(본 논문은 대형 언어 모델(LLM)의 관련성 판단에서 숨겨진 편향을 진단하고 투명성을 높이기 위한 프레임워크를 제안합니다. 이 연구는 쿼리와 문서의 조합(Q-D 쌍)을 밀집 벡터로 임베딩하여 공유 의미 공간에서 클러스터링하는 방법론을 사용합니다. 이러한 접근법은 전역 통계를 넘어서, 특정 의미적 컨텍스트 내에서 인간과 LLM 사이의 판단 불일치를 분석할 수 있게 합니다.)
1. **기여물 1: 클러스터링 기반 프레임워크**
- **간단한 설명:** 쿼리와 문서의 조합을 의미 공간에 임베딩하고, 이를 클러스터링하여 유사한 의미적 컨텍스트를 그룹화합니다. 이 방식은 전역 통계보다 더 구체적인 분석이 가능하게 합니다.
- **비교적 복잡한 설명:** LLM과 인간의 판단 불일치를 진단하기 위해 쿼리-문서 쌍을 의미 공간에 임베딩하고, 이를 클러스터링하여 유사한 의미 컨텍스트 내에서 분석합니다.
- **복잡한 설명:** 본 논문에서는 LLM의 판단과 인간의 판단이 일치하지 않는 위치를 특정화하기 위해 쿼리와 문서의 조합을 임베딩하고, 이를 클러스터링하여 유사 의미 컨텍스트 내에서 분석하는 방법론을 제안합니다.
# 서론
대형 언어 모델(LLM)은 정보 검색(IR) 평가의 자동 판정자로 점점 더 많이 사용되고 있습니다. 최근 연구는 LLM이 종종 인간 관련성 레이블과 일치하지만, 특정 불일치가 남아 있음을 보여주고 있습니다. IR 시스템의 평가는 오랫동안 관련성 판단에 의존해 왔습니다. 이러한 판단은 쿼리에 대해 문서가 얼마나 유용한지 결정하는 것에 관한 것입니다. 이 판단들은 핵심적입니다. 그 이유는 검색 시스템이 어떻게 순위를 매기고 평가되는지를 결정하기 때문입니다. 예를 들어, 표준 TREC 트랙은 수 주간 전문 평가자가 풀타임으로 참여해야 합니다. 비용 외에도 인간 판단은 변동성이 있고, 순서에 따라 달라지며, 평가자 간 일관성도 떨어집니다. 이러한 문제들을 해결하기 위해 연구자들은 자연 언어 프롬프트에 대해 유창한 텍스트를 생성하는 LLM이 자동화된 판정자로 사용될 수 있는지를 탐구하고 있습니다. LLM은 이미 TREC 컬렉션과 상업적 검색 결과에서 관련성을 예측하는데 사용되어 인간 판정자(대중 작업자 포함)보다 훨씬 높은 처리량을 제공하고 주석 비용이 낮아졌습니다. 중요한 점은 여러 연구가 LLM 기반 판단이 완벽하지 않음에도 불구하고, 종종 시스템 수준 평가에 충분한 일관성을 보여준다는 것입니다. 또한, LLM은 컨텍스트 전환에 덜 영향을 받으며 다양한 평가 조건에서 더 일관된 결정을 내립니다. 게다가, LLM은 IR 시스템의 자동화된 평가를 대폭 강화하여 인간 주석 품질에 가까운 관련성 레이블을 제공합니다.
