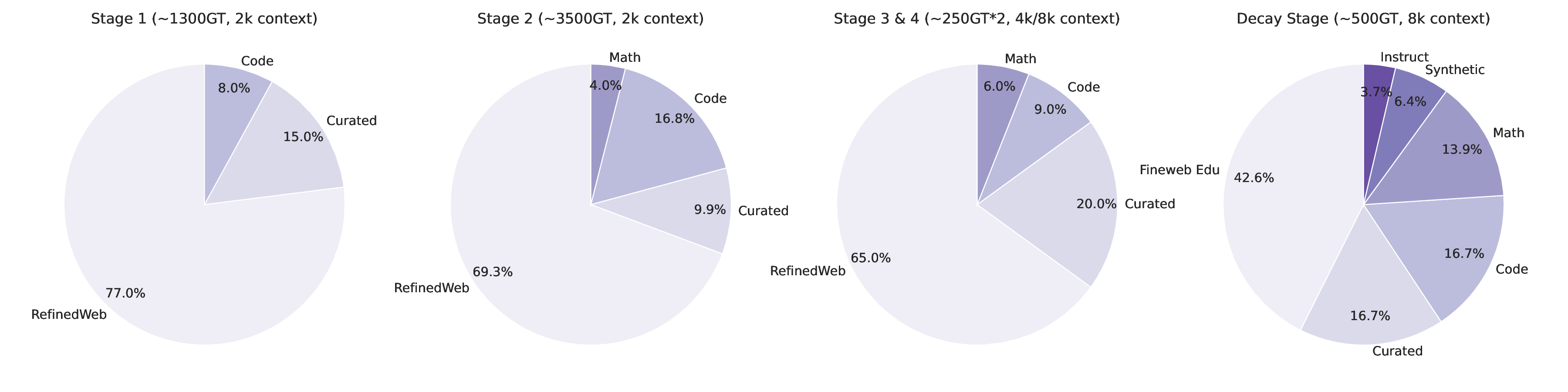
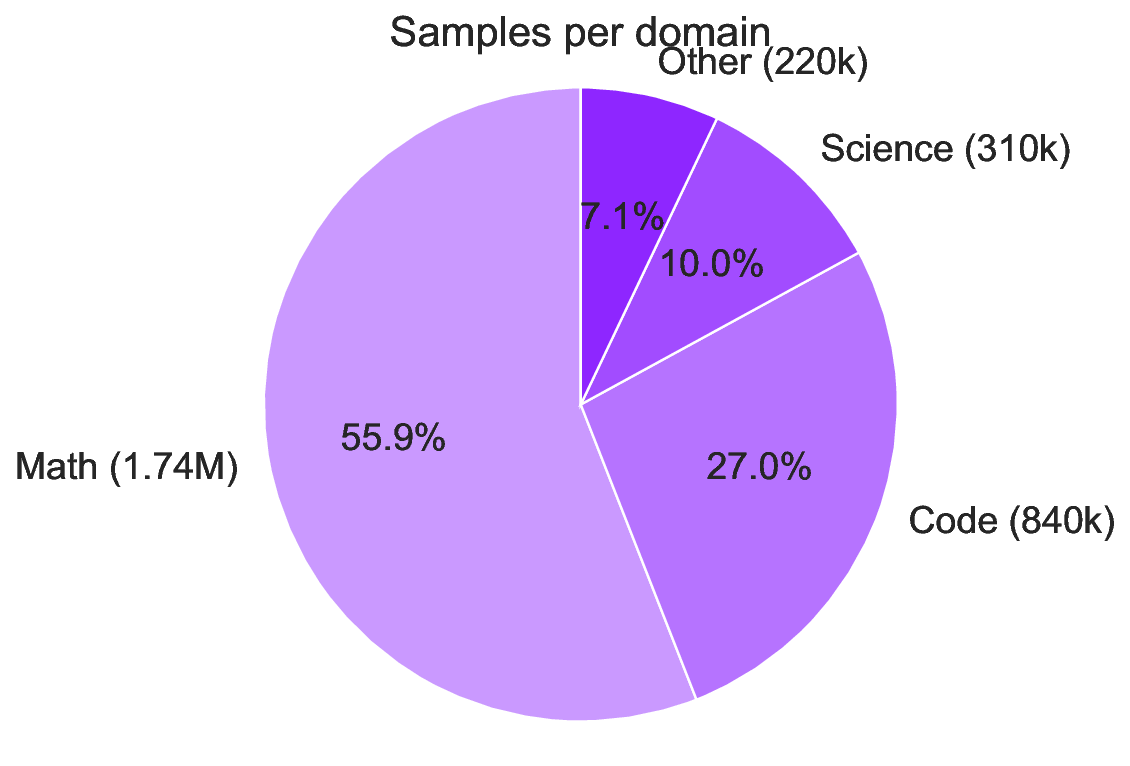
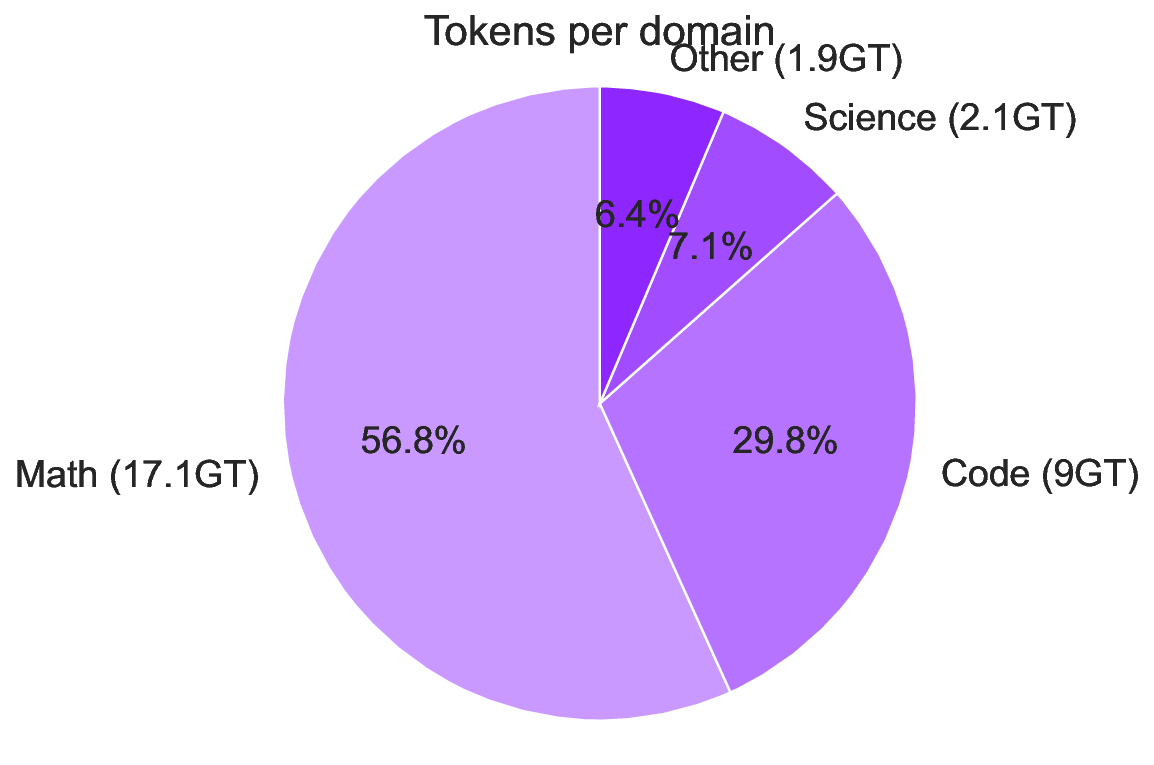
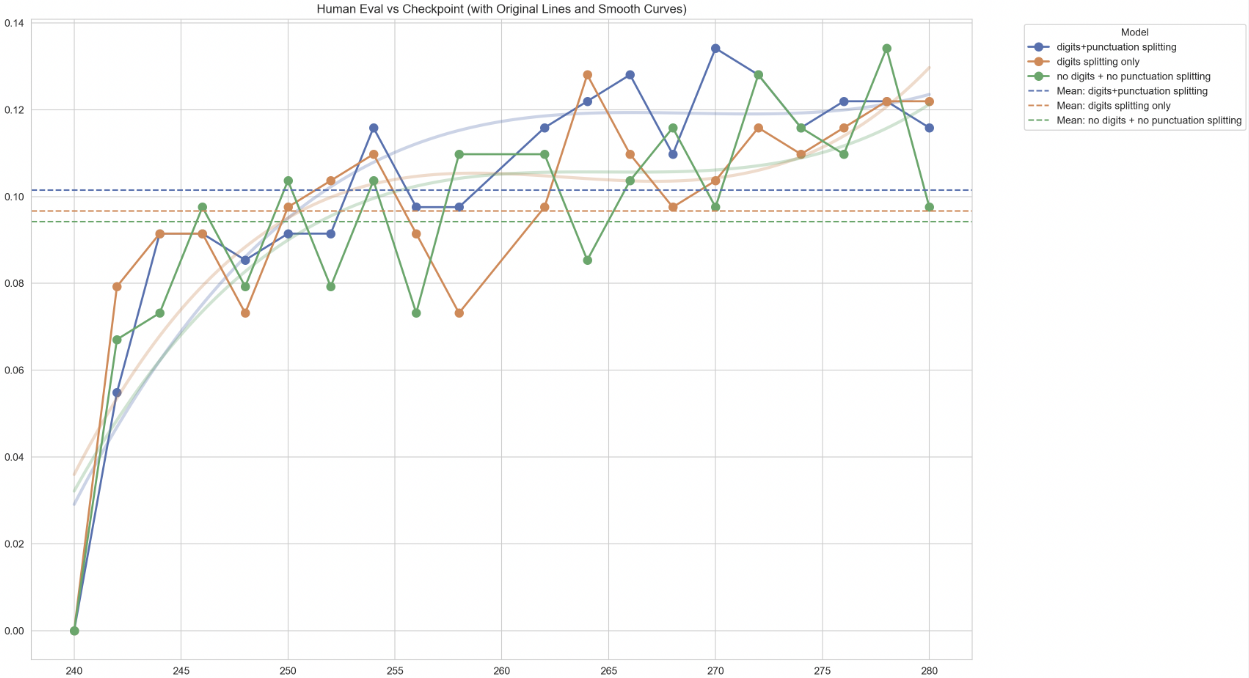
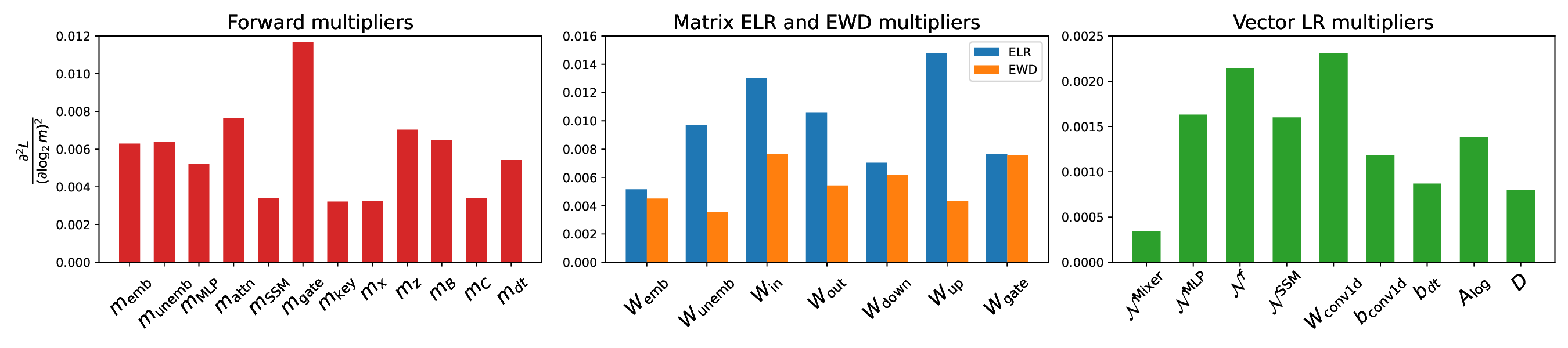
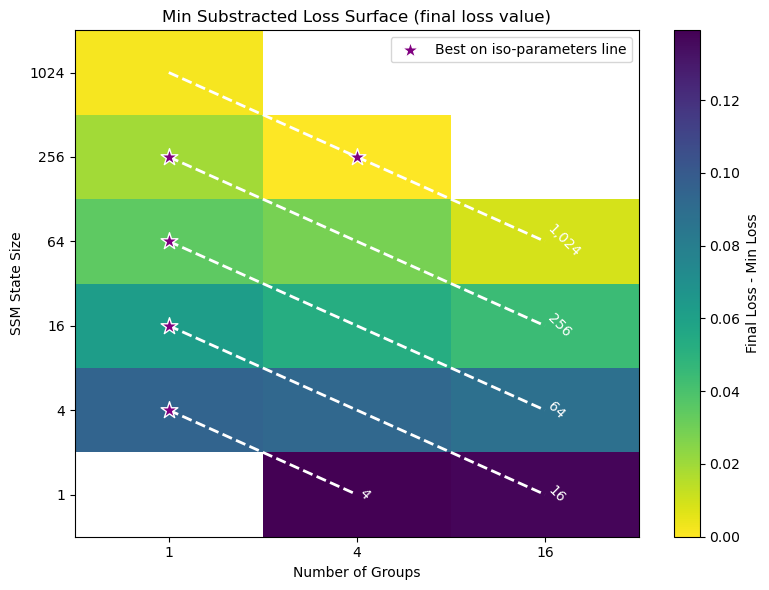
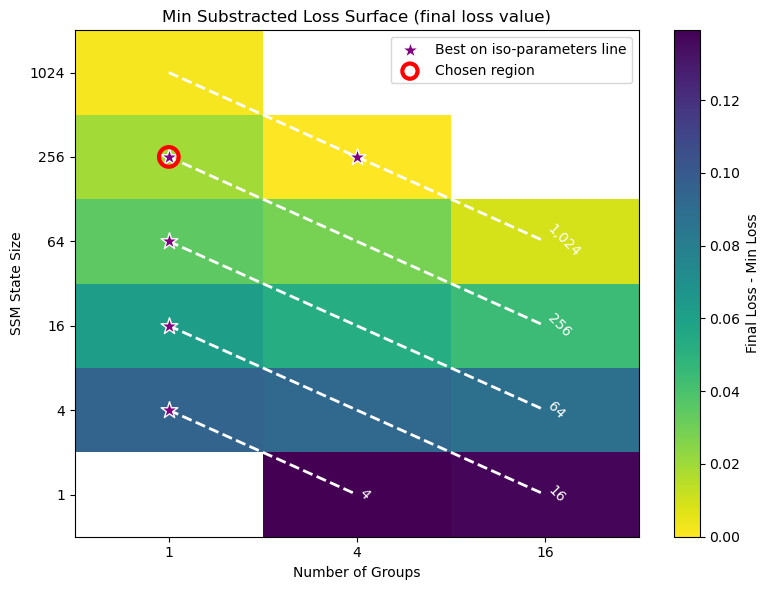
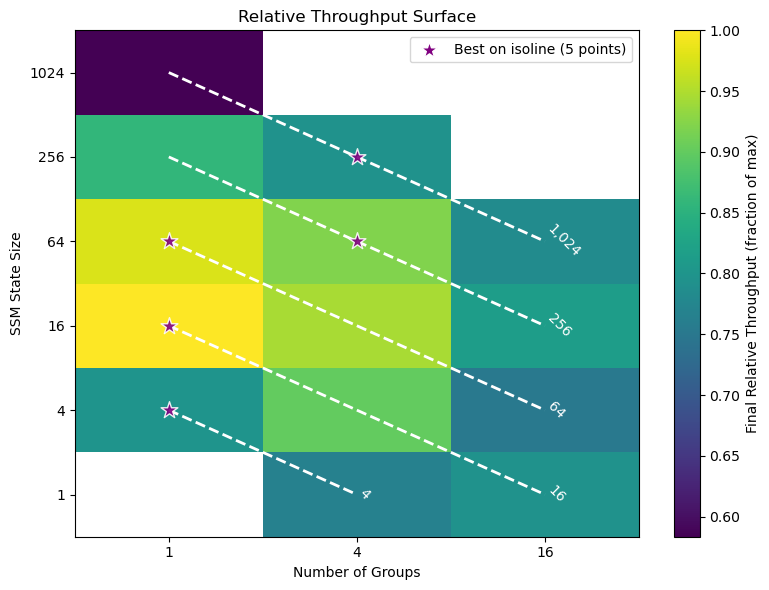
Falcon H1R 추론 효율성을 극대화한 하이브리드 모델
📝 원문 정보
- Title: Falcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling
- ArXiv ID: 2601.02346
- 발행일: 2026-01-05
