- Title: FormationEval, an open multiple-choice benchmark for petroleum geoscience
- ArXiv ID: 2601.02158
- 발행일: 2026-01-05
- 저자: Almaz Ermilov
📝 초록
대형 언어 모델(LLMs)이 과학 및 공학 분야의 전문적인 작업에 점점 더 많이 적용되고 있지만, 이러한 모델들이 특정 분야에서 얼마나 효과적으로 작동하는지 평가하기는 여전히 어려움이 있습니다. 일반적인 벤치마크인 MMLU는 광범위한 지식을 다루지만 전문 분야에 대한 집중적 평가는 제한적입니다. 석유 지질학과 지하시공 엔지니어링(심화 측정 물리학, 유전 특성화, 지질 해석 등 이해가 필요한 분야)에서 공개적으로 이용 가능한 벤치마크는 여전히 제한적입니다.
이 연구는 FormationEval이라는 505문항의 다중 선택형 질문 벤치마크를 통해 이러한 간극을 메우며, 이 벤치마크는 페트로물리학, 석유 지질학, 지구 물리학, 유전 공학, 침적학, 심층 공학 및 생산 공학 등 7개 영역을 다룹니다. 질문은 권위 있는 교과서와 개방형 강의 자료를 기반으로 개념 중심 방식을 사용하여 작성되며, 이는 문구 인식이 아닌 이해도를 테스트하며 저작권 제약을 준수합니다.
주요 기여는 다음과 같습니다: 1) 기술적 출처에서 다중 선택형 질문(MCQs) 생성 방법론; 2) 출처 메타데이터와 오염 위험 레이블이 포함된 정제 데이터 세트; 그리고 3) 여러 제공업체의 72개 언어 모델에 대한 평가, 이를 통해 도메인과 난이도 수준별 성능 패턴을 파악할 수 있습니다.
💡 논문 해설
1. **기여물: 개념 기반 질문 생성 방법론**
- 메타포: 이 연구는 LLMs에게 전문적인 지식을 테스트하는 문제를 만드는 새로운 길을 열었습니다. 그림으로 말하자면, 기존의 도로가 아니라 새롭게 만들어진 산책길을 따라 걸으며 더 깊은 이해를 얻을 수 있게 해줍니다.
기여물: 정제된 데이터 세트
메타포: 이 연구는 공학 분야에서의 문제 해결 능력을 평가하기 위해 치밀하게 만들어진 도자기와 같은 데이터 세트를 제공합니다. 각 도자기는 특정 기술적 주제에 대한 지식을 테스트하고, 저작권 위반 없이 작성되었습니다.
기여물: 다양한 언어 모델 평가
메타포: 이 연구는 여러 LLMs의 능력을 시험하기 위해 다양한 종류의 과일을 준비한 것과 같습니다. 각 과일은 다른 맛과 영양소를 가지고 있어, 어떤 과일이 가장 맛있는지 평가할 수 있게 해줍니다.
📄 논문 발췌 (ArXiv Source)
# 서론
대형 언어 모델(LLMs)은 과학 및 공학 분야의 전문적 작업에 점점 더 많이 적용되고 있지만, 이러한 모델들이 특정 분야에서 얼마나 효과적으로 작동하는지 평가하기는 여전히 어려움이 있습니다. 일반적인 벤치마크인 MMLU는 광범위한 지식을 다루지만 전문 분야에 대한 집중적 평가는 제한적입니다. 석유 지질학과 지하시공 엔지니어링(심화 측정 물리학, 유전 특성화, 지질 해석 등 이해가 필요한 분야)에서 공개적으로 이용 가능한 벤치마크는 여전히 제한적입니다.
이 연구는 FormationEval이라는 505문항의 다중 선택형 질문 벤치마크를 통해 이러한 간극을 메우며, 이 벤치마크는 페트로물리학, 석유 지질학, 지구 물리학, 유전 공학, 침적학, 심층 공학 및 생산 공학 등 7개 영역을 다룹니다. 질문은 권위 있는 교과서와 개방형 강의 자료를 기반으로 개념 중심 방식을 사용하여 작성되며, 이는 문구 인식이 아닌 이해도를 테스트하며 저작권 제약을 준수합니다.
