- Title: Enhancing Object Detection with Privileged Information A Model-Agnostic Teacher-Student Approach
- ArXiv ID: 2601.02016
- 발행일: 2026-01-05
- 저자: Matthias Bartolo, Dylan Seychell, Gabriel Hili, Matthew Montebello, Carl James Debono, Saviour Formosa, Konstantinos Makantasis
📝 초록
컴퓨터 비전 분야에서 객체 검출은 주요한 문제로, 자율 시스템, 환경 모니터링, 로봇공학 등 다양한 분야에 응용됩니다. 이 연구에서는 학습 중 특권 정보를 활용하는 Learning Under Privileged Information (LUPI) 패러다임을 객체 검출에 적용하여, 기존 방법보다 더 우수한 성능을 달성할 수 있는지 실험적으로 검증합니다.
💡 논문 해설
1. **효과적인 특권 정보 활용**: 이 연구는 학습 과정에서 추가적인 정보를 사용해 모델의 성능을 향상시키려고 합니다. 이를 통해 더 많은 데이터나 오랜 시간이 필요하지 않아도 높은 정확성을 달성할 수 있습니다.
2. **LUPI 패러다임 적용**: LUPI는 학습과 추론 사이에 정보 불균형을 해결하는 방법으로, 특권 정보를 활용하여 모델의 성능을 향상시킵니다.
3. **다양한 객체 검출 모델에서의 실험**: 여러 오픈 소스 기반의 객체 검출 모델과 데이터셋을 사용해 LUPI 패러다임이 실제 성능에 미치는 영향을 평가합니다.
단순 설명 및 비유
초급자: 이 연구는 학습 도중 추가적인 정보를 활용하여 더 정확한 예측 모델을 만드는 방법을 제시합니다. 이것은 마치 공부할 때 참고서를 사용해 더 잘 이해하고 기억하는 것과 같습니다.
중급자: LUPI 패러다임은 학습 과정에서만 사용 가능한 추가 정보를 활용하여, 실제 추론에서는 사용하지 않아도 모델의 성능을 향상시킵니다. 이것은 마치 실전 시험에서는 참고서를 볼 수 없지만, 공부할 때는 참고서를 이용해 더 잘 배울 수 있는 것과 같습니다.
고급자: 이 연구는 학습 과정에서 특권 정보를 활용하여 모델의 성능을 향상시키는 방법을 제시합니다. LUPI 패러다임은 기존의 데이터와 함께 추가적인 정보를 사용해 더 정확한 예측을 가능하게 합니다.
Sci-Tube 스타일 스크립트
초급자: “이 연구에서는 학습 과정에서 추가적인 정보를 활용하여 더 정확한 모델을 만드는 방법을 제시합니다. 이것은 공부할 때 참고서를 사용해 더 잘 이해하고 기억하는 것과 같습니다.”
중급자: “LUPI 패러다임은 학습 과정에서만 사용 가능한 추가 정보를 활용하여, 실제 추론에서는 사용하지 않아도 모델의 성능을 향상시킵니다. 이것은 실전 시험에서는 참고서를 볼 수 없지만, 공부할 때는 참고서를 이용해 더 잘 배울 수 있는 것과 같습니다.”
고급자: “이 연구는 학습 과정에서 특권 정보를 활용하여 모델의 성능을 향상시키는 방법을 제시합니다. LUPI 패러다임은 기존의 데이터와 함께 추가적인 정보를 사용해 더 정확한 예측을 가능하게 합니다.”
📄 논문 발췌 (ArXiv Source)
컴퓨터 비전, 지식 증류법, 특권 정보 활용 학습, 쓰레기 감지, 객체 검출
서론
컴퓨팅 하드웨어의 발달, 특히 GPU의 발전은 인공지능과 자동화 기술을 급속히 채택하게 만들었다. 이러한 환경에서 객체 검출이 핵심적인 문제로 부상하였으며, 자율 시스템, 환경 모니터링, 로봇공학 등 다양한 분야에 응용되고 있다. 지난 10년 동안 YOLO, Faster R-CNN, RetinaNet과 같은 모델들은 빠르고 정확한 검출 능력을 제공함으로써 객체 검출을 널리 배포 가능한 기술로 만들었다. 그럼에도 불구하고 일관된 고정밀도를 달성하는 것은 여전히 도전 과제이다. 많은 최신 모델들은 복잡한 아키텍처에 의존하며, 특정 도메인 사용 사례에 맞게 대규모 주석 데이터셋을 통해 미세 조정해야 한다. 이러한 작업은 실용적인 제약을 초래한다. 딥러닝 모델은 긴 학습 시간과 많은 계산 리소스를 요구하고, 대규모 데이터셋은 정확한 검출을 위해 비용이 많이 들고 노동 집약적인 주석 작업이 필요하다.
