- Title: Not All Needles Are Found How Fact Distribution and Don t Make It Up Prompts Shape Literal Extraction, Logical Inference, and Hallucination Risks in Long-Context LLMs
- ArXiv ID: 2601.02023
- 발행일: 2026-01-05
- 저자: Amirali Ebrahimzadeh, Seyyed M. Salili
📝 초록
본 연구는 장문 컨텍스트를 처리하는 대형 언어 모델(LLMs)의 성능을 평가하고, 실제 문서에서 정보 추출과 논리적 추론에 대한 새로운 평가 방법론을 제시한다. 이를 위해 “Needle-in-a-Haystack” 테스트를 확장하여 다양한 정보 분포와 위치를 시뮬레이션하고, 반-구체화(anti-hallucination) 프롬프트의 영향을 분석한다. 실험 결과는 더 긴 컨텍스트가 항상 성능을 개선하지 않는다는 것을 보여주며, 모델 간에 정보 처리 능력이 다르다는 점을 강조한다.
💡 논문 해설
1. **키 컨트리뷰션 1: 새로운 평가 방법론**
- 메타포: 우리가 큰 밀밭에서 바늘을 찾는 것과 마찬가지로, LLMs도 긴 문서에서 중요한 정보를 찾아내야 합니다. 이 연구에서는 단순히 한 곳에 있는 바늘만 찾는 것이 아니라, 여러 바늘을 다양한 위치에 분산시키고 그들이 어떻게 찾아내는지를 평가합니다.
- 설명: 기존의 “Needle-in-a-Haystack” 테스트를 확장하여 실제 문서에서 정보 추출과 논리적 추론 능력을 더 정확하게 평가하는 방법을 제시한다.
키 컨트리뷰션 2: 반-구체화 프롬프트의 영향 분석
메타포: 반-구체화 프롬프트는 LLMs에게 “거짓말하지 마세요”라는 지침을 주는 것과 같습니다. 이 연구에서는 이러한 지침이 추론 능력에 어떤 영향을 미치는지 분석한다.
설명: 반-구체화 프롬프트가 정보 추출, 논리적 추론 및 신뢰성에 미치는 영향을 측정하고, 이를 통해 LLMs의 성능과 안전성을 평가한다.
키 컨트리뷰션 3: 모델 간 성능 차이 분석
메타포: 다양한 자동차를 시험하는 것처럼, 이 연구에서는 여러 종류의 LLMs을 비교하여 각각의 장단점을 평가한다.
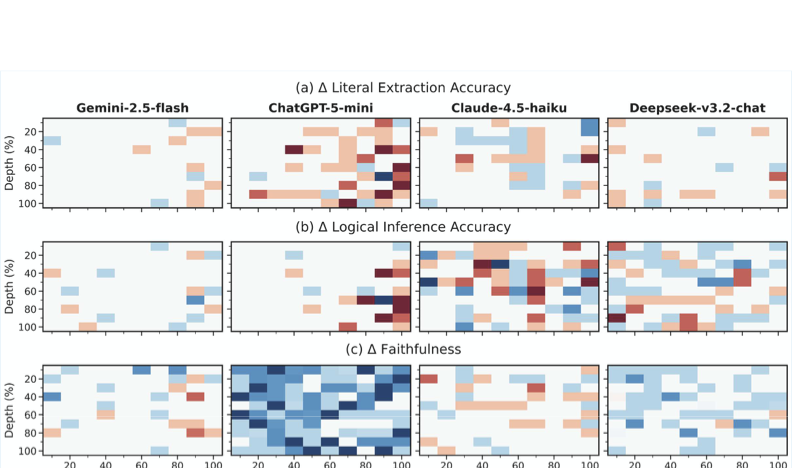
설명: 네 가지 대형 언어 모델(Gemini-2.5-flash, ChatGPT-5-mini, Claude-4.5-haiku, Deepseek-v3.2-chat)의 성능 차이를 분석하여 실제 문서에서 정보 처리 능력을 비교한다.
