- Title: Cost-Efficient Cross-Lingual Retrieval-Augmented Generation for Low-Resource Languages A Case Study in Bengali Agricultural Advisory
- ArXiv ID: 2601.02065
- 발행일: 2026-01-05
- 저자: Md. Asif Hossain, Nabil Subhan, Mantasha Rahman Mahi, Jannatul Ferdous Nabila
📝 초록
이 논문은 농업 지식에 대한 접근성을 개선하기 위해 벵골어 사용자를 위한 비용 효율적인 번역 중심의 검색 강화 생성(RAG) 프레임워크를 제안합니다. 이 시스템은 번역 -> 검색 -> 번역의 "샌드위치 아키텍처"를 채택하고, 4비트 양자화 오픈 소스 언어 모델을 활용하여 소비자가 구할 수 있는 하드웨어에서 정확한 답변을 생성합니다.
💡 논문 해설
1. **번역 중심의 RAG 파이프라인 설계**: 이 연구는 벵골어 농업 자문에 특화된 번역 기반 RAG 시스템을 설계했습니다. 이를 통해 사용자가 제공하는 벵골어 질의를 영어로 번역하고, 검색한 정보를 다시 벵골어로 번역하여 답변합니다. 이는 마치 비행기가 두 국가 사이에서 통역사 역할을 하는 것과 같습니다.
영역 특화 키워드 매핑 전략: 농부들이 사용하는 경구와 과학적 용어 간의 격차를 해소하기 위해, 시스템은 경구 표현을 과학적 용어로 변환하는 메커니즘을 도입했습니다. 이는 병원에서 의사가 환자의 증상을 이해하고 적절한 진단을 내리는 것과 유사합니다.
비용 효율적인 로컬 배포: 이 시스템은 모든 구성 요소를 로컬에서 실행하며, 양자화 기술을 활용하여 메모리 요구사항을 줄여 일반 소비자가 구할 수 있는 하드웨어에서도 작동하도록 설계되었습니다.
📄 논문 발췌 (ArXiv Source)
검색 강화 생성(RAG), 다국어 NLP, 저자원 언어, 벵골어, 농업 자문, 양자화, 대형 언어 모델(LLMs)
서론
