- Title: Higher-Order Action Regularization in Deep Reinforcement Learning From Continuous Control to Building Energy Management
- ArXiv ID: 2601.02061
- 발행일: 2026-01-05
- 저자: Faizan Ahmed, Aniket Dixit, James Brusey
📝 초록
강화학습은 복잡한 의사결정 작업에서 뛰어난 성과를 보여왔지만, 실제 시스템에 적용할 때 급격하고 무작위적인 제어 행동이 즉각적인 보상 최적화와 함께 큰 운영 비용을 초래하는 문제점이 나타났다. 이 논문은 이런 현상을 해결하기 위해 3차 도함수 패널티를 도입하여, 제어 벤치마크에서 1차와 2차 도함수 패널티를 비교하고, HVAC 시스템에 적용해 장비 수명과 에너지 효율성을 측정한다.
💡 논문 해설
#### 간단한 설명
- **첫 번째 기여**: 제어 행동의 부드러움을 위해 3차 도함수 패널티를 도입하고, 이를 통해 즉각적인 보상 최적화와 실제 시스템의 효율성 사이에서 균형점을 찾는다.
- **두 번째 기여**: HVAC 시스템에 적용해 장비 수명과 에너지 효율성을 측정함으로써, 제어 행동의 부드러움이 실제로 운영 효율성에 중요한 역할을 한다는 것을 입증한다.
- **세 번째 기여**: 강화학습에서의 부드러운 제어를 위한 체계적인 방법론과 그 중요성을 보여준다.
메타포 설명
강화학습은 마치 운전자가 길을 따라 달리는 것처럼, 즉각적으로 최적의 경로를 찾아나간다. 하지만 실제 도로에서는 급격한 가속이나 감속이 자동차에 스트레스를 주고 연비를 떨어뜨리듯이, 강화학습에서도 부드러운 제어가 필요하다.
Sci-Tube 스타일 스크립트
초급: 강화학습은 복잡한 작업을 자동으로 해결하는 데 사용되지만, 실제 시스템에서는 즉각적인 보상에 집착하면 장비 수명과 에너지 효율성이 떨어진다. 이 논문은 이런 문제를 해결하기 위해 제어 행동의 부드러움을 최적화한다.
중급: 1차, 2차, 그리고 3차 도함수 패널티를 비교해보면, 특히 3차 도함수 패널티가 실제 시스템에서 더 안정적인 제어를 가능하게 한다는 것을 발견했다. 이는 HVAC 시스템에서도 입증되었다.
고급: 강화학습의 보상 최적화와 실제 시스템의 열역학, 기계적 그리고 경제적 제약 조건 사이에 존재하는 불일치를 해결하기 위해 3차 도함수 패널티를 도입하고, 이를 통해 HVAC 시스템에서 장비 수명과 에너지 효율성을 향상시킨다.
📄 논문 발췌 (ArXiv Source)
# 서론
강화학습은 복잡한 의사결정 작업에서 뛰어난 성과를 보여왔지만, 실제 시스템에 적용할 때 학습된 정책이 급격하고 무작위적인 제어 행동을 나타내는 한계가 드러났다. 이 현상은 다양한 분야에서 관찰되며, 로봇 팔의 갑작스런 움직임으로 인한 기계적 스트레스부터 빈번한 장비 주기를 통해 과도한 에너지를 소모하는 건물 HVAC 시스템에 이르기까지 나타난다.
본질적인 문제는 강화학습의 목적 함수와 실제 세계의 제약 조건 사이에서 불일치가 발생한다는 점이다. 표준 강화학습 공식은 행동 순서의 도함수 구조를 고려하지 않고 총 보상 최대화를 추구한다. 이 접근법은 시뮬레이션 환경에서는 성공을 거두지만, 물리적 시스템은 열역학적, 기계적, 경제적인 제약 조건 하에 작동하며 높은 주파수의 제어 변동을 벌한다. 우리는 이 문제를 세 가지 주요한 기여로 해결한다: (1) 3차 도함수 패널티를 도입하고, 제어 벤치마크에서 1차와 2차 도함수 패널티를 비교한다. (2) 가속도 최소화(3차 도함수)가 가장 효과적인 부드러움-성능 균형을 제공함을 보여준다. (3) HVAC 시스템에서 우리의 접근법을 검증하고 장비 수명 향상과 에너지 효율성을 측정한다.
