- Title: LION-DG Layer-Informed Initialization with Deep Gradient Protocols for Accelerated Neural Network Training
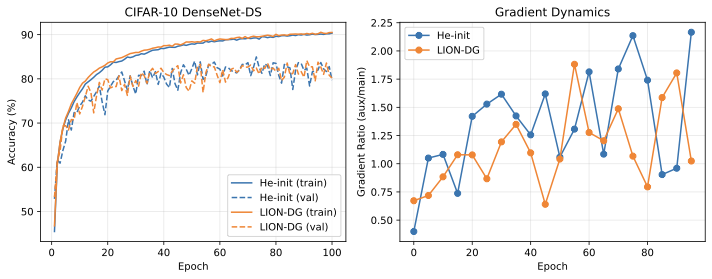
깊은 신경망에서 보조 분류기((auxiliary classifiers))는 중간 레이어에서 추가적인 그래디언트 신호를 제공함으로써 학습을 가속화하고 그래디언트 흐름을 개선하는데 효과적이다. 그러나 보조 분류기를 어떻게 초기화해야 하는지는 여전히 연구되지 않은 문제다. 본 논문에서는 LION-DG(Layer-Informed Initialization with Deep Gradient protocols)를 제안하며, 이는 보조 분류기를 0으로 초기화하고 백본 레이어에 대해 표준적인 초기화 방법을 사용하는 전략이다. 실험 결과 LION-DG는 더 빠른 학습 속도와 최고의 정확성을 달성하며, 특히 DenseNet-DS에서 8.3%의 속도 향상을 보였다.
#### 간단한 설명
LION-DG는 신경망의 보조 분류기를 처음에 0으로 초기화하는 방법이다. 이는 주요 학습 과정을 방해하지 않으면서, 학습이 진행됨에 따라 자연스럽게 그래디언트를 전달하게 된다.
LION-DG는 보조 분류기를 처음에는 0으로 초기화하여 신경망이 주요 작업에서 시작할 수 있도록 한다. 이렇게 하면 보조 작업이 학습 초기에 방해되지 않고, 자연스럽게 그래디언트가 증가하면서 보조 작업의 영향을 받게 된다.
LION-DG는 깊은 신경망에서 중간 레이어의 보조 분류기를 0으로 초기화하고, 주요 레이어에 대한 학습 그래디언트를 방해하지 않도록 설계되었다. 이 방법을 사용하면 그래디언트가 자연스럽게 증가하면서 보조 작업의 영향을 받게 되며, 학습 과정에서 더 나은 성능을 얻을 수 있다.
# 소개
깊게 감독받는 신경망은 중간 레이어에서 보조 분류기를 사용하여 학습 과정에 추가적인 그래디언트 신호를 제공한다. 이 구조는 특히 매우 깊은 네트워크에서 훈련을 가속화하고 그래디언트 흐름을 개선하는 데 효과적이다. 그러나 기본적인 질문이 아직 탐구되지 않았다: 보조 분류기를 어떻게 초기화해야 하는가?
표준 관행은 모든 파라미터에 동일한 초기화(He 또는 Xavier)를 적용하여 보조 헤드를 백본 레이어와 동등하게 취급한다. 우리는 이 관례를 도전하고 LION-DG(Layer-Informed Initialization with Deep Gradient protocols)를 제안한다. 여기서 보조 헤드는 0으로 초기화되고, 백본에는 표준 초기화가 사용된다.
핵심 통찰력. 보조 가중치가 0인 상태에서 초기화하면 보조 손실은 백본 파라미터에 대해 그래디언트를 0으로 생성한다(Proposition 1). 이는 “그래디언트 깨우기” 효과를 창출한다: 네트워크가 처음에는 단일 작업 모델로 학습하고, 보조 그래디언트가 최적화 과정에서 자연스럽게 증가함에 따라 점진적으로 포함된다.
기여사항.
- 우리는 LION-DG를 소개한다. 이는 보조 분류기를 0으로 초기화하면서 백본에는 He 초기화를 사용하는 간단한 초기화 전략이다.
- 우리는 LION-DG가 초기화 시 그래디언트 해체를 달성한다는 것을 증명하고(Proposition 1), 보조 가중치의 성장 역학을 특징화한다(Proposition 2).