- 저자: Falcon LLM Team, Iheb Chaabane, Puneesh Khanna, Suhail Mohmad, Slim Frikha, Shi Hu, Abdalgader Abubaker, Reda Alami, Mikhail Lubinets, Mohamed El Amine Seddik, Hakim Hacid
📝 초록 (Abstract)
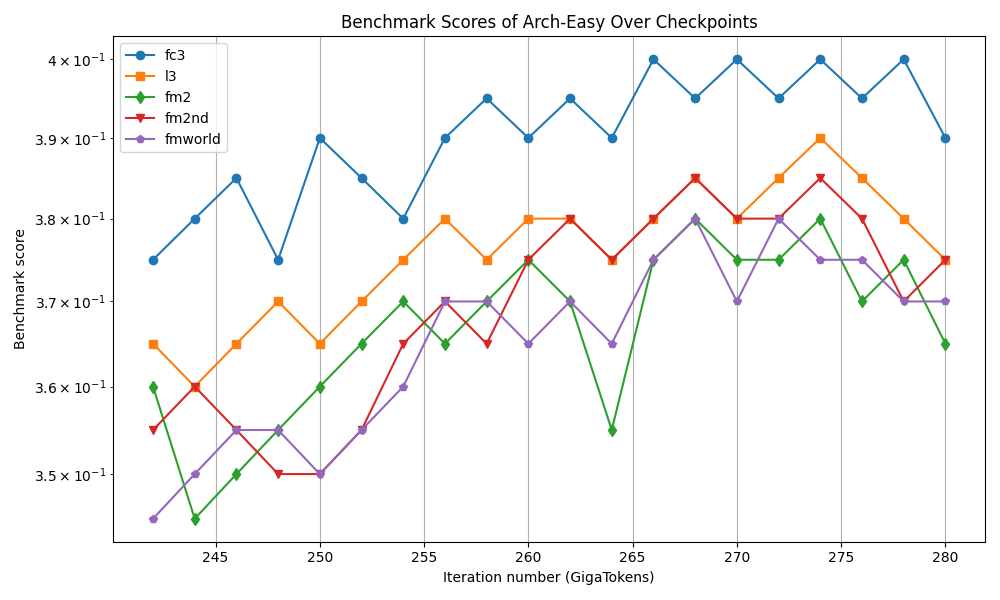
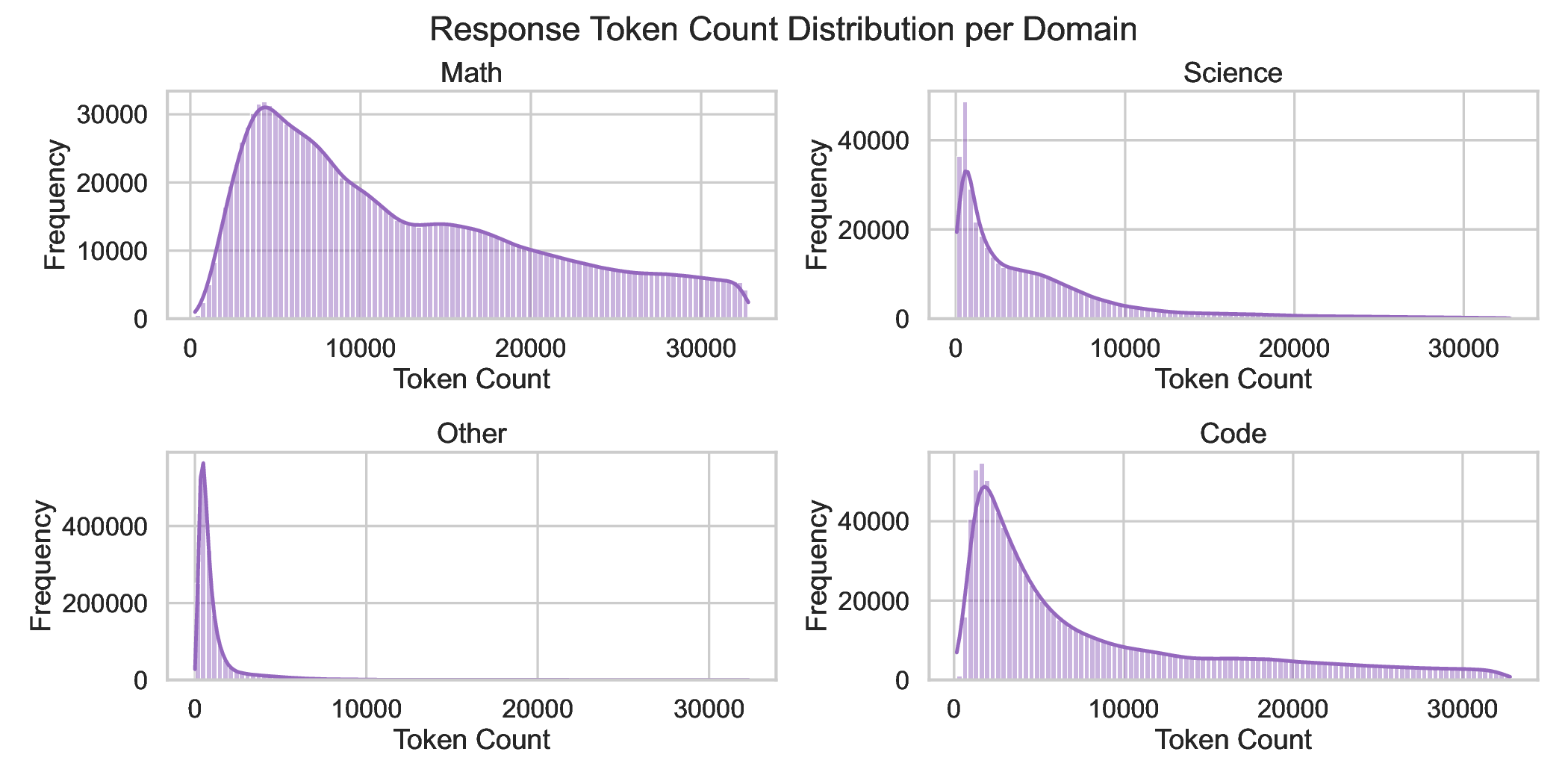
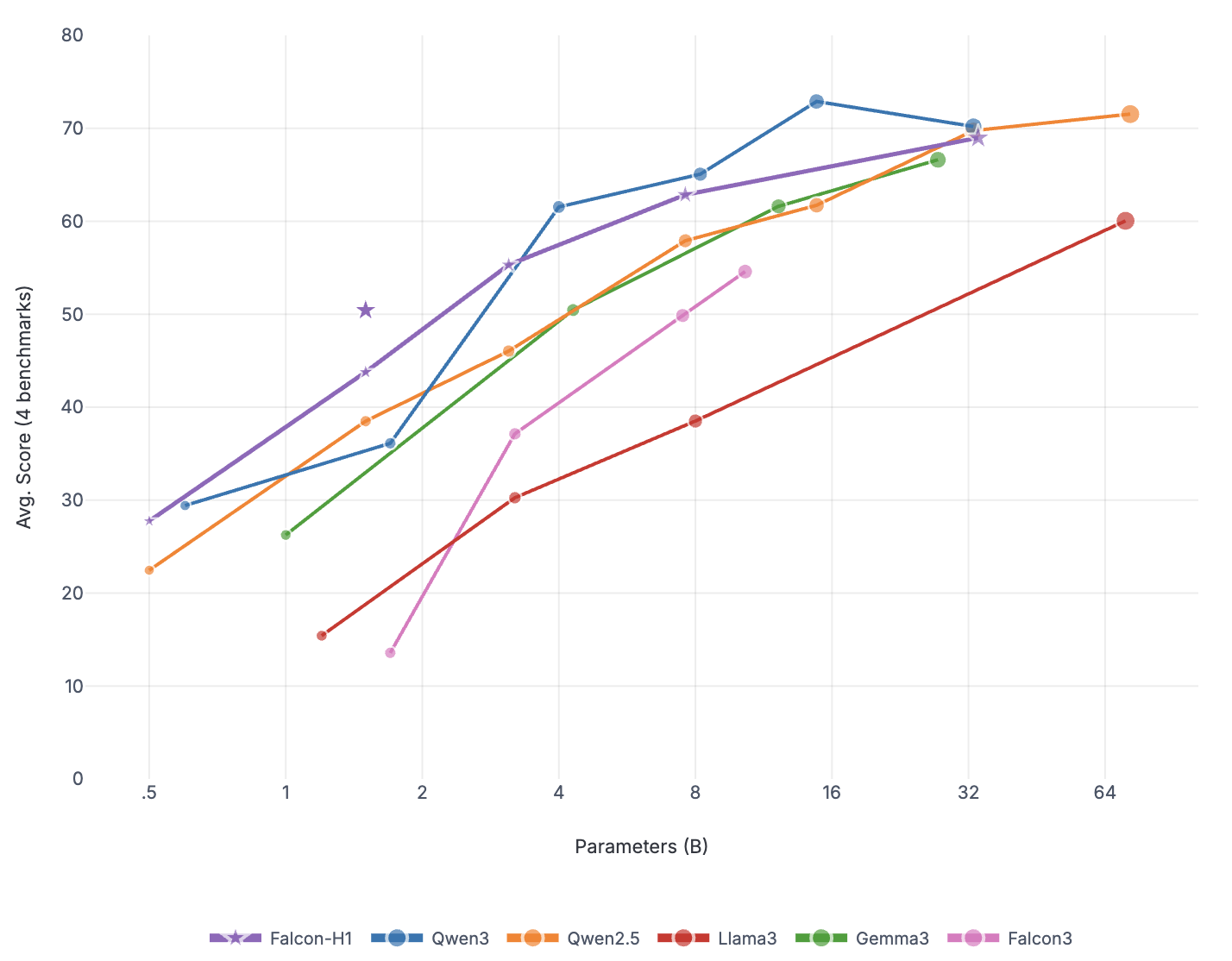
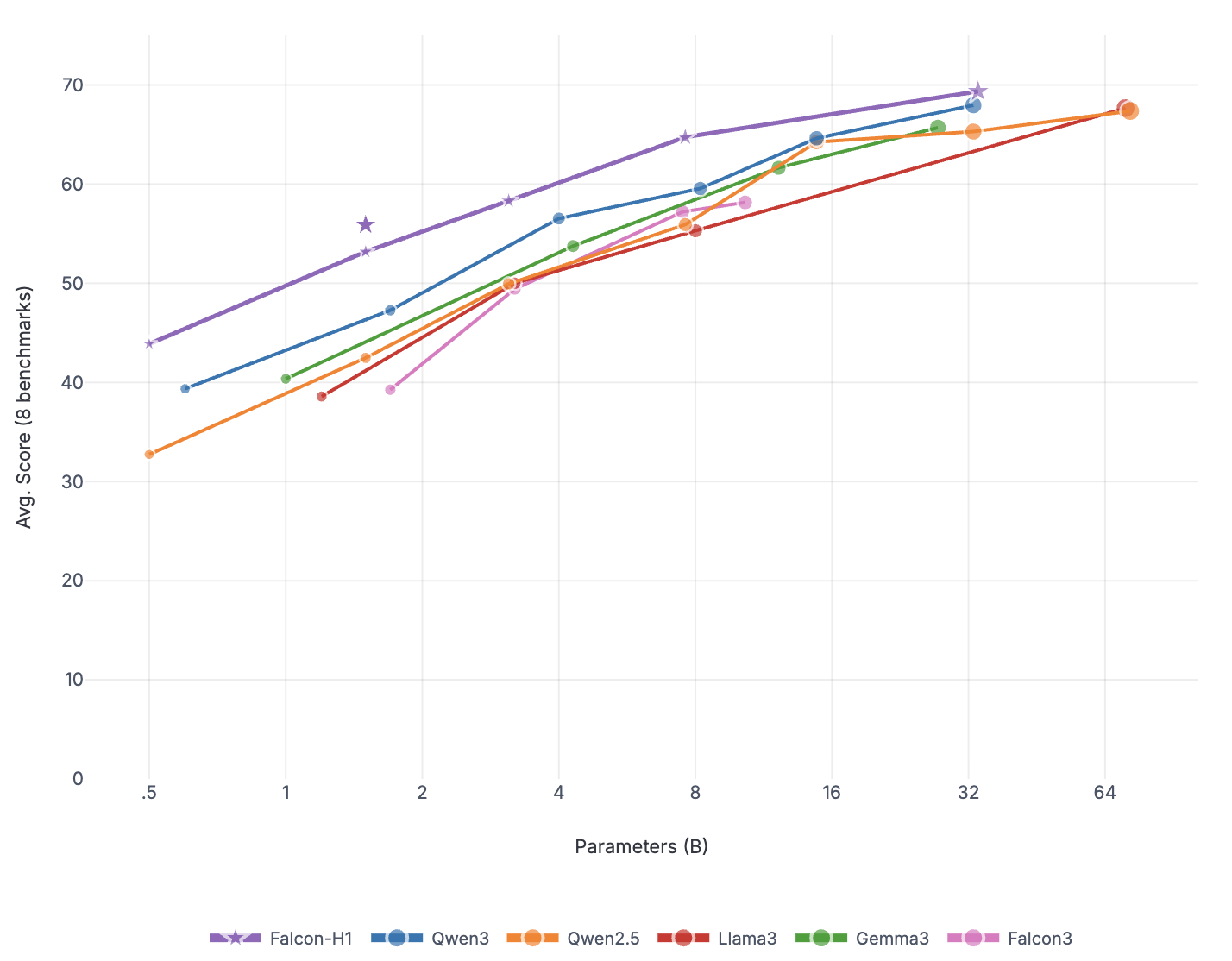
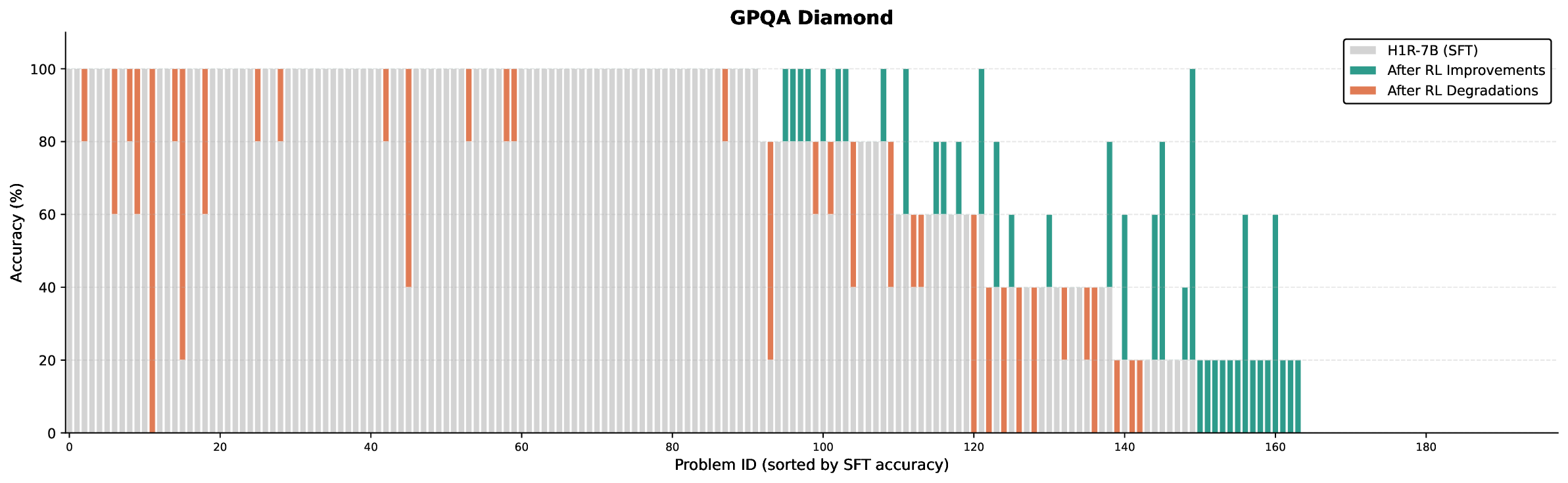
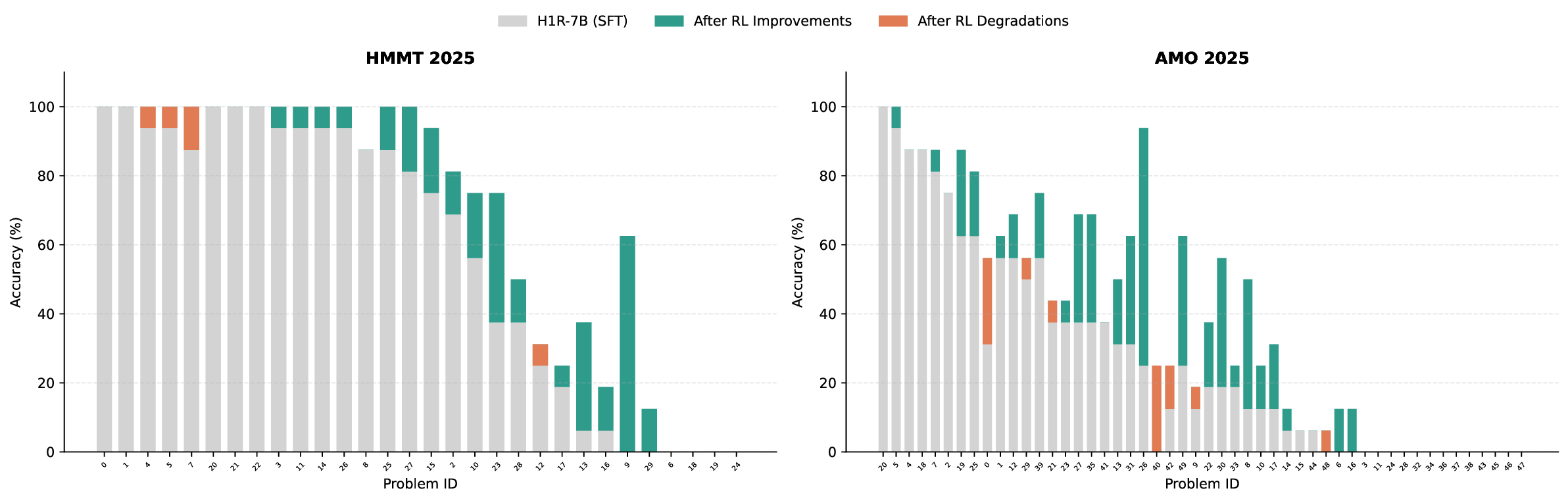
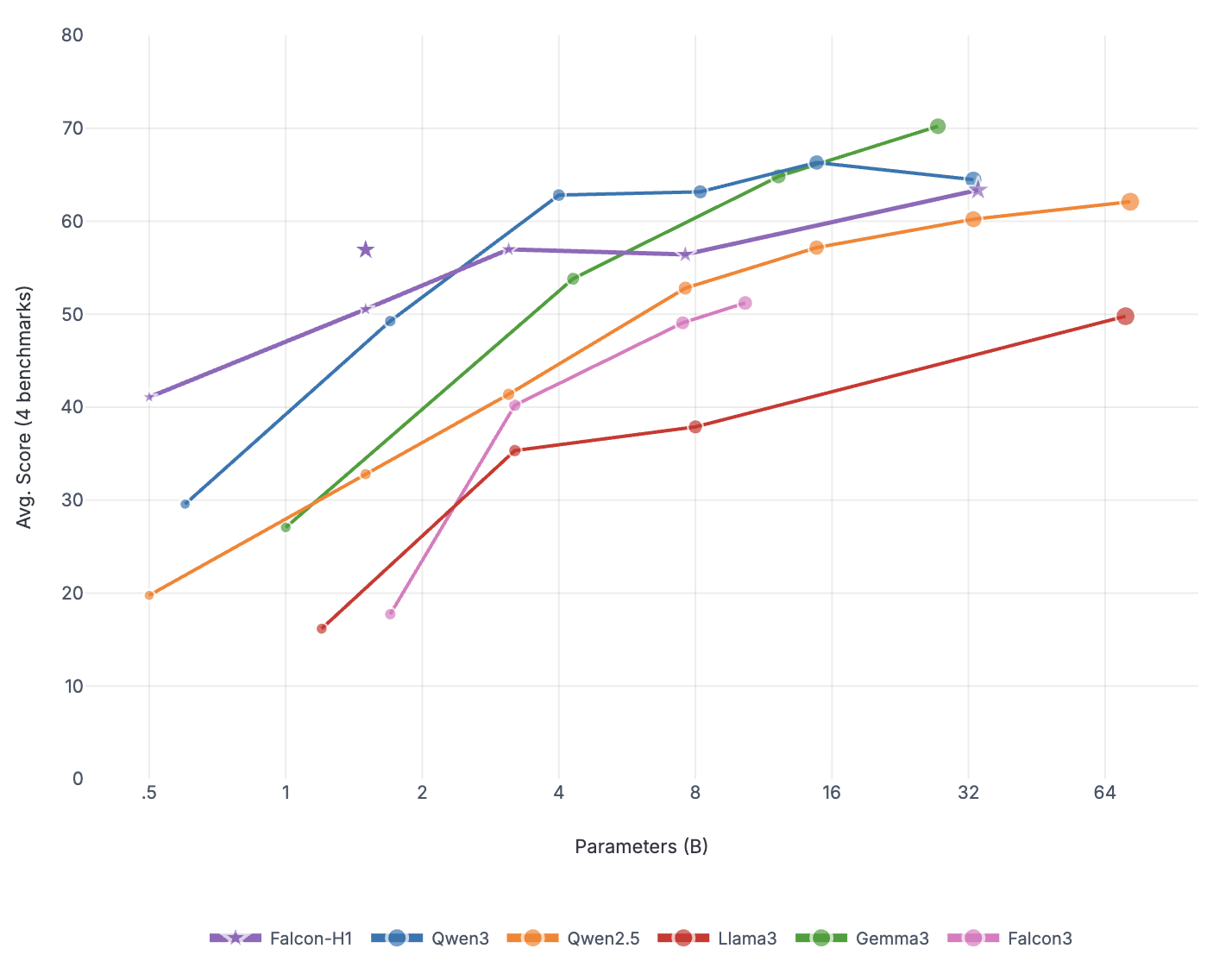
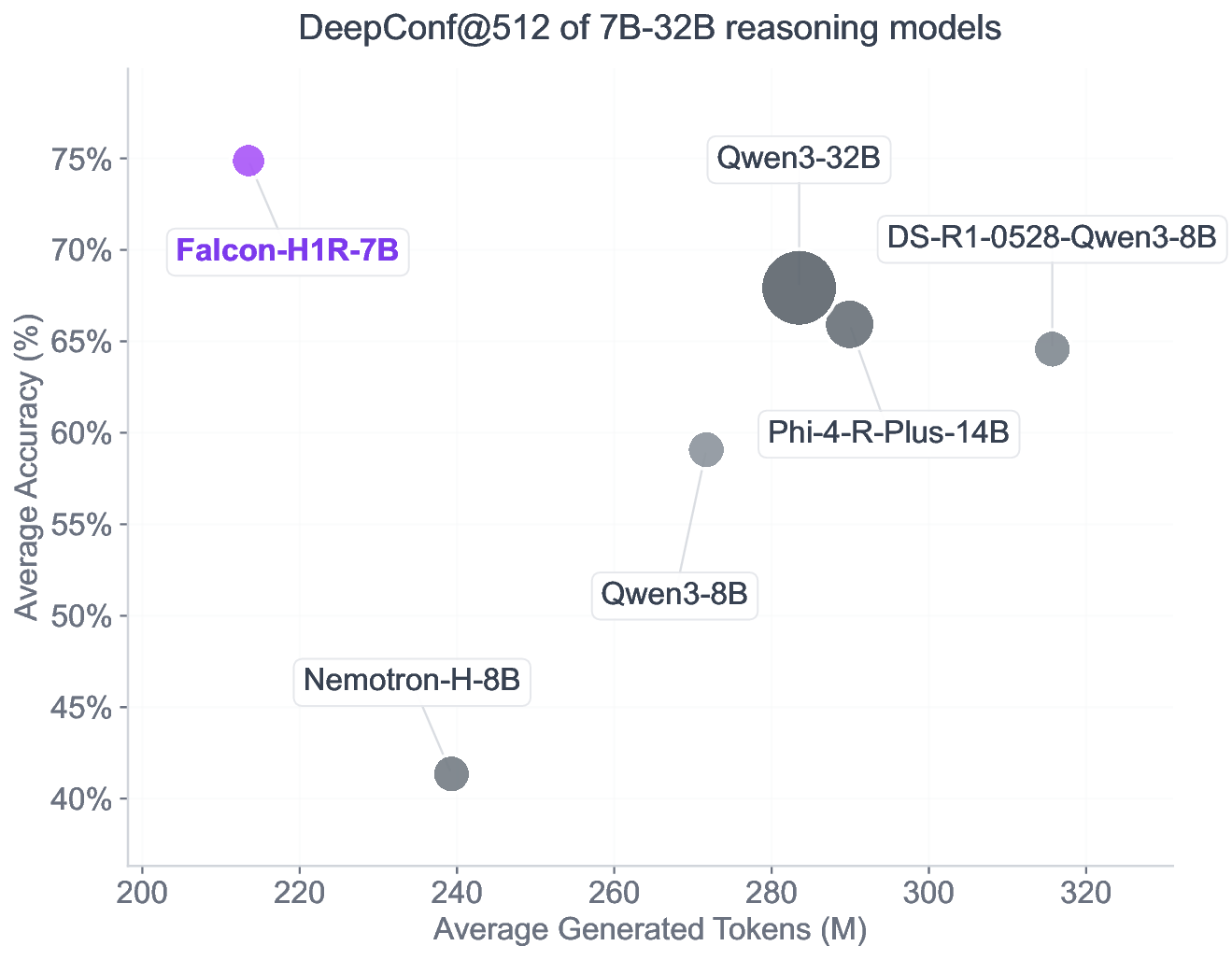
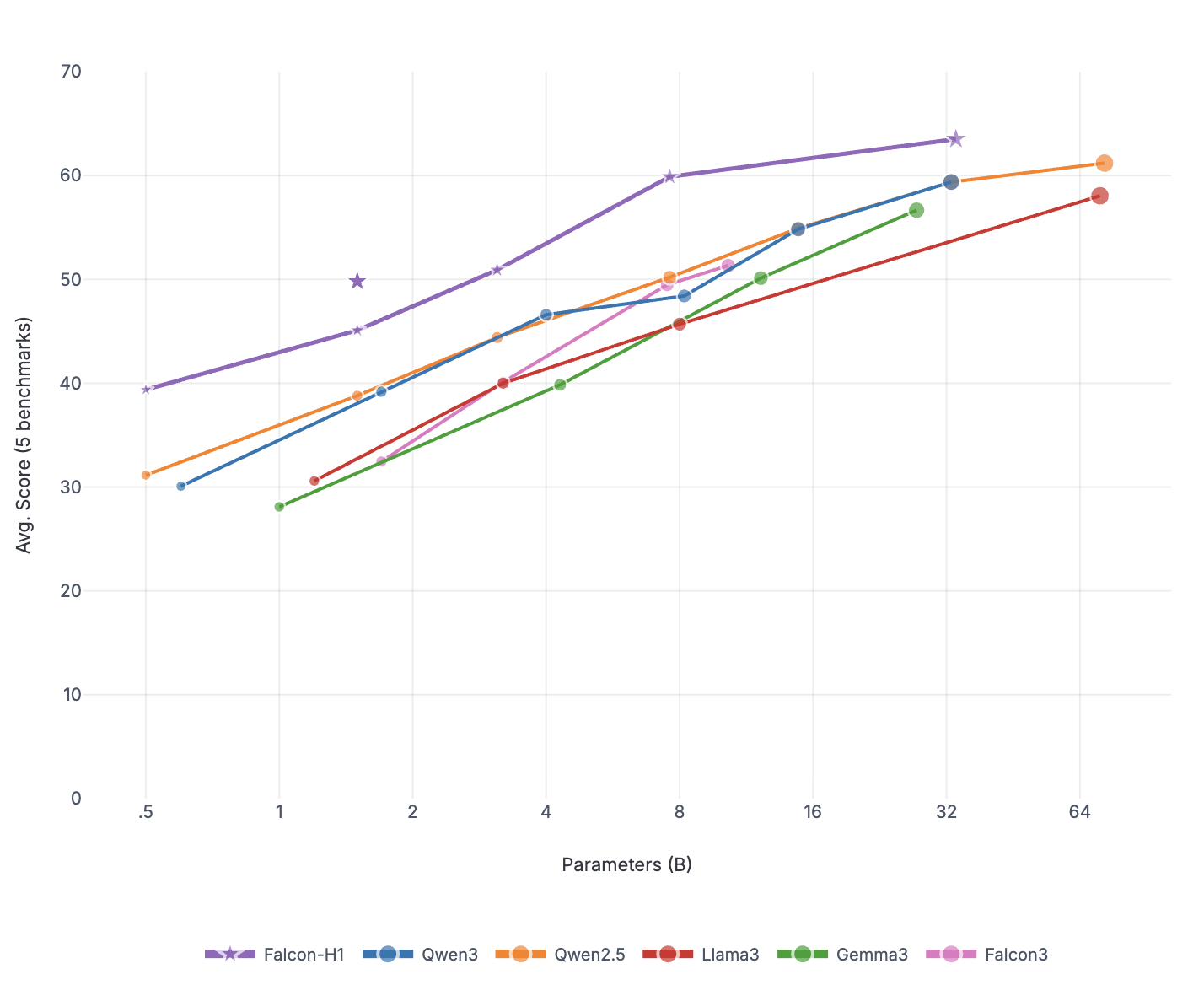
