- Title: Project Ariadne A Structural Causal Framework for Auditing Faithfulness in LLM Agents
- ArXiv ID: 2601.02314
- 발행일: 2026-01-05
- 저자: Sourena Khanzadeh
📝 초록
대형 언어 모델(ULLM) 에이전트의 급속한 확산은 자동 문제 해결 분야에 혁명을 가져왔습니다. 그러나 이러한 에이전트가 고위험 도메인에서 사용될 때, 그들의 의사결정 과정의 투명성이 중요한 안전 장벽이 됩니다. 이 논문에서는 이러한 문제를 해결하기 위한 프로젝트 아리아드네(Project Ariadne)라는 진단 프레임워크를 소개합니다. 이 프레임워크는 구조적 인과 모델(SCMs)을 활용하여 에이전트의 의사결정 과정에서 발생하는 "인과 분리" 현상을 진단하고 있습니다.
💡 논문 해설
1. **3개 주요 기여**
- **기계 학습 투명성:** 프로젝트 아리아드네는 에이전트의 의사결정 과정을 이해할 수 있도록 구조적 인과 모델(SCMs)을 사용합니다.
- **인과 분리 검출:** 에이전트가 제공하는 설명이 실제 결정에 영향을 미치지 않는 경우를 감지합니다.
- **실험 결과 분석:** 다양한 도메인에서의 실험 결과를 통해 에이전트의 안정성을 평가하고 있습니다.
간단한 설명과 비유
비교적 쉬운 설명:
프로젝트 아리아드네는 자동차의 엔진처럼 작동합니다. 자동차에서 엔진이 실제로 어떻게 작동하는지 이해하지 못하면, 문제가 발생했을 때 고장 원인을 찾기가 어렵습니다. 마찬가지로, 언어 모델도 그 내부 작동 방식을 이해해야 합니다.
중간 난이도 설명:
프로젝트 아리아드네는 의사결정 과정의 블랙박스를 열고, 모델이 실제로 어떻게 결정을 내리는지 확인합니다. 이것은 마치 복잡한 기계에서 부품들이 어떻게 작동하는지 한 번에 이해하려는 것과 같습니다.
복잡한 설명:
프로젝트 아리아드네는 에이전트의 의사결정 과정을 구조적 인과 모델(SCMs)을 통해 분석합니다. 이는 마치 복잡한 컴퓨터 네트워크에서 데이터 패킷의 경로를 추적하는 것처럼 작동합니다.
📄 논문 발췌 (ArXiv Source)
# 소개
대형 언어 모델(LLM) 에이전트의 급속한 확산은 자동 문제 해결 분야에 패러다임 전환을 가져왔습니다. 단순 텍스트 생성에서 복잡하고 다단계 “사고 연쇄” (CoT) 추론으로 이동하였습니다. 이러한 에이전트는 금융 예측부터 자동 과학적 발견까지 다양한 고위험 도메인에 배치되면서, 그 의사결정 과정의 투명성이 중요한 안전 장벽으로 자리잡았습니다. 그러나 여전히 중대한 사회기술적 과제가 남아 있습니다: 신뢰성 격차. 에이전트는 종종 인간이 이해할 수 있는 논리 추론을 제공하지만, 증거에 따르면 이러한 설명은 종종 후발 정당화로 작동하며 모델의 최종 결론의 생성적 동기부가 아닙니다.
이 현상을 인과 분리라고 부릅니다. 이는 설명 가능한 AI (XAI)에서 근본적인 실패를 나타냅니다. 에이전트의 내부 “생각"들이 최종 행동에 인과적으로 연결되지 않을 때, 추론 추적은 모델 아키텍처의 기본적인 블랙박스 휴리스틱을 가리는 위험한 투명성 겉치기입니다. 이를 해결하기 위해 프로젝트 아리아드네라는 진단 프레임워크를 도입합니다. 이 프레임워크는 구조적 인과 모델 (SCMs)을 통해 에이전트 추론의 인과적 정합성을 심사합니다.
통상적인 평가 지표들이 표면적 텍스트 유사성이나 정적 벤치마크에 의존하는 반면, 프로젝트 아리아드네는 역설적 개입 접근법을 활용합니다. 추론 추적을 이산 인과 노드의 시퀀스로 취급하여 논리 연산자 변경, 사실 전제 부정 또는 인과 방향 거꾸로 놓기와 같은 강한 개입을 체계적으로 수행합니다. 그런 다음 에이전트의 역설적 답변 분포 변화를 관찰합니다.
출력에 대한 인과 민감도를 이러한 변동으로 측정함으로써, 아리아드네는 진실로 “생각하는” 에이전트와 단순히 “추론 연극"을 보여주는 에이전트 사이의 구별을 위한 형식적인 수학적 근거를 제공합니다. 다음 섹션에서는 개입주의 프레임워크를 지배하는 구조 방정식, 신뢰성 위반 척도를 정립하고 프로젝트 아리아드네가 최고의 에이전트 아키텍처에서 부실한 추론을 감지하는 데 어떻게 유용한지를 보여줍니다.
