- Title: Code for Machines, Not Just Humans Quantifying AI-Friendliness with Code Health Metrics
AI가 코드를 이해하고 개선하는 데 있어, 인간이 읽기 쉬운 코드는 어떻게 도움을 줄 수 있을까? 본 논문은 CodeHealth 지표를 사용하여 AI 친화적인 코드 디자인이 더 나은 결과를 내는지 분석한다. 또한, Perplexity와 Source Lines of Code(SLOC)와 비교해보며, 인간이 이해하기 쉬운 코드가 실제로 AI에게도 더 친근한지 확인한다.
1. **코드 품질과 AI 친화성의 관계:** 본 연구는 'CodeHealth' 지표를 통해 코딩 품질이 AI 친화적인 코드 디자인에 어떻게 영향을 미치는지 분석하였다. CodeHealth 지표는 코딩의 유지보수성을 평가하는 데 사용되며, 본 연구에서는 이를 통해 코딩 품질이 AI 친화성과 어떤 관계를 가졌는지를 알아냈다.
2. **AI 친화적인 코드 디자인의 중요성:** '코드가 사람을 위해 작성되어야 한다'라는 기존의 견해에 더하여, 본 연구에서는 AI 친화적인 코드 디자인이 코딩 품질을 높이는 데에도 중요한 역할을 하며, 이는 결국 AI 도구를 효과적으로 활용하는 데도 도움이 된다고 제안하였다.
3. **PPL과 SLOC의 비교:** 본 연구에서는 CodeHealth 지표가 Perplexity와 Source Lines of Code(SLOC)보다 더 정확하게 코딩 품질을 예측할 수 있음을 보여주었다.
<ccs2012> <concept>
<concept_id>10011007.10011006.10011073</concept_id>
<concept_desc>소프트웨어 및 엔지니어링 소프트웨어 유지보수 도구</concept_desc>
<concept_significance>500</concept_significance> </concept>
</ccs2012>
서론
몇십 년 동안 “프로그램은 사람이 읽을 수 있도록 작성되어야 하며, 그 다음에 기계가 실행할 수 있게 되는 것"이라는 견해가 지배적이었다. 사람에게 친숙한 코드는 안전하고 신뢰성 있고 효율적인 소프트웨어 개발에 필수적이다. 그러나 AI 지원 코딩 도구의 등장으로 인해, 이제 코드의 대상은 사람이 아닌 기계도 포함하게 되었다.
Thoughtworks[^1]에서 수집된 초기 현장 관찰 결과는 고품질 코드에서는 AI 지원 코딩 도구가 더 잘 작동한다는 것을 나타낸다. 특히 모듈화가 잘 이루어진 코드는 환영을 줄이고 정확한 제안을 제공하는 경향이 있다. 이들을 *“AI 친화적인 코드 디자인”*이라고 부르며, 2025년 4월 기술 레이더에서 기존의 최선의 방법론들이 AI 친화성과 어떻게 조화를 이루는지 논의한다. 만약 이 관찰이 정확하다면, 사람을 위해 최적화된 코드는 대형 언어 모델(LLMs)에게도 더 쉽게 처리되고 개선될 수 있다는 것을 의미한다.
AI 친화성의 함의는 깊이 있다: 2025년 현재 약 80%의 개발자가 이미 AI 도구를 일상적으로 사용하고 있으며, 채택률은 급속히 증가할 것으로 예측된다. Gartner는 2024년 초에 14%에서 2028년까지 90%로 증가할 것이라고 예측한다. 동시에, 기술 부채를 체계적으로 추적하는 조직은 10% 미만이며, 개발자들은 코드 품질이 낮아 인력의 최대 42%를 낭비하고 있다. 이러한 수치는 오늘날의 대부분의 생산 코드가 안정적인 AI 개입에 적합하지 않다는 것을 시사하며, 이로 인해 버그와 비용이 많이 드는 재작업 위험이 증가한다.