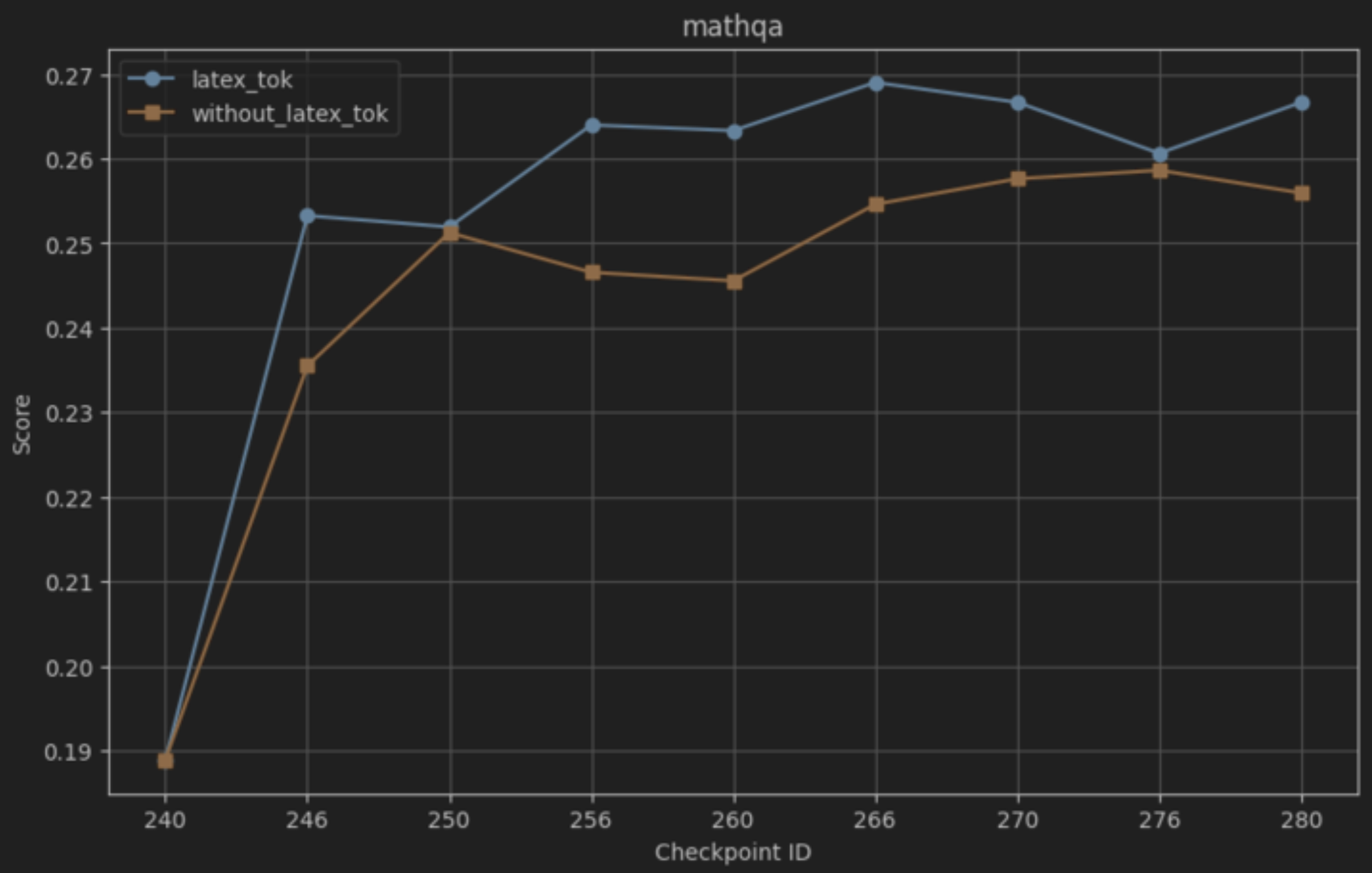
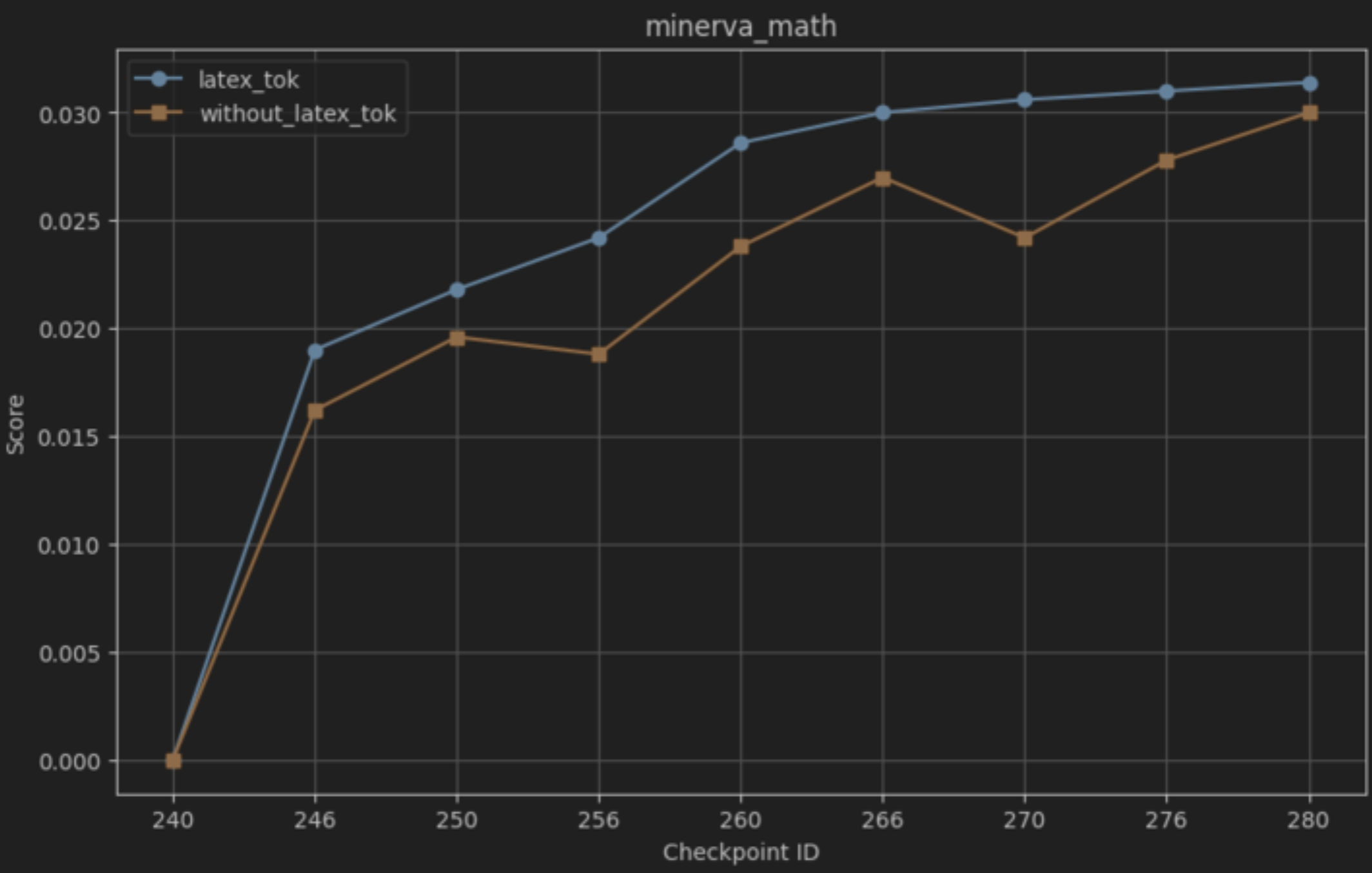
본 연구는 7 억 파라미터 규모의 추론 최적화 모델인 Falcon H1R을 소개한다. Falcon H1R은 소형 언어 모델(SLM)에서도 경쟁력 있는 추론 성능을 달성할 수 있음을 입증한다. 다양한 추론 중심 벤치마크에서 2배에서 7배 규모가 큰 최신 모델들을 일관되게 맞추거나 능가함으로써 파라미터 효율성을 강조한다. 이는 데이터 선별과 효율적인 SFT·RL 스케일링을 결합한 맞춤형 학습 전략이 모델 크기 증대 없이도 큰 성능 향상을 가능하게 함을 보여준다. 또한 Falcon H1R은 하이브리드 병렬 아키텍처와 토큰 효율성을 통해 추론 속도를 높이고 정확도를 동시에 향상시켜 테스트‑타임 스케일링 효율성을 극대화한다. DeepConf 방식을 적용해 정확도와 계산 비용 모두에서 최첨단 수준의 테스트‑타임 스케일링 효율을 달성했으며, 이는 대규모 체인‑오브‑생각 생성 및 병렬 추론이 요구되는 실용 시스템에 적합한 백본이 된다.💡 논문 핵심 해설 (Deep Analysis)
