- Title: DatBench Discriminative, Faithful, and Efficient VLM Evaluations
- ArXiv ID: 2601.02316
- 발행일: 2026-01-05
- 저자: DatologyAI, , Siddharth Joshi, Haoli Yin, Rishabh Adiga, Ricardo Monti, Aldo Carranza, Alex Fang, Alvin Deng, Amro Abbas, Brett Larsen, Cody Blakeney, Darren Teh, David Schwab, Fan Pan, Haakon Mongstad, Jack Urbanek, Jason Lee, Jason Telanoff, Josh Wills, Kaleigh Mentzer, Luke Merrick, Parth Doshi, Paul Burstein, Pratyush Maini, Scott Loftin, Spandan Das, Tony Jiang, Vineeth Dorna, Zhengping Wang, Bogdan Gaza, Ari Morcos, Matthew Leavitt
📝 초록
실증적 평가는 기초 모델 연구 진전의 주요 나침반 역할을 합니다. 최신 비전-언어 모델(VLM) 훈련에 중점을 둔 많은 연구가 있음에도 불구하고, 이들의 평가 방법론은 아직 초기 단계입니다. 그 성숙을 돕기 위해 우리는 평가에서 충족해야 하는 세 가지 요구 사항을 제안합니다: (1) 모달리티와 응용 분야에 대한 충실성, (2) 다양한 품질의 모델 간 차별 가능성, 그리고 (3) 계산 효율성. 