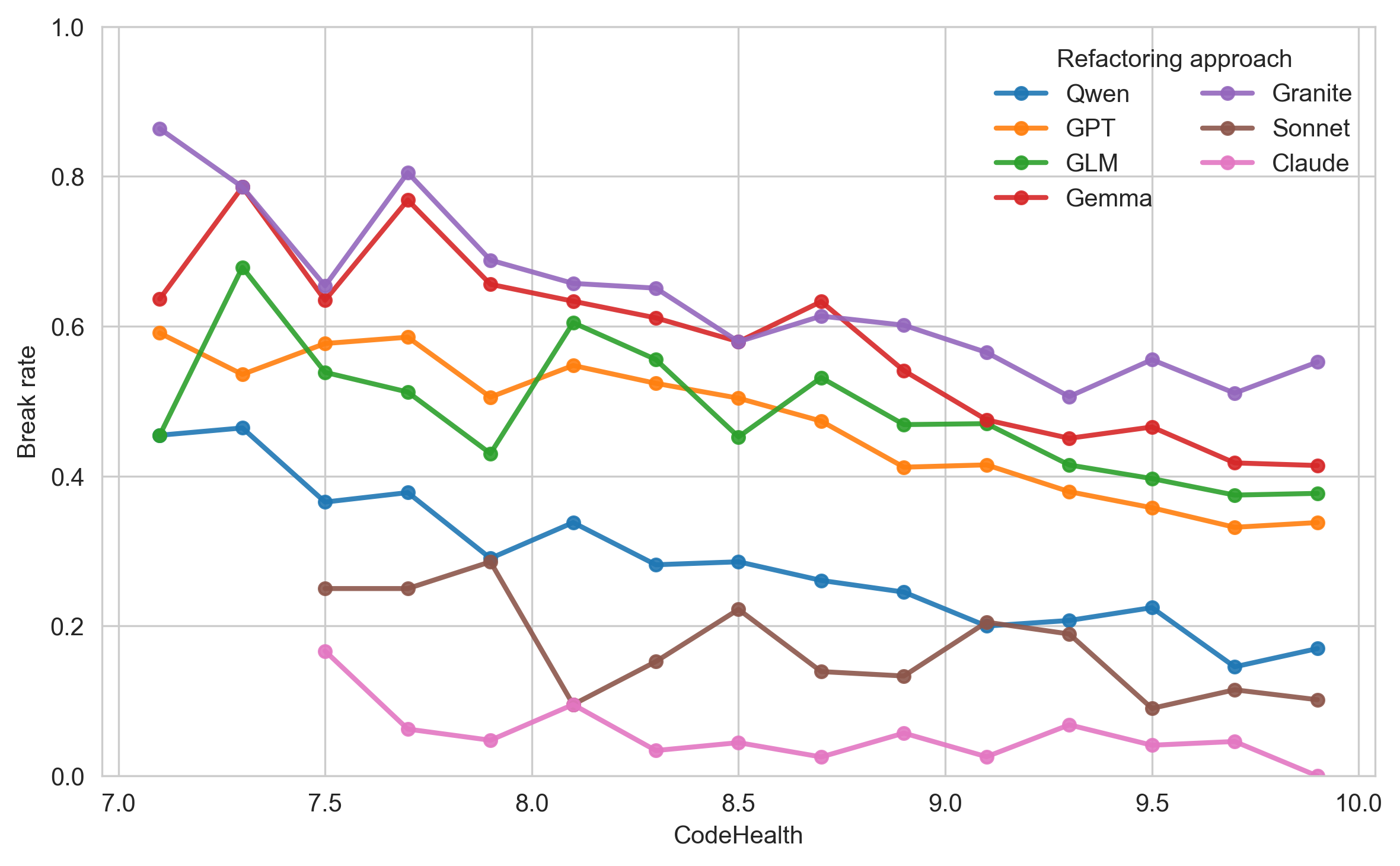
본 논문에서는 코드 품질과 AI 친화성 사이의 관계를 조사한다. 우리는 CodeHealth (CH) 지표를 사용하여 코드 품질을 측정하며, 이 지표는 이전 연구에서 결함 및 개발 노력 예측에 유효함이 검증되었다. 또한 최근 산업 연구에서도 사용되었다. AI 생성 리팩토링 성공률, 즉 기존 코드의 설계를 변경하지 않고 개선하는 것의 비율을 AI 친화성의 대안으로 사용한다. 리팩토링은 통과한 단위 테스트를 기능적 정확성을 판단하는 오라클로 사용할 수 있다. 따라서 AI 리팩토링이 정확하다는 것은 테스트가 통과하고, 유익하다는 것은 CH가 증가함을 의미한다.
