- Title: A New Benchmark for the Appropriate Evaluation of RTL Code Optimization
- ArXiv ID: 2601.01765
- 발행일: 2026-01-05
- 저자: Yao Lu, Shang Liu, Hangan Zhou, Wenji Fang, Qijun Zhang, Zhiyao Xie
📝 초록
최근에는 대형 언어 모델(LLM)이 반도체 회로 설계의 유연한 디자인에 있어 흥미로운 연구 방향으로 부상하고 있습니다. 특히, 많은 최근 작업들은 직접적으로 레지스터-트랜스퍼 레벨(RTL) 코드 형태로 반도체 회로 설계를 생성하기 위한 맞춤형 LLM을 개발하고 있습니다. 그러나 RTL 코드 최적화에 대한 기존 벤치마크는RTL 코드의 정확성에만 초점을 맞추고 있어, 전력, 성능, 면적(PPA) 측면에서의 실제 회로 설계 품질을 평가하지 않습니다. 이 문제를 해결하기 위해 새로운 벤치마크인 RTL-OPT를 제안합니다.RTL-OPT는 실용적인 최적화 패턴을 제공하며, 다양한 합성 설정에 대해 효과적으로 작동하도록 설계되었습니다.
💡 논문 해설
1. **새로운 벤치마크 제안:** 기존 벤치마크가 인위적인 문제를 중심으로RTL 코드의 최적화를 평가하는 데 한계가 있다면, RTL-OPT는 실제 회로 설계에서 발생할 수 있는 다양한 최적화 패턴을 제공합니다. 이를 통해 LLM들이 실제RTL 코드를 어떻게 개선하는지 더 정확하게 평가할 수 있습니다.
2. **합성 공정의 영향:** 합성 도구와 모드, 시계 주기 제약 조건 등이RTL 코드의 최종 PPA에 큰 영향을 미칩니다. 이를 고려하여 RTL-OPT는 여러 합성 설정에서 LLM의 성능을 평가할 수 있도록 설계되었습니다.
3. **실제 개선 확인:** 기존 벤치마크에서는 인위적인 문제로 인해RTL 코드의 실제 최적화를 정확히 평가하기 어렵습니다. 그러나 RTL-OPT는 실제 회로 설계에서 발생하는 문제를 반영하여, LLM이RTL 코드를 실제로 얼마나 잘 개선할 수 있는지 확인합니다.
📄 논문 발췌 (ArXiv Source)
# 서론
최근 몇 년 동안 대형 언어 모델(LLM)이 반도체 회로 설계의 유연한 디자인에 있어 흥미로운 연구 방향으로 부상하고 있습니다. 특히, 많은 최근 작업들은 직접적으로 레지스터-트랜스퍼 레벨(RTL) 코드 형태로 반도체 회로 설계를 생성하기 위한 맞춤형 LLM을 개발하고 있습니다.
RTL 코드 생성 평가: RTL 디자인은 디지털 회로 설계 구현의 출발점이며, 인간의 많은 노력과 전문성이 필요합니다. LLM 지원 RTL 코드 생성 기법은 엔지니어들을 반복적인 RTL 코딩 과정에서 해방시키는 것을 목표로 합니다. 다양한 LLM들의 RTL 생성 능력을 공평하게 비교하기 위해 고품질 벤치마크가 필요합니다. 대표적인RTL 코드 생성 벤치마크에는 VerilogEval, RTLLM, VerilogEval v2, RTLLM 2.0, CVDP 등이 있습니다.
RTL 최적화 평가의 어려움: 그러나 위에 언급된 벤치마크들은 주로 RTL 코드 생성의 정확성에 초점을 맞추고 있으며, 전력, 성능 및 면적(PPA) 측면에서 회로 설계의 궁극적인 품질 최적화를 명시적으로 평가하지 않습니다. RTL 코드는 합성 도구를 통해 궁극적인 회로 구현으로 변환되며, 이 과정에서RTL 코드를 구현으로 변환할 때 광범위한 논리 최적화가 이루어집니다. 따라서 PPA 결과는RTL 코드의 품질과 하류 합성 프로세스에 모두 의존합니다. 본 논문에서는 이 긴밀한 상호작용이 RTL 최적화를 벤치마킹하는 것이 특히 어렵게 만든다는 것을 지적할 것입니다.