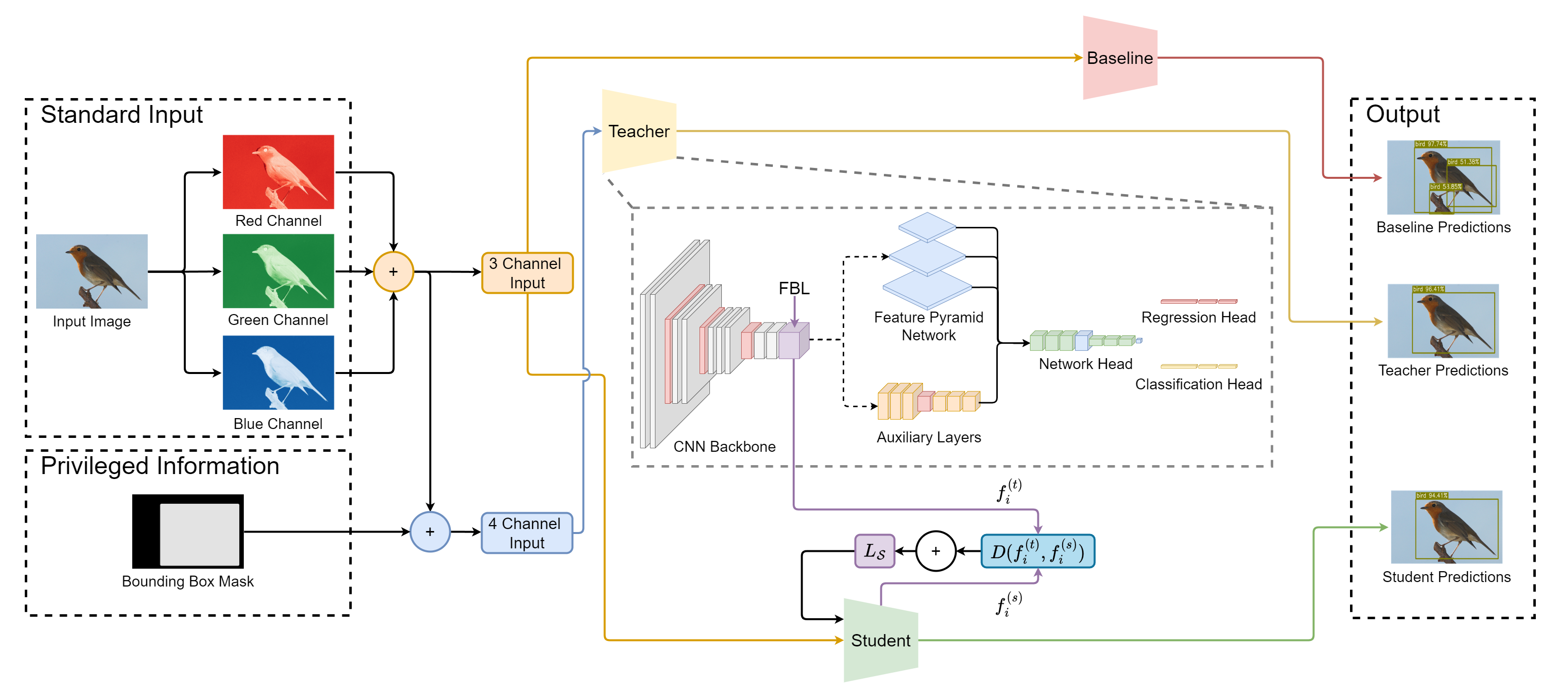
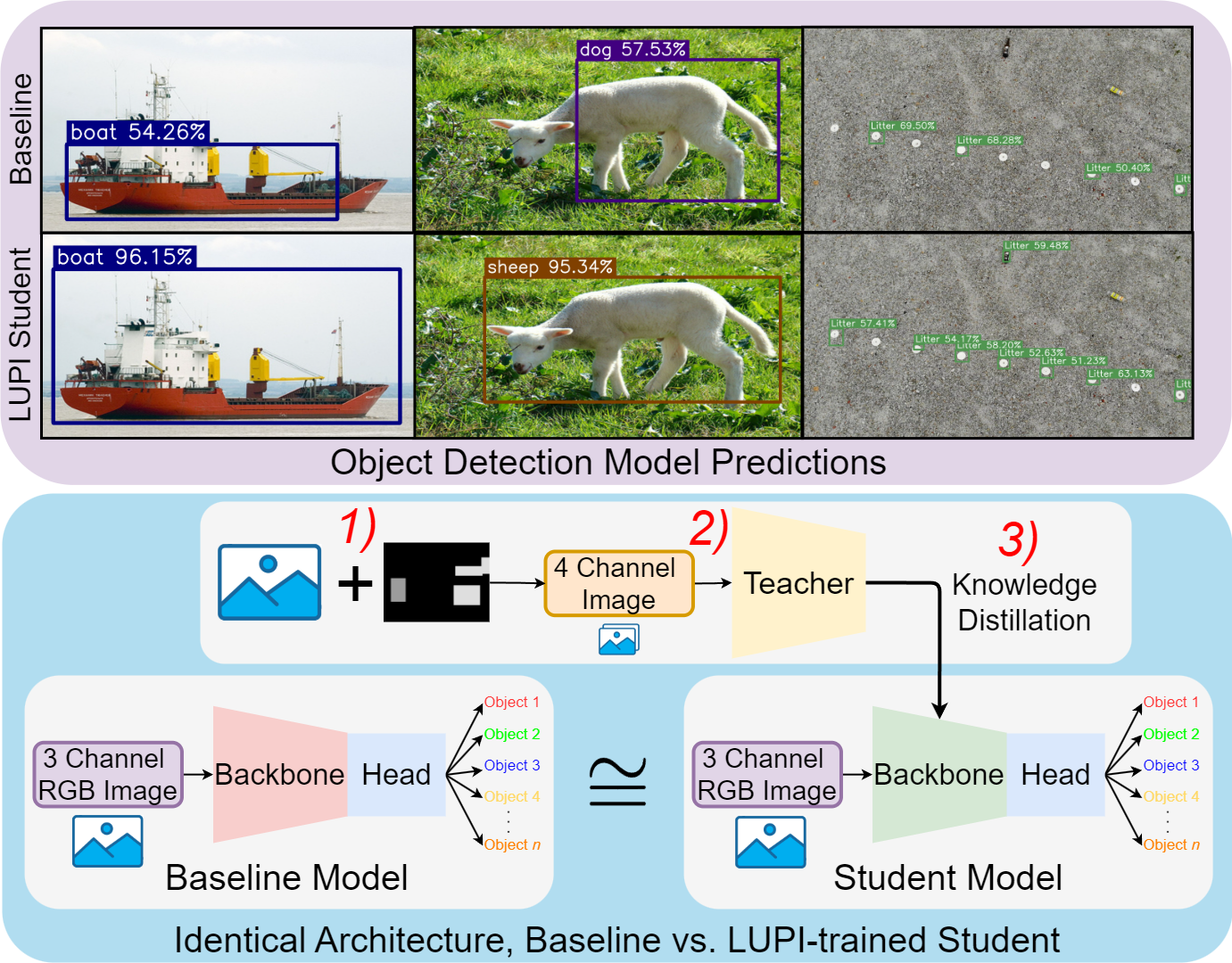
기본 객체 검출 예측과 LUPI 훈련된 학생 모델의 시각적 비교. 정확도가 향상되었으며 동일한 아키텍처를 유지했다는 것을 보여준다. 그림은 LUPI 훈련 파이프라인을 포함하며, 특권 정보, 교사 모델, 지식 증류법 등을 보여주며 이러한 개선 사항은 강화된 학습 과정에서만 발생한다.