이 관점에서 우리는 충실성과 차별 가능성을 위반하고 모델 능력을 왜곡하는 중요한 실패 모드를 파악합니다: (i) 선택식 질문 형식은 추측을 장려하고 하류 사용 사례를 잘 반영하지 않으며, 모델이 개선됨에 따라 일찍 포화상태에 이릅니다; (ii) 이미지 없이도 답변 가능한 문제들로 구성된 평가의 70%까지 해당하며; (iii) 잘못 표시되거나 애매한 샘플은 일부 데이터셋에서 최대 42%를 차지합니다. 효율성 측면에서는, 가장 첨단의 모델을 평가하는 계산 부담이 금지불능 수준으로 올라갔습니다: 일부 보고서에 따르면 개발용 컴퓨팅 자원의 거의 20%가 단순히 평가를 위해 사용되고 있습니다. 기존 벤치마크를 버리는 대신, 우리는 변환 및 필터링을 통해 충실도와 차별 가능성을 최대한 높이는 방법으로 이를 정제합니다. 선택식 질문을 생성적 작업으로 바꾸는 것이 모델의 능력을 최대 35%까지 급격히 낮추는 것을 발견했습니다. 또한, 무작정 해결 가능한 문제와 잘못 표시된 샘플들을 필터링하면 차별 가능성을 향상시키면서 동시에 계산 비용을 줄일 수 있습니다. 우리는 DatBench-Full이라는 33개의 데이터셋으로 구성된 청소된 평가 패키지와, 원래 데이터셋의 차별 가능성과 거의 일치하면서 평균적으로 13배(최대 50배) 속도 향상을 달성하는 차별적 하위 집합인 DatBench를 공개합니다. 우리의 연구는 VLM이 계속 확장됨에 따라 동시에 엄격하고 지속 가능한 평가 관행을 추구하는 길을 제시합니다.