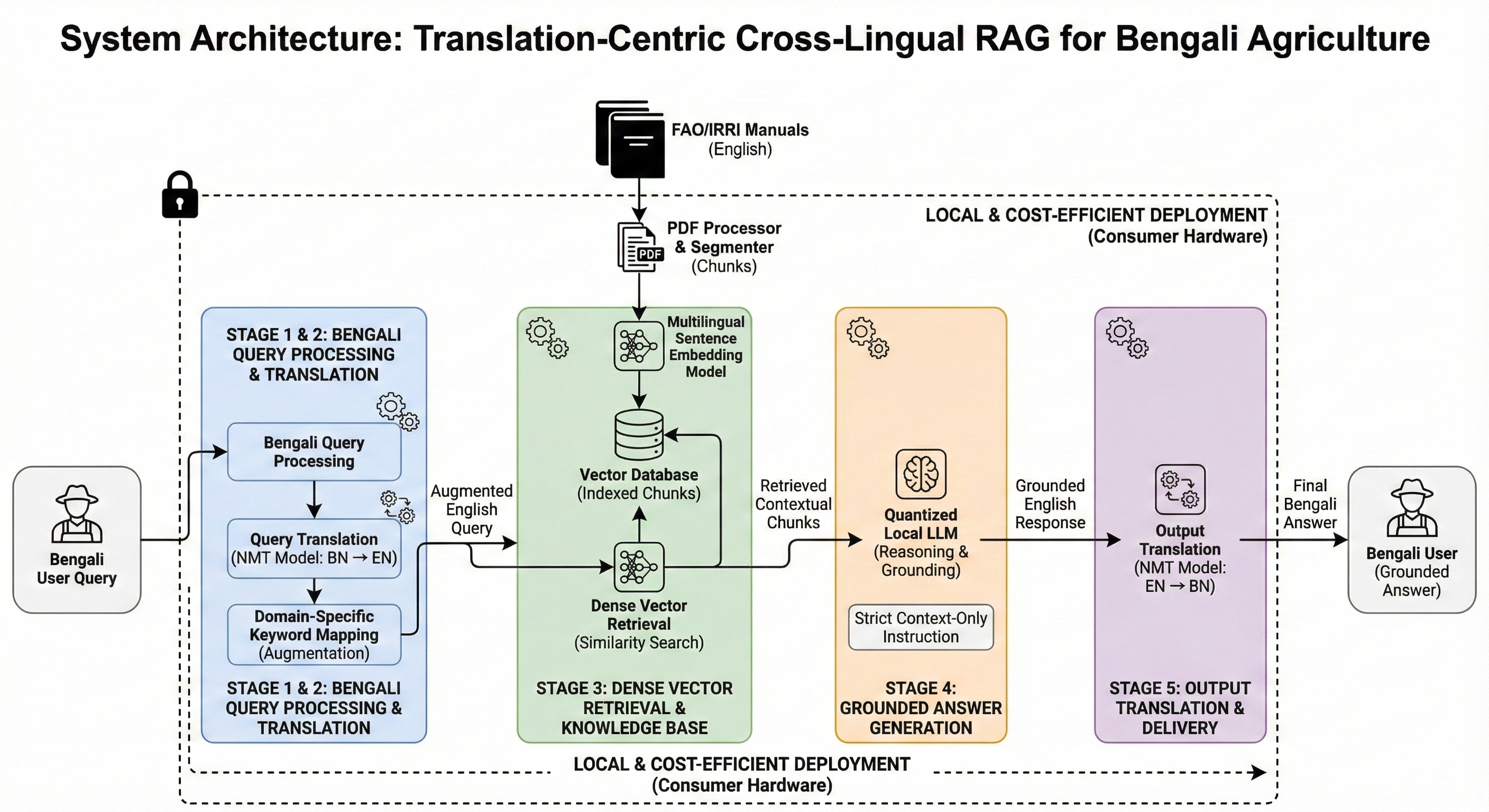
제안된 번역 중심의 다국어 RAG 파이프라인 시스템 아키텍처. 이 시스템은 벵골어 질의를 영어로 번역하고, 도메인 특화 키워드를 추가한 후, 관련 정보를 영어 매뉴얼에서 검색하여 근거 있는 답변을 생성합니다.
농업은 방글라데시와 같은 개발 중인 국가들에 있어 식량 안정성과 수입에 의존하는 수백만 사람들이 활동하고 있습니다. 국제기구인 농식품기구(FAO) 및 국제 쌀 연구소(IRRI)는 과학적으로 검증된 작물 질병, 비료 사용, 그리고 최선의 관행에 대한 지침을 포함한 상세한 농업 매뉴얼을 발행하고 있습니다. 그러나 접근성 문제로 인해 이러한 매뉴얼은 대부분 영어로 작성되어 있으며 정적 PDF 문서 형태로 배포됩니다. 지역 농부들은 주로 벵골어를 사용하기 때문에 이 정보는 사실상 접근 불가능합니다.
대형 언어 모델(LLMs)의 최근 발전으로 인해 정보 접근을 위한 자연어 인터페이스가 가능해졌습니다. 그러나 표준 LLMs을 직접 벵골어 농업 자문에 적용하는 것은 많은 제약이 있습니다. 대부분의 고성능 모델은 주로 영어 데이터로 학습되어, 벵골어 출력에서 문법적 품질이 부족하고 사실적인 불일치가 발생합니다. 또한 상업용 클라우드 기반 LLM 서비스는 저렴한 농촌 배포에 비용이 많이 듭니다. 더 중요한 문제는 외부 근거 없이 작동하는 생성 모델이 환상화(hallucinations)를 일으키기 쉽다는 것입니다. 이는 농업 관련 의사결정에서 안전하지 않은 권고를 초래할 수 있습니다.
Retrieval-Augmented Generation (RAG)은 근거 문서에 답변을 기반으로 함으로써 환상화를 줄이는 솔루션으로 제안되었습니다. RAG 시스템에서는 모델이 신뢰할 수 있는 출처에서 관련 정보를 검색한 후 답변을 생성합니다. 이러한 접근 방법은 효과적이지만, 대부분의 현재 RAG 프레임워크는 영어 사용이나 높은 컴퓨팅 자원 요구사항으로 인해 저자원 언어 및 배포 환경에서 적용이 제한됩니다.
