- Title: OpenSocInt A Multi-modal Training Environment for Human-Aware Social Navigation
- ArXiv ID: 2601.01939
- 발행일: 2026-01-05
- 저자: Victor Sanchez, Chris Reinke, Ahamed Mohamed, Xavier Alameda-Pineda
📝 초록
(이 논문에서는 사회 상호작용을 시뮬레이션하고 다양한 센서 데이터를 처리하는 오픈 소스 프레임워크인 OpenSocInt에 대해 설명한다. 이 시스템은 에이전트가 사회적 상황에서 행동할 수 있도록 학습시키는데 중점을 둔다. 그중 하나는 인간을 인식하는 사회적 네비게이션이다.)
💡 논문 해설
1. **오픈 소스 프레임워크 제공:** 이 논문은 OpenSocInt라는 오픈 소스 프레임워크를 소개하는데, 이를 통해 연구자들은 다양한 센서 데이터와 사회 상호작용을 시뮬레이션할 수 있다. 이는 마치 여러 도구가 들어있는 키트처럼, 연구자가 필요한 기능만 골라 사용할 수 있도록 설계되었다.
2. **다양한 학습 모델 지원:** OpenSocInt는 다양한 강화학습 알고리즘을 지원하며, 이를 통해 에이전트는 복잡한 사회 상호작용을 이해하고 학습할 수 있다. 이는 마치 여러 가지 음식을 섞어 맛있는 요리를 만드는 것과 같으며, 각각의 강화학습 알고리즘이 서로 다른 조미료와 같다.
3. **유연한 데이터 표현 방식:** 에이전트가 사용할 수 있는 다양한 입력 모달성을 제공하며, 이를 통해 에이전트는 상황에 따라 가장 적합한 정보를 활용할 수 있다. 이는 마치 여러 종류의 지도를 가지고 여행하는 것과 같으며, 필요에 따라 가장 유용한 정보만을 선택하여 사용할 수 있다.
📄 논문 발췌 (ArXiv Source)
# 소개
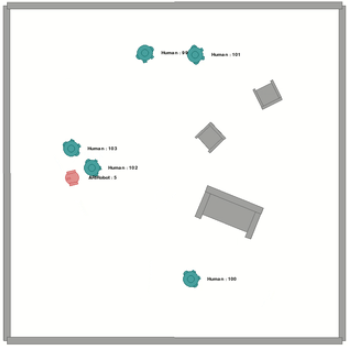
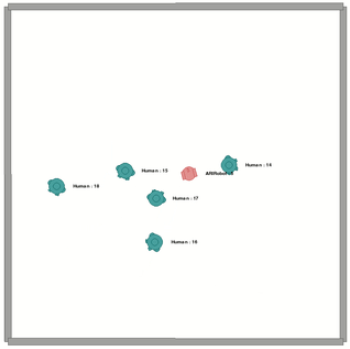
사회 상호작용의 계산적 연구는 비디오 게임, 가상 현실, 사회 로봇 등에 많은 응용 분야를 가지는 중요한 연구 분야이다. 이 분야는 본질적으로 다중 모달(multi-modal)로, 실제로 사용되는 센서가 여러 종류가 있다는 점에서 그렇다. 이러한 센서의 예로 카메라, 라이다(LIDAR), 초음파, 마이크 등이 있다. OpenSocInt는 사회 상황을 시뮬레이션하고 다양한 센서 데이터를 처리하기 위한 프레임워크를 제공하며, 주요 목표는 에이전트가 사회적 상호작용에 참여하도록 학습시키는 것이다. 가장 대표적인 예시로는 인간 인식 사회 네비게이션이 있으며, 이 환경의 두 가지 예(장애물/가구가 있는 경우와 없는 경우)는 [그림 1]에 제공되어 있다.
OpenSocInt의 환경 시뮬레이션 예시 (왼쪽): 장애물이 없는 경우, (오른쪽) 장애물이 있는 경우.