기여물들은 다음과 같습니다: (1) 기술적 출처에서 다중 선택형 질문(MCQs) 생성 방법론; (2) 출처 메타데이터와 오염 위험 레이블이 포함된 정제 데이터 세트; 그리고 (3) 여러 제공업체의 72개 언어 모델에 대한 평가, 이를 통해 도메인과 난이도 수준별 성능 패턴을 파악할 수 있습니다.
관련 연구
일반적인 벤치마크인 MMLU는 광범위한 지식과 추론 능력을 평가하지만 특정 분야에 대한 커버리지는 제한적입니다. MMLU는 57개 주제를 포함하는 전문 시험 문제를 포함하지만, 이 중 대부분은 지구 과학이나 공학 관련 주제가 아닙니다. 의학과 법률 등 분야별 벤치마크가 존재하지만 석유 지질학에는 유사한 평가 자원이 부족합니다.
기존의 다중 선택형 질문 생성 방법론은 대체로 원본 문장을 문제로 변환하는 데 초점을 맞추고 있습니다. 여기 제시된 개념 중심 방법론은 독창적인 문제 작성, 저작권 준수, 그리고 개념 이해 테스트에 중점을 두는 점이 다르다.
벤치마크 설계 및 구성
작업 정의와 범위
FormationEval은 정확히 하나의 올바른 답변을 가진 네 가지 선택지 다중 선택형 문제 형식을 사용합니다. 이 형태는 표준 평가 프레임워크와 호환되며, 정확도 계산이 간단해집니다.
질문은 7개 영역에 걸쳐 페트로물리학(심화 측정, 형성 평가), 석유 지질학(원천 암반, 마이그레이션, 트랩), 침적학(치환 환경, 다이제네시스), 지구 물리학(지진 해석, 암석 물리학), 유전 공학(액체 유동, 회수 메커니즘), 심층 공학(정공 안정성, 운영) 및 생산 공학(완공, 인공 리프트)을 다룹니다. 질문은 하나 이상의 영역에 속할 수 있습니다.
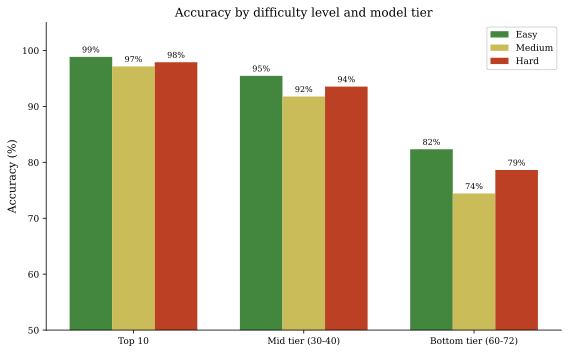
난이도는 교육 배경을 반영합니다. 쉬운 문제(학부 과정)는 정의와 직접적인 회상 테스트입니다. 중간 난이도 문제(대학원 또는 전문가 수준)는 개념을 시나리오에 적용하는 능력을 요구하고, 어려운 문제(전문가 수준)는 여러 개념을 통합하거나 경계 사례를 다룹니다.
출처 선택 및 라이선스 정책
벤치마크는 세 가지 출처에서 도출됩니다: Ellis & Singer의 Well Logging for Earth Scientists (219개 질문), Bjørlykke의 Petroleum Geoscience (262개 질문)와 TU Delft OpenCourseWare (24개 질문).
벤치마크는 개념 기반 유도 방식을 사용합니다. 질문은 원본 자료에서 추출된 개념에 기반하여 작성되며, 문장 복사나 독특한 문제 구조의 가까운 해석을 피합니다. 이는 아이디어(저작권 보호 대상이 아님)와 표현(보호됨) 사이의 법률적 차이를 존중합니다. 표준 기술 용어(porosity, Archie equation, neutron-density crossplot 등)는 저작권 대상이 아니므로 그대로 사용할 수 있습니다.
모든 생성된 항목은 derivation_mode: concept_based 태그와 원본 추적 필드를 포함하여 보호된 텍스트 재생산 없이 검증을 가능하게 합니다.
