- Title: Output Embedding Centering for Stable LLM Pretraining
- ArXiv ID: 2601.02031
- 발행일: 2026-01-05
- 저자: Felix Stollenwerk, Anna Lokrantz, Niclas Hertzberg
📝 초록
대형 언어 모델의 사전 학습은 비용이 많이 들 뿐만 아니라 특정 트레이닝 불안정성에 노출되기 쉽습니다. 특히 큰 학습률을 사용할 때 마지막 부분에서 자주 발생하는 특정 불안정성이 출력 로짓 발산입니다. 가장 널리 사용되는 완화 전략인 z-손실은 문제의 증상을 다루는 데 그치고 근본 원인을 해결하지 않습니다. 본 논문에서는 출력 임베딩의 기하학적 관점에서 불안정성을 분석하고 그 원인을 파악하였습니다. 이를 바탕으로 새로운 완화 전략인 출력 임베딩 센터링(OEC)을 제안하고, 이가 출력 로짓 발산을 억제한다는 것을 증명합니다. OEC는 확률적 작업인 μ-센터링 또는 정규화 방법인 μ-손실로 두 가지 다른 방식으로 구현될 수 있습니다. 실험 결과, 두 변형 모두 z-손실보다 학습 안정성과 학습률 민감도 측면에서 우수한 성능을 보여주며, 특히 큰 학습률에서도 z-손실이 실패할 때에도 훈련이 수렴하도록 보장합니다. 또한 μ-손실은 z-손실보다 정규화 하이퍼파라미터 조정에 대해 크게 덜 민감하다는 것을 발견하였습니다.
💡 논문 해설
#### 1. 분석
- **메타포:** 대형 언어 모델은 방대한 양의 데이터를 학습하는 거대한 배로 생각할 수 있습니다. 이 배가 항해 중에 불안정하게 동요하는 경우, 안전한 도착을 위해 이를 수정해야 합니다.
- **간단 설명:** 본 논문에서는 대형 언어 모델이 훈련 과정에서 출력 로짓의 발산 문제를 해결하기 위한 방법론을 제시합니다.
- **상세 설명:** 이 연구는 특히 언어 모델링 헤드에서 발생하는 로짓 발산 문제에 주목하고, 이를 막기 위해 다양한 방법론을 분석 및 제안합니다.
2. 방법
메타포: 출력 임베딩은 배의 선체를 안정시키는 기둥과 같습니다. 이 기둥이 중심을 유지하지 못하면 배가 흔들리게 됩니다.
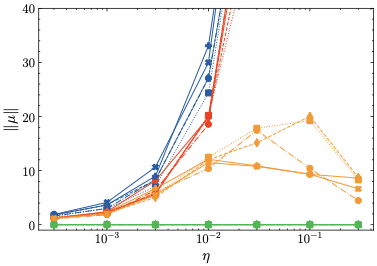
간단 설명: 연구팀은 출력 임베딩을 중앙에 위치하도록 조절하는 방법론 ($\mu$-centering 및 $\mu$-loss)를 제안합니다. 이를 통해 모델의 학습이 안정화됩니다.
상세 설명: $\mu$-centering 및 $\mu$-loss는 출력 임베딩을 중앙으로 이동시키고, 이를 통해 로짓 발산을 억제하고 학습 과정을 안정화시킵니다.
3. 학습률 민감도
메타포: 학습률은 배의 속도를 결정하는 항해사와 같습니다. 만약 항해사가 너무 빠르게 가거나 느리게 가면, 배는 안정적으로 도착하기 어렵습니다.
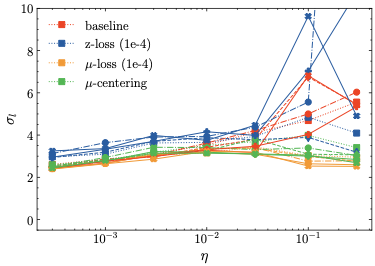
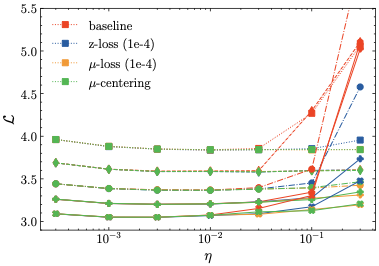
간단 설명: 제안된 방법론은 기존 z-loss에 비해 학습률 민감도를 줄여 훈련 과정을 더 안정화합니다.