그러나 이러한 장점에도 불구하고 LLM 기반 판단은 여전히 편향, 신뢰성 취약성 및 미묘한 인간 판단과의 불일치를 겪을 수 있습니다. 예를 들어 Alaofi 등은 쿼리 항목이 후보 패스에 나타나는 경우 특히 거짓 긍정을 일으키며 표면적 어휘 중첩에 과도하게 의존하는 경향이 있다는 것을 발견했습니다. Zhuang 등의 연구에서는 부분적으로 관련된 문서들에 대해 이진 “예스/노” 프롬프트가 노이즈 또는 편향된 출력을 생성할 수 있음을 경고합니다. Rahmani 등은 LLM로 구성된 인공 시험 컬렉션이 체계적인 편향을 도입하고 이를 하류 평가 결과에 전파시킬 가능성이 있다는 것을 보여주었습니다. Faggioli 등이 강조한 것처럼, IR에서의 평가는 궁극적으로 신뢰성과 안정성을 유지하기 위해 인간 판단에 근거해야 하지만, LLM 판단이 전문 주석자와 얼마나 일치하는지에 대한 지속적인 논쟁이 계속되고 있습니다. 이러한 연구들은 LLM의 신뢰성을 이해하는데 중요한 통찰력을 제공하지만, 기존 연구는 이러한 편향이 존재하는지 검출하는 데 초점을 맞추고 있으며, 그들이 실제로 어디에서 발생하는지를 특정화하는 것은 여전히 미결 문제입니다.
본 논문은 LLM 관련성 판단의 숨겨진 편향을 진단하고 투명성을 높이며 신뢰성을 강화하기 위한 목표를 가지고 있습니다. 쿼리-문서(Q-D) 쌍을 밀집 벡터로 임베딩하여 공유 의미 공간에 삽입하며, 관련성은 별도의 쿼리 및 문서 임베딩이 아닌 관계적 특성을 가지도록 합니다. 이러한 임베딩 공간을 클러스터링하면 의미적으로 유사한 Q-D 쌍들이 분석 가능한 일관된 이웃으로 그룹화됩니다. 이러한 클러스터링 기반의 합의 분석은 전역 합의 통계보다 풍부한 통찰력을 제공하며, 인간과 LLM 주석자가 체계적으로 불일치하는 위치를 탐지할 수 있습니다. 구체적으로 다음과 같은 연구 질문을 추구합니다:
- 쿼리-문서 임베딩이 인간-LLM 관련성 상호작용을 어느 정도 포착하는가?
- LLM 관련성 판단은 어디에서, 왜 인간 판단과 체계적으로 불일치하게 되는가?
우리의 기여는 다음과 같습니다:
- 클러스터링 기반 프레임워크를 제안하여 Q-D 쌍을 공유 의미 공간에 임베딩하고 전역 통계를 넘어 로컬, 컨텍스트 인식 진단을 수행합니다.
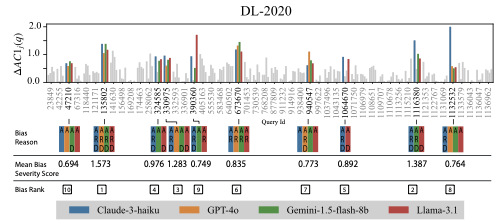
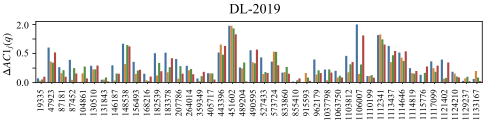
- IR 평가에서 Gwet의 AC1을 합의 측정으로 사용합니다. 이는 Cohen의 $`\kappa`$와 같은 널리 사용되는 측정 방법의 한계를 해결하고 라벨 불균형 하에서 더 안정적인 추정을 제공하며, 세밀한 클러스터 수준 합의 분석을 가능하게 합니다.
- 클러스터 기반 합의 변화량을 제안하여 동일 쿼리에 대한 LLM-인간 합의가 다양한 의미적 이웃에서 어떻게 달라지는지 측정합니다. 이를 통해 체계적인 불일치를 특정화하고 임베딩 공간 내 안정적이지 않은 영역을 식별하며 편향이 특히 발생하기 쉬운 쿼리를 진단할 수 있습니다.