스키마 및 메타데이터
각 질문에는 고유 식별자, 문제 문구, 네 가지 선택지, 답변 인덱스(0-3), 답변 키(A-D), 난이도 수준, 도메인, 주제와 올바른 답변을 설명하는 레이트리얼 필드가 포함됩니다. 레이트리얼은 개발 중 인간 검증을 돕고 벤치마크 사용자에게 교육적 가치를 제공합니다.
각 항목에는 유사한 질문이 언어 모델 훈련 데이터에 존재할 가능성을 나타내는 contamination_risk 레이블이 포함됩니다. low는 출처 특유의 새로운 질문을 가리키며, medium은 비슷한 질문이 있을 수 있는 일반적인 개념을 의미하고, high는 훈련 데이터에 거의 확실하게 존재할 표준 초급 주제를 나타냅니다. 학습 데이터에 대한 접근 없이는 오염 위험 평가가 어렵지만 이 레이블은 주제의 공통성에 기반한 추정치입니다.
출처 메타데이터는 출처 식별자, 제목, 장 참조, 라이선스 및 검색 일자를 포함합니다. A 부록에는 전체 스키마 참고가 있습니다.
다중 선택형 문제 생성 파이프라인
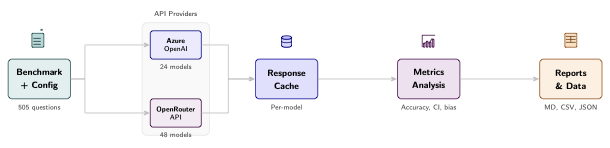
질문은 추론 모델(GPT-5.2 with high reasoning effort)을 사용하여 생성되며, 이 모델은 출처 장(3.2절 참조)을 확장된 사고 체인으로 처리한 다음 출력을 만듭니다. 파이프라인은 네 단계로 구성됩니다:
텍스트 추출은 OCR을 사용하여 원본 PDF를 마크다운 형식으로 변환하며, 구조와 수학적 기호를 유지합니다.
분할은 문서를 장 또는 섹션별로 분할하고, 각 조각은 모델 컨텍스트 크기에 맞추어져 있습니다(보통 한 장, 약 10,000-15,000 토큰).
후보 생성은 GPT-5.2 with high reasoning effort을 사용하여 장 텍스트와 스키마 요구 사항, 개념 기반 유도 규칙, 난이도 목표 및 출력 형식에 대한 자세한 시스템 프롬프트를 받습니다. 모델은 각 장당 5-12개의 문제를 생성합니다.
검증은 스키마 준수(중복 선택지 없음, 답변 인덱스 범위 내) 및 원본 텍스트에서 지원을 확인하고 불명확한 항목을 표시합니다.
1 그림은 이 파이프라인의 전체 과정을 보여줍니다. 원본 데이터를 최종 데이터셋으로 변환하는 과정을 나타냅니다.
시스템 프롬프트는 질문이 출처 장에 대한 액세스 없이 도메인 지식만으로 해결할 수 있는 독립적인 문제여야 함을 강조합니다. “장에 따르면” 또는 “문서가 설명한다"와 같은 문구의 사용은 명시적으로 금지됩니다. 생성 프롬프트 요약은 부록 B에서 확인 가능하며, 전체 시스템 프롬프트는 저장소에서 확인할 수 있습니다.
/>
다중 선택형 문제 생성 파이프라인. 원본 PDF는 OCR을 통해 마크다운으로 변환되고, 장 단위로 분할되어 GPT-5.2에 의해 후보 질문이 생성되며 스키마 준수 및 출처 증거 확인을 위한 검증 과정을 거칩니다.
품질 보장 및 감사
고급 LLM 지시 수행의 신뢰성에도 불구하고 인적 점검은 필수적입니다. 각 출처 장에 대해 2-5개의 질문이 수동으로 검증되어 다음을 확인합니다: (1) 표시된 답변이 올바르고 명확한지; (2) 오해를 살만한 선택지는 틀리지만 분명히 인식 가능하게 작성되었는지; (3) 질문 또는 답변에 복사된 표현이 없는지; (4) 레이트리얼은 표시된 답변을 지원하는지.