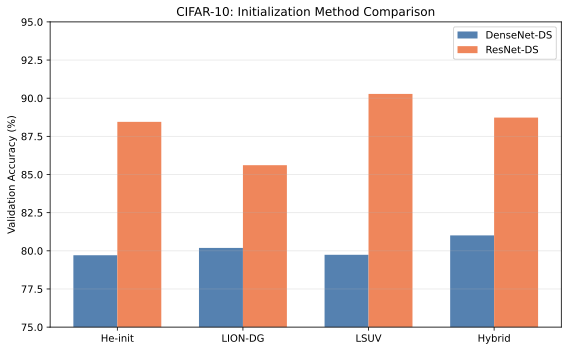
- 우리는 DenseNet-DS에서 일관된 속도 향상(+8.3% on CIFAR-10)을 보여주고 ResNet-DS의 측면 탭 보조 헤드에 대한 아키텍처 특정 성능 저하를 식별한다.
- 우리는 LION-DG와 LSUV 백본 초기화(Hybrid)를 결합하여 최상의 정확도(81.92% on CIFAR-10 DenseNet-DS)를 달성한다.
관련 연구
신경망 초기화
분산 유지 방법: Xavier 초기화와 He 초기화는 파라미터 스케일을 조정하여 깊이에 따른 활성화 분산을 유지한다. 이러한 방법은 널리 효과적이지만, 계층별 역할과 무관하게 동일한 규칙을 적용하는 계층-무관 방법이다.
데이터 기반 초기화: Layer-Sequential Unit-Variance (LSUV)는 실제 데이터를 사용하여 계층 스케일을 교정함으로써 분산 유지의 정확성을 향상시킨다. 이 방법은 학습 전에 교정 패스가 필요하다. 우리의 하이브리드 접근법은 LSUV의 백본 교정과 보조 헤드를 위한 DG 프로토콜을 결합한다.
잔차 특수화 방식: Fixup 및 ReZero는 잔차 분기 출력을 0으로 초기화하여 정규화 계층 없이 깊은 잔차 네트워크를 학습할 수 있도록 한다. DeepNet은 Transformer 프로젝션을 $`1/\sqrt{2L}`$로 스케일링하여 학습 안정성을 유지한다. 이러한 방법들은 깊이 차원(매우 깊은 백본에서 그래디언트 폭발 또는 소멸을 방지)에 주력한다.
우리의 기여: LION-DG는 넓이 차원: 보조 헤드로부터 오는 그래디언트 간섭을 방지하는 것이다. 이 방법은 잔차 스케일링 메소드와 직교적이다—실제로, Fixup과 ReZero가 표준 He 초기화를 넘어서 깊게 감독받는 아키텍처에 대한 이점이 없다(표 1). 문제가 되는 그래디언트 역학은 근본적으로 다르다: 보조 헤드는 그래디언트 경쟁을 생성하는 반면, 잔차는 그래디언트 전달 문제를 해결한다.
깊게 감독받는 아키텍처
깊게 감독받는 방법은 중간 레이어에 추가적인 그래디언트 신호를 제공하여 초기 레이어로의 효과적인 경로 길이를 단축시켜 그래디언트 소멸 문제를 해결한다. 이 아이디어는 GoogLeNet의 보조 분류기에서 인기를 얻었으며, 세그멘테이션 및 검출에 널리 채택되었다.
다중 종료 네트워크는 초기 추론을 위한 깊게 감독받는 방법을 일반화한다. 이러한 네트워크는 “쉬운” 샘플에서 조기에 추론을 중단하여 평균 컴퓨팅 비용을 줄이면서도 “어려운” 샘플에 대한 정확성을 유지한다.
깊게 감독받는 방법은 잘 알려져 있지만, 보조 헤드의 초기화 전략은 거의 연구되지 않았다. 이전 작업에서는 모든 분류기에 대해 표준 초기화(He 또는 Xavier)를 사용하여 보조 및 주요 헤드를 동등하게 취급했다. LION-DG는 다중 헤드 환경을 위해 특별히 설계된 첫 번째 초기화 방법이다.