💡 논문 해설
1. **핵심 기여 1: DatBench의 개발** - 이 연구는 데이터 분석을 통해 모델 평가를 보다 정확하고 효율적으로 만드는 방법을 제시합니다. 이를 위해, 기존 벤치마크에서 신뢰성과 차별성을 높이는 전략을 적용했습니다. DatBench는 마치 불필요한 잡음이 많은 음악 파일에 노이즈 캔슬링 기술을 적용하여 중요한 정보만 남기는 것과 같습니다.
핵심 기여 2: 평가의 효율성 향상 - DatBench는 모델 평가를 위해 필요한 계산 자원을 크게 줄이는 데 성공했습니다. 이 방법은 마치 대규모 도서관에서 필요 없는 책들을 제거하여 중요한 정보에 더 쉽게 접근할 수 있도록 만드는 것과 같습니다.
핵심 기여 3: 신뢰성 있는 평가 데이터셋 - DatBench의 핵심 목표 중 하나는 모델이 실제 사용 사례와 관련된 시나리오에서 얼마나 잘 작동하는지를 측정합니다. 이를 위해, 불필요한 예제를 제거하고 중요한 기능을 유지합니다. 이 과정은 마치 레스토랑 메뉴에서 필요 없는 항목들을 제거하여 고객이 주요 요리를 더 쉽게 선택할 수 있도록 하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
maketitle 감사 aketitle
DatologyAI 팀
서론
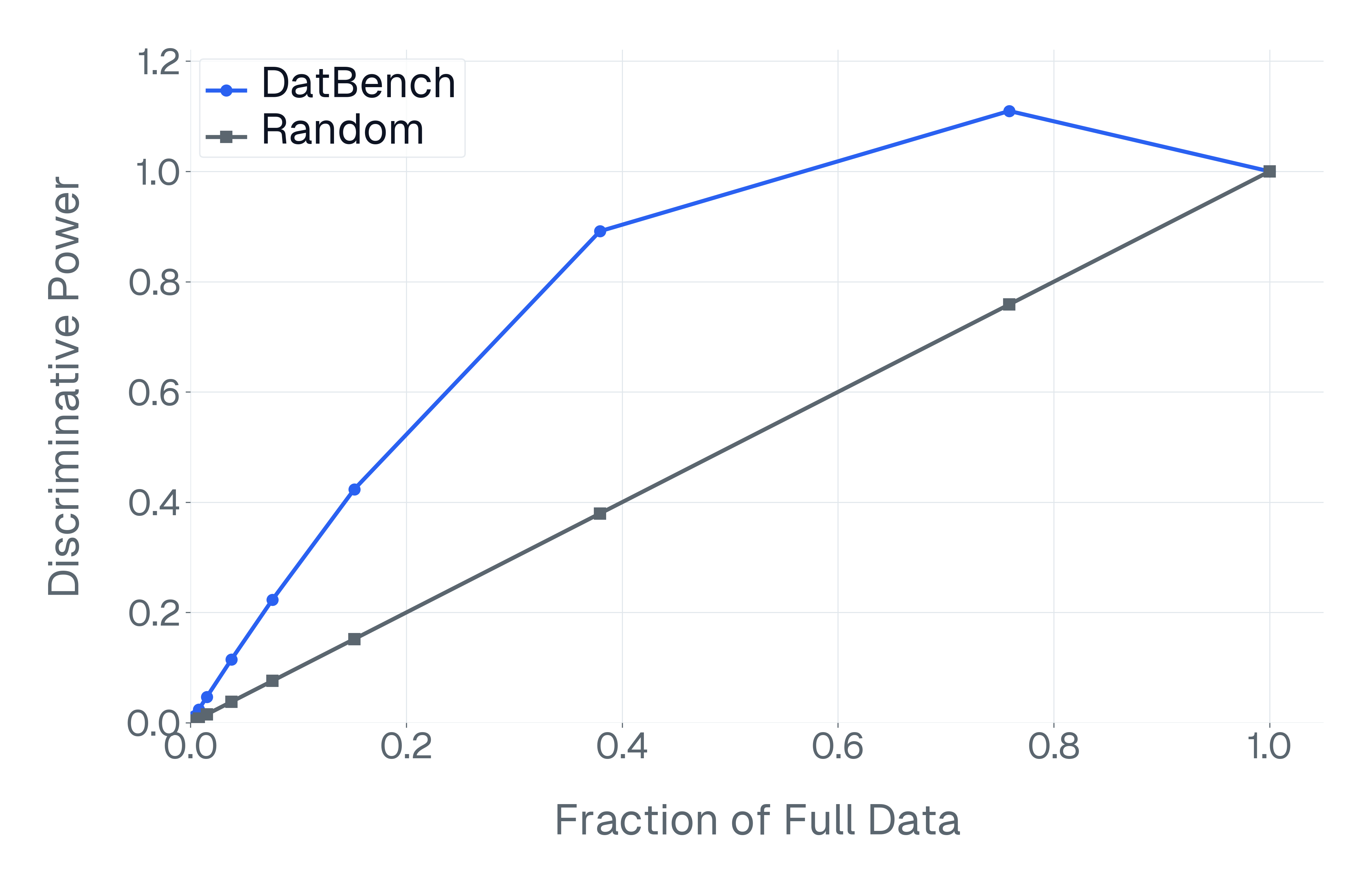
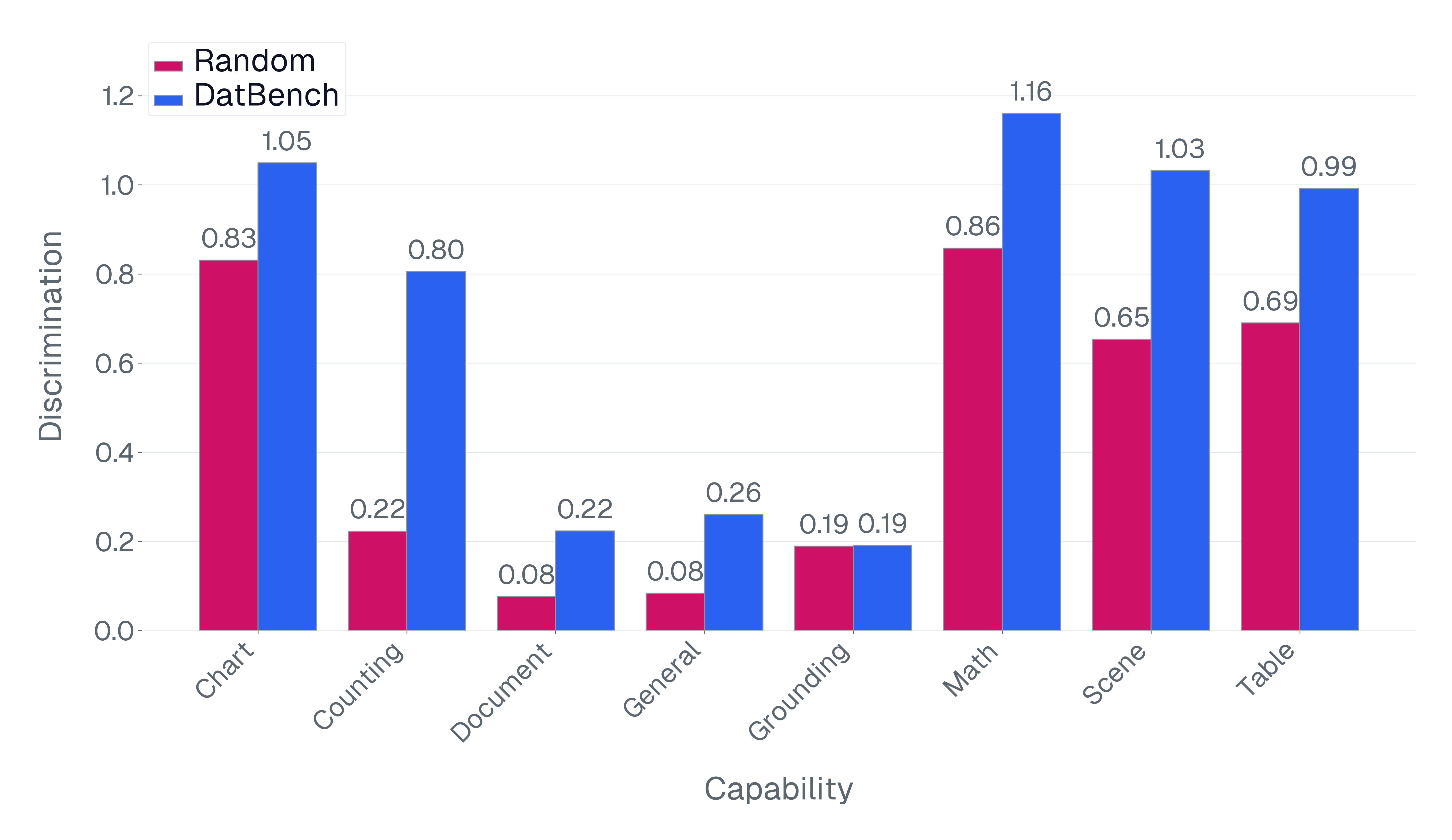
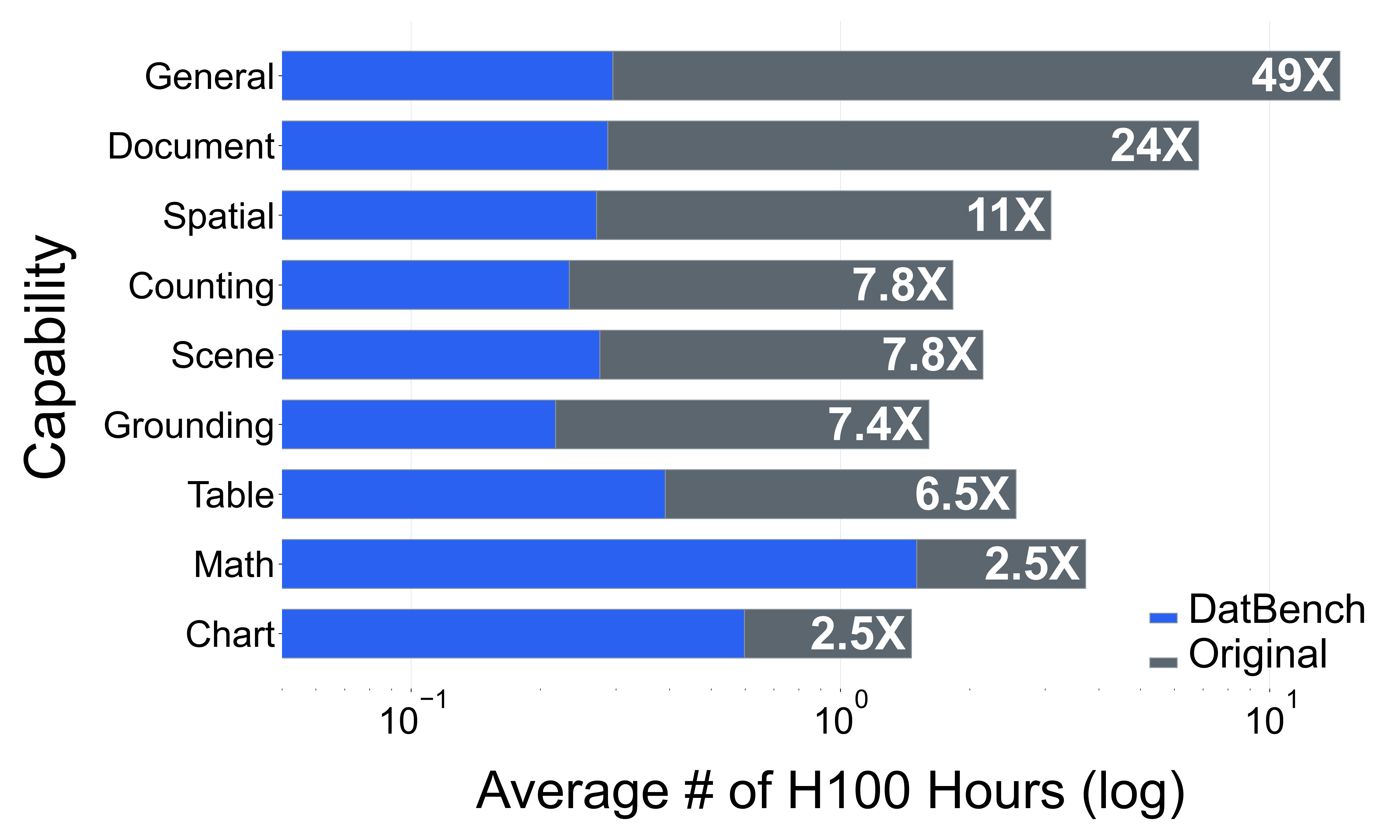
