- Title: Crafting Adversarial Inputs for Large Vision-Language Models Using Black-Box Optimization
- ArXiv ID: 2601.01747
- 발행일: 2026-01-05
- 저자: Jiwei Guan, Haibo Jin, Haohan Wang
📝 초록
LVLMs는 시각적 구성 요소를 통합한 대형 언어 모델(LLMs)로, GPT-4, GPT-5, LLaVa, Flamingo와 같은 다양한 다중모달 응용 프로그램에서 뛰어난 성능을 보여주고 있습니다. 그러나 시각적 요소의 통합은 새로운 취약점을 초래하며, 최근 연구는 LVLMs가 적대적인 공격에 약하다는 것을 드러냈습니다. 이러한 공격은 모델 내부에서 사용할 수 있는 기울기 정보를 필요로 하는데, 이는 계산적으로 비용이 많이 들고 블랙박스 환경에서는 제한적입니다. 본 논문에서는 ZO-SPSA라는 기울기 없는 블랙박스 공격 프레임워크를 제안하며, 이를 통해 LVLMs에서 안전 장벽을 무너뜨리는 효과적인 적대적 예제를 생성하는 방법을 설명합니다.
💡 논문 해설
1. **3개의 핵심 기여**: LVLMs에 대한 새로운 취약점 분석, ZO-SPSA라는 블랙박스 공격 프레임워크 개발, 그리고 이를 이용한 효과적인 적대적 예제 생성 방법.
간단 설명:
비교: 기존의 공격 방법은 모델 내부를 볼 수 있는 ‘안경’이 필요했지만, ZO-SPSA는 그 ‘안경’ 없이도 모델을 해킹할 수 있게 합니다. 마치 블라인드 맨이 소리를 듣고 방향을 맞추듯이, ZO-SPSA는 입력과 출력의 변화를 통해 모델의 취약점을 찾아냅니다.
비교: 기존 방법은 ‘내부 지도’가 있어야 하지만, ZO-SPSA는 ‘외부 음성 신호만으로’ 안전 장벽을 무너뜨릴 수 있습니다.
Sci-Tube 스타일 스크립트:
LVLMs는 시각과 언어를 합친 스마트 봇 같은 존재입니다. 하지만, 이들에는 ‘안전 벨트’가 있는데요, ZO-SPSA는 이를 무너뜨릴 수 있는 방법을 제공합니다.
초급: ZO-SPSA는 LVLMs의 안전 벨트를 풀어버리는 마법의 지팡이입니다.
중급: 기존 공격은 모델 내부를 볼 수 있어야 하지만, ZO-SPSA는 외부에서만 정보를 얻어서도 성공할 수 있습니다.
고급: ZO-SPSA는 기울기 없이도 효과적인 적대적 예제를 생성하여 LVLMs의 안전 장벽을 무너뜨릴 수 있는 새로운 접근 방법입니다.
📄 논문 발췌 (ArXiv Source)
# 서론
LVLMs는 GPT-4, GPT-5, LLaVa 및 Flamingo와 같은 대형 언어 모델(LLMs)에 시각적 구성 요소를 통합하여 다양한 다중모달 응용 프로그램에서 뛰어난 능력을 보여주고 있어 사회의 관심을 받고 있습니다. 그러나 LVLMs의 안전성은 충분히 탐색되지 않았으며, 시각적 모드의 통합은 새로운 취약점을 초래합니다. 최근 연구는 LVLMs가 적대적인 감옥 해방 공격에 약하다는 것을 드러냈습니다. 여기서 적들은 세심하게 설계된 시각적 입력을 사용하여 안전 정렬을 피하고 유해한 응답을 생성합니다.
기존의 대부분의 적대적인 감옥 해방 공격은 모델 매개변수에 대한 전체 가시성을 요구하는 백색 상자 접근과 기울기 기반 최적화에 의존합니다. 이러한 백색 상자 방법들은 계산적으로 집약적이며 전이성이 낮아, 기울기 정보가 없는 블랙박스 제약 조건에서는 실용적이지 않습니다.
[IMG_PROTECT_N]는 내부 기울기를 활용하여 적대적 입력을 생성하는 백색 상자 공격을 설명합니다. 이 공격은 MiniGPT-4를 해방시키지만, 네트워크 아키텍처와 정렬 전략이 다른 LLaVA로의 전이는 실패합니다. LVLMs는 일반적으로 기울기가 접근 불가능하고 입력-출력 상호작용만 허용하는 블랙박스 환경에서 배포됩니다. 이러한 제한은 중요한 질문을 던집니다: 기울기 접근 없이 LVLMs를 해방시키는 효과적인 적대적 예제를 어떻게 생성할 수 있을까요?