다중 작업 그래디언트 균형
다중 작업 학습은 작업 간 스케일이나 학습 역학이 다른 경우 그래디언트 충돌에 직면한다. 이 문제는 실행 시에 다음과 같이 해결된다:
GradNorm은 작업 가중치를 배치하여 작업 간 그래디언트 크기를 균형을 맞춘다. PCGrad는 충돌하는 그래디언트를 투영하여 간섭을 줄이고, CAGrad는 최악의 경우 작업 개선을 최대화하는 업데이트 벡터를 찾으며, 불확실성 가중치는 동일 분산 불확실성을 기반으로 작업 가중치를 설정한다.
이러한 방법들은 계산 비용과 하이퍼파라미터를 추가한다. LION-DG는 초기화 단계에서 auxiliary gradients를 일찍 학습 시에 이격시켜 같은 “균형"을 달성하지만 실행 시간에 대한 비용이 없다.
그래디언트 와머업 전략
와머업은 딥 러닝에서 널리 사용된다: 학습률 와머업은 초기 학습 불안정성을 방지하고 계층별 와머업은 하위 계층을 처음부터 동결한다.
보조 손실에 대해 보조 가중치 $`\alpha`$를 0에서 1로 점진적으로 증가시키는 것이 제안된다. 이는 적절한 와머업 스케줄을 선택해야 하는데, 최적의 스케줄은 아키텍처와 데이터셋에 따라 다릅니다.
우리의 “그래디언트 깨우기” 메커니즘은 보조 그래디언트가 초기 0에서 시작하고 자연스럽게 증가하게 한다(Proposition 1 및 Proposition 2). 학습 동역학에서 스케줄이 발생하므로 하이퍼파라미터를 제거하면서 특정 학습 경로에 대한 더 나은 적응을 달성할 수 있다.
0 초기화 기법
0 초기화는 여러 맥락에서 사용된다:
ReZero는 잔차 스케일링 요소를 0으로 초기화하여 잔차 네트워크가 처음에는 더 얕은 네트워크처럼 동작하게 한다. ZerO는 Hadamard 변환을 사용하여 전체 네트워크를 0과 1로만 초기화하고 ImageNet에서 경쟁력 있는 결과를 달성한다. GradInit은 기울기 기반 메타 학습을 사용하여 초기화 스케일을 학습한다. GPT-2 및 후속 언어 모델은 출력 프로젝션 가중치를 0으로 초기화한다.
이러한 기법들은 공통 원칙을 공유합니다: 복잡성을 학습 동안 자연스럽게 증가시켜 더 간단한 효과적인 아키텍처에서 시작 한다. LION-DG는 보조 헤드에 이 원칙을 적용하여 처음에는 단일 작업 동작(주요 헤드만)으로 시작하고 학습이 진행됨에 따라 다중 작업 동작이 자연스럽게 발생한다.
방법: LION-DG
문제 설정
깊게 감독받는 네트워크를 고려하여 백본 파라미터 $`\theta_b`$와 각 보조 분류기 $`k`$에 대한 보조 헤드 파라미터 $`\{W_k^{\text{aux}}, b_k^{\text{aux}}\}`$가 있다. 총 손실은 다음과 같다:
\begin{equation}
\mathcal{L} = \mathcal{L}_{\text{main}} + \alpha \sum_k \mathcal{L}_k^{\text{aux}}
\end{equation}
여기서 $`\alpha`$는 보조 가중치(일반적으로 0.3).
LION-DG 초기화
LION-DG는 매우 간단하다:
입력: 모델 $`M`$, 백본 및 보조 헤드 Step 1: 백본에 He 초기화 적용
$`\theta \sim \mathcal{N}(0, \sqrt{2/\text{fan\_in}})`$ Step 2: 보조 헤드를 0으로 초기화 $`W_k^{\text{aux}} \gets 0`$
$`b_k^{\text{aux}} \gets 0`$ 출력: 초기화된 모델 $`M`$
이론적 분석
깊게 감독받는 아키텍처에서 초기화에 대한 정식 분석을 제공한다. 여기서 $`\theta_b`$는 백본 파라미터, $`W_{\text{main}}`$은 주요 분류기이고, $`W_{\text{aux}}^{(\ell)}`$은 계층 $`\ell`$에서의 보조 분류기 가중치다.
