- Title: Surprisal and Metaphor Novelty Judgments Moderate Correlations and Divergent Scaling Effects Revealed by Corpus-Based and Synthetic Datasets
- ArXiv ID: 2601.02015
- 발행일: 2026-01-05
- 저자: Omar Momen, Emilie Sitter, Berenike Herrmann, Sina Zarrieß
📝 초록
최근 언어 모델링의 발전은 전통적인 자연어 처리 시스템에서 어려웠던 언어 창조성 연구에 대한 새로운 관심을 불러일으켰다. 이 논문에서는 기존과 신규 메타포 사이의 차이점을 탐구하고, 언어 모델(LM)을 사용하여 메타포의 창조성을 측정하는 방법을 제안한다. 특히, LM에서 계산된 'surprisal' 점수와 메타포 창조성 간의 상관관계를 분석하며, 이를 통해 신규 메타포와 기존 메타포 사이의 차이점을 구분할 수 있는 새로운 방법을 제시한다.
💡 논문 해설
1. **기존과 신규 메타포의 구별**: 전통적인 자연어 처리 시스템은 메타포를 이해하는 데 어려움이 있었다. 이 논문에서는 언어 모델(LM)을 사용하여 기존 메타포와 신규 메타포 사이의 차이점을 분석한다. 이를 통해, 창조적 언어에 대한 새로운 이해가 가능하다.
Surprisal 점수를 통한 창조성 측정: ‘surprisal’은 단어의 확률을 기반으로 계산되는 값이며, 이는 인간이 문장을 읽을 때 얼마나 어려움을 겪는지를 예측하는 데 사용된다. 논문에서는 surprisal 점수를 메타포 창조성 측정에 활용한다.
cloze-surprisal 방법론: 기존의 surprisal 계산은 문장의 왼쪽만 고려하므로, 이는 문맥을 완전히 이해하는 데 한계가 있다. cloze-surprisal 방법론은 단어의 오른쪽 문맥까지 고려하여 더 정확한 창조성 측정이 가능하도록 한다.
📄 논문 발췌 (ArXiv Source)
# 들어가며
최근 언어 모델링의 발전은 전통적인 자연어 처리(NLP) 시스템에서 어려웠던 언어 창조성 연구에 대한 새로운 관심을 불러일으켰다. 창조적 언어의 한 예로 메타포가 있으며, 이것은 소스 도메인(문장 단위의 직역 의미)을 타겟 도메인(비직역적 의미)으로 매핑하여 발생한다. 그러나 모든 메타포가 동일한 수준의 창조성을 가진 것은 아니다. 많은 경우 이러한 매핑은 매우 통상적이며, 예를 들어 “논지를 공격하다"라는 표현에서 보듯이 소스 도메인 “전쟁”을 타겟 도메인 “논쟁”으로 매핑하는 것은 사전에도 나올 수 있는 일반적인 의미이다. 다른 메타포는 “체포된 물” (Figure 1)과 같이 더 비통상적이고 창조적인 매핑을 수립한다.
style="width:100.0%" />
VUA-ratings에서 메타포 창조성 평가(n)와 GPT2-base의 놀라움 측정(s)을 보여주는 문장. 상단은 직접-놀라움 측정, 하단은 cloze-놀라움 측정을 나타낸다.
통상적 메타포와 신규 메타포 사이의 구분은 이론적으로 잘 정립되어 있으며 인지 처리 실험에서도 연구되었다. 신규 메타포는 통상적인 메타포보다 더 많은 해석 노력이 필요하다. 이러한 새로운 연결을 만드는 과정에서 통상적 메타포와 비교해 복잡성이 증가한다.
그러나 인간 주석자가 신규 메타포를 구별하는 것은 여전히 어려운 작업이다. 메타포 분석에 대한 계산 방법은 종종 창조성 차원을 고려하지 않으며, 일부 연구는 신규 메타포의 감지가 통상적 메타포보다 더 어렵다는 점을 강조한다. 이 논문에서는 LMs가 통상적 및 신규 메타포를 처리하는 과정과 LM 기반 지표와 다양한 메타포 창조성 주석 방법 간의 상관관계에 대한 질문을 탐구하여 이러한 연구의 공백을 채우려고 한다.
