불균형 데이터 세트는 한 클래스(소수 클래스)가 다른 클래스들(다수 클래스)에 비해 크게 소수로 나타나는 기계 학습 및 통계적 분석에서의 주요 도전 과제입니다. 이 불균형은 예측 모델이 소수 클래스에 대해 성능이 저하되는 편향된 결과를 초래하며, 이러한 소수 클래스는 고장 감지, 의료 진단, 네트워크 보안 또는 컴퓨터 비전과 같은 중요한 경우들을 나타낼 수 있습니다. 이를 완화하기 위해 다양한 데이터 증강 기법들이 개발되었습니다.
이 논문에서는 Synthetic Minority Over-sampling Technique (SMOTE)이라는 가장 널리 사용되는 증강 방법에 대해 이론적 분석을 제공합니다. 특히, SMOTE가 생성하는 합성 샘플들이 원래 데이터 분포로 수렴하는 과정을 이론적으로 입증하고자 합니다. 우리의 주요 기여는 다음과 같습니다:
확률 수렴: 합성 랜덤 변수 $`Z`$가 표본 크기 $`n`$이 무한대로 접근할 때 원래 랜덤 변수 $`X`$로 확률적으로 수렴한다는 것을 증명합니다.
최근접 이웃 순위 $`k`$: $`k`$의 값이 합성 샘플의 수렴 속도에 미치는 영향을 분석하고, 더 낮은 값을 사용하면 더 빠른 수렴을 얻을 수 있다는 것을 보여줍니다.
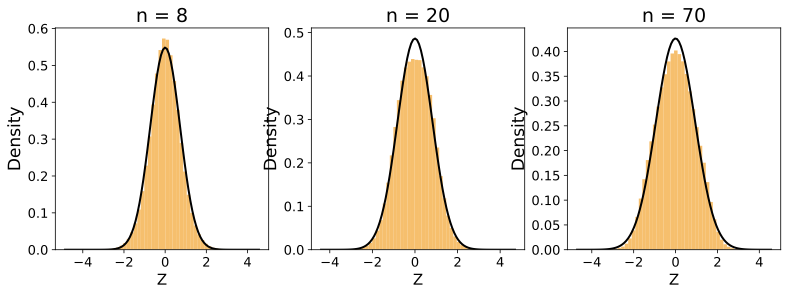
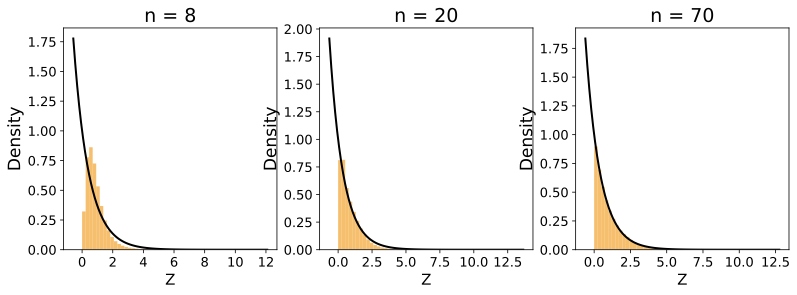
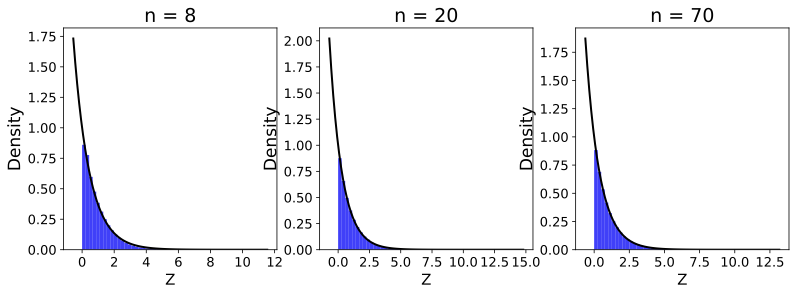
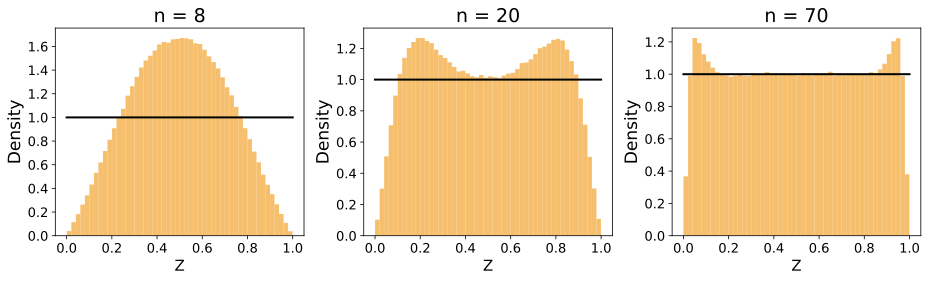
경험적 검증: 균일, 가우시안 및 지수 분포를 사용한 시뮬레이션 연구를 통해 이론 결과를 확인합니다.
