(주요 내용: 이 논문은 PDF 문서에 대한 질의응답(QA)을 위한 새로운 데이터셋인 pdfQA를 제안합니다. pdfQA는 합성 데이터와 실제 인간 주석화된 QA 쌍으로 구성되어 있으며, 이를 통해 다양한 복잡도 차원에서 모델 성능을 평가할 수 있습니다.)
💡 논문 해설
1. **pdfQA의 출현:** pdfQA는 PDF 문서에 대한 질의응답(QA)을 위한 데이터셋입니다. 이는 합성 데이터와 실제 인간 주석화된 QA 쌍을 포함하며, 다양한 복잡도 차원에서 모델 성능을 평가할 수 있도록 설계되었습니다.
복잡도 차원의 중요성: pdfQA에서는 여러 복잡도 차원(예: 파일 유형, 질문 및 답변 유형, 관련 출처 분산 등)에 따라 QA 쌍이 생성됩니다. 이는 모델 성능을 체계적으로 분석하고 개선할 수 있는 기반을 마련합니다.
질과 난이도 필터링: pdfQA는 엄격한 질과 난이도 필터를 적용하여 최종 데이터셋의 품질을 보장합니다. 이를 통해 모델은 실제 세계에서 더 효과적으로 작동할 수 있습니다.
📄 논문 발췌 (ArXiv Source)
# 소개
대형 언어 모델(LLMs)은 코딩, 수학, 일반적인 QA 벤치마크에서 점점 더 인상적인 능력을 보여주며 다양한 작업에 사용됩니다. 주요 활용 영역 중 하나는 증거 기반 질문 응답(Evidence-Based Question Answering, EBQA)입니다. 이는 오늘날 대부분의 경우 생성형 검색 엔진이나 검색 강화 생성(Retrieval Augmented Generation, RAG)에서 볼 수 있습니다. 그러나 EBQA의 신뢰성에 대한 지속적인 논란이 있으며, 오픈 소스 모델에서는 특정 문제점들이 제기되고 있습니다. 성능 측정 및 개선을 위한 주요 이슈 중 하나는 실제 벤치마크가 부족하다는 점입니다.
실제 QA의 시작점은 다양한 문서 유형 처리입니다. 그럼에도 불구하고 대부분의 증거 기반 QA 데이터셋은 사전 가공된 텍스트 샘플에서 시작합니다. 이런 맥락에서 PDF는 크게 연구되지 않았습니다. 벤치마크가 PDF를 다루더라도 여전히 세 가지 단점이 있습니다. 첫째, 대부분의 데이터셋은 특정 사용 사례에 집중되어 있습니다(예: 과학 보고서나 재무보고). 둘째, 더 포괄적인 벤치마크에서도 질문 복잡도 차원(예: 텍스트 또는 표 출처, 출처 수량, 질문 난이도)에 대한 구분이 부족합니다. 일반적으로 하나의 벤치마크 내에서는 복잡도 차원이 동일합니다(예: 표만을 다루는 질문). 셋째, 질문과 답변의 품질 및 난이도가 평가되지 않습니다. 고급 품질은 특히 인간 주석화 데이터에 대해 자주 가정되며, 이전 연구에서 제기된 문제에도 불구하고 그렇습니다.
이러한 단점을 해결하기 위해 우리는 pdfQA를 제안합니다. pdfQA는 4K의 합성 데이터(syn-pdfQA)와 PDF 기반의 실제 QA 쌍 2K(real-pdfQA)가 포함되어 있습니다. syn-pdfQA에서는 합성 데이터 생성 프로세스를 활용하여 10개의 복잡도 차원(예: 파일 유형, 질문 및 답변 유형, 문서 내 관련 출처 분산)에 대한 QA 쌍을 만듭니다. real-pdfQA에서는 기존의 인간 주석화된 PDF QA 벤치마크 9가지를 결합하고 소스 PDF 문서를 검색하여 준비합니다. 두 데이터셋 모두 엄격한 품질 및 난이도 필터링을 거칩니다.