우리는 언어 모델(LM)이 인간 문장 처리의 어려움 효과를 설명할 수 있는 능력을 연구하는 연구 라인을 기반으로 한다. surprisal은 LM에서 문맥 내 단어의 음수 로그 확률로 계산되며, 이를 통해 인간의 처리 어려움(예: 읽기 시간)에 대한 강력한 예측치를 제공할 수 있다.
최근 연구는 어떤 LM이 가장 견고하고 인지적으로 타당한 처리 어려움 예측을 제공하는지를 나타내는 혼합된 그림을 보여준다. GPT-2 모델의 다양한 크기에서 surprisal 추정치를 테스트했을 때, 작은 모델 크기를 사용하여 계산한 surprisal이 큰 모델보다 인간 읽기 시간과 더 잘 맞는 역 스케일 효과가 관찰되었다. 반면에, 작은 규모와 중간 규모의 LM을 여러 언어로 학습시켜 보니 LM 품질은 일반적으로 읽기 시간 예측력과 연관이 있다는 것을 발견했다.
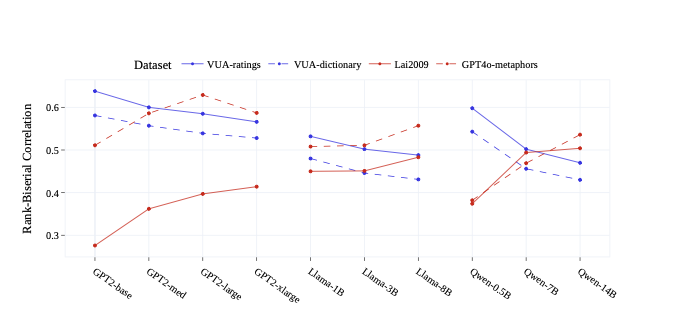
이 논문에서는 다양한 LMs에서 계산된 메타포 단어의 surprisal 점수를 창조성 지표로 사용하여 실험을 수행한다. 결과는 LMs의 surprisal과 다양한 메타포 창조성 주석 사이에 중요한, 긍정적이고 중간 수준의 상관관계가 있다는 것을 발견한다. 네 가지 다른 데이터셋에서 실험을 수행하였으며, 두 개의 코퍼스 기반 신규 데이터셋에서는 “역 스케일” 패턴이 지원되는 효과를 관찰했고, 반대로 두 개의 합성 데이터셋에서는 “품질-예측력” 가설을 뒷받침하는 모순적인 패턴을 발견했다. 우리는 지시어 튜닝이 surprisal과 메타포 창조성 간의 상관관계에 미치는 영향도 조사한다. 또한 장르 분할에 대한 깊은 분석을 수행하여 장르, 메타포 밀도 및 LM perplexity가 surprisal 예측력의 품질을 결정하는 잠재적 요인임을 발견했다. 마지막으로, 단어의 조건부 확률에 오른쪽 문맥을 포함시키는 새로운 surprisal 계산 방법인 cloze-surprisal을 제안한다. 이를 통해 surprisal과 메타포 창조성 주석 간의 상관관계를 몇 가지 점 높일 수 있다. 일반적으로 본 연구는 LMs로 언어 창조성을 연구하는 새로운 방향을 열며, 장르별로 체계적인 메타포 창조성 주석이 제공되는 새로운 측정 방법과 데이터셋의 필요성을 강조한다.
관련 작업
메타포 주석
코퍼스 기반 메타포 연구에서 가장 일반적으로 사용되는 주석 스키마는 Vrije Universiteit (MIPVU)에서 설계한 메타포 식별 절차이다. 이 방법은 문맥상 비직역적으로 사용된 단어를 식별하기 위한 신뢰할 수 있는 단계별 프레임워크로, 이를 통해 VU Amsterdam Metaphor Corpus (VUAMC)을 구성하였다. 이 코퍼스는 BNC Baby 에디션에서 소설, 뉴스, 학술 글쓰기 및 대화 분할에서 샘플링한 186,673단어를 포함하며 장르 균형이 잘 맞춰진 대규모 코퍼스이다. VUAMC는 메타포 연구의 벤치마크가 되었으며, 이후 영어 코퍼스 및 다국어 노력에 영감을 주었다.
