- Title: ARIES A Scalable Multi-Agent Orchestration Framework for Real-Time Epidemiological Surveillance and Outbreak Monitoring
- ArXiv ID: 2601.01831
- 발행일: 2026-01-05
- 저자: Aniket Wattamwar, Sampson Akwafuo
📝 초록
세계 건강 감시는 현재 지식 격차라는 도전에 직면해 있습니다. 일반적인 목적으로 사용되는 인공지능이 확산되었지만, 만성적 환영 현상과 전문 데이터 시ilos를 탐색하는 능력 부족으로 인해 여전히 고스테이크 역학 분야에는 적합하지 않습니다. 본 논문은 ARIES(Agentic Retrieval Intelligence for Epidemiological Surveillance)라는 특화된 자율적 다중 에이전트 프레임워크를 소개합니다. 이 프레임워크는 정적인 질병별 대시보드에서 벗어나 동적인 지능 생태계로 나아가도록 설계되었습니다. 계층형 명령 구조 위에 작성된 ARIES는 GPTs를 활용해 WHO(World Health Organization), CDC(Center for Disease Control and Prevention) 및 피어 리뷰 연구 논문을 자동으로 조회할 수 있는 확장 가능한 서브 에이전트 스와rm을 조정합니다. 감시 데이터의 추출과 논리적 종합을 자동화함으로써 ARIES는 신흥 위협과 신호 발산을 실시간에 가깝게 식별하는 특화된 사고를 제공합니다. 이 모듈형 아키텍처는 특정 작업을 수행하는 에이전트 스와rm이 일반적인 모델보다 우수하다는 것을 입증하며, 다음 세대의 발생 대응 및 글로벌 건강 지능에 강력하고 확장 가능한 솔루션을 제공합니다.
💡 논문 해설
1. **다중 에이전트 시스템의 활용:** ARIES는 복잡한 데이터 소스를 관리하는 데 있어 다중 에이전트 아키텍처를 사용합니다. 이 시스템은 각각 특정 도메인에 맞게 구성된 에이전트들이 정보를 수집하고 분석하여 최종 결과를 생성합니다. 이를 통해, 여러 출처에서 얻어진 데이터를 통합하고 종합적인 결과를 제공할 수 있습니다. 이는 마치 여러 전문가들이 함께 일하는 것과 같습니다.
LLM의 활용 및 최적화: ARIES는 대형 언어 모델(Large Language Models, LLMs)을 사용하여 질병 감시와 예측을 수행합니다. 에이전트들은 각각 특정 작업에 따라 다른 LLM을 사용할 수 있습니다. 이로 인해, 복잡한 질병 데이터 분석에서도 높은 효율성을 보입니다.
데이터 소스의 실시간 업데이트: ARIES는 공식 API와 최신 데이터 소스를 통해 정보를 수집하고 이를 실시간으로 업데이트합니다. 이를 통해 최신 정보만을 사용하여 분석 및 예측이 가능하며, 이는 마치 뉴스 방송국에서 최신 뉴스를 실시간으로 전달하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
건강 감시, 계산적 역학, 다중 에이전트 시스템,
질병 관리, 대형 언어 모델.
소개
년에 걸쳐 세계 보건기구(WHO), 질병 예방 및 통제 센터(CDC) , 그리고 국가 의학 도서관(NCBI)에서 많은 데이터가 출판되었습니다. 이 데이터는 XML, JSON, 텍스트 및 표 등 다양한 형식으로 제공됩니다. 이러한 데이터를 기반으로 여러 대시보드와 분석, 추세가 있습니다. 시간 시리즈 예측 알고리즘, 머신 러닝 알고리즘이 구현되어 질병 확산의 특성을 예측합니다. WHO는 질병 발생 소식(Disease Outbreak News, DONs)을 주기적으로 발행하며 평가 및 조언 정보를 제공합니다. 이 데이터셋은 매우 크고 특정 작업을 위해 정제하는 데 엔지니어링적 도전 과제입니다. 수집, 쿼리, 분석 및 의사 결정과 추세 분석에 사용할 수 있는 형식으로 표시하기 위한 큰 노력이 필요합니다. 실시간에서는 여러 출처에서 정보를 쿼리하고 다양한 형식의 텍스트를 수집하는 것이 지연 시간을 초래하여 의사결정과 행동을 늦추는 데 매우 도전적입니다.