우리의 결과는 사람이 읽기 쉬운 코드가 AI 도구와 더 호환되며, LLM들이 건강한 CodeHealth 범위($`CH\ge9`$)에서 리팩토링 작업에 실패하는 비율이 현저히 낮음을 확인한다. 이로 인해 15-30%의 위험 감소가 이루어진다. 또한 CH는 perplexity (PPL, LLM 내부적 확신 지표)와 Source Lines of Code (SLOC)보다 리팩토링 정확성을 예측하는 데 더 우수함을 보여준다.
이러한 결과는 소프트웨어 조직들이 AI 지원 코딩 도구를 채택하는데 도움을 줄 수 있다. CH를 사용하여 AI 처리에 적합한 코드 부분과 너무 많이 깨질 위험이 있는 코드를 식별하는 것을 제안한다. 더 넓게 보면, 이 연구는 인류와 기계가 일치하는 공유 코딩 품질 지표라는 AI 채택의 중요한 요소를 추가한다. 이전 연구에서는 코드 품질을 비즈니스 필수로 포지셔닝하였지만, 우리는 코드 품질이 안전하고 효과적인 AI 사용의 전제 조건이라는 것을 제안하며, 다음 10년 동안 소프트웨어 조직에 있어 존재론적 문제일 수 있다.
본 논문은 다음과 같은 구성으로 나누어져 있다. 섹션 2에서는 배경과 관련 연구를 설명한다. 섹션 3에서는 우리의 연구 질문, 데이터셋 및 방법을 소개한다.
섹션 4에서는 결과를 보고하고,
마지막으로 섹션 5에서는 함의를 논의하며, 섹션 6에서는 향후 연구 방향을 제시하여 결론을 맺는다.
배경 및 관련 연구
이 장은 CH와 PPL을 소개하고, 코드 이해와 AI 리팩토링에 관한 관련 작업을 제시한다.
유지보수성과 CodeHealth™
CodeHealth™ (CH)는 CodeScene 소프트웨어 엔지니어링 인텔리전스 플랫폼에서 사용되는 품질 지표다. 이 지표의 목표는 개발자가 코드를 이해하는 데 얼마나 인지적으로 어려운지를 포착하는 것이다.