그런 다음 오픈 소스 모델로 pdfQA의 질문에 답합니다. syn-pdfQA에서는 복잡도 차원이 실제로 모델 성능과 상관관계를 나타내며 분석 가능성을 제시합니다. 또한 real-pdfQA에서 인간 주석화된 QA 쌍은 더 어렵게 보입니다. 이로써 pdfQA는 다양한 원본 문서 및 관련 출처에 대한 QA 쌍을 포함하며, QA 쌍 분류와 실세계의 어려운 작업을 제공합니다. 따라서 pdfQA는 다양한 종단 간 평가 시나리오(예: 파싱)를 지원할 수 있습니다.
style="width:80.0%" />
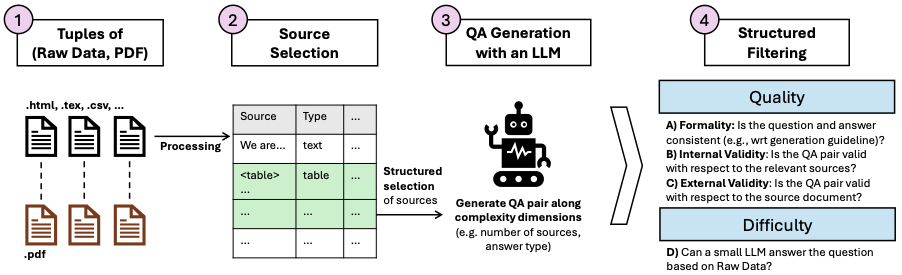
합성 데이터 생성ipeline. 입력은 PDF와 구조화된 형식(예: .tex 또는 .html 파일)의 동일한 문서 튜플입니다. 우리는 재무 보고서, 연구 논문, 책, 지속 가능성 공개 정보를 사용합니다(1). 이들은 구조화된 출처로 처리됩니다(2), 여기에서 대형 언어 모델은 다양한 복잡도 차원을 가진 QA 쌍을 생성합니다(3). 우리는 pdfQA의 유효하고 어려운 QA 쌍을 보장하기 위해 품질 및 난이도 필터를 적용합니다(4).
pdfQA
pdfQA는 두 가지 유형의 데이터셋으로 구성됩니다: syn-pdfQA, 합성 데이터 생성 파이프라인을 사용하여 다양한 복잡도 차원을 가진 QA 쌍을 만듭니다, 그리고 real-pdfQA, PDF에 대한 9개의 도메인별 인간 주석화된 데이터셋을 수집합니다. 두 데이터셋 모두 QA 쌍의 품질과 난이도를 보장하기 위해 필터링됩니다.
syn-pdfQA
syn-pdfQA 생성은 네 단계로 진행됩니다(그림 1 참조). 첫째, 구조화된 원시 데이터 파일이 동반되는 PDF를 검색합니다. 이것은 “.tex” 또는 “.html” 등의 파일입니다. 이는 원래 파일(즉, PDF의 완벽하게 파싱된 버전)을 기반으로 QA 쌍을 생성할 수 있게 하며, 최종 벤치마크는 PDF 파일에서 시작될 수 있습니다. 우리는 재무 보고서, 연구 논문, 책, 지속 가능성 공개 정보에서 다양한 입력 파일을 샘플링합니다(자세한 내용은 부록 6 참조).
둘째, 우리는 원시 파일을 구조화된 형식으로 처리하여 단락 수준에서 개별 출처를 분리하고 텍스트 또는 표로 레이블링합니다. 또한 문서 내 위치나 문서 길이와 같은 특성을 추적합니다. 더불어, 우리는 모든 출처에 대한 임베딩 모델을 사용하여 단순히 위치뿐만 아니라 출처 내의 의미적 관계도 추적합니다(자세한 내용은 부록 7 참조). 각 QA 쌍 생성 시, 무작위로 선택된 시드 단락과 주변 5-15개의 출처를 사용합니다. 이는 시드 단락 주변(위치적 근접성) 또는 동일 클러스터 내에 있는(의미적 근접성) 출처들입니다.
