- Title: K-EXAONE Technical Report
- ArXiv ID: 2601.01739
- 발행일: 2026-01-05
- 저자: Eunbi Choi, Kibong Choi, Seokhee Hong, Junwon Hwang, Hyojin Jeon, Hyunjik Jo, Joonkee Kim, Seonghwan Kim, Soyeon Kim, Sunkyoung Kim, Yireun Kim, Yongil Kim, Haeju Lee, Jinsik Lee, Kyungmin Lee, Sangha Park, Heuiyeen Yeen, Hwan Chang, Stanley Jungkyu Choi, Yejin Choi, Jiwon Ham, Kijeong Jeon, Geunyeong Jeong, Gerrard Jeongwon Jo, Yonghwan Jo, Jiyeon Jung, Naeun Kang, Dohoon Kim, Euisoon Kim, Hayeon Kim, Hyosang Kim, Hyunseo Kim, Jieun Kim, Minu Kim, Myoungshin Kim, Unsol Kim, Youchul Kim, YoungJin Kim, Chaeeun Lee, Chaeyoon Lee, Changhun Lee, Dahm Lee, Edward Hwayoung Lee, Honglak Lee, Jinsang Lee, Jiyoung Lee, Sangeun Lee, Seungwon Lim, Solji Lim, Woohyung Lim, Chanwoo Moon, Jaewoo Park, Jinho Park, Yongmin Park, Hyerin Seo, Wooseok Seo, Yongwoo Song, Sejong Yang, Sihoon Yang, Chang En Yea, Sihyuk Yi, Chansik Yoon, Dongkeun Yoon, Sangyeon Yoon, Hyeongu Yun
📝 초록
이 기술 보고서는 LG AI Research에서 개발한 대규모 다국어 언어 모델 K-EXAONE을 소개합니다. K-EXAONE은 총 236B의 파라미터를 갖춘 Experts 혼합 구조 위에 구축되어 있으며, 추론 과정에서는 23B의 파라미터가 활성화됩니다. 이 모델은 256K 토큰 컨텍스트 윈도우를 지원하며 한국어, 영어, 스페인어, 독일어, 일본어, 베트남어 등 여섯 가지 언어를 다룹니다. 우리는 K-EXAONE을 종합적인 벤치마크 스위트에 대한 평가에서 논리적 추론 능력, 에이전시 능력, 일반적인 능력, 한국어 전문성 및 다국어 기능을 평가합니다. 이러한 평가를 통해 K-EXAONE은 유사한 크기의 공개 가중치 모델과 비교할 수 있는 성능을 보여줍니다. K-EXAONE은 더 나은 삶을 위한 AI 발전을 목표로 하며, 다양한 산업 및 연구 애플리케이션에 활용될 수 있는 강력한 소유권 AI 기반 모델로서의 위치를 차지하고 있습니다.
💡 논문 해설
1. **Key Contribution: 모델 아키텍처 혁신**
- K-EXAONE은 Mixture-of-Experts(MoE) 구조를 채택하여, 모델의 용량을 효율적으로 확장할 수 있습니다. 이는 마치 여러 전문가들이 함께 일하는 것과 같아서, 각각이 자신에게 가장 잘 맞는 작업을 처리함으로써 전체 시스템의 성능을 향상시킵니다.
Key Contribution: 멀티링어 지원 강화
K-EXAONE은 토크나이저를 업데이트하여 독일어, 일본어, 베트남어 등 다양한 언어를 지원합니다. 이는 마치 여러 나라의 언어를 자유롭게 사용할 수 있는 통역사와 같아서, 다양한 문화와 컨텐츠 간의 소통을 가능하게 합니다.
Key Contribution: 긴 문맥 처리
K-EXAONE은 최대 256K 토큰까지 지원하는 긴 문맥 처리 능력을 갖추고 있습니다. 이는 마치 장문의 책을 한 번에 읽어내려가는 것과 같아서, 복잡한 정보를 빠르게 이해하고 처리할 수 있는 능력을 제공합니다.