/>
기존 벤치마크에서의 과도하게 인위적인 비최적화와 최적화된 RTL 코드 쌍의 예.
/>
우리가 제안한 벤치마크 RTL-OPT에서의 비최적화와 최적화된 RTL 코드 예, 실제 최적화 기회를 반영합니다.기존RTL 최적화 작업과 우리가 제안한 벤치마크의 예제 비교. 비최적화 설계는 LLM이 개선하기 위한 입력이며 최적화된 설계는 금형 참조입니다.
RTL 코드 최적화 평가: RTL 최적화를 위한 고품질 벤치마크 생성은 오픈 소스 회로 설계의 극심한 부족으로 인해 본질적으로 어려운 작업입니다. 이는 반도체 기업들에게 귀중한 IP입니다. 최근 몇몇 LLM 작업들은 더 최적화된 RTL 코드 생성을 목표로 하며, 이는 궁극적인 칩 품질의 PPA 측면에서 더 나은 결과를 가져올 것으로 예상됩니다. 이러한 작업들은 기존 벤치마크에 평가되지만, 우리의 연구는 이 벤치마크가 여러 면에서 부족하다고 지적합니다: 1) 현실적이지 않은 설계: 이 벤치마크의 많은 비최적화 RTL 코드들이 인위적인 변형을 기반으로 하여 실제 실용에서는 나타나지 않는 불필요한 비효율성을 반영하지 못함; 2) 간소화된 합성 설정: Yosys와 같은 약한 합성 도구에 의존하여 표면적RTL 코드 변화에 민감하고 산업 수준의 흐름과 잘 맞지 않음; 3) 부족한 평가: 면적 관련 지표만을 중점적으로 평가하며 전력 및 타이밍은 무시함. 이는 일반적인 회로 설계 과정에서 보편적으로 나타나는 상호 교환관계를 간과합니다.
본 논문에서는RTL 최적화에 대한 기존 작업들을 검토하고 핵심 질문을 재고합니다: RTL 코드의 최적화를 어떻게 적절하게 평가할까? 기존 작업들과 하류 합성 흐름을 신중히 검토했습니다. 이 연구는 RTL 최적화를 평가하는 것이 쉽지 않으며, 잘못된 결론에 쉽게 이르게 될 수 있음을 드러냈습니다. 특히RTL 코드 중 하나가 우수한지 여부(즉, 더 최적화되었는지)는 합성 도구와 설정에 크게 의존합니다. 기존 작업에서 나타난 “최적화된"RTL 코드들이 종종 다른, 보통은 더욱 고급 합성 옵션을 사용할 때 “비최적화"RTL 코드보다 동일하거나 더 나쁘게 나타납니다.
그림 1은 설계의 일반적인 문제점인 인위적인 변환 기반의 RTL 쌍을 강조합니다. 이러한 인위적인 비효율성 예시는 실제RTL 코딩에서 드물게 발생하는 불필요한 계산 및 초과 산술 연산 등을 포함하며, 합성 도구들이 쉽게 이들을 최적화할 수 있어 LLM이RTL 품질을 개선하는 효과를 과대평가할 가능성이 있습니다. 최적화된 버전(example1_opt)은 s1 = a + b로 논리를 직접 구현하고 이를 기반으로 s2 = s1 * 2를 도출합니다. 반면 비최적화 버전(example1)은 불필요한 단계를 추가하여 먼저 s1 = a + b, 그 다음에 0을 더하고 1로 곱하는 중간 와이어 t1과 t2를 생성한 후 이를 합쳐 s2를 만듭니다. 이러한 구조는 자연스럽지 않고 실용적인RTL 코딩에서는 거의 나타나지 않으므로 벤치마크 예제가 현실적이지 않습니다. 그림 2는 RTL-OPT의 예시를 보여주며, 자세한 분석은 Section 3.2에 있습니다.