방글라데시 농업 컨텍스트에서는 명확한 어휘 간격(gap)에 대한 추가적인 도전 과제가 있습니다. 농부들은 작물 질병과 증상(예: “Magra”)을 설명할 때 지역적 또는 구어체 용어를 자주 사용하지만, 공식 매뉴얼은 과학적 용어(예: “줄기 굶주림”)에 의존합니다. 이 불일치는 표준 검색 시스템이 사용자의 질의와 관련된 기술 문서를 효과적으로 연결하는 것을 방해합니다.
이러한 도전을 해결하기 위해, 우리는 비용 효율적인 벵골어 농업 자문용 다국어 RAG 프레임워크를 제안합니다. 벵골어로 직접 답변 생성을 강요하지 않고 번역 기반 접근 방법을 채택했습니다. 사용자의 질의는 벵골어에서 영어로 번역되며, 도메인 특화 키워드 매핑 전략을 활용하여 구어체 표현을 과학적 용어와 맞춤, 그리고 관련 문단을 검색합니다. 시스템은 근거 있는 영어 답변을 생성하고 이를 다시 벵골어로 번역해 사용자에게 제공합니다.
제안된 시스템은 오픈 소스 구성 요소를 완전히 활용하여 표준 소비자용 하드웨어에서 실행되며, 유료 클라우드 API에 의존하지 않습니다. 대표적인 질의 예제를 통해 실증 평가 결과, 시스템은 근거 있는, 문맥 상 관련성이 있는 답변을 생성하면서 실제 자문 시나리오에 적합한 실용적인 추론 지연 시간을 유지합니다.
이 연구의 주요 기여는 다음과 같이 요약됩니다:
번역 중심의 다국어 RAG 파이프라인 설계를 벵골어 농업 자문에 특화했습니다.
도메인 특화 키워드 매핑 전략을 도입하여 농부 언어와 과학적 문서 간의 격차를 해소합니다.
로컬 배포가 가능한 비용 효율적인 구현 방안을 제시했습니다.
관련 연구
최근 연구는 검색 강화 생성(RAG)이 지식 집약적인 작업에서 사실적 신뢰성을 향상시키기 위해 활용되는 방법을 탐구하였습니다. Lewis 등은 기초적인 RAG 프레임워크를 소개하며, 신경망 검색과 생성 모델을 결합하면 외부 문서에 답변을 기반으로 함으로써 환상화를 크게 줄일 수 있음을 입증했습니다. 후속 연구들은 의료와 농업 등 전문 분야로 RAG의 적용 범위를 확장하였습니다.
몇 가지 작업은 특정 도메인에 특화된 RAG 시스템을 중점적으로 다루었습니다. AgroLLM 및 관련 연구는 농업 질문-답변이 정제된 전문가 매뉴얼에서 정보를 검색하는 것이 단순히 모델의 내재 지식에 의존하는 것보다 이점을 제공함을 보여주었습니다. 그러나 이러한 시스템은 주로 영어 입력을 위한 것으로 설계되어 있으며, 고성능 컴퓨팅 자원 접근이 필요하다는 가정을 하고 있습니다.
RAG에서 저자원 언어의 도전 과제는 여러 최근 연구에서 강조되었습니다. 벵골어 및 기타 남아시아 언어에 대한 연구는 다중언어 또는 영어 중심 LLMs를 직접 사용할 때 품질이 떨어지고 사실적 정확성이 저하된다는 점을 보여주었습니다. BanglaMedQA 등의 연구는 단순히 검색만으로는 부족하다고 강조하며, 신뢰성 있는 성능을 달성하기 위해서는 지능적인 경로 및 근거 메커니즘이 필요함을 제시했습니다.