다수의 연구에서는 이진ITERAL/METAPHOR 라벨링을 넘어서 확장된 주석을 제시하였다. 네 단계 메타포성 척도를 도입하여 선명성과 친숙도 같은 요소를 고려하였다. 또한, “의도성"이라는 개념을 제안하여 특정 메타포가 의도적으로 인식되어야 하는지 구분하였다. 이 프레임워크에서 신규 메타포는 일반적으로 의도적이다. 직접적인 창조성 주석은 VUAMC의 메타포 단어 쌍에 대한 0-3 점 창조성 척도로 평가하도록 주석자를 요청하여 처음 도입하였다. 또한, 모든 메타포 단어를 고려하는 종합적인 접근법을 제안하였으며, 순위별 창조성 판단을 연속점수로 집계하였다. 최근에는 사전 기반 방법이 제안되어 문맥적 의미가 사전 항목에서 누락된 경우 메타포를 신규로 표시하도록 하였다.
심리언어학 연구도 메타포 데이터셋을 생성하지만, 이러한 데이터셋은 크기가 작고 통제된 합성 문장(고정 단어, 구조, 문장 길이 등)을 특징으로 한다. 일부는 기존 또는 신규 메타포로 분류되는 메타포의 데이터셋도 생성하였다.
Surprisal의 예측력
LM에서 계산된 surprisal 추정치는 여러 행동적 및 뉴런 측정에 대해 인간 처리 어려움을 포착한다. 독자 속도와 눈트래킹 연구에서는 인과 모델에서 단위 수준 surprisals이 단어 및 구문 요인을 넘어서 읽기 시간을 예측하는 데 유의미한 영향을 미친다. 비슷한 효과는 문법성에 대한 인간 민감도와 LM surprisal 간에 보고되었다.
LM 기반 메타포 창조성 지표
최근 연구에서는 다양한 LM 기반 접근법—프롬팅, surprisal, 임베딩 유사성 및 주의 패턴—을 사용하여 은유적 언어를 분석하였다. 다국어 사전 훈련된 LMs의 중간 계층 임베딩에 메타포 관련 정보가 인코딩됨을 보여주었다. 또한 GPT-4는 대학생보다 인간 심사관이 선호하는 새로운 문학적 메타포 해석을 생성함으로써 어휘 오버랩을 넘어서 은유적 의미에 민감하다는 것을 시사한다. BERT의 마스킹된 토큰 확률을 측정하여 기존, 신규 및 무의미한 메타포를 검증하였으며, 새로운 메타포가 낮은 확률을 받지만 창조성과 무의미함 사이의 구분이 명확하지 않았다. 우리는 이를 최근 LMs와 더 넓은 모델, 데이터셋, 장르 간 비교로 확장한다. 또한 BERT 기반 분류기를 훈련시켜 메타포 감지 작업과 함께 창조성 점수를 예측하도록 하였다.
MIPVU 절차에 따라 VUAMC의 모든 단어는 메타포 관련 단어(MRW) 또는 그렇지 않은 것으로 주석화되었다. 186,673단어 중 24,762단어(15,155개의 내용 단어)가 MRW로 표시된다. 원래 VUAMC에는 창조성 주석이 포함되어 있지 않지만, 우리는 같은 코퍼스에 대한 다양한 주석 프로토콜을 제공하는 두 개의 주석 연구를 활용한다.