관련 연구
더 큰 연구 경로는 LLM-판정자 파이프라인의 유효성과 제한점을 점점 더 탐구하고 있습니다. 벤치마킹 연구는 신중하게 프롬프트를 제공하면 LLM이 사용자의 선호도를 추정할 수 있음을 보여주었습니다. 그러나 다른 작업은 과도한 의존 위험에 대해 우려하며 편향, 제한된 투명성 및 엄격한 방법론의 필요성을 지적합니다. 동시에 조사와 입장 논문들은 LLM을 평가자로 사용할 때 편향 강화, 재현 가능성 문제 및 방법론 일관성 부족에 대한 위험을 경고합니다. 실증적인 오류 분석은 또한 LLM 판단의 약점을 드러냈습니다. Alaofi 등은 모델이 어휘 중첩과 적대적 쿼리에 현혹되며 과도한 추론을 하며, LLM들은 관련성을 과도하게 예측하는 경향이 있지만 비관련성 레이블은 보다 신중하고 신뢰할 수 있음을 관찰했습니다. 비교 연구는 LLM 판정자들이 종종 인간 판정자보다 서로 더 일치함을 발견했습니다. TREC 2024 RAG 트랙에서 Upadhyay 등은 자동화된 판단이 인간 레이블을 대체할 수 있다고 주장했으나, 이 주장을 곧 대립하는 의견들이 제기되었습니다. Clarke와 Dietz는 순환성과 조작의 위험성을 강조한 반면, Balog 등은 LLM 판정자가 다른 LLM들에 의해 생성된 실행 결과를 선호하는 경향이 있음을 경험적으로 증명했습니다.
이러한 발견들은 단순히 얼마나 많은 불일치가 발생하는지뿐만 아니라 쿼리와 문서의 의미 공간에서 어디서, 왜 불일치가 발생하는지를 이해할 필요성을 강조합니다. 이전 벤치마킹 노력들은 다양한 판단을 평균화하는 매크로 수준 통계에 집중하여 어떻게 불일치가 구성되고 어디에서 시작되는지에 대한 질문을 남겨두었습니다.
최근 연구는 합성 평가의 편향과 유효성을 진단하는데 초점을 맞추고 있습니다. Rahmani 등은 합성 쿼리가 인간 쿼리와 스타일 및 길이에서 차이를 보이며 GPT-4 판단이 체계적으로 관대해 절대 성능 스코어를 부풀리지만 상대적 순위는 비교적 안정적임을 보여주었습니다. Arbabi 등은 상대 편향 프레임워크를 도입하여 임베딩 분석과 LLM-판정자 평가를 결합해 주제별 하위 공간에서 과적과 부족 레이블링 경향을 측정합니다. 이러한 연구들은 편향이 무작위보다 구조화되고 컨텍스트에 따라 달라짐을 보여줍니다. 이 발견들은 단순히 얼마나 많은 불일치가 발생하는지뿐만 아니라 어디서, 왜 발생하는지를 이해하는 것이 중요함을 강조하며, 이러한 질문은 전역 IR 평가 지표로는 충분히 다루기 어렵습니다.
IR 평가에서 합의 신뢰성이 중요합니다. 시스템 효과성은 관련성 판단의 신뢰성에 의존하기 때문입니다. Cohen의 $`\kappa`$는 주요 측정 수단이었지만 라벨 불균형 상황에서 불안정하며, 이를 “카파 역설"이라고 부릅니다. 불균형 데이터셋에서는 $`\kappa`$가 평가자들이 크게 일치하더라도 그 중 대부분의 합의를 우연으로 할인하는 경우가 많아 합의를 과소평가할 수 있습니다. IR 외에도 Vidgen 등은 Gwet의 AC1을 혐오 발언 주석에 적용하여 불균형 라벨에서도 견고함을 보여주었습니다. Haley 등은 AC1이 IR 맥락에서 적합한 대안임을 강조했지만, 아직 널리 채택되지 않았습니다. 이는 AC1의 우수성을 인식하고 있지만, IR 평가에 체계적으로 사용하는 것은 여전히 탐구 중입니다.