이 논문의 결과는 SMOTE 알고리즘에서 $`k = 1`$을 사용하는 것이 원래 분포로 더 빨리 수렴하도록 하는 등 실제 응용에 대한 중요한 통찰력을 제공합니다. 이러한 통찰력은 실무자들이 SMOTE를 사용할 때 적절한 매개변수를 선택하고 증강된 데이터를 기반으로 훈련하는 모델의 성능을 개선하는 데 도움이 될 것입니다.
💡 논문 해설
#### 1. Simple Explanation (초등학생 수준)
SMOTE는 소수가 있는 클래스에 더 많은 샘플을 만들어서 불균형한 데이터를 균형 있게 만드는 방법입니다. 우리는 SMOTE가 원래 데이터와 비슷하게 작동하는지 확인했습니다.
2. Medium Explanation (중고생 수준)
불균형 데이터에서 소수 클래스의 성능을 향상시키기 위해 SMOTE 알고리즘이 사용됩니다. 이 논문에서는 SMOTE가 생성한 합성 샘플들이 원래 데이터와 얼마나 비슷해지는지 분석했습니다. 특히, 최근접 이웃 수 $`k`$가 작을수록 더 빨리 비슷하게 변한다는 것을 발견했습니다.
3. Advanced Explanation (대학생 수준)
SMOTE 알고리즘의 합성 샘플 생성 과정에서, 원래 데이터 분포와의 수렴성을 이론적으로 증명하고자 했습니다. 특히, 최근접 이웃 순위 $`k`$가 작은 경우 더 빠르게 원래 데이터 분포로 수렴한다는 것을 보여주었습니다.
📄 논문 발췌 (ArXiv Source)
**키워드:** 수렴성, 불균형 데이터, 최적 순위, 샘플링, SMOTE, 이론 분석
개요
불균형 데이터 세트는 기계 학습 및 통계적 분석에서 널리 퍼진 도전 과제로, 한 클래스(소수 클래스)가 다른 클래스들(다수 클래스)에 비해 크게 소수로 나타나는 현상을 의미합니다. 이 불균형은 예측 모델이 소수 클래스에 대해 성능이 저하되는 편향된 결과를 초래하며, 이러한 소수 클래스는 고장 감지, 의료 진단, 네트워크 보안 또는 컴퓨터 비전과 같은 중요한 경우들을 나타낼 수 있습니다. 이를 완화하기 위해 다양한 데이터 증강 기법들이 개발되었습니다.
가장 널리 사용되는 증강 방법 중 하나는 Chawla 등이 제시한 합성 소수 과샘플링 기술(Synthetic Minority Over-sampling Technique, SMOTE)입니다. SMOTE는 존재하는 소수 클래스 인스턴스와 그 근처 이웃을 통해 새로운 합성 샘플을 생성합니다. 구체적으로, 주어진 소수 클래스 샘플에 대해 $`k`$-최근접 이웃과 연결된 선분 위에서 합성 포인트를 생성합니다. 이러한 접근법은 실험적으로 성공적이었으며 다양한 응용 분야와 여러 가지로 확장되었습니다.
SMOTE의 널리 퍼진 채택 및 수많은 경험적 연구에도 불구하고, SMOTE의 이론적 측면은 여전히 상대적으로 탐구되지 않았습니다. 특히, 샘플 크기가 증가함에 따라 SMOTE가 생성한 합성 샘플이 원래 데이터 분포와 어떻게 연관되는지에 대한 이해는 제한적이었습니다. 수렴성이 알고리즘의 효과를 이해하는 데 중앙적입니다. 이론적인 근거는 알고리즘의 효과성을 이해하고 매개변수 선택을 안내하며 개선된 증강 방법의 개발을 지원할 것입니다.
이 논문에서는 원래 데이터 분포로 SMOTE 생성 샘플의 수렴성에 대한 이론적 분석을 제공함으로써 이러한 분석적인 틀의 공백을 메우고자 합니다. 우리의 연구는 연속 랜덤 변수 $`X`$를 고려하며, 이를 기반으로 독립 동일 분포(i.i.d.) 표본에서 생성된 합성 랜덤 변수 $`Z`$의 행동을 살펴봅니다.