VUA-ratings
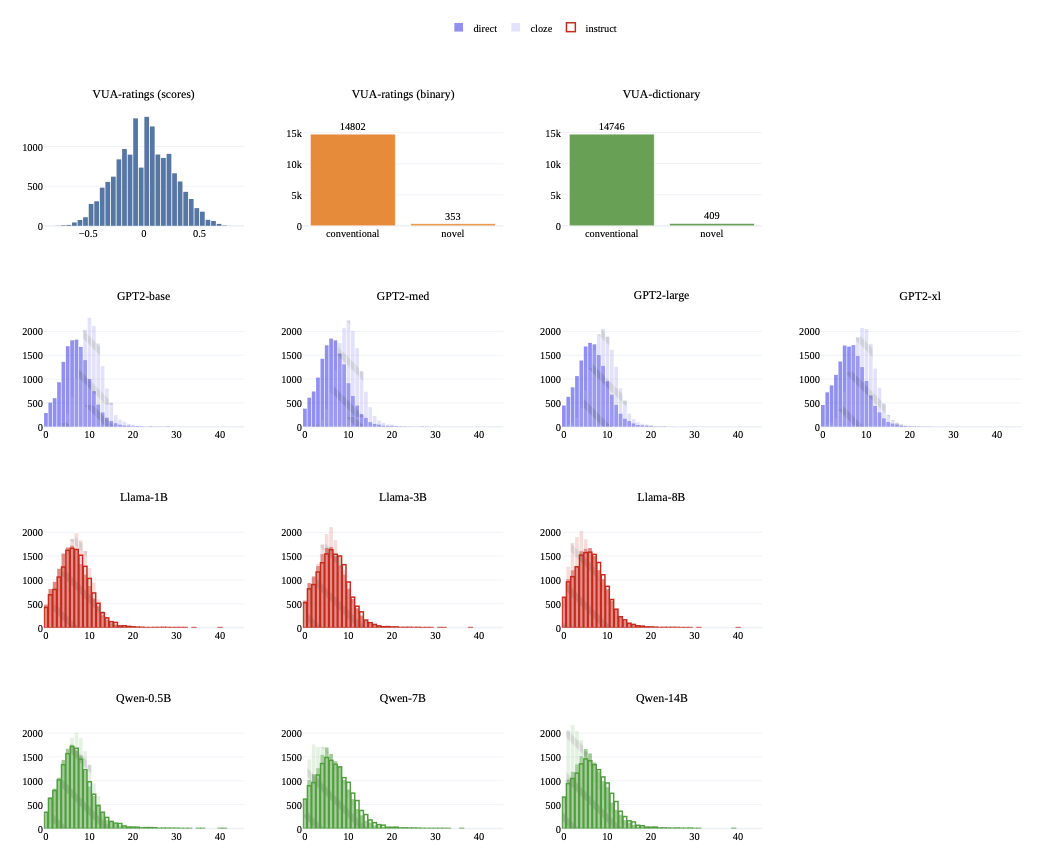
VUAMC의 메타포 창조성에 대한 대중 소싱된 점수를 수집하였다. 그들의 설정에서, 주석자는 4개의 문장 중 하나가 MRW(내용 단어만)를 포함하고 있는지 확인하도록 요청되었다. 각 MRW는 6개의 다른 최고-최악 스케일링 비교에 나타났다. 이러한 주석들은 -1부터 +1까지의 범위에서 연속적인 Best-Worst Scaling 점수로 변환되었으며, 이는 -1이 가장 통상적이고 +1이 가장 창조적인 것을 의미한다. 또한 0.5의 임계값을 사용하여 이러한 점수를 이진 라벨로 변환하였다. 이를 통해 VUA에서 15,155개의 내용 메타포 단어 중 353개의 메타포가 신규로 표시되었다.
VUA-dictionary
사전 기반 방법을 제안하여 문맥적 의미가 사전 항목에 없는 경우 메타포를 신규로 표시하였다. 이 방법은 VUAMC에 적용되었으며, 특히 VUA-ratings와의 메타포 의도성 주석에 따라 잠재적으로 신규 메타포(총 1,160개)를 재주석화하였다. 그들의 절차는 1,160개 중 409개의 내용 메타포 단어만을 신규로 표시하도록 하였다. 연구에서는 VUA의 나머지 메타포를 통상적이라고 가정한다.
합성 데이터셋
합성 메타포 창조성 데이터셋은 주로 고정된 소스에서 생성되는 특징을 가지고 있다. 일반적으로 대상 메타포 단어에 대한 비교 가능한 문장이 포함된다. 우리는 두 가지 유형의 이러한 데이터셋을 검토한다: 심리언어학 연구에서 기존 및 신규 메타포를 다룬 합성 데이터셋과 GPT-4o로 생성한 토이 데이터셋이다.