그러나 주석 이미지는 현재 최신 객체 검출 모델이 완전히 활용하지 못하는 매우 풍부한 정보를 포함하고 있다. 본 연구에서는 고급 설명력과 세밀한 정보가 자동으로 구성되어 학습 중에 사용되면서 객체 검출기 성능을 개선할 수 있는 가설을 실험적으로 검증한다. 초기 결과를 바탕으로, 우리는 Learning Under Privileged Information (LUPI) 패러다임을 채택하고 이를 효과적으로 활용하기 위해 구성 요소를 조정한다.
LUPI 패러다임은 학습과 추론 사이에 정보 불균형이 있는 문제를 해결하는데 사용된다. 추가적인 정보는 학습 중에는 이용 가능하지만 추론 시에는 제공되지 않는다. 이 방법을 통해 테스트 시에는 접근할 수 없는 매우 정보가 많은 데이터 스트림을 활용하여 대규모 주석 데이터셋의 요구를 크게 줄일 수 있다. 특권 정보는 깊이 단서, 눈에 띄는 맵, 고해상도 이미지 또는 도메인별 주석 등 다양한 형태로 존재할 수 있다. 이러한 신호들을 통합함으로써 모델은 훈련 중 더 풍부한 특징 표현을 학습하여 일반화를 개선하고 수렴 속도를 높이면서 추론 요구 사항을 그대로 유지한다 (그림
1 참조).
본 연구는 여러 가지로 독특하다. 첫째, 우리는 깊은 학습 기반 객체 검출기에 특권 정보를 주입하는 일반적인 방법론을 제안하고 개발한다. 제안된 방법론은 모델에 상관없이 아키텍처 선택에 구애받지 않는다. 둘째, 우리는 다섯 가지 오픈 소스의 최신 사전 훈련 객체 검출 모델과 여러 드론 기반 쓰레기 감지 데이터셋 및 Pascal VOC 벤치마크를 사용하여 우리의 방법론이 미치는 영향을 조사한다. 셋째, 우리는 이전 연구에서 분석한 성능을 확장하고 개선하며 객체 규모별, 표준 COCO 지표별, 다양한 형태의 특권 정보(깊이, 눈에 띄는 맵 및 그들의 결합)와 추론 시간과 모델 크기 등의 실용적 요인도 조사한다. 마지막으로 광범위한 실험을 통해 특권 정보가 모델 성능 향상에 중요함을 입증하고 LUPI 기반 접근 방식의 가능성에 대한 심층적인 통찰력을 제공하며, 이 패러다임의 과학적 및 실용적 함의를 평가한다.
관련 연구
객체 검출은 분류와 위치 추정을 포함하는 복잡한 문제이다. 이 분야는 기존 특징 매칭과 머신 러닝 기법에서 딥러닝 방법으로 진화해 현재 최고 성능을 제공하고 있다. 본 섹션에서는 딥러닝 기반 객체 검출 및 컴퓨터 비전에 적용된 LUPI와 관련된 연구를 검토한다.
딥러닝을 이용한 객체 검출
객체 검출은 복잡한 배경과 간섭물 속에서 객체를 탐지하고, 크기 변동성, 가려짐 처리, 클래스 불균형 및 데이터셋 편향, 작은 객체 감지 등을 해결해야 하는 복수의 도전 과제를 포함하는 지도 학습 작업이다. 이러한 모든 문제는 강력한 학습 알고리즘을 요구한다. 현재 최고 성능의 객체 검출 모델은 다양한 딥러닝 아키텍처를 활용하며, 경계 상자와 범주 레이블을 포함하는 출력을 생성한다. 이러한 네트워크는 일반적으로 한 단계, 두 단계, 트랜스포머 기반 및 기타 딥러닝 접근 방식으로 분류된다.