고전적인 IR 연구는 관련성이 본질적으로 주관적이라는 것을 확립했습니다. 이 주관성은 의도, 작업 및 애매함에 의해 형성됩니다. 이러한 주관성을 바탕으로 관련성을 쿼리만 혹은 문서만의 속성이 아닌 쿼리-문서 쌍의 관계적 속성으로 보는 것이 적절합니다. 최근 연구는 단순히 LLM과 인간 사이에 얼마나 많은 불일치가 있는지를 밝혀내는 것뿐만 아니라, 그것이 어디에서, 왜 발생하는지 분석하기 위한 의미론적으로 기반한 방법이 필요함을 강조하고 있습니다. 우리의 연구는 레이블 수준 비교를 넘어 임베딩 기반 접근법으로 의미 공간 내에서 불일치를 특정화하는 방향으로 이 연구를 발전시킵니다. 공동 Q-D 임베딩 공간의 이웃 분석, 클러스터 수준 합의 안정성 검토 및 편향 패턴 식별을 통해 코퍼스 수준 평균이 숨기는 불일치의 잠재적 구조를 드러냅니다.
방법론 및 실험 설정
본 논문은 쿼리-문서(Q-D) 쌍의 의미 클러스터링을 통해 관련성 판단을 분석하는 방법론과 설정을 제시합니다. [^1]
데이터셋
TREC Deep Learning 2019 (DL-2019), TREC Deep Learning 2020 (DL-2020) 벤치마크 데이터셋, MS MARCO 패스 컬렉션에 기반한 LLM 관련성 판단을 평가합니다. Fröbe 등이 보고한 것처럼 Claude-3-haiku, Gemini-1.5-flash-8b, GPT-4o 및 Llama-3.1을 대표적인 LLM 판정자로 선택했습니다. 이 모델들은 일관되게 높은 합의도, 유사성 및 순위 성능을 보여주었습니다.
Table 1은 데이터셋 특성을 요약합니다. 우리의 실험은 이진 관련성 설정에 기반하며, TREC 권장 사항과 프로토콜에 따라 점수 2와 3을 관련(1)으로 매핑하고, 점수 0과 1을 비관련(0)으로 매핑합니다.
| 데이터셋 이름 |
쿼리 |
문서 |
관련성 판단 |
관련됨(%) |
비관련됨(%) |
| DL-2019 |
43 |
9,139 |
9,260 |
27.0 |
73.0 |
| DL-2020 |
54 |
11,224 |
11,386 |
15.0 |
85.0 |
TREC 데이터셋 특성
Q-D 쌍 임베딩
임베딩 목적으로 INSTRUCTOR를 사용합니다. 이는 자연 언어 지시문을 조건으로 하는 작업에 대한 임베딩을 생성하도록 미세 조정된 인코더입니다. INSTRUCTOR는 지정된 작업에 따라 의미상 유사한 입력을 가깝게 위치시키고 관련 없는 것을 멀리 떨어뜨립니다. 이 설계는 신중하게 선택된 작업 지시문과 함께 IR 및 관련성 평가에서 특히 적합합니다. 이 연구에서는 인간과 LLM의 관련성 판단 간 합의를 분석하는 데 INSTRUCTOR 임베딩을 처음 사용했습니다.