Lai2009
우리가 어떻게 뇌가 기존 및 새로운 메타포를 다르게 처리하는지 조사하였다. 이를 위해, 그들은 두 가지 창조성 정도의 메타포를 포함하는 제어 실험 항목을 구성했다. 두 명의 언어학자가 104개 단어를 선택하고 각 단어에 대해 총 4개의 문장을 구성하였으며 Conceptual Metaphor Theory (CMT)에 따라, 각 단어는 하나의 직접적인 사용, 하나의 통상적 메타포, 하나의 신규 메타포 및 하나의 이상한 사용을 포함하며, 대상 단어가 각 문장의 마지막 단어로 나타난다. 친숙성과 해석 가능성 테스트에서 통상적이고 새로운 메타포 의미 사이에 유의미한 차이를 보였다. 실험에서는 각 단어의 통상적 및 신규 메타포 의미만을 선택하여 208개 문장(통상적인 104개, 신규 104개)을 얻었다.
GPT-4o-metaphors
VUA와 대비되는 더 엄격한 설정이나 Lai2009에 비해 다양성 있는 문장 길이, 구조 및 창조성 정도를 갖춘 환경에서 실험을 테스트하기 위해 합성 데이터셋을 구성하였다. GPT-4o에게 통상적이고 신규 메타포 의미로 사용할 수 있는 5개의 동사와 5개의 명사를 생성하도록 요청하였다. 각 단어에 대해, 모델이 대상 단어를 통상적인 의미에서 10가지 다른 문장과 신규 의미에서 10가지 다른 문장을 생성하도록 다시 프롬프트를 주었다. 결과적으로 200개의 문장 데이터셋을 얻었으며, 그 중 100개는 통상적 메타포를 포함하고 있으며 나머지는 신규 메타포를 포함한다.
방법 및 실험
LM에서 계산된 surprisal 점수와 다양한 메타포 창조성 주석 간의 상관관계를 탐구하기 위한 실험을 설명한다.
대상 단어의 surprisal
정보 이론에서는 확률 $`p(x)`$가 있는 사건 $`x`$의 정보량은 다음과 같이 정의된다: $`I(x) = -\log p(x)`$. LMs를 사용하여 시퀀스의 다음 토큰을 예측하도록 학습한 경우, 이러한 양은 surprisal로 불리며 순서 내의 단어 $`w_i`$에 대해 다음과 같이 계산된다: $`\mathrm{Surprisal}(w_i) = -\log p(w_i \mid w_{
실험에서는 문장 수준 문맥에서 메타포 단어의 단위 surprisal을 측정한다. 모든 문장을 독립적인 선생님 강제 전방 패스에 LM에 입력하고 대상(메타포) 단어(s)의 surprisal을 기록한다. 이를 direct-surprisal이라고 명명하여 cloze-surprisal과 구분한다.
대부분의 LMs는 단어보다 서브워드를 사용하므로, 단위 surprisal 추정치와 그에 따른 하류 측정에 영향을 미칠 수 있는 구현 선택이 필요하다. 투명성 및 재현성을 위해, 우리의 구현에서 surprisal 값을 계산하는 데 영향을 미치는 두 가지 선택사항을 보고한다. 첫째, 정확한 대상 단어의 오프셋을 사전에 계산하여 해당 문장의 LM 토큰화에 대한 최소 스패닝 토큰을 검색하고 이를 통해 일반적으로 대상 단어와 함께 앞쪽 공백 문자가 추가되는 방식으로 정확한 단어로 대응한다. 예를 들어 ‘‘Ġarrested’’은 “arrested"에 해당하며, 매우 드문 경우로 마지막 토큰이 구두점에 연결되어 있다 (예: [‘‘Ġindivid’’, ‘‘ual’’, ‘‘ism,’’]는 “individualism”을 나타냄). 또한 대부분의 인과 LM의 토큰화에서 앞쪽 공백문자 문제를 해결하기 위한 수정사항도 적용한다. 둘째, surprisal은 문장 내 이전 단어가 현재 단어가 대상 단어일 확률을 조건으로 계산된다. 따라서 문장의 첫 번째 단어에 대한 surprisal을 계산하는 것은 문제가 될 수 있다. 문장의 첫 번째 단어에 대한 surprisal을 계산하기 위해 입력 문장을 “시퀀스 시작” 특수 토큰으로 앞쪽에 붙여준다.