전체 데이터셋(505개의 문제, 45개 이상의 장)은 스키마 준수 및 레이트리얼 일관성을 위해 배치로 검토되었습니다. 인적 점검 외에도 LLM 기반 배치 검토는 비일관성 여부를 확인했습니다. 감사 로그는 배치 상태와 수정 필요 사항을 기록합니다.
필수 레이트리얼 필드는 검증을 가속화했습니다. 레이트리얼이 지원하는 답변과 모순되는 경우, 초기 스크린링에서 즉시 확인 가능합니다.
편향 분석 및 완화
초기 분석에서는 두 가지 활용 가능한 패턴이 발견되었습니다.
길이 편향은 중요했습니다. 올바른 답변이 전체 문제의 55% 이상(예상치 25%)에서 유일하게 가장 긴 답변으로 나타났으며, 평균 문자 수는 86.6자로 다른 선택지보다 69.8자가 더 많았습니다.
질문어 편향도 존재했습니다. 절대적 표현인 “항상"은 오답만에 등장(49건, 정확도 0%), 반면 조심스러운 표현인 “가능성 있다"는 올바른 답변에서만 나타났습니다(13건, 정확도 100%).
이 패턴들은 랜덤 추측보다 더 잘 활용될 수 있었습니다.
완화 방법은 선택지의 기술적 맥락을 확장하여 길이 불균형을 줄이는 것(55%에서 43.2%)과 “항상” 표현을 다양한 동의어로 대체하는 것입니다(“inevitably, necessarily, inherently”)를 사용하여 단일 단어 활용을 방지했습니다. 또한 “가능성 있다"는 13개의 오답에 추가되었습니다(예: “영향력이 없다” $\to$ “가능성이 있습니다”).
잔여 문제는 여전히 존재합니다. 길이 편향은 여전히 25% 기준선을 초과하고 있으며, 절대적 단어 동의어 모두 정확도가 0%, 따라서 “절대 단어=틀림” 패턴은 여전히 활용 가능합니다.
베치마크 목적상 이러한 잔여 편향이 상대적인 비교에 크게 영향을 미치지 않을 것입니다. 모든 문제에서 동일한 패턴이 적용되므로, 편향 기반의 이점은 모든 모델에게 동등하게 적용되어 모델 간 비교의 유효성을 유지할 수 있습니다. 주요 활용(길이를 올바른 답변으로 추정, “항상"을 오답 표시, “가능성 있다"는 정답 표시)은 해결되었습니다. 완화 후, 올바른 답변은 평균 87자로 다른 선택지보다 약 13자(2-3개 단어) 더 길었습니다. 유일하게 가장 긴 답변이 올바른 경우는 43.2%에 불과하므로 길이 기반 전략은 실패할 확률이 성공보다 높습니다. 절대적 단어 동의어는 전체 질문 중 약 10% 미만을 차지합니다. 이러한 제한 사항은 투명성을 위해 기록되어 있으며, 부록 C에는 자세한 통계가 있습니다.
PDF 내보내기 검토
검토를 용이하게 하기 위해 데이터셋은 커버 페이지와 모든 메타데이터를 보여주는 질문 카드 및 탐색을 위한 북마크가 포함된 PDF로 내보냅니다. 이 형식은 도메인 전문가들이 품질 검사를 수행할 때 JSON보다 접근성이 높으며, 프로그래밍 도구 없이도 주제별로 질문을 찾아볼 수 있습니다. 생성된 JSON에서 PDF 렌더링을 함께 제공하여 통찰력을 얻고 점검하기 쉽습니다.