INSTRUCTOR는 임베딩이 다양한 지시문에 맞게 조정될 수 있습니다. 우리는 이진 분류, 판단 중심 작업, 의미적 유사성 및 검색 중심 주제를 포함한 19가지 대안 표현을 체계적으로 탐색했습니다. 각 지시문 변형은 HDBSCAN으로 클러스터링된 임베딩 세트를 생성했습니다. 중요한 점은 합의 측정이 의미 표현에 적용되었으며 관련성 레이블에는 적용되지 않았다는 것입니다. 이진화된 인간 레이블은 클러스터링 후에만 부착되어 각 이웃 내에서 판단 분포를 평가합니다. 임베딩 품질을 측정하기 위해, 우리는 관련성과 비관련성을 주도하는 클러스터의 순수도와 그 순수도 히스토그램을 검사했습니다. 교차 지시문 비교에서 80분위 순수도를 견고한 기준으로 사용하여 최소 80% 이상의 클러스터가 달성하는 순수도 수준을 나타냈습니다. 예를 들어, *“쿼리에 대한 문서의 관련성을 판단하라”*라는 지시문과 INSTRUCTOR-XL을 사용할 때 비관련성 클러스터에서 $`\approx0.70`$, 관련성 클러스터에서는 $`\approx0.61`$의 순수도를 달성했습니다. 이 지시문은 대안보다 인간 판단에 대해 더 강력하고 안정적인 정합성을 보여주었기 때문에 INSTRUCTOR-XL과 함께 모든 하류 분석을 위한 임베딩 구성으로 선택되었습니다.
이 선택을 검증하기 위해 다른 모델도 테스트했습니다. E5-Large-v2는 비대칭 검색에서 효과적이지만, 우리의 분석은 공유 Q-D 임베딩을 필요로 합니다. Qwen3-Embedding-8B은 강력한 벤치마크 성능에도 불구하고 일관성 있는 클러스터를 생성하지 못하고 다수 레이블 정합성이 약했습니다. 이러한 결과는 INSTRUCTOR-XL과 선택된 지시문을 우리의 연구에서 가장 안정적이고 효과적인 구성으로 확인하였습니다.
클러스터링
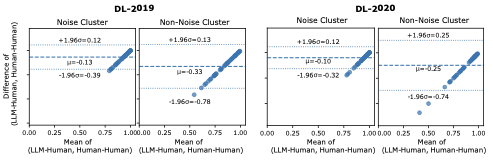
임베딩 단계 후, Q-D 쌍을 HDBSCAN로 클러스터링합니다. 이는 공유 의미 공간의 밀집한 영역을 식별하고 구형이나 균일한 형태를 가정하지 않습니다. 이는 의미적으로 다양하고 불균형하게 분포된 Q-D 임베딩에 잘 맞습니다. 중요한 점은 HDBSCAN이 일부 포인트를 노이즈 클러스터($`C_{-1}`$)로 할당하여 의미적으로 모호하거나 밀집한 이웃과 연결되지 않은 Q-D 쌍을 포착한다는 것입니다. 이러한 경우는 인간과 LLM 판단이 가장 불일치할 가능성이 높은 편향적 또는 불안정 영역을 탐지하는 유용한 신호를 제공합니다.
Figure 1은 Q-D 쌍의 클러스터링 예제를 보여줍니다. 각 색상 그룹($`C_{1}`$, $`C_{2}`$, $`C_{3}`$)은 밀집한 의미 이웃을 나타내고, 회색 점($`C_{-1}`$)은 노이즈 할당을 나타냅니다. 교차 표시는 쿼리 $`q_{1}`$의 예시 Q-D 쌍들을 표시하며, 관련 문서에 따라 다른 클러스터로 분류됩니다. 예를 들어, $`\langle q_{1}, D_{1} \rangle`$와 $`\langle q_{1}, D_{3} \rangle`$는 서로 다른 클러스터에 위치하여 그들의 의미적 정합성이 다르다는 것을 반영합니다. 이는 하나의 쿼리의 문서를 일관된 하위 집합으로 분리하는 방법을 보여줍니다. 특히, 동일한 문서가 다른 쿼리와 함께 다른 클러스터에 나타날 수 있음을 의미하며, Q-D 임베딩은 문서 내용보다 의미적 컨텍스트를 포착합니다. 클러스터링 후에 이진화된 인간과 LLM 관련성 레이블을 클러스터 구성원에게 부착하여 전역 및 로컬 합의 패턴을 평가할 수 있습니다.