📄 논문 발췌 (ArXiv Source)
# 서론
연구와 기업에서 대형 언어 모델(LLMs)의 장문 컨텍스트가 정보 검색을 재구성할 수 있다는 믿음이 확산되고 있다. LLMs의 컨텍스트 창이 확장되면서 때로는 100만 토큰 이상으로, 사용자는 복잡한 검색 파이프라인을 우회하고 문서나 데이터베이스를 직접 프롬프트에 붙여 구체적인 응답을 얻을 수 있다. LLM 공급업체는 이러한 더 큰 컨텍스트 창을 빠르게 변화하는 AI 시장에서 경쟁력을 강조한다.
그럼에도 불구하고 특정 사용 사례에 대한 LLMs의 효율성과 신뢰성이 명확하지 않다. 컨텍스트 창 크기는 중요한 마케팅 및 평가 지표이지만, 실제 활용은 작업별로 다르다. 최근 연구는 입력 컨텍스트가 증가할수록 LLMs의 성능이 저하되며, 특히 관련 정보가 퍼져 있을 때 더욱 그러하다고 보여준다. 이러한 현상은 “중간에 잃어버림” 또는 “나중에 잃어버림”과 같은 위치 효과로 인해 발생한다. 이러한 도구의 광범위한 채택은 신뢰성 문제를 더 중요하게 만들 수 있다.
LLMs을 평가하는 데 있어 합성 코퍼스 또는 바늘에서 허브스트랙(NIAH) 검사와 같은 벤치마크에 의존하는 것이 한계이다. NIAH 검사는 긴 문서 내에 숨겨진 단일 사실을 찾는다. 실제 응용에서는 사실이 종종 분산되어 있고, 교차 참조가 일반적이다. 고립된 사실에 초점을 맞춘 평가는 LLMs의 장문 컨텍스트 성능을 과대평가할 수 있으며, 잠재적인 다중 추론이나 “두 가지 단계의 저주”를 무시하는 경우 더욱 그렇다.
생산에서 사용되는 반-구체화(anti-hallucination) 지침은 “만들지 마세요” 또는 “구체화하지 마세요"와 같이 LLMs의 신뢰성을 향상시키는 데 사용된다. 이러한 프롬프트가 직접적인 추출, 논리적 추론 및 전반적인 신뢰성에 미치는 영향은 충분히 이해되지 않았다. 이러한 프롬프트는 구체화를 줄이지만 모델을 보수적으로 만들며, 사실의 추출이나 추론 실패로 이어질 수 있다. 즉, 얼마나 많은 회상과 추론 정확도가 구체화 위험 감소에 희생되는지 중요한 질문이다.
본 연구는 장문 컨텍스트 LLMs의 벤치마크 분석을 제공하고 복잡한 지표를 피하는 새로운 평가 접근법을 소개한다. 이 연구는 컨텍스트 길이, 사실 배치, 반-구체화 프롬프트 및 모델 차이에 대한 영향을 검토하며 추출, 추론 및 구체화에 대해 탐색한다. 네 가지 대형 LLMs을 평가하여 이러한 효과를 명확히 한다.
분석은 다음 사항에 초점을 맞춘다:
유효한 컨텍스트 길이는 모델이 의미있게 활용할 수 있는 토큰의 최대 범위이다.
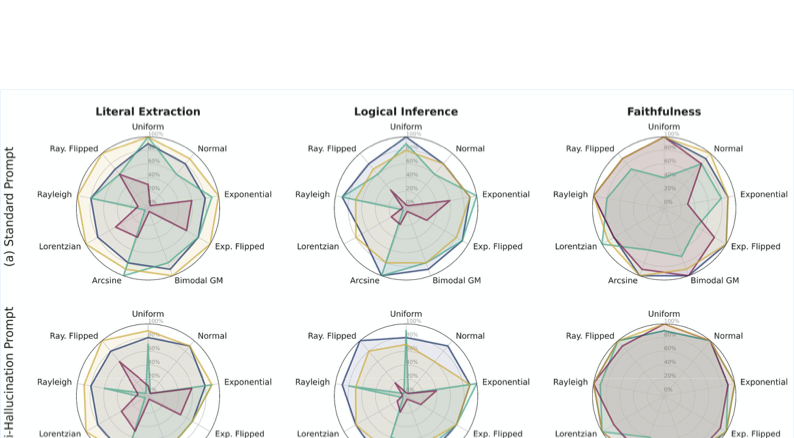
사실 배치는 관련 정보가 코퍼스 내에서 어떻게 공간적 및 통계적으로 배열되는지, 그리고 이를 통해 직접적인 추출, 논리적 추론 및 구체화 위험에 어떤 영향을 미치는지를 조사한다.