모듈형 아키텍처
OpenSocInt는 세 가지 다른 모듈로 구성되어 있다: 시뮬레이터, 에이전트, 환경. [그림 2] 참조.
/>
OpenSocInt의 모듈형 아키텍처: 에이전트는 행동을 취하고 환경으로부터 관찰과 보상을 받는다. 이러한 행동 후, 환경은 시뮬레이터에 질의를 보내고 시뮬레이션 데이터로부터 보상과 새로운 관찰을 계산한다.
시뮬레이터 모듈
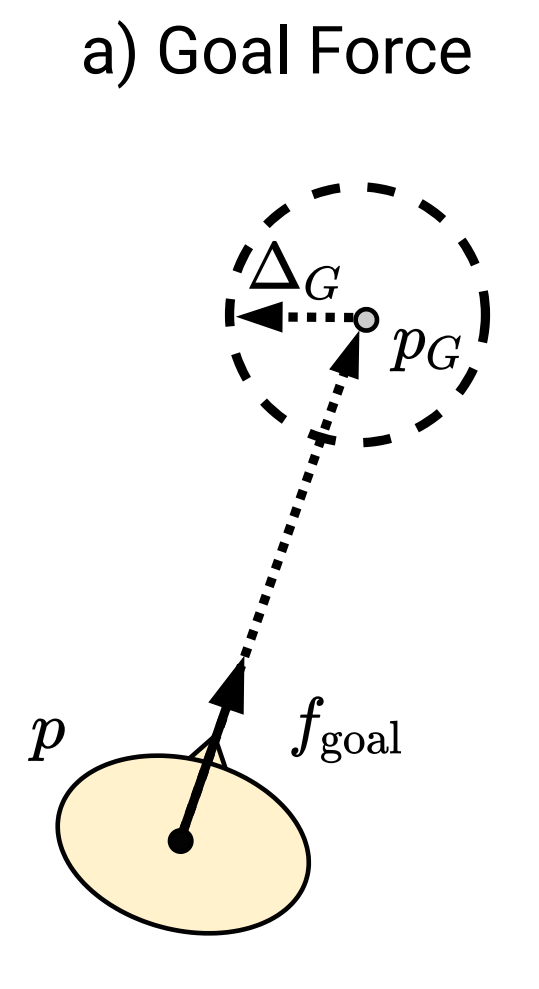
이 모듈은 장면의 상태를 추적하고, 환경으로부터 에이전트에 대한 정보를 받아 상태를 업데이트하며, 업데이트된 상태를 환경에 제공하는 역할을 한다. 내부적으로, 시뮬레이터는 에이전트의 위치, 동적 및 정적인 장애물의 위치([그림 1 참조])와 에이전트 목표의 위치(각도와 거리)를 알고 있다.
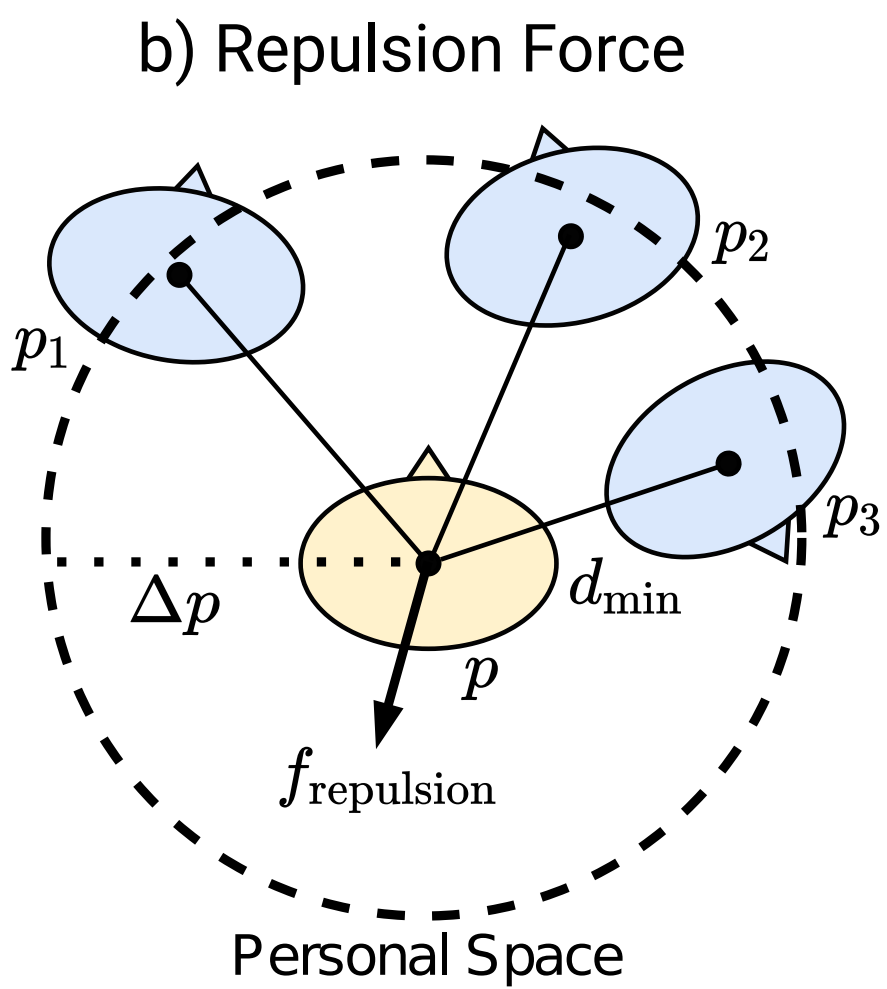
시뮬레이터 모듈에서 사용되는 목표 힘 (왼쪽) 및 사회/반발 힘 (오른쪽)의 다이어그램.
새로운 상태를 계산하기 위해, 시뮬레이터는 에이전트와 동적 장애물(인간)의 다음 위치를 계산해야 한다. 각 인간은 목표를 가지고 있다고 가정하며, 각 사람의 새로운 위치는 사회 힘 모델과 목표 힘 모델의 가중 합을 통해 계산된다. 후자의 경우, 힘은 목표 방향으로 지향되며 거리에 비례한다(최대 단위 값). 반면 전자는 인간들이 서로 너무 가까이 있지 않도록 하는 반발 힘을 기반으로 한다([그림 3 참조]). 이 반발 힘은 에이전트를 고려하지 않는다. 초기 실험에서는 에이전트가 이를 활용하여 사람들이 떨어지게 만들어 목표로 직진하는 것을 배울 수 있음을 보여주었다.