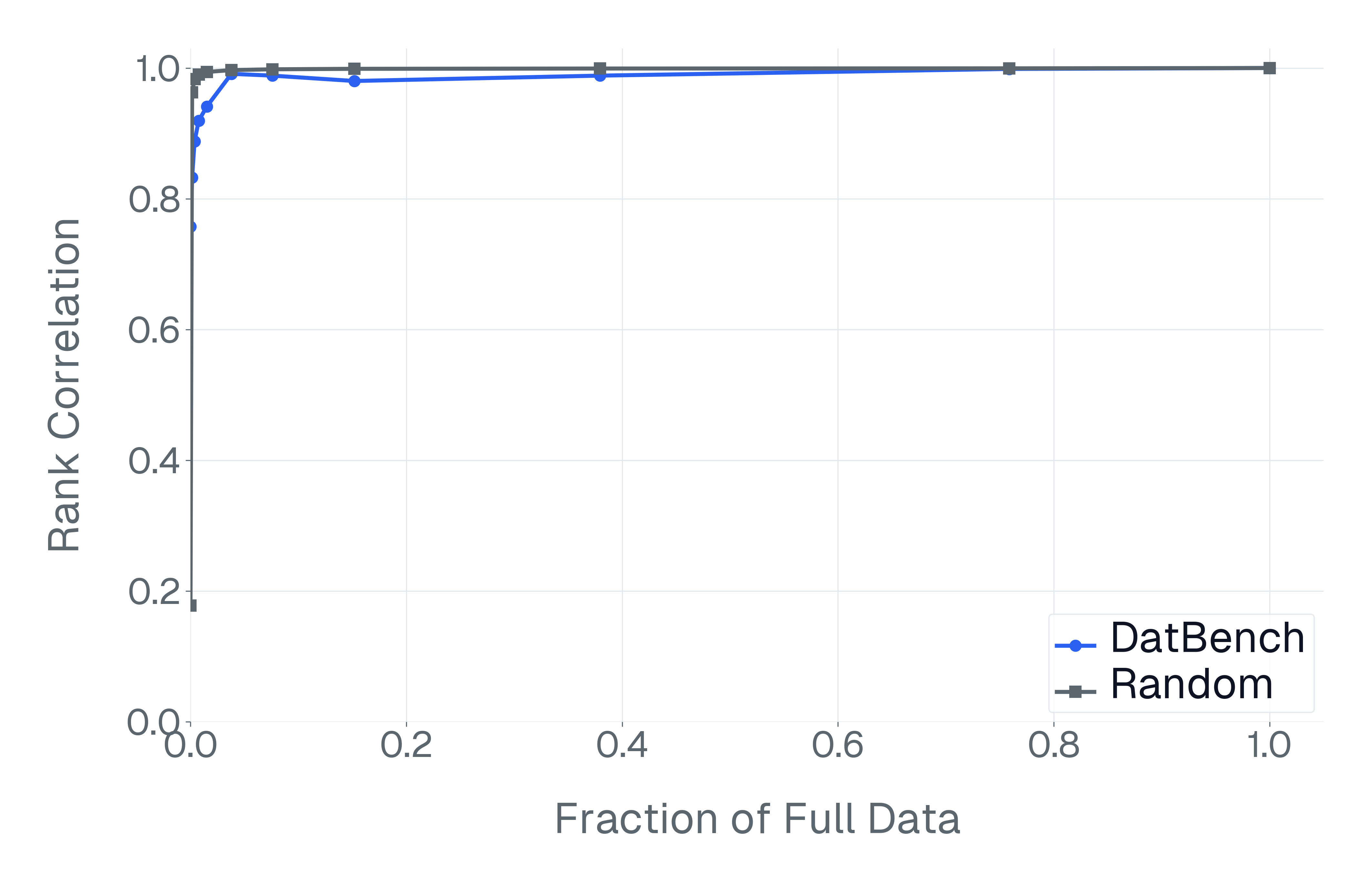
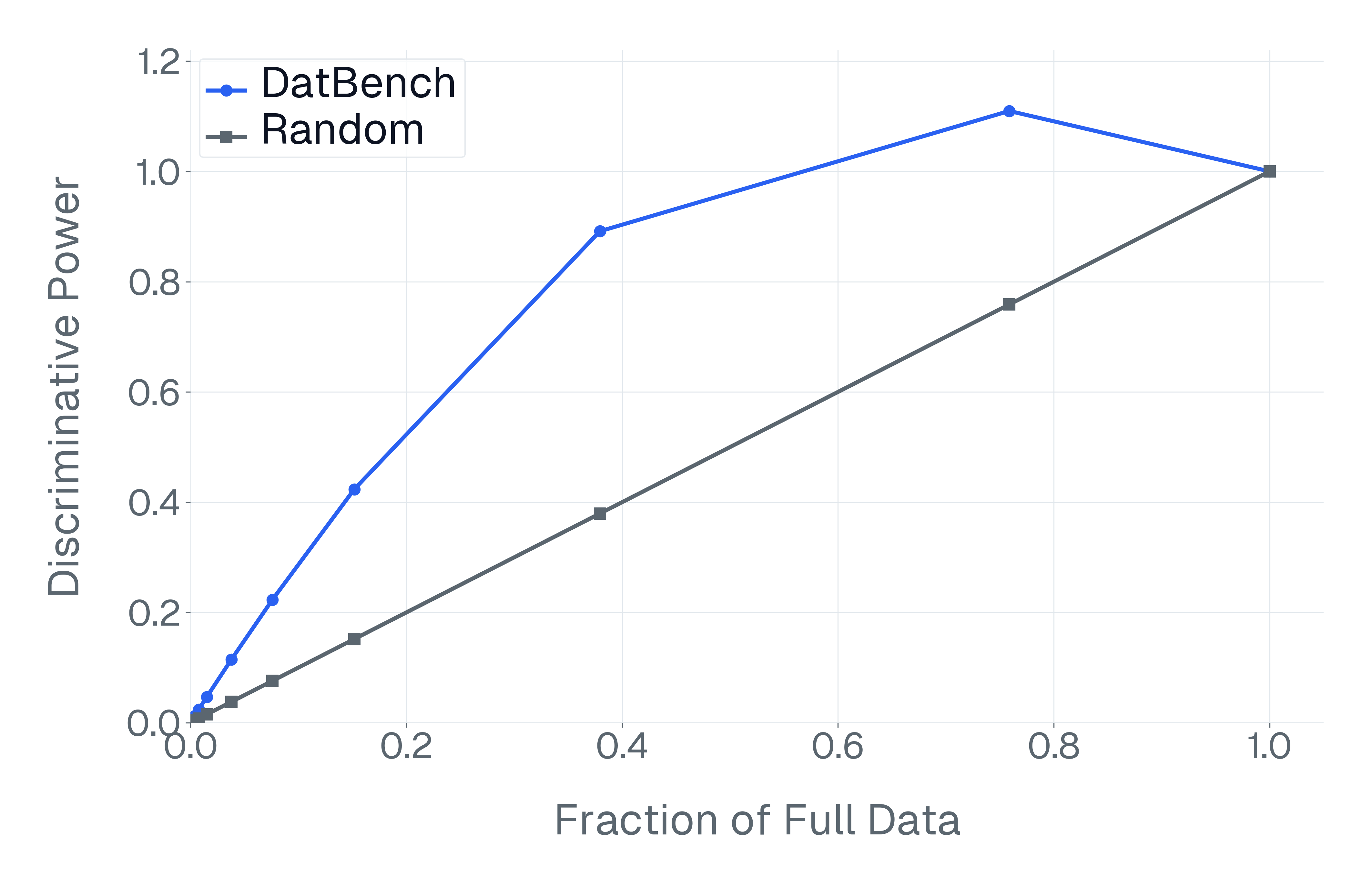
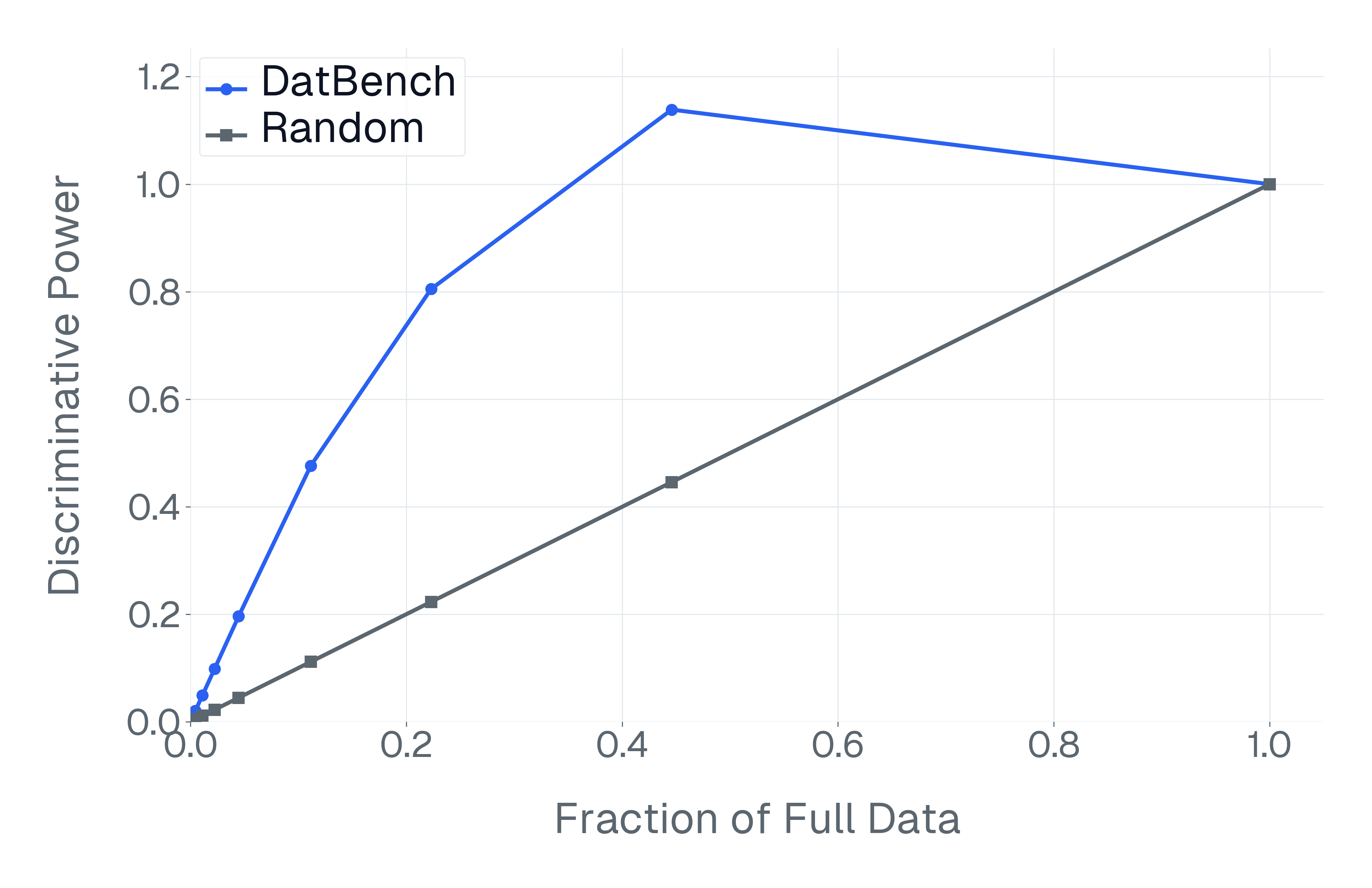
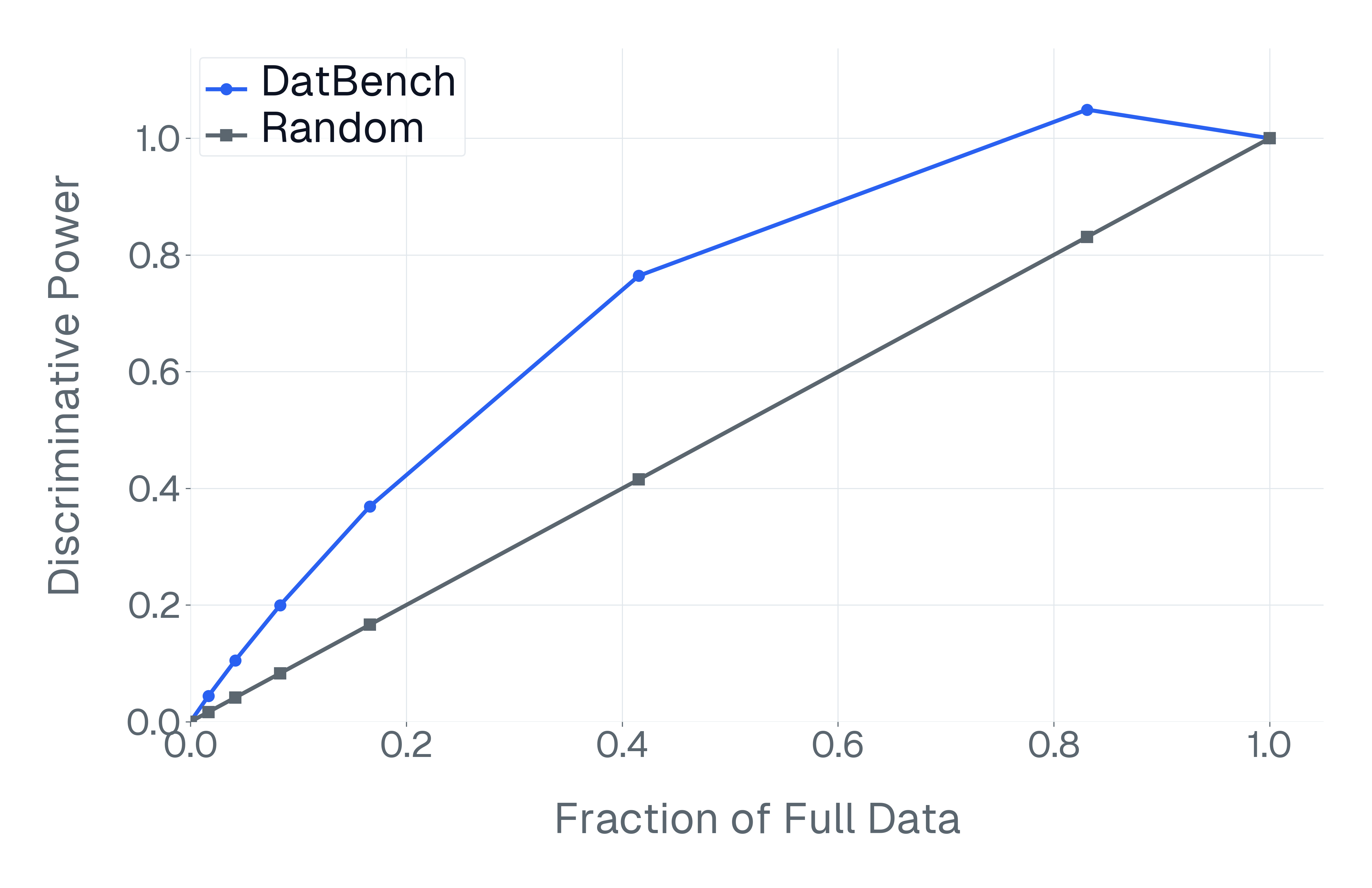
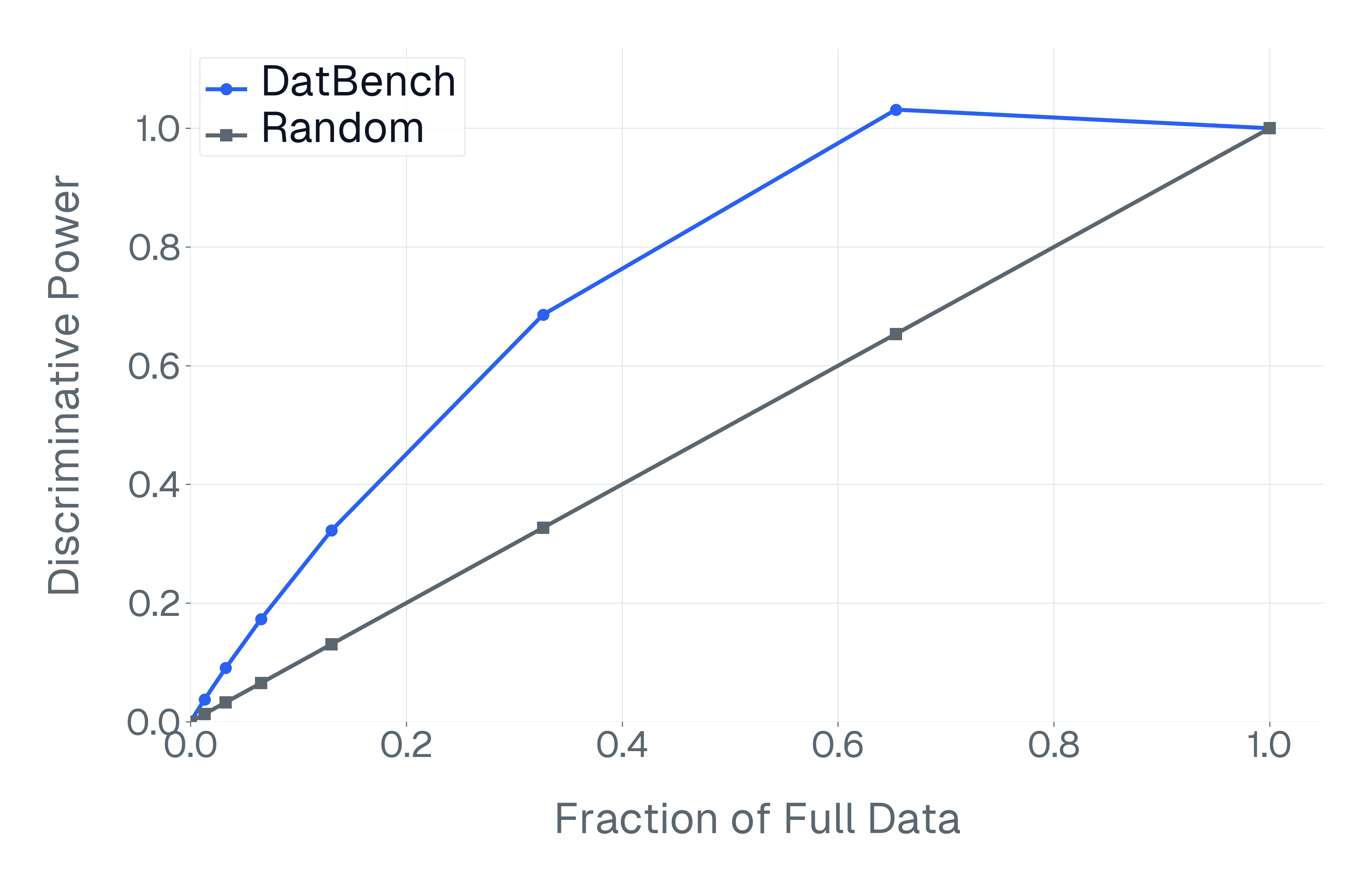
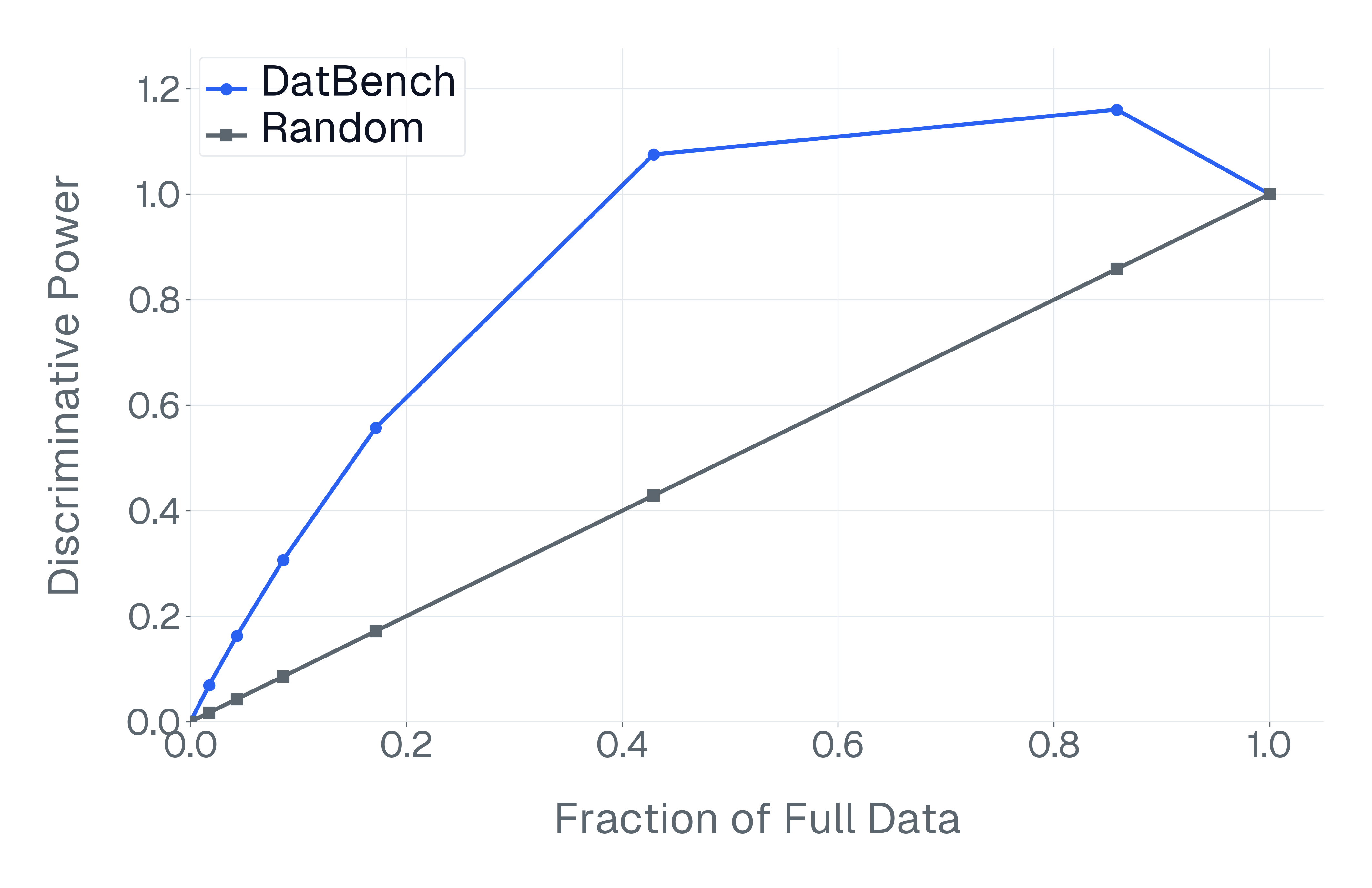
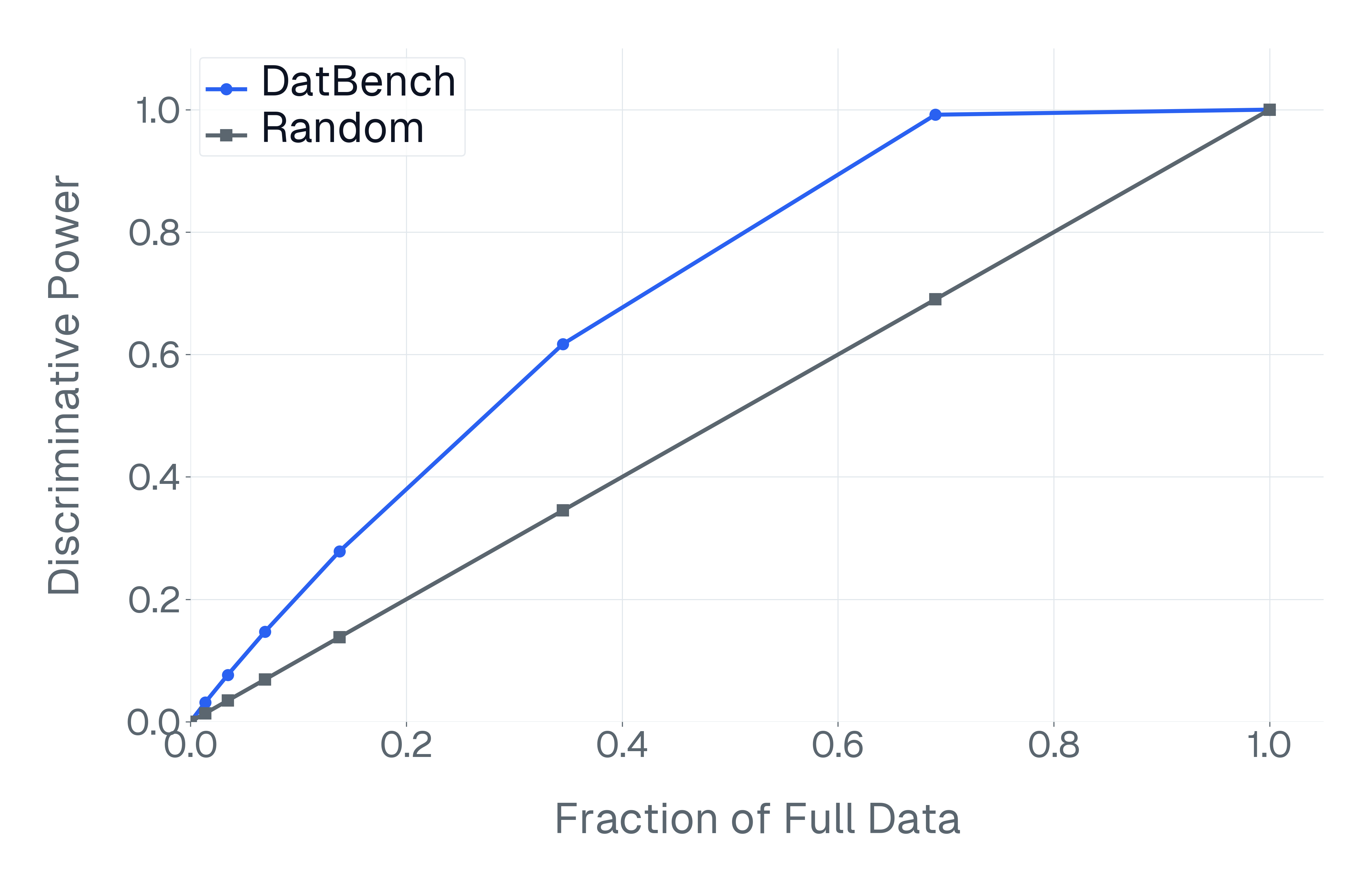
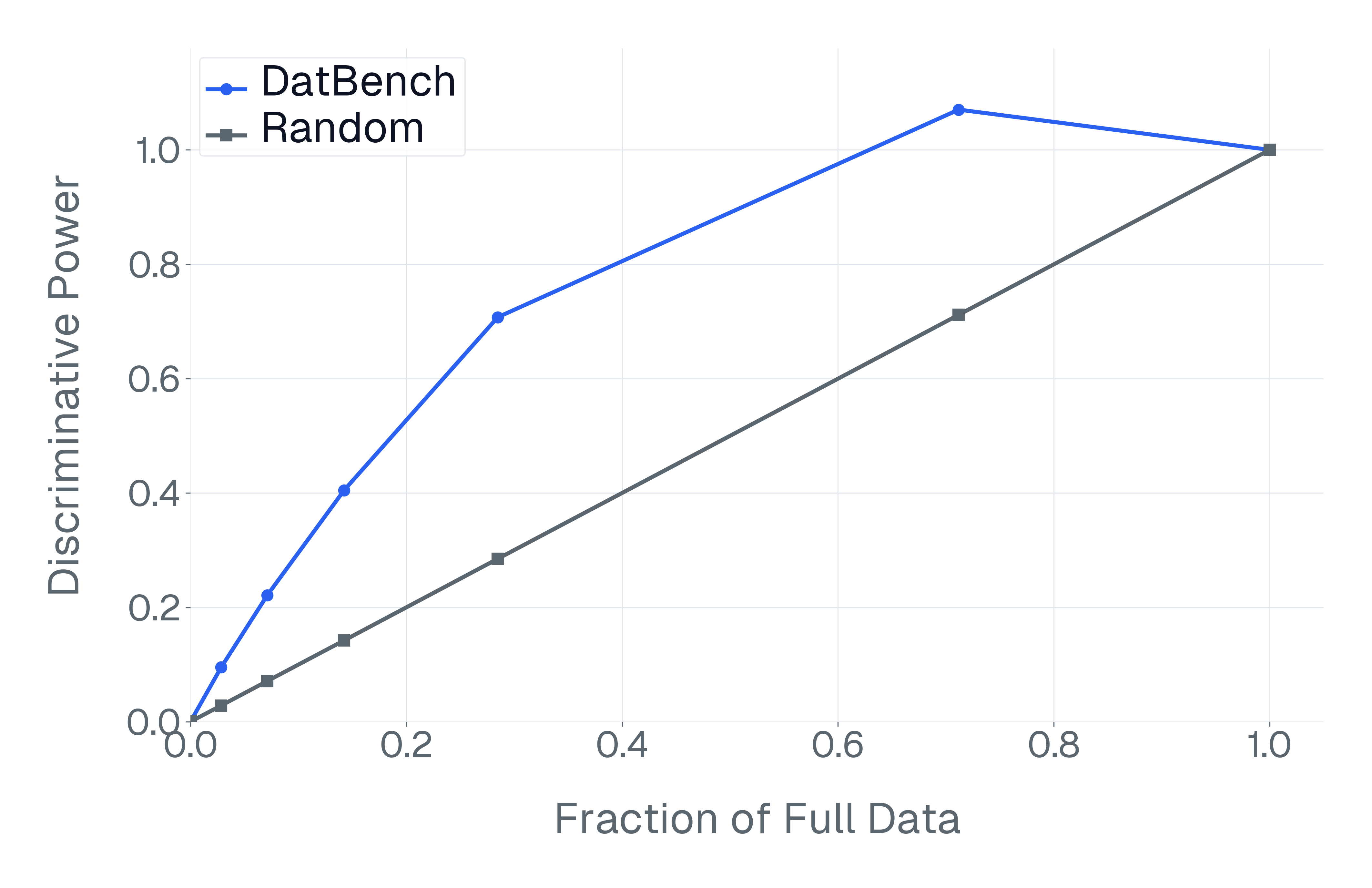
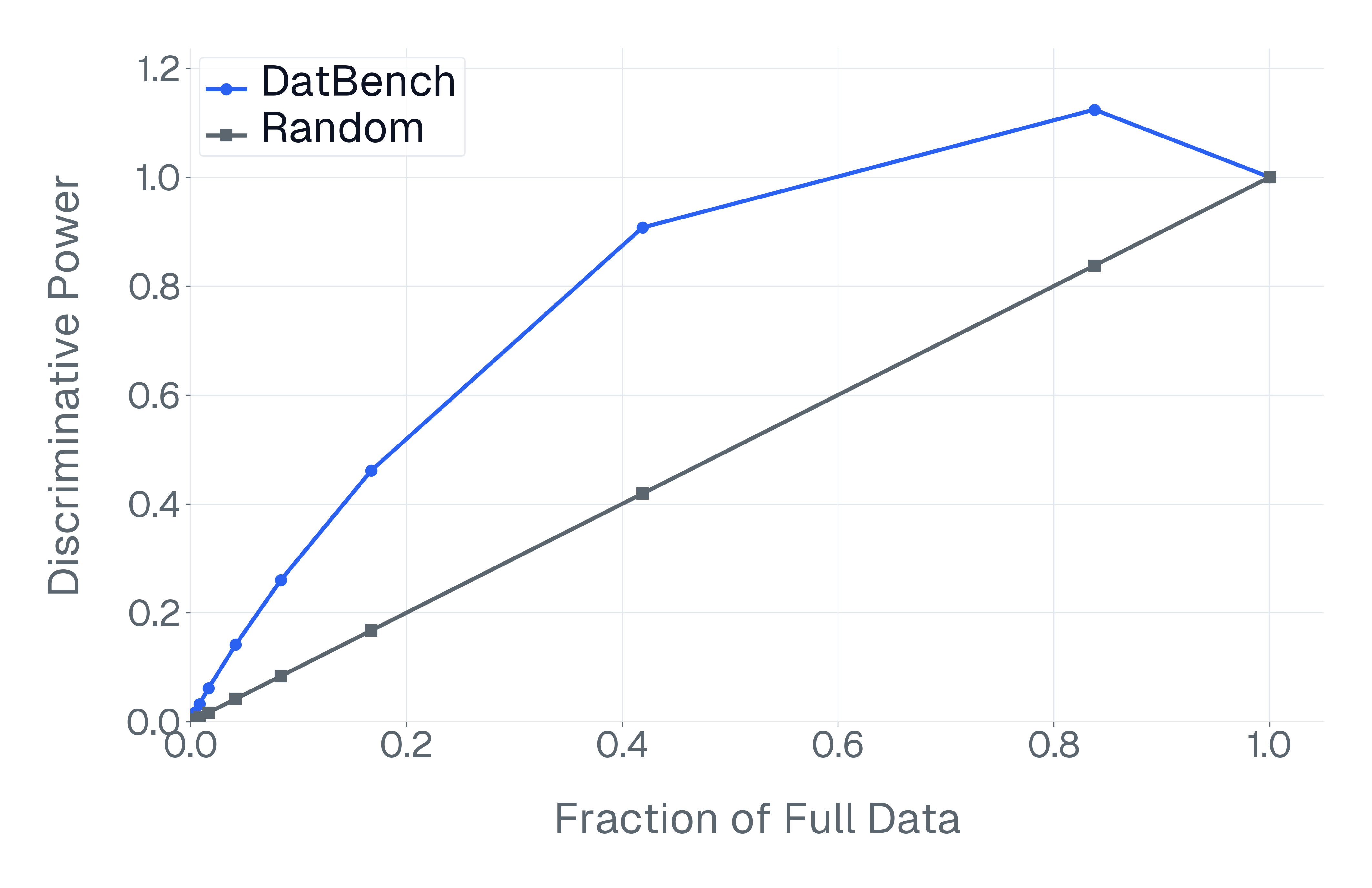
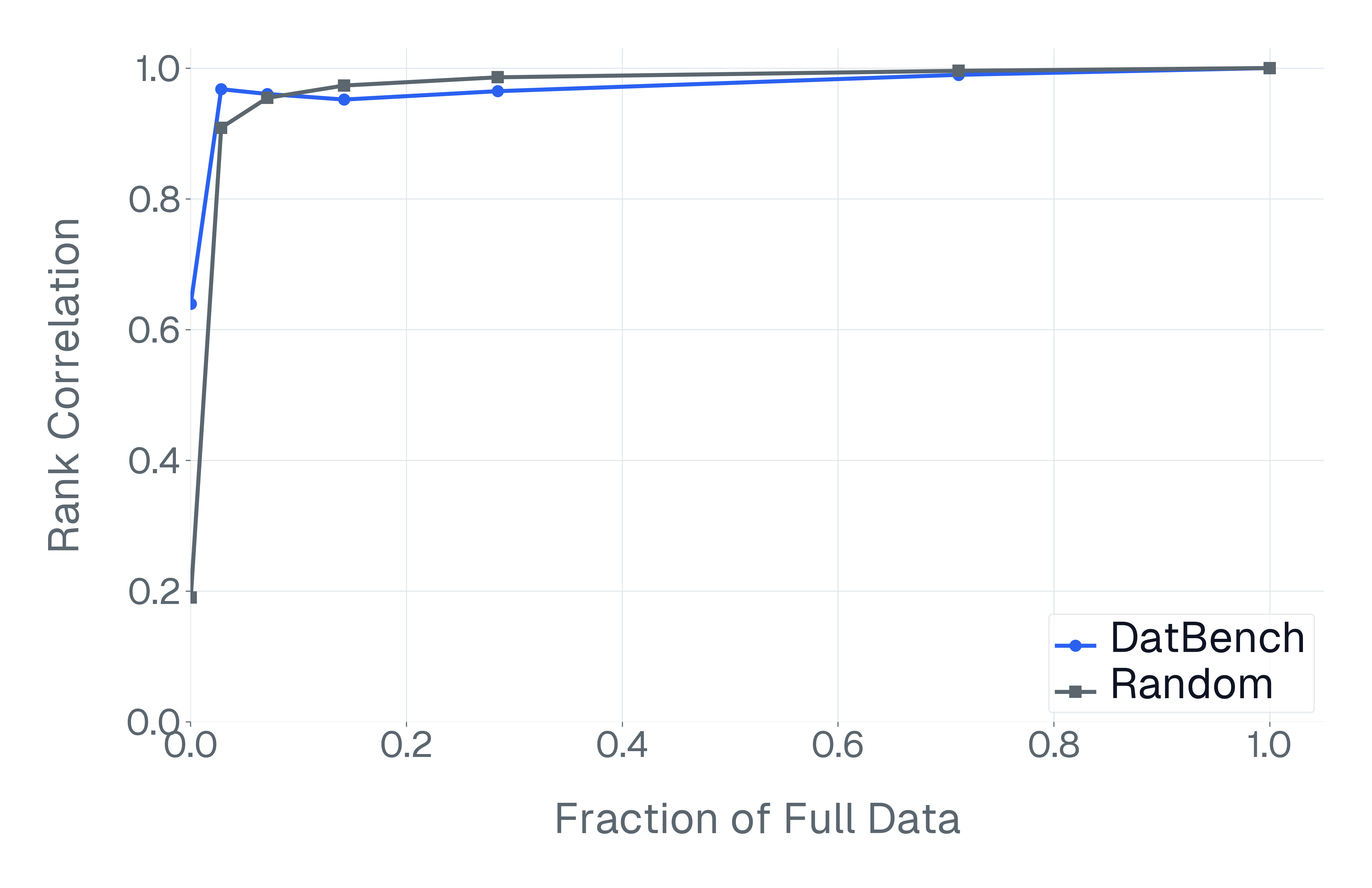
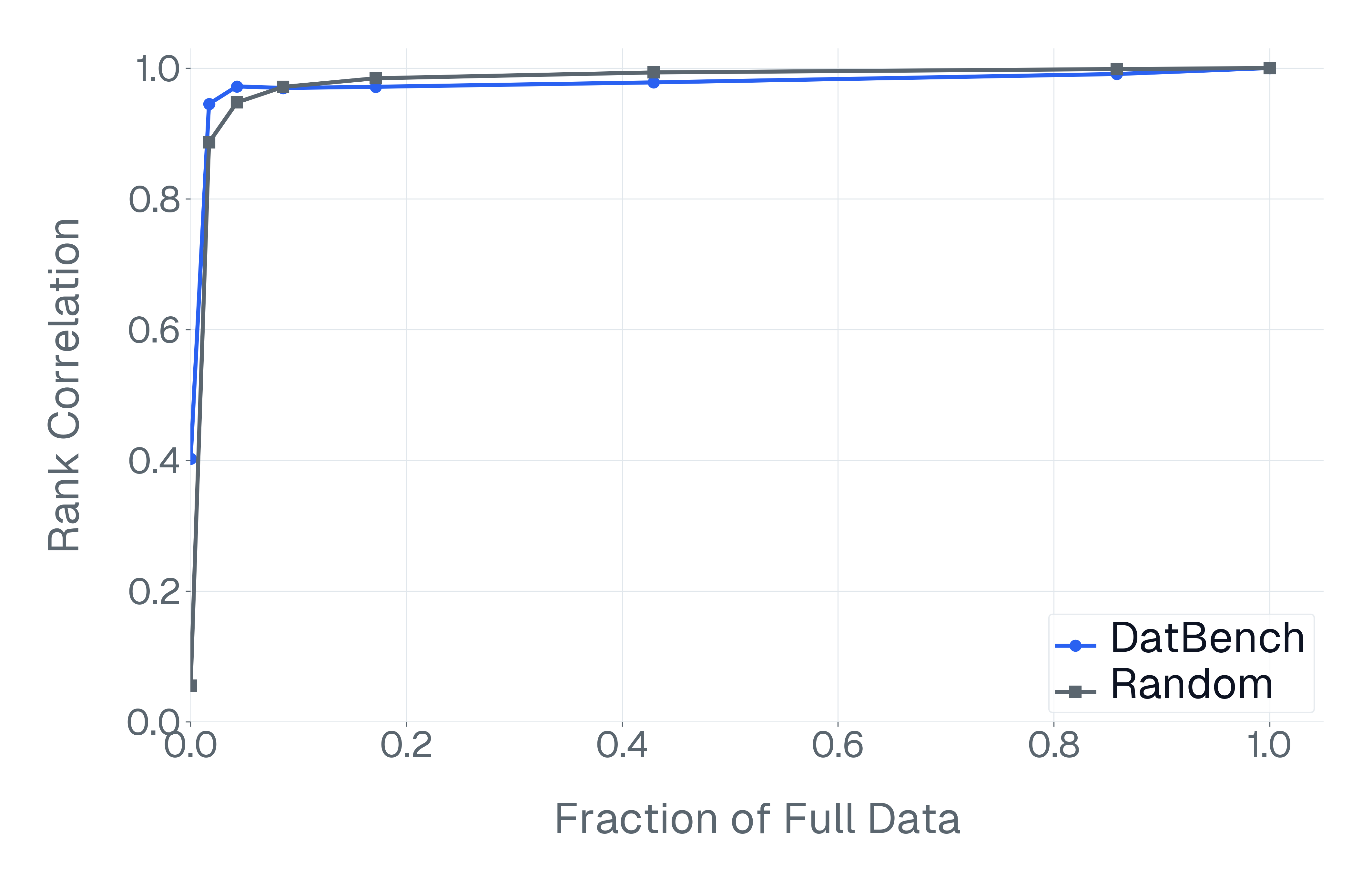
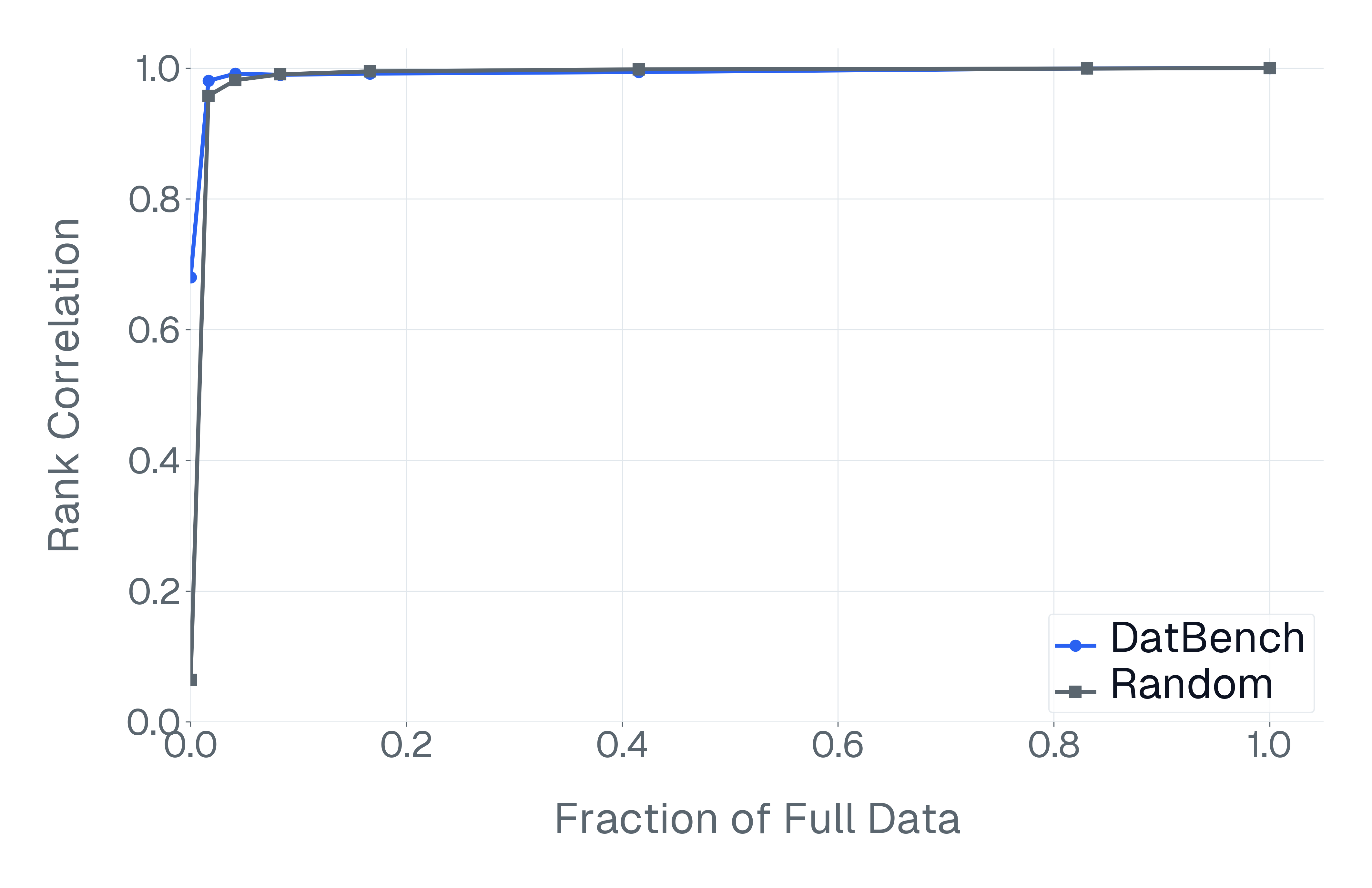
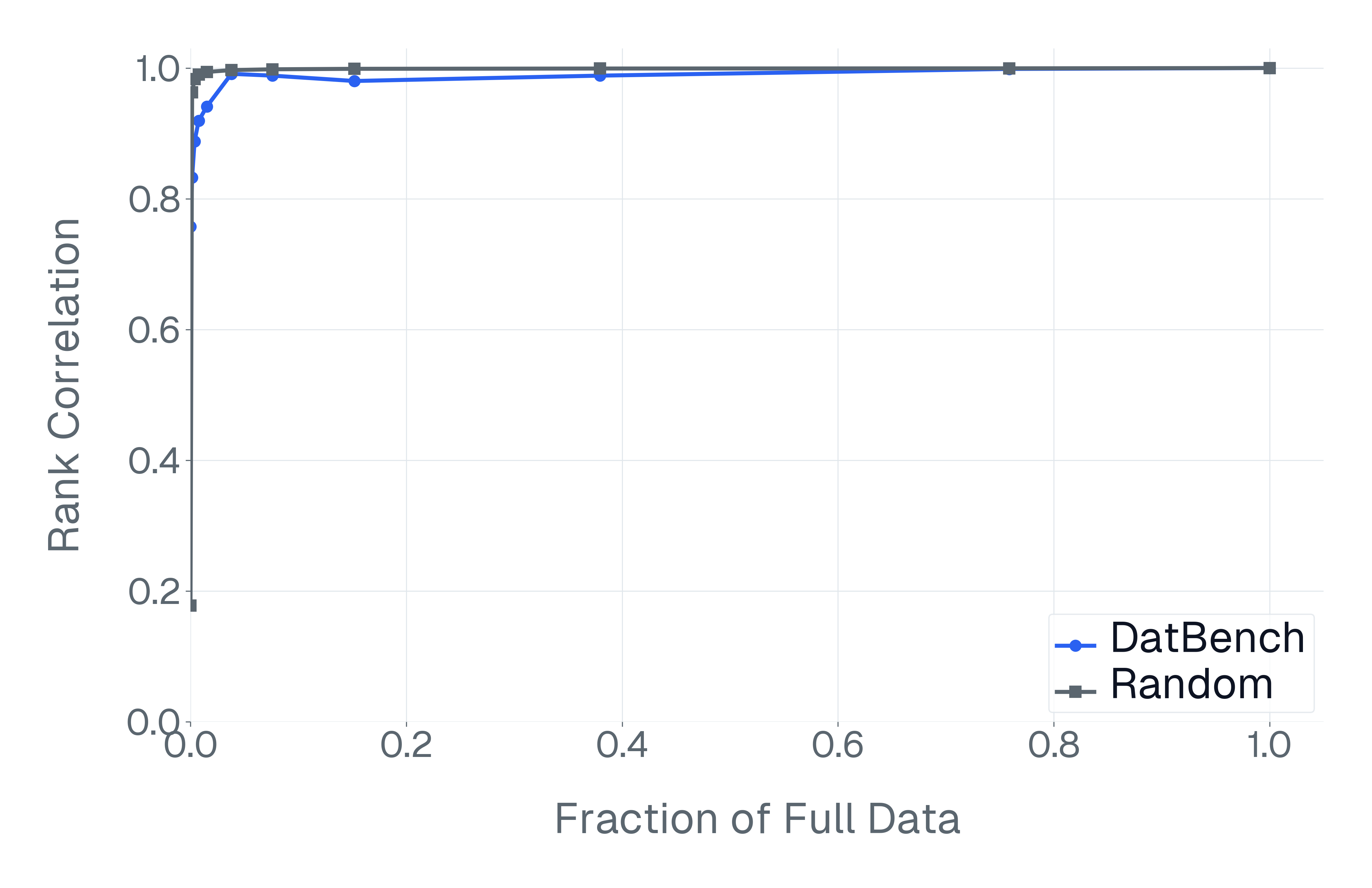
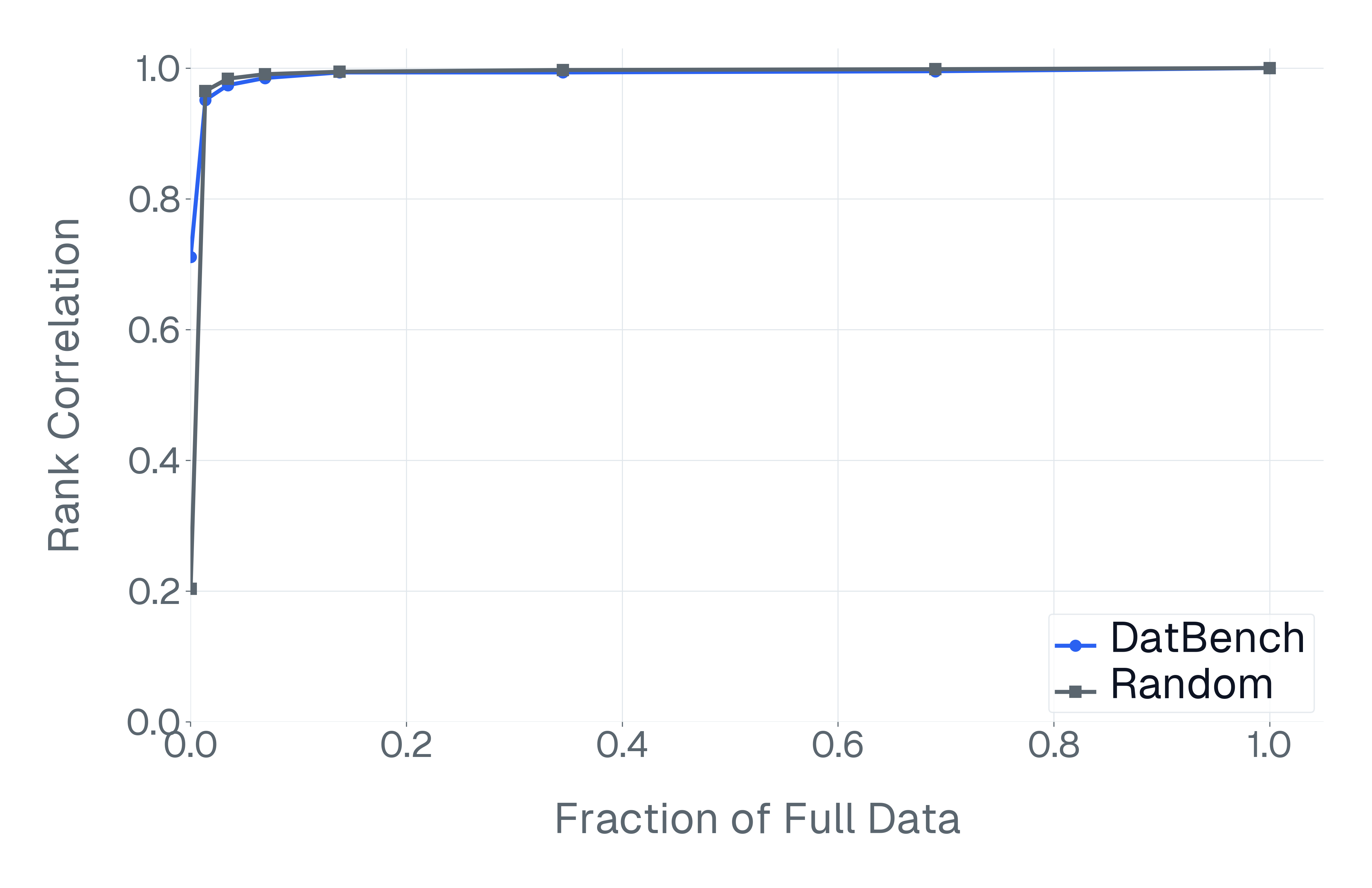
DatBench은 평가 비용을 줄이면서 차별적인 신호를 증가시킵니다. 패널 (a)은 유지된 데이터의 양에 따른 차별화 능력을 보여주며, 표적 선택은 전체 벤치마크의 차별화 능력을 40% 미만의 샘플로 도달할 수 있음을 보여줍니다. 패널 (b)은 평균 H100 시간과 9개 기능에 걸친 상대적인 속도 향상을 보고합니다.