구제약 상태의 구체화 행위는 명시적인 반-구체화 프롬프트가 모델 출력을 어떻게 변경하는지 분석하며 보수적인 실패 모드와 누락 오류를 포함한다.
테스트된 LLM 중에서 위 세 가지 지표에 대해 최적의 성능을 갖춘 LLM을 식별한다.
실험 설계는 NIAH를 확장하여 직접 추출과 논리적 추론을 분리한다. 정규분포와 지수 분포와 같은 확률적인 사실 배치를 도입하여 실제 문서에 더 가깝게 시뮬레이션한다. “안전세금”은 구체화 감소와 추출 또는 추론 감소 사이의 무역 오프를 측정하며, 반-구체화 프롬프트가 있는 경우와 없는 경우의 출력을 비교하여 측정된다.
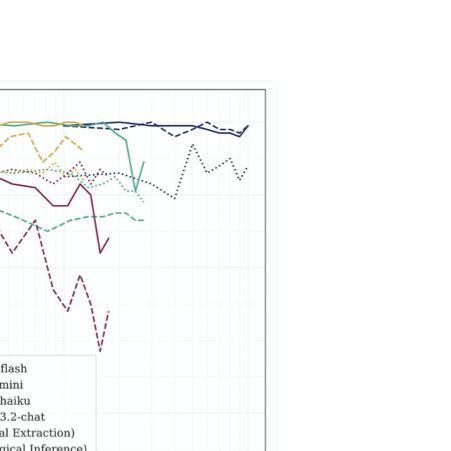
결과는 더 긴 컨텍스트가 항상 더 나은 성능을 보장하지 않는다는 것을 보여준다. 관련 정보가 희석되면 성능이 저하되며, 모델 간에 실제 분포에 대한 견고성이 다르다. 반-구체화 프롬프트는 구체화를 줄이지만 올바른 추론을 억제할 수 있어 보수적인 행동과의 무역 오프가 있다.
대규모 언어 AI를 신속하게 채택하는 조직은 종종 큰, 필터링되지 않은 코퍼스를 LLM에 입력하며, 이는 LLM 출력이 의사결정에 중요한 역할을 한다. 실패는 주로 모델 선택, 컨텍스트 사용 및 안전 조절의 부족에서 기인한다. 효과적인 컨텍스트 길이와 사실 배치에 대한 견고성을 우선시하여 신뢰성 있는 장문 컨텍스트 LLM 사용을 위해 노력해야 한다.
관련 연구
장문 컨텍스트 LLMs의 초기 관찰과 경험적 증거는 이러한 모델들이 긴 입력 문서를 처리할 때 여러 가지 이유로 어려움을 겪는다는 것을 보여주었다. 주목할 만한 현상 중 하나인 “U자형 메모리”는 위치 편향이 강함을 나타낸다: LLMs은 관련 정보가 입력 컨텍스트의 처음이나 끝에 있을 때 성능이 더 좋으며, 중간 부분은 크게 나쁘게 작용한다. 이러한 모델들이 컨텍스트 중앙에 대한 주의력 부족이 컨텍스트 길이 증가와 함께 악화되어 정보 누락과 구체화 증가로 이어진다는 것이 확인되었다.
최근 프레임워크는 이를 “나중에 잃어버림” 효과로 확장하여 모델들이 컨텍스트의 뒷부분을 우선 순위에서 제외한다는 것을 보여준다. 최근 연구에서는 다중 턴 대화에서도 같은 패턴이 나타난다는 점을 확인했다. LLMs은 계속해서 컨텍스트가 쌓일수록 정보를 잃어버리고 작업 정확도가 크게 하락한다.