📄 논문 발췌 (ArXiv Source)
/>
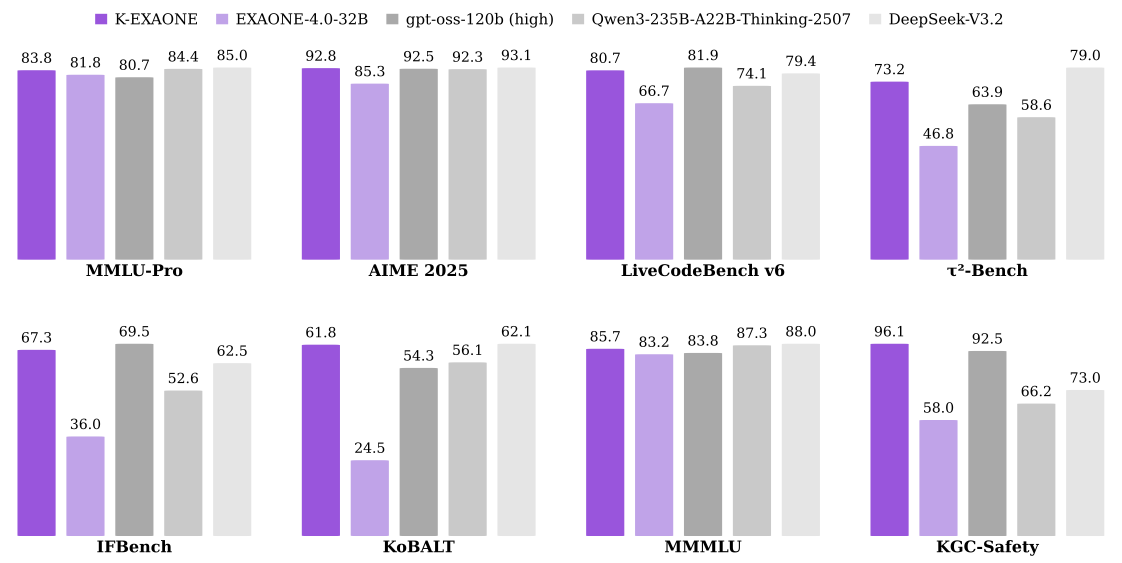
K-EXAONE의 8개 카테고리에 대한 주요 평가 결과: 세계 지식(MMLU-Pro), 수학 (AIME 2025), 코딩 (LiveCodeBench v6), 에이전트 도구 사용(τ2-Bench),
지시어 따르기 (IFBench), 한국어 (KoBALT), 다중 언어 (MMMLU), 안전성 (KGC-Safety). 평가에 사용된 모든 모델은 추론 모델입니다. τ2-Bench 점수는 가중치 평균입니다.
서론
대형 언어 모델(LLMs)의 전 세계적인 개발은 현재 격렬한 경쟁을 겪고 있으며, 선두 국가들은 성능이 우수한 모델을 배포하기 위해 노력하고 있습니다. 이 경쟁에서 현재는 폐쇄 소스 모델이 경쟁력을 가지고 있지만, 오픈 웨이트 모델은 공격적인 확장 전략을 통해 빠르게 따라잡고 있습니다. 오픈 웨이트 모델의 성장을 주도하는 요인 중 하나는 모델 크기에 따른 확장 효과로, 이미 수백억 개의 파라미터를 넘어 trillion-파라미터 규모에 가까워지고 있습니다. 이 확장 작업은 폐쇄 소스와 오픈 웨이트 모델 간의 성능 격차를 줄이는 데 중요합니다.
그러나 한국에서는 고유한 도전 과제가 존재합니다. 전 세계 리더들과 비교했을 때, AI 전문 데이터 센터와 AI 칩에 대한 상대적으로 부족한 자원으로 인해 대규모 모델의 개발이 제한되고 있습니다. 그 결과 이전 노력은 수십억 개의 파라미터로 이루어진 비용 효율적인 소형 모델에 중점을 뒀습니다. 그러나 이러한 도전에도 불구하고, AI 전환을 위한 견고하고 신뢰할 수 있는 기반을 구축하기 위해서는 글로벌 규모에서 최상위 성능을 보여주는 모델이 필요합니다. 이러한 인프라스트럭처의 간극을 메꾸기 위해 한국 정부는 대규모 AI 모델 개발에 필요한 주요 자원, 예를 들어 GPU 등을 제공하는 전략 프로그램을 시작했습니다. LG AI 연구소는 이_Initiative에 적극적으로 참여하여 정부 지원을 활용해 K-EXAONE 기반 모델을 개발했으며, 이를 상세하게 설명한 기술 보고서입니다.