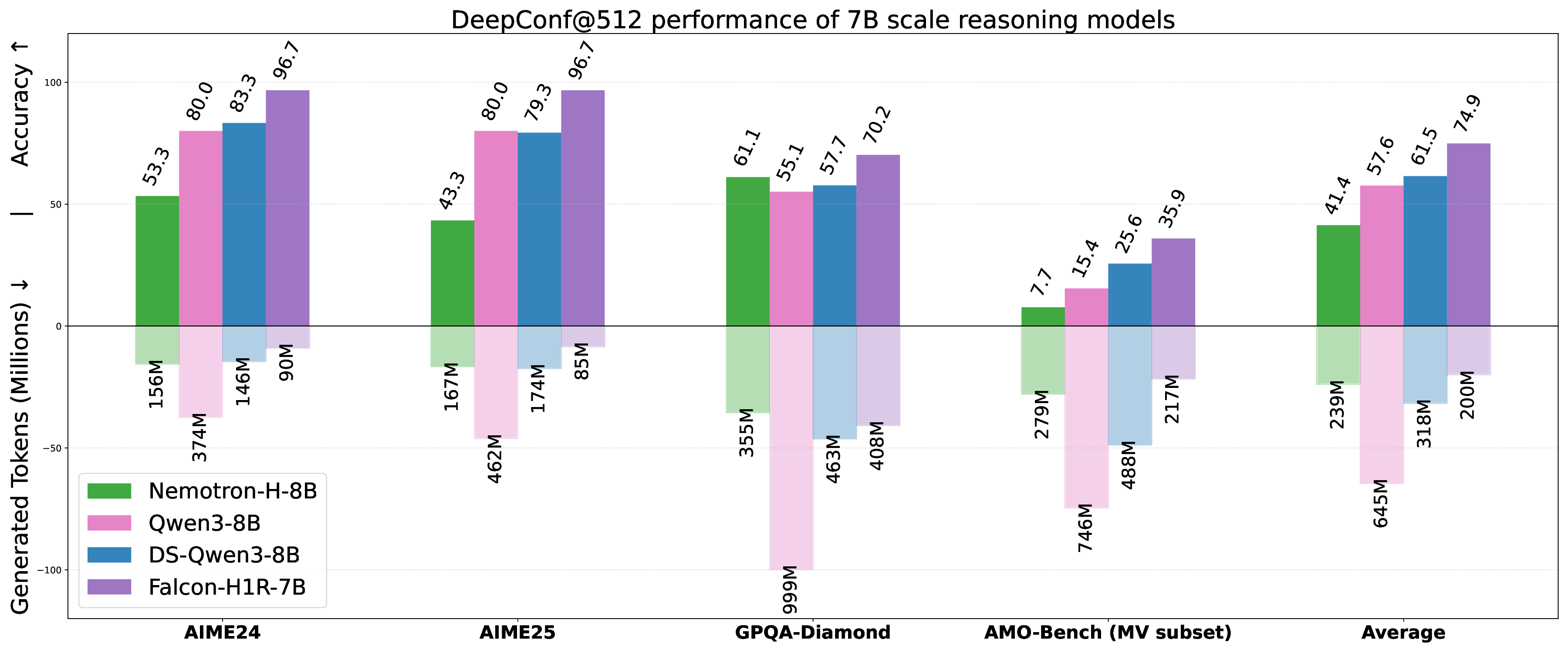
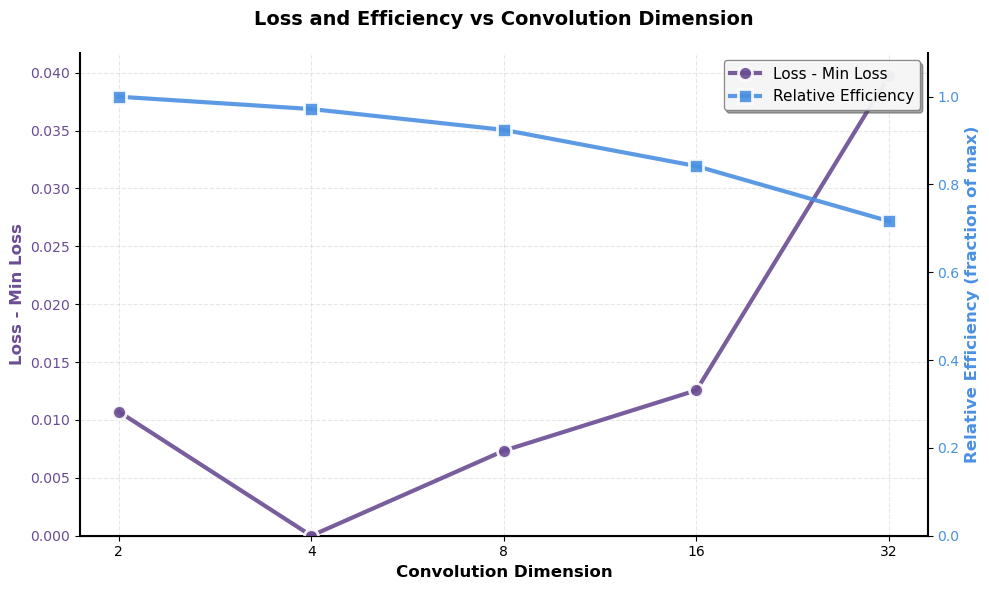
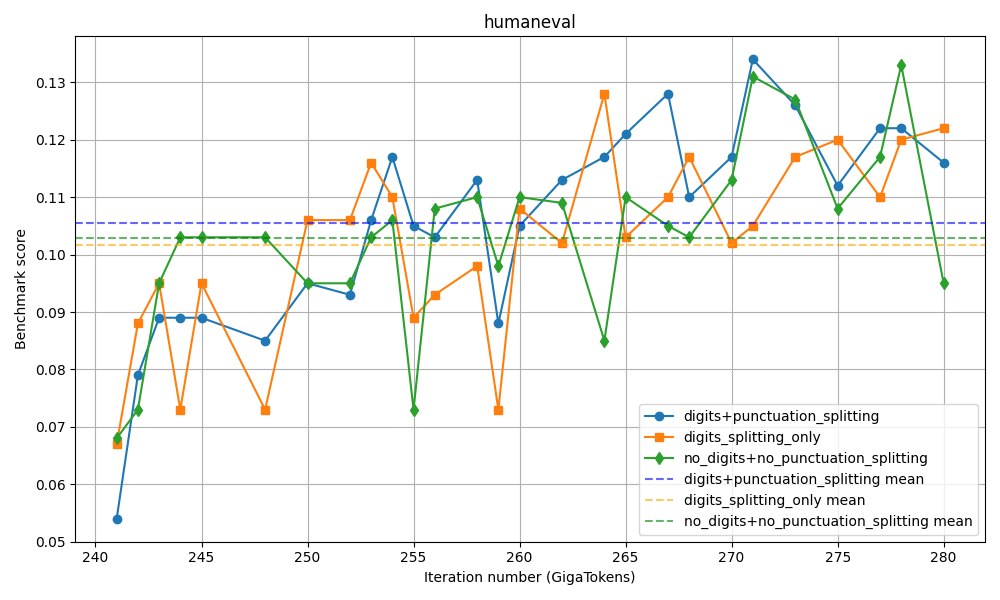
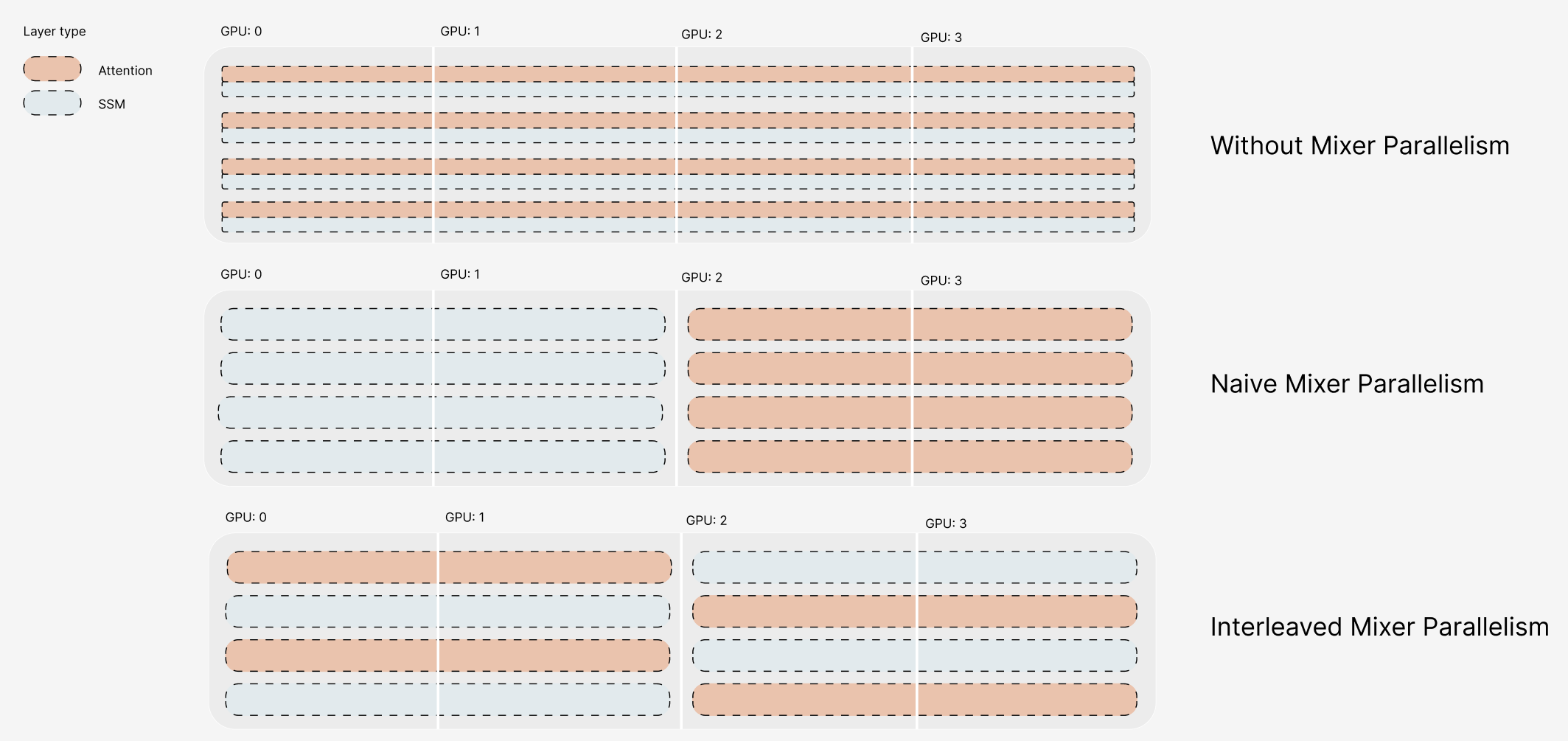
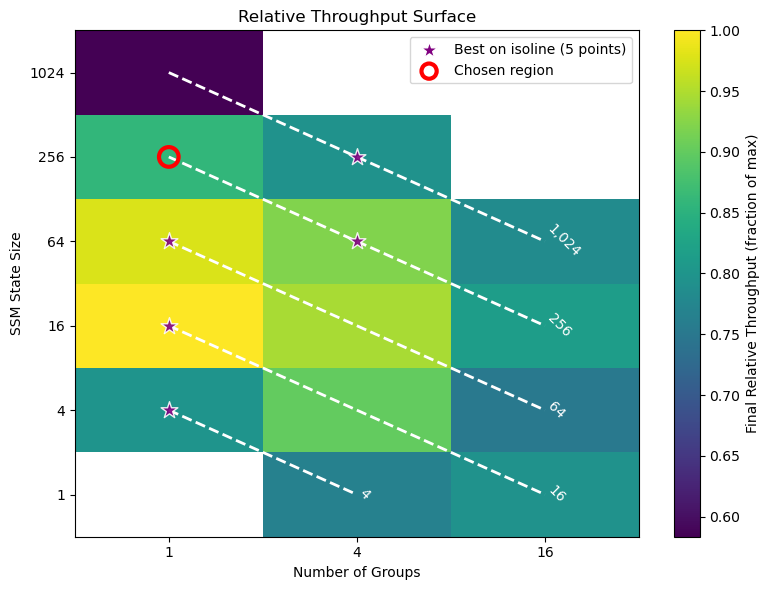
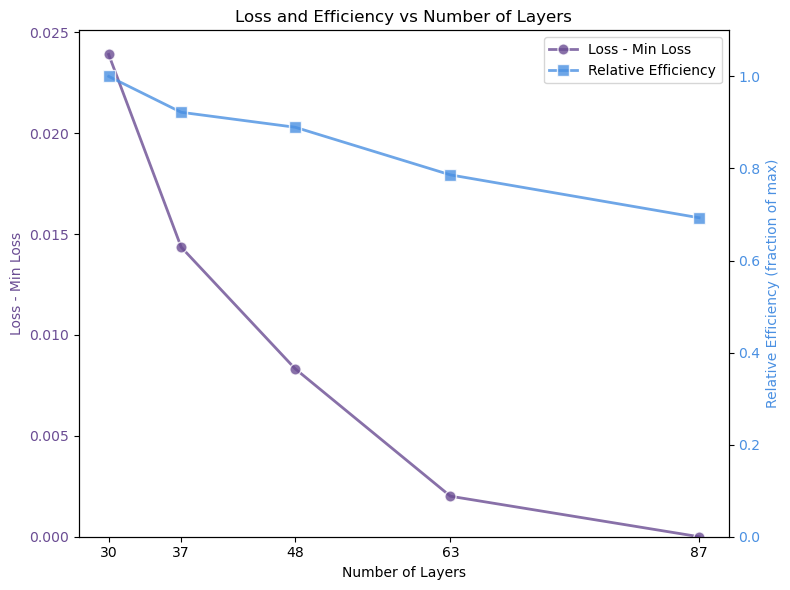
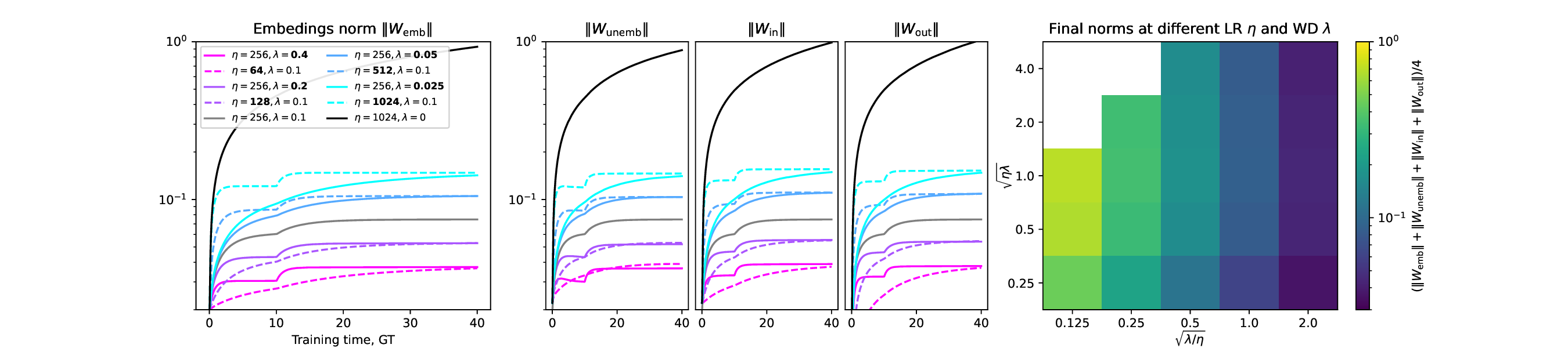
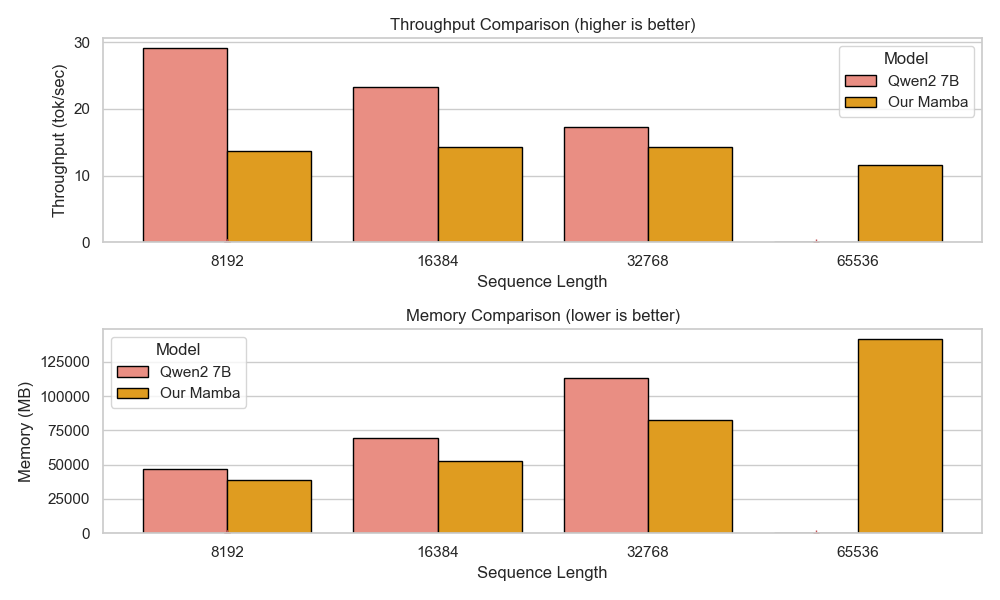
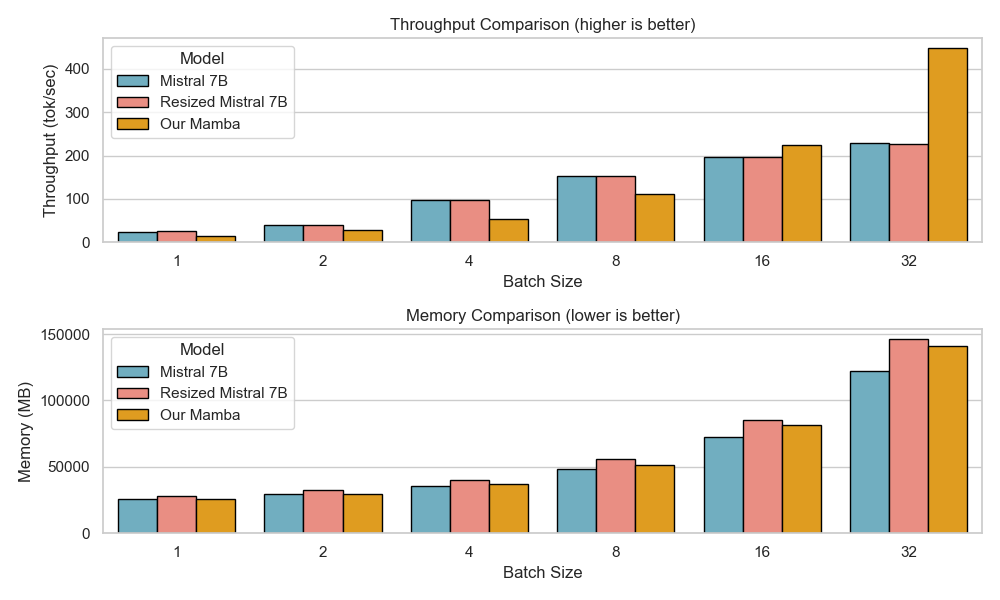
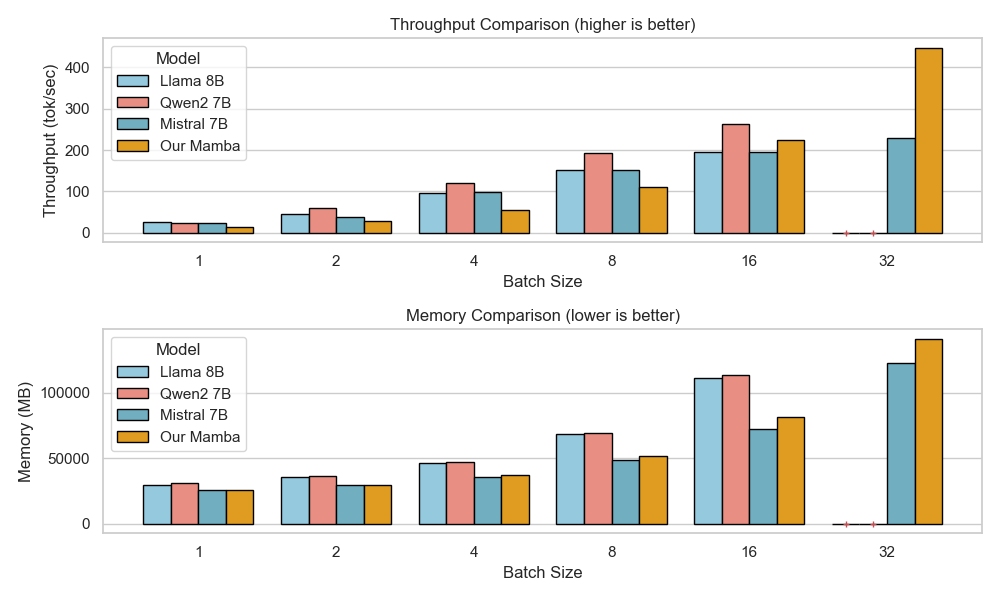
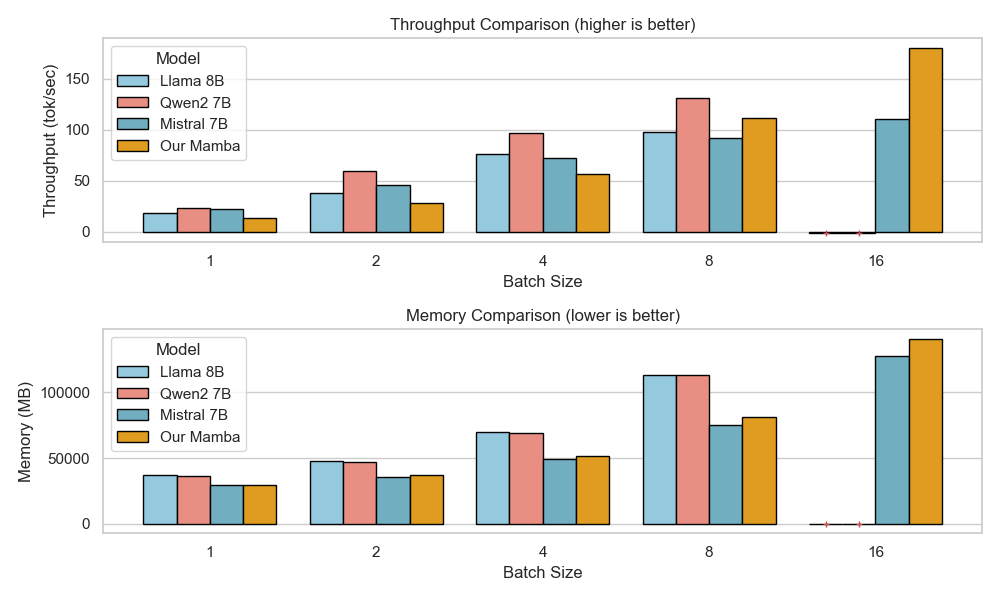
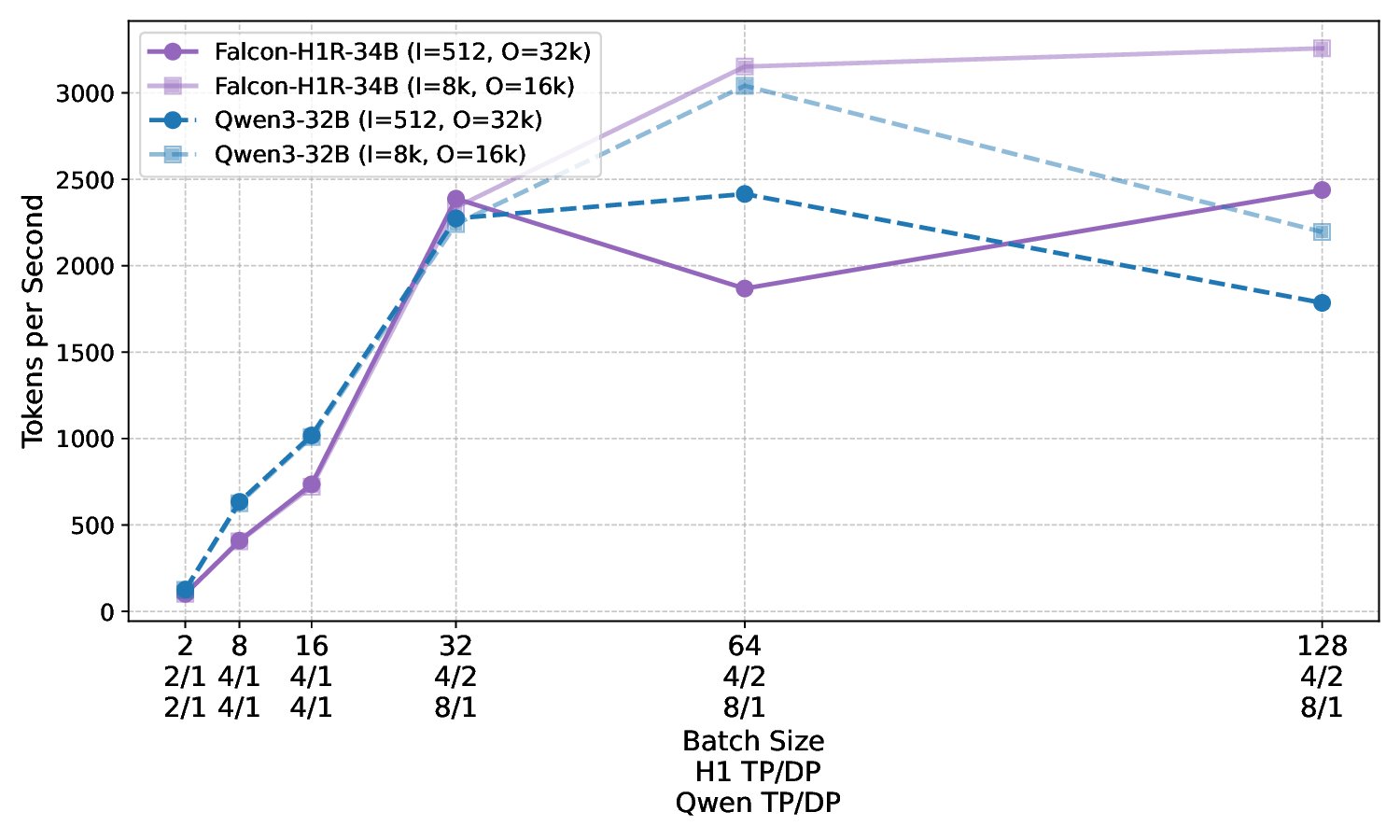