바늘에서 허브스트랙 검사는 LLMs의 장문 컨텍스트 능력을 평가하는 데 널리 사용되는 벤치마크이다. Greg Kamradt는 이 테스트를 GPT-4을 평가하기 위해 도입했다. 그러나 이러한 벤치마크는 주로 단일 포인트 추출에 초점을 맞추고 있어 분산된 증거에 대한 합리적 추론에 대한 통찰력이 제한적이었다.
최근 확장은 장문 컨텍스트 LLMs을 연속적인 바늘 추출과 의미 추론을 통해 평가한다. 다른 연구는 컨텍스트 길이, 구체화 및 누락 정보에 초점을 맞추거나 테스팅을 100만 토큰 제한까지 확장했다.
많은 연구들은 모델 가중치에 저장된 매개변수 지식과 추론 시 제공되는 컨텍스트 지식 사이의 차이점에 집중한다. 컨텍스트 길이가 증가할수록 LLMs은 제공된 컨텍스트 증거를 탐색하기보다 매개변수 사전을 기본으로 하는 경우가 많다. 이는 약 70%의 컨텍스트 지식과 30%의 매개변수 지식 사이의 일관된 의존 비율을 유지한다. 컨텍스트 증거가 명시적이지 않거나 더 분산되어 있을 때 더욱 그렇다.
이러한 관찰에도 불구하고 성능 분포는 체계적인 평가 부족으로 인해 희박하다. 대부분의 문헌은 다양한 컨텍스트 길이를 중심으로 집중하고 있지만 정보 구조가 결과에 미치는 영향에는 초점을 맞추지 않았다. 우리의 연구에서는 증거의 분포적 속성을 변경하여 하류 성능에 어떤 영향을 미치는지를 특별히 보여주며, 컨텍스트 구조화에 대한 중요한 통찰력을 제공한다.
구체화는 널리 연구되었으며 다양한 감소 전략이 개발되었다. 그러나 체인-오브-사유 추론은 일부 작업에서 성능을 향상시키지만 장문 컨텍스트 설정에서 구체화를 줄이는 데 효과적인지는 논란의 여지가 있다.
생산 시스템에 대한 충분한 양적 검토는 이루어지지 않았으며, 인간이 확인한 벤치마크에서는 최신 모델에서도 40% 이상의 구체화율을 보였다. 최근 연구들은 과도한 보수주의와 회피로 인해 명백하고 명시적인 질문에도 답하지 못하는 실패를 보여준다.
마지막으로, 여러 연구는 LLMs의 컨텍스트 내 추론 시 행동과 인간 기억 시스템 사이에 유사성을 찾았다. 이러한 연구들은 무관하거나 원치 않는 정보로 메모리를 과부하 상태로 만드는 것이 중요한 데이터를 잊게 한다는 현상을 보여준다.
방법론
실험 설계 및 평가 프레임워크
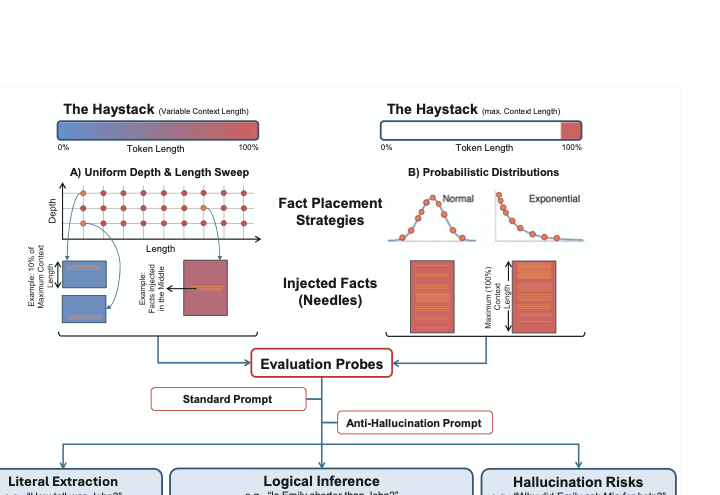
장문 성능을 철저히 평가하기 위해 우리는 전통적인 “바늘에서 허브스트랙” 패러다임을 확장하여 실제 추출 과제를 반영한다. 균일한 사실 배치에만 의존하지 않고, 확률 분포로 관리되는 다양한 “허브스트랙” 탑올로지를 도입한다.