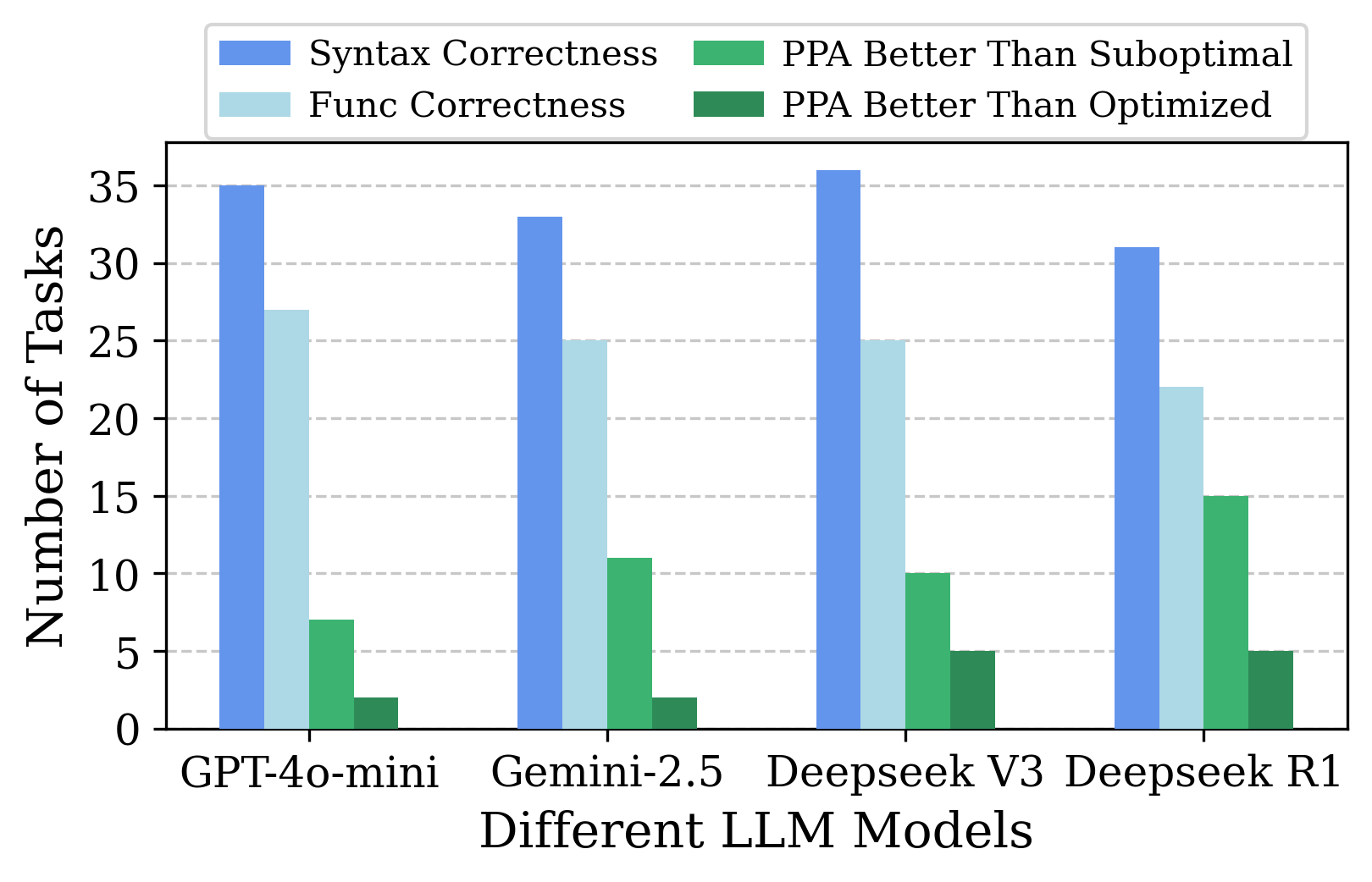
우리가 관찰한 바에 따라, 새로운 벤치마크 RTL-OPT를 제안합니다. 이는 LLM이RTL 설계 최적화 능력을 체계적으로 평가할 수 있도록 특별히 설계되었습니다. RTL-OPT는 36개의 수작으로 작성된RTL 최적화 작업을 포함하며, PPA 품질을 목표로 합니다. 주요 차별점은 다양하고 현실적인 최적화 패턴을 제공하는 것입니다. 비트 폭 최적화, 사전 계산 및 LUT 변환, 연산자 강도 감소, 제어 단순화, 리소스 공유, 상태 인코딩 최적화 등을 포함하며 모두 입증된 산업 관행에서 파생되었습니다. 이러한 패턴은RTL 최적화에 실제로 중요한 변형을 포착하고 있으며 고급 합성에서도 효과적입니다. 이는 기존 작업들이 종종 실제 최적화 영향을 부족하게 갖는 것과 구별됩니다. 그림 4와 같이 각 RTL-OPT 작업에는RTL 코드 쌍이 제공되며, 하나는 의도적으로 비최적화된 버전(최적화 필요)이고 다른 하나는 금형 참조로 최적화된 버전입니다. LLM들은 비최적화 코드를 입력으로 받아 기능성을 유지하면서 더 최적화된RTL 코드를 생성하려고 합니다. 구체적으로, RTL-OPT는: 실제 설계 도전 과제를 포괄하고 대표적으로 커버하는 36개의 수작 작업을 제공하며, 기능 정확성 확인 및 LLM-최적화 설계와 디자이너 최적화 금형 참조 간의 궁극적인 PPA 비교를 자동으로 수행하는 통합 평가 프레임워크(Figure 4)를 제공합니다.