경험적 평가는_FOUNDATION_MODELS의 진전을 인식하고 비교하며 행동하는 주요 메커니즘입니다. 머신 러닝이 좁은, 특정 작업에 특화된 시스템에서 일반적인 목적으로 사용되는 비전-언어 모델(VLMs)로 이동함에 따라 벤치마크는 이제 중요한 역할을 합니다: 무엇이 진전인지 정의하고 실질적인 계산 및 인간 자원 분배를 직접 형성합니다. 평가는 더 이상 수동 보고 도구가 아니라 연구 방향을 주도하는 활성 요소입니다.
그러나 현대의 평가 파이프라인은 측정하려는 행동과 점점 맞지 않게 되었습니다. 모델 입력이 다중 매체를 포함하고 출력이 점차 생성적이고 확률적이 되면서 벤치마크는 진정한 능력을 단순한 휴리스틱 및 내재적인 변동성에서 구분해야 합니다. 언어만을 사용하는 모델의 평가에 대한 방법론적 주목은 지속되어 왔지만, VLM 평가는 비교적으로 덜 조사되었습니다.
최근 증거는 이 격차가 심각한 약점으로 변했다는 것을 시사합니다. 기존 VLM 벤치마크는 데이터 품질 실패를 포함하며 잘못 라벨링되거나 모호한 예제, 시각적 입력 없이 해결 가능한 질문, 다중 선택 형태의 과도한 의존 등이 있습니다. 이러한 요소들은 보고된 정확도를 부풀리고 평가에 큰 잡음을 소개하며 신호 대 잡음 비율을 줄입니다. 이와 같은 환경에서 작은 개선은 종종 몇 퍼센트 수준으로 설명되며, 벤치마크 고유의 특이성을 오버피팅하는 것이 진정한 능력 개선보다 더 가능성 있는 해석을 제공합니다.
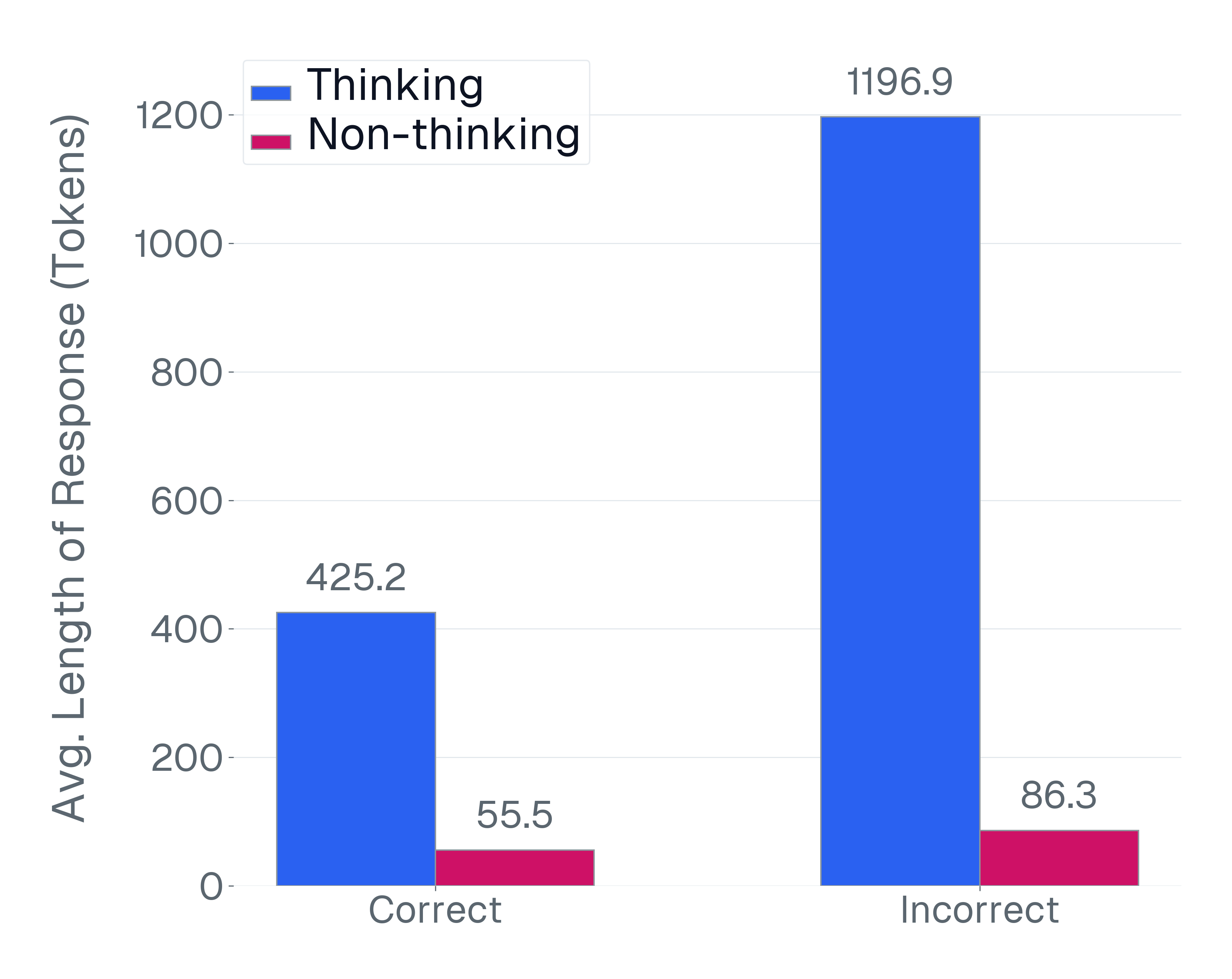
동시에 평가는 주요 계산 병목 현상이 되었습니다. 종합적인 VLM 평가 스위트를 실행하는 것은 총 개발 컴퓨팅의 비중있는 부분을 소비하고 있습니다. 예를 들어, OLMo3 개발 중 후 훈련 단계에서 전체 컴퓨팅 예산의 약 20%가 평가에만 할당되었습니다. VLMs는 고해상도 이미지를 나타내기 위해 필요한 밀집된 시각적 토큰 시퀀스와 추론 시간에 확장된 추론 경로를 통해 각 예제 당 수십 천 개의 토큰을 초과할 수 있습니다. 자세한 분석은 이 비용 대부분이 무의미하거나 잡음이 있거나 약하게 차별적인 샘플 평가에 사용되는 것을 보여줍니다.
본 연구에서는 효과적인 평가 설계를 데이터 커리에이션 문제로 다루어야 한다고 주장합니다. 새로운 벤치마크를 반복적으로 만들기보다, 우리는 체계적으로 평가 데이터를 변환하고 필터링하여 신뢰성, 차별화 능력 및 효율성을 극대화하려 합니다. 이 관점은 최근 훈련 데이터 커리에이션의 성공을 반영하며, 세심한 데이터 변환과 선택은 모델 품질과 컴퓨팅 효율성에서 큰 개선을 가져왔습니다. 우리는 같은 원칙들이 평가에도 동일한 영향을 미칠 수 있음을 보여줍니다.
이 관점을 바탕으로, 현대 VLM 평가 데이터셋에 대한 세 가지 기준을 정의합니다: (i) 신뢰성: 예제는 시각적 입력이 필요하고 의도된 후속 사용 사례를 반영해야 합니다; (ii) 차별화 능력: 예제는 더 강한 모델과 약한 모델 사이를 신뢰할 수 있게 구분해야 합니다; (iii) 효율성: 평가는 단위 컴퓨팅당 신호를 극대화해야 합니다. 이러한 기준은 기존 벤치마크의 네 가지 체계적 실패 모드를 드러내고 표적 개입을 촉구합니다(섹션 3).
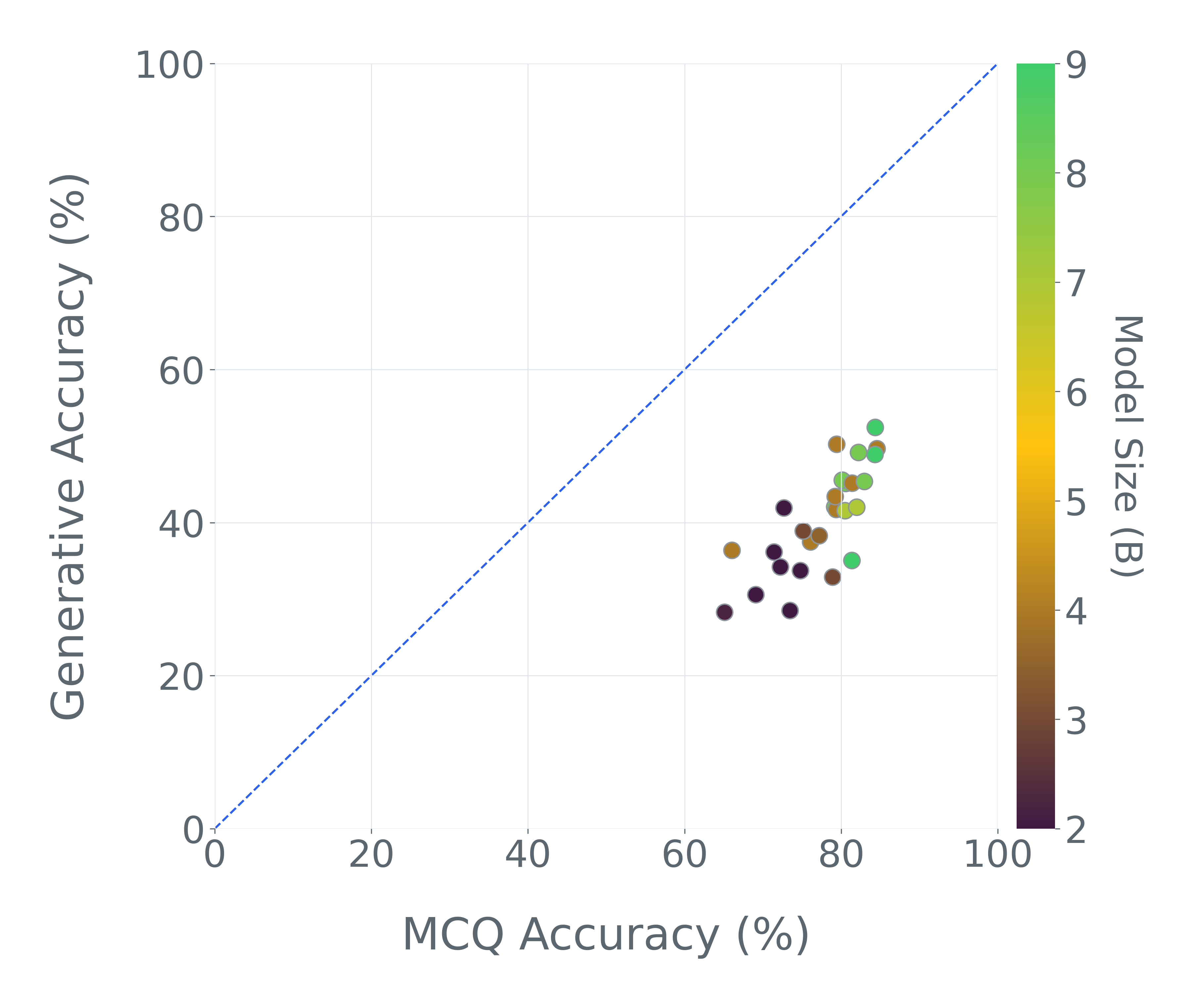
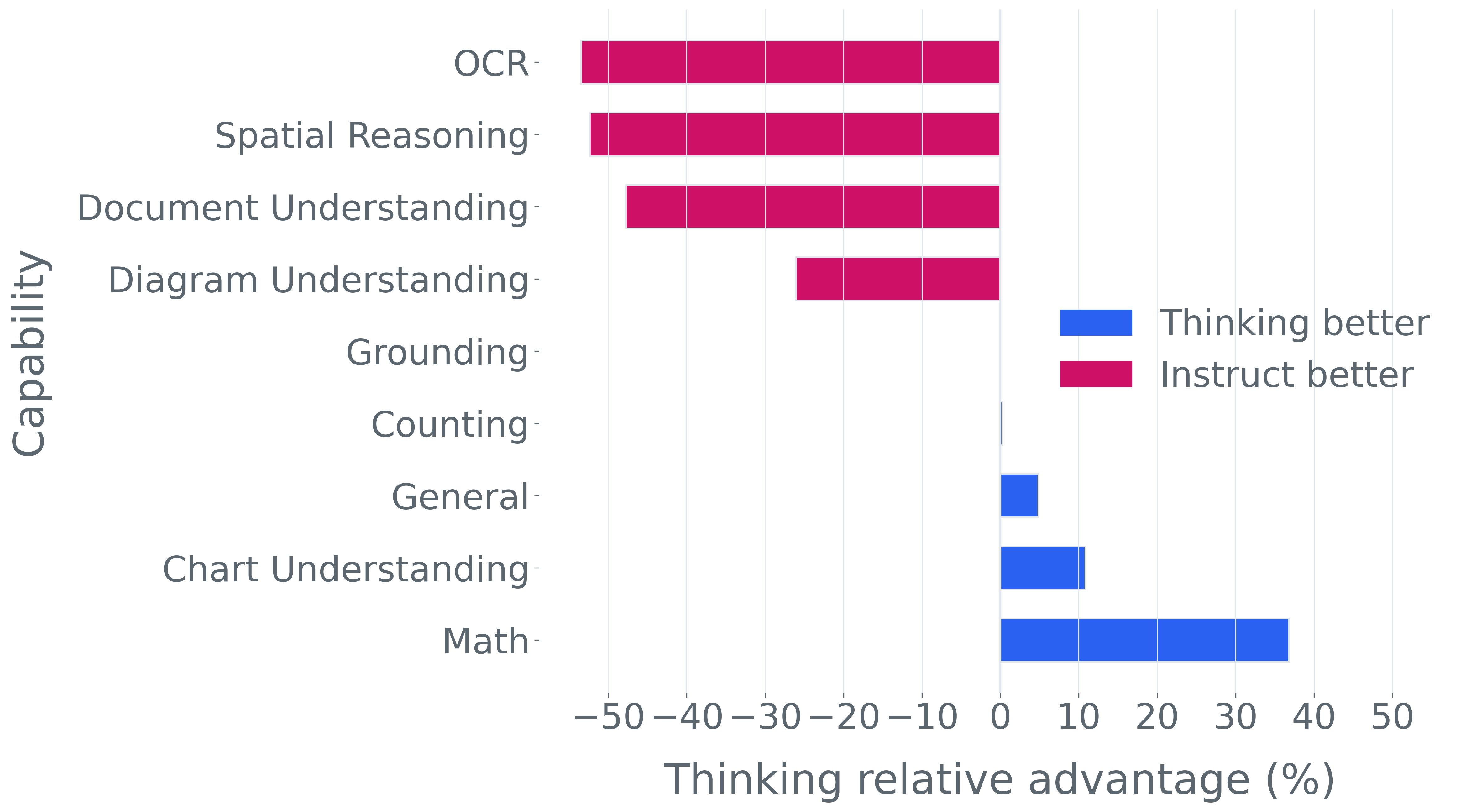
첫째, 다중 선택 형식은 생성 설정에서 신뢰성과 약한 차별화 능력을 갖습니다. MCQ를 오픈 엔드 생성으로 변환하면 큰 숨겨진 능력 격차가 드러납니다. AI2D에서는 평균 정확도가 77.56%에서 40.53%로 하락하며, 가장 강한 MCQ 모델은 거의 35점씩 잃습니다. 생성 변환이 불가능할 때, 순환 평가는 기회 기준을 붕괴시키고 유사한 부풀려진 효과를 노출합니다.