K-EXAONE은 EXAONE 4.0의 하이브리드 아키텍처를 바탕으로 추론과 비추론 능력을 결합하여 일반적인 용도와 전문적인 용도 모두에서 성능을 향상시킵니다. 또한 글로벌 및 로컬 주의 모듈을 통합한 하이브리드 주의 메커니즘을 사용하여 긴 맥락 입력 처리를 효율적으로 수행할 수 있습니다. 이는 실제 응용 프로그램에 중요한 기능입니다.
K-EXAONE을 돋보이게 하는 주요 아키텍처 혁신 중 하나는 Mixture-of-Experts(MoE) 패러다임의 채택입니다. 이 디자인은 최고 수준의 모델에서 점점 더 많이 사용되고 있으며, 확장성과 효율적인 계산을 가능하게 합니다. 또한 EXAONE 4.0이 한국어, 영어, 스페인어를 지원하는 반면 K-EXAONE은 토크나이저를 업데이트하여 독일어, 일본어, 베트남어를 포함시켜 다양한 언어적 맥락에서의 활용성을 넓혔습니다.
모델링
모델 구성
K-EXAONE은 LG AI 연구소가 이전에 발표한 EXAONE 시리즈와 구조적으로 다르다. EXAONE은 밀집형 모델링 패러다임을 채택하지만, K-EXAONE은 모델 용량을 효율적으로 확장할 수 있는 MoE 아키텍처로 설계되었습니다. 이는 100B 파라미터 규모 이상의 모델 훈련에 점점 더 많이 채택되고 있습니다.
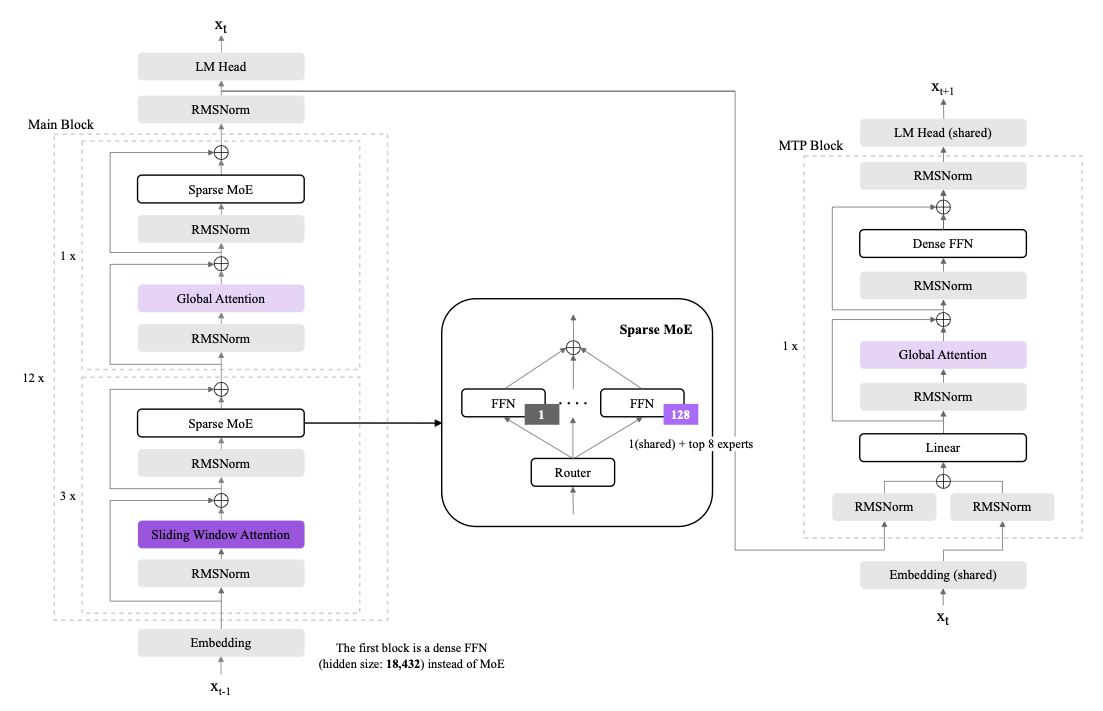
Figure 2에서 보듯이, K-EXAONE은 이전 연구에서 영감을 받은 세분화된 희소 MoE 설계를 채택하고 있습니다. 128명의 전문가로 구성되며 각 토큰당 상위 8명의 전문가와 추가적인 공유 전문가가 활성화되어, 각 라우팅 결정 시 9명의 전문가가 동시에 활성화됩니다. 전체 파라미터 수는 236B이지만 약 23B의 파라미터만 활성화되어, 표현력 다양성과 강력한 성능을 유지하면서 훈련 및 추론에 효율적인 자원 사용을 가능하게 합니다. 라우팅 안정성을 개선하고 전문가 활용 효율성을 높이기 위해 MoE 라우팅 메커니즘에서 시퀀스 수준 로드 밸런싱을 적용하며, 모든 토큰이 용량 기반 드롭 없이 전문가에게 배치되는 방침인 dropless routing 정책을 채택하여 대규모 MoE 훈련의 그래디언트 흐름 안정화와 수렴 성능 개선을 보장합니다.