다국어 RAG는 유망한 솔루션으로 부상하고 있습니다. 이전 작업인 XRAG은 저자원 언어 질의를 영어로 번역한 후 검색하면 문서 매칭이 크게 향상된다는 것을 보여주었습니다. NLLB 및 Helsinki-NLP와 같은 대규모 다중언어 번역 모델은 신중하게 적용될 때 도메인 특화적 의미를 유지합니다. 그러나 현재의 다국어 RAG 시스템은 종종 클라우드 기반 API에 의존하고 있습니다. 최근 벤치마크는 또한 문화적으로 민감한 RAG 작업을 탐구하였습니다.
비용 효율적인 모델 배포에 대한 최신 연구는 양자화 기술이 메모리 및 컴퓨팅 요구사항을 크게 줄일 수 있음을 입증했습니다. 양자화 오픈 소스 LLMs은 완전히 로컬 배포를 가능하게 하며, 개인 정보 보호와 오프라인 접근성을 위해 중요합니다. LoRA 등의 기술은 이러한 과정을 더욱 최적화합니다. 그러나 몇 가지 연구가 양자화, 다국어 검색 및 도메인 특화 어휘 정합성 통합을 단일 시스템에 통합하지 않았습니다. 우리의 작업은 이 간극을 메우기 위해 번역 중심의 로컬 배포 가능한 RAG 시스템을 제안합니다.
시스템 아키텍처 및 방법론
시스템 개요
제안된 시스템은 번역 중심 다국어 RAG 파이프라인으로 설계되었습니다. 핵심 디자인 원칙은 사용자 상호 작용 언어(벵골어)와 추론 및 검색 언어(영어)를 분리하는 것입니다. 시스템은 5단계로 구성됩니다: (1) 벵골어 질의 처리, (2) 질의 번역과 키워드 정규화, (3) 권위 있는 영어 매뉴얼에서 문서 검색, (4) 근거 답변 생성, 그리고 (5) 벵골어로 출력 번역.
데이터 수집 및 지식베이스 구축
지식베이스는 FAO와 IRRI 등 권위적인 출처가 발행한 영어 농업 매뉴얼의 정제된 콘텐츠를 포함하고 있습니다. 각 PDF 문서는 자동 문서 로더를 사용하여 처리되며, 그 후 텍스트는 문맥적 연속성을 유지하도록 고정 길이로 겹치는 조각으로 분할됩니다.
벵골어 질의 처리 및 번역
사용자의 질의는 벵골어로 제공됩니다. 영어 중심 LLMs의 알려진 제약 때문에 벵골어에서 직접 추론을 피합니다. 대신, 각 벵골어 질의는 오픈 소스 신경망 기계 번역 모델을 사용하여 영어로 번역됩니다.
도메인 특화 키워드 매핑
주요 도전 과제 중 하나는 농부 언어와 과학적 언어 간의 불일치입니다. 이를 해결하기 위해 시스템은 도메인 특화 키워드 매핑 메커니즘을 포함합니다. 이 구성 요소는 번역된 질의에 표준화된 과학 용어를 삽입하여 검색 리콜을 개선하고 복잡한 온톨로지를 요구하지 않습니다.
밀집 벡터 검색
문서 검색에는 밀집 벡터 유사성 검색이 사용됩니다. 지식베이스의 각 텍스트 조각은 다국어 문장 임베딩 모델을 통해 임베딩됩니다. 이러한 임베딩은 벡터 데이터베이스(FAISS)에 인덱싱되어 효율적인 유사성 기반 검색을 가능하게 합니다.
근거 답변 생성
검색된 문서 조각은 로컬 배포된 양자화 대형 언어 모델에게 제공됩니다. 이 모델은 엄격한 지시문으로 프롬프트되어 검색된 문맥만 기반으로 답변을 생성하도록 명령받습니다. 필요한 정보가 존재하지 않으면, 모델이 해당 정보가 사용 불가능하다고 명확하게 표시합니다.
벵골어로 출력 번역
근거 있는 영어 답변은 NLLB 프레임워크를 사용하여 다시 벵골어로 번역됩니다. 이 최종 벵골어 출력은 사용자에게 제공되며, 그 밑바닥 추론이 검증된 영어 출처로부터 유래되었음을 보장합니다.
로컬 및 비용 효율적인 배포
모든 구성 요소는 로컬에서 실행됩니다. 언어 모델은 메모리 요구사항을 줄이기 위해 양자화 기술을 사용하여 표준 소비자 하드웨어에서 작동하도록 배포됩니다.