CodeScene은 코드 스멜을 식별한다, 예를 들어 God 클래스, 깊게 중첩된 논리 및 복제된 코드 등이다. 본 연구에서 사용한 Python의 경우, CodeScene은 25가지의 코드 스멜을 감지할 수 있다.
CodeScene은 발견된 스멜의 수와 심각도를 파일 단위로 1부터 10까지의 점수로 결합한다. 낮은 점수는 인간에게 더 높은 인지 부담, 즉 높은 유지보수 비용을 의미한다.
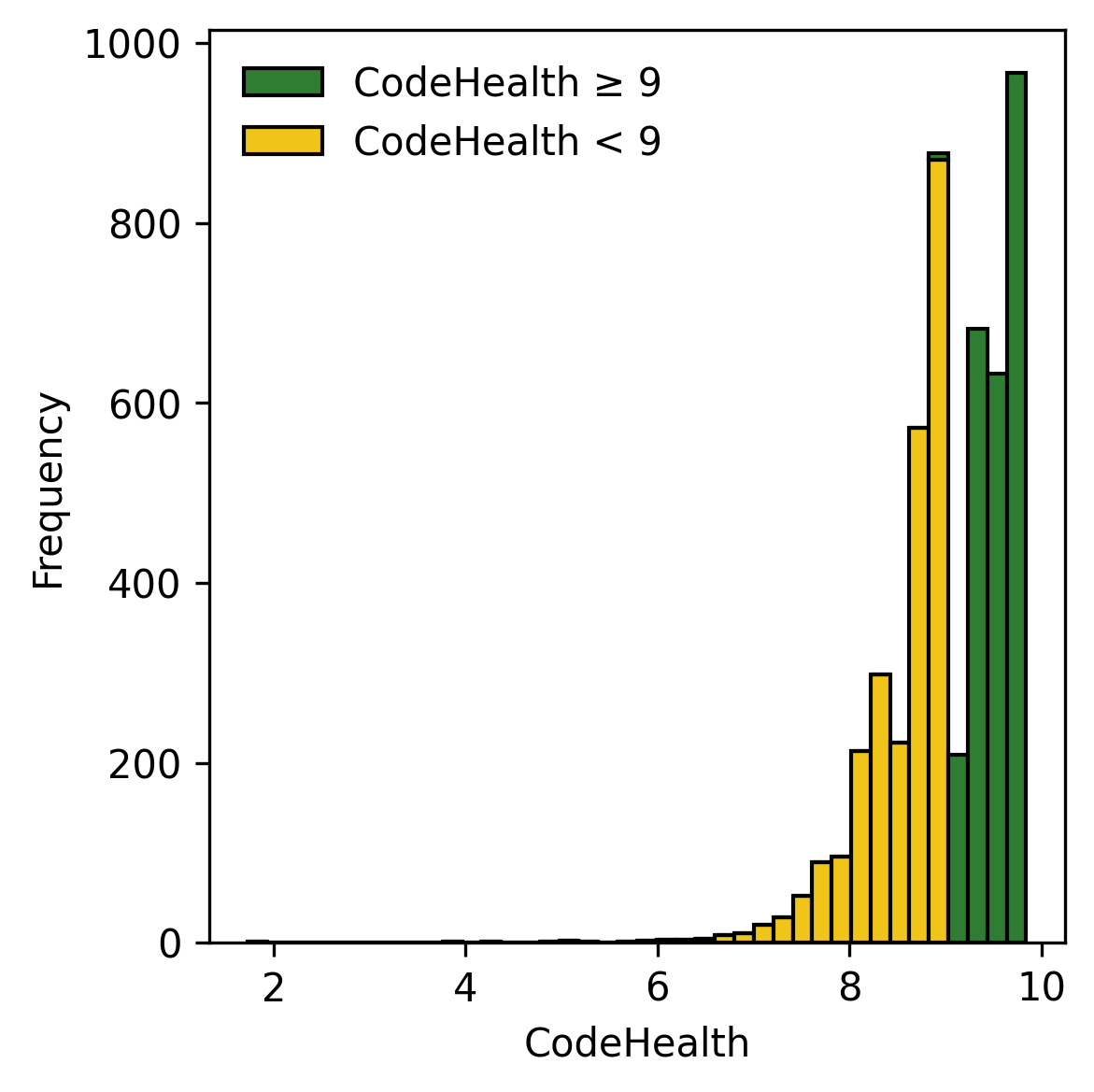
CodeScene은 파일을 세 가지 CH 구간 중 하나에 속하게 분류한다: Healthy (CH $`\ge 9`$), Warning ($`4 \le \text{CH} < 9`$) 및 Alert ( $`< 4`$). 본 연구에서는 Warning과 Alert 파일을 Unhealthy라고 부른다.
우리는 이전에 CH 지표를 여러 연구에서 검증했다. Manual Maintainability Dataset에 대한 연구에서, CH는 인간 유지보수 판단보다 다른 메트릭 및 평균 인간 전문가와 더 잘 일치함을 보고하였다.
또한 우리는 CH와 파일 단위 결함 밀도 및 개발 시간 사이의 연관성을 통해 비즈니스 관점에서 이 지표를 검증했다. 이러한 이전 연구를 기반으로, 이제 CH와 AI 친화성 간의 관계를 조사한다.
LLM 신뢰도와 Perplexity
LLM 출력을 평가하기 위한 여러 메트릭이 제안되었다. 엔트로피, 상호 정보 및 PPL과 같은 내부적인 지표는 출력 정확도와 환영 위험의 프록시로 사용될 수 있다.
소프트웨어 도메인에서 Sharma 등은 생성된 코드의 기능적 정확성이 낮을수록 높은 엔트로피와 상호 정보가 관련됨을 보였다. Ray 등이 이전에 수행한 연구에서도 결함이 있는 코드는 올바른 코드보다 높은 엔트로피를 가졌다고 보고하였다.
이는 Hindle 등이 수행한 기초적인 작업, 즉 코드의 자연스러움에 대한 연구를 바탕으로 한다.