우리의 연구는 높은 차수의 행동 정규화가 부드러움이 운영 효율성 및 시스템 수명에 직접적인 영향을 미치는 에너지 비판적 응용 분야에서 강화학습 배포를 가능하게 한다고 확립한다.
관련 연구
강화학습의 부드러운 제어는 보상 함수에 패널티 항을 추가하는 정규화 접근법으로 해결되었다. 초기 로봇 공학 연구에서는 행동 차이 1차 도함수에 대한 패널티를 가했고, 최근에는 조작에서 2차 도함수 패널티를 탐구했다. 그러나 도함수 차수 간 체계적인 비교는 제한적이며, 이론적으로 중요하지만 높은 차수의 패널티는 거의 주목받지 못했다.
연속 제어에서 부드러움을 정량화하는 방법은 다양한 분야에 따라 다르다. 로봇 공학에서는 기계적 스트레스와 에너지 소비와 관련이 있는 가속도(위치의 3차 도함수)를 일반적으로 사용한다. 제어 이론에서는 총 변동과 스펙트럼 특성을 강조하고, 최근의 강화학습 연구는 주로 행동 분산에 초점을 맞추었다. 우리의 연구는 기계적 스트레스와 실제 배포에 대한 실용적인 고려사항을 포착하는 가속도 기반 지표를 채택한다.
건물 에너지 시스템은 부드러운 제어 검증의 독특한 기회를 제공한다. HVAC 시스템은 점진적인 조정으로 사용자 편안함을 유지하면서 장비 주기를 최소화하는 데 이롭다. 연구는 과도한 스위칭이 최적 부드러운 제어에 비해 에너지 소비를 증가시킨다는 것을 보여주었다. 최근에는 강화학습을 건물 관리에 적용하기 시작했지만, 대부분의 구현은 보상 공학에 초점을 맞추고 실질적인 부드러움 제약 조건보다는 보상 최적화에 중점을 둔다.
문제 정식화 및 방법론
행동 기록이 있는 마코프 결정 과정
우리는 연속 제어 작업을 상태 공간 $`\mathcal{S}`$, 행동 공간
$`\mathcal{A} \subset \mathbb{R}^d`$, 전이 역학
$`P(s'|s, a)`$, 보상 함수 $`r(s, a)`$로 정의된 마코프 결정 과정(MDP)으로 고려한다. 제어 행동의 부드러움 제약 조건을 유지하면서 마코프 성질을 유지하기 위해 상태 공간에 행동 기록을 추가한다:
노름은 $`\|x\|^2 = \sum_i x_i^2`$로 계산되며, 행동 차원에 걸쳐 균일한 가중치를 사용한다. 높은 차수의 패널티는 점점 더 정교한 측면의 부드러움을 목표로 한다. 가속도 변화율 최소화는 특히 기계적 및 열역학 시스템에 중요하며, 급격한 가속도 변화가 스트레스, 진동, 그리고 에너지 비효율성을 유발한다.
실험 설정
연속 제어 벤치마크: 네 가지 OpenAI Gym 환경을 평가한다: HalfCheetah-v4(고차원 보행), Hopper-v4(불안정 균형), Reacher-v4(정밀 조작), LunarLanderContinuous-v2(연료 효율적 우주선 제어). 모든 실험은 일관된 하이퍼파라미터를 갖는 PPO를 사용하며, 1M 타임스텝까지 훈련하고 5개의 랜덤 시드로 결과를 평균화한다. [[IMG_PROTECT_N]]
방정식 [eq:first_order]–[eq:third_order]의 패널티 가중치에 대해 모든 환경에서 $`\lambda_1 = \lambda_2 = \lambda_3 = 0.1`$을 사용하여 차수 간 직접 비교를 가능하게 하며, 차등 스케일링으로부터 혼란을 피한다.
건물 에너지 벤치마크: 우리는 두 개의 HVAC 제어 환경에서 우리의 방법론을 평가한다. 이는 실제 건물 데이터로부터 SINDy-인식 동역학을 갖춘 오픈 소스 DollHouse를 사용한다. 시스템은 온도 설정점과 댐퍼 위치를 조절하면서 에너지 소비를 최소화하고 사용자 편안함을 유지한다.