/>
K-EXAONE 모델 아키텍처의 설명. 이 모델은 MoE 블록의 스택을 포함하며, 훈련 안정성을 위해 첫 번째 층만 밀집형 계층으로 구현되었습니다. 각 MoE 블록에서 128명의 전문가 풀 중에서 8명의 라우팅된 전문가와 하나의 공유 전문가를 선택하여, 각 라우팅 결정 시 총 9명의 동시 활용 전문가가 있습니다. 훈련 중 MTP 기반 보조 목표를 적용하여 추가 +1 미래 토큰 예측을 감독합니다.
또한 K-EXAONE은 밀집형 계층 기반 Multi-Token Prediction (MTP) 모듈을 통합하여 자원 효율적인 보조 훈련을 가능하게 합니다. 이는 라우팅 오버헤드와 메모리 소비를 최소화하면서 미래 토큰 예측 능력을 향상시킵니다. 추론 시 K-EXAONE은 MTP 블록을 사용하여 자동 초안 작성에 활용되어, 표준 자기회귀 디코딩보다 약 1.5$`\times`$의 디코딩 처리량 개선이 이루어집니다.
K-EXAONE은 최대 256K 토큰까지 지원하며 EXAONE 4.0에서 처음 소개된 하이브리드 주의 아키텍처를 통합하여, 전체 계층에 걸친 전역 주의(GA)와 비교해 메모리 소비 및 계산 오버헤드를 크게 줄여 효율적인 긴 맥락 모델링을 가능하게 합니다.
훈련 안정성과 긴 맥락 추론을 개선하기 위해 K-EXAONE은 EXAONE 4.0에서 유래한 두 가지 아키텍처 기능, QK Norm 및 SWA(슬라이딩 윈도우 주의)만 RoPE(Rotary Positional Embeddings)를 포함합니다. QK Norm은 주의 계산 전 쿼리와 키 벡터에 레이어 정규화를 적용하여 깊은 네트워크에서 발생하는 주의 로짓 폭발을 완화하고 훈련 동적 안정성을 유지합니다. RoPE는 선택적으로 SWA 계층에만 적용되어 전역 토큰 상호 작용을 방해하지 않으며, 긴 시퀀스 추론에 대한 강건성을 개선합니다.