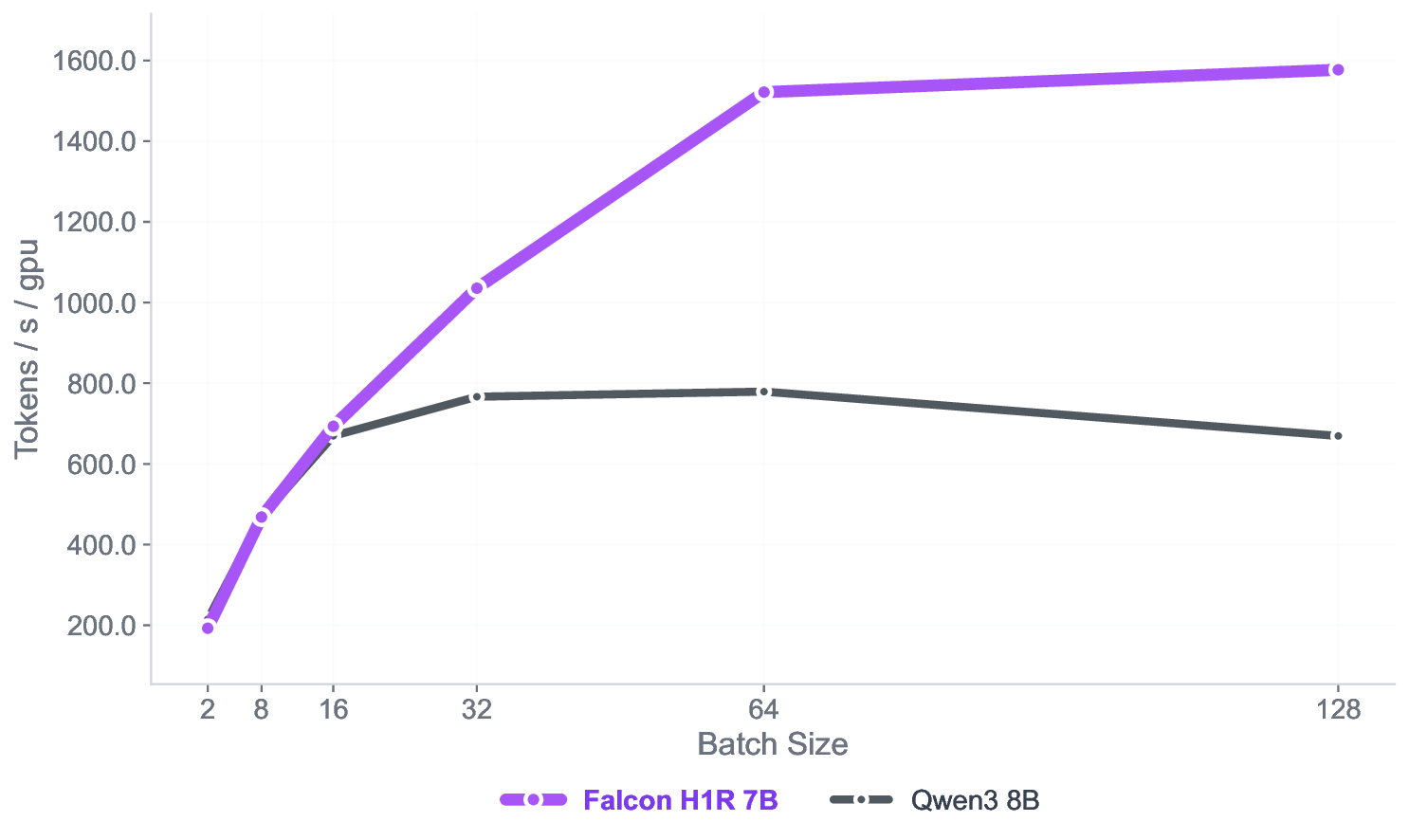
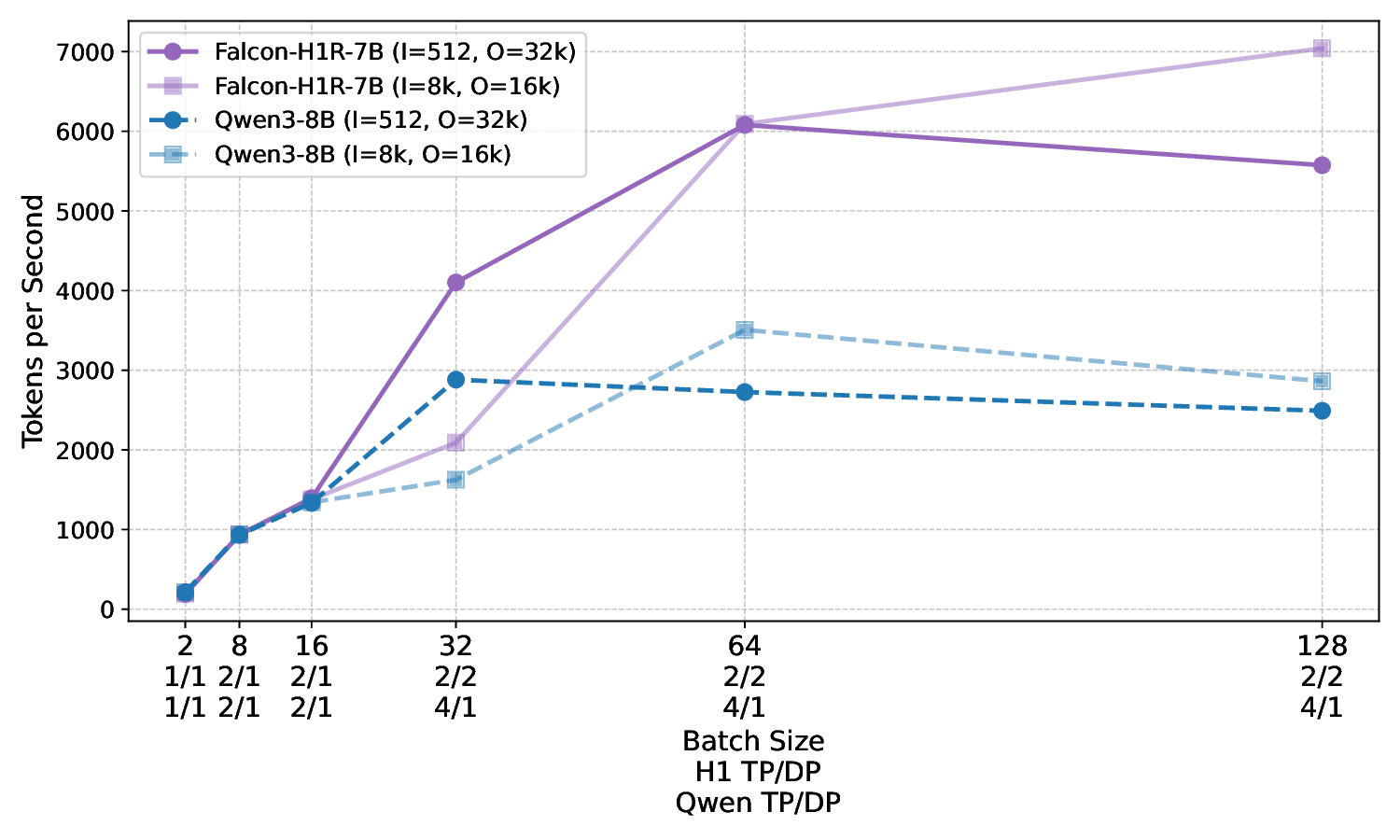
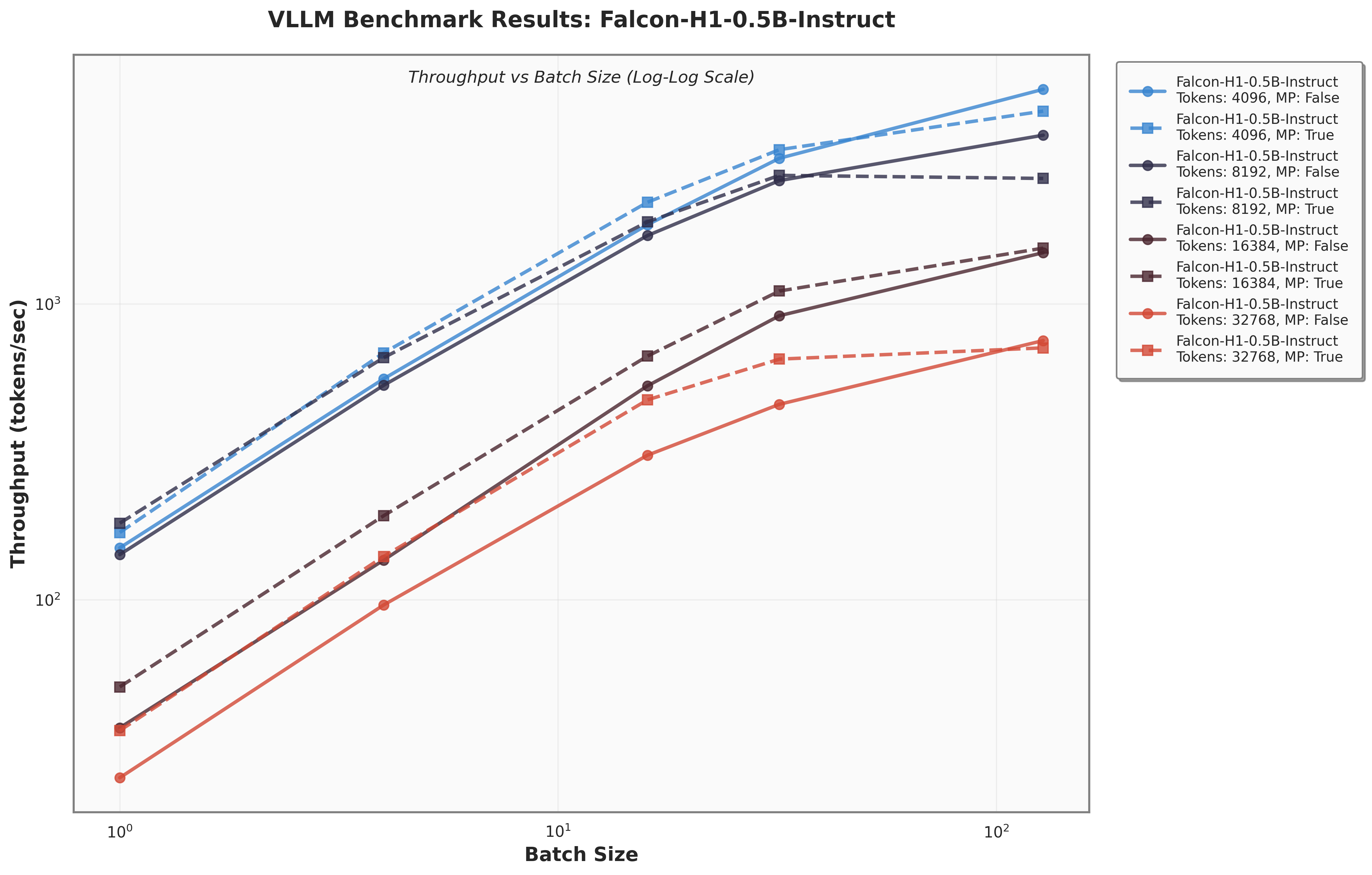
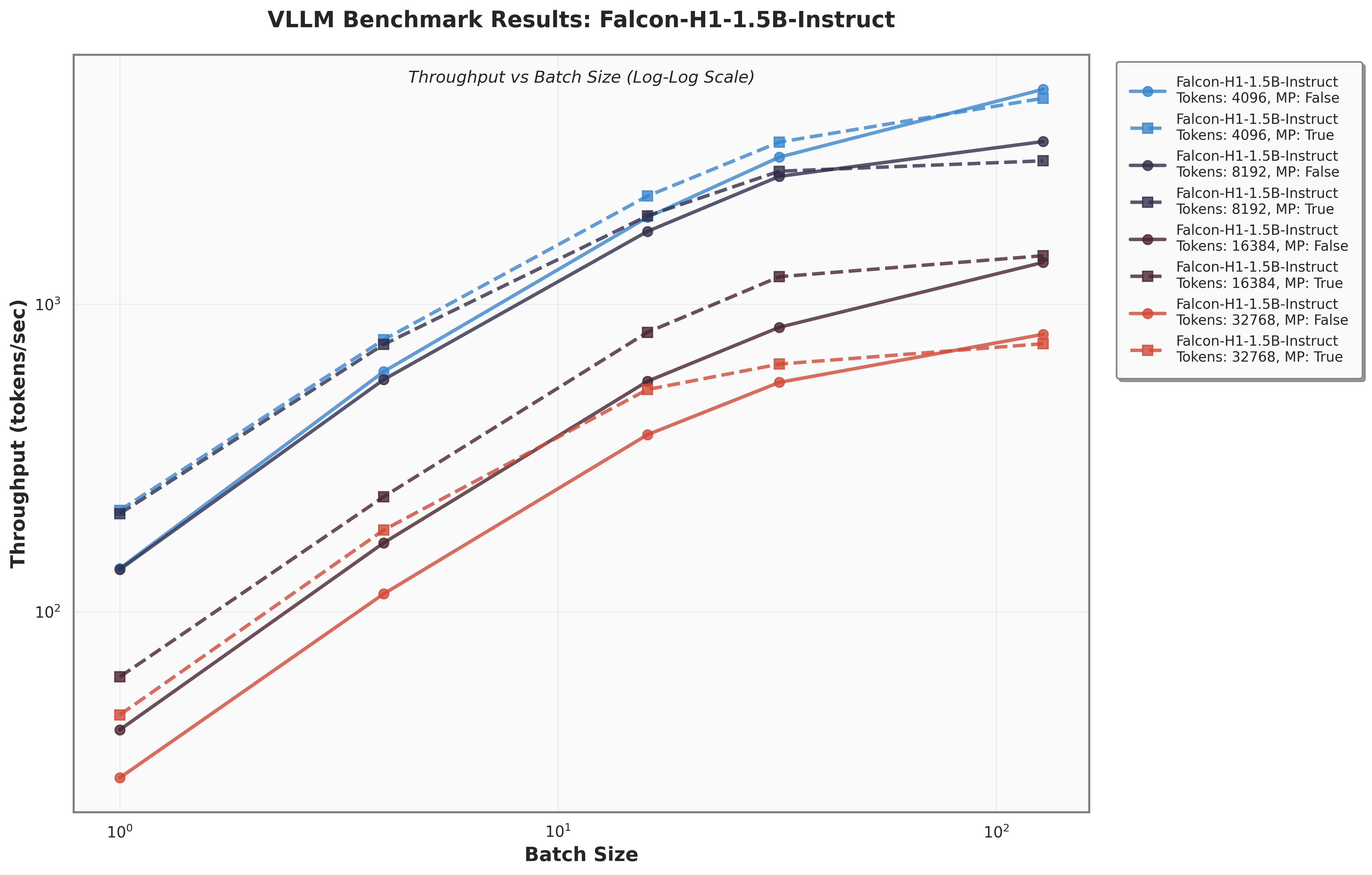
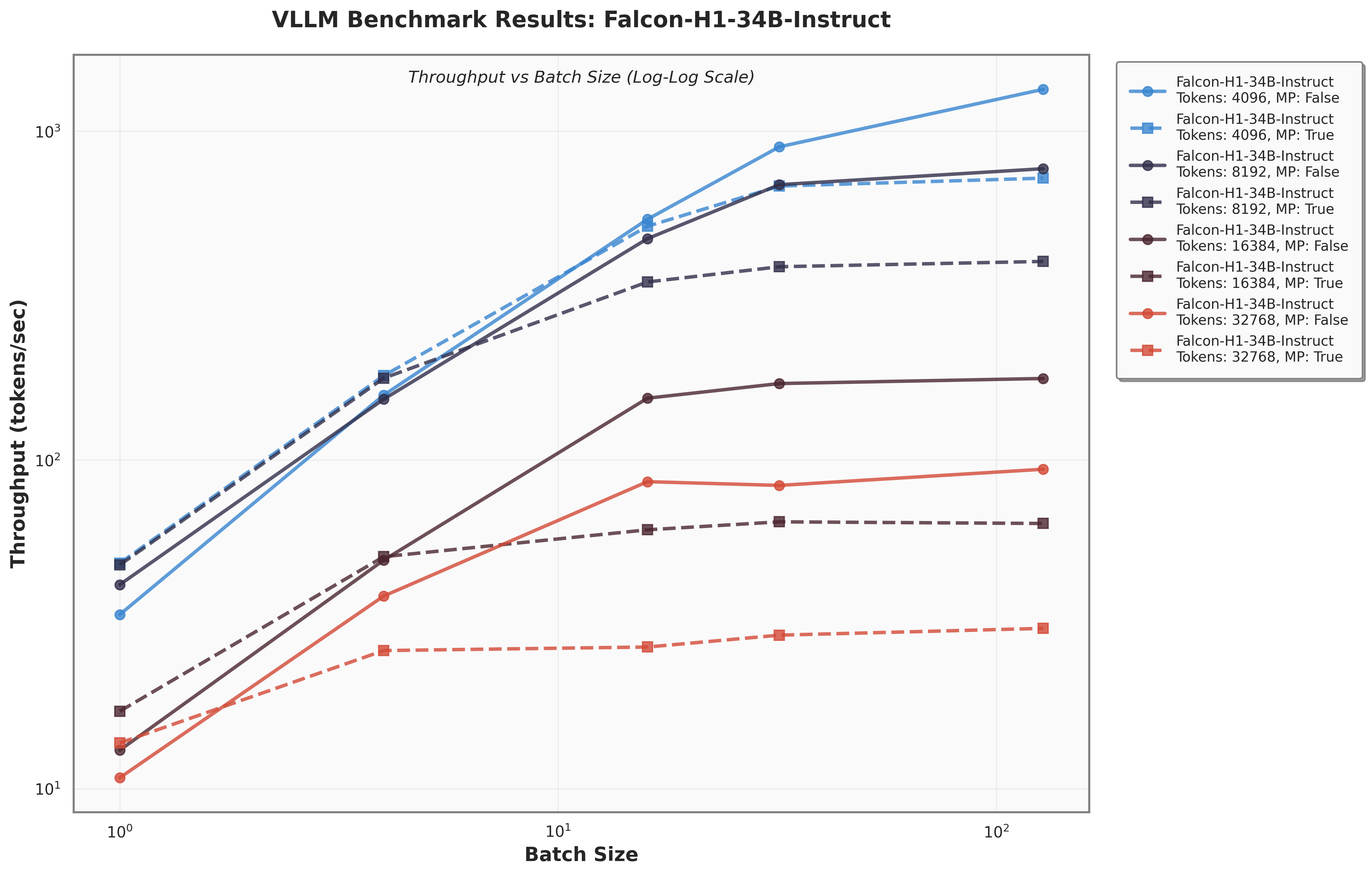
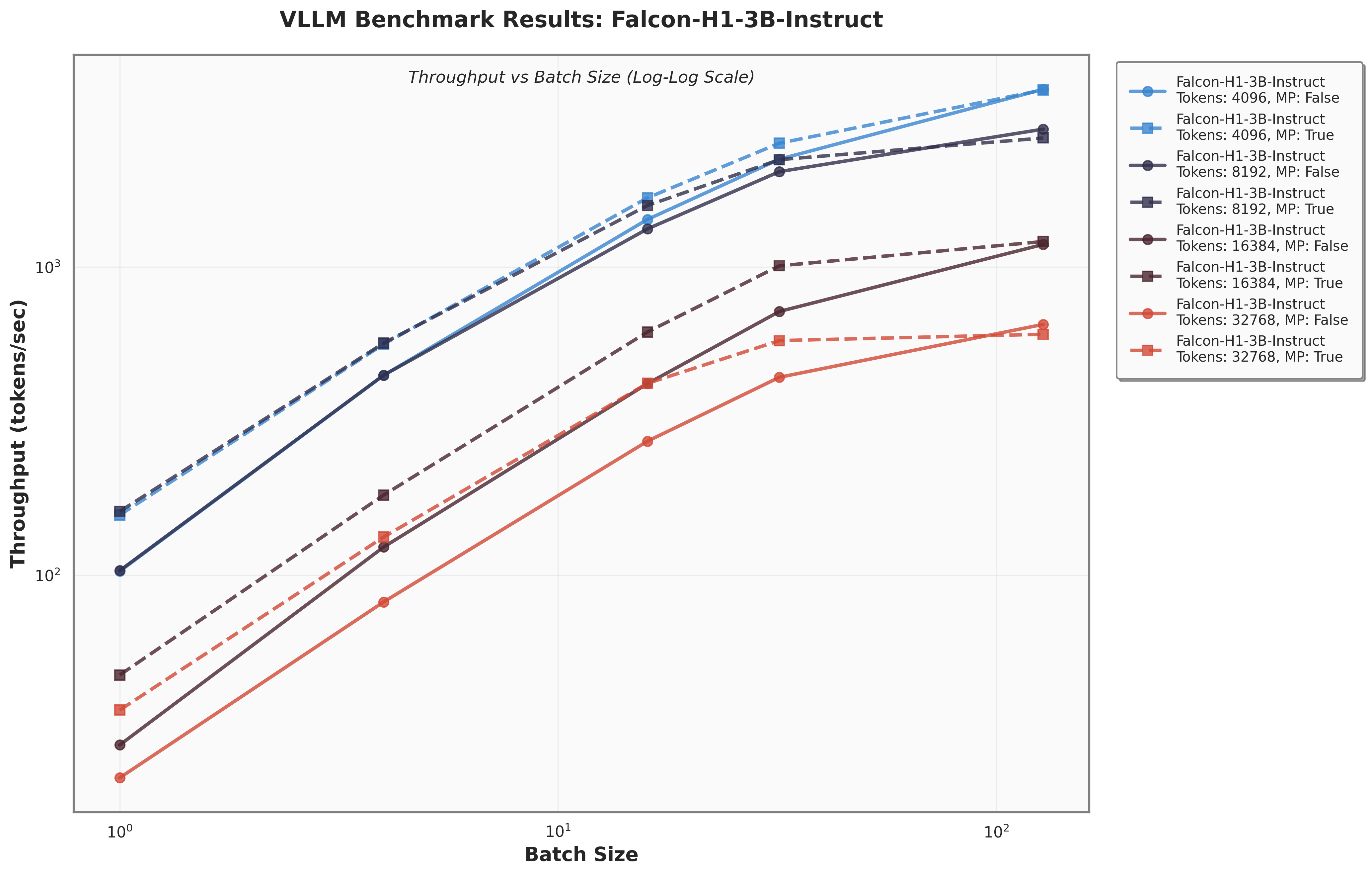
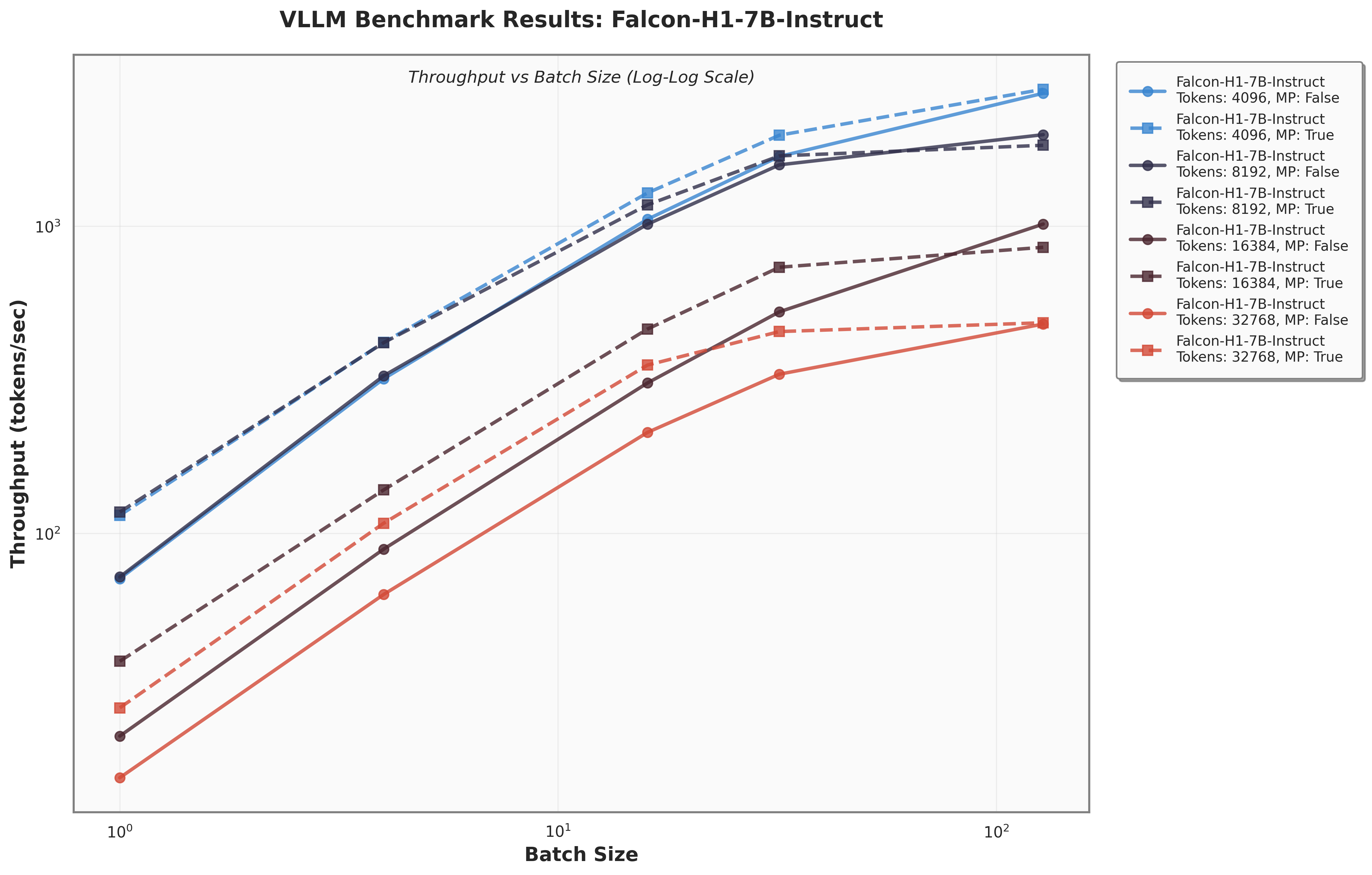
아키텍처 측면에서 Falcon H1R은 “하이브리드 병렬” 설계를 채택한다. 전통적인 트랜스포머 레이어는 토큰‑레벨 병렬성을 유지하면서, 특정 연산(예: 매트릭스 곱셈)에서는 모델‑레벨 파이프라인 병렬을 적용한다. 결과적으로 GPU/TPU 자원을 보다 효율적으로 활용해 토큰당 연산량을 감소시키고, 동일한 하드웨어에서 기존 7 억 모델 대비 1.8배~2.3배 빠른 추론 속도를 달성한다.