셋째, 우리는 샘플된 출처를 활용하고 GPT-4.1에게 이를 기반으로 질문과 답변을 생성하도록 지시합니다(프롬프트 설정은 부록 8 참조). QA 쌍 생성 시, 모델이 특정 유형의 질문과 답변을 생성하도록 요청합니다. 구조적 지식에 대한 원 데이터와 결합하면 다양한 복잡도 차원을 만들 수 있습니다(자세한 내용은 부록 9 참조). 구조적 지식(sn)과 대형 언어 모델(llm)에 기반한 차원을 구분할 수 있습니다:
답변 유형 (llm): 예/아니오, 값 추출, 단일 단어 또는 개방형 답변,
답변 길이 (sn): 답변의 길이,
논리적 사고 (llm): 답변이 정보의 복제인지 논리적 사고를 필요로 하는지,
질문 난이도 (llm): 미리 정의된 난이도 수준(간단, 중간, 어려움),
매체 유형 (sn): 질문에 답변하는 데 사용되는 매체 유형(예: 텍스트, 표, 혼합 매체),
관련 출처 개수 (sn): 질문을 답하기 위해 필요한 관련 출처의 수,
출처 분산 (sn): 첫 번째와 마지막 관련 출처 사이에 있는 텍스트 양의 거리 측정,
파일 위치 (sn): 파일 내에서 관련 출처가 모여있는 위치를 가늠하는 대리자,
파일 유형 (sn): 질문이 어떤 파일 유형에 속하는지 나타내는 것,
파일 길이 (sn): 파일의 길이.
넷째, 생성된 QA 쌍에 품질 및 난이도 필터를 적용합니다(그림 1 참조). 품질 필터는 GPT-4.1-mini의 도움을 받아 세 가지 차원을 검사합니다. 먼저, 생성 과정에서 정의된 형식적 기준에 따라 QA 생성이 이루어졌는지 확인합니다. 특히 질문이 전체 문서를 지칭하는지(예: “위쪽 테이블"이라는 문구가 없는지), 답변이 결정론적인지(예: “일부 조건을 이름 짓기”), 그리고 답변 유형이 올바른지(“예/아니오” 답변 유형은 실제로 “예” 또는 “아니오"만 포함하는지)를 확인합니다. 둘째, 내부 유효성을 검사합니다. 즉, 관련 출처와 질문을 고려할 때 답변이 올바른가요? 셋째, 외부 유효성을 검사합니다. 즉, 관련 출처 및 원 데이터에서 상위 k개의 의미적으로 연관된 출처를 고려할 때 답변이 여전히 올바른가요? 생성 과정 중 선택한 출처에 정보 부족으로 인해 답변과 모순되는 경우 이를 확인해야 합니다(부록 10 참조).
품질 필터 외에도 최종 데이터셋은 더 어려운 질문을 위한 필터링도 거칩니다. 간단한 휴리스틱 방식으로, GPT-4o-mini가 전체 원 데이터 파일을 사용하여 질문에 답할 수 있다면 그것은 너무 쉽다는 것입니다. 최종 데이터셋에는 모델이 답변하지 못한 QA 쌍만 포함됩니다(부록 11 참조). 합성적으로 생성된 QA 쌍 중 품질 필터에 의해 20.4%가 제거되었으며, 나머지 중에서는 난이도가 충분하지 않아 67.5%가 제거되었습니다(부록 12 참조). 총 7,655개의 입력 QA 쌍을 생성했으며 필터링 후에는 1,982개가 남았습니다(표 4 참조). 엄격한 품질 필터링에도 불구하고 최종 데이터셋은 오류 있는 QA 쌍을 포함할 수 있습니다. 이를 완화하기 위해 두 명의 인간 주석자가 필터링된 200개의 QA 쌍을 검증했습니다. 정확성이 88%이며 주석자 동의율이 93%(부록 14 참조)로 확인되어 올바른 QA 데이터셋을 생성했음을 강화합니다.
필터링 후 최종 데이터셋. syn-pdfQA의 입력은 합성적으로 생성된 QA 쌍이며, real-pdfQA는 9개 벤치마크에서 온 QA 쌍입니다. 두 개 모두 품질 및 난이도를 위해 필터링됩니다. 그런 다음 n 필터링된 QA 쌍은 주석을 체크하여 정확한지 검사합니다.
syn-pdfQA
real-pdfQA
입력 QA 쌍
7,655
22,866
필터링 후
1,982
2,041
필터링 후 최종 데이터셋. syn-pdfQA의 입력은 합성적으로 생성된 QA 쌍이며, real-pdfQA는 9개 벤치마크에서 온 QA 쌍입니다. 두 개 모두 품질 및 난이도를 위해 필터링됩니다. 그런 다음 n 필터링된 QA 쌍은 주석을 체크하여 정확한지 검사합니다.