우리의 주요 기여는 다음과 같습니다:
확률 수렴: 우리는 합성 랜덤 변수 $`Z`$가 샘플 크기 $`n`$이 무한대로 접근할 때 원래 랜덤 변수 $`X`$로 확률적으로 수렴한다는 것을 증명합니다(정리 [ref1]). 이 결과는 충분히 큰 표본을 사용하면 SMOTE 생성 샘플의 분포가 원래 데이터 분포를 근사하는 것을 보장합니다.
최근접 이웃 순위 $`k`$의 영향: 우리는 $`k`$ 값이 $`Z`$에서 $`X`$로의 수렴 속도에 미치는 영향을 분석합니다. 우리의 분석은 더 낮은 값을 사용하면 더 빠른 수렴을 얻을 수 있다는 것을 보여줍니다(방정식 [ref2]). 구체적으로, $`k`$-번째 최근접 이웃과 샘플 포인트 사이의 예상 거리는 $`k`$가 증가함에 따라 커집니다. 따라서 더 높은 값을 사용하면 합성 샘플이 원래 데이터 포인트에서 더 멀리 위치할 가능성이 있어 수렴 속도를 느려질 수 있습니다.
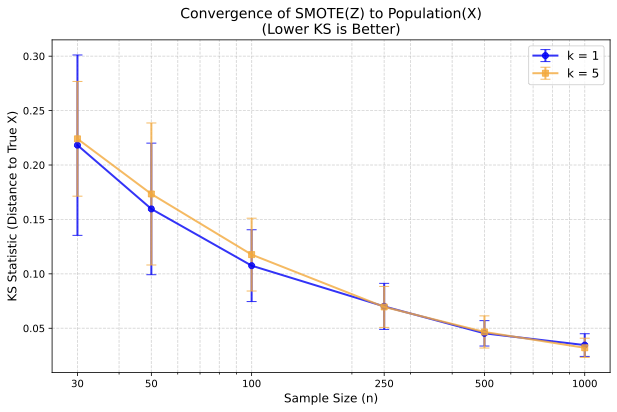
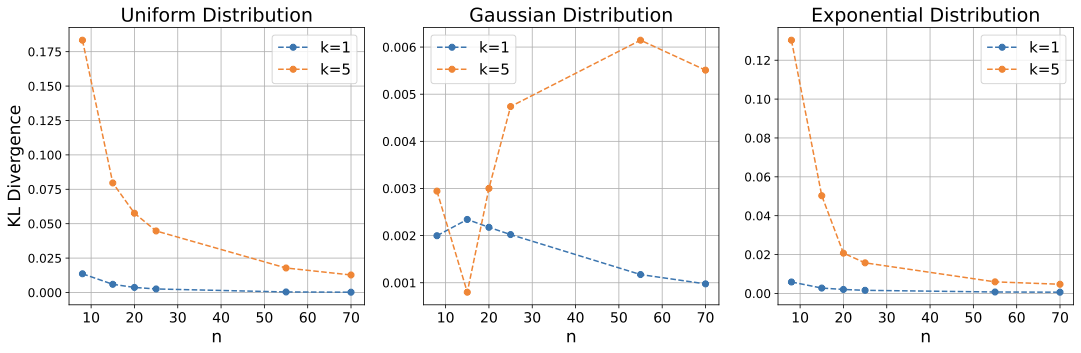
경험적 검증: 균일, 가우시안 및 지수 분포를 사용한 시뮬레이션 연구로 우리의 이론 결과를 뒷받침합니다(그림 [ref5]–[ref8]). 우리는 $`k`$ 값과 샘플 크기 $`n`$에 따른 $`Z`$의 수렴 행동을 살펴보고, Kullback-Leibler (KL) 발산으로 측정된 결과에서 더 낮은 값을 사용하면 $`Z`$가 $`X`$ 분포로 빠르게 수렴한다는 것을 관찰합니다(그림 [ref12]).