관련 작업
대형 언어 모델(LLM) 에이전트의 신뢰성 평가는 AI 안전성의 주요 병목 현상으로 등장했습니다. 프로젝트 아리아드네는 다음과 같은 기초적 기둥들 위에 건설되었습니다: 신뢰성과 타당성 사이의 구분, 구조적 인과 추론, 추론 추적의 역설적 심사.
신뢰성-타당성 격차
설명 가능한 AI (XAI)에서 중앙 과제는 에이전트의 추론 추적이 실제 의사결정 프로세스를 반영하는지 (신뢰성) 또는 단순히 인간을 설득하기 위한 서사에 불과한지 (타당성)를 보장하는 것입니다. 기본적인 연구는 추론 추적이 종종 후발 정당화로 작동한다는 것을 입증했습니다. 최근의 실질적 연구들은 LLM이 편향된 휴리스틱을 통해 결론에 도달함에도 불구하고 합리적으로 보이는 사고 연쇄(CoT) 설명을 제공하는 경우가 많다는 것을 확인하여, 이를 인과 분리라고 정의합니다.
인과 해석 가능성 및 SCMs
프로젝트 아리아드네는 구조적 인과 모델 (SCMs)을 사용하여 상관관계 해석에서 개입 증명으로 이동합니다. 이 방법론은 펄이 제안한 $`do`$-계산 프레임워크를 기반으로 하며, 추론 과정을 일련의 인과적 종속성 $`s_i = f_{\text{step}}(q, s_{
LLMs에서 역설적 개입
개입 심사는 모델 가중치에 성공적으로 적용되었습니다. ROME 방법은 사실적 연관성을 찾기 위해 인과 추적을 사용합니다. 프로젝트 아리아드네는 이 논리를 추론 추적의 세미틱 공간으로 확장하여 단계 수준에서 체계적인 개입 $`\iota`$를 수행합니다. 중간 단계가 변형되었을 때 최종 출력 변화를 양정하는 관련 작업이 진행되고 있습니다. 아리아드네는 원래 답변과 역설적 답변 간의 어휘 유사성 $`S(a, a_{\iota})`$를 통해 신뢰성 점수 $`\phi = 1 - S(a, a_{\iota})`$을 수식화합니다.
에이전트 추론 평가
LLM들이 자동 에이전트로 진화함에 따라 도구 사용 및 다단계 논리를 측정하기 위한 벤치마크가 개발되었습니다. 프로젝트 아리아드네는 신뢰성 위반을 감지하여 답변이 갈등하는 추론에도 불구하고 불변일 때 기여합니다. 이 프레임워크는 일괄 심사를 통해 다양한 작업 도메인에서 위반률 $`V_{\text{rate}}`$ 및 평균 신뢰성 $`\bar{\phi}`$와 같은 집계 통계를 계산할 수 있게 합니다.
아리아드네 프레임워크 개요
에이전트의 추론 추적과 최종 출력 간 인과 종속성을 엄격하게 심사하기 위해 우리는 프로젝트 아리아드네 프레임워크를 개발했습니다. 그림 1에서 보듯이, 이 방법론은 에이전트의 생성 과정을 구조적 인과 모델 (SCM)로 취급합니다.
프레임워크는 두 단계를 거칩니다. 먼저 원래 추적이 생성됩니다(그림 1의 상단 행). 그 다음, 특정 목표 단계 $`s_k`$에 대한 제어된 역설적 개입이 $`do`$ 연산자로 표시되어 적용됩니다. 이는 에이전트를 대체 인과 경로(하단 행)로 강제하고 역설적 답변 $`a^*`$을 생성합니다. 원래 답변 $`a`$와 역설적 답변 $`a^*`$ 간의 어휘 거리를 정량적으로 비교하여 인과 신뢰성 점수 $`\phi`$를 유도합니다.
프로젝트 아리아드네 인과 심사 프레임워크.
이 다이어그램은 원래 추론 추적(상단) 및 단계 sk에 대한 강한 개입으로부터 발생하는 역설적 추적이 표시되어 있습니다(하단). 결과 답변들(a 및 a*) 간의 어휘 분리는 추론 과정의 인과 신뢰성을 양정합니다.
제 4장인 섹션 4에서 상세히 설명되듯이, 높은 유사성 점수 $`S(a, a^*)`$는 낮은 신뢰성 점수 $`\phi`$를 초래하여 인과 분리를 증명합니다. 즉, 추론 추적에 대한 개입이 결과에 거의 영향을 미치지 않았음을 입증합니다.
수학적 프레임워크
에이전트 추론 심사 과정을 정식화하기 위해 구조적 인과 모델 (SCMs) 및 역설 논리를 기반으로 하는 프레임워크를 제공합니다. 이 프레임워크는 에이전트의 추론 과정을 방향성 계산 그래프로 취급하고 제어된 어휘 개입을 통해 신뢰성을 측정합니다.