PPL은 원래 음성 인식 과제에 제안되었다. 시퀀스 내 예측 모델의 평균 엔트로피의 지수로 정의된다.
엔트로피가 “평균적인 놀람"을 나타낸다면, PPL은 이 대신 “얼마나 많은 선택지"를 의미하는 척도이다. 이는 LLM이 직전 토큰에 기반하여 다음 토큰을 예측하는 데 얼마나 확신하는지를 측정한다 - 점수가 높을수록 신뢰도가 낮다.
수학적으로, $`t_{1:N}`$은 토큰 시퀀스라고 가정할 때, 평균 교차 엔트로피 ($`H`$)는 다음과 같이 표현된다:
H = -\frac{1}{N}\sum_{i=1}^{N}\log p(t_i \mid t_{<i}).
PPL은 $`\exp(H)`$. 본 연구에서는 다섯 개의 Hugging Face 모델에서 PPL을 직접 얻는다.
코드 이해와 Perplexity
Gopstein 등은 Confusion Atoms이라는 용어를 사용하여 소스 코드 내에서 인간이 혼란스러워하는 작은 고립된 패턴을 지칭하였다. Atom은 코드에서 혼란을 일으키는 가장 작은 단위이다.
통제 실험을 통해 그들은 이해 오류율을 크게 증가시키는 애트อม 세트를 식별했다. 예를 들어, “Assignment as Value,” 즉 V1 = V2 = 3;와 “Logic as Control Flow,” 즉 V1 && F2();.
이 개념을 바탕으로 Abdelsalam 등은 현재 하이브리드 개발 환경에서 인간 프로그래머와 LLM 간 이해 차이의 위험성을 논의한다. 그들은 인간과 LLM이 코드의 다른 특징에 혼란스러워하면, 불일치 위험이 있다고 주장한다.
LLM PPL 및 EEG 반응을 비교한 결과, LLM과 인간은 코드에서 비슷한 문제를 겪는다는 것을 발견했다.
Casulnuovo 등이 수행한 이전 통제 실험도 인류의 이해와 LLM에게 코드 스니펫이 얼마나 놀람스러운지 사이에 연결성을 제시한다.
Kotti 등은 다양한 프로그래밍 언어의 PPL을 탐색하였다. GitHub 프로젝트에서 1,008개 파일을 분석한 결과, 강력하게 타입화된 언어와 동적 타입화된 언어 사이에 체계적인 차이가 있음을 발견했다.
예를 들어, LLM별로 Perl은 높은 PPL 값을, Java는 낮은 PPL 값을 보였다. 그들은 이러한 PPL 결과가 특정 프로젝트에서 LLM 기반의 코드 완성 적합성을 평가하는 데 사용될 수 있다고 추측한다.
본 연구에서는 건강한 Python 코드와 불건전한 코드 간의 PPL 개념을 탐색한다.
AI 리팩토링
LLMs에 의해 많은 소프트웨어 엔지니어링 응용 프로그램이 혁신되었다. 여러 연구들은 다양한 조합의 LLM과 프롬프트를 사용하여 설계 개선 및 코드 스멜 제거에 대한 잠재력을 탐구한다.
Pomian 등은 EM-Assist라는 도구를 도입하여 Extract Method 리팩토링을 자동으로 제안하고 수행하도록 했다. 같은 팀은 추출 방법 외에도 Move Method와 같은 고급 리팩토링 작업에 대해 계속 연구 중이다.
Tornhill 등은 코드 스멜 5가지를 자동으로 제거하는 도구 ACE를 개발했다.
2025년, 에이전트형 AI는 산업과 연구에서 주요 트렌드였다. 코딩 에이전트는 LLM에 의해 구동되지만, 일반적으로 제한된 컨텍스트 윈도우를 넘어서 코드베이스를 이해하고 기억을 유지한다는 점을 주장한다.
이는 에이전트가 더 큰 작업을 수행하고 독립적으로 운영할 수 있게 한다. 현재 가장 인기 있는 에이전트는 Watanabe 등이 세심하게 설명한 Anthropic의 Claude Code이다.
He 등과 Wang 등은 관련 학술 문헌에 대한 최신 개요를 참고하라.
리팩토링은 코딩 에이전트가 수행할 수 있는 여러 작업 중 하나다. 예를 들어, Xu 등은 MANTRA라는 다중 에이전트 프레임워크를 제시하였다.