환경 모듈
이 모듈의 목적은 에이전트와 시뮬레이터 간의 통신을 용이하게 하는 것이다. 한편, 에이전트가 취한 행동은 환경으로 전송되어 시뮬레이션 시간을 진행한다. 시뮬레이터 내부 상태는 받은 행동에 따라 업데이트되며, 새로운 상태는 다시 환경 모듈로 전달된다. 이 모듈은 새로운 상태를 하나 이상의 센싱 모달리티로 변환한다.
첫 번째 센싱 모달리는 에이전트 기준으로 가장 가까운 장애물(정적 또는 동적)의 좌표(직교좌표나 극좌표 형식)를 포함한다. 이 센싱 모달리는 간단한 편이지만 많은 정보가 부족하다는 단점이 있다. 두 번째 접근 방식은 로봇 주변의 LIDAR 데이터로, Raycast 형태로 변환된다. 데이터 차원은 고정되어 있으며 원하는 정확도에 따라 달라진다. 예를 들어, 로봇 주변 각각의 거리를 측정하면 360개 값이 있는 벡터가 생성된다. 이 형식은 전자의 것보다 약간 복잡하지만 훨씬 더 많은 정보를 인코딩한다. LIDAR 사용 시에는 가려진 장애물이 표현되지 않는다. 세 번째 접근 방식은 로봇 주변의 공간을 나타내는 현지 중심 점유 그리드(LEOG)를 사용하는 것이다. 그리드의 각 요소는 해당 요소가 점유되어 있으면 1, 그렇지 않으면 0이다. 이 표현의 크기는 맵의 크기와 해상도에 따라 달라진다. 예를 들어, $`6~\textrm{m}\times 6`$ m 그리드와 각 픽셀당 $`0.1`$ m의 정밀도는 $`60\times 60`$ 이미지를 생성한다. 환경은 에이전트가 사용하는 입력에 따라 시뮬레이션 상태를 이러한 표현 중 하나 이상으로 변환할 수 있다.