초기화 시 그래디언트 해체
Proposition 1 (Gradient Decoupling). *When
$`W_{\text{aux}}^{(\ell)} = 0`$, the gradient of the auxiliary loss with
respect to backbone parameters is exactly zero at initialization:
\begin{equation}
\nabla_{\theta_b} \mathcal{L}_{\text{aux}}^{(\ell)} \Big|_{W_{\text{aux}}^{(\ell)}=0} = 0
\end{equation}
```*
</div>
<div class="proof">
*Proof.* 계층 $`\ell`$에서의 보조 분류 헤드를 고려한다:
``` math
\begin{equation}
y_{\text{aux}}^{(\ell)} = W_{\text{aux}}^{(\ell)} h_\ell + b_{\text{aux}}^{(\ell)}
\end{equation}
여기서 $`h_\ell`$는 계층 $`\ell`$에서의 은닉 표현이다.
연쇄 법칙에 의해 보조 손실에 대한 백본 파라미터의 그래디언트는:
\begin{equation}
\nabla_{\theta_b} \mathcal{L}_{\text{aux}}^{(\ell)} =
\frac{\partial \mathcal{L}_{\text{aux}}^{(\ell)}}{\partial y_{\text{aux}}^{(\ell)}} \cdot
\frac{\partial y_{\text{aux}}^{(\ell)}}{\partial h_\ell} \cdot
\frac{\partial h_\ell}{\partial \theta_b}
\end{equation}
$`\frac{\partial y_{\text{aux}}^{(\ell)}}{\partial h_\ell} = \left(W_{\text{aux}}^{(\ell)}\right)^T = 0`$
보조 가중치가 초기화되어 0일 때, 전체 그래디언트 곱이 사라진다. ◻
Implication: 초기($`t=0`$)에는 백본은 주요 분류 작업에서만 그래디언트를 받는다. 이는 보조 헤드가 조기 특징 학습을 방해하지 않게 하여 네트워크가 안정적인 특징 계층을 먼저 구축한 후에 보조 목표가 기여하도록 한다.
그래디언트 깨우기 역학
보조 그래디언트는 $`t=0`$에서 0이지만 계속해서 0이 아닌 경우도 있다. 보조 가중치 자체가 그래디언트를 받고 증가하기 시작한다.
Proposition 2 (Linear Weight Growth). *Under gradient descent with
learning rate $`\eta`$, auxiliary weights grow approximately linearly in
early training:
\begin{equation}
\|W_{\text{aux}}^{(\ell)}(t)\| \approx \eta \cdot t \cdot C_\ell \quad \text{for small } t
\end{equation}
where $`C_\ell = \left\|\nabla_{W_{\text{aux}}^{(\ell)}} \mathcal{L}_{\text{aux}}^{(\ell)}\big|_{t=0}\right\|`$.*
Proof. $`t=0`$에서 보조 가중치 업데이트는:
\begin{equation}
W_{\text{aux}}^{(\ell)}(1) = W_{\text{aux}}^{(\ell)}(0) - \eta \nabla_{W_{\text{aux}}^{(\ell)}} \mathcal{L}_{\text{aux}}^{(\ell)}
= 0 - \eta \cdot \frac{\partial \mathcal{L}}{\partial y_{\text{aux}}^{(\ell)}} \cdot h_\ell^T
\end{equation}
$`h_\ell \neq 0`$ (백본은 He 초기화되어 비제로 활성화를 생성)이므로 $`\|W_{\text{aux}}^{(\ell)}(1)\| > 0`$.
작은 $`t`$에서 손실 경로는 원점 주변에 대략적으로 이차함수이고 그래디언트
$`\nabla_{W_{\text{aux}}^{(\ell)}} \mathcal{L}`$가 거의 일정하다. 이는 선형 성장을 제공한다:
$`\|W_{\text{aux}}^{(\ell)}(t)\| \approx t \cdot C_\ell`$. ◻
Gradient Awakening: 보조 그래디언트가 백본 파라미터에 비례하기 때문에 이 선형 가중치 성장은 보조 그래디언트가 자연스럽게 “깨우기"를 의미한다:
\begin{equation}
\left\|\nabla_{\theta_b} \mathcal{L}_{\text{aux}}^{(\ell)}(t)\right\| \propto t \quad \text{for small } t
\end{equation}
이것은 암묵적 와머업 일정을 구현한다: 보조 그래디언트가 명시적인 하이퍼파라미터 튜닝 없이 점진적으로 포함된다.