상세 설명: $\mu$-centering 및 $\mu$-loss는 기존의 z-loss보다 학습률에 덜 민감하고, 따라서 LLM의 사전 훈련 과정이 더욱 안정적입니다.
📄 논문 발췌 (ArXiv Source)
# 소개
대형 언어 모델(LLMs)은 다양한 태스크를 해결하는 데 큰 가능성에 찬물이었다. 그러나 LLMs의 사전 훈련 과정에서 가장 계산 비용이 많이 드는 단계에서 불안정성이 발생하는 문제는 반복적으로 나타나며, 이로 인해 많은 양의 계산 리소스가 낭비되는 경우가 많다. 훈련 불안정성은 다양한 형태를 띠는데, 특히 매우 큰 주목 로짓이나 언어 모델링 헤드에서 출력 로짓의 발산 등이 있다. 본 논문에서는 후자를 특별히 다룬다.
언어 모델링 헤드
우리는 디코더만을 사용하는 Transformer 모델을 고려하며, 이때 언어 모델링 헤드는 최종 은닉 상태를 어휘의 토큰에 대한 확률 분포로 매핑하는 마지막 구성 요소이다. 표기법에 따라, 표준 언어 모델링 헤드는 다음과 같은 방정식으로 정의된다:
$\mathcal{L}\in \mathbb{R}_{\geq 0}$는 다음 토큰 예측의 손실이며, p_t \in [0,1]은 참 셀 단어 $t \in \mathcal{V}에 할당된 확률을 나타낸다. 여기서 $\mathcal{V}\equiv \{1, \ldots, V\}$, $V는 어휘의 크기이며 각 토큰 $i \in \mathcal{V}에 대한 로짓과 출력 임베딩은 $l_i \in \mathbb{R} 및 $e_i \in \mathbb{R}^H로 표시되며, $H는 모델의 은닉 공간 차원이다. 최종 은닉 상태는 $h \in \mathbb{R}^H로 주어진다. 출력 임베딩 $e_i는 독립적으로 학습하거나 입력 임베딩과 연결될 수 있다.
z-loss
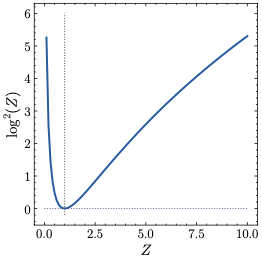
출력 로짓의 발산 문제에 가장 널리 채택된 해결책은 z-loss이며, 이는 에서 소개되었다. Eq. ([eq:lmhead_probabilities])의 분모를 $Z := \sum_{j=1}^V \exp{(l_j)}$로 표기하면,
MATH
\begin{align}
Z := \sum_{j=1}^V \exp{(l_j)}
\label{eq:Z}
\end{align}
z-loss가 로짓의 발산을 막아 훈련 과정을 안정화시키는 효과적인 방법임이 밝혀졌으며, 따라서 여러 최근 모델에서 활용되었다. 마찬가지로, Baichuan 2은 최대 로짓 값의 제곱에 대한 벌점을 부과하는 z-loss 변형인 max-z loss를 도입했다. 반면 Gemma 2은 “로짓 소프트 캡핑"을 통해 로짓을 고정된 수치 범위 내에서 유지하도록 강제한다. NormSoftMax는 로짓의 분포에 기반한 소프트맥스 함수의 동적 온도 스케일링을 제안하는 또 다른 방법이다. 위의 모든 방법은 로짓 발산의 증상을 다루지만 그 원인에는 대처하지 않는다. 원인을 파악하기 위해 Eq. ([eq:lmhead_logits])를 통해 로짓에 영향을 미치는 출력 임베딩의 역할을 살펴볼 것이다.