데이터셋 요약
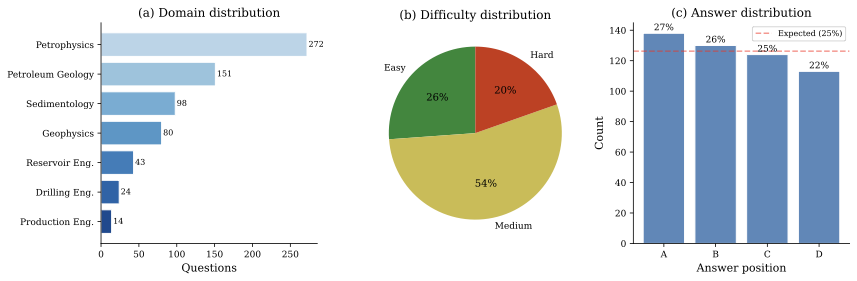
FormationEval 버전 0.1은 영어로 작성된 505개의 문제와 811개의 고유 주제(질문은 여러 주제를 다룰 수 있음)를 포함합니다. 1 표는 주요 지표를 요약하고, 2 표는 도메인 및 난이도별 분포를 보여줍니다. 질문은 세 가지 출처에서 유래합니다: Bjørlykke의 교과서가 가장 큰 비중을 차지하고 있으며(262개 문제, 52%), Ellis & Singer (219개 문제, 43%)와 TU Delft 개방 강의 자료(24개 문제, 5%).
/>
데이터셋 구성. (a) 도메인별 질문 수, 페트로물리학이 출처 커버리지에 따라 다수를 차지하고 있으며; (b) 난이도 분포는 30/50/20 목표와 가까움; (c) 답변 위치 분포는 기대되는 25% 기준선 근처입니다.
평가 설정
모델 및 제공업체
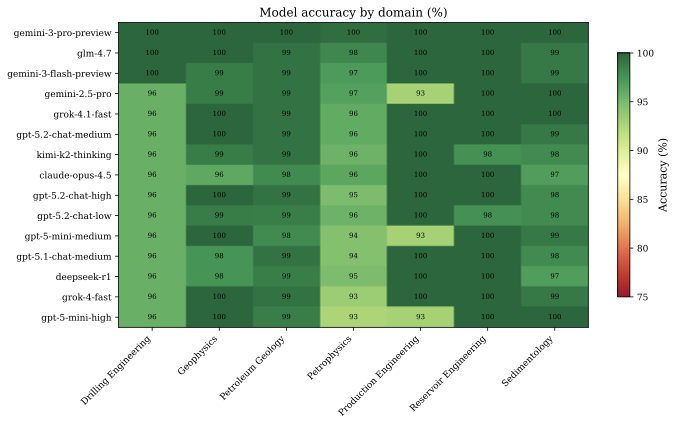
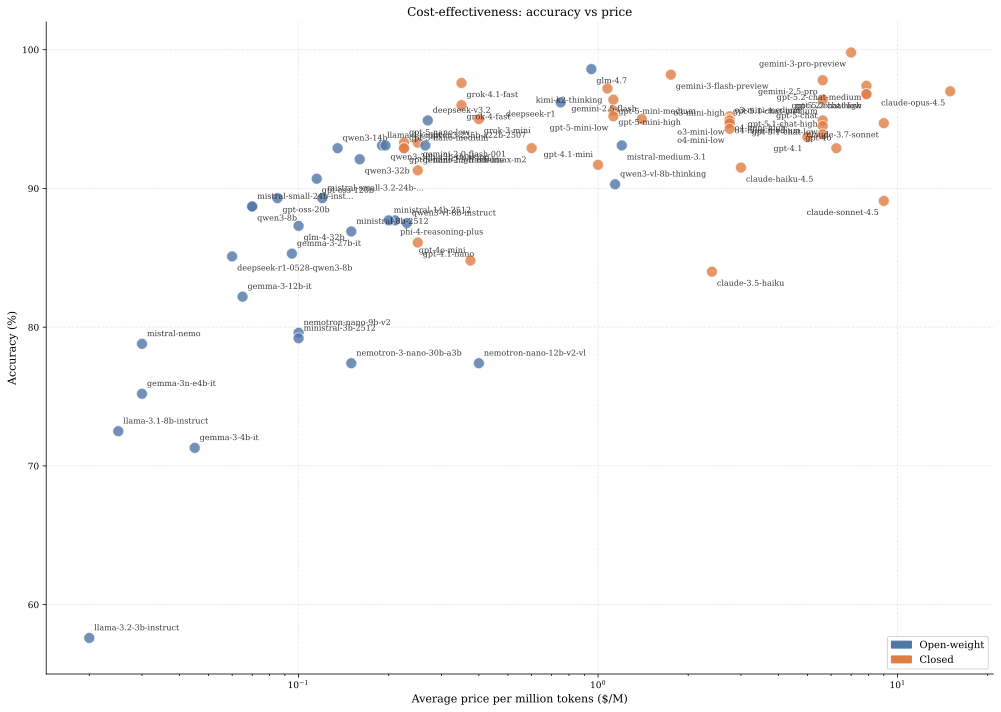
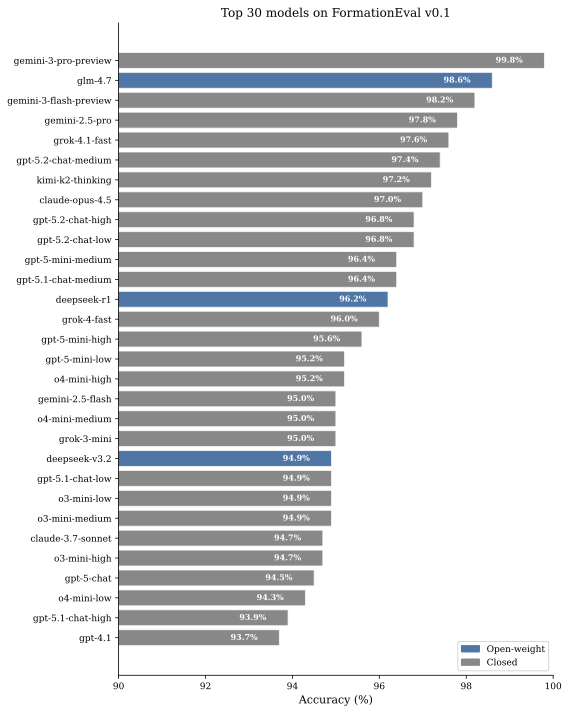
