대형 언어 모델(LLMs)은 강력한 의학적 지식을 보유하고 사실적으로 정확한 답변을 생성할 수 있습니다. 그러나 기존의 모델들은 종종 개별 환자의 상황을 고려하지 못해 임상적으로는 맞지만 환자들의 요구와 잘 맞지 않는 답변을 제공하는 경향이 있습니다. 본 연구에서는 DeCode라는 훈련이 필요 없고 모델에 무관한 프레임워크를 소개합니다. 이 프레임워크는 기존 LLMs을 임상 환경에서 상황에 맞는 답변을 생성하도록 조정합니다. 우리는 OpenAI HealthBench, 즉 LLM 응답의 임상적 관련성과 유효성을 평가하기 위해 설계된 포괄적이면서도 어려운 벤치마크를 사용하여 DeCode를 평가했습니다. DeCode는 이전 최고 기록인 28.4%에서 49.8%로 성능을 향상시켰으며, 이는 상대적으로 75%의 개선입니다. 실험 결과는 LLMs의 임상적 질문에 대한 답변 품질을 개선하는 데 DeCode가 효과적임을 시사합니다.
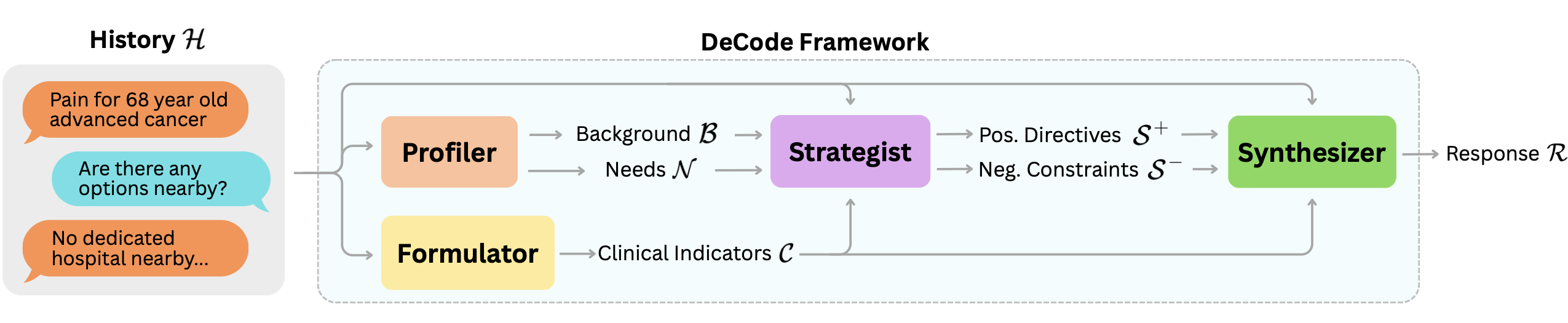
1. **DeCode 프레임워크 소개**: DeCode는 환자 맞춤형 의료 응답 생성을 위한 모듈화 접근법입니다. 이 프레임워크는 기존 대화에서 여러 분석적 관점을 추출하고, 이를 통합하여 의학적으로 정확하면서도 환자 맥락에 적합한 최종 응답을 제공합니다.
2. **응답 생성의 구조화**: DeCode는 사용자의 배경과 필요를 이해하는 'Profiler', 임상 지표를 추출하는 'Formulator', 의사소통 전략을 결정하는 'Strategist', 그리고 최적의 응답을 생성하는 'Synthesizer' 모듈로 구성됩니다.
3. **성능 향상**: DeCode는 HealthBench에서 성능을 크게 개선하며, 이전 최고 기록인 28.4%를 49.8%까지 높였습니다.
# 소개
대형 언어 모델(LLMs)은 최근 다양한 의료 자연어 처리 작업에서 강력한 성능을 보여주었으며, 특히 의학적 질문-답변(QA) 작업에서 뛰어난 결과를 내고 있습니다. 이 작업에서는 모델이 임상적으로 중요한 질문에 대한 올바른 답변을 생성할 수 있는 능력을 평가합니다. 이 개발은 여러 선택지와 생성형 설정, 전문적 시험 유형의 문제, 그리고 오픈 도메인 임상 지식 평가를 포함한 의학 QA 벤치마크 컬렉션을 통해 입증되었습니다. 이러한 평가 결과는 현대 LLMs이 표준화된 테스트 조건 하에서 상당한 의료 지식과 추론 능력을 가지고 있음을 보여줍니다.
기존의 의학적 QA 벤치마크 대부분은 정답의 정확성이나 추론 정확성을 측정하도록 설계되어 있으며, 종종 완전 일치, 여러 선택지 선별, 또는 전문가의 사실적 유효성 평가를 통해 이를 수행합니다. 이러한 지표는 지식 회상과 임상 추론을 평가하는 데 적합하지만 환자와 의사 소통 시나리오에서 모델 응답이 이해할 수 있는지, 환자 맥락에 적절하게 조정되었는지, 안전하고 동정심 넘치는 의료 의사소통의 기준과 일치하는지를 포착하지 못합니다.
이 한계가 정확성 지표를 넘어 평가 프레임워크를 필요로 하는 동기를 부여하며, OpenAI HealthBench는 이 간극을 메우기 위해 사실적 정확성을 포함한 여러 질적 차원에서 의료 LLM 출력을 평가하도록 설계되었습니다. 기존 의학 QA 데이터셋과 달리 HealthBench는 응답 전달 방식이나 대상에 독립적인 단일 정답을 가정하지 않고, 의료 응답의 상호작용적 측면을 명시적으로 모델링하여 임상적으로 관련된 응답 품질에 대한 세밀한 분석이 가능하게 합니다.