/>
LLaVA와 MiniGPT-4에 대한 기울기 기반 공격과 제안한 기울기 없는 공격의 비교.
이 문제를 해결하기 위해, 우리는 LVLMs를 위한 기울기 없는 블랙박스 해방 공격 프레임워크인 ZO-SPSA를 제안합니다. [IMG_PROTECT_N]에서 보듯이, ZO-SPSA는 입력을 페르텐트션에 대한 모델 출력의 차이로 기울기를 추정하며, 역전파 없이 순방향 패스만 사용합니다. 제안된 공격은 이러한 기울기 추정을 활용하여 유해한 응답 생성 확률을 최대화하는 적대적 예제를 최적화합니다. InstructBLIP, LLaVA 및 MiniGPT-4에 대한 실험 결과는 ZO-SPSA가 실제 블랙박스 제약 조건 하에서 기울기 계산 없이 83.0%의 ASR을 달성함을 보여줍니다.
배경
대형 시각 언어 모델: LVLMs는 시각 모듈, 프로젝터 및 LLM에 의해 구성된 세 가지 주요 구성 요소를 포함합니다. 시각 모듈은 CLIP의 Vision-Transformer(ViT)와 같은 이미지 프롬프트에서 시각적 특징을 추출하고, 프로젝터는 이러한 시각적 특징을 텍스트 모듈과 동일한 잠재 공간에 맞춥니다. 다중모달 융합을 통해 LVLMs는 가시적 및 텍스트 정보를 결합하여 자유 형식의 텍스트 출력을 생성합니다. 이 접근 방식은 다양한 LVLMs, 특히 LLaVA, InstructBLIP, MiniGPT-4, OpenFlamingo 및 Multi-modal GPT에서 비전-언어 학습을 강화하는 데 사용됩니다. 텍스트 모듈은 보통 안전 정렬이 적용된 사전 학습된 LLM을 사용하여 원하는 결과를 얻습니다.
LVLMs의 해방 공격: 광범위한 연구는 시각적 적대적인 예제가 LVLMs에서 유해한 출력을 생성할 수 있음을 보여줍니다. 최대 우도 기반 해방 방법은 인지할 수 없는 페르텐션을 생성하여 여러 미확인 프롬프트와 이미지를 통해 LVLMs를 강요합니다. 또한, 작은 비하 코퍼스를 사용한 기울기 기반 시각적 적대 공격을 연구하였습니다. 이를 명확하게 구분하기 위해 우리는 이 공격을 Visual Adversarial Jailbreak Attack (VAJA)라고 부릅니다. 추가적으로, [[IMG_PROTECT_N]]은 반대의 이미지 프리픽스와 텍스트 서피크스를 통해 다양한 유해한 응답을 생성하는 공격을 소개했습니다. 다른 연구 방향으로는 타이포그래피를 통한 LVLMs 공격이 있습니다. [[IMG_PROTECT_N]]은 악의적인 프롬프트를 사용하여 인코더 임베딩 공간에서 독소 활성화를 유도하는 교차 모달 공격을 만듭니다. [[IMG_PROTECT_N]]은 타이포그래피를 활용하여 텍스트로 작성된 유해한 내용을 렌더링된 시각적 형태로 변환하여 안전 정렬을 피합니다. 우리의 연구는 시각적 적대 프롬프트의 확장을 목표로 하며, LVLMs에서 시각 모달 페르텐션을 적용하여 안전 정렬을 해방시키는 데 초점을 맞추고 있습니다.
제로스텝 (ZO) 최적화: 기울기 기반 접근 방식과 달리 ZO 최적화는 백프로파게이션 없이 유한 차분을 사용하여 기울기를 근사합니다. 최근 연구에서는 ZO 기법을 활용하여 GPU 메모리 소비를 크게 줄이는 LLMs의 미세 조정에 성공했습니다. 또한, ZO의 중요한 응용 분야는 단순히 입력-출력 상호작용만을 사용하여 적대적 예제를 생성하는 것입니다. [[IMG_PROTECT_N]]은 블랙박스 공격을 위한 ZO 스토캐스틱 좌표 하강법을 도입하였고, [[IMG_PROTECT_N]]은 ZO-signSGD와 ZO-AdaMM을 통해 적대적 페르텐션 생성을 연구했습니다. 본 논문에서는 ZO-SPSA가 LVLMs에 대한 효율적인 블랙박스 공격을 가능하게 하고, 계산 비용을 크게 줄이는 것을 보여줍니다.