RTL 코드 최적화 재고
본 절에서는RTL 코드 최적화에 대한 기존 벤치마크와 제안한 RTL-OPT 벤치마크를 여러 합성 설정을 통해 종합적으로 검토합니다. 이를 통해 일반적인 벤치마크들이 인위적인 설계 예시에만 의존하는 한계점을 드러냅니다.
합성 공정의 영향
우리 연구 결과,RTL 최적화 평가(즉, 어떤RTL 코드가 더 나은 PPA를 가져오는지 판단)는 간단한 작업이 아님을 지적합니다. 주요 이유 중 하나는 최종 설계 품질도 합성 프로세스에 따라 달라진다는 점입니다. 합성 도구, 최적화 모드, 및 타이밍 제약 조건의 차이가RTL 코드의 구조적 차이를 최종 구현에서 어떻게 반영하는지 크게 영향을 미칩니다.
합성 도구의 효과: 다양한 도구는 각각 다른 최적화 전략과 휴리스틱을 채택합니다. Synopsys Design Compiler(DC)와 같은 상업용 도구는 보통 더 적극적이고 고급 최적화를 수행하는 반면, Yosys와 같은 오픈 소스 도구는 학술 연구에서 가치 있는 대안을 제공하지만 약한 옵션입니다. 따라서 동일한RTL 코드 쌍은 사용되는 합성 도구에 따라 다른 수준의 품질 차이를 나타낼 수 있습니다.
컴파일 모드의 효과: 상업용 도구는 최적화 적극성이 서로 다른 여러 컴파일 모드를 지원합니다. 더 고급 모드(예: DC의 compile_ultra)는 논리를 적극적으로 재구조화하므로 미세한RTL 차이점을 희석시킬 수 있습니다.
시계 주기 제약 조건의 효과: 목표 시계 주기도 합성 동작을 형성합니다. 긴밀한 제약 조건은 적극적인 타이밍 기반 최적화를 유도하는 반면, 완화된 제약 조건은RTL 변종 간의 차별성을 줄일 수 있습니다. 현실적이고 일관된 타이밍 목표를 선택하여RTL 코드 평가가 공정하고 해석 가능하게 하는 것이 중요합니다.
기존 벤치마크 검토
기존 벤치마크는 여러 쌍의 비최적화와 인간 최적화 RTL 설계를 제공하며, 추가적으로 그들의 LLM 기반 최적화 실험으로 생성된RTL 코드도 포함합니다. 그러나 우리의 연구 결과는 다음과 같습니다: 1) 합성 후에 인간 최적화RTL 설계와 LLM 최적화RTL 설계가 종종 대응하는 비최적화대조군을 능가하지 못하며, 많은 경우 거의 동일하거나 더 나쁘며 특히 고급 합성 옵션을 적용할 때 더욱 그렇습니다. 2) 다양한 합성 도구에 대한 최종 PPA의 명확히 다른 영향: 강력한 최적화 기능을 가진 상업용 도구 DC는 비최적화와 최적화RTL 사이의 차이를 제거하는 반면 오픈 소스 Yosys는 이를 부각시킵니다. 이러한 결과들은 기존 벤치마크가 실제RTL 코드 개선을 정확하게 반영하지 못함을 시사합니다.