실험 설정
데이터셋 및 지식베이스
우리는 FAO와 IRRI로부터 수집한 영어 농업 매뉴얼의 도메인 특화 코퍼스를 정제하였습니다. 최종 코퍼스는 약 180페이지로 구성되며, 전처리 후 대략 650-700개의 텍스트 조각(600자 및 50자 겹치기)이 생성되었습니다.
검색: Sentence-Transformers (all-MiniLM-L6-v2) 및 FAISS 인덱스 사용.
LLM: Llama-3-8B-Instruct (Unsloth을 통해 4비트 양자화).
하드웨어: 단일 NVIDIA Tesla T4 GPU (16GB VRAM) on Kaggle.
결과 및 토론
이 섹션에서는 시스템의 정성적 및 실증 분석을 제시합니다.
정성 성능 분석
우리는 대표적인 질의 세 가지 범주: 병 진단, 용량 지침, 비영역 검사를 통해 시스템을 평가했습니다.
범주
사용자 질의 (벵골어)
검색된 개념
판정
병 진단
벼 곰팡이 증상
벼 곰팡이 / P. oryzae
성공
용량 지침
우레아 규칙
우레아 / 질소 적용
성공
비영역
미국 대통령은 누구입니까?
정치 / 무관
패스
정성적 분석 결과
결과는 도메인 특화 키워드 주입의 효과를 보여줍니다. 예를 들어, “Blast"에 대한 지역 용어가 Pyricularia oryzae로 성공적으로 매핑되어 FAO 및 IRRI 매뉴얼에서 정확한 검색이 가능했습니다.
시스템 지연 시간
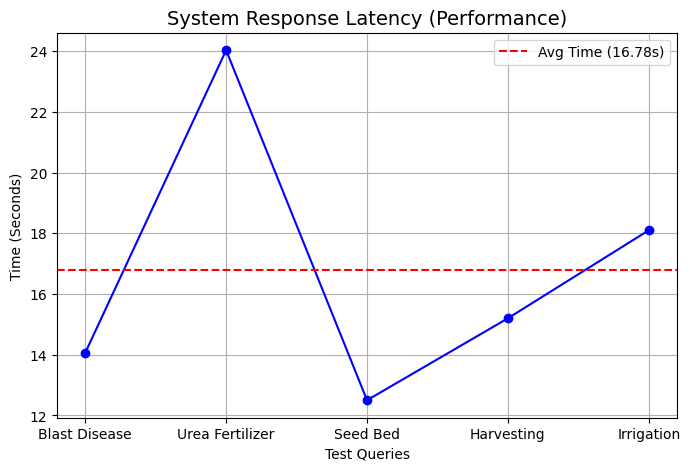
평균 전체 지연 시간은 Tesla T4 GPU에서 질의 당 약 15.6초였습니다. 지연 시간 분석은 그림 2에 나와 있습니다. 단일 언어 영어 시스템보다 높지만, 정확성보다 초당 속도가 중요하지 않은 비동기 자문 사용 사례에서는 받아들일 만한 수준입니다.