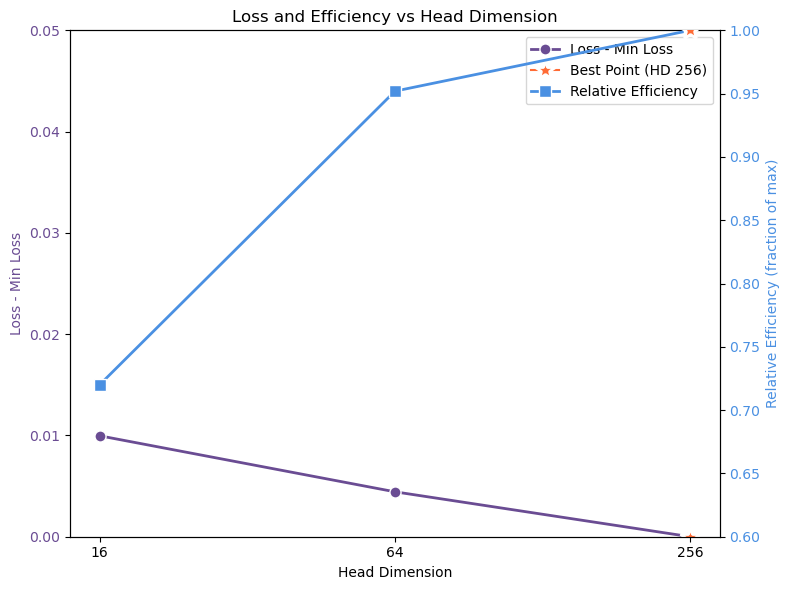
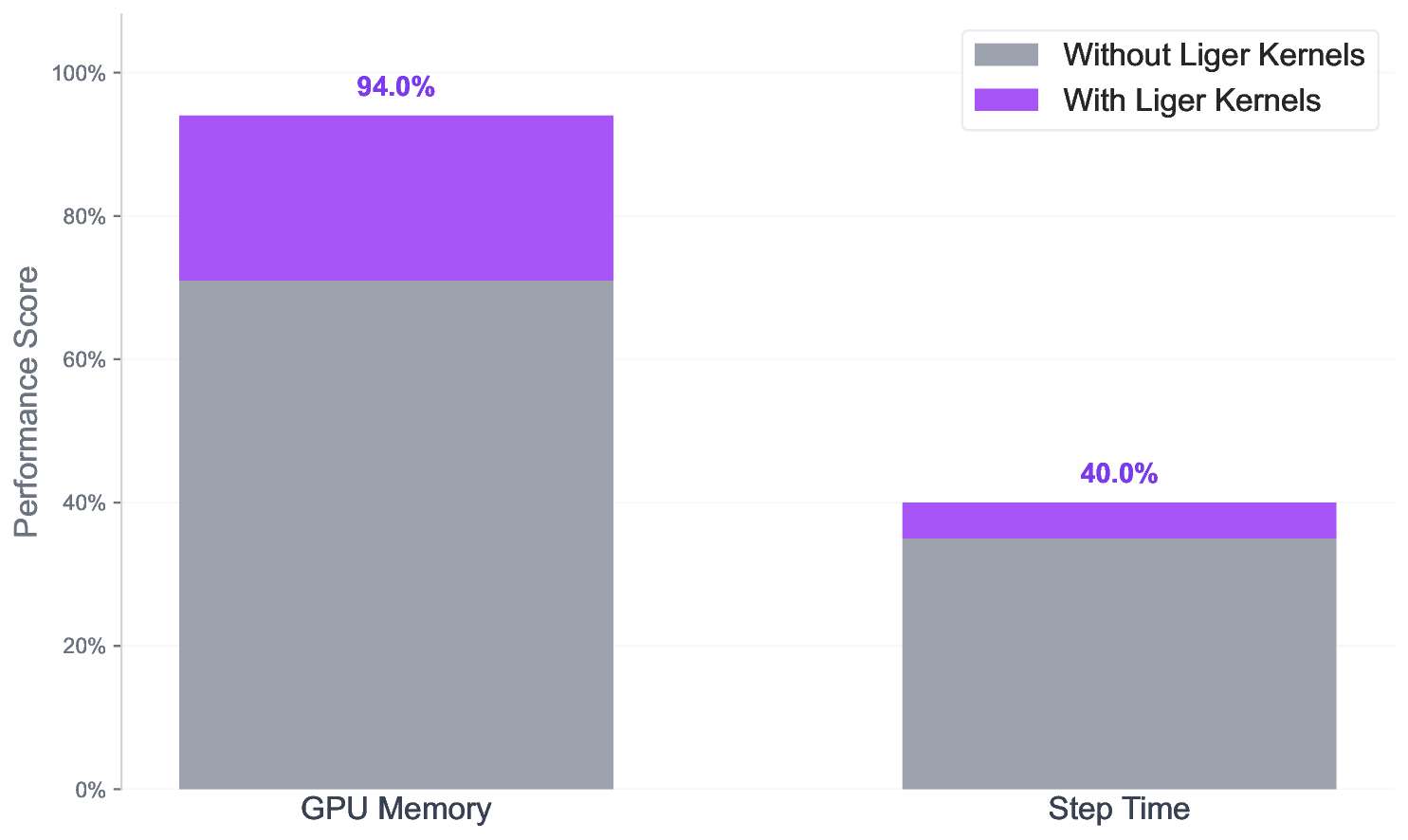
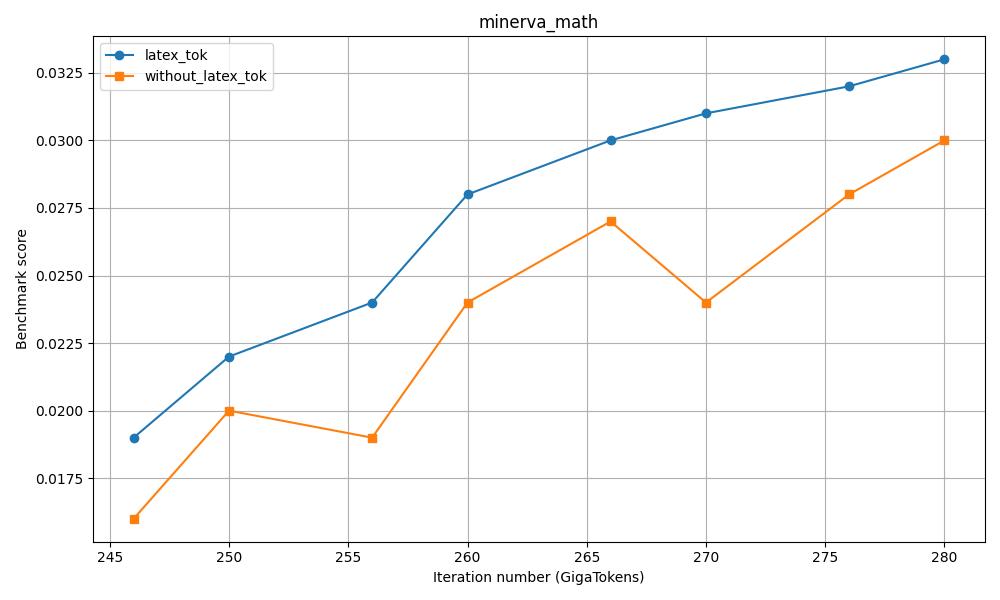
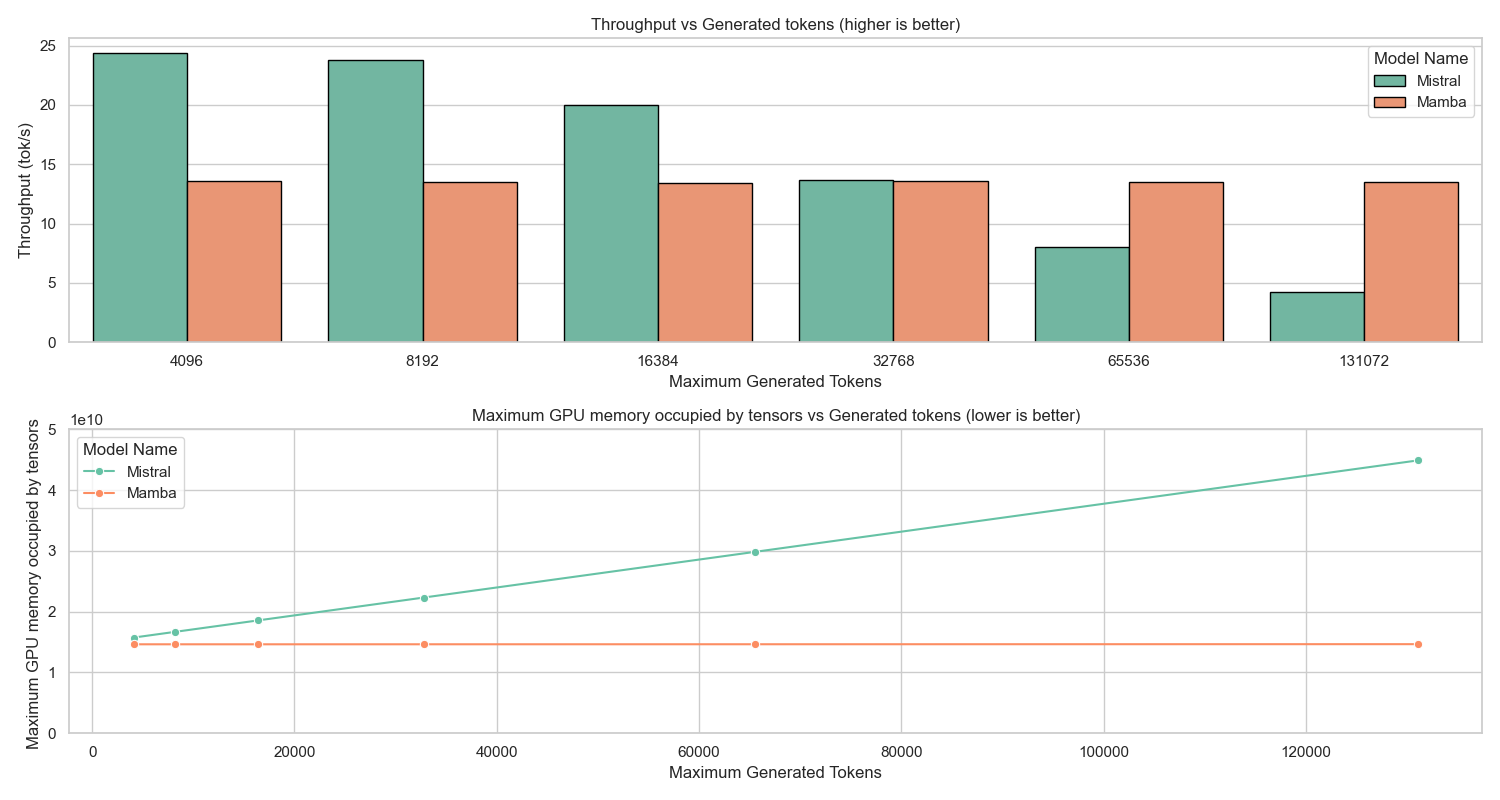
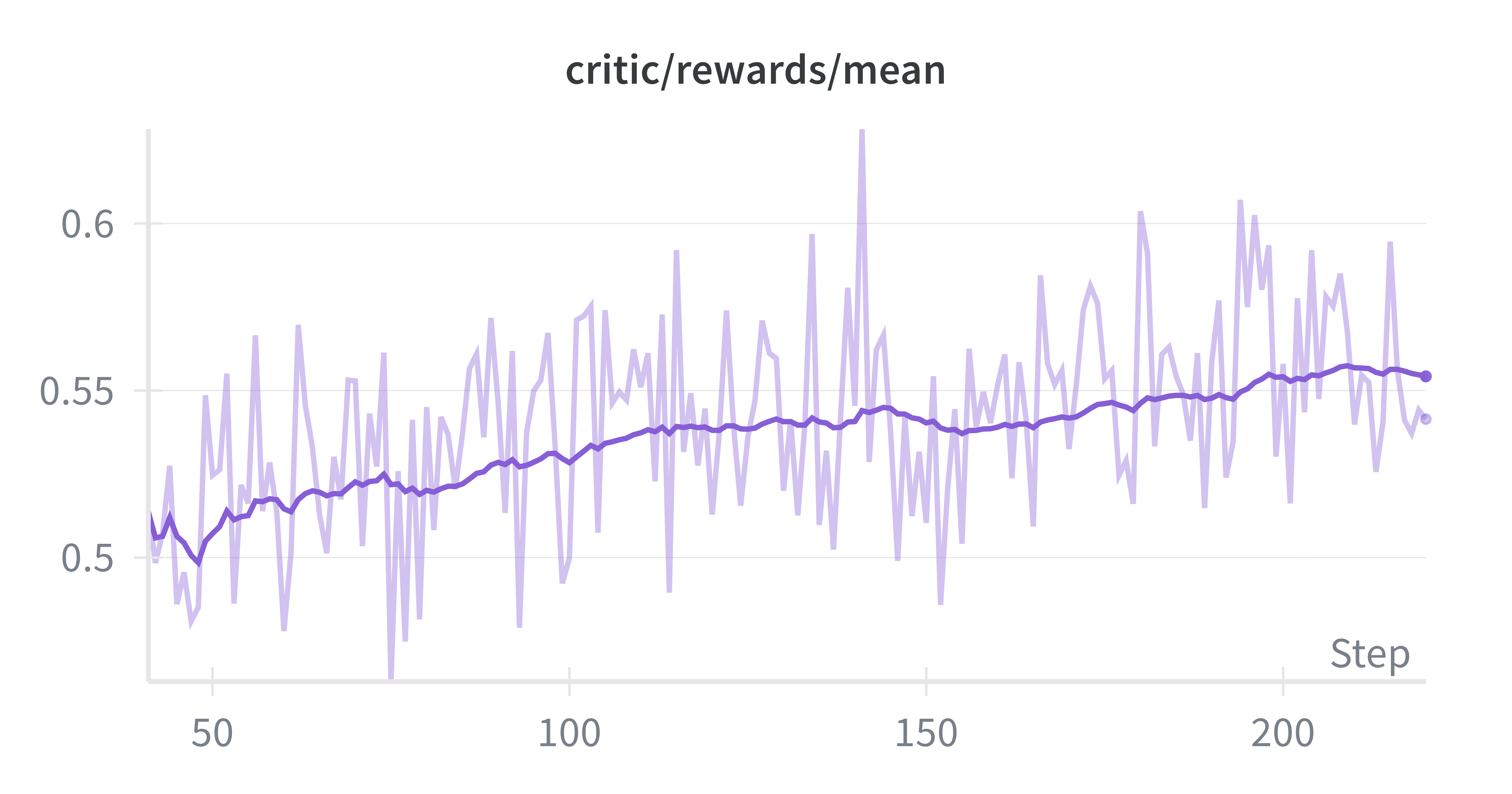
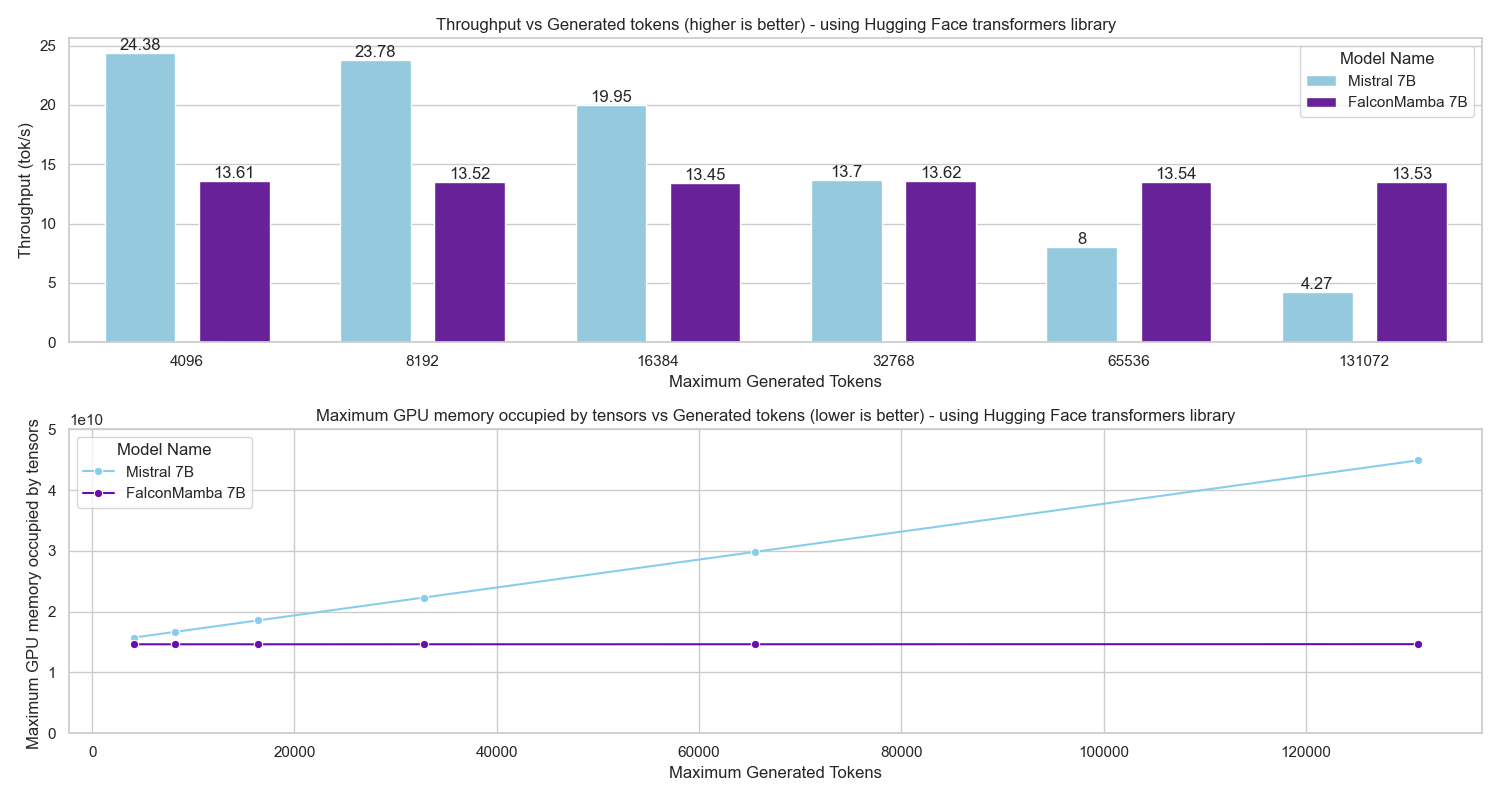
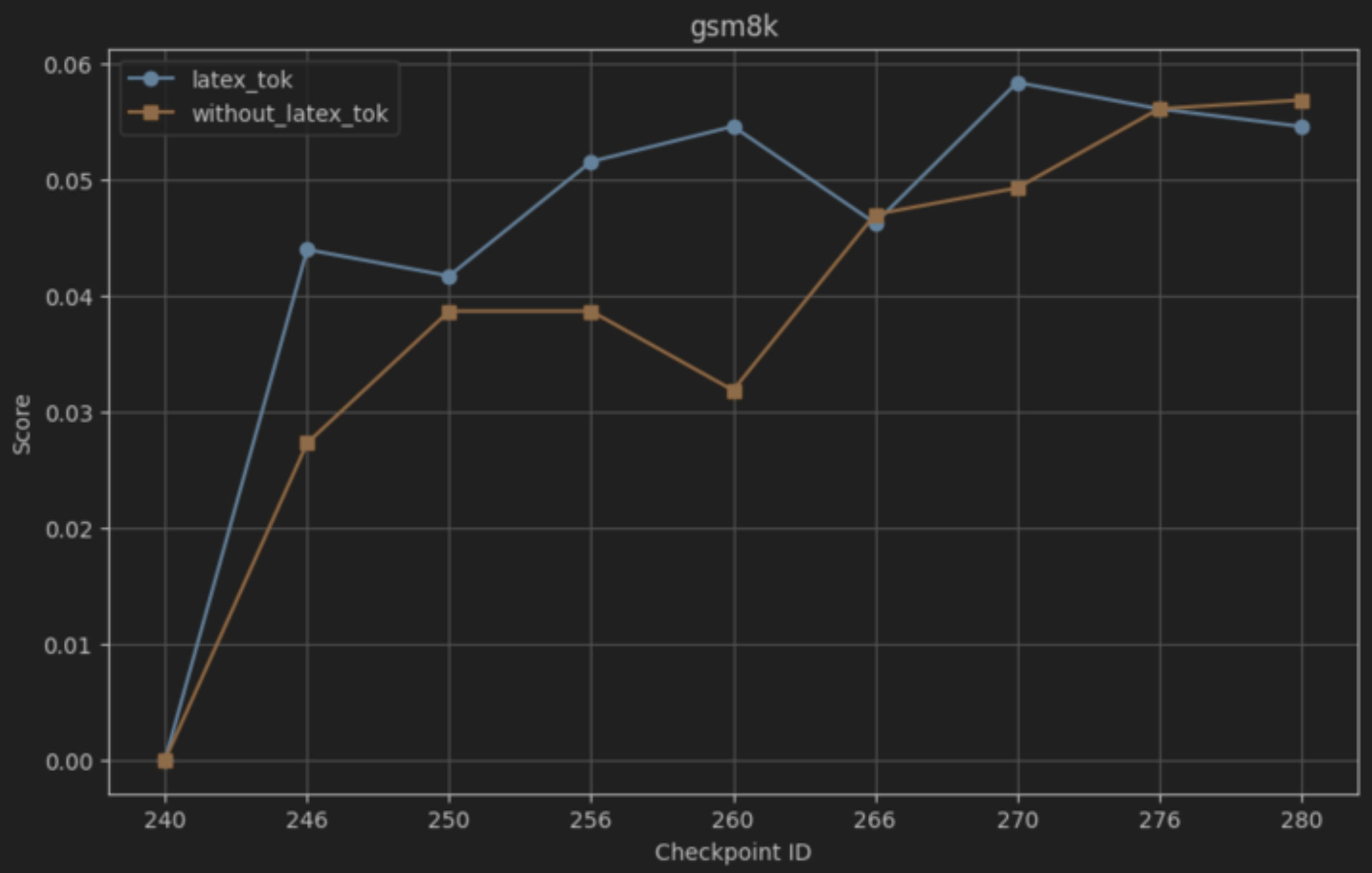
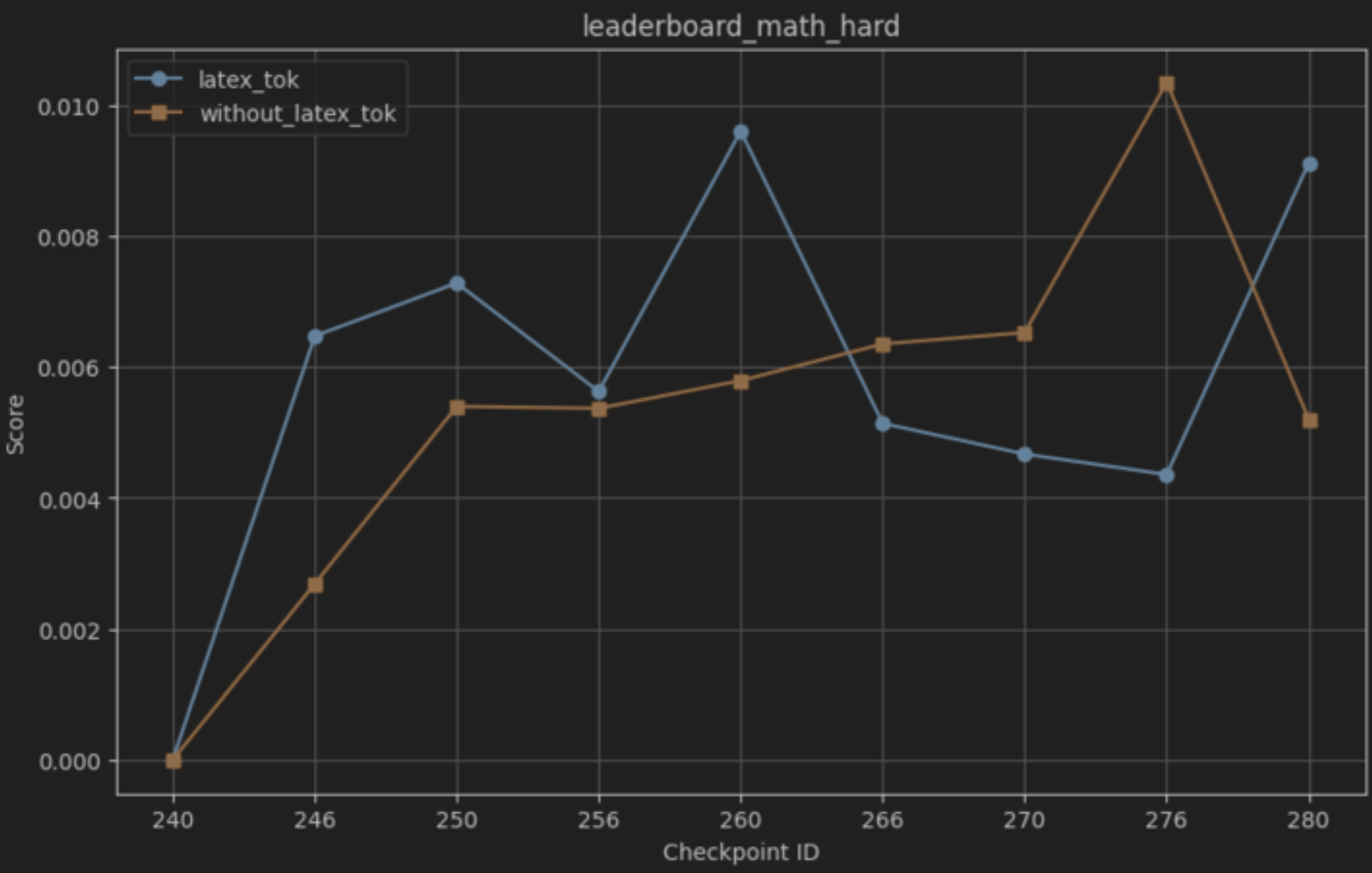
테스트‑타임 스케일링 효율성은 DeepConf이라는 최신 자동화 구성 프레임워크를 통해 최적화된다. DeepConf은 하드웨어 자원, 배치 크기, 토큰 길이 등을 실시간으로 모니터링하고, 비용‑효율적인 스케줄링 정책을 자동으로 생성한다. 이를 적용한 Falcon H1R은 동일한 정확도 목표 하에 기존 SOTA 모델 대비 30 %~45 % 적은 FLOPs와 전력 소비를 기록한다.