기존 벤치마크의 평가 결과는 표 [tab:measure1]과 [tab:measure2]에 나와 있습니다. 우리는 전체 벤치마크에서 43개 쌍의RTL 코드를 신중히 검토하고 평가했습니다. 특히, 표 [tab:measure1]은 각 비최적화와 인간 최적화 설계 쌍을 비교하며 합성 후에 인간 최적화 참조가 실제로 더 나은지, 더 나쁘거나 같은지를 평가합니다. 또한 PPA 비교에서 “교환” 결과가 있을 수 있습니다: 한 PPA 지표에서는 개선이 있지만 다른 지표에서는 저하됨을 나타냅니다. Yosys의 경우, 이전 작업과 마찬가지로 셀 수만을 비교합니다. 표 [tab:measure1]에 따르면 compile_ultra를 사용할 때 43개 중 13개의 인간 최적화RTL이 그들의 비최적화대조군보다 나았습니다. 이 숫자는 compile을 사용할 때 16으로 증가하고 Yosys에서는 24로 더 증가합니다. 많은 인간 최적화RTL은 특히 고급 합성 옵션에서 비최적화RTL보다 나아지지 않았습니다. 이는 상업용 도구가 인위적인 비효율성을 제거할 수 있는 반면 오픈 소스 도구는 이를 유지함을 강조하며 명확한 차이를 보여줍니다.
우리는 더 긴밀한 타이밍 목표(clock period = 0.1ns)로 다양한 시계 제약 조건하에서 평가를 확장했습니다. 이에 대한 결과는 표 [tab:measure1]의 회색 항목에 나와 있습니다. 동일한 합성 모드(compile 또는 compile_ultra)를 사용할 때 더 긴밀한 타이밍 제약 조건은 PPA 교환을 나타내는 경우가 약간 증가하고 실제로 나은RTL 코드의 수가 줄어듭니다.
표 [tab:measure2]에서는 LLM 최적화 설계와 이전 작업에서 직접 공개된 비최적화 설계를 추가로 비교합니다. 표 [tab:measure2]에 따르면 GPT-4.0과 제안한 모델 모두 compile_ultra를 사용할 때 12개 중 3개의 LLM 최적화RTL이 그들의 비최적화대조군보다 나았습니다. compile을 사용할 때는 5개가 나아졌습니다. 요약하면, 많은 LLM 최적화RTL은 특히 고급 합성 옵션에서 비최적화RTL보다 나아지지 않았습니다. 이는 엄격한 합성 프로세스 하에서는 벤치마크가 제한적인 효과를 보여준다는 것을 나타냅니다.
우리의 벤치마크 검토
표 [tab:measure1]에서 우리는 동일한 설정을 사용하여 제안된 벤치마크 RTL-OPT도 평가했습니다. 표 [tab:measure1]에 따르면RTL-OPT의 36개 중 35개의 인간 최적화RTL 코드는 compile_ultra를 채택할 때 나았으며, Yosys에서는 36개 중 33개가 나았습니다. 표 [tab:measure1]에서 더 긴밀한 타이밍 제약 조건을 사용할 경우 23개 사례는 여전히 나아졌고 13개는 PPA 교환 결과를 나타냈으며, 어떤 경우도 궁극적인 PPA가 동일한 것은 없었습니다. 기존 벤치마크와 비교했을 때 RTL-OPT는RTL 설계 평가에서 현저한 향상을 보였습니다.
이RTL-OPT의 명확한 검증은 그 설계 철학에서 비롯됩니다: 실제 비최적화RTL 구현을 제공하여 의미 있는 개선 여지를 갖추고 인위적인 불필요한 부족함이 합성 도구에 의해 제거되는 것이 아니라 실제RTL 코드를 최적화하는 데 필요한 진정한 곤란함을 반영합니다.
RTL-OPT 벤치마크
본 절에서는 LLM의RTL 코드 최적화 평가를 위한 벤치마크인 RTL-OPT를 제시합니다. RTL-OPT는 전문가들에 의해 수작으로 작성된 실제 비최적화 및 최적화RTL 쌍을 제공하며, 진정한 부족함과 의미 있는 금형 참조를 보장합니다. 다양한 설계 유형을 포괄하고 상업용 및 오픈 소스 도구 모두로 평가되어RTL 최적화를 진전시키는 견고하고 실용적인 자원을 제공합니다.