최근 몇 년 동안 OpenAI와 같은 대형 언어 모델(Large Language Models, LLMs)이 개발되면서 정보 및 데이터 추출 방식이 크게 향상되었습니다. LLM은 가장 무난한 정보에서 인터넷에 있는 모든 정보까지 다루는 여러 연구 및 문헌 텍스트로 학습됩니다. 이러한 모델들은 단계별로 개발되어 다양한 정보 소스를 통해 학습되며, 계산적 역학과 질병 발생 분야에서 사용되는 비중이 증가하고 있습니다. 다양한 형식의 정보 추출 및 분석은 또 다른 중요한 엔지니어링 도전 과제입니다. 이러한 LLM은 일반화된 모델로 사용자의 쿼리에 기반하여 질문을 답변할 수 있는 능력을 가지고 있지만, 환영증상과 잘못된 사실적 정보 또는 낡은 정보를 추출하는 경향이 있습니다. LLM 모델이 학습한 것과 특정 분야의 최신 발전 사이에는 지식 간극이 존재합니다. 그러나 이러한 LLM들은 한 가지 특정 도메인이나 영역에서 더 잘 작동합니다. 그러나 이러한 LLM들에는 관련 비용이 발생합니다. 감시 및 발생에 대한 사용은 에러를 줄이고 해당 작업만을 위한 대화를 허용하며 관련되고 최신 정보만을 검색하는 프레임워크가 필요합니다.
이 도전 과제를 해결하기 위해 이 논문에서는 ARIES를 소개합니다. ARIES는 자동 질병 감시를 위한 다중 에이전트 프레임워크입니다. 여러 에이전트들이 각각 할당된 작업을 수행하는 결정 지능 시스템으로 작용합니다. 현재의 아키텍처에서 새로운 데이터 소스가 등장하면 새 에이전트와 도구를 통합할 수 있어 확장 가능합니다.
관련 연구
Samaei et al은 EpidemIQ라는 다중 에이전트 프레임워크를 소개했습니다. 이 프레임워크는 사용자 및 특정 에이전트로부터 입력을 받아 문헌 검토, 데이터 시각화, 네트워크 모델링 및 전문가 작업을 수행하여 과학적 형식의 전체 논문을 작성합니다. 도구가 매우 강력하지만 최근 발생 소식이나 질병 확산 추세를 고려하도록 개발되지 않았습니다. 그러나 이 논문은 실시간 발생 분석과 논리에 대한 다중 에이전트 아키텍처와 최신 기술을 소개합니다.
대형 언어 모델은 요약, 추출, 생성 및 분석 등 다양한 목적으로 항상 사용됩니다. Kwok et al.과 Patlolla, Padmavath et al. 등은 유사한 방법으로 ChatGPT와 같은 LLM에 채팅하여 중요한 역학 매개변수인 재생산 수와 유행 규모를 추정했습니다. 자연어 생성 및 감염 모델인 Susceptible-Exposed-Infected-Recovered (SEIR) 프레임워크의 목표 명확화 및 응답 정제를 통해 고전적인 질병 전파 모델을 활용할 수 있습니다. 이 접근법은 효과적이지만, ChatGPT와 같은 일반화된 언어 모델을 사용하는 것에 여전히 한계가 있으며 이는 과거 데이터에 대한 완전한 액세스를 제공하지 않습니다. 복잡한 전파 모델에서는 자연언어 생성이 전체 컨텍스트 창을 사용합니다. 무료 버전은 사용자가 동일한 컨텍스트에서 대화할 수 있는 시간을 제한합니다. 컨텍스트 변경 시 사용자는 지금까지 수행한 모든 작업의 진행 상황을 잃게 됩니다. 이는 모델 생성이나 부정확한 모델 생성을 방지합니다. ARIES를 채택하면 에이전트가 공식 API 또는 데이터 소스에서 도구를 사용하므로 데이터가 최신임을 보장할 수 있습니다.