한 단계 검출기는 단일 네트워크를 사용하여 위치 추정과 분류 문제를 해결한다. YOLO (You Only Look Once)와 SSD (Single Shot MultiBox Detector)는 이 범주에 속하는 인기 있는 예들이다. 두 단계 검출기는 별도의 네트워크로 위치 추정 및 분류를 수행하며, Faster R-CNN과 Mask R-CNN이 대표적인 예시다. 트랜스포머 기반 검출기인 DETR와 RT-DETR은 객체 검출을 위해 자가 주의 메커니즘을 활용한다. CenterNet이나 SAHI와 같은 다른 딥러닝 접근 방식은 강화 학습 기법을 통합한다.
이 다양한 접근 방법들은 객체 검출에 대한 도전 과제를 해결하기 위한 여러 전략들을 보여준다. 한 단계 검출기는 속도와 효율성을 우선시하며, 두 단계 검출기는 복잡한 장면에서 정확도가 뛰어나다. 트랜스포머 기반 모델은 객체 관계를 표현하는 유연성으로 다른 아키텍처 패러다임들이 각각의 감지 문제 측면을 해결하고 있음을 보여준다.
컴퓨터 비전에서 특권 정보 활용 학습
컴퓨터 비전 분야에서 LUPI의 사용은 아직 잘 알려져 있지 않으며, 특히 객체 검출 분야에서는 더욱 그렇다. 우리의 초기 연구는 이 영역에 대한 몇 가지 기여 중 하나이다. 초기 연구들은 대체로 객체 위치 탐지 작업에 초점을 맞추었다. Feyereisl et al. (2014)은 Caltech-UCSD Birds 데이터셋에서 구조적 SVM+ 알고리즘을 사용해 분할 마스크와 SURF 특징을 특권 정보로 활용하여 객체 위치를 탐색했으나, 개선 효과는 미미했다. Sun et al. (2018)은 같은 데이터셋에서 특권 정보를 사용한 객체 위치 탐지 연구를 수행했지만 역시 제한적인 성능 향상을 보였다.
LUPI는 이미지 분류 분야에서는 더 넓게 탐색되었다. Sharmanska et al.은 의미론적 속성, 경계 상자, 텍스트 설명 및 주석가의 논리를 특권 정보로 사용해 SVM+ 프레임워크 내에서 측정 가능한 성능 개선을 보였다. Wang et al.은 고해상도 이미지와 태그를 포함한 관계 데이터를 다중 레이블 분류에 통합하여 이러한 정보 활용의 효과를 증명했다. Makantasis et al.은 음성 및 생리학적 특징을 감정 모델링에서 시각 기반 모델을 개발하기 위해 특권 정보로 사용해 in-vitro와 in-vivo 감정 모델링 작업 사이의 격차를 줄이려고 했다.
LUPI는 지식 증류법과 밀접한 관련이 있다. 지식 증류법은 최근 컴퓨터 비전 분야에서 점점 더 많이 사용되고 있는 기술이다. 이 프레임워크에서는 고용량 네트워크(선생님)가 작은 네트워크(학생)에게 정보를 전달하여 학생이 풍부하고 유익한 표현을 배우게 한다. Hinton의 일반화된 증류 개념은 이 과정을 형식화한다. 컴퓨터 비전 응용에서는 학생과 선생님 네트워크 사이에서 특징 및 로짓 매칭 방법이 일반적으로 사용되며, 특히 위치 증류법은 공간적 정보가 풍부한 영역에 초점을 맞추어 학생 모델이 가장 중요한 부분을 집중하게 함으로써 검출 성능을 개선한다.
그러나 지식 증류법과 LUPI는 목표와 정보 요구사항에서 근본적으로 다르다. 지식 증류의 주요 목표는 더 작지만 선생님 모델과 동등한 성능을 내는 학생 모델을 구축하는 것이며, 두 모델은 동일한 입력 정보를 사용한다. 반면에 LUPI는 큰 네트워크를 압축하려는 목적보다는 훈련 중 특권 정보를 활용하여 훈련된 선생님 모델로부터 추론 시에는 해당 정보가 없어도 예측을 하는 학생 모델로 지식을 전달하는 것을 목표한다. 따라서 지식 증류법은 모델 압축에 초점을 맞추는 반면, LUPI는 훈련과 추론 사이의 정보 불균형 문제를 해결한다.