또한, 시뮬레이션 상태의 표현 외에도, 환경은 에이전트 목표의 상대 위치와 시뮬레이터 데이터로부터 계산된 보상을 전달한다.
/>
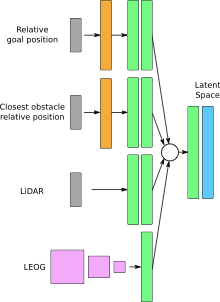
다양한 입력 모달리티를 처리하기 위한 아키텍처. 합성곱 층(LEOG에 대한 것)은 분홍색, 완전 연결 층은 초록색, 라디얼 기저 함수 층은 오렌지색으로 표시되어 있다. 원은 다중 모달 융합을 나타낸다. 구현된 다양한 에이전트는 파란색 상자에 표시된 잠재 공간에서 시작한다.
에이전트 모듈
에이전트는 관찰(시뮬레이션 상태의 표현, 하나 이상의 모달리티), 목표 위치, 그리고 얻은 보상을 받는다.
학습 시, 관찰은 네트워크를 통해 전송되어 취한 행동과 학습에 필요한 다른 값을 출력한다. 이러한 값들은 사용하는 딥 RL 패러다임에 따라 달라진다(아래 참조). 손실이 계산되고 역전파된다. 선택된 행동은 환경으로 다시 전달되며, [그림 2]에서 보는 것처럼 루프를 완성한다.
다양한 모달리티를 입력하는 다중 모달 에이전트 아키텍처는 [그림 4]에 표시되어 있다. 잠재 공간(파란색 상자)은 하나 이상의 모달리티와 에이전트 목표로부터 학습된다. LEOG는 몇 개의 합성곱 층(분홍색)을 통해 처리되며, 평탄화되고 하나 이상의 완전 연결 층(초록색)을 통해 변환된다. LIDAR(RayCast)와 다른 두 가지 모달리티는 하나 이상의 완전 연결 층을 통해 변환된다. 매우 저차원 입력(e.g., 목표 위치 및 가장 가까운 장애물 위치)에서 학습하는 것을 돕기 위해, 라디얼 기저 함수 층(오렌지색)이 사용되어 전체 연결층에 전달되기 전에 표현 차원을 증가시킨다. 하나 이상의 모달리티는 잠재 표현으로 결합되며, 이는 구현된 다양한 강화 학습 에이전트에 의해 사용된다.