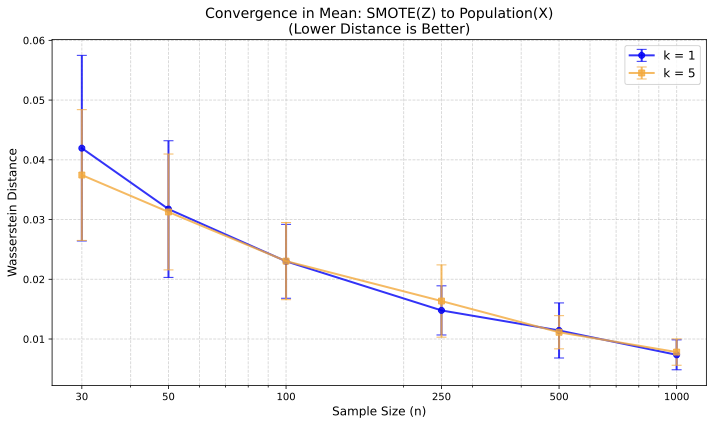
평균 수렴: $`X`$가 컴팩트 지원을 갖는다고 추가적으로 가정할 때, 우리는 $`n \rightarrow \infty`$일 때 $`Z`$가 $`X`$로 평균적으로 수렴한다는 것을 증명합니다(정리 [ref3]). 이 강력한 수렴 형태는 합성 및 원래 데이터 분포 간의 관계에 대한 더 깊은 이해를 제공합니다.
우리의 결과는 SMOTE를 데이터 증강에서 적용하는 데 있어 실제적인 의미가 있습니다. 특히, $`k = 1`$을 사용하여 가장 가까운 이웃을 선택하면 원래 분포로 더 빠르게 수렴할 수 있다는 통찰력을 제공합니다. 이러한 통찰력은 실무자들이 SMOTE의 적절한 매개변수를 선택하고 증강된 데이터를 기반으로 훈련하는 모델의 성능을 개선하는 데 도움이 될 것입니다.
본 논문의 나머지 부분은 다음과 같이 구성되어 있습니다. 섹션 [ref4]에서는 확률 및 평균 수렴에 대한 주요 이론적 결과와 증명을 제시합니다. 섹션 [ref5]에서는 우리의 이론 결과를 뒷받침하고 $`k`$ 값과 샘플 크기 $`n`$의 효과를 탐구하는 시뮬레이션 연구를 상세히 설명합니다. 마지막으로, 섹션 [ref6]에서는 우리의 작업의 의미와 향후 연구 방향에 대해 논의합니다.
우리는 이 연구가 SMOTE의 이론적 이해를 크게 높이고 기계 학습에서 데이터 증강 기법을 더욱 탐구하는 길을 열 것이라고 믿습니다.
불균형 데이터를 처리하는 것은 여전히 활발한 연구 분야입니다. 다양한 샘플링 알고리즘이 개발되었지만, SMOTE 알고리즘은 논문에서 가장 널리 알려진 방법 중 하나입니다. Chawla 등이 2002년에 처음 제시한 SMOTE는 다양한 응용 분야에서 성공적으로 적용되었습니다. SMOTE의 여러 가지 확장 버전들은 원래 알고리즘의 샘플링 성능을 향상시키기 위해 개발되었습니다. 예를 들어, Adaptive Synthetic (ADASYN) 알고리즘은 생성되는 샘플 수를 클래스별로 다르게 조정하며, Borderline SMOTE는 경계 표본을 식별하고 이를 사용하여 새로운 합성 인스턴스를 만듭니다. 또한 SVM-SMOTE는 지원 벡터 머신을 SMOTE 프레임워크에 통합하였습니다. 최근에는 Center Point SMOTE, Inner and Outer SMOTE, DeepSMOTE 및 Deep Attention SMOTE 등이 제안되어 SMOTE의 적용성과 효능성을 더욱 확장하고 있습니다.
SMOTE의 인기와 널리 퍼진 사용에도 불구하고 이론적 속성을 분석하는 연구는 매우 적습니다. King과 Zeng은 로지스틱 회귀에서 무작위 약샘플링 전략의 이론적 측면을 이해하려고 시도하였습니다. Elreedy와 Atiya는 SMOTE 생성 패턴의 기대값과 공분산 행렬을 파악하였습니다. 최근에는, Elreedy 등은 방정식 [ref7]에서 $`Z`$의 이론적 분포를 개발했습니다. 그러나 방정식 [ref7]은 두 중적분 형태로 표현되어 실용적이지 않습니다. Sakho 등은 기하학적 인수 대신 랜덤 변수를 사용하여 방정식 [ref7]을 다른 방법으로 도출하였습니다. Sakho 등은 $`Z`$가 $`X`$로 수렴하는 것을 연구하고, $`X`$의 지원이 제한된 경우 $`Z_{K,n}\mid X_c = x_c\to x_c`$가 확률적으로 수렴한다는 것을 보였습니다. 또한, 이들은 $`Z`$가 조건부 평균으로 $`X`$에 수렴한다는 증거를 제공하여 수렴 결과를 개선했습니다.