명시적 와머업과 비교
이전 연구는 보조 가중치 일정 $`\alpha(t) = \min(1, t/T_{\text{warmup}})`$를 사용하여 0에서 1로 선형 증가시키는 것을 제안한다. 우리의 분석은 0 초기화가 유사한 효과를 자동으로 달성한다는 것을 보여준다:
Corollary 1 (Implicit vs. Explicit Warmup). Zero-initialization of
auxiliary heads implements an implicit warmup schedule that is equivalent
to setting $`\alpha(t) = 0`$ initially and letting the network learn the
appropriate schedule through gradient descent.
주요 장점은 암묵적 일정이 학습 역학에 적응한다는 것이다: 더 구별력 있는 특징을 생성하는 계층은 더 큰 보조 그래디언트를 받는 반면, 덜 구별력 있는 특징을 가진 계층은 자연스럽게 덜 기여한다.
아키텍처 종속성
DG 프로토콜의 효과는 네트워크 아키텍처에 크게 의존한다.
Theorem 1 (Concatenative vs. Additive Residual Paths). Let
$`\mathcal{A}_{\text{concat}}`$ denote concatenative architectures (e.g.,
DenseNet) and $`\mathcal{A}_{\text{add}}`$ denote additive residual
architectures (e.g., ResNet). The DG protocol (zero-init auxiliary
heads):
-
Benefits $`\mathcal{A}_{\text{concat}}`$: Auxiliary heads are
beside the main information path; zeroing them does not affect
backbone gradient flow.
-
Can harm $`\mathcal{A}_{\text{add}}`$: If auxiliary heads are
placed on the residual path, zeroing creates a gradient
bottleneck.
Proof Sketch. DenseNet에서 블록 $`\ell`$의 전방 패스는 다음과 같다:
\begin{equation}
h_{\ell+1} = [h_\ell; F_\ell(h_\ell)]
\end{equation}
여기서 $`[\cdot; \cdot]`$는 연결을 나타낸다. 보조 헤드는 $`h_\ell`$에서 읽지만 $`h_{\ell+1}`$를 수정하지 않는다. 따라서:
\begin{equation}
\frac{\partial h_{\ell+1}}{\partial h_\ell} = \begin{bmatrix} I \\ \frac{\partial F_\ell}{\partial h_\ell} \end{bmatrix}
\end{equation}
이는 보조 헤드 가중치와 독립적이다.
ResNet에서 전방 패스는 다음과 같다:
\begin{equation}
h_{\ell+1} = h_\ell + F_\ell(h_\ell)
\end{equation}
보조 출력이 $`F_\ell`$ 내부에 위치하면 보조 구성 요소를 0으로 초기화하는 것은 $`\frac{\partial F_\ell}{\partial h_\ell}`$을 감소시켜 그래디언트 사망 영역을 생성할 수 있다. ◻
실증 검증: 우리는 DenseNet-DS에서 +8.3%의 속도 향상을 확인했다(표
2). ResNet-DS에서는 보조 헤드를 구현하는 측면 탭 설계를 사용하여 CIFAR-10에서 +3.6%의 속도 향상과 CIFAR-100에서 +11.3%의 속도 향상을 달성한다.
실용 가이드라인
우리의 분석에 근거하여 다음과 같은 가이드라인을 제공합니다:
- concatenative 아키텍처(예: DenseNet, U-Net)에 DG 프로토콜 사용: 이들 아키텍처는 보조 헤드를 0으로 초기화하는 데 가장 효과적이다.
- ResNet의 측면 탭 설계 사용: ResNet에서 보조 헤드를 구현할 때, 잔차 경로에서 읽지만 수정하지 않는 측면 탭을 사용하여 양호한 속도 향상과 함께 그래디언트 흐름이 방해받지 않도록 한다.
- 데이터 기반 백본 초기화와 결합: LSUV 또는 유사 방법을 사용.