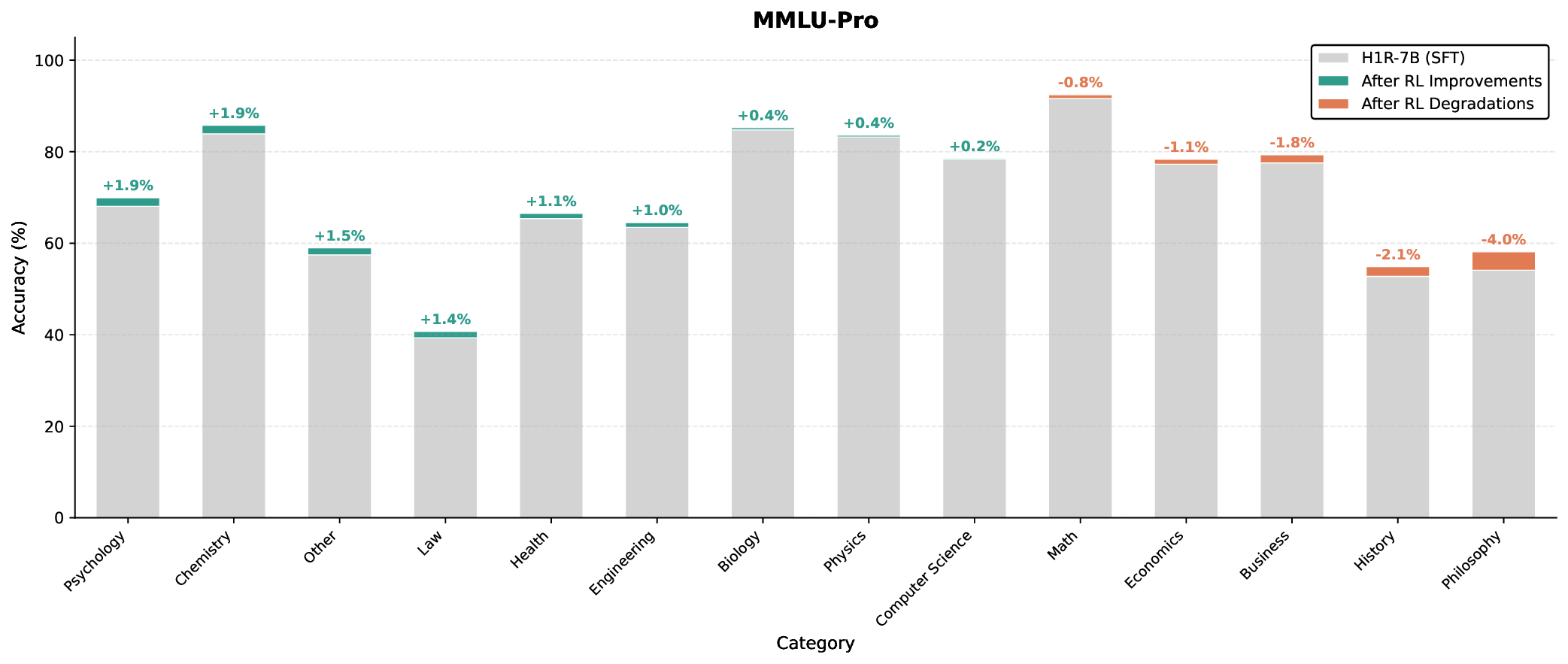
이러한 결과는 “파라미터 수가 곧 성능을 결정한다”는 기존 패러다임을 재검토하게 만든다. 특히, 비용‑제한이 큰 기업·연구기관, 모바일·엣지 디바이스와 같이 메모리·연산 자원이 제한된 환경에서 Falcon H1R은 실용적인 대안이 될 수 있다. 다만, 현재 실험은 주로 영어 기반 베이스라인과 공개 벤치마크에 국한되어 있어, 다언어·다문화 환경에서의 일반화 가능성은 추가 검증이 필요하다. 또한, 강화학습 단계에서 보상 설계가 모델 편향을 증폭시킬 위험이 존재하므로, 보상 함수의 투명성과 공정성에 대한 지속적인 모니터링이 요구된다.
요약하면, Falcon H1R은 데이터 선별, 효율적 파인튜닝, 하이브리드 병렬 아키텍처, 자동화된 테스트‑타임 최적화를 결합해 작은 파라미터 규모에서도 고성능 추론을 구현한다. 이는 차세대 AI 시스템이 “작고 빠르며 똑똑한” 방향으로 진화할 수 있음을 실증적으로 보여준다.
📄 논문 본문 발췌 (Translation)