지연 시간 분석: 번역 및 LLM 추론 시간과 검색 시간 비교
출처 분포
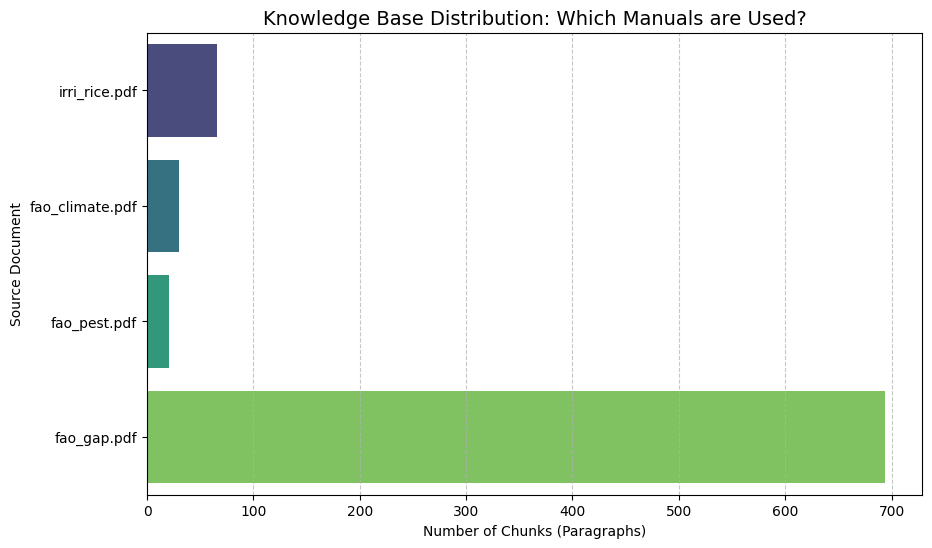
시스템은 질의 유형에 따라 다수 권위 있는 출처(FAO, IRRI)에서 균형 잡힌 검색을 보여주었습니다. 병 관련 질의는 주로 FAO 해충 가이드와 연결되었으며 비료 관련 질의는 IRRI 생산 매뉴얼과 연결되었습니다. 이는 검색 메커니즘이 적절한 문맥을 선택하는 데 효과적임을 입증합니다.
검색된 문서 분포: 권위 있는 FAO 및 IRRI 매뉴얼에 대한 의존성 확인
한계
불행히도, 제안된 시스템은 여전히 향후 연구가 필요할 정도의 몇 가지 한계를 가지고 있습니다.
번역 품질에 대한 종속성
프레임워크는 벵골어와 영어 간을 연결하는 신경망 기계 번역에 의존합니다. 초기 벵골어에서 영어로의 번역 오류나 애매함은 검색 및 추론 단계로 전파되어 답변 정확성을 저하시킬 수 있습니다.
방언과 언어적 변이
방글라데시에서 사용되는 벵골어는 지역에 따라 큰 차이가 있습니다(예: Silheti, Chittagonian, Rangpuri). 현재 시스템은 표준 벵골어 입력을 가정하고 있으며 방언 철자, 발음 또는 지역 특화 어휘를 명시적으로 처리하지 않아, 비표준 입력에 대한 성능이 저하될 수 있습니다.
추론 지연 시간
평균 전체 지연 시간은 약 15.6초로 농업 자문에서 비동기 사용에는 적합하지만 실시간 대화형 상호 작용에는 적절하지 않습니다.
정적 지식베이스
시스템은 고정된 농업 매뉴얼 코퍼스를 기반으로 운영되며, 일일 날씨 조건이나 실시간 시장 가격과 같은 동적 또는 시기적인 질의에 답변할 수 없습니다.
접근성 제약
현재 구현은 텍스트 기반 상호 작용만 지원합니다. 이는 문맹 및 준문맹 농부들에게 액세스를 제한하며, 이들은 목표 사용자 인구의 큰 부분을 차지하고 있습니다.
결론 및 미래 연구 방향
이 논문은 벵골어 사용자를 위한 농업 지식에 대한 접근성을 개선하기 위해 비용 효율적인 다국어 검색 강화 생성(RAG) 프레임워크를 제안합니다. 번역 -> 검색 -> 번역의 “샌드위치 아키텍처"와 4비트 양자화 오픈 소스 언어 모델을 활용하여 사용 가능한 하드웨어에서 정확한, 근거 있는 답변을 생성하며 유료 클라우드 API에 의존하지 않습니다.
실험 결과는 영어 농업 매뉴얼과 저자원 언어 사용자를 연결하는 효과를 입증하며 강력한 사실적 근거와 비영역 질의 거부의 견고성을 유지합니다. 발견은 다국어 검색, 통제된 번역 및 도메인 특화 키워드 매핑을 결합하여 자원이 제약되는 환경에서 농업 자문에 대해 실용적이고 확장 가능한 솔루션을 제공함을 확인합니다.
미래 연구는 여러 핵심 확장을 중점으로 합니다. 첫째, 자동 음성 인식(ASR)의 통합은 문맹 사용자의 접근성을 향상시킬 것입니다. 둘째, 지역 벵골어 방언 처리를 위해 방언에 따른 정규화 또는 다중