아nisotropic 임베딩
Transformer 모델의 임베딩이 나타내는 잘 알려진 현상 중 하나는 은닉 공간에서 각 차원을 균등하게 분포하지 않는다는 점이다. 이 anisotropy 문제는 처음 에서 설명되었다. 당시에는 임베딩이 은닉 공간에서 좁은 원뿔 내에 존재한다는 것이 이해되었다. 여러 정규화 방법이 제안되었는데, 예를 들어 코사인 정규화, 라플라스 정규화 및 스펙트럼 제어 등이 있다. 에서 임베딩은 실제로 중심 주변에서 근접 이성적이며 관찰된 anisotropy는 주로 원점으로부터의 임베딩의 공통적인 이동 때문이라고 주장했다. 최근에 이 현상의 근본 원인이 무엇인지 밝혔다; 그들은 Adam의 2차 모멘텀이 임베딩의 공통 이동을 일으키는 원인임을 보여주고, 최적화기 기반 완화 전략으로 Coupled Adam을 제안했다. 또한 그들의 분석은 현상이 입력 임베딩보다는 출력 임베딩에서 발생한다는 것을 밝혀냈다.
우리의 공헌
본 논문은 다음과 같은 기여를 제공한다.
분석: 우리는 위의 두 연구를 결합하고, anisotropic 임베딩이 출력 로짓 발산을 일으키는 데 어떤 역할을 하는지 분석한다.
방법론: 우리는 출력 임베딩을 중심으로 유지하는 두 가지 관련 완화 전략을 제안한다: $\mu$-centering 및 $\mu$-loss.
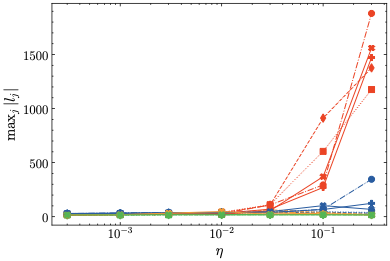
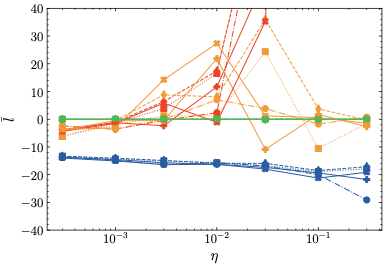
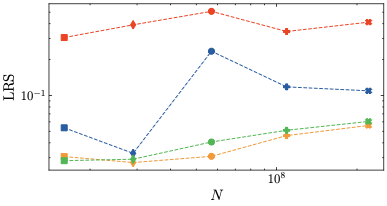
학습률 민감도: 실험적으로 우리의 방법이 z-loss에 비해 학습률 민감도가 감소하고, 따라서 LLM 사전 훈련 과정이 더 안정적임을 보여준다.
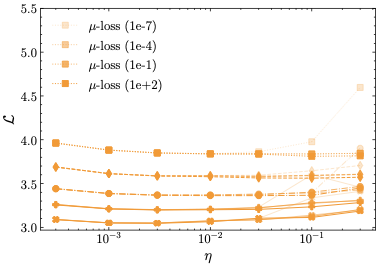
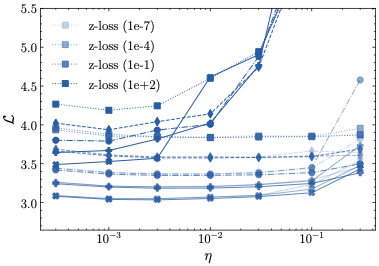
하이퍼파라미터 민감도: 우리의 정규화 방법인 $\mu$-loss는 z-loss보다 하이퍼파라미터에 덜 민감하며, z-loss에는 세밀한 하이퍼파라미터 튜닝이 필요하다. 또한 우리의 결과는 z-loss의 최적 하이퍼파라미터가 이전에 가정했던 것보다 더 크다는 것을 나타낸다.