긴 맥락 설정에서 추론 효율성 최적화를 위해 슬라이딩 윈도우 크기를 4,096에서 128로 줄여 KV-캐시 사용을 최소화하면서 모델링 용량을 유지합니다. 다양한 효율적인 긴 맥락 추론 아키텍처 설계 중 K-EXAONE은 SWA와 GA를 채택하며, 이는 현대 LLM 추론 엔진에 원래 지원되므로 배포 접근성을 개선하고 시스템 호환성을 향상시킵니다. 자세한 모델 구성은 Table 1에서 확인할 수 있습니다.
K-EXAONE의 자세한 모델 구성.
블록
구성
값
Main
Block
Layers (Total/SWA/GA)
48 / 36 / 12
슬라이딩 윈도우 크기
128
주의 헤드 (Q/KV)
64 / 8
헤드 차원
128
전문가 (총/공유/활성화)
128 / 1 / 8
파라미터 (총/활성화)
236B / 23B
MTP
Block
주의 헤드 (Q/KV)
64 / 8
헤드 차원
128
파라미터
0.52B
토크나이저
EXAONE 시리즈의 이전 모델과 비교하여, 우리는 토크나이저를 재설계하고 어휘 크기를 100K에서 150K로 늘려 토큰 효율성, 하류 작업 성능 및 다중 언어 확장성을 개선했습니다. 원래 어휘의 상위 70% 부분을 유지하고 추가 언어, STEM(과학, 기술, 공학, 수학), 코드 도메인에 대한 커버리지를 확대하기 위해 용량을 재할당했습니다. 효율성을 더욱 개선하기 위해 SuperBPE 전략을 채택하여 일반적인 단어 시퀀스를 하나의 토큰으로 만들고 전체 시퀀스 길이를 줄입니다. 슈퍼워드 토큰은 K-EXAONE 어휘의 약 20%를 차지하며, 영어, 한국어 및 다중 언어 커버리지는 2:3:1 비율로 할당됩니다.
r0.43
또한 확장된 어휘와 슈퍼워드 유닛을 지원하기 위해 토크나이저의 전처리 정규 표현식 및 정규화 방법을 업데이트했습니다. 슈퍼워드 경계, 줄 바꿈 및 다중 언어 유니코드 문자를 처리하는 데 사용되는 전처리 정규 표현식을 교체하고, 코드와 STEM 코퍼스에서 흔히 발견되는 상첨자, 하첨자 및 기호가 많은 텍스트의 의미적 차이를 유지하기 위해 유니코드 정규화를 NFKC에서 NFC로 변경했습니다.
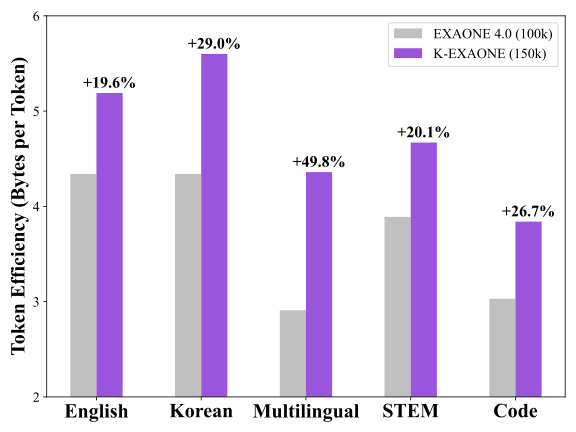
Figure [fig:tokenizer_efficiency]
토크나이저 효율성은 바이트당 토큰을 측정한 것으로, 각 토큰이 나타내는 바이트 단위의 텍스트 범위가 더 클수록 높은 값입니다. K-EXAONE은 영어, 한국어, 다중 언어, STEM 및 코드 입력에 걸쳐 효율성을 일관되게 개선했으며, 이전 EXAONE 토크나이저보다 평균적으로 약 30% 개선되었습니다.
훈련
사전 학습
K-EXAONE은 기본 지식을 구축하고 도메인 전문성과 추론 능력을 강화하는 세 단계 사전 학습 곡선을 활용합니다. EXAONE 4.0의 데이터 파이프라인을 상속하지만, 다면적인 데이터 필터링 프로세스를 적용하여 품질 높은 데이터를 보장합니다. 또한 모델의 언어 커버리지를 독일어, 일본어 및 베트남어까지 확장했습니다. 또한 사후 학습을 더욱 지원하기 위해 코퍼스에 추론 트레젝토리를 결합하여 합성합니다. 사전 학습에 사용된 데이터와 계산 자원의 양은 Table 2에서 요약되어 있습니다.