주석
(n 필터링된 QA 쌍)
필터링 후 최종 데이터셋. syn-pdfQA의 입력은 합성적으로 생성된 QA 쌍이며, real-pdfQA는 9개 벤치마크에서 온 QA 쌍입니다. 두 개 모두 품질 및 난이도를 위해 필터링됩니다. 그런 다음 n 필터링된 QA 쌍은 주석을 체크하여 정확한지 검사합니다.
88%
(200)
필터링 후 최종 데이터셋. syn-pdfQA의 입력은 합성적으로 생성된 QA 쌍이며, real-pdfQA는 9개 벤치마크에서 온 QA 쌍입니다. 두 개 모두 품질 및 난이도를 위해 필터링됩니다. 그런 다음 n 필터링된 QA 쌍은 주석을 체크하여 정확한지 검사합니다.
91%
(100)
real-pdfQA
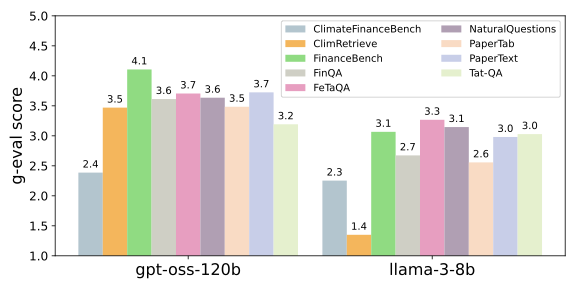
real-pdfQA 생성은 두 단계로 진행됩니다. 첫째, PDF 파일을 기반으로 하는 인간 주석화된 QA 데이터셋을 검색합니다. 이론적으로 많은 데이터셋이 PDF에서 시작하지만, 파일 자체는 일반적으로 오픈 소스가 아닙니다. 따라서 우리는 해당 PDF를 검색하기도 합니다(과거 연구 참조). 또한 우리가 나중에 필터링 단계와 호환되도록 QA 쌍을 출처 정보와 함께 보완하는 데이터셋을 필터링합니다. 9개의 인간 주석화된 PDF 기반 QA 데이터셋을 사용합니다: FinQA, FinanceBench, ClimateFinanceBench, ClimRetrieve, FeTaQA, NaturalQuestions, PaperTab 및 Qasper의 PaperText, Tat-QA(마지막 다섯 개의 데이터셋은 PDF 컬렉션 참조).
둘째, 우리는 이러한 데이터셋에 품질 및 난이도 필터를 적용합니다(그림 1 참조). 데이터셋이 인간 주석화되었지만, 품질 관리는 NLP 벤치마크의 유효성에 대한 우려에 대응하고 우리 특정 사용 사례 요구 사항에 맞추는 것을 목표로 합니다. 실제로 우리의 품질 필터는 58%의 QA 쌍을 제거합니다. 필터링된 데이터 포인트의 주요 이유는 전체 문서로 일반화할 수 없는 것입니다. 이는 원래 사용 사례에서 비롯됩니다. 많은 질문이 특정 텍스트나 표를 지칭(예: “이 표에 있는 값은 무엇입니까?")합니다. 우리의 품질 필터를 통해 전체 문서에 대한 유효성을 보장하려고 하며, 이러한 QA 쌍을 제거합니다(부록 13 참조). 품질 필터링된 QA 쌍 중 78%는 난이도 필터에 의해 제거됩니다. 즉, GPT-4o-mini가 전체 문서를 주어진 상태에서 질문을 정확하게 답변할 수 있었습니다. 따라서 처음에는 22K 개의 항목으로 시작하여 필터링된 real-pdfQA는 2041개의 QA 쌍을 포함합니다(표 4 참조). 다시 한번, 이들 QA 쌍이 실제로 유효한지 랜덤하게 추출된 100개의 QA 쌍을 주석화하여 확인했습니다. 정확성은 91%였습니다(부록 14 참조).
 style="width:80.0%" />
style="width:80.0%" />