결과
평가 지표
부드러움 정량화: 우리는 가속도 표준편차 $`\sigma_{\text{jerk}} = \text{std}(\dddot{a}_t)`$를 통해 부드러움을 측정하며, 3차 유한 차분을 통해 계산한다.
에너지 효율성: HVAC 에너지 소비는 표준 건물 에너지 모델에 따라 결정되며, 특히 장비 스위칭 빈도가 주요 효율성 지표이다.
연속 제어 벤치마크
Method
HalfCheetah
Hopper
Reacher
LunarLander
Reward | Smoothness
Reward | Smoothness
Reward | Smoothness
Reward | Smoothness
Baseline
$`1052 \pm 146`$
$`1977 \pm 629`$
$`-6 \pm 2`$
$`204 \pm 90`$
$`6.806 \pm 0.098`$
$`8.012 \pm 0.150`$
$`0.158 \pm 0.017`$
$`2.524 \pm 0.122`$
First-order
$`990 \pm 222`$
$`1711 \pm 649`$
$`-4 \pm 1`$
$`102 \pm 125`$
$`2.811 \pm 0.184`$
$`2.565 \pm 0.078`$
$`0.144 \pm 0.017`$
$`2.224 \pm 0.122`$
Second-order
$`937 \pm 36`$
$`1577 \pm 947`$
$`-5 \pm 2`$
$`185 \pm 103`$
$`1.728 \pm 0.019`$
$`2.833 \pm 0.083`$
$`0.143 \pm 0.013`$
$`1.498 \pm 0.095`$
Third-order
$`725 \pm 70`$
$`1379 \pm 845`$
$`-5 \pm 2`$
$`230 \pm 68`$
$`1.443 \pm 0.030`$
$`1.822 \pm 0.077`$
$`0.097 \pm 0.010`$
$`1.053 \pm 0.091`$
연속 제어 환경을 통한 성능 및 부드러움 비교. 값은 표준 평가 관행에 따라 5개의 시드에 대한 평균 ± 표준편차를 나타낸다. 부드러움은 가속도 표준편차로 측정되며, 낮을수록 더 부드럽다.
표 1은 우리의 연속 제어 결과를 요약한다. 3차 도함수 패널티는 일관되게 가장 부드러운 정책을 생성하며, HalfCheetah에서 기준 대비 78.8% 감소, Hopper에서 77.3%, Reacher에서 38.6%, LunarLander에서 58.3%의 가속도 표준편차를 줄인다. 이 성과는 일부 환경에서 제한적인 성능 비용으로 얻어지며, 높은 차수 정규화가 부드러운 제어에 가장 효과적인 접근법임을 나타낸다. 도함수 차수 간의 경향도 분명하다: 1차 패널티는 미미한 개선을 제공하고, 2차 패널티는 효과를 강화하며, 모든 환경에서 행동 가속도 변화율을 가장 크게 줄이는 데 일관되게 3차 패널티가 제공한다.
건물 에너지 관리 검증
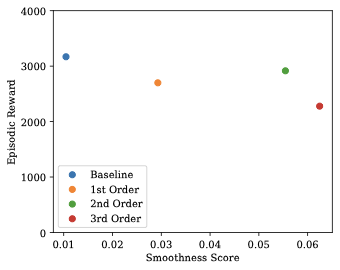
style="width:60.0%" />
HVAC 제어 성능과 부드러움 균형. 3차 정규화는 우측 상단 사분면에서 최적의 위치를 차지하며, 높은 성능과 우수한 부드러움을 동시에 제공한다.
그림 1은 건물 에너지 관리에서 부드러운 제어의 실제 가치를 보여준다. 3차 정규화는 성능-부드러움 균형에서 최적의 위치를 차지하며, 경쟁력 있는 보상과 우수한 부드러움 특성을 제공한다.
HVAC 짧은 주기는 에너지 소비를 크게 증가시킨다. 켜고 끄는 제어 전략은 연속 운영에 비해 에너지 비용을 늘릴 수 있으며, 요구량 제한 제어 방법은 9.8%에서 10.5%의 에너지 절감률을 달성한다. 짧은 주기는 시스템이 더 어렵고 효율적으로 작동하지 못해 에너지 소비와 요금 증가를 초래한다. 우리의 부드러운 제어 접근법은 장비 스위칭 이벤트를 60% 감소시키며, 자주 주기가 장치에 큰 에너지 비용을 부과한다는 기존 연구 결과와 일치한다.