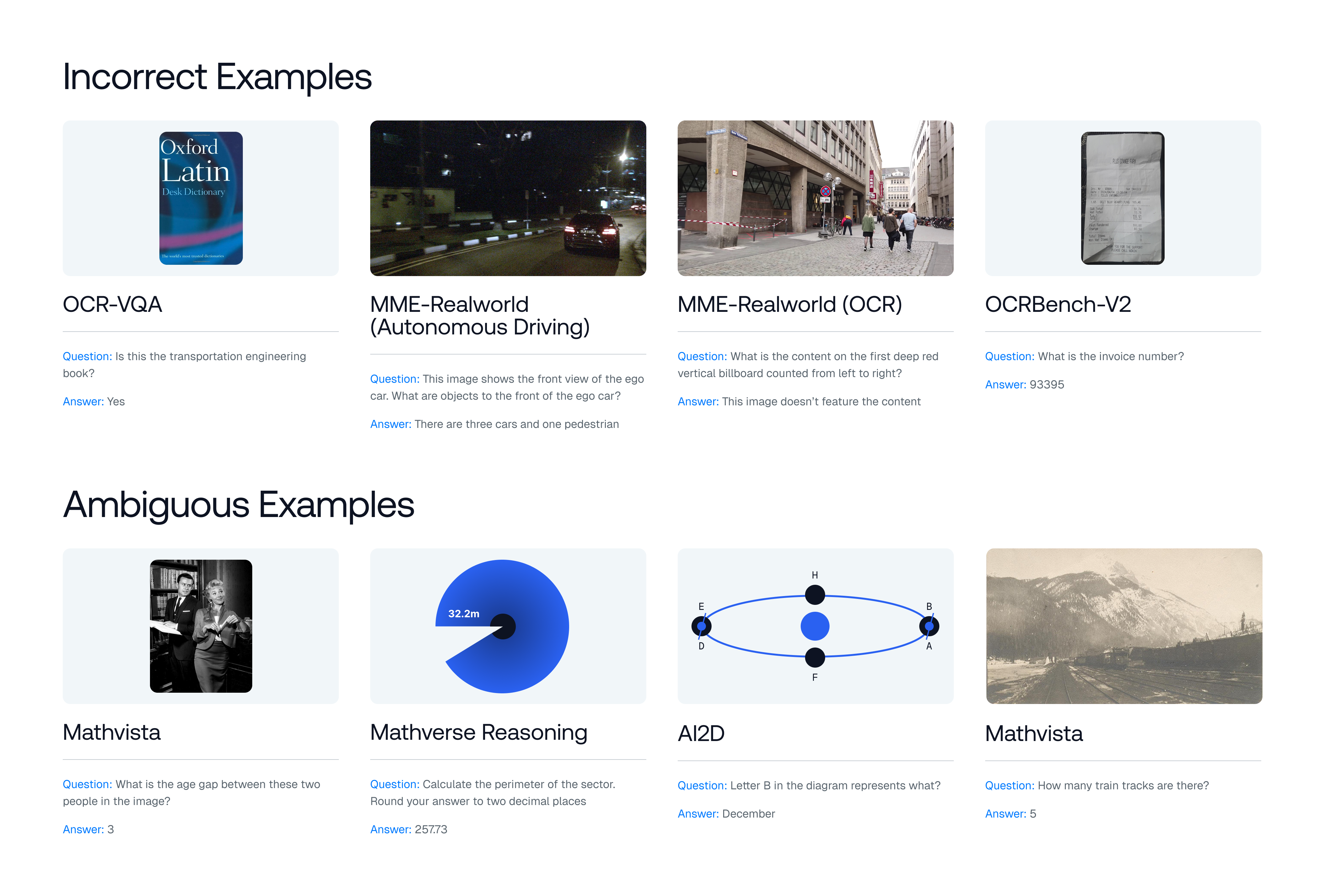
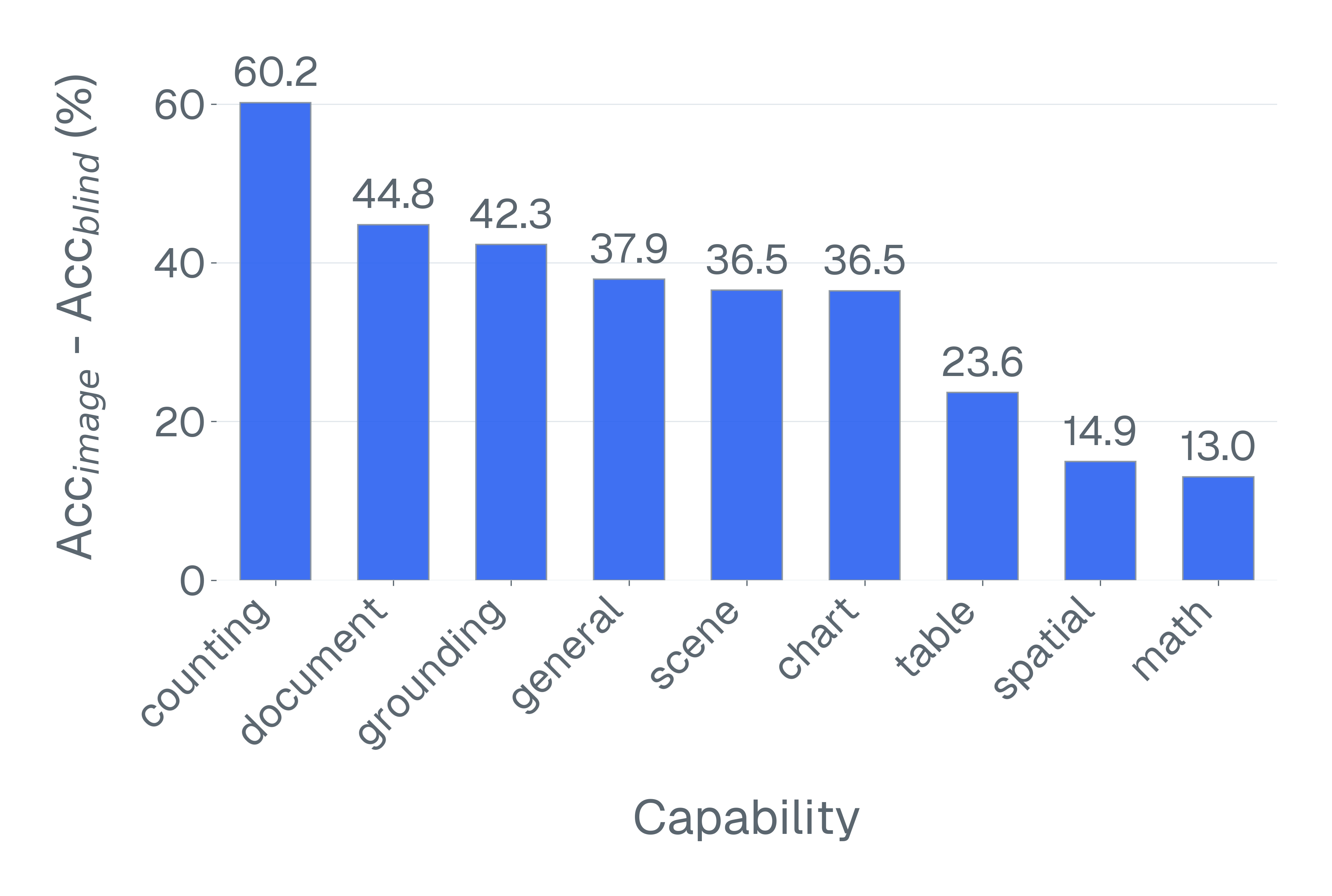
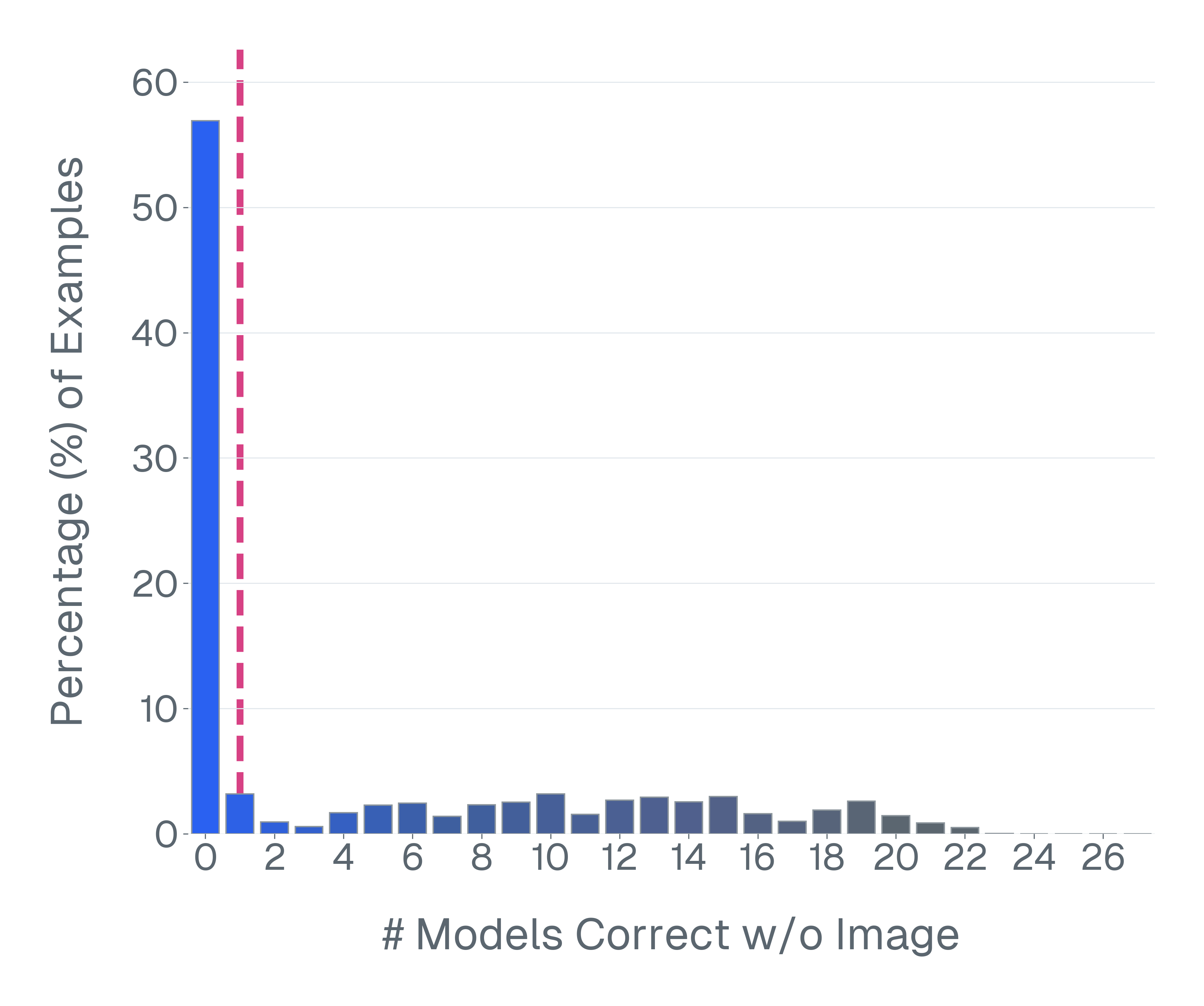
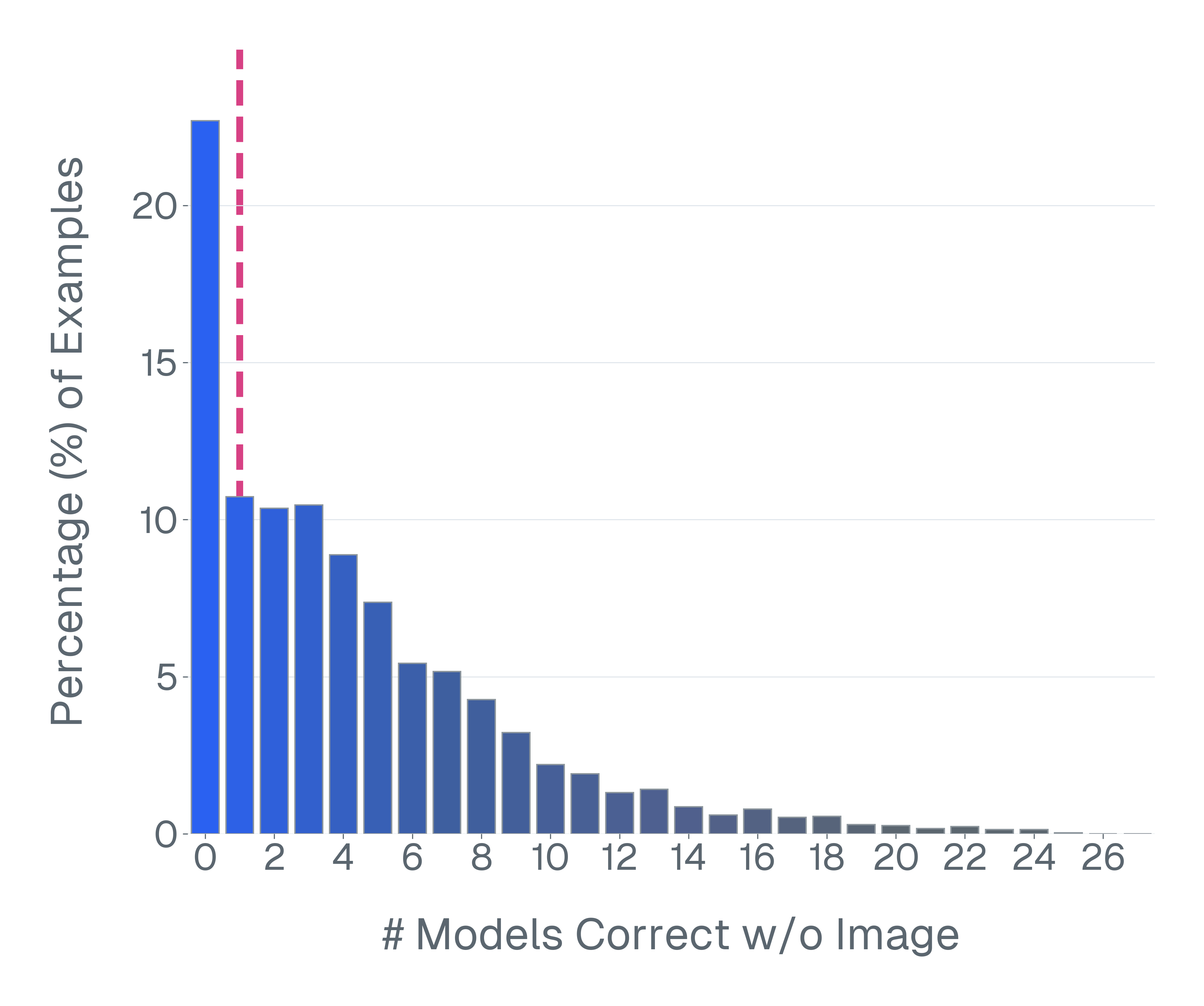
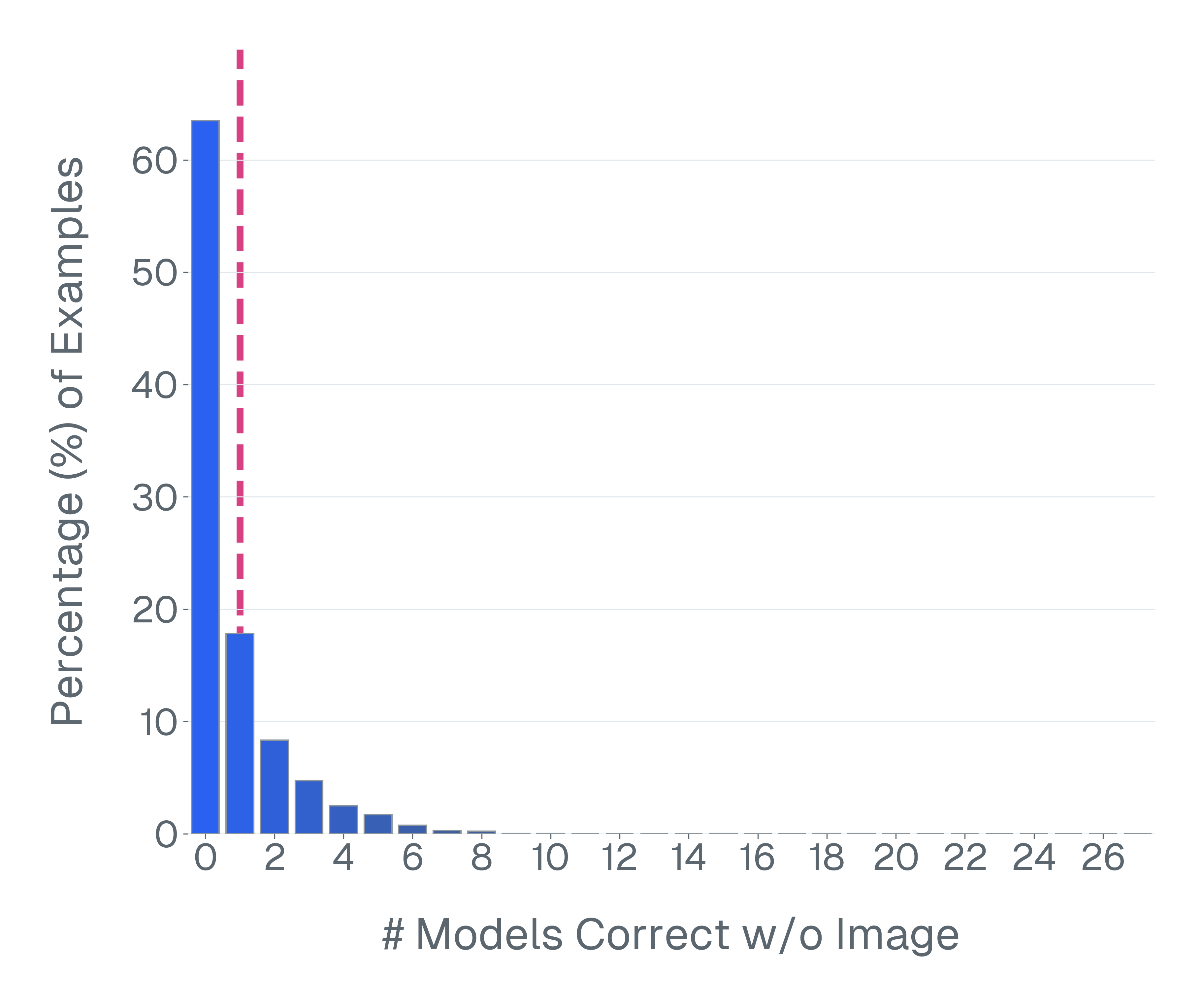
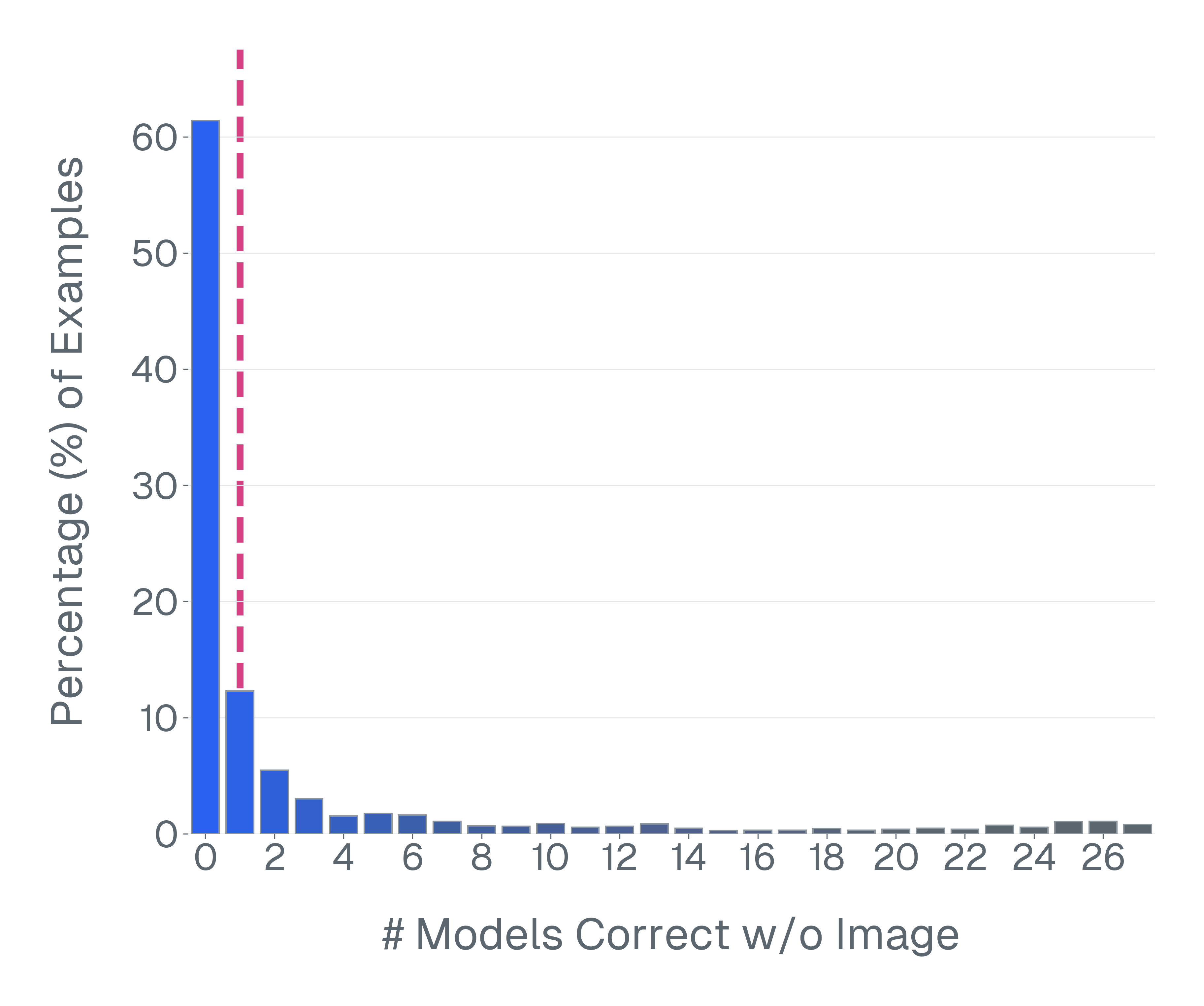
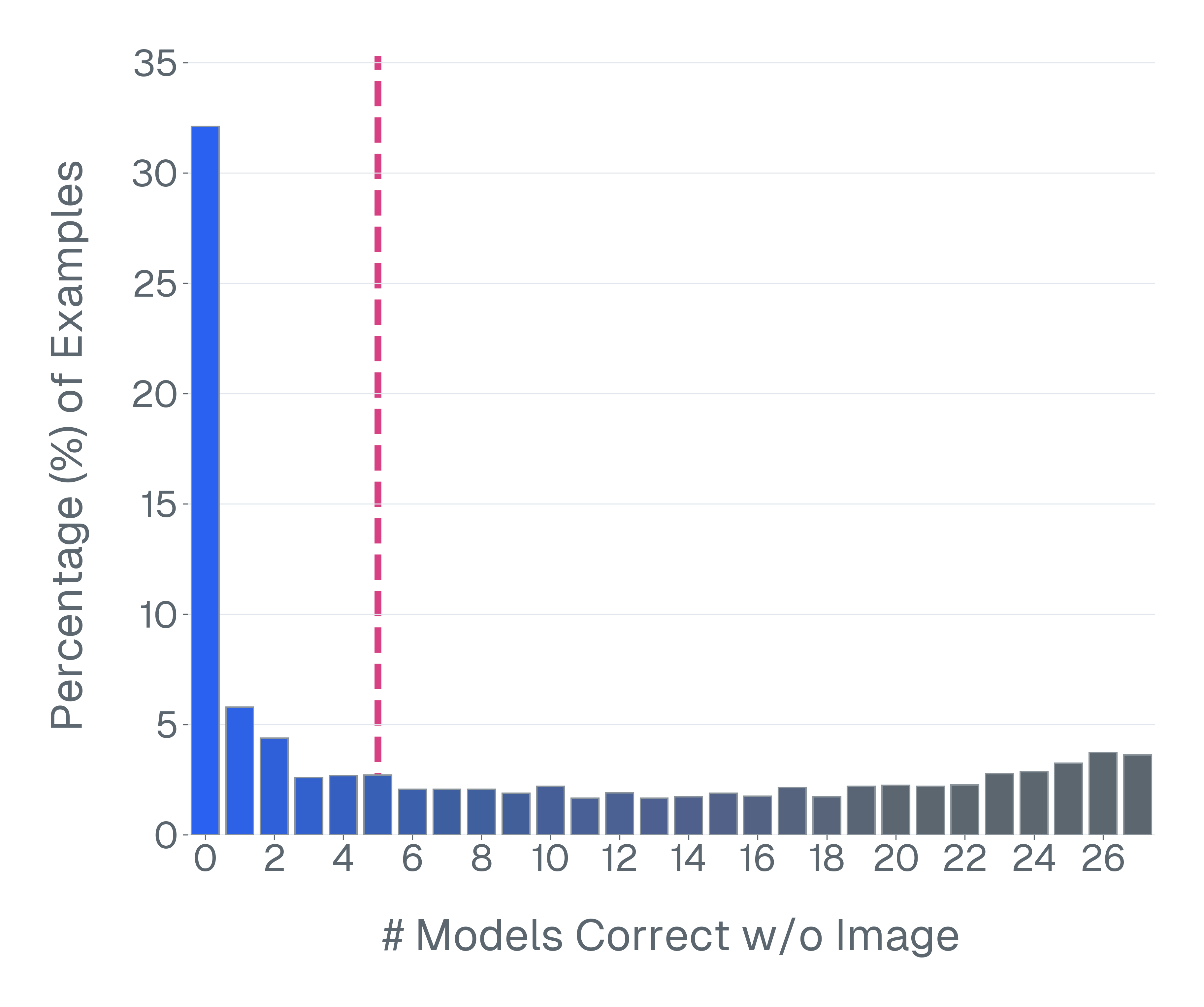
둘째, 많은 VLM 벤치마크는 시각적 입력 없이 해결될 수 있습니다. 이미지를 제거하고 모델을 평가하면 VQA-v2의 샘플 중 70% 이상이 언어 사전 지식만으로 올바르게 답변할 수 있음을 발견합니다. 이러한 예제는 다중 모드 추론을 측정하는 데 실패합니다.
