- Title: Safety at One Shot Patching Fine-Tuned LLMs with A Single Instance
- ArXiv ID: 2601.01887
- 발행일: 2026-01-05
- 저자: Jiawen Zhang, Lipeng He, Kejia Chen, Jian Lou, Jian Liu, Xiaohu Yang, Ruoxi Jia
📝 초록
대규모 언어 모델(LLMs)의 널리 퍼진 사용은 기만, 폭력 및 차별과 같은 유해한 콘텐츠 생성 가능성에 대한 우려를 제기했습니다. 이를 해결하기 위해 안전 정합성이 핵심 패러다임으로 부상했으며, 이를 위한 일반적인 접근 방식은 감독 조정(SFT) 및 인간 피드백 기반 강화학습(RLHF), 직접적 선호도 최적화(DPO) 등입니다. 그러나 사용자가 제공한 데이터를 조정 파이프라인에 도입하면 새로운 보안 취약성이 발생합니다. 이를 해결하기 위해, 본 논문은 한 번의 안전 업데이트만으로도 유해한 업데이트를 중화시킬 수 있다는 것을 밝히며, 이 방법을 통해 모델의 안전성을 복원할 수 있음을 보여줍니다.
💡 논문 해설
1. **한 번에 안전 회복**
대규모 언어 모델(LLMs)이 유해한 데이터로 조정되었을 때, 단 한 개의 신중히 선택된 안전 사례만으로도 정합성을 복원할 수 있습니다. 이는 마치 작은 알약 하나가 큰 질병을 치료하듯 작용합니다.
기울기와 내재 차원 분석
안전 회복 메커니즘은 기울기의 특성과 내재 차원 분석에 근거합니다. 이를 통해 유해한 업데이트를 빠르게 중화시킬 수 있다는 것을 발견했습니다. 이는 마치 강력한 방어벽이 적을 밀어내듯 작용합니다.
실험을 통한 유효성 검증
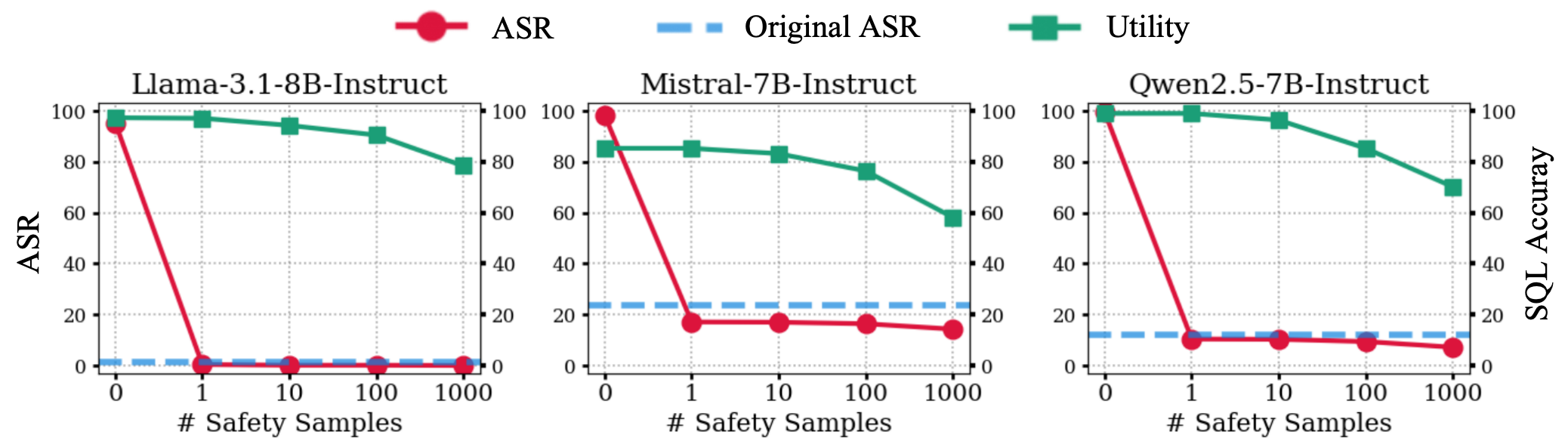
다양한 모델과 API에서 실험 결과, 단 한 번의 패칭으로 안전 정합성을 완전히 복원하면서도 하류 작업 효율은 그대로 유지됩니다. 이는 마치 조정된 자동차가 안전하게 최고 속도로 달릴 수 있도록 하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
maketitle 감사합니다 aketitle
서론
대규모 언어 모델(LLMs)의 널리 퍼진 사용은 기만, 폭력 및 차별과 같은 유해한 콘텐츠 생성 가능성에 대한 우려를 제기하였습니다. 이를 해결하기 위해 안전 정합성이 핵심 패러다임으로 부상했으며, 일반적인 접근 방식에는 감독 조정(SFT) 및 선호도 기반 방법론이 포함됩니다. 이러한 방법들로 모델은 유해한 프롬프트를 인식하고 안전한 거절을 할 수 있습니다.