MANTRA는 리팩토링 작업을 위해 세 개의 에이전트를 개발자, 리뷰어 및 수정 역할로 구성하고 LLM 사용보다 우수한 성능을 보여준다. 그러나 Claude도 다중 에이전트 솔루션이 아닌데에도 불구하고 강력한 리팩토링 에이전트이다.
본 연구에서는 현재 공개되지 않은 MANTRA를 제외하고, 현대적인 에이전트형 AI 리팩토링의 대표 예로 Claude (v2.0.13)을 연구한다.
방법
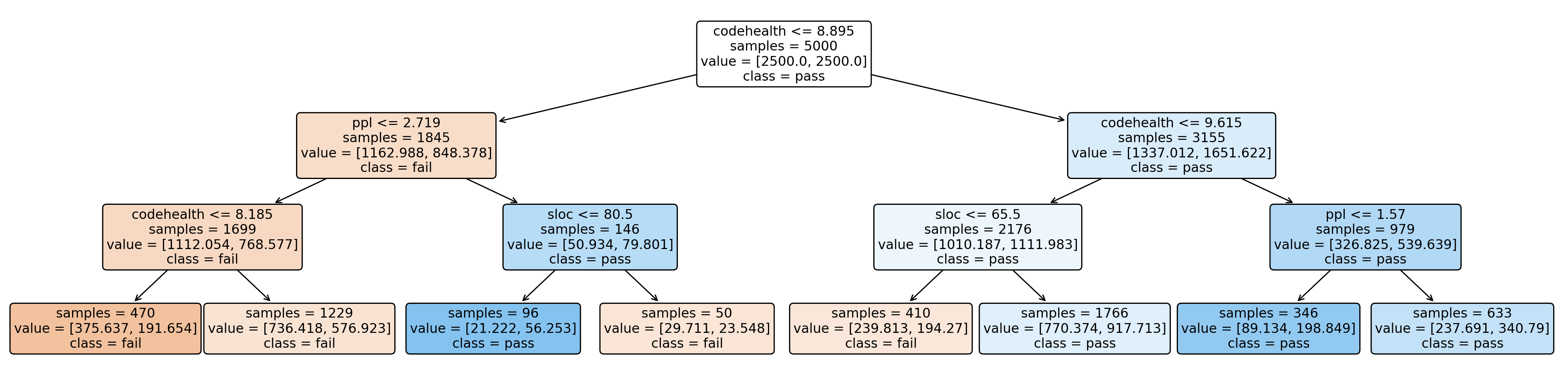
우리의 목표는 코드 특성이 AI 리팩토링 능력에 어떻게 영향을 미치는지를 탐구하는 것이다. 특히 CodeHealth를 중점적으로 살펴본다.
우리는 세 가지 연구 질문(RQs)을 제시하여 코드 특성과 AI 친화성 간의 관계를 조사한다.
-
건강한 코드와 불건전한 코드 사이에서 Perplexity는 어떻게 다를까?
-
건강한 코드와 불건전한 코드 사이에서 AI 리팩토링 실패율은 어떻게 다를까?
-
CodeHealth가 AI 리팩토링 실패율을 예측하는 데 얼마나 효과적인가?
데이터셋 생성
우리는 Google DeepMind에 의해 호스팅되는 GitHub[^2]의 CodeContests 데이터셋을 샘플링한다. Li 등이 소개한 이 데이터셋은 AlphaCode를 위한 훈련 데이터로 사용되며, 5개의 출처에서 약 1천 2백만 개의 정답 및 오답 솔루션을 포함한다.
우리는 문제에 대해 세심하게 작성된 테스트 케이스가 기능적 정확성을 검증하므로 리팩토링 후 실용적인 오라클을 제공하는 도메인에서 코드를 연구한다.
우리는 5,000개의 솔루션으로 구성된 데이터셋을 다음과 같은 네 가지 설계 선택 사항을 바탕으로 생성한다.
첫째, Python에 초점을 맞추어 새로운 관점과 편의성을 높인다. CodeContests에는 Java 및 C++ 솔루션이 포함되어 있지만, Java는 리팩토링 연구에서 광범위하게 연구되었고, C++은 더 복잡한 컴파일 및 테스트 프로세스를 가지고 있다.