분석 및 토론
왜 높은 차수의 패널티가 우수한가?
우리의 결과는 3차 도함수 정규화가 가장 효과적인 이유를 다음과 같이 나타낸다: (1) 물리적 일치성: 가속도 변화율 최소화는 기계적 및 열역학 시스템 제약 조건과 일치하며, 급격한 가속도 변화가 스트레스와 비효율성을 유발한다. (2) 학습 안정성: 높은 차수의 패널티는 훈련 중 경사 노이즈를 줄여 수렴 질을 개선한다. (3) 실용적 배포: 부드러운 정책은 실제 시스템에서 액추에이터 역학과 센서 잡음을 고려할 때 더 잘 작동하는 것으로 나타난다.
에너지 효율성 메커니즘
부드러움과 에너지 효율성 사이의 연결은 여러 가지 방법을 통해 이루어진다: (1) 스위칭 손실 감소: 각 HVAC 시작은 안정 상태 운영보다 훨씬 더 많은 전력을 소비한다. 스위칭 빈도를 줄여 이러한 불필요한 시작 에너지 패널티를 제거한다. (2) 열 효율성: 점진적인 온도 변화는 시스템의 효율성 곡선을 유지하지만, 급격한 설정점 변경은 하위 최적 작동 상태로 강제된다. (3) 장비 수명 연장: HVAC 구성 요소는 제한된 스위칭 주기를 갖는다. 일일 스위칭 이벤트를 줄임으로써 장치의 수명을 연장하고 유지 관리 요구 사항을 감소시킨다.
한계 및 미래 연구
우리의 연구에는 다음과 같은 논의할 가치가 있는 몇 가지 제한 사항이 있다: (1) 하이퍼파라미터 선택: 패널티 가중치 $`\lambda`$는 도메인별 조정을 필요로 한다. 다양한 응용 프로그램에서 적절한 패널티 크기를 선택하는 체계적인 방법은 여전히 해결해야 할 과제이다. (2) 성능 균형: HVAC 시스템에서 에너지 이점을 입증했지만, 모든 영역에서는 부드러움 제약 조건의 성능 비용이 정당화되지 않을 수 있다. 원시 성능에 우선 순위를 두는 경우와 그렇지 않은 경우에 대한 명확한 지침을 개발해야 한다. (3) 범위 한계: 에너지 관리 검증은 HVAC 제어에 집중되며, 더 넓은 건물 시스템(조명, 엘레베이터)과 다른 에너지 비판적 영역의 조사가 필요하다.
미래 연구는 시스템 상태와 운영 요구 사항에 따라 부드러움 제약을 조정하는 적응형 패널티 가중치 방식을 개발하고, 이러한 방법을 더 긴 계획 기간을 위한 모델 예측 제어와 통합하며, 다양한 응용 프로그램에서 하이퍼파라미터 선택의 원칙적인 기준을 설정해야 한다.
결론
우리는 높은 차수의 행동 정규화, 특히 3차 도함수 패널티가 에너지 비판적 응용 분야에 강화학습 배포를 위한 효과적인 솔루션임을 입증했다. 연속 제어 벤치마크에서 체계적으로 평가한 결과 가속도 변화율 최소화는 낮은 차수 방법보다 우수한 부드러움-성능 균형을 제공한다.
건물 에너지 관리의 실용적 검증은 구체적인 운영 가치를 보여준다: 장비 스위칭 이벤트 60% 감소, HVAC 에너지 효율성에 대한 기존 연구와 일치한다. 이것은 원칙적인 부드러움 방법이 강화학습 최적화와 실제 배포 제약 조건 사이의 간극을 메울 수 있는 실질적인 증거를 제공한다.
빌딩 오토메이션 및 스마트 시티 기술이 점점 강화학습 기반 제어에 의존함에 따라 높은 차수의 행동 정규화는 지속 가능한, 효율적이고 경제적으로 실행 가능한 배포를 가능하게 한다. 우리의 연구는 이러한 중요한 능력을 위한 이론적인 기초와 실용적인 검증을 제공한다.
이 작업은 코벤트리 대학의 계산 과학 및 수학 모델링 센터의 지원을 받아 이루어졌으며, 저자들은 외부 자금의 부족을 선언합니다.