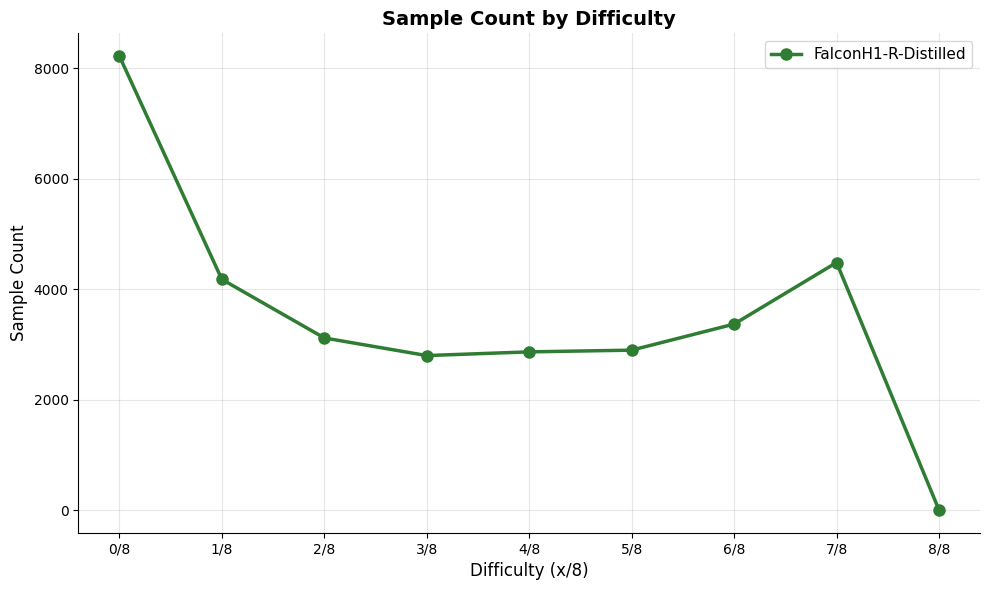
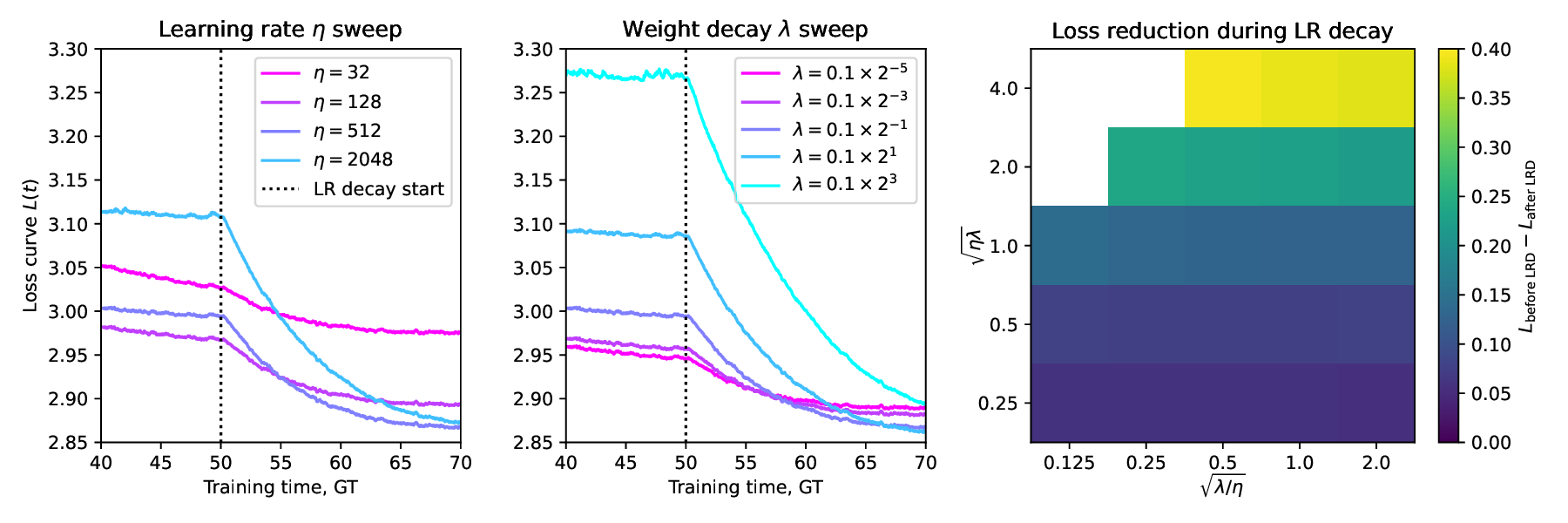
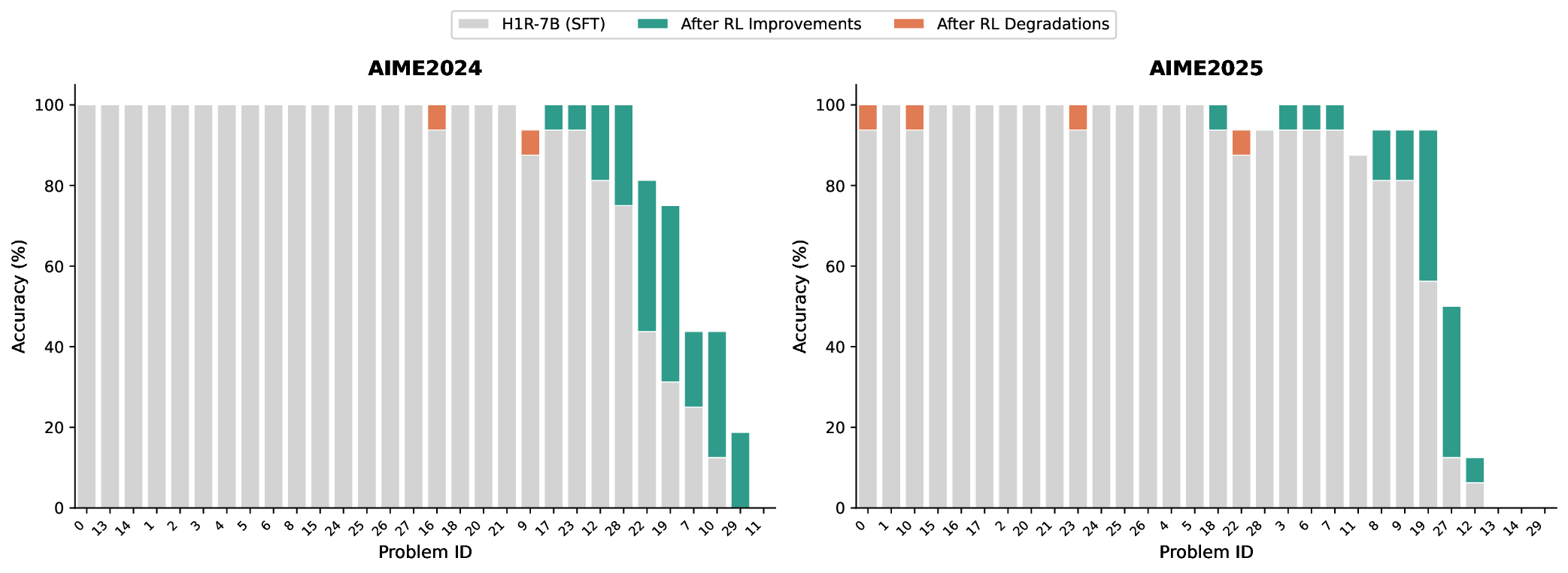
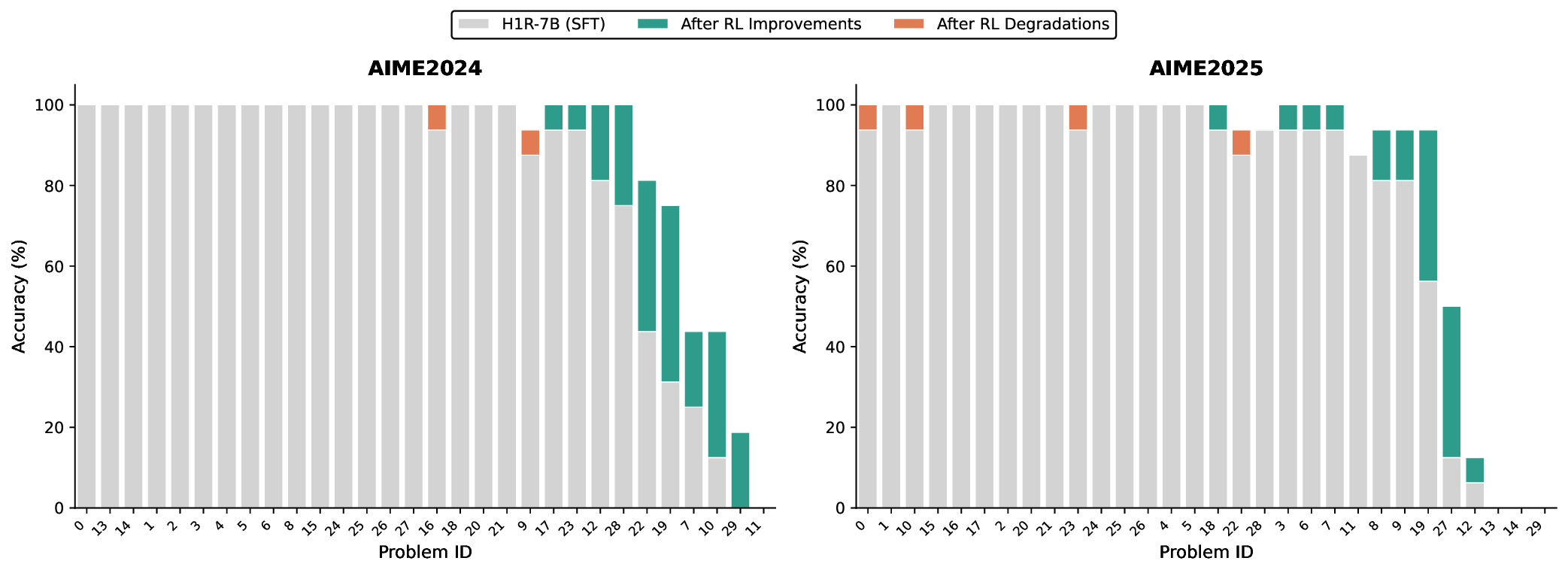
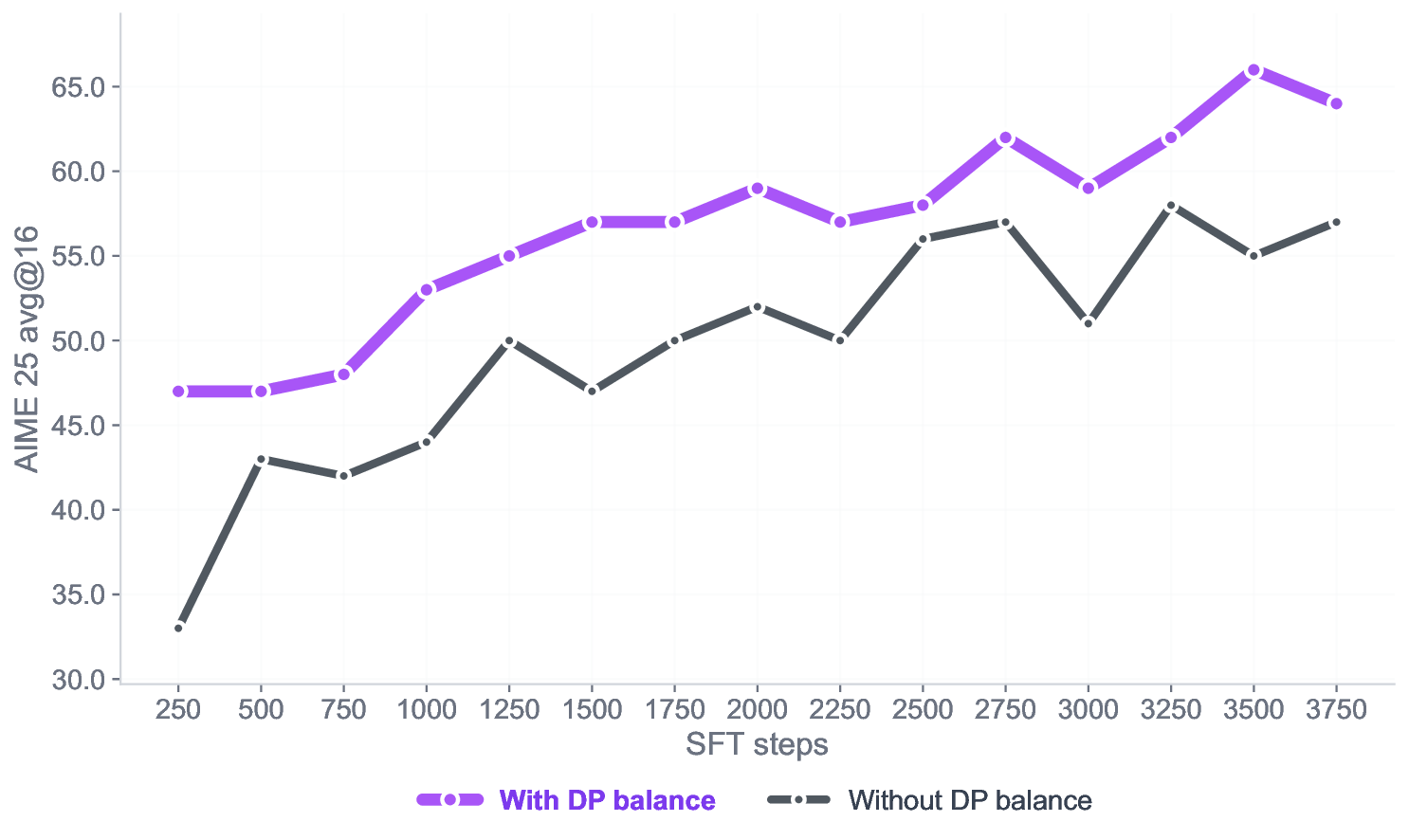
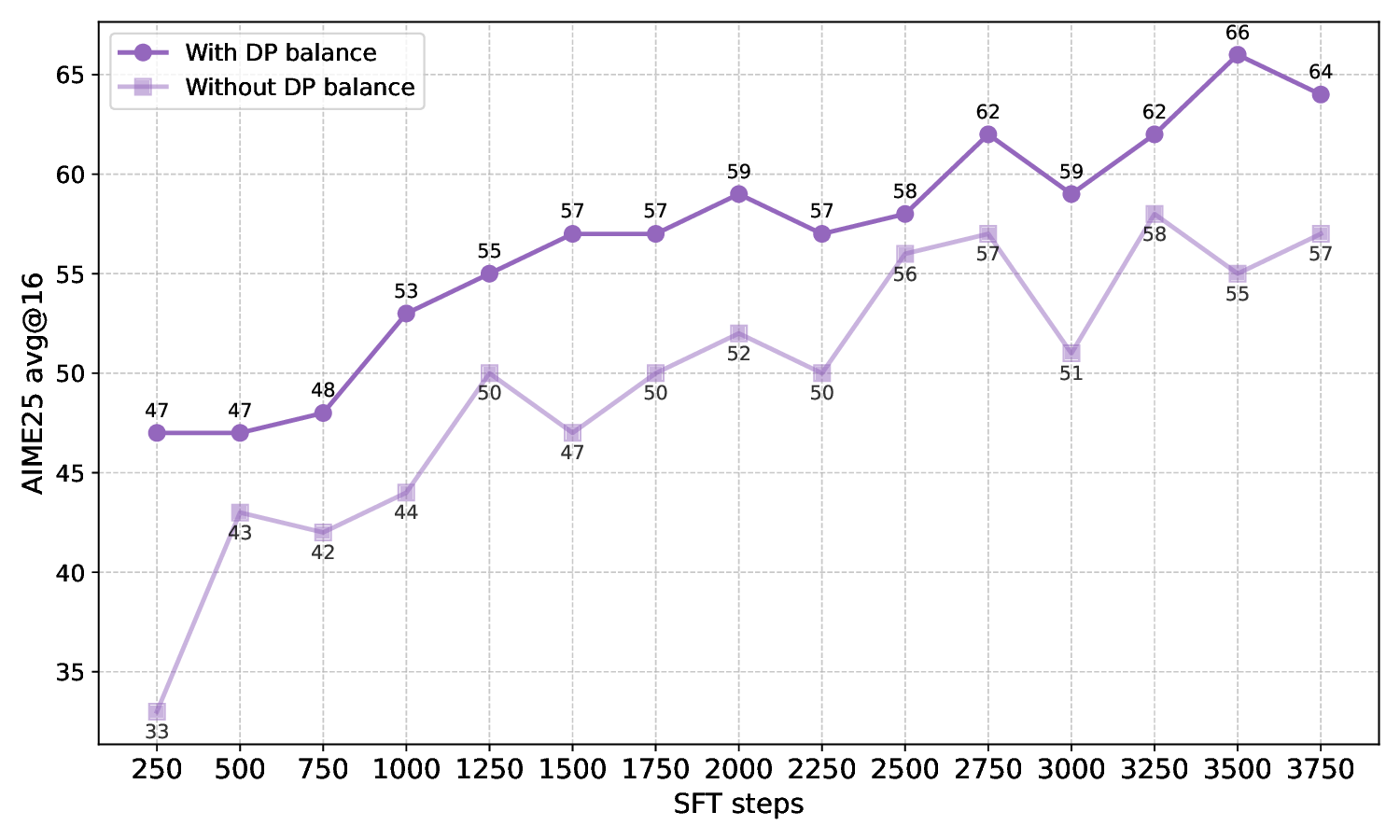
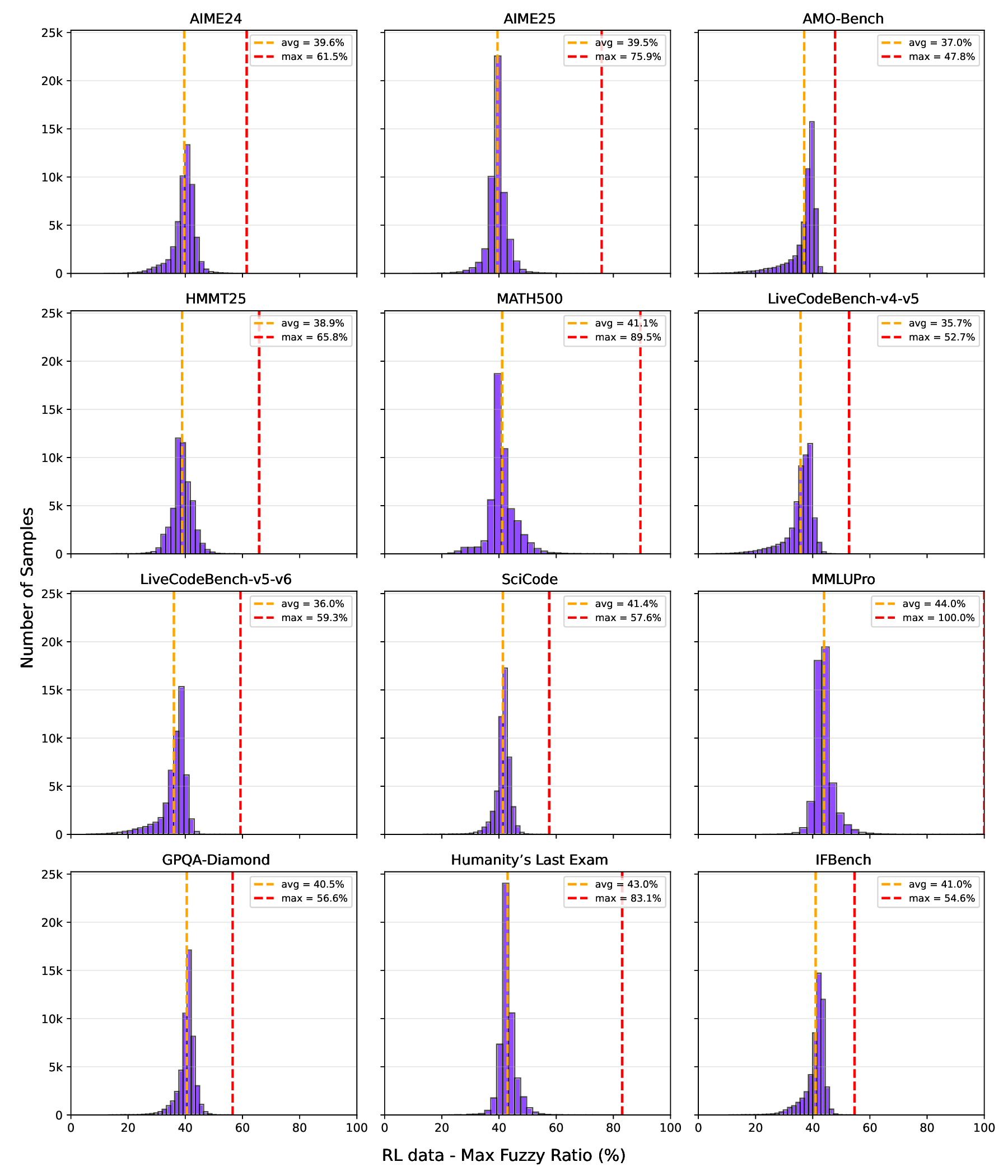
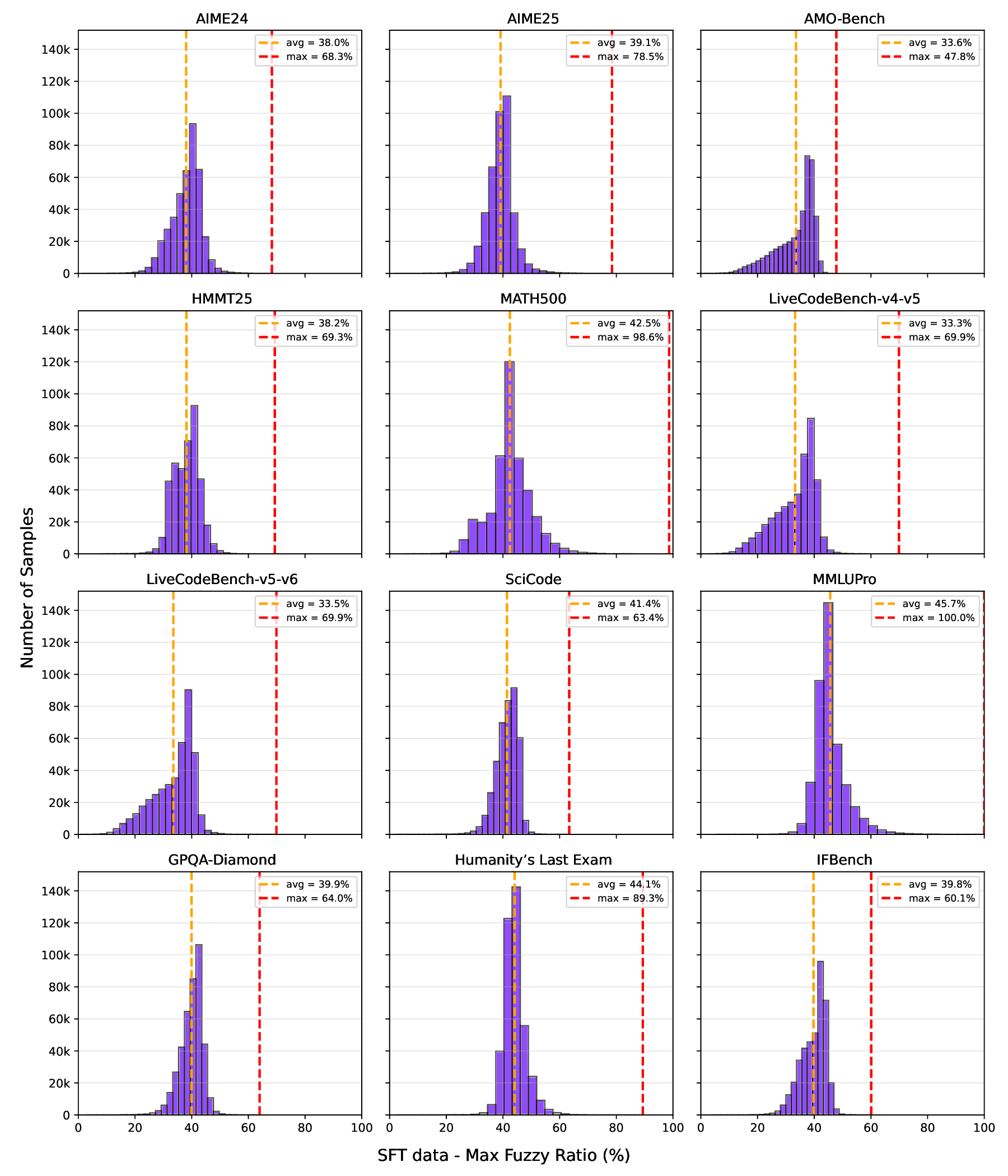
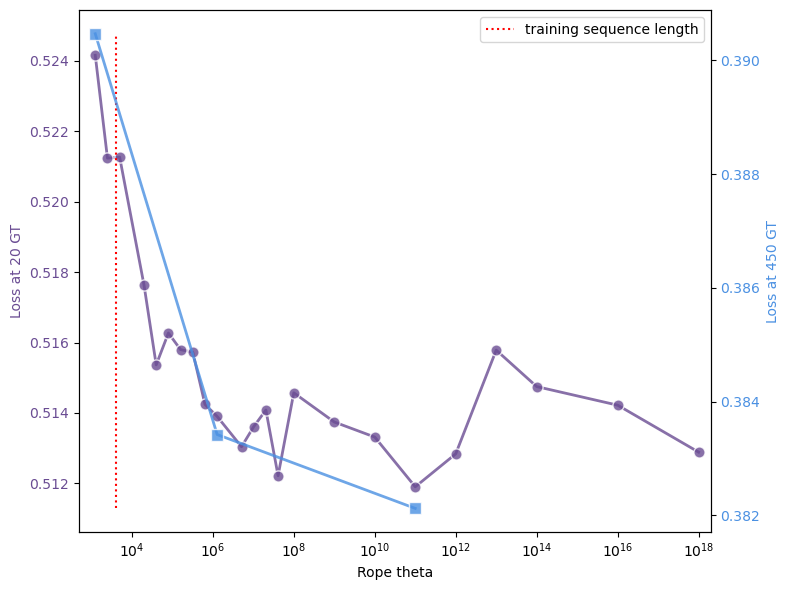
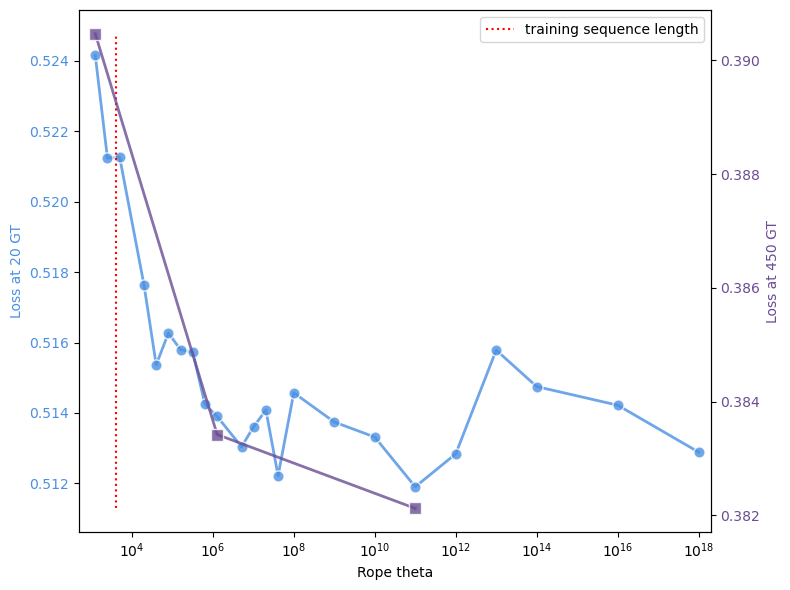
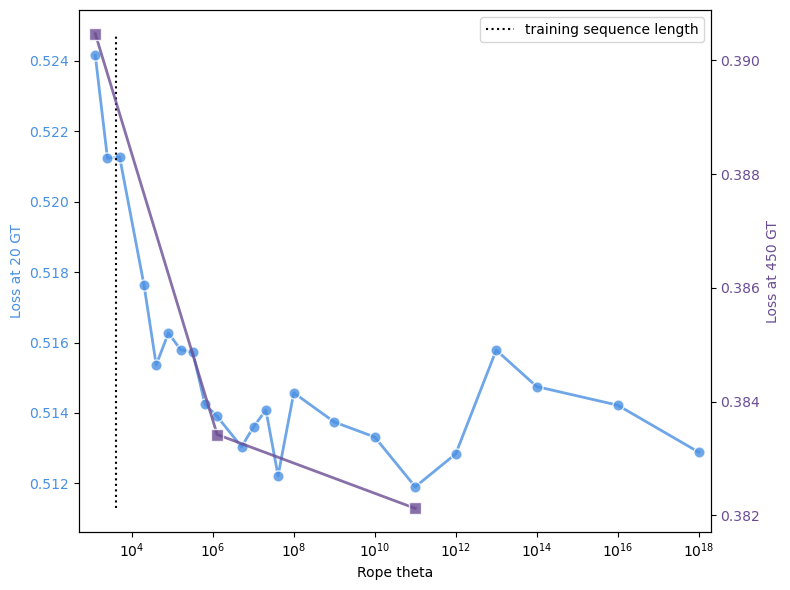
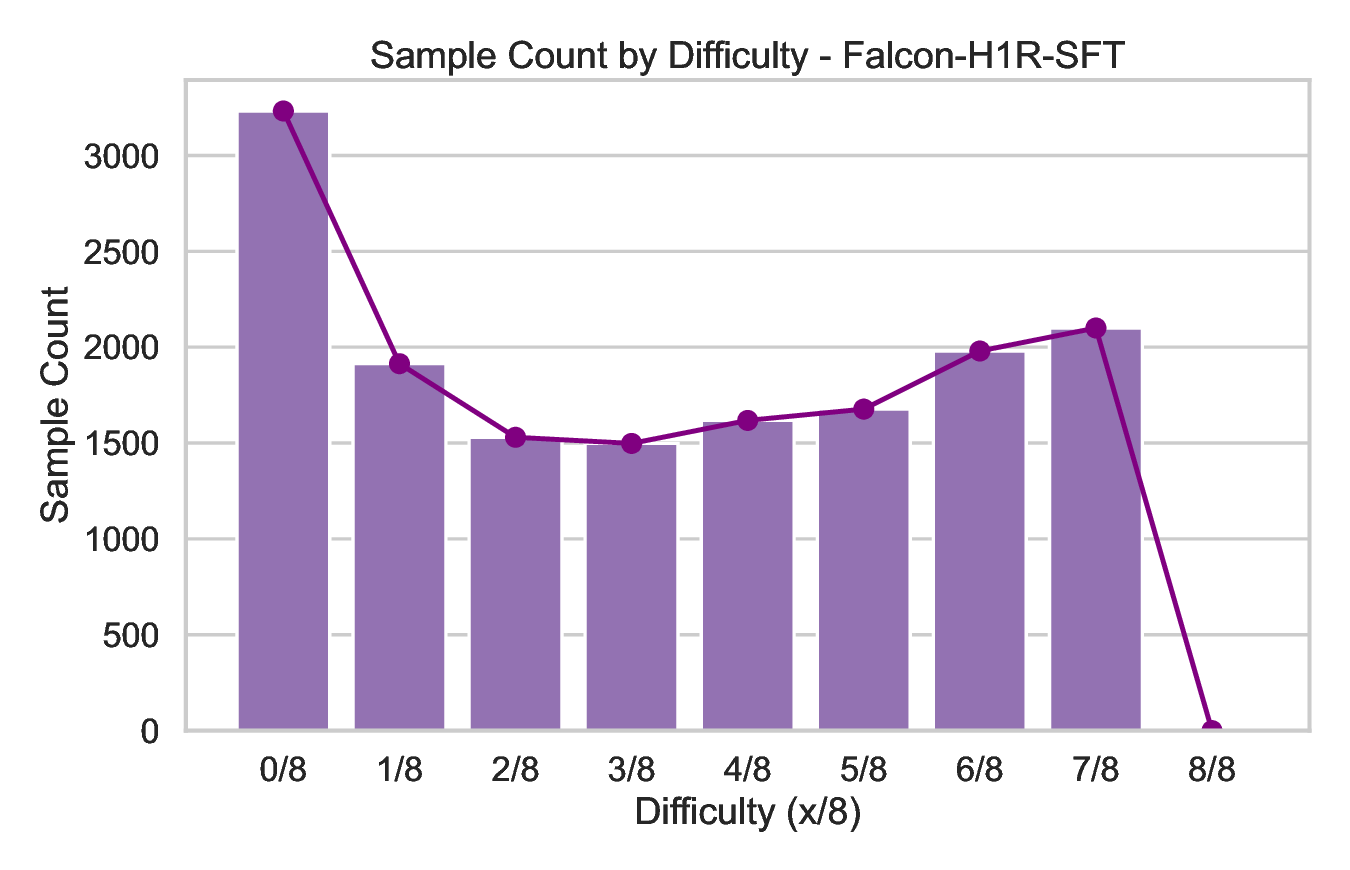
📸 추가 이미지 갤러리