모델
236B-A23B
사전 학습 데이터 크기(토큰)
11T
계산량(FLOPs)
$`1.52 \times 10^{24}`$
K-EXAONE을 위한 사전 학습 데이터 크기와 계산 자원.
멀티링어 커버리지 확장
다양한 언어 지원을 넓히기 위해 EXAONE 4.0의 언어 커버리지를 영어, 한국어 및 스페인어에서 독일어, 일본어 및 베트남어로 확장합니다. 이들 추가 언어의 고품질 웹 텍스트를 통합합니다. 사전 학습 데이터 분포는 언어별로 크게 다릅니다. 이를 균형을 맞추기 위해 대상 언어 간 전문 지식 및 추론 패턴을 확산하는 코르스의 생성을 통해 교차 언어 지식 이전을 활용합니다.
사고 증강 데이터 합성
EXAONE 4.0의 큐레이션 전략에 사고를 명시적으로 감독하는 요소를 추가하여 데이터 합성 파이프라인을 더욱 풍부하게 합니다. 동기 부여는 에서 유래하며, 문서 기반 사고 트레젝토리를 생성하고 이를 원본 내용과 통합하여 단계별 추론을 인코딩한 일관된 샘플을 만듭니다. 이러한 사고 증강 코퍼스는 추론 행동의 전달 및 후속 사후 학습의 효과성을 향상시킵니다.
학습 설정
K-EXAONE은 FP8 정밀도로 원래 훈련되어 BF16 정밀도에서 얻은 것과 비교할 수 있는 훈련 손실 곡선을 달성하며, FP8 훈련이 최적화 안정성을 유지하면서 전체적인 양자화 인식 수렴을 가능하게 합니다. 모든 학습 단계에서 Muon 옵티마이저와 Warmup–Stable–Decay(WSD) 학습률 스케줄러를 사용합니다. 최대 학습률은 $`3.0 \times 10^{-4}`$이며, 선형 워밍업 이후 안정적인 플랫폼과 후속 감소 스케줄로 이어집니다. MoE 정규화를 위해 시퀀스 보조 손실 계수는 $`1.0 \times 10^{-4}`$, 전문가 편향 업데이트 요인도 학습 중에 $`1.0 \times 10^{-4}`$로 설정됩니다. MTP 목표에는 손실 가중치 0.05가 적용됩니다.
맥락 길이 확장
K-EXAONE은 최대 256K 토큰의 맥락 길이를 지원하도록 설계되었습니다. 이를 달성하기 위해 두 단계의 맥락 길이 확장 절차를 사용합니다. 기본 모델은 최대 8K 토큰까지 사전 학습되며, 첫 번째 단계에서는 8K에서 32K로, 두 번째 단계에서는 32K에서 256K로 확장됩니다. 두 단계 모두 동일한 고수준 데이터 혼합 구성 요소인 리허설 데이터셋, 합성 추론 데이터셋, 및 엔드-투-엔드 긴 문서 데이터셋을 유지하며, 각 단계의 표적 맥락 구역과 안정성 요구 사항에 맞게 샘플링 비율을 조정합니다.
리허설 데이터셋으로 짧은 맥락 성능 유지
긴 맥락 전문성의 주요 위험 중 하나는 짧은 맥락 성능 저하입니다. 이를 완화하기 위해 맥락 확장 시 핵심 구성 요소로 리허설 데이터셋을 포함합니다. 리허설 데이터셋은 사전 학습 분포에서 가져온 고품질 샘플과 다른 짧은 맥락 데이터를 재사용하여 더 짧은 구역에 대한 모델의 동작을 정점으로 하는 일관된 훈련 신호를 제공합니다. 리허설은 Stage 1
(8K$`\rightarrow`$32K)과
Stage 2 (32K$`\rightarrow`$256K) 모두에 포함되며, 단계별로 그 비율을 조정합니다.