방법론
훈련 설정의 세부 구조. 교사 네트워크는 RGB 이미지와 특권 입력 채널을 수신하여 풍부한 중간 표현을 생성한다. 학생 네트워크는 RGB 이미지만 처리하지만, 지식 증류법을 통해 추가적인 감독을 받으며 교사로부터 학습한다. 기준 RGB 모델이 비교를 위해 포함되어 있으며, 학생은 기준에 비해 정교한 예측을 제공한다.
고급 설명력과 세밀한 정보가 자동으로 구성되고 학습 중에 활용됨으로써 객체 검출기 성능을 개선할 수 있는 가설을 실험적으로 검증하기 위해, 우리는 교사-학생 프레임워크를 채택한다. 이 섹션에서는 문제를 정식화하고 제안된 접근 방법을 설명한다.
문제 정의
우리는 표준 입력 이미지 $`x \in X`$, 학습 중에만 사용 가능한 추가 특권 정보 $`x^* \in X^*`$ 및 해당 참값 레이블 $`y \in Y`$(각 객체를 나타내는 경계 상자 $`b`$와 클래스 레이블 $`l`$을 포함)로 구성된 각 학습 샘플을 고려한다. 학습 데이터셋은 다음과 같은 트리플렛 세트로 구성된다:
우리의 경우에, 함수 $`f_w`$는 신경망을 통해 구현되고 $`w`$는 해당 네트워크의 가중치에 해당한다. ([eq:student])와
([eq:weights])는 네트워크가 예측을 만드는 데 $`X`$만 사용하지만, 파라미터 추정에는 $`X`$, $`Y`$, 그리고 추가적인 특권 정보 $`X^*`$를 모두 사용한다는 것을 보여준다.
제안된 접근 방법
우리는 교사-학생 패러다임을 활용하여 특권 정보를 활용한다. 교사 네트워크
$`f_{\text{teacher}}: X \cup X^* \rightarrow Y`$는 표준 및 특권 입력 모두에 액세스할 수 있어 풍부하고 유익한 중간 표현을 학습할 수 있다. 반면, 학생 네트워크 $`f_{\text{student}}: X \rightarrow Y`$는 표준 입력만 관찰하며 특권 정보에 직접 접근할 수 없다. 그러나 학습 중에는 교사의 중간 계층 $`l`$에서의 잠재 표현을 복제하도록 학생이 유도되므로 간접적으로 추가된 특권 컨텍스트로부터 혜택을 받는다.
$`f_{\text{teacher}}`$와 $`f_{\text{student}}`$ 모두 $`L`$ 계층으로 구성된 신경망으로 구현된다:
여기서 “$`\circ`$”는 함수 합성이고, $`f_i^{(t)}`$, $`f_i^{(s)}`$는 교사 및 학생 네트워크의 각각 $`i`$번째 계층을 나타낸다. 두 네트워크 모두 $`l`$-계층은 같은 숫자의 은닉 뉴런을 가지므로, 그들의 잠재 표현을 직접 비교할 수 있다.
학습 세트 $`\mathcal{D}_{\text{train}}`$에 속하는 트리플렛 $(x_i, x_i^*, y_i)$에 대해 학생은 자신의 잠재 특징 $`f_l^{(s)}(x_i)`$를 교사의 특징 $`f_l^{(t)}(x_i, x_i^*)`$와 정렬하도록 훈련된다. 이 정렬은 지식 전달 과정의 기반이 되며 학생이 표준 입력만을 사용하면서도 교사의 더 풍부한 중간 표현을 근사할 수 있게 한다.
학생은 표준 검출 감독과 교사로부터의 지식 전달 사이를 균형 잡히게 하는 결합 손실 함수로 최적화된다:
([eq:lupi-loss])에서 $`\alpha \in [0,1]`$는 참값 레이블로부터의 감독과 교사로부터의 지도 사이의 상대적 가중치를 제어한다. 교사-학생 프레임워크의 성공은 학습 중 사용되는 특권 정보의 유형 및 품질에 밀접하게 연결되어 있다. 우리는 이러한 정보가 어떻게 구성되고 통합되며 학습 과정을 강화하는지 설명한다.