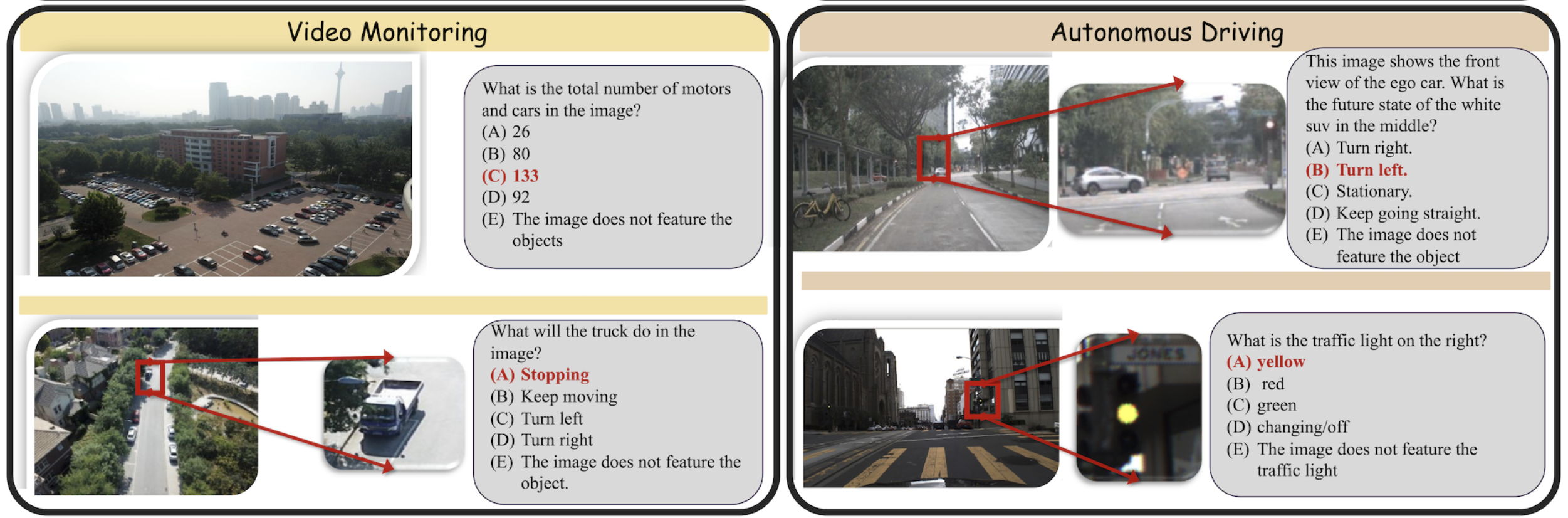
셋째, 저해상도 입력과 부정확하거나 모호한 주석은 큰 잡음을 생성합니다. 여러 단계 필터링 파이프라인을 사용하여 MME-RealWorld(Autonomous Driving) 등의 벤치마크에서 최대 42.07%의 샘플을 제거할 수 있습니다. 이러한 경우 평가는 사실적 라벨링 오류와 결정 불가능한 기준 진실—불량 이미지 품질로 인해 타겟 객체를 식별하기조차 어렵게 만든 것—으로 혼란스러워하며 신뢰할 수 있는 성능 평가를 실질적으로 배제합니다.
넷째, 기존 평가 스위트는 비효율적입니다. 다양한 1B-10B 규모의 모델에 걸쳐 높은 차별화 능력을 가진 항목을 명시적으로 선택하여 최대 50$`\times`$(평균 13$`\times`$)의 속도 향상을 달성하며 전체 벤치마크의 차별화 능력을 소량의 데이터로 가깝게 맞춥니다(Figure 1).