둘째, 우리는 솔루션에 최소 하나의 CodeScene 코드 스멜이 존재하도록 한다. 코드 스멜 제거는 실제 리팩토링 목표이다.
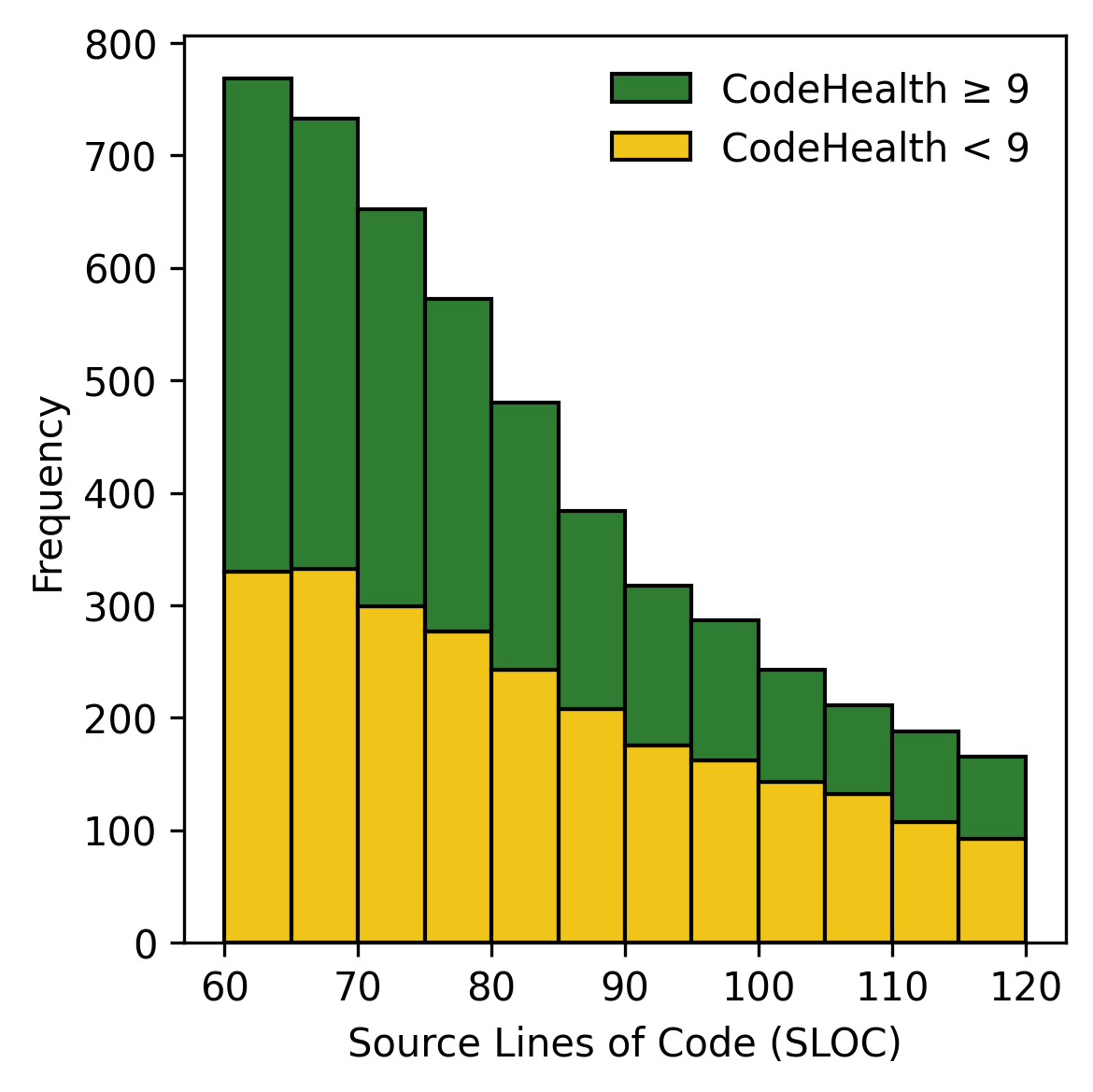
셋째, 우리는 60~120 SLoC 사이에 있는 솔루션만 연구한다. 유지보수성과 크기 간에는 강한 상관관계가 있어, 샘플링 단계에서 이를 적어도 부분적으로 통제한다.
넷째, 우리는 데이터셋 내 다양성을 능동적으로 추구하며, 많은 솔루션이 매우 유사하다는 점을 고려한다. 이에 따라 CodeBleu를 사용하여 유사성 계산을 수행하되 다음과 같은 가중치를 사용: n-gram=0.1, weighted-n-gram=0.4, ast-match=0.5, 그리고 dataflow-match=0.
실제 샘플링 과정은 다음과 같은 단계로 이루어졌다 (남아 있는 솔루션 수는 괄호 안에 표시됨):
-
전체 CodeContests 데이터셋을 다운로드한다(13,210,440).
-
Python 3 솔루션만 필터링한다(1,502,532).
-
동일한 (Type 1 클론) 솔루션을 모두 제거한다(1,390,531).
-
CodeScene 코드 스멜이 없는 모든 솔루션을 제거한다(88,156).
-
주석 및 바운드되지 않은 문자열 리터럴을 제거한다.
-
60~120 SLOC 사이에 있는 솔루션만 필터링한다(18,074).
-
Healthy와 Unhealthy 코드로 두 개의 계층으로 분할한다[^3].
-
각 계층에서 아래 단계를 수행하여 총 2,500개의 솔루션이 포함될 때까지 반복한다:
- 임의로 선택된 후보 솔루션을 샘플링한다.
- 해당 테스트 케이스를 실행하고 실패하는 경우 스킵한다.
- CodeBleu 유사성을 계산하여 현재 샘플들과의 유사성이 0.9 이상인 경우 스킵한다.
- 솔루션을 계층에 추가한다.
-
두 개의 계층을 병합하여 최종 데이터셋(5,000)을 구성한다.
대형 언어 모델 선택
우리는 평가를 위해 여섯 가지 LLM을 선택했다. 다섯 개는 약 20-30B 파라미터의 오픈 가중치 모델로, 로컬 데이터 센터에서 실행할 수 있다.
인기와 Hugging Face에서의 다운로드 통계를 바탕으로 네 가지 모델을 선택하고 IBM에서 최근에 출시한 LLM을 추가하여 중형 LLM이라고 부른다.
또한 Anthropic API를 통해 State-of-the-Art(SotA) LLM을 포함한다.
- gemma-3-27b-it (Google) – 2025년 3월
- GLM-4-32B-0414 (Zhipu AI) – 2025년 4월
- Granite-4.0-H-Small (IBM) – 2025년 10월
- gpt-oss-20b (OpenAI) – 2025년 8월
- Qwen3-Coder-30B-A3B-Instruct (Alibaba Cloud) – 2025년 8월
- claude-sonnet-4-5-20250929 (Anthropic) – 2025년 9월
모든 LLM에 대해 샘플링 온도를 0.7로 설정하여 동일한 환경에서 리팩토링 다양성을 활성화하고 최대 8,192개의 새로운 토큰까지 생성을 제한한다.
다른 모든 설정은 기본값을 사용한다.
RQ$`_1`$ Perplexity
우리는 연구 대상인 다섯 개의 LLM에 대해 전체 5,000개 샘플에 대한 PPL 점수를 추출한다. 그런 다음 샘플을 Healthy와 Unhealthy로 분할하고 각 LLM에 대해 다음과 같은 귀무 가설을 제시한다:
- 건강한 코드와 불건전한 코드의 perplexity 분포는 동일하다.
기술 통계는 매우 높은 PPL을 갖는 일부 아웃라이어를 확인하였다. 수작업 분석 결과, 경쟁 프로그래밍에서 일부 참가자가 솔루션 후에 사용할 목적으로 천문학적인 큰 정수나 매우 긴 문자열을 하드코딩하는 패턴이 LLM의 다음 토큰 불확실성을 크게 증가시킨다.
이는 일측 변동 z-점 필터링을 적용하여 처리되었으며, 각 LLM에서 출력에서 z>2.5인 샘플(약 5%)을 제거하였다.
PPL 점수는 보통 오른쪽으로 치우쳐 있으며, 정규성은 S