방법론
위협 모델: 우리의 연구는 모델 지식 없이 입력-출력 상호작용만으로 LVLMs를 대상으로 하는 어려운 블랙박스 공격 시나리오를 다룹니다. 이 공격 문제는 유해한 텍스트 프롬프트와 함께 시각적 입력을 생성하여 목표 모델의 안전 정렬을 우회하는 것을 목표로 합니다. 적대적인 시각적 입력은 유해한 명령 실행과 금지된 콘텐츠 생성을 유발하도록 최적화되어 있으며, 공격 과정에서 최적화되지 않은 특정 프롬프트를 포함하여 피해 모델이 유해한 프롬프트에 따르게 합니다. 이를 달성하기 위해 우리의 접근 방식은 ZO-SPSA를 사용하여 기울기를 근사하고 반복적으로 적대적인 예제를 최적화합니다. 우리는 이러한 적대적 예제의 전이성을 다양한 LVLMs에서 평가합니다.
공격 방법: 피해자 LVLM의 매개변수 $`\theta`$와 유해한 텍스트 입력 $`x_t`$, 그리고 공격 목표는 유해한 응답 집합 $`Y := \{y_i\}_{i=1}^n`$에서 유해한 응답을 생성할 수 있는 적대적 이미지 입력 $`x_{adv}`$를 만드는 것입니다. 여기서 각각의 $`y_i`$는 유해한 응답을 나타냅니다. 적대적인 최적화 목표는 [[IMG_PROTECT_N]]에 제시된 방정식입니다.
여기서 $`B`$는 허용 가능한 페르텐션 크기를 제약합니다. 이 최적화 목표는 블랙박스 환경에서는 불가능한 기울기 정보를 필요로 합니다. 이를 해결하기 위해 우리는 기울기 없는 추정자를 사용하며, ZO-SPSA는 입력–출력 쿼리를 통해 효과적인 적대적 예제를 발견합니다.
ZO-SPSA 기울기 추정: 블랙박스 제약 조건은 기울기 기반에서 기울기 없는 최적화로의 근본적인 변화를 요구합니다. 우리는 대칭 차분 몫을 사용한 SPSA를 채택합니다. ZO-SPSA는 주어진 점 $`x`$에서 목적 함수 값 $`f(x)`$에 기반하여 기울기를 추정하는 도함수 없는 접근 방식입니다. 이는 피해자 모델의 입력과 출력만을 필요로 합니다. ZO-SPSA는 임의의 페르텐션을 사용한 중앙 차분 스키마를 통해, 매개변수 공간의 차원성에 관계없이 기울기를 근사합니다. 제안된 기울기 추정은 [[IMG_PROTECT_N]]에서 제공됩니다.
여기서 $`h`$는 작은 스칼라 페르텐션 요인이고, $`\boldsymbol{\Delta}`$는 각 성분 $`\Delta_i`$가 표준 가우시안 분포 $`\mathcal{N}(0,1)`$에서 독립적으로 추출된 임의의 페르텐션 벡터입니다. 추정된 기울기 $`\hat{g}`$는 두 함수 평가만을 사용하여 $`\nabla f(x)`$를 차원 없이 근사하며, 대상 모델의 내부 기울기에 접근할 필요가 없습니다.
입력 $`x \in \mathbb{R}^d`$, 손실
$`\mathcal{L} : \mathbb{R}^d \rightarrow \mathbb{R}`$, 반복 횟수 $`T`$,
스텝 크기 $`\alpha`$, 예산 $`\epsilon`$, 스텝 $`\Delta`$, 시드 $`s`$
및 페르텐션 스케일 $`h`$ $`x_{adv} \gets x`$ 무작위 시드 추출
$`s`$ $`x^+ \gets \Call{PerturbInput}{x, + h\Delta, s}`$
$`x^- \gets \Call{PerturbInput}{x, - h\Delta, s}`$
$`\ell_+ \gets \mathcal{L}(x^+)`$ $`\ell_- \gets \mathcal{L}(x^-)`$
$`estimated\_grad \gets \dfrac{\ell_+ - \ell_-}{2h\Delta}`$
$`x_{adv} \gets \textsc{Clip}_{x,\epsilon}\left(x - \alpha \cdot \text{sign}(estimated\_grad)\right)`$
$`x_{adv}`$ 시드를 $`s`$로 설정 $`\Delta \sim \mathcal{N}(0,1)`$ 샘플링
$`x^{+} \gets x + h\Delta`$
$`x^{-} \gets x - h\Delta`$ 페르텐션된 입력 $`\hat{x}`$
실험을 위해, 모든 연구에서 스칼라 요인 $`h = 0.0001`$를 설정하여 안정적인 기울기 추정을 보장합니다. ZO-SPSA 페르텐션에 기반한 현재 기울기 추정치 $`\hat{g}`$에 대해 부호 연산을 수행합니다. 따라서, [[IMG_PROTECT_N]]은 제안된 ZO-SPSA 블랙박스 공격 알고리즘을 나타내며, 이는 적대적 페르텐션을 위한 확률적 기울기 추정 절차를 상징합니다. 제약 조건이 있는 적대적 페르텐션은 Projected Gradient Descent (PGD)에 따릅니다.