객체 검출을 위한 특권 정보
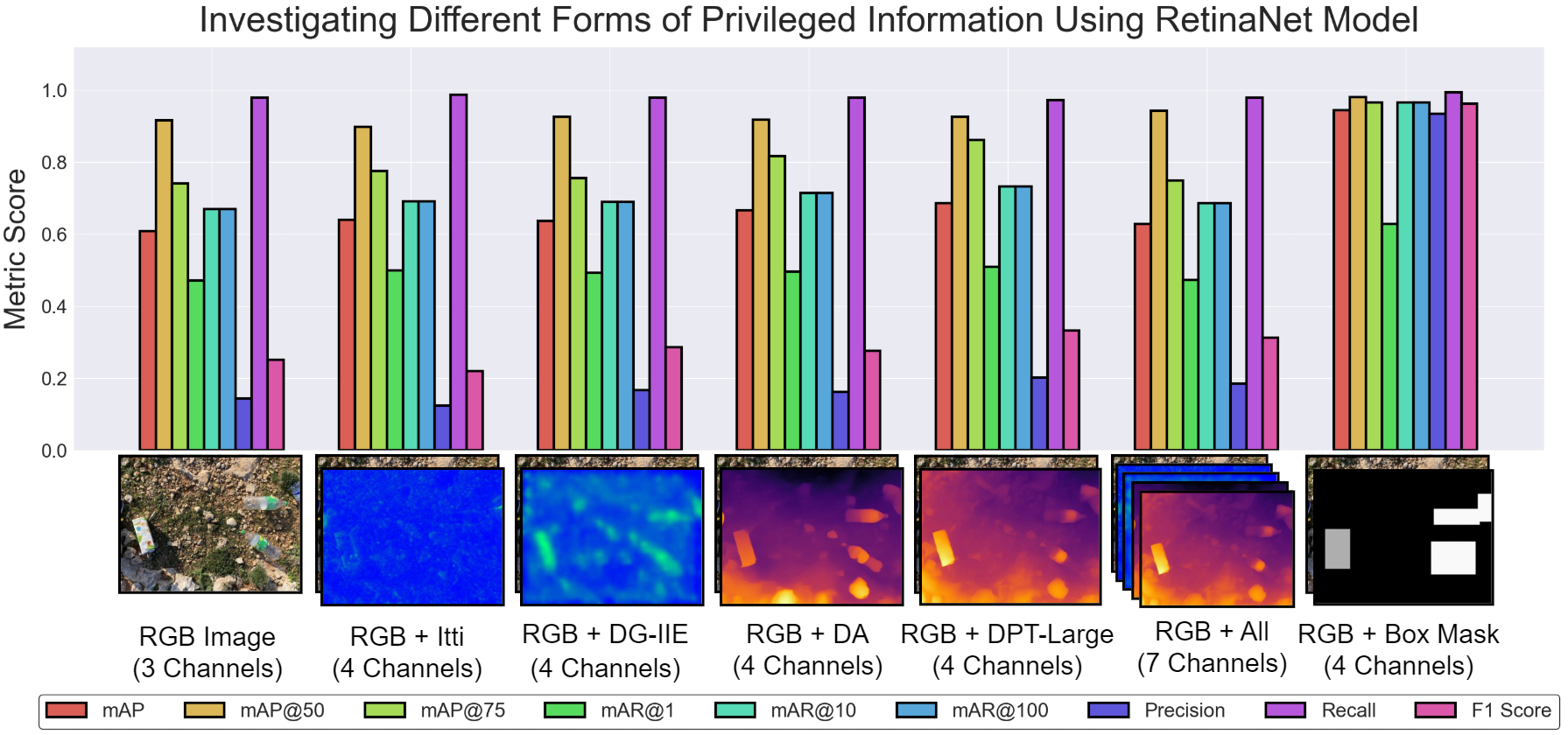
RetinaNet 모델을 사용한 SODA 1-metre 데이터셋에서 다양한 형태의 특권 정보에 대한 조사. 비교는 눈에 띄는 맵, 깊이, 융합 및 경계 상자 마스크 표현을 포함한다. 경계 상자 마스크가 검출 정확도를 가장 크게 향상시켰다.
객체 검출을 위한 효과적인 특권 정보 선택은 위치 추정과 분류에 의미있게 기여하는 단서가 필요하다.