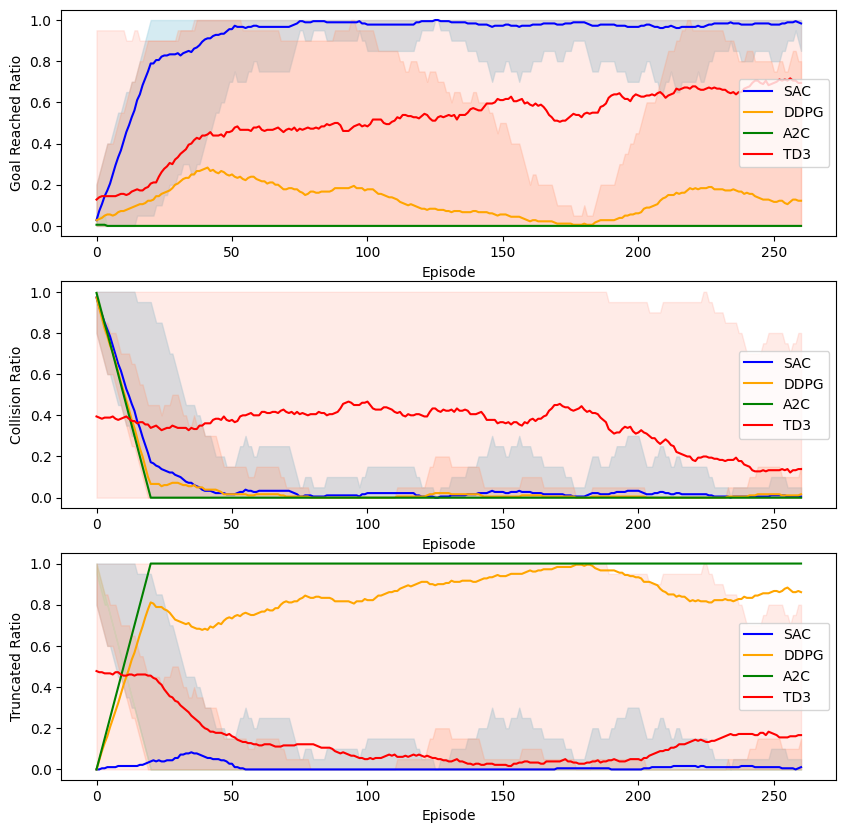
구현된 모든 에이전트는 동일한 잠재 표현(이미지에서 파란색)을 활용하며, 다음 딥 RL 패러다임을 포함한다: TD3, DDPG, A2C 및 SAC.
저장소
코드 저장소는 공개되어 있으며,[^1], agent와 env 폴더를 비롯하여 데이터셋 생성과 학습 레시피를 위한 몇 가지 유틸리티 폴더가 있다. 시뮬레이터는 별도의 저장소에 유지되며, 이는 시뮬레이터만 관심 있는 사용자가 전체 OpenSocInt 패키지를 다운로드할 필요가 없게 한다. 스크립트, 옵션 및 시각화 도구에 대한 자세한 설명은 README.md 파일에서 확인할 수 있다.
실험 프로토콜
제안된 소프트웨어 패키지의 사용을 검증하기 위해 위에서 설명한 환경과 시뮬레이터를 통해 강화학습 에이전트를 학습하는 일련의 실험을 수행했다. 여기에서는 실험 프로토콜의 주요 정보를 설명한다.
보상 함수
학습 중, 에이전트는 최적 행동을 배워야 한다. 이를 위해 에이전트는 특정 회수(episode) 동안 환경과 상호작용하며 행동을 취한다. 회수가 종료되는 세 가지 조건은 다음과 같다: 목표에 도달하거나 물체/인간과 충돌하거나, 최대 단계 수를 초과할 때까지 목표에 도달하지 않고 충돌하지 않은 경우(회수 상태는 “Truncated”로 표시된다). 에이전트의 최적 행동은 누적 보상을 최대화하는 것이다. 중간 단계에서의 보상 함수는 다음과 같다:
여기서 $`r_{\textsc{step}}(t) =-\omega_{step}`$은 불필요한 단계를 처벌하고, $`r_{\textsc{goal-d}}`$와 $`r_{\textsc{social}}`$는 [그림 3 참조]에서 보여주는 목표 방향 및 사회 반발 힘에 해당하며 각각 계수 $`\omega_{\textsc{goal-d}}`$와 $`\omega_{\textsc{social}}`$로 곱해진다. 목표 도달 또는 충돌 시(회수가 끝나는 경우)의 보상은 다음과 같다:
여기서 $`\gamma_{\textsc{goal-r}}(t)=1`$은 목표에 도달한 경우이고, 그렇지 않으면 0이며 $`\gamma_{\textsc{coll}}(t)`$는 충돌에 대해 유사하게 정의된다. 가중치 계수 값들은 당연히 우리의 패키지에서 매개변수화될 수 있다. 아래 실험에서는 다음과 같은 값을 사용한다: $`\omega_{\textsc{goal-r}}=500`$, $`\omega_{\textsc{coll}}=-500`$, $`\omega_{step}=-5`$, $`\omega_{\textsc{goal-d}}=10`$, 그리고 $`\omega_{\textsc{social}}=-100`$.