우리의 연구는 기존 문헌을 두 가지 방식으로 발전시킵니다. 첫째, 우리는 지원이 제한되지 않은 경우에도 $`Z`$가 확률적으로 $`X`$에 수렴한다는 것을 보여줍니다. 둘째, 우리는 지원이 제한된 경우 $`Z`$가 평균으로 $`X`$에 수렴함을 보여주며, 이는 확률적 수렴보다 강력한 수렴 형태입니다.
주요 결과
연속 랜덤 변수 $`X`$, 누적 분포 함수 $`F`$ 및 확률 밀도 함수 $`f`$를 가정합니다. 독립 동일 분포(i.i.d.) 표본 $`X_1, X_2, \dots, X_n`$이 $`X`$로부터 추출된다고 고려합니다. SMOTE-$`k`$ 절차를 통해 생성된 랜덤 변수 $`Z`$에 대해 $`n\rightarrow \infty`$일 때 $`Z`$가 $`X`$로 수렴한다는 것을 보여줍니다.
입력: 샘플 $`(X_1, X_2, \dots, X_n)`$과 이웃 순위 $`1\leq k\leq n-1`$
출력: 합성 샘플 $`Z`$
무작위로 인스턴스 $`X_i`$를 선택합니다.
$`X_i`$의 $`k`$번째 최근접 이웃을 찾습니다. 이를 $`X_{i,(k)}`$라고 합니다.
$`\lambda \sim U(0, 1)`$를 생성합니다.
합성 포인트 $`Z= X_i + \lambda (X_{i,(k)} - X_i)`$를 만듭니다.
반환: $`Z`$
SMOTE-$`k`$ 알고리즘의 더 일반적인 버전이 있으며, 이는 섹션 [ref8]에서 논의됩니다. 특히, SMOTE-$`k`$ 알고리즘에 대한 모든 결과는 더 넓은 알고리즘에도 적용됩니다.
정리 1. $`X`$가 연속 랜덤 변수라고 가정합니다. $`Z`$는 독립 동일 분포(i.i.d.) 표본 $`X_1, X_2, \dots, X_n`$에서 추출된 SMOTE-$`k`$ 절차를 통해 생성된 랜덤 변수입니다. 그러면 $`n\rightarrow \infty`$일 때 $`Z`$가 확률적으로 $`X`$에 수렴합니다.
증명. $`F`$는 연속 누적 분포 함수이고, $`f`$는 $`X`$의 대응하는 확률 밀도 함수입니다. $`X_1, X_2, \dots, X_n`$이 독립 동일 분포 표본이라는 가정 하에 $`Z`$가 $`X_1`$과 그 $`k`$번째 최근접 이웃 $`X_{1,(k)}`$ 사이에서 생성되었음을 가정할 수 있습니다. 우리는 $`Z`$가 확률적으로 $`X_1`$로 수렴한다는 것을 보여줄 것입니다, 즉,
따라서 $`D_{(k)} = |X_{1,(k)} - X_1|`$는 $`X_1`$에서 다른 샘플 포인트까지의 $`k`$번째 가장 작은 거리입니다. 우리의 목표는 $`P(D_{(k)} \geq \varepsilon)`$를 추정하는 것입니다.
$`Y`$를 $`X_2, X_3, \dots, X_n`$ 중에서 $`\varepsilon`$ 내에 있는 샘플 포인트의 수로 정의합니다:
MATH
Y = \sum_{i=2}^{n} \mathbf{1}_{\{ D_i \leq \varepsilon \}},
클릭하여 더 보기
여기서 $`\mathbf{1}_{\{ D_i \leq \varepsilon \}}`$는 $`D_i \leq \varepsilon`$일 때 1이고 그렇지 않으면 0인 지시 함수입니다. $`X_1 = x_1`$이 주어졌을 때 각 $`D_i`$는 서로 독립이며, 사건 $`\{ D_i \leq \varepsilon \}`$은 성공 확률
우리의 목표는 이 기대값이 $`n \to \infty`$일 때 0으로 수렴한다는 것을 보이는 것입니다. 이를 위해, 모든 $`\delta > 0`$에 대해 $`f`$가 적분 가능하므로 다음을 만족하는 컴팩트 집합 $`S \subset \mathbb{R}`$이 존재합니다: