- Title: TopoLoRA-SAM Topology-Aware Parameter-Efficient Adaptation of Foundation Segmenters for Thin-Structure and Cross-Domain Binary Semantic Segmentation
- ArXiv ID: 2601.02273
- 발행일: 2026-01-05
- 저자: Salim Khazem
📝 초록
본 연구에서는 다양한 도메인에서 이진 세분화를 위한 기초 모델의 적응을 위해 TopoLoRA-SAM이라는 원칙적인 프레임워크를 제안한다. SAM ViT-B 이미지 인코더는 고정되며, 각 트랜스포머 블록의 피드포워드 네트워크(FNN) 층에 학습 가능한 LoRA 모듈을 삽입하고, 고해상도 임베딩 텐서에서 마스크 디코딩 전에 가벼운 깊이별 분리 컨볼루션 어댑터를 사용한다. 이 설계는 미세 조정을 가능하게 하면서 사전 학습된 표현을 유지한다.
💡 논문 해설
1. **TopoLoRA-SAM의 원칙적 프레임워크**: 본 연구에서는 기초 모델인 SAM을 다양한 도메인에서 이진 세분화에 적응시키기 위한 TopoLoRA-SAM이라는 새로운 프레임워크를 제안한다. 이를 통해, 복잡한 신경망 구조를 미세 조정하면서도 사전 학습된 일반적인 표현을 유지할 수 있다.
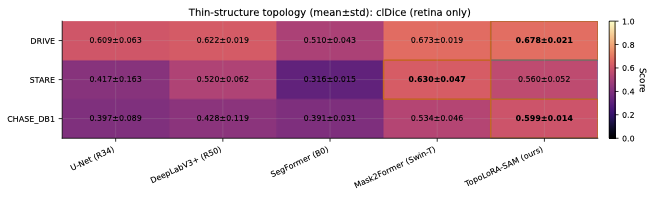
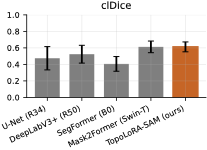
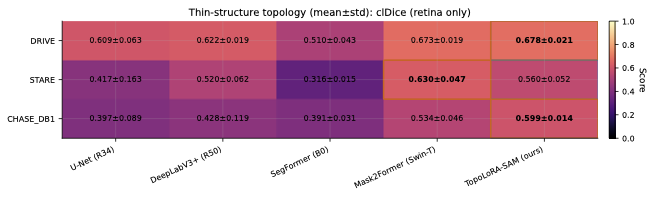
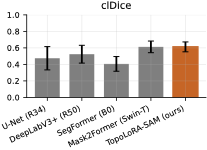
파라미터 효율적 조정과 위상 구조 보존: TopoLoRA-SAM은 파라미터 효율적 조정(PEFT) 방법론인 LoRA와 가벼운 공간 어댑터를 통합하여, 얇고 긴 구조의 연결성을 유지하는 데 중점을 두고 있다. 이를 통해 병변이나 해안선과 같은 얇은 구조물의 세분화에서 중요한 연결성을 보존할 수 있다.
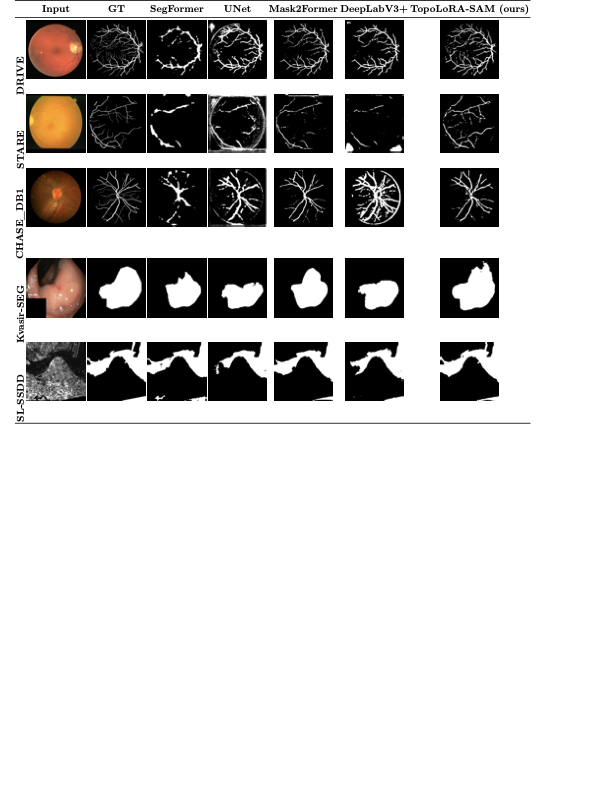
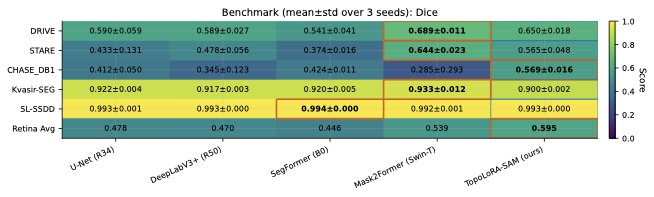
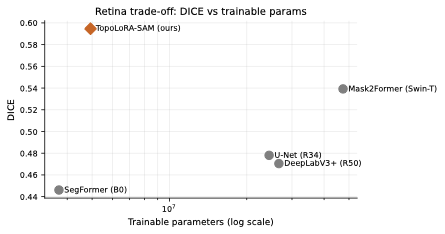
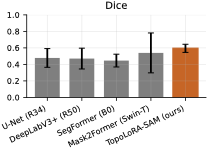
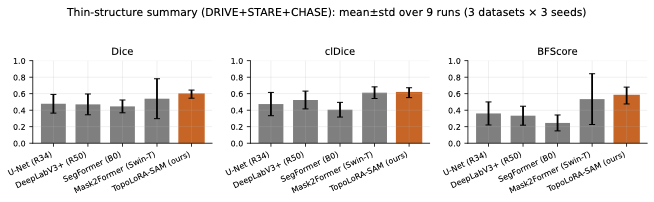
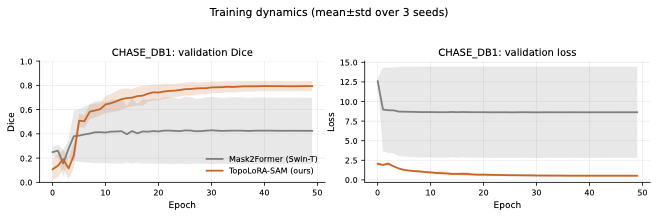
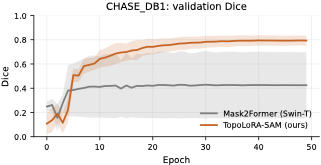
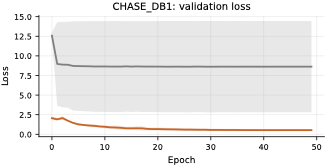
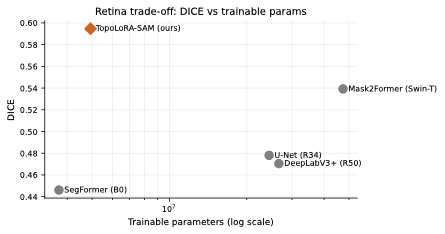
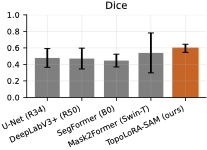
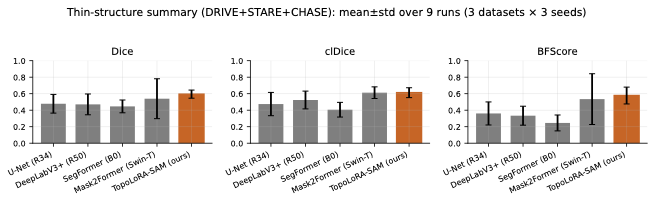
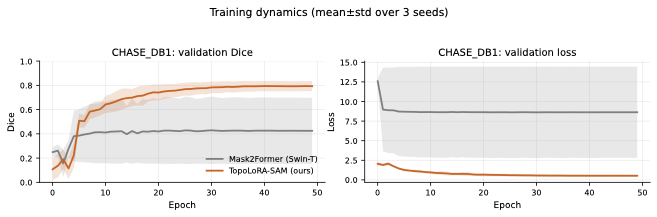
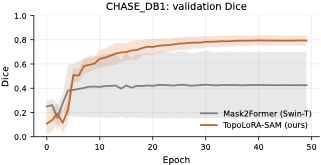
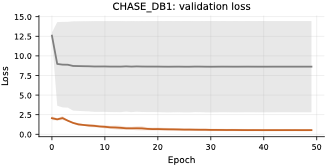
다양한 데이터셋에 대한 성능 평가: 본 연구는 다섯 가지 이진 세분화 데이터셋(시신경 혈관, 장폴립, SAR 해/육지)을 사용하여 TopoLoRA-SAM의 성능을 평가한다. 특히 CHASE_DB1에서 뛰어난 성능을 보이며, 전체 모델 파라미터 중 5.2%만 학습하는 것으로도 좋은 결과를 얻는다.
📄 논문 발췌 (ArXiv Source)
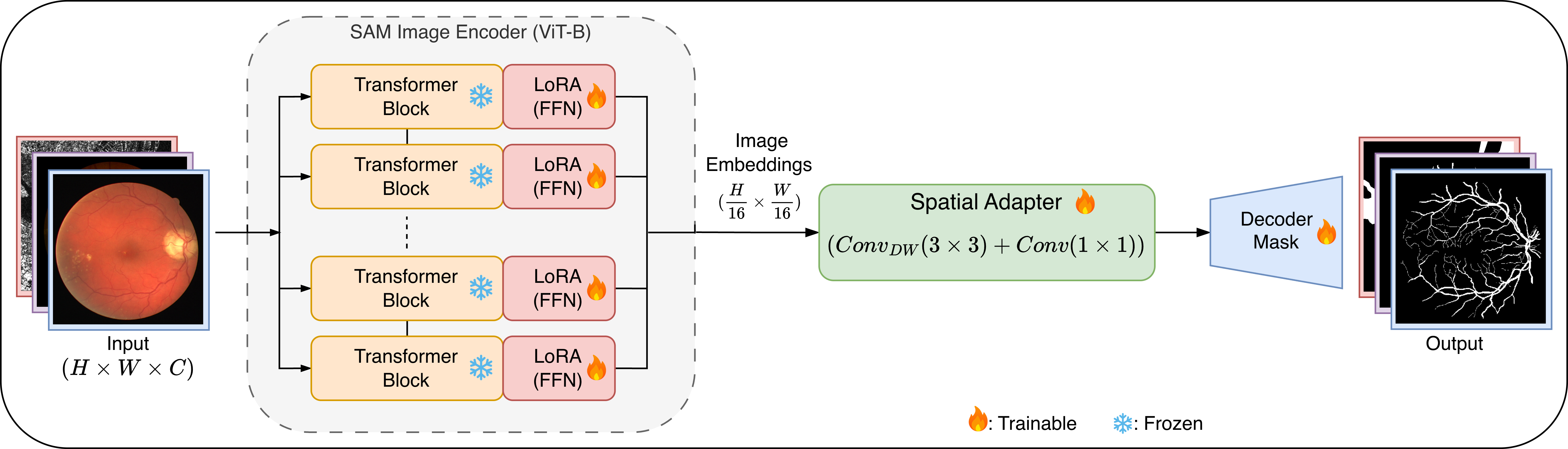
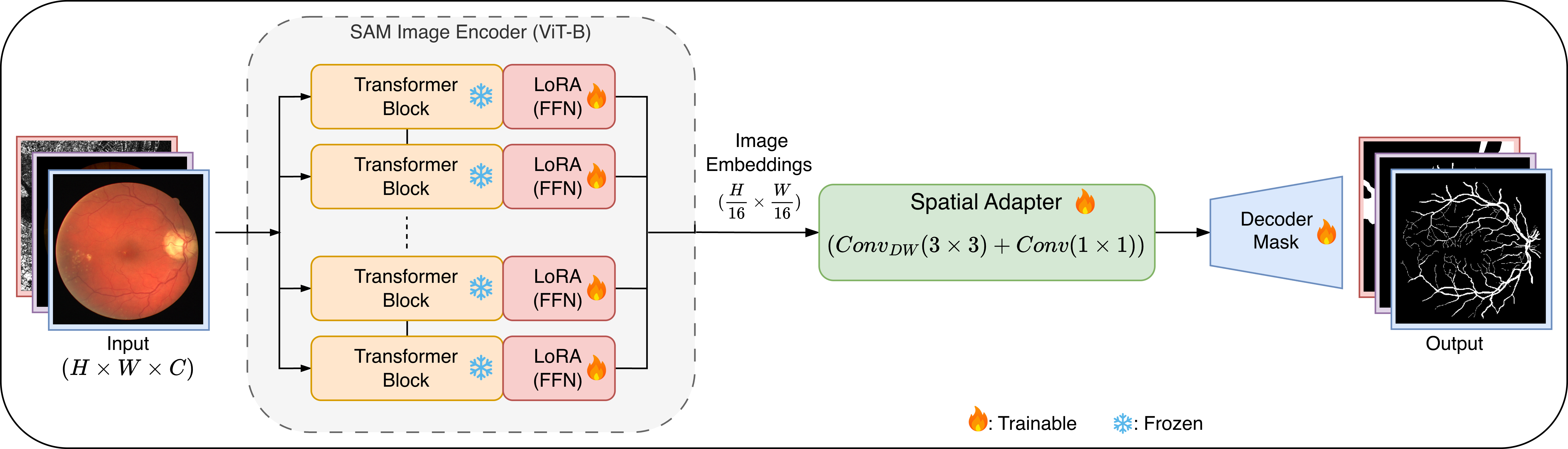
TopoLoRA-SAM 아키텍처 개요.
우리는 SAM ViT-B 이미지 인코더를 고정하고 각 트랜스포머 블록의 피드포워드 네트워크(FNN) 층에 LoRA 모듈(빨강)을 삽입한다. 가벼운 깊이별 분리 컨볼루션 어댑터(초록색)는 고해상도 임베딩 텐서를 마스크 디코딩 전에 정제하고, 학습은 BCE, Dice, clDice를 결합한 위상 인식 손실을 사용한다.
소개
세분화는 의료 이미징과 원격 감시 등 다양한 중요한 응용 분야의 기반이 된다. 최근 Segment Anything Model (SAM)과 같은 기본 모델은 웹 스케일 사전 학습을 통해 뛰어난 제로샷 일반화를 달성했지만, 특수 도메인에 대한 적응에는 여전히 많은 도전이 있다. 특히 얇고 긴 구조(시신경 혈관, 도로 네트워크)에서는 작은 픽셀 단위의 오차가 전체 브랜치를 연결할 수 없게 만들 수 있으며, 표준 영역 기반 손실은 이러한 위상 위반에 대해 크게 무감각하다. 또한 SAR이나 체내 관찰과 같은 모달리티는 자연 이미지와 달리 텍스처, 노이즈 특성 및 의미가 다르므로 웹 사전 학습된 표현의 이전성이 제한된다.
10억 개 이상의 파라미터를 가진 기본 모델을 완전히 미세 조정하는 것은 계산적으로 금지되며 일반화 가능한 표현의 잊혀짐 위험이 있다. LoRA, 어댑터 및 시각적 프롬프트 휴닝과 같은 파라미터 효율적인 미세 조정(PEFT) 방법은 사전 학습된 지식을 유지하면서 소수의 파라미터만 업데이트하는 대안을 제공한다. 최근에는 SAM 적응에 대한 PEFT 연구가 시작되었지만, 도메인 특이적 이진 세분화를 위한 위상 인식 적응에 대한 체계적인 연구는 여전히 제한적이다.
본 논문에서는 TopoLoRA-SAM이라는 프레임워크를 소개한다. 이 프레임워크는 다양한 도메인에서 이진 세분화를 위해 파라미터 효율적인 적응과 위상 보존 감독을 통합한다. 우리의 접근 방식은 SAM ViT-B 이미지 인코더를 고정하고 피드포워드 층에 학습 가능한 LoRA 모듈을 삽입하며, 이는 고해상도 특징 맵에서 작동하는 가벼운 깊이별 분리 컨볼루션 어댑터로 보완된다. 이러한 설계는 미세 조정을 가능하게 하면서 사전 학습된 일반화 가능한 표현을 유지한다. 얇은 구조의 위상적 정합성을 해결하기 위해 clDice 손실을 도입하여 중앙선 겹침 최적화를 명시적으로 수행하고 연결된 중심선을 장려한다. 우리의 기여는: (i) LoRA와 가벼운 공간 어댑터를 결합한 위상 인식 파라미터 효율적인 SAM 적응; (ii) 5개의 이진 세분화 데이터셋에 대한 벤치마크(시신경 혈관, 다발성 낭종, SAR 해/육지)와 영역, 경계, 위상, 캘리브레이션 지표; 그리고 (iii) CHASE_DB1에서 강력한 성능과 최고의 식판 평균 Dice를 달성하며 모델 파라미터의 5.2%만 학습하는 것.
관련 연구
세분화 아키텍처
전완 컨볼루션 네트워크는 세분화에 혁명을 가져왔으며, U-Net은 의료 이미징에서 여전히 기초적인 인코더-디코더 패러다임과 스킵 연결을 설정했다. DeepLabV3+는 다중 스케일 컨텍스트 집약을 위해 이상한 공간 피라미드 풀링을 도입했으며, 최근의 자기 구성 접근 방식인 nnU-Net은 체계적인 하이퍼파라미터 최적화를 통해 강력한 성능을 달성했다. 이러한 아키텍처는 비전 트랜스포머와 계층 설계에 관한 기초 연구를 바탕으로 한다.
세분화를 위한 기본 모델
Segment Anything Model은 10억 개 이상의 마스크로 사전 학습되어 프롬프트 가능한 제로샷 세분화를 가능하게 하는 새로운 패러다임을 나타낸다. SAM은 상호작용적인 마스크 생성에 뛰어나지만, 도메인 특이적 이진 마스크에 대한 세분화 적응에는 프롬프트 없이 작업할 수 있는 능력이 필요하다. SAM 2는 이러한 기능을 비디오로 확장하여 프롬프팅 패러다임의 확장성을 보여준다. 그러나 의료 이미징이나 원격 감시와 같은 분포 이동이 상당한 도메인에서는 프롬프트 없는 적응과 작업 특화 튜닝이 필수적이다.
SAM의 전문 도메인 적응
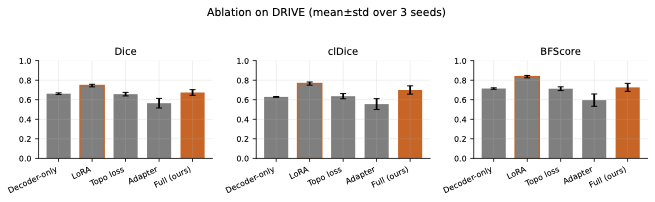
여러 동시 연구는 의료 이미징을 위한 SAM 적응을 다루고 있다. MedSAM은 대규모 의료 데이터셋에서 SAM을 미세 조정하여 다양한 모달리티에 걸친 강력한 일반화를 보여준다. SAM-Adapter는 성능이 저조한 장면용 도메인 특이적 어댑터 모듈을 제안하며, SAM-Med2D는 2D 의료 이미지 세분화에 초점을 맞춘다. HQ-SAM은 향상된 마스크 경계를 위한 고품질 출력 토큰을 도입하고, PerSAM은 학습 없는 프롬프트 학습을 통해 일회성 개인화를 가능하게 한다. 우리의 작업은 파라미터 효율성(LoRA + 어댑터)과 얇은 구조 도메인의 연결성을 유지하기 위한 위상 보존(clDice)을 동시에 다룬다.
파라미터 효율적 미세 조정
PEFT 방법론은 최소한의 파라미터 오버헤드로 기본 모델 적응을 가능하게 한다. LoRA는 가중치 업데이트를 저랭크 행렬로 재매개변수화하여 언어 모델에서 전체 미세 조정과 비교 가능한 성능을 달성한다. AdaLoRA는 적응적 랭크 할당을 통합하고, DoRA는 학습 동역학 개선을 위해 가중치를 크기와 방향으로 분해한다. 어댑터 모듈은 변환기 블록 사이에 학습 가능한 병목 층을 삽입하며, AdaptFormer은 이를 시각적 작업에 적응시킨다. Visual Prompt Tuning (VPT)은 입력 시퀀스 앞에 학습 가능한 토큰을 추가한다. Scale-and-shift tuning (SSF)은 더욱 파라미터 효율적인 대안을 제공한다.
위상 인식 손실 및 지표
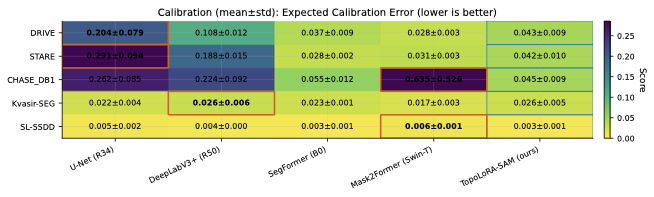
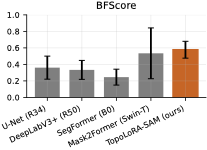
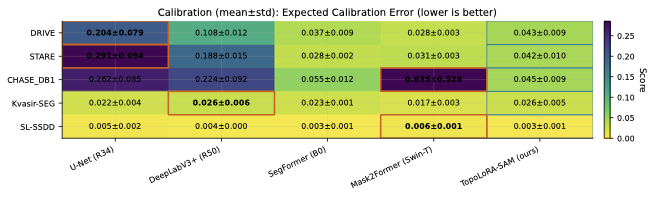
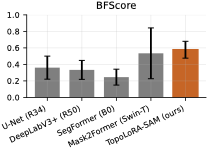
표준 겹침 지표(Dice, IoU)는 얇은 구조의 연결성을 깨뜨리는 위상 오류에 무감각하다. clDice는 연결된 중심선을 장려하기 위해 가변형 소스켈레톤화를 사용하여 골격 겹침을 계산한다. TopoLoss와 Betti matching과 같은 보완적인 접근 방식은 지속적 호몰로지 또는 지속성 바코드 대응을 통해 위상 정확성을 장려하며, 경계에 초점을 맞춘 BFScore는 윤곽 정밀도를 평가한다. 확률 출력의 경우 예상 캘리브레이션 오차(ECE)와 같은 신뢰성 지표는 임상 배포에서 중요하다.
문제 포뮬레이션
입력 이미지 $`\mathbf{x} \in \mathbb{R}^{H \times W \times 3}`$을 주면, 우리는 전경 확률(vessel, polyp 또는 sea 영역)을 나타내는 이진 세분화 마스크 $`\hat{\mathbf{y}} \in [0,1]^{H \times W}`$를 예측하려고 한다. SAM의 프롬프트 가능 패러다임은 사용자가 제공한 포인트나 상자를 기반으로 인스턴스 무관 마스크를 생성하지만, 우리의 작업에서는 실행 시 프롬프트 없이 세분화 예측을 필요로 하므로 SAM의 인코더-디코더 아키텍처를 직접 이진 마스크 출력을 위한 엔드투엔드 학습으로 적응시켜야 한다.
SAM 아키텍처와 프롬프트 없는 디코딩
우리는 SAM ViT-B 아키텍처를 채택한다. (i) 12개의 트랜스포머 블록을 포함하는 Vision Transformer(ViT) 이미지 인코더는 임베딩 $`\mathbf{z} \in \mathbb{R}^{256 \times \frac{H}{16} \times \frac{W}{16}}`$를 생성한다. (ii) 사용자 상호작용을 임베딩 공간에 매핑하는 프롬프트 인코더, 그리고 (iii) 이미지와 프롬프트 임베딩을 교차 주의를 통해 결합하는 가벼운 마스크 디코더이다. 이진 세분화를 위해 우리는 프롬프트 없는 모드에서 작동한다. 사용자에게 제공되는 null 프롬프트 임베딩($`\varnothing`$)으로, 마스크 디코더는 세분화 예측 헤드로 작용한다. 디코더는 단일 이진 마스크를 출력하고 이를 바이리니어 보간법을 통해 대상 해상도에 확대한다.
저랭크 적응(LoRA)
효율적 적응과 사전 학습된 표현 유지에 기여하기 위해, 우리는 고정된 이미지 인코더에 LoRA 모듈을 삽입한다. 사전 학습된 선형 계층의 가중치 행렬 $`\mathbf{W}_0 \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}}`$에 대해, LoRA는 순방향 패스를 다음과 같이 재매개변수화한다:
여기서 $`\mathbf{A} \in \mathbb{R}^{r \times d_{\text{in}}}`$와 $`\mathbf{B} \in \mathbb{R}^{d_{\text{out}} \times r}`$는 학습 가능한 저랭크 요인으로, 랭크 $`r \ll \min(d_{\text{in}}, d_{\text{out}})`$. 우리는 $`\mathbf{A}`$를 Kaiming uniform로 초기화하고 $`\mathbf{B}`$를 0으로 초기화하여 $`\Delta\mathbf{W} = \mathbf{0}`$을 초기에 보장한다. 스케일링 요인 $`\alpha/r`$는 저랭크 업데이트의 크기를 조절한다.
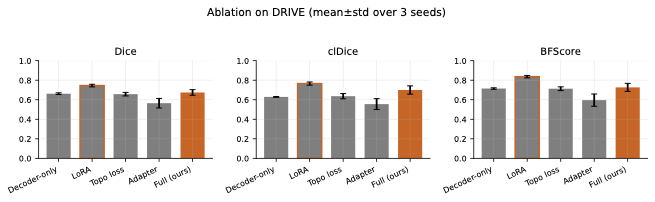
우리는 각 트랜스포머 블록 내부의 피드포워드 네트워크(FNN) 층, 특히 mlp.lin1과 mlp.lin2 프로젝션을 대상으로 한다. 이 설계 선택은 FNN 계층이 작업 특화된 특징 변환을 포착하는 반면 주의 가중치는 더 전달 가능한 관계 패턴을 인코딩한다는 직관에 따른 것이다. $`r=16`$과 모든 12개 블록에 LoRA를 적용하면 약 240만 개의 학습 가능 파라미터가 인코더에 추가된다.
공간 컨볼루션 어댑터
LoRA는 인코더의 표현 능력을 세분화 적응으로 허용하지만, 얇은 구조는 SAM의 $`16\times`$ 다운샘플링된 임베딩보다 더 높은 해상도에서 미세한 공간 추론을 필요로 한다. 우리는 이미지 임베딩 텐서 $`\mathbf{z}`$에 가벼운 깊이별 분리 컨볼루션 어댑터를 적용한다:
여기서 $`\text{Tprec}`$는 예측된 골격이 진정한 마스크와 얼마나 겹치는지를 측정하고, $`\text{Tsens}`$는 GT 골격의 커버리지를 측정한다. 소프트 골격화는 소프트 예측 맵에 적용된 반복적 형태학 연산(최소 풀링)을 통해 구현된다.
모델
전체 (M)
학습 가능 (M)
학습 가능한 %
U-Net (ResNet34)
24.4
24.4
100.0%
DeepLabV3+ (ResNet50)
39.8
39.8
100.0%
SegFormer (MiT-B0)
3.7
3.7
100.0%
Mask2Former (Swin-T)
47.4
47.4
100.0%
TopoLoRA-SAM (ours)
93.7
4.9
5.2%
파라미터 효율성 비교. TopoLoRA-SAM은 전체 파라미터의 5.2%만 학습하면서 경쟁력 있는 또는 우수한 성능을 달성한다.
구현 세부사항
우리는 SAM ViT-B 사전 학습 가중치를 사용하고 모든 인코더 파라미터를 고정하지만 LoRA 모듈은 제외한다. 마스크 디코더는 여전히 학습 가능하다($`\sim`$240만 개의 파라미터). 총 학습 가능한 파라미터: $`\sim`$490만 (LoRA: 240만, 어댑터: 66K, 디코더: 240만), 전체 93.7M에 비해. 표 1은 파라미터 효율성을 요약한다. 학습은 AdamW, 학습률 $`10^{-4}`$, 코사인 감소 및 50 에폭을 사용한다.
실험적 설정
데이터셋
다섯 가지 이진 세분화 벤치마크를 다루며 세 가지 독특한 응용 분야를 포함한다:
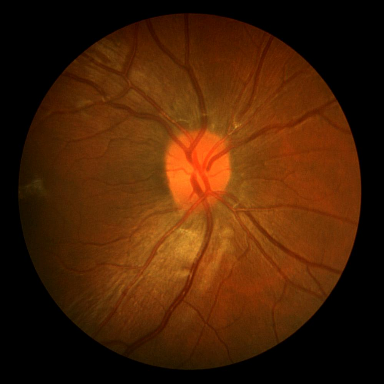
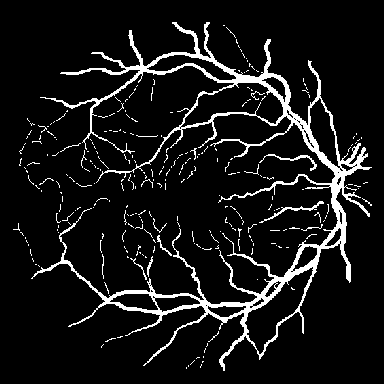
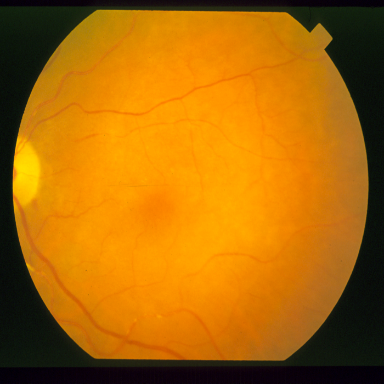
시신경 혈관 세분화
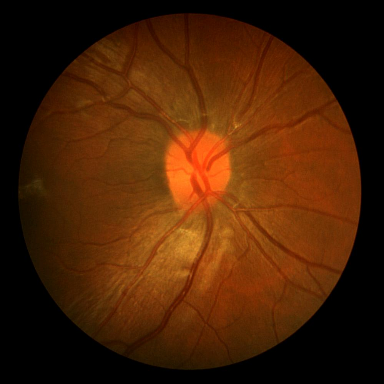
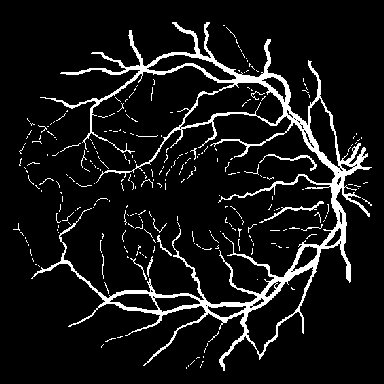
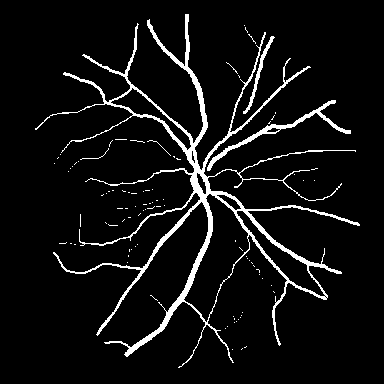
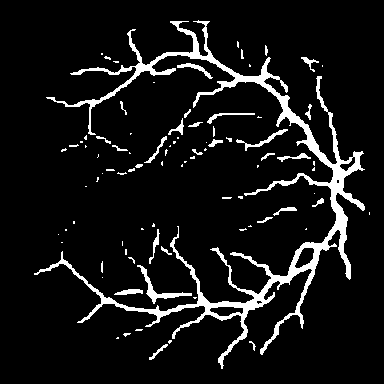
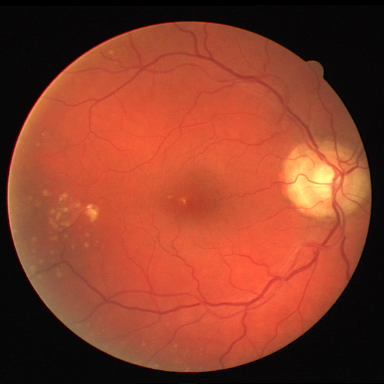
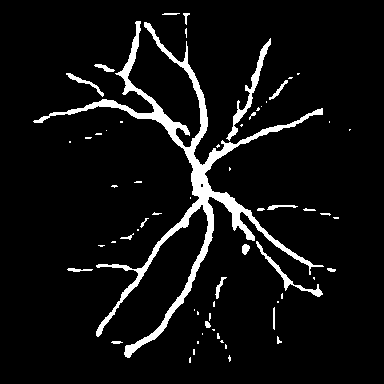
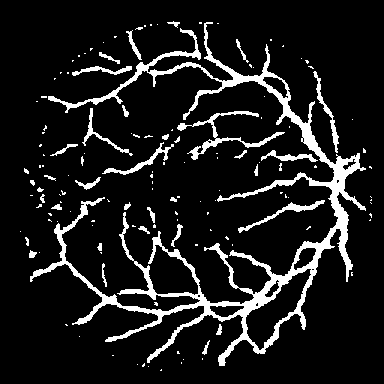
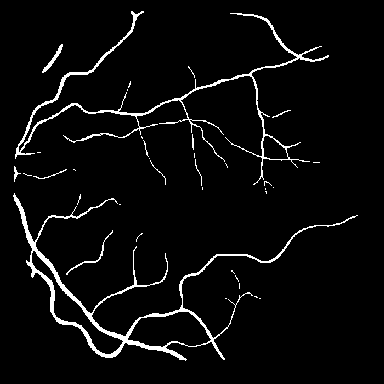
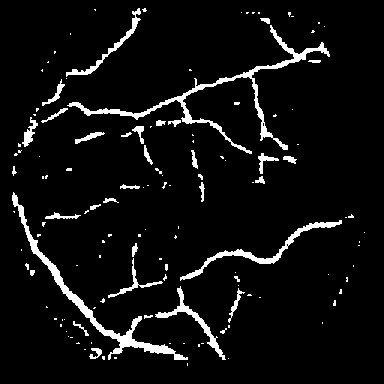
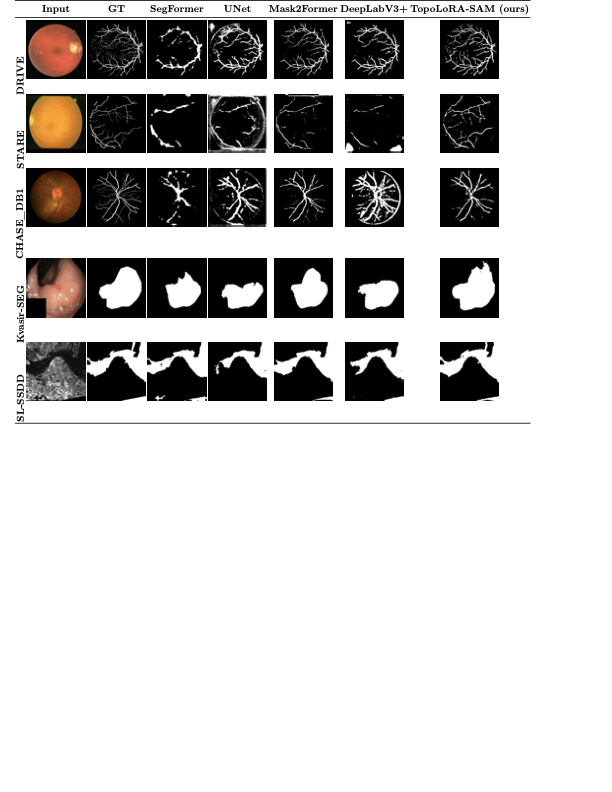
DRIVE는 전문 안과 의사의 수작업 혈관 주석을 가진 40개의 색상 펀더스 이미지(584$`\times`$565)를 포함하며, 학습은 20장의 이미지를 사용하고 테스트는 20장의 이미지를 사용한다. STARE는 병리학적 이상을 가진 혈관이 있는 20개 이미지(700$`\times`$605)를 제공하며, CHASE_DB1은 소아 인구 연구에서 얻어진 고해상도 이미지(999$`\times`$960)로 구성되어 있다. 이러한 데이터셋은 혈관 분석에 임상적으로 중요한 연결성을 유지하는 얇은 구조 세분화를 예시한다.
폴립 세분화
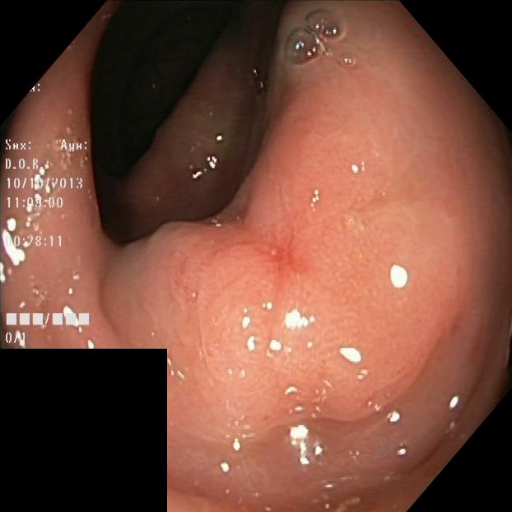
Kvasir-SEG에는 대장 내시경 이미지와 해당 폴립 마스크가 포함되어 있으며, 조기 대장암 검출에서 중요한 작업을 나타낸다. 이미지는 해상도 및 폴립 출현이 다양하다.
SAR 해/육지 세분화
SL-SSDD는 해양 경계를 구별하기 위한 합성 개구 레이더(SAR) 영상을 제공하며, 스펙클 노이즈, 낮은 대비 및 자연 이미지와의 상당한 분포 이동으로 인해 어려움을 겪는다.
전처리와 증강
모든 데이터셋은 ImageNet 표준화($`\mu=[0.485, 0.456, 0.406]`$, $