HealthBench에서의 경험적 결과는 전통적인 의학 QA 벤치마크에서 유사한 정확성을 가진 모델들이 다른 비정확성 차원에서 상당한 변동을 보여준다는 것을 나타냅니다. 이는 표준화된 QA 성능과 환자 중심 맥락 인식 사이의 불일치를 드러내며, 의료 LLM에 대한 다차원 평가의 중요성을 강조합니다.
본 연구에서는 Decoupling Content and Delivery(DeCode) 프레임워크를 소개합니다. DeCode는 클리니컬 대화에서 환자 특정 응답을 생성하기 위한 모듈화 접근법입니다. DeCode는 기존 의료 상호작용을 여러 보완적인 분석적 관점으로 나누며, 각각은 전문 LLM 모듈을 통해 구현됩니다. 이 모듈의 출력은 최종적으로 의학적 정확성과 환자 맥락을 고려한 응답을 생성하기 위해 통합됩니다.
중요하게도, DeCode는 훈련 없는 패러다임에서 작동하며, 명시적인 클리니컬 형식화와 구조화된 의사소통 제약 조건을 통해 생성 과정을 조율합니다. 경험적으로 우리는 DeCode가 HealthBench의 성능을 크게 개선하고 이전 최고 기록인 28.4%를 49.8%까지 높였음을 보여주었습니다. 또한, DeCode는 여러 선두 LLM에 걸쳐 일관되게 일반화됨을 보여주며, 이를 통해 개인화된 의료 응답 생성의 모델 무관 원칙이 포착되고 있음을 시사합니다.
본 논문의 나머지 부분은 다음과 같이 구성되어 있습니다. 관련 작업은 섹션 2에서 소개됩니다. 제안된 방법론은 섹션 3에 제시됩니다. 실험 설정과 결과는 각각 섹션 4와 섹션 5에서 제공됩니다. 마지막으로, 섹션 6에서는 논문을 결론짓습니다.
관련 연구
대형 언어 모델(LLMs)의 초기 의학적 질문-답변 평가에는 주로 표준화된 여러 선택지 벤치마크가 포함되었습니다. 이들 벤치마크는 MedQA, MedMCQA, PubMedQA 등이 있으며, 이러한 벤치마크들은 LLMs의 의학 지식을 평가하고 개선하는 데 큰 연구를 촉발시켰습니다. 그러나 이러한 평가는 본질적으로 정적이고 정확성 중심적이므로 의사소통 능력, 맥락 감수성, 그리고 사실적 정확성을 넘어서 환자 중심 전달을 평가하기에는 한계가 있습니다.
HealthBench는 개방형, 다중 턴 의료 대화를 기반으로 하는 의학 QA에 대한 다차원 평가 프레임워크를 도입합니다. 기존의 여러 선택지 벤치마크와 달리 HealthBench는 의사가 작성한 챠트를 사용하여 임상적 정확성, 의사소통 품질, 맥락 인식 등 행동 차원을 평가함으로써 의학 QA 시스템에 대해 더 포괄적인 평가를 가능하게 합니다.
MuSeR는 HealthBench에 초점을 맞추어 학생 LLM이 참조 교사 모델로부터 고품질 응답을 통해 안내받는 자기 개선 프레임워크를 제안합니다. 원래 표현에서 MuSeR는 데이터 합성과 지도 훈련을 사용합니다: 학생은 초기 응답을 생성하고 여러 차원에 걸친 구조화된 자기 평가를 수행한 후 수정된 최종 답변을 제공합니다. 이러한 훈련 기반 파이프라인은 계산적으로 집약적이며 주로 훈련 가능한 오픈 소스 LLM에 적용되지만, 핵심 자기 개선 프로세드는 추론 시에도 적용될 수 있어 응답 개선을 위한 모델 증류나 미세 조정 없이 가능합니다.
병행적으로, 복잡한 의학적 QA를 해결하기 위해 전문 역할에 따라 추론을 분해하는 다중 에이전트 프레임워크가 제안되었습니다. MedAgents는 토론 기반 가설 개선을 위한 역할 연기 전문가를 사용하고, MDAgents는 쿼리 복잡성에 따라 전문가 팀을 동적으로 구성합니다. 최근 접근법은 이 패러다임을 더욱 확장하며, KAMAC은 생성 중 지식 간극을 해결하기 위해 수요에 따른 전문가 모집을 도입하고 AI Hospital은 상호작용 환자 시뮬레이션 환경에서 에이전트 기반 시스템을 평가합니다. 그러나 이러한 방법들은 주로 진단 추론과 전통적인 벤치마크의 정확성을 강조하며, 복잡한 추론 결과가 명확하고 사용자와 일치하는 응답으로 어떻게 번역되는지 종종 무시됩니다.
이 관찰에 근거하여 우리는 DeCode를 소개합니다. 이는 의학적 내용 추론을 응답 전달로부터 명시적으로 분리하는 모듈화 프레임워크입니다. 훈련 기반 또는 에이전트 중심 접근법과 달리 DeCode는 추가적인 훈련이나 특정 모델에 대한 의존성을 필요로 하지 않으며, 구조화된 생성을 지원하여 맥락화되고 사용자와 일치하는 의료 응답을 강조합니다. 다음 섹션에서 우리의 구현을 소개하겠습니다.