R. Allard et al은 질병 감시에 ARIMA 알고리즘을 사용한 시간 시리즈에 대해 설명했습니다. 이 논문에서는 예측을 통해 의사결정자가 변동성을 고려하고 유행을 감지하는 데 도움이 된다는 결론을 내렸습니다. 그러나 이것은 생성 AI 측면에서 지능을 포함하지 않습니다. 전통적인 머신 러닝(ML) 알고리즘에 더 집중합니다. 이는 Wattamwar et al과 유사한 작업입니다. 그들은 전 세계의 바이러스 질병 발생을 모니터링하기 위해 특화된 접근 방식을 사용했습니다. 그러나 ARIES에서는 사용자가 쿼리를 요청하면 에이전트가 관련 도구에서 데이터를 수신하여 예측을 수행할 수 있습니다.
대형 언어 모델이 대부분의 분야에서 주요한 위치를 차지하기 전에는 머신 러닝과 딥러닝이 패턴 찾기와 탐지에 중요한 역할을 했습니다. 이는 데이터 수집, 데이터 정리 및 데이터 조작에 많은 시간을 소비해야 함을 의미했습니다. Syed Ziaur Rahman et al.과 다른 연구자들은 시계열 및 공간 예측 모델과 위험 예측 모델을 분석하여 질병 에피소드와 그 특성 간의 상관관계를 찾았습니다. 딥 뉴럴 네트워크(DNNs)와 길고 짧은 시간 메모리(LSTM) 모델, 준감독 학습(SSL) 알고리즘 등 다양한 텍스트에서 공식 기관이 관리하는 소셜 미디어 데이터 및 웹 아티클에 적용되어 유망한 결과를 보여주었습니다.
Consoli, Sergio et al.과 다른 연구자들은 WHO와 질병 발생 뉴스에서 제공된 데이터셋의 정보 추출(IE)을 수행했습니다. 추출은 Llama-2-70b-chat, Mistral-7b-openorca, Mpt-30b-chat, Pythia-12b, Gpt-4-32k 등 여러 대형 언어 모델에서 수행되었습니다. 이 논문에서는 ProMed와 WHO DONs 데이터셋을 통해 이러한 모델들의 정확도를 테스트한 결과를 보여줍니다. 이것은 이러한 모델들이 앙상블로 사용될 때 정확한 결과를 제공할 수 있음을 보여줍니다. Sara De Luca는 LLM을 이용해 Covid19와 2020-2022년의 Mpox 유행병에 대한 두 가지 사례 연구에서 90.2%의 정밀도로 제로샷 분류를 수행했습니다. 이 접근법은 뉴스 발생의 이상 탐지 및 ICD-9-CM 질병 코드 분류 목적으로 도입되었습니다.
이것을 영감으로, ARIES 아키텍처에서는 각 에이전트 LLM이 목적에 맞게 업데이트되어 비용과 지연 시간을 줄입니다.
방법론
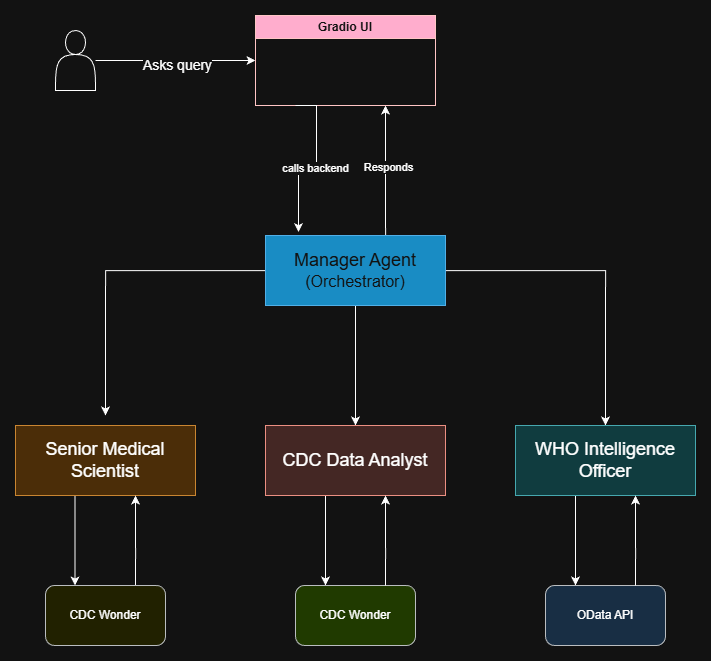
ARIES는 데이터 검색을 위한 다중 에이전트 아키텍처로 구성됩니다. 이 시스템은 공중 보건 긴급 운영 센터(EOC)의 운영 계층을 모방하여 여러 글로벌 데이터 소스를 탐색하도록 설계되었습니다.
순차적 프로세스와 달리 누적 오류 전파 위험을 방지하기 위해 ARIES는 중앙 “매니저” 에이전트가 자율 하위 에이전트의 스와rm을 조정하는 커맨드 및 제어 구조를 활용합니다. 이 논문에서는 아래에 구성되고 테스트된 에이전트 세트.
매니저 에이전트
최고 의료 책임자 역할을 합니다. 쿼리 분해, 작업 위임 및 최종 응답 합성을 수행하는 역할입니다. 매니저는 하위 에이전트의 출력을 논리적 일관성 평가하고 소스 간의 컨텍스트를 식별합니다.
전문 에이전트
각 도메인에 맞게 구성된 하위 에이전트 계층입니다.
시니어 의학 과학자: 쿼리 기반의 최신 문헌 및 연구 텍스트를 추출하기 위해 NCBI PubMed 데이터베이스와 BioC-JSON 상호 운용 형식을 사용합니다.
CDC 데이터 분석가: CDC WONDER 서버로 복잡한 XML-POST 요청을 자동화하여 데이터를 검색합니다.
WHO 정보 관리자: OData 필터 API 호출을 통해 WHO 질병 발생 뉴스(DONs)를 모니터링하여 실시간 위험 평가 및 국제 건강 조언을 검색합니다.
아키텍처 다이어그램
도표 1은 간단한 작동 아키텍처를 보여주며 사용자의 쿼리에 대한 답변을 반환합니다. 모든 에이전트는 작업별로 분할되어 있으며 새로운 에이전트가 추가될 수 있습니다.
운영 실행
ARIES의 운영 실행은 네 단계 “조사 루프"를 따릅니다.
소비: 사용자는 자연어 쿼리를 제공합니다(예: “북아메리카 유제품 종사자에서 현재 발생 중인 조류독감 위험 평가”).
분해 및 위임: 매니저는 쿼리를 임상(PubMed), 통계(CDC) 및 규제(WHO) 작업으로 분해하고 하위 에이전트에게 병렬로 할당합니다.
논리적 추론: 하위 에이전트들은 발견한 내용을 매니저에게 반환합니다. 매니저는 논리 검증을 수행하여 모순을 확인합니다(예: WHO “낮은 위험” 경보와 CDC “사망률 증가”).
최종 보고서: LLM은 사용자에게 하위 에이전트의 로직을 투명하게 표시합니다.
논문의 아키텍처는 Python과 CrewAI를 활용하여 구축되었습니다. CrewAI 프레임워크는 각 에이전트에 역할, 목표 및 배경 스토리를 할당하는 기능을 제공합니다. 에이전트는 또한 사용 가능한 모든 LLM 모델을 구성할 수 있습니다. 작업이 간단하면 추론 비용과 지연 시간을 절약하기 위해 작은 LLM을 구성할 수 있습니다. 접근 방식은 모든 에이전트에 대해 gpt-4o를 테스트했습니다. 작업은 또한 세 가지 출처에서 데이터를 가져와 매니저 에이전트에게 전송한 후 삼각측량하는 설명과 함께 정의되었습니다.
워크플로
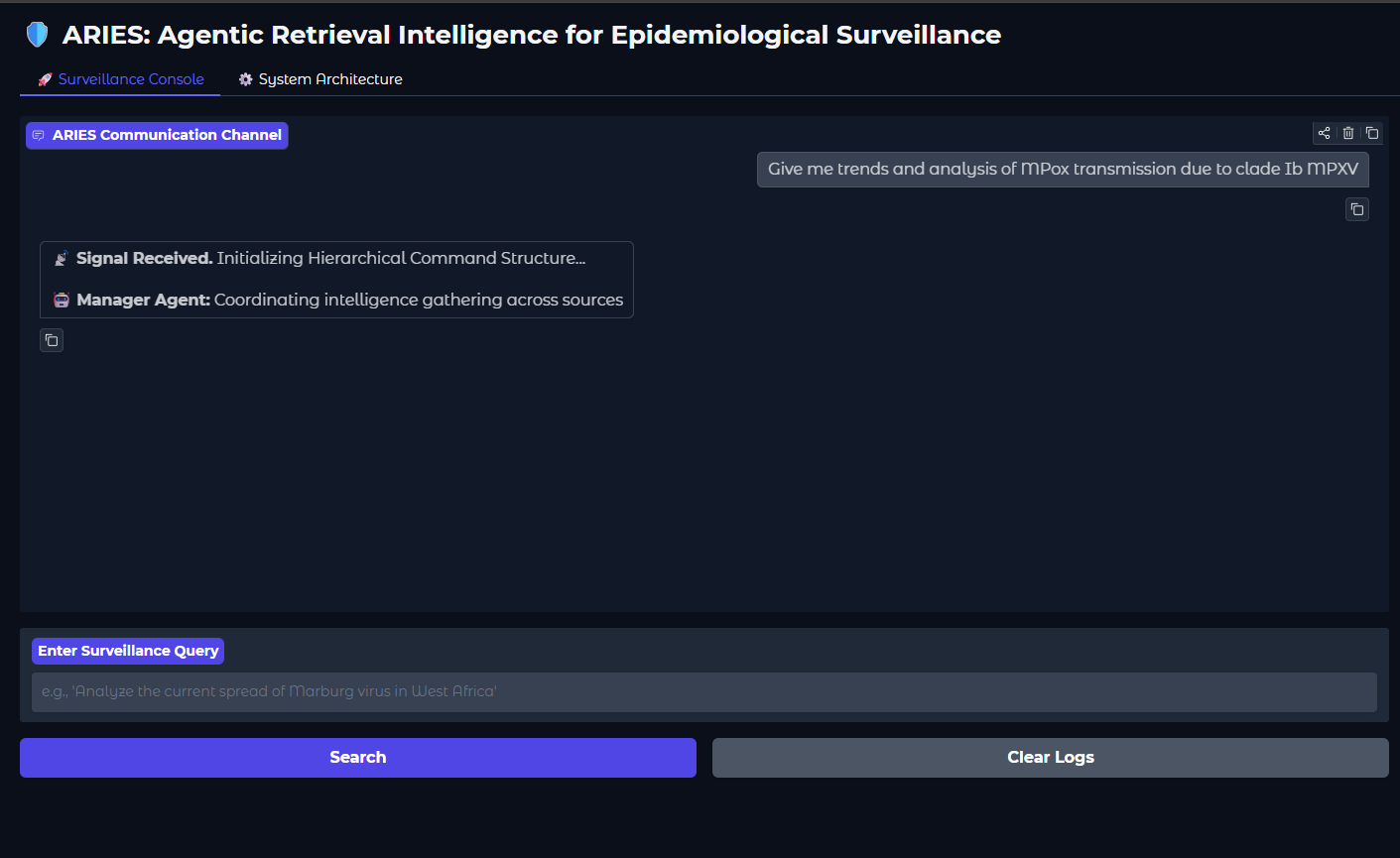
ARIES UI
도표 2는 사용자가 시스템과 상호 작용하는 방식을 보여줍니다. 서버 측 이벤트를 표시하여 모델이 어떻게 생각하고 어떤 유형의 흐름을 따르는지 확인할 수 있습니다. 쿼리는 백엔드로 전송되며 매니저 또는 오케스트레이터 에이전트가 트리거되어 쿼리를 분석하고 의도를 식별합니다.
매니저의 생각 및 인식
도표 3은 에이전트의 사고와 정보 수집을 수행해야 함을 이해하는 것을 보여줍니다.
에이전트 식별하위 에이전트에게 작업 위임
도표 4와 도표 5는 오케스트레이터에서 CDC 데이터 분석가 및 WHO 관리자인 AI 에이전트를 트리거하여 필요한 관련 정보를 수집하도록 업무를 위임하는 과정을 보여줍니다.
모든 하위 에이전트에서 수집한 정보사용자에게 UI로 최종 출력
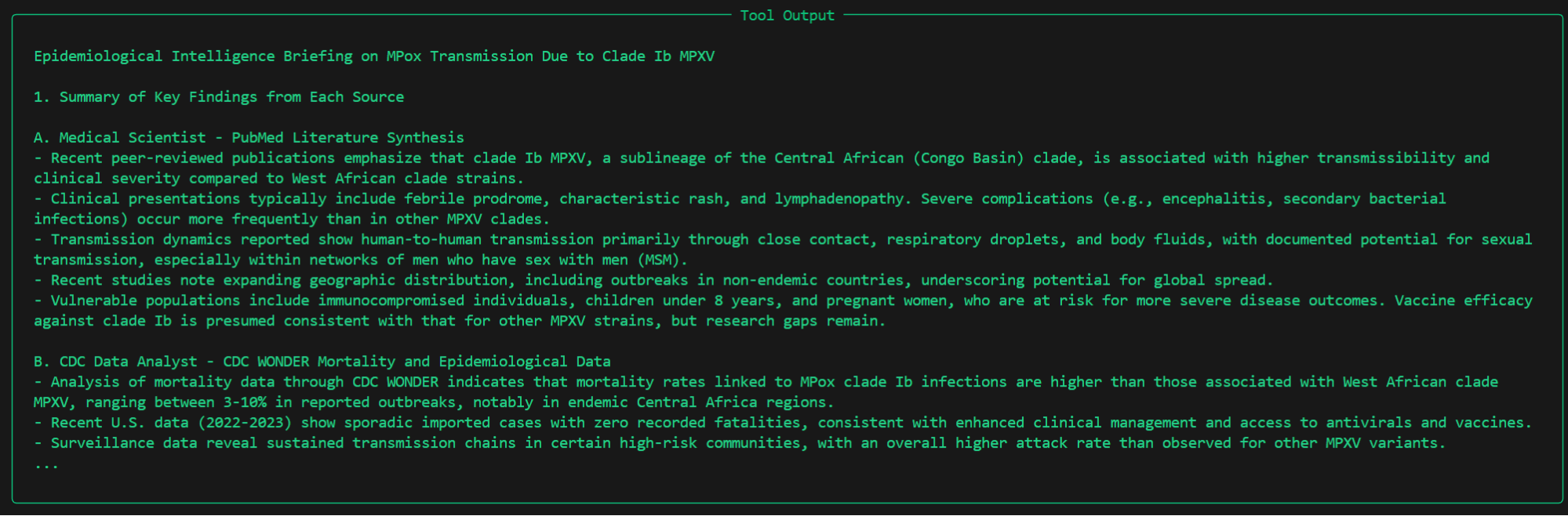
도표 6은 각 하위 에이전트가 매니저 에이전트에게 보내는 요약 정보의 전체 내용을 수집한 것입니다.
도표 7은 사용자가 도착한 정보를 기반으로 매니저 에이전트에서 생성된 특정 형식의 최종 출력입니다.
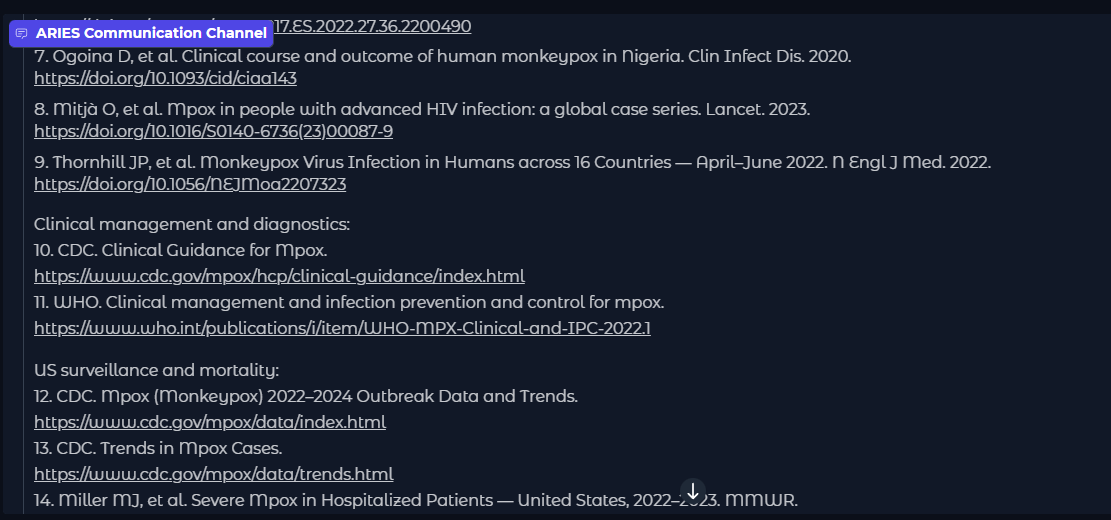
데이터 출처 링크
도표 8은 데이터가 수집된 출처를 표시하여 사용자가 사실을 확인하고 인간의 판단에 포함되게 합니다.
CrewAI
CrewAI는 Python으로 에이전트를 생성하는 프레임워크입니다. Flows, Crews, Agents, Process 및 Tasks와 같은 구성 요소 세트가 있습니다. 이러한 구성 요소의 조합으로 다중 에이전트 아키텍처를 만들 수 있습니다. 각 구성 요소는 구현되는 사용 사례에 따라 고유한 기능을 제공합니다. Memory, LLMs, Knowledge, Reasoning, Training 및 Tools은 각 구성 요소에 대한 풍부한 커스터마이징과 확장성을 위해 구성할 수 있습니다. 이 논문에서는 ARIES가 Crew 구성 요소, 여러 에이전트, 구성 가능한 LLM, WHO DONs, PubMed 문헌 및 CDC Wonder와 같은 도구로 구성된 학습 및 추론 능력을 활용합니다.
CDC WONDER
WONDER는 Wide-ranging ONline Data for Epidemiologic Research의 약자로 연구, 의사결정, 프로그램 평가 및 자원 배분을 위한 공중 보건 정보의 출처입니다. 이 데이터 소스를 통해 누구나 통계적 연구 데이터, 참고 자료, 건강 관련 주제에 대한 지침에 접근할 수 있습니다. 사망률, 암 발생률, 결핵 등 많은 유용한 주제에 대한 데이터셋을 쿼리할 수 있습니다. 이 데이터는 XML 형식으로 HTTP를 통해 API로 요청할 수 있습니다.