그러나 LLMs가 현실 세계 애플리케이션에 점점 더 많이 배포됨에 따라 사용자는 특정 도메인으로의 적응, 맞춤 스타일 채택 또는 하류 작업 성능 향상을 기대합니다. 이를 위해 OpenAI와 Anthropic 등 제공자는 조정 API를 제공하여 사용자가 데이터셋을 업로드하고 맞춤형 모델을 얻는 것을 가능하게 합니다.
그러나 사용자 제공 데이터의 도입은 새로운 보안 취약성을 생성합니다. 최근 연구는 조정이 안전 정합성을 무효화할 수 있으며, 이는 악성 행위를 삽입하기 위한 전략으로 알려져 있습니다. 이를 통해 LLMs-as-a-Service(LMaas) 패러다임에서 제공자가 사용자의 데이터셋을 업로드하고 조정 및 추론을 수행한 후 API를 통해 결과를 배포하는 과정은 안전 문제에 노출됩니다.
LLM-as-a-Service의 위협 모델 개요.
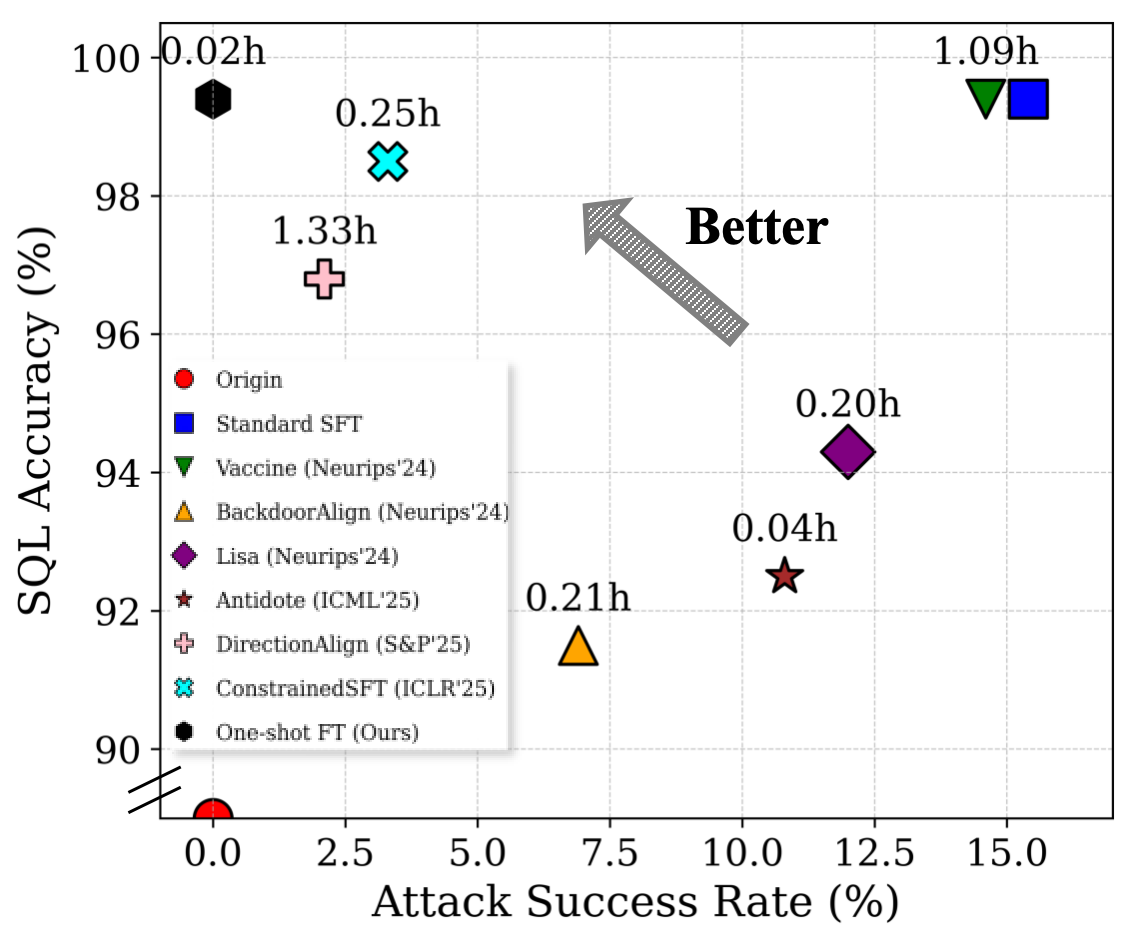
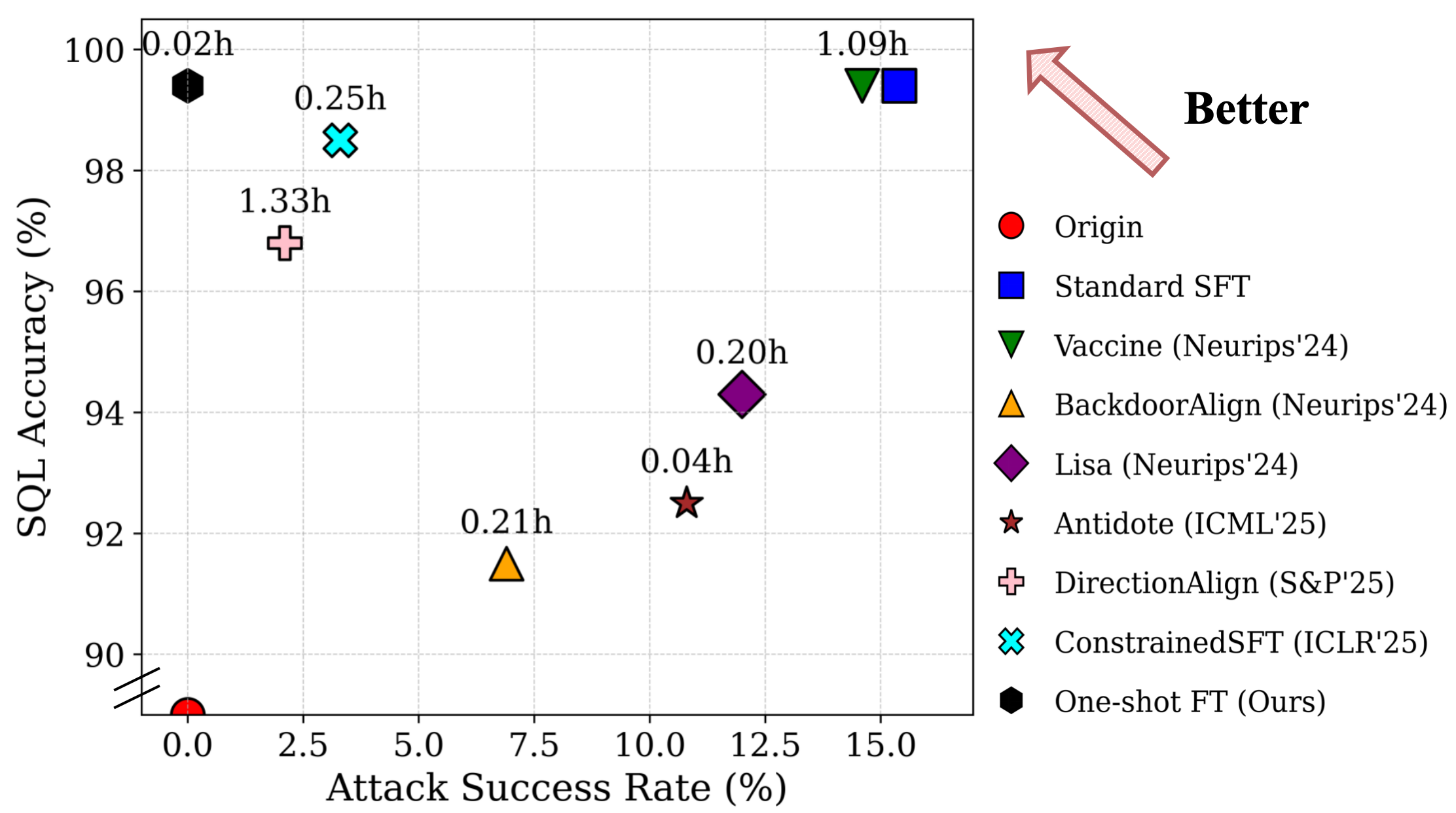
최근에는 조정 시의 보안 리스크를 완화하려는 노력이 이루어졌습니다. Vaccine 및 BackdoorAlign은 변형이나 숨겨진 트리거를 통해 견고성을 향상시키지만, 이는 작업 효용성에 악영향을 미칩니다. Lisa는 조정 시 안전 데이터를 주입하여 정합성을 개선하지만 대규모로 수집된 데이터셋과 큰 계산력이 필요합니다.
본 논문에서는 다음과 같은 질문을 제기합니다:
안전성을 복원하면서 효용성을 포기하지 않고 최소한의 비용으로 어떻게 할 수 있을까요?
대규모로 수집된 안전 데이터셋이나 복잡한 수정 메커니즘에 의존하지 않고, 정합성을 회복하기 위한 최소 신호를 식별할 수 있는지 살펴보았습니다. 이를 통해 단 한 개의 신중히 선택된 안전 사례만으로도 유해 업데이트를 중화시킬 수 있음을 발견했습니다.