지표
학습 중 세 가지 지표의 변화를 보고한다. 첫 번째는 에이전트가 목표에 도달하여 회수를 끝낸 경우의 비율이다. 두 번째는 정적 또는 동적 장애물과 충돌하여 회수가 종료된 경우의 비율이다. 세 번째는 최대 단계 수까지 도달했지만 목표에 도달하지 않았거나 충돌하지 않은 경우의 비율이며, 이전 섹션 참조. 중요한 점은 이러한 지표가 학습 집합이 아닌 독립적인 셋에서 계산된다는 것이다. 즉, 재생 버퍼에는 포함되지 않는다. 정확히 말하면, 50회 학습 회수마다 모델을 20회의 테스트 회수로 평가하며, 700회 학습 회수(또는 280회 테스트 회수)까지 진행한다. 각 구성에 대해 이 작업은 5번 반복된다. 각 지표의 평균과 표준 편차는 10회의 테스트 회수를 포함하는 이동 윈도우에서 보고된다.
결과
LEOG 인코딩의 영향
RayCast와 가장 가까운 장애물 특성은 상대적으로 컴팩트하지만, LEOG는 압축 가능한 원시 특성이므로 이를 신경망을 통해 인코딩한다. 그러나 LEOG 인코더 사전 학습의 중요성을 평가해야 한다. 인코더를 사전 학습하기 위해, 에이전트는 무작위 정책을 사용하여 환경에서 데이터를 수집하도록 허용한다. OpenSocInt가 계산적으로 무거운 커스텀 시뮬레이터와 인터페이스되는 경우, 온라인으로 인코더 사전 학습이 불가능하므로 우리의 코드는 미리 생성된 데이터셋이나 기존 데이터셋을 사용하여 사전 학습할 수 있는 옵션도 제공한다. 핵심 학습 매개변수(e.g., 배치 크기)를 매개변수화하고, 학습 진행 상황을 시각화하는 도구도 제공한다.
다른 설정에 대한 성공률, 충돌률 및 중단률의 평균과 표준 편차. (a) LEOG 인코딩 전략: 사전 학습된 동결, 사전 학습 후 미세 조정, 처음부터 학습. (b) 다른 특성: LEOG, RayCast 및 가장 가까운 객체. (c) 특성 융합: LEOG, RayCast 및 LEOG+RayCast. (d) 다양한 RL 패러다임: SAC, TD3, DDPG, A2C.
모달리티의 영향
먼저 네트워크 입력으로 사용되는 특성의 영향을 분석한다. 다시 말해, 에이전트 기준 극좌표로 가장 가까운 장애물, LIDAR 또는 RayCast 정보 및 현지 중심 점유 그리드(LEOG)가 있다.
[그림 5]는 이러한 모달리티를 입력할 때의 지표를 보고한다.
비슷한 성능을 최종적으로 수렴하지만 학습 초기에는 눈에 띄는 차이점이 있다. 즉, RayCast와 가장 가까운 장애물과 같은 간단한 특성은 이해하기 쉽기 때문에 초기에는 우월하다. 그러나 LEOG 특성은 더 많은 데이터를 사용하여 학습할 때 동일한 평균 성능을 제공하고 표준 편차가 작아지므로 신뢰성이 높다.
모달리티 융합의 영향
이전 섹션에서 다양한 특성을 비교했으며, 여기서는 서로 다른 특성 모달리티를 결합하는 것의 이점을 고려한다.
[그림 6]은 이러한 모달리티의 융합 결과를 보고한다.
결과적으로 LEOG와 RayCast의 조합이 가장 우수한 성능을 나타내며, 각각 개별적으로 사용할 때보다 작은 표준 편차를 가진다. 이는 두 가지 특성 모달리티가 서로 보완적이라는 것을 의미한다.