BioC JSON for PubMed Literature
BioC 포맷은 임상 문헌의 텍스트 마이닝에 널리 사용되고 간결함, 상호 운용성 및 광범위한 활용을 목표로 하는 표준 포맷입니다. 이 형식은 텍스트 데이터를 공유하고 대규모 주석과 텍스트 샘플 처리를 수행하는 데 사용됩니다. BioC Json은 XML 파일을 bioC json 파일로 변환하는 도구입니다. 이 논문에서는 에이전트 간 또는 사용자에게 정보를 전달할 때 LLM이 이해하기 쉽게 만드는 데 유용합니다. 대부분의 데이터 및 텍스트 교환이 JSON 형식으로 이루어지며 ARIES 프레임워크에서 모든 종류의 LLM을 사용하는 것을 확장 가능하게 만듭니다.
결과
에이전트 구성의 비교 분석
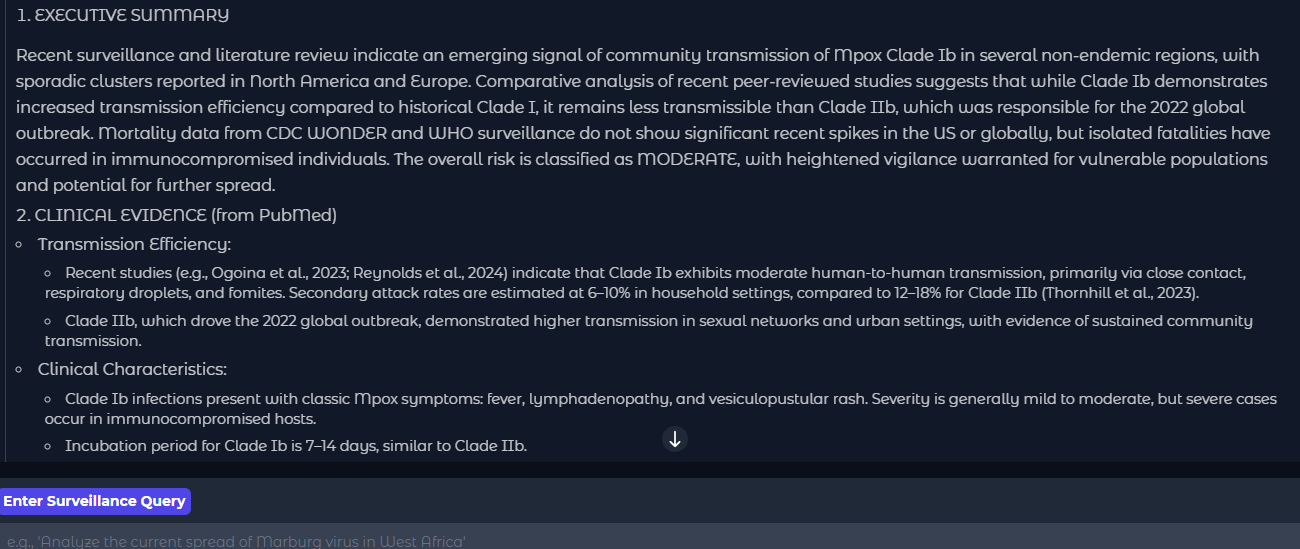
쿼리: 비본래 지역에서 Mpox Clade Ib의 커뮤니티 전파 신호를 분석하고, 최근 문헌을 기반으로 Clade Ib와 Clade IIb 간 생물학적 전파 효율성을 대조하며, 미국/전 세계 감시 데이터에서 최근 사망률 증가 여부를 확인하십시오.
ARIES의 구성 가능한 LLMs을 각 에이전트 및 오케스트레이터에 테스트했습니다. 동일한 쿼리는 LLM 변경 시 결과도 변경되었습니다. 초기에는 모든 에이전트에게 단일 LLM인 gpt-4o만 사용되었으며, 그 결과가 도표 8과 도표 9에서 보여집니다.
후에 각 작업에 따라 에이전트의 LLM을 구성했습니다. 매니저 LLM은 5.1로 설정되어 있으며 모든 전문 에이전트는 o3입니다.