r0.42
우리의 연구는 다음과 같은 세 가지 기여를 합니다:
첫째, 한 번에 안전 회복 현상을 발견하였습니다. 안전 회복을 이중 최적화 문제로 정식화하고 유해 업데이트된 LLM에서 단 하나의 신중히 선택된 안전 사례만으로도 정합성을 복원할 수 있음을 보여줍니다.
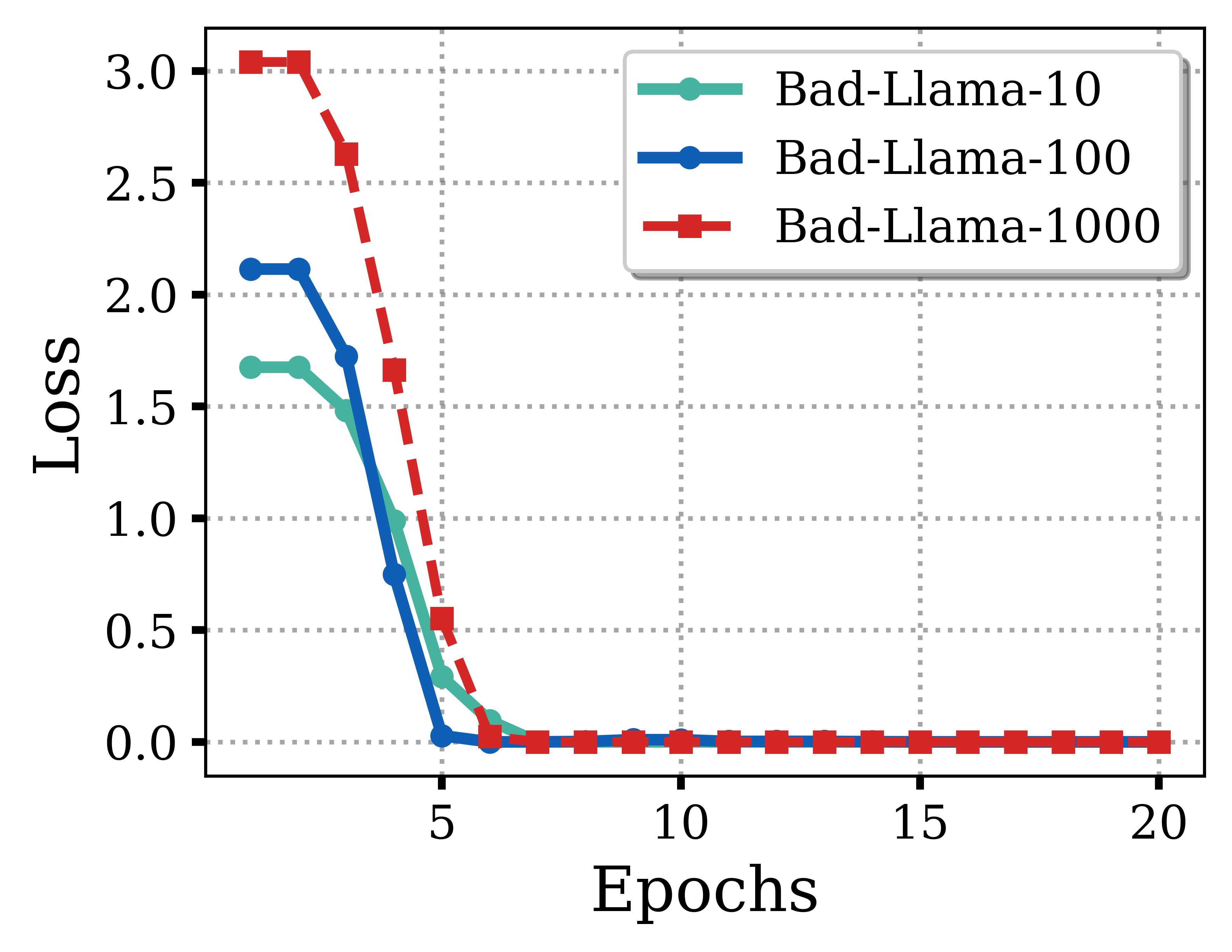
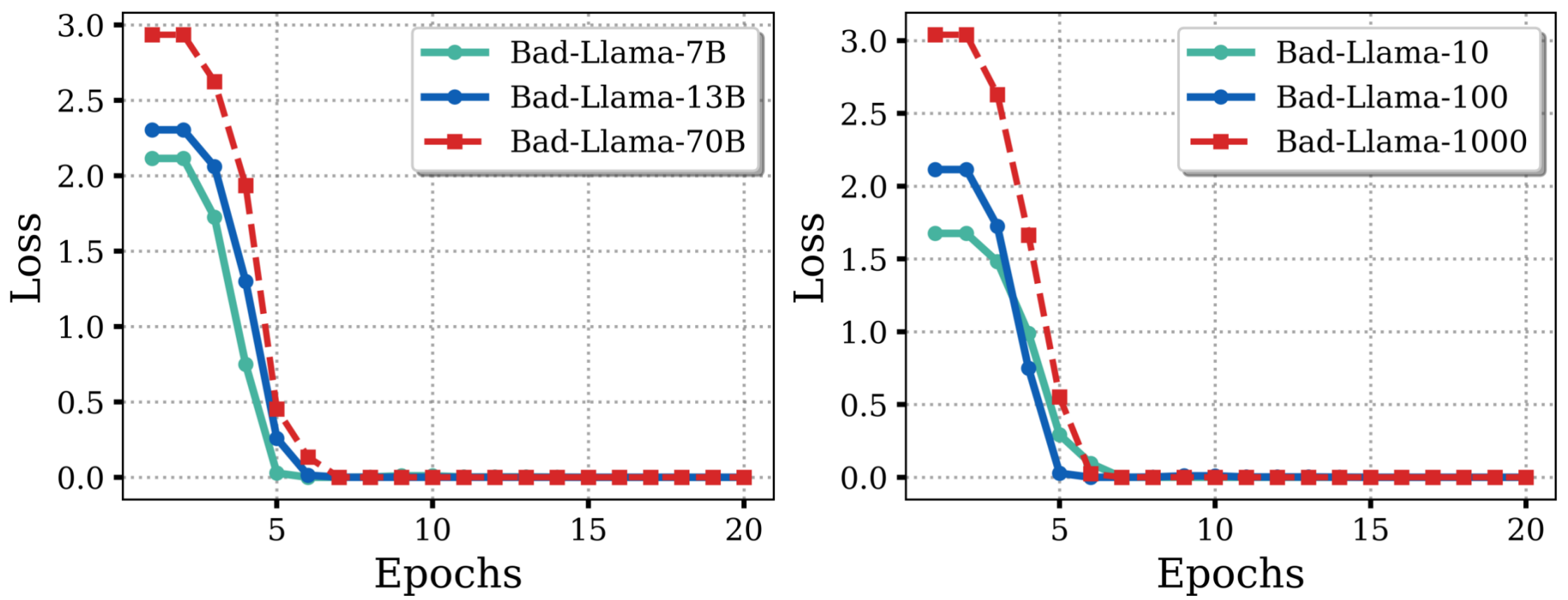
둘째, 기울기 및 내재 차원 분석을 통해 한 번에 패치가 어떻게 작동하는지 설명하였습니다. 안전 기울기의 특이값 분해(SVD)를 통해 정합 신호는 낮은 랭크의 내재 하위 공간에 위치함을 보여주었습니다.
셋째, 다양한 오픈 소스 모델 및 폐쇄형 API에서 방법의 유효성과 일반성을 검증하였습니다. 결과적으로 한 번 패치로 안전 정합성을 완전히 복원하면서도 하류 효용성은 그대로 유지되었습니다.
재정합 문제
안전, 효용 및 효율성 사이의 절충
최근 몇 가지 방어가 제안되었는데, Vaccine은 인공 변형을 도입하여 유해 임베딩 이동을 시뮬레이션하고 최소화 최적화를 통해 모델을 면역시키는 방법입니다. 그러나 이러한 접근법은 작업 효용성을 저하시킵니다.
BackdoorAlign은 안전 사례를 숨겨진 “백도어 트리거"로 접두사화하여 정합성을 강제하는 아이디어를 기반으로 합니다. 이는 조정 시의 안전 응답을 보장하지만, 일반 작업에서 성능이 저하됩니다.
안전 데이터셋을 직접 조정 단계에 통합하는 Lisa도 있습니다. 그러나 이 접근법은 대규모 정합 데이터가 필요하며 데이터와 계산 비용이 증가합니다.
Antidote 및 DirectionAlign는 손상된 파라미터를 제거하거나 부분적으로 초기화하여 유해 업데이트를 중화시키지만, 교정 효과는 제한적입니다. ConstrainedSFT는 초기 토큰에 대한 업데이트를 제약하는 정규화 조정 목표를 제안합니다.
이러한 방법들은 조정 공격에 대한 방어를 개선하지만, 안전성 향상은 작업 효용성 저하, 추가 데이터의 높은 의존도 또는 제한적인 교정 효과라는 기본적인 절충을 드러냅니다. 이러한 문제는 동시에 안전성을 보장하면서 작업 효율성을 유지하고 가볍게 작동할 수 있는 방어를 찾는 동기를 부여합니다.
최신 재정합 방법의 평가
평가 지표. LLM의 안전성은 공격 성공률(ASR)과 유해 점수(HS)로 측정됩니다. ASR은 악의적인 명령에 응답을 거부하지 못하는 비율입니다. 이러한 악의적인 명령은 HEx-PHI와 AdvBench에서 왔습니다.