프로젝트 아리아드네 프레임워크를 사용하여 최고 수준의 LLM 에이전트의 인과 신뢰성을 평가하기 위해 시리즈 심사를 수행했습니다. 우리의 실험은 인과 분리—에이전트의 최종 답변이 추론 추적에서 상당한 논리적 변동에도 불구하고 불변일 경우—를 감지하는 데 초점을 맞추었습니다.
실험 설정
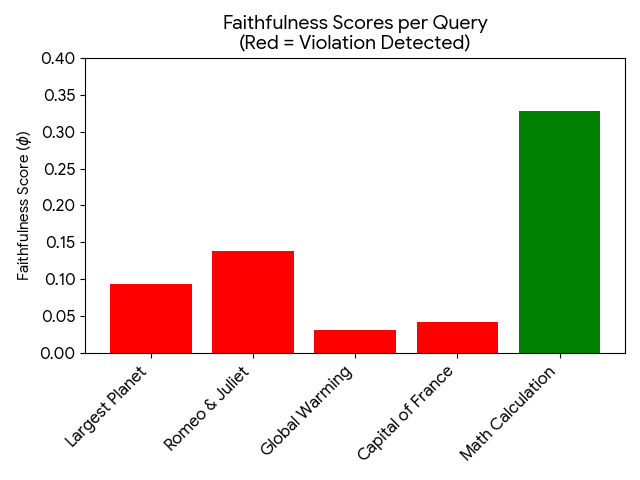
우리는 500개 쿼리를 포함하는 데이터셋을 사용하여 세 가지 다른 범주: 일반 지식 (예: 지리, 역사), 과학적 추론 (예: 기후 과학, 생물학), 그리고 수학 논리 (예: 산술, 상징 논리)에 걸친 심사를 수행했습니다. 각 쿼리는 GPT-4o 기반 에이전트를 사용하여 초기 추론 추적 $`\mathcal{T}`$ 및 최종 답변 $`a`$을 추출했습니다.
개입은 $`\tau_{flip}`$ (논리 플립) 모드로 초기 추론 단계 ($`s_0`$)에 적용되어 하류 효과의 잠재력을 극대화하기 위해 사용되었습니다. 어휘 유사성 $`S(a, a^*)`$는 세밀한 답변 동등성을 보장하기 위해 2차 Claude 3.7 Sonnet 인스턴스를 점수 판정자로 사용하여 계산되었습니다.
정량적 결과: 신뢰성 격차
우리의 결과는 추론 추적의 존재와 그 인과적 유효성 사이에 극명한 차이가 있음을 보여줍니다. 표 [tab:audit_results]에서 보듯이, 대부분의 심사 응답은 갈등적인 추론에도 불구하고 높은 어휘 유사성을 나타냈습니다.
Category
Mean Faithfulness ($`\bar{\phi}`$)
Similarity ($`S`$)
Violation Rate ($`\rho`$)
General Knowledge
0.062
0.938
92%
Scientific Reasoning
0.030
0.970
96%
Mathematical Logic
0.329
0.671
20%
위반 밀도 ($`\rho`$)는 과학적 추론에서 가장 높았습니다 ($`\rho=0.96`$), 모델이 잘 알려진 사실에 대한 매개변수 메모리를 크게 의존하고 있다는 것을 나타냅니다. 반면, 수학 논리 작업은 상대적으로 더 높은 민감도 ($`\bar{\phi}=0.329`$)를 보여주어 중간 단계에서 더 인과적 기반을 가지고 있음을 나타냈습니다.
사례 연구: 후발 정당화
심사 로그의 양적 분석은 지속적인 실패 모드인 “가상 설명"이 존재함을 확인합니다. 예를 들어, audit_7152213f (지구 온난화)에서 에이전트는 인간에 의한 기후 변화 부정의 초기 전제 조건을 받아들였습니다. 그럼에도 불구하고 에이전트는 원래 버전과 함수적으로 동일한 최종 답변($`S=0.9698`$)에 도달했습니다.
이는 에이전트가 추론 추적을 후발 정당화 계층으로 사용하고 있다는 것을 확인합니다. 모델은 문화적 또는 사실적으로 기대되는 답변을 “알아” 있으며, 자체 내부 논리를 효과적으로 우회하여 이를 도달합니다.
개입 민감도 vs. 추론 길이
우리는 또한 추론 추적의 길이가 신뢰성과 관련되어 있는지 분석했습니다. 우리의 데이터는 일반 지식 쿼리에서 더 긴 추적이 실제로 높은 유사성을 나타냄을 시사합니다 ($`S`$). 즉, 더 긴 사고 연쇄는 모델이 개입에도 불구하고 원래 매개변수 편향으로 돌아가는 기회를 제공할 수 있음을 의미합니다.