완화 전략
본 절에서는 로짓 발산을 억제하기 위한 다양한 방법론을 이론적으로 탐구한다. 먼저 z-loss를 분석하고, 그것이 모든 종류의 로짓 발산을 억제하지 못함을 보여준다. 문제의 원인을 다루는 더 일관된 방법을 찾기 위해 출력 임베딩이 로짓에 미치는 영향을 살펴본다. 이를 바탕으로, 출력 임베딩을 중심으로 하여 로짓 발산을 억제하는 두 가지 관련 방법론을 제시한다: $\mu$-centering 및 $\mu$-loss.
z-loss
Eq. ([eq:zloss])의 z-loss 항은 그림 1의 왼쪽에 나와 있다. 이는 모델이 $Z \approx 1$를 충족하는 로짓을 생성하도록 유인한다. 이가 로짓 자체에 어떤 영향을 미치는지 탐구하기 위해, 큰 z-loss $\mathcal{L}_z$로 이어지는 두 가지 다른 메커니즘이 각각 $Z \to 0$과 $Z \to \infty$를 나타낸다는 것을 먼저 주목해야 한다.
Lemma 1. *무한 z-loss $\mathcal{L}_z$는 다음 두 가지 (상호 배타적인) 시나리오 중 하나에 해당한다:
MATH
\begin{align}
&(i) \ &\exists~j \in [1, V]: l_j \to + \infty& \nonumber \\
&(ii) \ &\forall~j \in [1, V]: l_j \to - \infty& \nonumber
\end{align}
```*
</div>
<div class="proof">
*Proof.* *(i)* 이 문장은 $Z \to \infty$와 동치이며, 이는 $\mathcal{L}_z \to \infty$를 따르게 한다. *(ii)* 이 문장은 $\forall~j \in [1, V]: \exp(l_j) \to 0$, 다시 말해 $Z \to \infty$와 동치이며, 이는 $\mathcal{L}_z \to \infty$를 따르게 한다. ◻
</div>
Lemma <a href="#lemma:1" data-reference-type="ref" data-reference="lemma:1">1</a>의 두 조건은 공통적으로 가장 큰 로짓이 발산한다는 점을 가지고 있다. 이를 다음과 같이 간결하게 통합할 수 있다.
<div id="theorem_zloss" class="proposition">
**Proposition 2.** *무한 z-loss $\mathcal{L}_z$는 다음에 해당한다:
``` math
\begin{align}
\max_j l_j \to \pm \infty
\end{align}
```*
</div>
<div class="proof">
*Proof.* Lemma <a href="#lemma:1" data-reference-type="ref" data-reference="lemma:1">1</a>로부터 직접적으로 따름. ◻
</div>
따라서 z-loss는 어떤 단일 로짓의 긍정적 발산을 방지하고, 모든 로짓이 공동으로 부정적 발산을 막는다. 주목할 만하게도, 이는 어떠한 단일 로짓의 부정적 발산도 막지 못한다.
## 출력 임베딩과 로짓
z-loss에 대한 논의를 바탕으로, 출력 임베딩 $e_i$와 로짓 $l_i$ 사이의 관계를 살펴본다. 특히 그들의 평균 및 범위를 고려한다. 이는 후속 섹션에서 제시할 우리의 출력 임베딩 중앙화 방법론을 위한 기반으로 사용된다.