style="width:95.0%" />
확장 바늘에서 허브스트랙 평가 프레임워크 개요. (A) 정보 깊이와 컨텍스트 길이에 대한 균일 스캔은 기준 성능 맵을 설정한다. (B) 확률적 사실 배치 전략(예: 정규 또는 지수 분포)은 실제 문서의 정보 퍼짐을 시뮬레이션한다. 프레임워크는 직관 추출, 논리적 추론 및 신뢰성에 대한 세 가지 능력을 평가하며 표준과 반-구체화 프롬프트 조건 모두에서 수행된다.
본 연구에서는 두 가지 독특한 프롬프팅 전략을 테스트한다: 직접 답변을 요구하는 표준 프롬프트와 정보가 없으면 답변을 거부하도록 명시적으로 지시하는 “만들지 마세요”를 포함하는 반-구체화 프롬프트. 이 이중 탐사 접근법은 추출 실패와 구체화 위험을 분리하여 모델이 올바른 정보를 검색하는지(직관 추출)뿐만 아니라 이를 바탕으로 추론할 수 있는지(논리적 추론) 및 진실에 충실한지(신뢰성) 측정한다.
본 연구에서 직관 추출은 입력 컨텍스트 내에서 명시적으로 제공된 사실을 정확하게 식별하고 재생산하는 것을 의미하며, 어떤 의미 변환이나 추론도 필요하지 않다. 논리적 추론은 반추론이 아닌 하나 이상의 제공된 사실에 기반한 결론 도출로, 입력으로부터 직접 지원되는 귀결 또는 합당한 설명이 아니다.
코퍼스 구성 및 처리
“허브스트랙”이 실제 인지 부담을 제시하도록 하기 위해 우리는 Honoré de Balzac의 La Comédie Humaine에서 파생된 대규모 서사 데이터셋을 구축했다. 초기 코퍼스는 프로젝트 구텐베르크를 통해 공개 도메인에서 출처한 38개 소설을 포함하며, 약간 연결되고 19세기 프랑스를 배경으로 한다.
원본 코퍼스에는 약 200만 토큰이 포함되어 있다(tiktoken을 통해 측정). 자연스러운 하위 컨텍스트 생성을 위해 우리는 부분 재귀적 컨텍스트 수축 방법을 사용했다. 기본 코퍼스는 세그먼트로 나뉘고 요약하여 특정 목표 토큰 수에 맞추어져 있다(예: 100k 세그먼트를 20% 줄여 80k 토큰을 얻음). 이를 통해 각 모델의 최대 컨텍스트 창 크기의 분수 또는 완전한 크기에 자연스러운 하위 컨텍스트를 생성할 수 있으며 의미적 흐름을 유지한다.
모델 구성 및 하이퍼파라미터
네 가지 생산 규모 모델을 평가하여 현재 장문 처리에서 최고의 상태를 대표하도록 한다. 표 1은 각 모델의 최대 컨텍스트 창 크기를 상세히 보여준다.
Model
Max Context (Tokens)
Gemini-2.5-flash
1,000,000
ChatGPT-5-mini
272,000
Claude-4.5-haiku
175,000
Deepseek-v3.2-chat
128,000
모델 이름과 최대 컨텍스트 창 크기. 참고: Claude-4.5-haiku 토큰은 tiktoken을 통해 보고되었으며 원래 제한은 약 20만개이다.
재현성을 보장하고 구체화 변동성을 최소화하기 위해 API가 허용하는 경우 결정론적 디코딩 전략을 강제한다. 하이퍼파라미터는 다음과 같이 표준화된다:
Temperature: $`0.0`$ – 결정론성을 극대화하고 창의적인 변화를 줄인다.
Top_p: $`1.0`$ – 로짓의 전체 확률 질량을 고려한다.
Frequency Penalty: $`0.0`$ – 특정 엔티티 이름(바늘)이 답변에 필수적이므로 반복에 대한 처벌을 방지한다.
Presence Penalty: $`0.3`$ – 약간의 처벌을 적용하여 특정 엔티티 이름의 반복을 약간 억제하도록 한다.