이 개입을 적용하여
DatBench
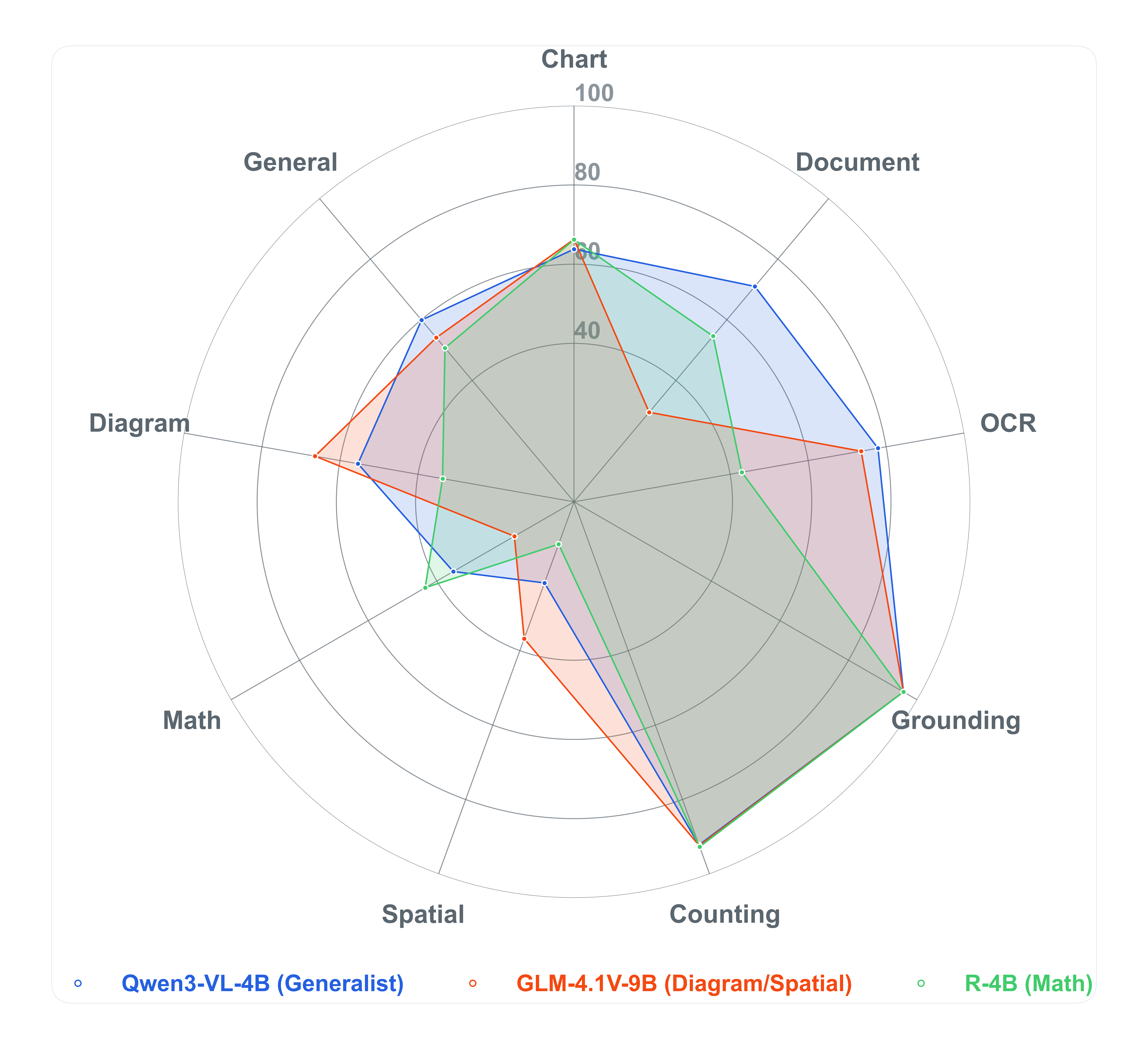
(섹션 4)를 소개합니다. 이는 신뢰성, 차별화 능력 및 컴퓨팅 효율성을 갖춘 VLM 평가 커리에이션 스위트입니다. 이를 구성하기 위해 기존 데이터셋의 대규모 풀을 9개 기본 VLM 기능으로 분할하고 다음과 같은 두 결과물로 공개합니다:
DatBench
, 모든 기능에 걸쳐 평균적으로 13$`\times`$의 속도 향상을 제공하는 고효율 하위 집합으로 샘플당 신호를 증가시킵니다.
DatBench-Full
, 시각적으로 해결 가능하거나 객관적으로 저품질 데이터를 제외한 후 남아있는 고품질 샘플의 전체 콜렉션입니다.
효율성 뿐만 아니라 이 작업은 27개의 최신 VLM에 대한 경험적 통찰력을 제공하여 전통적인 평가 아래에서는 구조적인 한계를 보이지 않게 합니다(섹션 5). 우리는 추론 시간 확장을 통해 인식 성능을 악화시키는 과도한 사고 패널티, 현재 VLM이 고수준 추론과 저수준 인식 사이의 급격한 긴장 관계를 보이고, 언어 사전 지식이 일반적인 벤치마크에서 진정한 다중 모드 능력을 체계적으로 가리고 있음을 보여줍니다. 이러한 리소스와 결과는 평가 품질을 개선하면서 비용을 극적으로 줄이는 동시에 빠른 발전 속도에 맞추어 평가 관행을 개선하는 경로를 제공합니다.
관련 연구
신뢰성 있는 평가. 최근 연구는 VLM 벤치마크의 유효성 문제를 식별하여 다양한 감소 전략을 제안하고 있습니다. 다중 선택 평가에서 높은 위험 기준에 의해 발생하는 성능 부풀리기를 해결하기 위해 여러 연구에서는 작업을 생성적 답변 매칭 설정으로 재구성하거나 순환 평가 기술을 사용하는 것을 제안합니다. 더 넓게 보면, 이전 연구는 애매하고 쉽게 풀 수 없는 비교 프롬프트가 모델에게 체계적으로 잘못된 선호를 유발할 수 있음을 보여주며, 평가 프롬프트 자체가 충분한 근거나 맥락 없이 선택을 강제하는 경우 감성적인 편향의 은밀한 원천이 될 수 있습니다. 이는 순환 평가 및 기타 옵션 강건 MCQ 프로토콜과 같은 개입을 더 촉구합니다. 다른 노력은 평가 메트릭의 통계적 정제에 초점을 맞춥니다. 예를 들어, 아이템 반응 이론(IRT)을 동기화한 가중치를 적용하여 단순 평균 정확도를 넘어서 항목 난이도와 차별성을 고려합니다.
이러한 문제 외에도 다중 선택 형식은 실제 VLM 사용과 맞지 않습니다. 모델들은 일반적으로 작은, 사전에 정의된 옵션 세트에서 선택하는 것이 아니라 개방형, 생성적 설정에서 배포됩니다. 결과적으로 강력한 MCQ 성능은 옵션 제거나 프롬프트 특정 편향을 보상하여 실제 능력을 과대평가할 수 있으며, MCQ 기반 평가는 모델의 능력을 제약하고 생성적 행동을 탐색하지 않아서 실세계 LLM 및 VLM 배포에서 주도적인 역할을 하는 것을 체계적으로 왜곡합니다.
추가 분석은 많은 VLM이 시각적 입력을 의미있게 활용하지 않고 특정 벤치마크에서 잘 수행될 수 있음을 제시하며, 이러한 평가가 실제로 시각적 이해 또는 다중 모드 추론을 측정하는지 의심스럽습니다. 이에 대비해 신호를 복구하려는 후속 통계적 모델링 접근법과 달리, 우리의 방법은 체계적인 변환 및 필터링을 통해 벤치마크 예제의 데이터 품질을 개선하여 평가 신뢰성을 근본적으로 개선했습니다.
효율성 및 차별화 평가. 모델 평가 효율성을 높이기 위한 노력은 크게 (1) 심리 측정 모델링, 그리고 (2) 평가 데이터의 의미 구조 활용에서 나옵니다. IRT 기반 방법은 잠재 능력 변수를 모델링하여 항목 난이도와 차별성을 추정합니다. 실제로 이러한 접근법은 일반적으로 많은 모델을 여러 항목에 대한 평가로 구성된 큰, 밀집형 응답 행렬을 필요로 하며, 이 규모가 없으면 추정치는 하이퍼파라미터 선택에 매우 민감해질 수 있습니다.
다른 연구는 의미 구조를 활용합니다. 예를 들어, 임베딩 기반 클러스터링을 사용하여 대표적인 하위 집합을 선택하거나 Scales++는 정성적, 루브릭 기반 작업 세분화에 의존합니다. 이러한 접근법은 주목할 만한 한계를 가지고 있습니다. 클러스터링 결과는 임베딩 모델의 선택과 긴밀히 연결되어 있으며, 통일된 다중 모드 임베딩이 부족함을 고려하면 이는 큰 문제입니다. 반면에 루브릭 기반 방법은 본질적으로 노동 집약적이고 주관적이며.
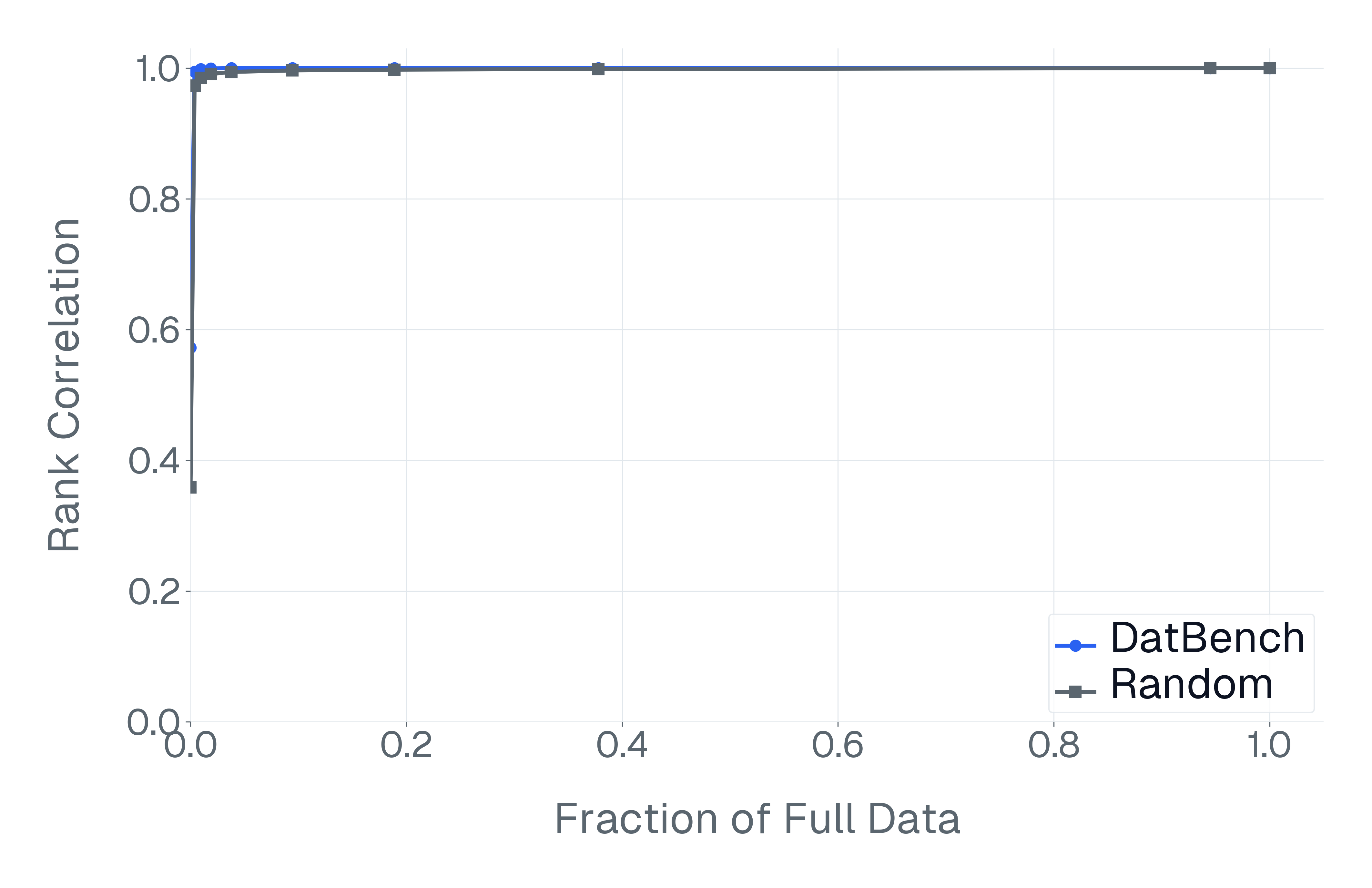
더 넓게 보면, 단순히 모델 순위를 유지하려고 최적화하는 접근법에는 근본적인 한계가 있습니다. 섹션 3.4에서 보여주듯이, 순위 상관은 빠르게 포화되고 종종 무작위 하위 집합에서도 달성될 수 있으며 개별 샘플들은 약한 모델과 강한 모델 사이를 신뢰할 수 있게 구분하지 않습니다. 결과적으로 순위 안정성을 우선시하면 고정된 평가 모델 세트에 대한 과적합 위험을 초래하며 기본적인 예제의 품질을 보장하지 않습니다. 이전 연구는 다양한 측정값을 결합하는 문제를 해결하기 위해 Plackett-Luce 모델을 통해 다종류 평가를 집계하는 것을 제안하며, 이것은 메트릭 교정 문제에 강건한 순위의 중요성을 강조합니다. 이 접근법은 데이터 품질 아래에서 작동하며 잡음이 많거나 시각적으로 해결 가능한 샘플을 통합하면 최종 순위로 이러한 요소가 전파됩니다.
이러한 접근법과 달리 우리는 전체 순위를 유지하는 것보다 개별 샘플의 타겟 커리에이션에 초점을 맞춥니다. 먼저, 우리는 신뢰성 문제 해결을 위한 평가 데이터의 체계적인 변환 및 필터링을 수행합니다. 두 번째로, 우리가 사용하는 차별화 하위 집합 선택 전략은 순위 유지 방법과 달리 대규모 모델 응답 행렬이 필요하지 않은 높은 신호 샘플을 식별합니다.
**DatBench**의 제작
MCQ 평가: 고 잡음, 저 신뢰성
이 섹션에서는
DatBench
의 방법론을 소개합니다. 이 프레임워크는 소음을 포함한 대규모 VLM 평가 스위트를 고품질, 차별화된 벤치마크로 변환하는 데 초점을 맞춥니다. 우리의 접근법은 현재 평가 체계에서 네 가지 중요한 실패를 체계적으로 해결합니다: (1) 다중 선택 질문(MCQ)의 신호 희석, (2) 시각적 맥락 없이 해결 가능한 예제, (3) 잘못된, 모호하거나 저해상도 샘플, 및 (4) 계산 비용이 너무 높음. 첫 세 가지 개입은 평가 데이터의 신뢰성과 차별화 능력을 향상시키며, 네 번째는 결과 벤치마크가 효율적이고 차별화된 것임을 보장합니다.
데이터셋 및 기능.
우리의 목표는 9개의 독립적인 VLM 기능에 대한 신뢰성 있고 차별화되며 효율적인 평가를 구축하는 것입니다(그림 2 참조): (1) 차트 이해: 막대 그래프, 원형 차트, 선 그래프 및 정보그래픽에서 양적 데이터를 추출하고 트렌드 분석을 수행하는 것; (2) 문서 이해: 디지털 또는 스캔된 문서의 구조화된 레이아웃을 파싱하고 텍스트 중심의 시각적 처리에 중점을 두고 핵심 정보를 추출하는 것; (3) 장면 OCR: 상점 이름, 길 표지판 및 제품 라벨과 같은 자연 환경에서 발견되는 텍스트 정보를 인식하고 해석하는 것; (4) 수학 및 논리: 기하학, 물리 학습자료표, 복잡한 논리 퍼즐을 포함하는 다중 모드 수학 문제 해결; (5) 공간 추론: 객체의 상대 위치를 평가하고 방향성과 3D 공간에 대한 물리적 이해력을 보여주는 것; (6) 근거 설정: 텍스트에서 언급된 특정 영역이나 객체를 경계 박스 또는 분할형 작업을 통해 식별하고 로케이션하는 것; (7) 세기: 다양한 환경과 겹치는 시각적 컨텍스트에서 특정 객체의 정확한 수를 계산하는 것; (8) 도표 및 표: 학교 수준의 도표와 구조화된 표에서 데이터 포인트를 해석하고 추론하고 있는 관계를 추출하는 것; 그리고 (9) 일반적인: 전체적인 이미지 설명과 실제 세계 장면 이해 기반의 고수준 시각적 질문 답변(VQA). 이를 달성하기 위해 각 기능에 대한 다양한 평가 세트를 수집하고 문제 (1)-(4)를 해결하기 위한 방법론을 적용합니다. 변환