단어 임베딩의 평균
``` math
\begin{align}
\mu&= \frac{1}{V} \sum_{i=1}^V e_i
\label{eq:mu}
\end{align}
\begin{align}
- \max_i \| e_i \| \cdot \| h \| \leq l_j \leq \max_i \| e_i \| \cdot \| h \|
\label{eq:bounds_logit_expression}
\end{align}
```*
</div>
<div class="proof">
*Proof.* $l_j \stackrel{(\ref{eq:lmhead_logits})}{=} e_i \mathpalette\mathbin{\vcenter{\hbox{\scalebox{h}{$\m@th.5\bullet$}}}} = \| e_i \| \| h \| \cos \alpha_i$, 여기서 $\alpha_i$는 $e_i$와 $h$ 간의 각도이다. ◻
</div>
요약하면, 평균 출력 임베딩은 평균 로짓에 직접적으로 영향을 미치며, 출력 임베딩의 노름은 로짓의 범위를 정의한다. 따라서 출력 임베딩을 제어하는 것은 로짓을 제어하는 방법이다. 이 통찰력은 *출력 임베딩 중앙화* (OEC)의 기초를 마련한다. OEC의 아이디어는 평균 출력 임베딩 $\mu$ (Eq. (<a href="#eq:mu" data-reference-type="ref" data-reference="eq:mu">[eq:mu]</a>))가 원점에 제한되도록 하는 것인데, 이를 통해 임베딩의 공통적인 이동 및 무제어된 로짓 성장을 억제한다. OEC는 두 가지 변형으로 제공되며, $\mu$-centering과 $\mu$-loss를 소개할 것이다.
## $\mu$-centering
OEC는 각 출력 임베딩 $e_i$에서 평균 출력 임베딩 $\mu$를 뺌으로써 결정론적이고 하이퍼파라미터 없이 구현될 수 있다. 최적화 단계 후 새로운 출력 임베딩 $e_i^\star$:
``` math
\begin{align}
e_i^\star &= e_i - \mu
\label{eq:output_embedding_centering}
\end{align}
그러나 $\mu$-centering은 덜 명백하지만 더 중요한 효과도 가지고 있다: Lemma 4의 전역 로짓 제한을 감소시켜, $| l_i |$의 무제한 성장 및 발산을 억제한다. Theorem 6에서 이를 정식화하기 전에, 다음과 같은 표기법과 어떻게 작동하는지에 대한 직관을 소개할 것이다. 각각의 개별 출력 임베딩과 평균 출력 임베딩 간의 점 곱부터 시작한다:
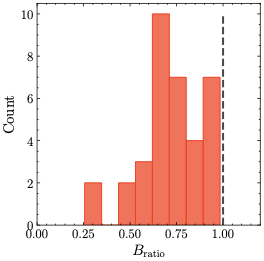
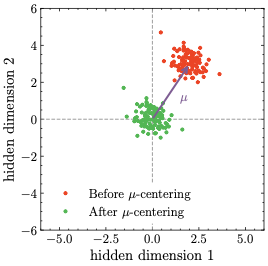
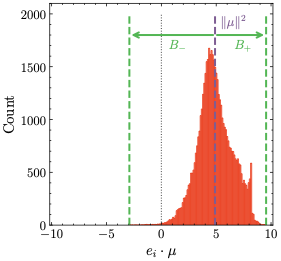
Left: Eq. ([eq:zloss])의 z-loss는 $10^{-4}$ 요인을 제외하고 나와 있다. 수직 허선은 Z = 1, 즉 z-loss가 0에 도달하는 지점을 나타낸다 (수평 허선으로 표시). Center: Anisotropic Embeddings와 $\mu$-centering의 효과를 설명한다. 보라색 화살표는 평균 임베딩 μ을 나타낸다. Right: 훈련된 모델에서 표준 언어 모델링 헤드의 점 곱 $e_i \mathpalette\mathbin{\vcenter{\hbox{\scalebox{\mu}{$\m@th.5\bullet$}}}}의 히스토그램. 빗금친 검은색 선은 0을, 보라색과 초록색 점선은 ∥μ∥2 = 4.9와 점 곱의 극값을 각각 나타낸다. 예시에서는 B− = 7.8 및 B+ = 4.7, 즉 출력 로짓 제한 감소 조건 (Eq. ([eq:theorem_oec_condition]))이 충족됨을 나타낸다: $B_{\rm ratio}= 0.82 \leq
1$.
보이는 대로, 점 곱의 분포는 보통 중심이 $\| \mu\|^2$인 왜곡된 정규분포를 약간 모방한다. 더욱 중요하게도, 이것은 $| \mu|^2 - # Limit to 15k chars for stability
 />
/>  />
/>  />
/>