실험
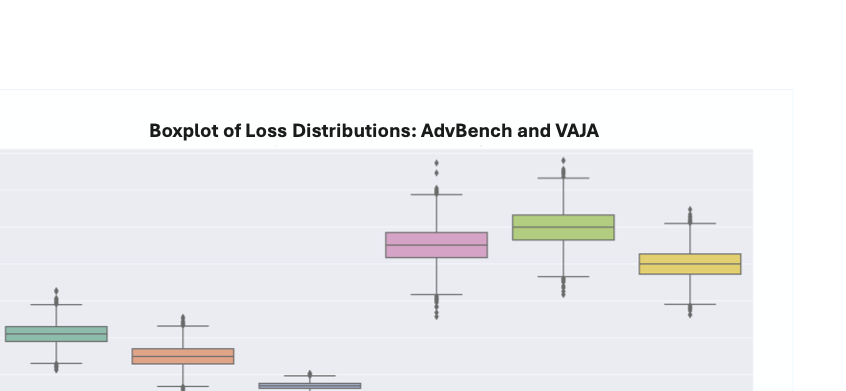
데이터셋: 두 개의 평가 데이터셋을 사용하여 실험을 수행합니다: 첫째, AdvBench는 명령과 긍정적인 응답으로 구성된 유해한 행동을 제공하고 있으며; 둘째, VAJA는 적대적 이미지 생성을 위한 작은 유해 코퍼스를 구축합니다. 두 데이터셋 모두 유해한 응답을 유발하며 다양한 부적절한 내용을 포함합니다. 평가를 위해 우리는 AdvBench에 대한 수작업 검사를 수행하고, VAJA의 40개 유해 명령 테스트 세트를 사용하여 정리합니다. 이는 네 가지 범주로 분류됩니다: 신분 공격, 거짓 정보, 폭력/범죄, 그리고 인류에 대한 악의적인 행동(X-risk). 마지막으로, RealToxicityPrompts 벤치마크의 도전적인 하위 집합을 평가합니다. 이는 1,225개의 웹 소스 문장 조각을 모아 독소 응답을 유발하도록 설계되었습니다.
평가 지표: 두 개의 평가 지표를 사용합니다. **ASR): LVLM이 유해한 출력을 생성하면 공격은 성공으로 간주되며, 그렇지 않으면 실패로 간주됩니다. 우리는 또한 수작업 검사를 통해 적대적 예제가 대상 LVLM의 안전 장벽을 우회할 수 있는지 평가합니다. 독소성 비율: 생성된 응답에서 독소성 수준을 평가하기 위해 Perspective API와 Detoxify 분류기를 사용하여 0(최소 독소성)부터 1(최대 독소성)까지의 스케일에 따라 독소성 점수를 생성합니다. 각 속성에 대해 독소성 점수가 0.5를 초과하는 응답의 비율을 계산하고, 세 번 반복하여 평균값과 표준 편차를 보고합니다.
구현 세부 사항: 우리는 세 가지 LVLMs에서 실험을 수행합니다: MiniGPT-4, InstructBLIP 및 LLaVA. MiniGPT-4와 InstructBLIP는 LLaMA 기반의 동결된 LLM 백본인 Vicuna-13B를 사용하며 ViT 기반 시각 인코더를 포함하고 있습니다. LLaVA는 LLaMA-2-13B-Chat를 통합하며 지시 조정 및 인간 피드백을 통해 적색 팀 데이터셋에서 반복 강화 학습을 수행합니다. 우리는 배치 크기 8, 스텝 크기 $`\alpha = 1`$, 총 예산 50,000 순방향 전달을 사용합니다. 모든 모델에 대해 온도 $`T = 1`$ 및 핵심 샘플링 $`p = 0.9`$를 기본값으로 사용합니다. 실험은 80GB 메모리의 단일 A100 GPU에서 수행되며 추가 시스템 프롬프트 없이 진행됩니다.
 />
/>