평가에는 Azure OpenAI와 OpenRouter를 통해 액세스 가능한 72개의 모델을 포함합니다. 평가는 2025년 12월에 진행되었습니다. 모델은 OpenAI(GPT-4o, GPT-4.1, GPT-5 시리즈, o3-mini, o4-mini), Anthropic(Claude 3.5 Haiku, Claude 3.7 Sonnet, Claude Opus 4.5, Claude Sonnet 4.5, Claude Haiku 4.5), Google(Gemini 2.0, 2.5, 3 시리즈, Gemma 3), Meta(Llama 3.1, 3.2, 4), DeepSeek(R1, V3.2), Mistral(Small, Medium, Nemo, Ministral), Alibaba(Qwen3 시리즈), Zhipu(GLM-4, GLM-4.7), xAI(Grok 3, 4), Moonshot(Kimi K2), MiniMax(M2), Microsoft(Phi-4) 및 Nvidia(Nemotron)에서 나왔습니다.
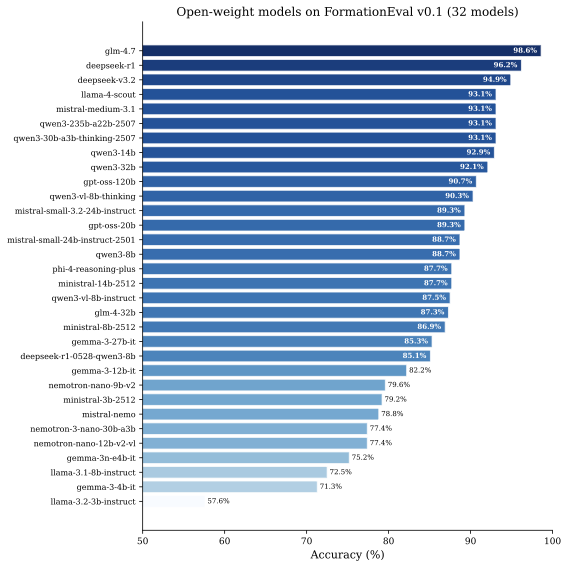
모델은 3B 매개변수 변형체부터 최신 추론 모델까지 다양합니다. 공개 가중치 모델(72 중 32)에는 GLM-4.7, DeepSeek-R1 등이 포함됩니다.