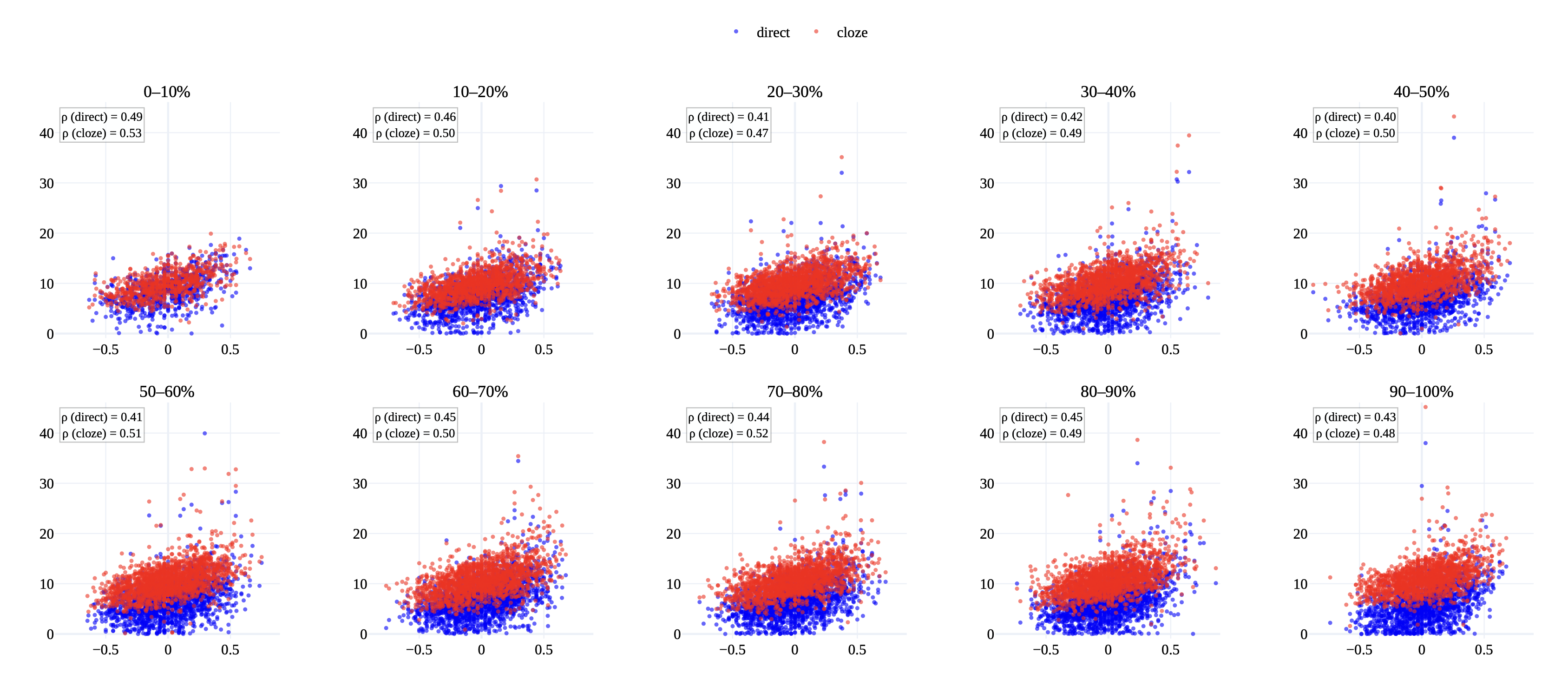
cloze-surprisal
표준 (왼쪽에서 오른쪽) surprisal은 의미적 문맥 속성을 예측하는 데 사용되는 대리로서 단어의 미래(오른쪽) 문맥을 조건화하지 않는다는 한계가 있다. 이는 자연적으로 발생하는 코퍼스 데이터(VUA 데이터셋 포함)에서 메타포 단어가 여러 문장 위치에 나타날 수 있으며, 일부 경우 GPT-4o-metaphors 데이터셋에서도 문제가 된다 (Table [tab: data_examples] 참조). 오른쪽 문맥을 포함하면서 자동회귀 설정을 유지하기 위해, 우리는 단어의 조건부 확률에 오른쪽 문맥을 포함시키는 cloze-surprisal 방법을 계산한다.